
Accumulating technical dept may lead your company to a crisis. But it may also become a powerful driver of massive process changes and help with engineering practices adoptions. I'll tell you about it on my own example.

Dodo Pizza IT team grew from 2 developers serving one country to 60 people serving 12 countries over the course of 7 years. As a Scrum Master and XP Coach I helped teams establish processes and adopt engineering practices, but this adoption was too slow. It was challenging for me to make the teams keep high code quality when multiple teams work on a single product. We fell into the trap of preference for business features over technical excellence and accumulated too much architectural technical debt. When marketing launched a massive advertising campaign in 2018, we couldn’t stand the load and fell down. It was a shame. But during the crisis, we realized that we are able to work many times more efficiently. The crisis has pushed us towards revolutionary changes in processes and the rapid introduction of best-known engineering practices.
You may think that Dodo Pizza is a regular pizzeria network. But actually Dodo Pizza is an IT company who happens to sell pizza. Our business is based on Dodo IS — cloud-based platform, which manages all the business processes, starting from taking the order, then cooking and finishing to inventory management, people management and making decisions. In only 7 years we have grown from 2 developers serving a single pizzeria to 70+ developers serving 470+ pizzerias in 12 countries.
When I joined the company two years ago, we had 6 teams and about 30 developers. The Dodo IS codebase had about 1M lines of code. It had a monolithic architecture and very little unit tests coverage. We had no API/UI tests by then. The code quality of the system was disappointing. We knew it and dreamed about bright future when split the monolith into dozen of services and rewrite the most hideous parts of the system. We even draw the “to be architecture” diagram, but honestly did almost nothing towards the future state. My primary goal was to teach the developers engineering practices and build a development process, making 6 teams work on a single product.
As the team grew we suffered from lack of clear process and engineering practices more. Our releases became bigger and longer because more and more developers contributed to the system, but we had no automated regression tests and therefore wasted more time on manual regress with every release. We suffered from many changes made by 6 teams in separate branches. When a teams merged their changes to a single branch before release, sometimes we used to lose up to 4 hours resolving merge conflicts.
When I came to Dodo 2 years ago as Chief Agile Officer, I had a great desire to make of our then small team — about 12 people, a dream team. I immediately began to introduce engineering practices. Most of the teams adopted pair programming, unit testing and DDD pretty soon. But not everything was easy. I had to overcome the resistance of the developers, the Product Owner, and the support team.
As opposed to engineering practices, not everyone favored the idea of feature teams. Developers were used to thinking that a team focused on one component is writing better code. It was not clear how to combine the rapid development of business features with the long overdue massive refactoring of a complex system. A continuous stream of bugs also required constant attention. The support team favoured having their own team focused on bugs fixing only. Many teams were used to working in separate branches and were afraid to integrate frequently. We released no more than once a week, and each release took quite a long time, required tremendous amount of manual regress and UI tests support. I tried to fix it, but my process changes were too slow and fragmented.
In pursuit of the speed of developing business features, we have not always thought through technical solutions well. A lack of experience affected us as well. In the beginning, the company could not afford hiring the best developers. We worked with enthusiasts who agreed to help with the creation of Dodo IS, believed in the founder of the company — Fedor and worked almost for food (pizza, of course). The developers who joined the team later followed the established architecture, which became outdated. So we had a monolithic application with a single database, containing all the data from all the components in one place. Tracker, checkout, site, API for landing pages — all components of the system worked with a single database, which become a bottleneck. Our monolithic architecture created monolithic problems. A single blog post led to a restaurant checkout outage.
Monolithic architecture is good to start because it is simple. But it can not withstand the high load being a single point of failure.
February 14 is a Valentine's Day. Everyone loves this holiday. For lovers to congratulate each other, on February 14 we make a special pizza — pepperoni in the shape of a heart. I will remember the February 14, 2018 forever, because on this day, when all the pizzerias were working at full load, Dodo IS started to fall. In each pizzeria we have 4-5 tablets for tracking which order a pizza maker makes dough for, put ingredients, bake or send to delivery. The number of pizzerias reached 300+, each tablet updated its state multiple times per minute. All these requests created such a massive load on the database that the SQL server ceased to withstand and the database started to fail. Dodo IS laid down at the most inappropriate moment — during the peak of sales. There was a busy holiday season ahead: February 23 (Army and Navy Day), March 8 (International Women's Day), May 1 (Day of International Solidarity of Workers) and May 9 (Victory Day in World War II). During these holidays, we were expecting an even greater orders growth.
The day when you will die. Knowing our growth plans and the limit of the load that we can withstand, we figured out how long we can stay alive, that is, when today's peak load becomes regular. The estimated date of Armageddon expected in about six months — in August or September. How does it feel to live, knowing the date of your death?
Stop feature development for a year. Together with CEO Fedor, we had to make an arduous decision. Perhaps one of the most difficult decisions in the history of the company. We stopped the development of business features. We thought we would stop for 3 months, but soon we realized that the volume of technical debt was so great that 3 months would not be enough and we have to continue working on technical issues and postpone the business backlog. In fact, with 6 teams we have made only one business feature during the next year. The rest of the time, the teams were engaged in the repayment of technical debt. This debt cost us a lot — over $1.5 mln.
Over the year, we had these notable accomplishments:
Our architect managed the technical backlog. We used the architectural changes to drive the backlog. Each team had the freedom to do what was right to create a useful architecture. For the year with the 6th teams we made for business only one valuable feature. The rest of the time, the teams worked on technical debt. It would seem that we can be proud of ourselves. But ahead of us there was a huge disappointment.
Fail during Federal Marketing Campaign. The second crisis of trust.
Technical debt is easy to accumulate, but very difficult to repay. It is unlikely that you will be able to understand in advance how much it will cost you.
Despite the fact that we spent a whole year fighting technical debt, we were not ready for massive Marketing Campaign and screwed up in front of our business. You gain trust in drops, you lose it in buckets. And we had to gain it again.
We missed the moment when it was necessary to slow down the speed of developing business features and tackle technical debt. It was too late when we noticed. We lay down under load again. The system crashed and rebooted every 3 hours. Our business lost tens of millions of rubles.

But thanks to the crisis, we saw that in extreme conditions we can work many times more efficiently. We released 20 times a day. Everyone worked as one team, focusing on a single goal. During two weeks of crisis, we’ve done what we were afraid of starting before because we believed it would take months of work. Asynchronous order, performance tests, clear logs are only a small part of what we did. We were eager to continue to work as effectively, but without overtime and stress.
After the retrospective, we completely restructured our processes. We took the LeSS framework and supplemented it with engineering practices. Over the next few months, we made a breakthrough in the engineering practices adoption. Based on the LeSS framework, we have implemented and continue to use:
1. The power of focus. Before the crisis, each team worked on its own backlog and specialized in its domain. In the backlog, there were finely decomposed tasks, the team selected several tasks for a sprint. But during the crisis, we worked quite differently. The teams did not have specific tasks, they had a big challenging goal instead. For example, a mobile app and API must handle 300 orders per minute, no matter what. It is up to the team how to achieve the goal. The teams themselves formulate hypotheses, quickly check them in Production and throw away. And this is exactly what we wanted to continue doing. Teams do not want to be dumb coders, they want to solve problems.
The power of focus manifested itself in solving complex problems. For example, during the crisis, we created a set of performance tests in spite we had no expertise. We also made the logic of receiving an order asynchronous. We have long thought about it and talked, and it seemed to us that this is a very difficult and long task. But it turned out that the team is quite capable of doing it in 2 weeks, if it they are not distracted and completely focused on the problem.
2. Regular hackathons. We liked to work in the mode when all the teams are aimed at one goal and we decided to sometimes arrange such a “hackathons”. It cannot be said that we carry them out regularly, but there was a couple of times. For example, there was a 500-errors hackathon when all the teams cleaned the logs and removed the causes of 500 errors on the site and in the API. The goal was to keep the logs clean. When the logs are clean, the new errors are clearly visible, you can easily configure the threshold values for the alerts. It is similar to unit tests — they can not be a little red.
Another example of a hackathon is bugs. We used to have a huge bugs backlog, some of the bugs had been in the backlog for years. It seemed that they would never end. And every day there were new ones. You have to somehow combine work on bugs and on regular backlog items.
3. Temporary project teams to stable feature teams. There was a funny story with project teams. During the crisis, we formed tiger teams of people who were best skilled for the task. After the crisis was over the teams decided to continue this practice and disband the teams. Despite the fact that I didn’t like this idea at all, I let them try. In just 2 weeks (one sprint), at the next retrospective, the teams abandoned this practice, (this decision made me extremely happy). They tried and understood why it is much more comfortable to work in a stable feature team. Even if the team lacks some skills, they can gradually learn. But the team spirit, support and mutual assistance is formed for a long time, it takes months. Short-term project teams are constantly in forming and storming phase. You can endure it for a couple of weeks, but you cannot work like this all the time. It’s good that the teams tried and understood the benefits of stable feature teams.
4. Get rid of manual regress. Before the crisis, we released once a week, and during the crisis — dozens of times a day. We loved our ability to release often. We appreciated how convenient it was to make a small change, quickly deploy it and immediately get feedback from production. Therefore, we changed our approach to releases, and this affected the approach to programming and design. Now we release continuously, every 1-2 days. Everything in the dev branch goes into production. Even if some features are not ready, this is no reason not to release the code. If we don’t want to show some not-ready yet feature to users, we hide it with feature toggles. This approach helped us to develop in small steps.
We set a goal to get rid of manual regressions. It took us 1.5 years to reach it. But having a long-term ambitious goal makes you think about steps leading to the goal.
5. Performance Test is part of the regression test. During the crisis we created a set of performance tests. It was a completely new area for us. Nevertheless, in just 2 weeks, we managed to create some performance tests using Visual Studio tools. These tests helped us not only catch performance degradation. We used them to add synthetic load to Production server to identify the performance limits. For instance, if the organic production load is 100 orders/min and we add 50 more orders/min with help of our performance tests, we can see if the Production servers can handle the increased load. As soon as we notice exceptions or increased latency, we stop the test. Making these experiments, we figured out the max load our Production servers can handle, and what will be the hotspot.
Next year we outstaffed the performance tests to experienced PerformanceLab team. They sat together with our developers and infrastructure people, and helped us create a robust set of performance tests. Now we run these tests weekly and provide fast feedback to development teams if performance is impacted.
Some of the engineering practices were iteratively refined. For example, frequent releases. We started with weekly release cycles, supported with slow and fragile manual testing. We developed features for one week and tested for another week. But it was hard to maintain changes made by multiple during a week. Then we tried isolated team releases, when only changes made by single team were released. But this process failed because every team had to wait in the queue for several weeks. Then the teams learned benefits of frequent integration and we started practicing joined releases of multiple teams changes. The developers started to experiment with Feature Toggle and push to Production unfinished features. Eventually we came to Continuous Integration and multiple releases per day for monolith and Continuous Deployment for microservices.
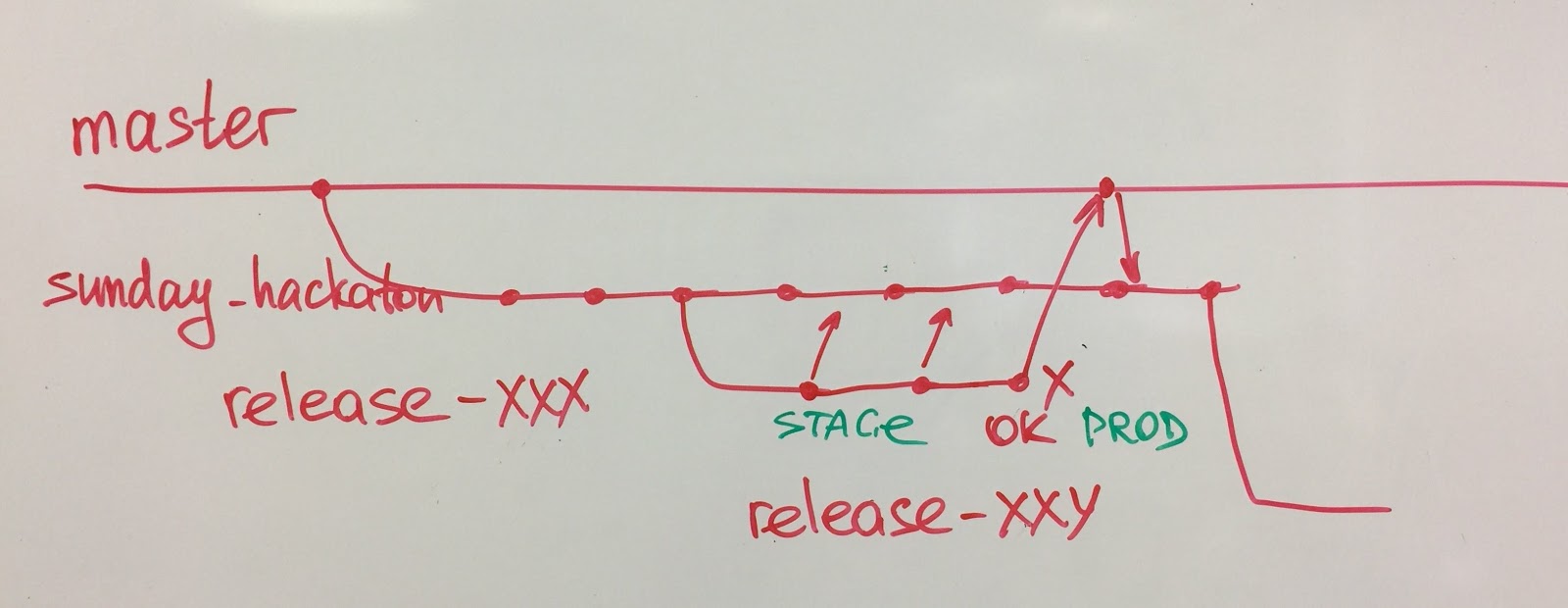
Another interesting case is with our QA department. We used not to have a QA team, instead we had manual testers. Realizing the need for test automation, we formed a QA team, but from the first day this team knew that it would be disbanded one day. After 6 months the team automated our key business scenarios and, with the help of developers, wrote a convenient Domain Specific Language (DSL) for writing tests. The team broke up, and quality engineers joined the feature teams. Now the teams themselves develop and maintain autotests.
Today we have a single backlog that 9 feature teams are working on. Feature teams are stable, cross-functional, cross-component teams. Most of our teams are feature teams.
6. Focus on engineering practices. All our teams use pair programming. I consider pair programming one of the most simple but powerful practices that helps to implement other engineering practices. If you do not know which engineering practice to start, I recommend pair programming.
The main result that the crisis gave us is a shake-up. We woke up and began to act. The crisis has helped us see the maximum of our opportunities. We saw that we can work many times more efficiently and quickly achieve our goals. But this requires changing the regular way of working. We have ceased to be afraid to make bold experiments. As a result of these experiments, over the past year we have significantly improved the quality and stability of Dodo IS. If during the spring holidays in 2018 our pizzerias could not work because of Dodo IS, then in 2019, with growth from 300 to 450 pizzerias, Dodo IS worked flawlessly. We quietly experienced the peak of sales in the New Year, during the second Marketing Campaign and the spring holidays. For the first time in a long time, we are confident in the quality of the system and sleep well at night. This is the result of the constant use of engineering practices and focus on technical excellence.
Engineering practices are not needed by themselves if they do not benefit your business. As a result of the focus on technical excellence, we improve code quality and develop business features with predictable speed. Releases have become a regular event for us. We release the monolith every 2 days, and smaller services every few minutes. This means that we can quickly deliver business value to our users and collect feedback faster. Thanks to the flexibility of the feature teams, we get high speed of development.
Today we use a wide range of engineering practices:
They help 9 teams to work on a common code and a single product that includes dozens of components — a mobile and desktop site, a mobile app on iOS and Android, and a giant back office with cash register, tracking, restaurant display, personal account, analytics and forecasting.
It may seem that we have already made good progress in engineering practices, but we are only at the beginning, we still have room to grow. For example, we try, but so far unsystematically, mob programming. We study the BDD test writing approach. We still have room to grow in CI, we understand that integrating even once a day is not often enough. And when we grow up to 30 teams, it will be necessary to integrate more often. We are still in progress of the transition from TDD to ATDD. We have to create a sustainable and scalable architectural decision-making process.
The most important thing is that we headed for strengthening Technical Excellence.
Due to the fact that all 9 teams are working on a common backlog and on one product, teams have a strong desire to cooperate with each other. They learned to make strong decisions themselves.
Some teams showed a desire to use all 12 XP practices and asked me for help as XP Coach and Scrum Master.
I wish I would not let the crisis happen. As a developer, I felt personal responsibility for accumulating too large technical dept and not raising a red flag earlier:
Technical dept lead us to crisis. But from the crisis both developers and business people learned how important the focus on technical excellence and engineering practices are. We used the crisis as a trigger for massive organizational and processes change.
I would like to say a big thank you to all the people helped me with my journey from crisis to LeSS transformation. I constantly feel your support.
Many thanks to our CEO, Fedor Ovchinnikov for trust. You are the true leader of the company with genuine agile culture.
Many thanks to Dmitry Pavlov, our Product Owner, my old friend and co-trainer.
Thank you Alex Andronov and Andrey Morevsky for supporting me in my role.
Great thanks to Dasha Bayanova, our first full-time Scrum Master, who believed me and always helps and supports me with all our initiative. Your help is hard to overestimate.
Special huge thank you to Johanna Rothman who helped me with writing this report in any condition: being on vacation, recovering after illness. Johanna, it was a great pleasure working with you. Your help, advice, attention to details and diligence are very much appreciated.
Dodo Pizza IT team grew from 2 developers serving one country to 60 people serving 12 countries over the course of 7 years. As a Scrum Master and XP Coach I helped teams establish processes and adopt engineering practices, but this adoption was too slow. It was challenging for me to make the teams keep high code quality when multiple teams work on a single product. We fell into the trap of preference for business features over technical excellence and accumulated too much architectural technical debt. When marketing launched a massive advertising campaign in 2018, we couldn’t stand the load and fell down. It was a shame. But during the crisis, we realized that we are able to work many times more efficiently. The crisis has pushed us towards revolutionary changes in processes and the rapid introduction of best-known engineering practices.
Background
You may think that Dodo Pizza is a regular pizzeria network. But actually Dodo Pizza is an IT company who happens to sell pizza. Our business is based on Dodo IS — cloud-based platform, which manages all the business processes, starting from taking the order, then cooking and finishing to inventory management, people management and making decisions. In only 7 years we have grown from 2 developers serving a single pizzeria to 70+ developers serving 470+ pizzerias in 12 countries.
When I joined the company two years ago, we had 6 teams and about 30 developers. The Dodo IS codebase had about 1M lines of code. It had a monolithic architecture and very little unit tests coverage. We had no API/UI tests by then. The code quality of the system was disappointing. We knew it and dreamed about bright future when split the monolith into dozen of services and rewrite the most hideous parts of the system. We even draw the “to be architecture” diagram, but honestly did almost nothing towards the future state. My primary goal was to teach the developers engineering practices and build a development process, making 6 teams work on a single product.
As the team grew we suffered from lack of clear process and engineering practices more. Our releases became bigger and longer because more and more developers contributed to the system, but we had no automated regression tests and therefore wasted more time on manual regress with every release. We suffered from many changes made by 6 teams in separate branches. When a teams merged their changes to a single branch before release, sometimes we used to lose up to 4 hours resolving merge conflicts.
Shit happens
In 2018 Marketing run our first federal advertising campaign on TV. It was a huge event for us. We spent 100M roubles ($1.5M) funding the campaign — quite a significant amount for us. IT team prepared to the campaign also. We automated and simplified our deployment — now with a single button in TeamCity we could deploy the monolith to 12 countries. We investigated performance tests and performed vulnerability analysis. We did our best but we encountered unexpected problems.
The advertising campaign was terrific. We went from 100 to 300 orders/minute. This was good news. Bad news were that Dodo IS couldn’t withstand such a load and died. We achieved our vertical scaling limits and couldn’t handle orders anymore. The system rebooted every 3 hours. Every minute of downtime cost us millions money as well as lost of respect from furious customers.
When I came to Dodo 2 years ago as Chief Agile Officer, I had a great desire to make of our then small team — about 12 people, a dream team. I immediately began to introduce engineering practices. Most of the teams adopted pair programming, unit testing and DDD pretty soon. But not everything was easy. I had to overcome the resistance of the developers, the Product Owner, and the support team.
As opposed to engineering practices, not everyone favored the idea of feature teams. Developers were used to thinking that a team focused on one component is writing better code. It was not clear how to combine the rapid development of business features with the long overdue massive refactoring of a complex system. A continuous stream of bugs also required constant attention. The support team favoured having their own team focused on bugs fixing only. Many teams were used to working in separate branches and were afraid to integrate frequently. We released no more than once a week, and each release took quite a long time, required tremendous amount of manual regress and UI tests support. I tried to fix it, but my process changes were too slow and fragmented.
The story of fall and rise
Initial state: Monolithic Architecture
In pursuit of the speed of developing business features, we have not always thought through technical solutions well. A lack of experience affected us as well. In the beginning, the company could not afford hiring the best developers. We worked with enthusiasts who agreed to help with the creation of Dodo IS, believed in the founder of the company — Fedor and worked almost for food (pizza, of course). The developers who joined the team later followed the established architecture, which became outdated. So we had a monolithic application with a single database, containing all the data from all the components in one place. Tracker, checkout, site, API for landing pages — all components of the system worked with a single database, which become a bottleneck. Our monolithic architecture created monolithic problems. A single blog post led to a restaurant checkout outage.
True story
To illustrate how fragile monolithic architecture is, I’ll give just one example. Once all our restaurants on Russia stopped accepting orders because of a blog post. How can this happen?
One day our CEO — Fedor published a post on his blog. This post quickly gained popularity. There is a counter on the Fedor's blog website showing a number of pizzerias in our chain and the total revenue of all the pizzerias. Every time someone read Fedor’s blog, the web server sent a request to the master database to calculate revenue. These requests overloaded the database and it stopped serving requests from the restaurant’s checkout. So a popular blog post disrupted the work of the entire restaurant chain. We quick-fixed the problem, but it was a clear sign (among many others) that our architecture is not able to meet business needs and have to be redesigned. But we ignored these signs. We implemented quick and easy solutions (like adding read-only replica of the master database), but we had no any technical redesign roadmap.
Monolithic architecture is good to start because it is simple. But it can not withstand the high load being a single point of failure.
Early Fails in 2018
February 14 is a Valentine's Day. Everyone loves this holiday. For lovers to congratulate each other, on February 14 we make a special pizza — pepperoni in the shape of a heart. I will remember the February 14, 2018 forever, because on this day, when all the pizzerias were working at full load, Dodo IS started to fall. In each pizzeria we have 4-5 tablets for tracking which order a pizza maker makes dough for, put ingredients, bake or send to delivery. The number of pizzerias reached 300+, each tablet updated its state multiple times per minute. All these requests created such a massive load on the database that the SQL server ceased to withstand and the database started to fail. Dodo IS laid down at the most inappropriate moment — during the peak of sales. There was a busy holiday season ahead: February 23 (Army and Navy Day), March 8 (International Women's Day), May 1 (Day of International Solidarity of Workers) and May 9 (Victory Day in World War II). During these holidays, we were expecting an even greater orders growth.
The day when you will die. Knowing our growth plans and the limit of the load that we can withstand, we figured out how long we can stay alive, that is, when today's peak load becomes regular. The estimated date of Armageddon expected in about six months — in August or September. How does it feel to live, knowing the date of your death?
Stop feature development for a year. Together with CEO Fedor, we had to make an arduous decision. Perhaps one of the most difficult decisions in the history of the company. We stopped the development of business features. We thought we would stop for 3 months, but soon we realized that the volume of technical debt was so great that 3 months would not be enough and we have to continue working on technical issues and postpone the business backlog. In fact, with 6 teams we have made only one business feature during the next year. The rest of the time, the teams were engaged in the repayment of technical debt. This debt cost us a lot — over $1.5 mln.
Some improvements after a year
Over the year, we had these notable accomplishments:
- We have automated and accelerated our deployment pipeline. Previously, the deployment was semi-manual. We deployed to 10 countries in about 2 hours.
- Began to split a monolith. The most loaded part of the system — the tracker — was split out to a separate service, with its own database. Now the tracker communicates with the rest of the system through a queue of events.
- We began to separate the Delivery Cashier — the second component that creates a high load.
- Rewrote user and device authentication system.
Our architect managed the technical backlog. We used the architectural changes to drive the backlog. Each team had the freedom to do what was right to create a useful architecture. For the year with the 6th teams we made for business only one valuable feature. The rest of the time, the teams worked on technical debt. It would seem that we can be proud of ourselves. But ahead of us there was a huge disappointment.
Fail during Federal Marketing Campaign. The second crisis of trust.
Technical debt is easy to accumulate, but very difficult to repay. It is unlikely that you will be able to understand in advance how much it will cost you.
Despite the fact that we spent a whole year fighting technical debt, we were not ready for massive Marketing Campaign and screwed up in front of our business. You gain trust in drops, you lose it in buckets. And we had to gain it again.
We missed the moment when it was necessary to slow down the speed of developing business features and tackle technical debt. It was too late when we noticed. We lay down under load again. The system crashed and rebooted every 3 hours. Our business lost tens of millions of rubles.
But thanks to the crisis, we saw that in extreme conditions we can work many times more efficiently. We released 20 times a day. Everyone worked as one team, focusing on a single goal. During two weeks of crisis, we’ve done what we were afraid of starting before because we believed it would take months of work. Asynchronous order, performance tests, clear logs are only a small part of what we did. We were eager to continue to work as effectively, but without overtime and stress.
Lessons learned
After the retrospective, we completely restructured our processes. We took the LeSS framework and supplemented it with engineering practices. Over the next few months, we made a breakthrough in the engineering practices adoption. Based on the LeSS framework, we have implemented and continue to use:
- single backlog;
- fully cross-functional and cross-component feature teams;
- pair programming;
- Trying Mob Programming.
- Genuine Continuous Integration, meaning multiple code integrations from 9 teams in a single branch;
- simplified configuration management with trunk-based development;
- frequent releases: Continuous Deployment for microservices, multiple releases per day for monolith;
- no separate QA team, QA experts are part of development teams.
6 practices we’ve chosen after the crisis
1. The power of focus. Before the crisis, each team worked on its own backlog and specialized in its domain. In the backlog, there were finely decomposed tasks, the team selected several tasks for a sprint. But during the crisis, we worked quite differently. The teams did not have specific tasks, they had a big challenging goal instead. For example, a mobile app and API must handle 300 orders per minute, no matter what. It is up to the team how to achieve the goal. The teams themselves formulate hypotheses, quickly check them in Production and throw away. And this is exactly what we wanted to continue doing. Teams do not want to be dumb coders, they want to solve problems.
The power of focus manifested itself in solving complex problems. For example, during the crisis, we created a set of performance tests in spite we had no expertise. We also made the logic of receiving an order asynchronous. We have long thought about it and talked, and it seemed to us that this is a very difficult and long task. But it turned out that the team is quite capable of doing it in 2 weeks, if it they are not distracted and completely focused on the problem.
2. Regular hackathons. We liked to work in the mode when all the teams are aimed at one goal and we decided to sometimes arrange such a “hackathons”. It cannot be said that we carry them out regularly, but there was a couple of times. For example, there was a 500-errors hackathon when all the teams cleaned the logs and removed the causes of 500 errors on the site and in the API. The goal was to keep the logs clean. When the logs are clean, the new errors are clearly visible, you can easily configure the threshold values for the alerts. It is similar to unit tests — they can not be a little red.
Another example of a hackathon is bugs. We used to have a huge bugs backlog, some of the bugs had been in the backlog for years. It seemed that they would never end. And every day there were new ones. You have to somehow combine work on bugs and on regular backlog items.
We introduced the policy #zerobugspolicy in 4 steps.
- Initial bug cleaning based on date. If the bug is in the backlog for more than 3 months, simply delete it. Most likely it was there for ages.
- Now, sort the remaining defects based on how they affect customers. We carefully sorted out the remaining bugs. We kept only defect that makes life difficult for a large group of users. If this is just something that causes inconvenience, but you can cope with it — ruthlessly delete. So we reduced the number of bugs to 25, which is acceptable.
- Hackathon. All the teams swarm and fix all the bugs. We did this in a few sprints. Each sprint every team took several bugs and fixed it. After 2-3 sprints we had a clear bugs backlog. Now you could enter #zerobugspolicy.
- #zerobugspolicy. Each new bug now has only two ways. Ether it falls into backlog, or not. If it gets into backlog, we fix it first. Any bug in backlog has higher priority than any other backlog item. But in order to get into backlog, the bug must be serious. Either it causes irreparable harm, or it affects a large number of users.
3. Temporary project teams to stable feature teams. There was a funny story with project teams. During the crisis, we formed tiger teams of people who were best skilled for the task. After the crisis was over the teams decided to continue this practice and disband the teams. Despite the fact that I didn’t like this idea at all, I let them try. In just 2 weeks (one sprint), at the next retrospective, the teams abandoned this practice, (this decision made me extremely happy). They tried and understood why it is much more comfortable to work in a stable feature team. Even if the team lacks some skills, they can gradually learn. But the team spirit, support and mutual assistance is formed for a long time, it takes months. Short-term project teams are constantly in forming and storming phase. You can endure it for a couple of weeks, but you cannot work like this all the time. It’s good that the teams tried and understood the benefits of stable feature teams.
4. Get rid of manual regress. Before the crisis, we released once a week, and during the crisis — dozens of times a day. We loved our ability to release often. We appreciated how convenient it was to make a small change, quickly deploy it and immediately get feedback from production. Therefore, we changed our approach to releases, and this affected the approach to programming and design. Now we release continuously, every 1-2 days. Everything in the dev branch goes into production. Even if some features are not ready, this is no reason not to release the code. If we don’t want to show some not-ready yet feature to users, we hide it with feature toggles. This approach helped us to develop in small steps.
We set a goal to get rid of manual regressions. It took us 1.5 years to reach it. But having a long-term ambitious goal makes you think about steps leading to the goal.
We did it in 3 steps.
- Automate critical path. In June 2017, we formed the QA team. The task of the team was to automate the regression of the most critical functional of Dodo IS — order taking and production. For the next 6 months, a new QA team of 4 people covered the entire critical path. Feature teams developers actively helped them. Together we wrote a beautiful and understandable Domain-Specific Language (DSL), which was readable even by customers. In parallel with the End-to-End tests, the developers covered the code with unit tests. Some new components were redesigned with TDD. After that we disbanded the QA team. The former QA team members joined feature teams to share expertise how to support and maintain autotests.
- Shadow mode. Having autotests, during 5 releases we did manual regressions in shadow mode. The teams relied only on automated tests suite, but when the team decided “We are ready to release”, we run manual regress to check if our autotests miss any bugs. We tracked how many bugs were caught manually and not caught by autotests. After 5 releases we reviewed the data and decided we can trust our autotests. No major bugs were missed.
- Remove manual regressions. When we had enough tests that we started to trust them, we abandoned manual testing completely. The more we run our tests, the more we trust them. But this happened only 1.5 years after we began to automate the regression testing.
5. Performance Test is part of the regression test. During the crisis we created a set of performance tests. It was a completely new area for us. Nevertheless, in just 2 weeks, we managed to create some performance tests using Visual Studio tools. These tests helped us not only catch performance degradation. We used them to add synthetic load to Production server to identify the performance limits. For instance, if the organic production load is 100 orders/min and we add 50 more orders/min with help of our performance tests, we can see if the Production servers can handle the increased load. As soon as we notice exceptions or increased latency, we stop the test. Making these experiments, we figured out the max load our Production servers can handle, and what will be the hotspot.
Next year we outstaffed the performance tests to experienced PerformanceLab team. They sat together with our developers and infrastructure people, and helped us create a robust set of performance tests. Now we run these tests weekly and provide fast feedback to development teams if performance is impacted.
Some of the engineering practices were iteratively refined. For example, frequent releases. We started with weekly release cycles, supported with slow and fragile manual testing. We developed features for one week and tested for another week. But it was hard to maintain changes made by multiple during a week. Then we tried isolated team releases, when only changes made by single team were released. But this process failed because every team had to wait in the queue for several weeks. Then the teams learned benefits of frequent integration and we started practicing joined releases of multiple teams changes. The developers started to experiment with Feature Toggle and push to Production unfinished features. Eventually we came to Continuous Integration and multiple releases per day for monolith and Continuous Deployment for microservices.
Another interesting case is with our QA department. We used not to have a QA team, instead we had manual testers. Realizing the need for test automation, we formed a QA team, but from the first day this team knew that it would be disbanded one day. After 6 months the team automated our key business scenarios and, with the help of developers, wrote a convenient Domain Specific Language (DSL) for writing tests. The team broke up, and quality engineers joined the feature teams. Now the teams themselves develop and maintain autotests.
Today we have a single backlog that 9 feature teams are working on. Feature teams are stable, cross-functional, cross-component teams. Most of our teams are feature teams.
6. Focus on engineering practices. All our teams use pair programming. I consider pair programming one of the most simple but powerful practices that helps to implement other engineering practices. If you do not know which engineering practice to start, I recommend pair programming.
Results
The main result that the crisis gave us is a shake-up. We woke up and began to act. The crisis has helped us see the maximum of our opportunities. We saw that we can work many times more efficiently and quickly achieve our goals. But this requires changing the regular way of working. We have ceased to be afraid to make bold experiments. As a result of these experiments, over the past year we have significantly improved the quality and stability of Dodo IS. If during the spring holidays in 2018 our pizzerias could not work because of Dodo IS, then in 2019, with growth from 300 to 450 pizzerias, Dodo IS worked flawlessly. We quietly experienced the peak of sales in the New Year, during the second Marketing Campaign and the spring holidays. For the first time in a long time, we are confident in the quality of the system and sleep well at night. This is the result of the constant use of engineering practices and focus on technical excellence.
Results for business
Engineering practices are not needed by themselves if they do not benefit your business. As a result of the focus on technical excellence, we improve code quality and develop business features with predictable speed. Releases have become a regular event for us. We release the monolith every 2 days, and smaller services every few minutes. This means that we can quickly deliver business value to our users and collect feedback faster. Thanks to the flexibility of the feature teams, we get high speed of development.
Today we have 480 pizzerias online, 400 of which are in Russia. During the May holidays this year, there were problems with order processing at our pizzerias again. But this time the bottleneck was customer service at pizzerias. Dodo IS was running like clockwork, despite the growing number of pizzerias and orders.
Results for the teams
Today we use a wide range of engineering practices:
- Fully cross-functional and cross-component feature teams.
- Pair Programming / Mob Programming.
- Genuine Continuous Integration, meaning multiple code integrations from 9 teams in a single branch.
- Simplified configuration management with trunk-based development.
- Common goal for multiple teams.
- Subject Matter Expert is in the team.
- No separate QA team, QA experts are part of development teams.
- Eventual manual regress replacement with autotests.
- Zero bugs policy.
- Technical debt backlog.
- Stop the Line as a driver for deployment pipeline acceleration.
They help 9 teams to work on a common code and a single product that includes dozens of components — a mobile and desktop site, a mobile app on iOS and Android, and a giant back office with cash register, tracking, restaurant display, personal account, analytics and forecasting.
What can be better
It may seem that we have already made good progress in engineering practices, but we are only at the beginning, we still have room to grow. For example, we try, but so far unsystematically, mob programming. We study the BDD test writing approach. We still have room to grow in CI, we understand that integrating even once a day is not often enough. And when we grow up to 30 teams, it will be necessary to integrate more often. We are still in progress of the transition from TDD to ATDD. We have to create a sustainable and scalable architectural decision-making process.
The most important thing is that we headed for strengthening Technical Excellence.
Due to the fact that all 9 teams are working on a common backlog and on one product, teams have a strong desire to cooperate with each other. They learned to make strong decisions themselves.
For example, the following practices have been proposed and implemented by the teams themselves.
- Stop the Line as a driver for deployment pipeline acceleration (see my experience report “Stop the Line to Streamline your Deployment Pipeline”).
- Replace UI tests with API tests.
- Single-click automated deployment.
- Host to Kubernetes.
- Development team deploys to Production.
Some teams showed a desire to use all 12 XP practices and asked me for help as XP Coach and Scrum Master.
What we learned
I wish I would not let the crisis happen. As a developer, I felt personal responsibility for accumulating too large technical dept and not raising a red flag earlier:
- Engineering practices protect business from crisis.
- Do not accumulate technical debt. It may be too late and cost too high.
- Evolutionary changes take several times longer than revolutionary ones.
- Crisis is not always a bad thing. Use crisis to revolutionize processes.
- However, a long evolutionary preparation is required in advance.
- Do not blindly implement all the practices that you like. Some practices are waiting in the wings, and when he comes, the teams will use them without resistance. Wait for the right moment.
- Refine and adapt practices to your context.
- Over time, the teams themselves begin to make strong decisions and implement them. Give them a safe environment to try, fail and learn on mistakes.
Technical dept lead us to crisis. But from the crisis both developers and business people learned how important the focus on technical excellence and engineering practices are. We used the crisis as a trigger for massive organizational and processes change.
Acknowledgements
I would like to say a big thank you to all the people helped me with my journey from crisis to LeSS transformation. I constantly feel your support.
Many thanks to our CEO, Fedor Ovchinnikov for trust. You are the true leader of the company with genuine agile culture.
Many thanks to Dmitry Pavlov, our Product Owner, my old friend and co-trainer.
Thank you Alex Andronov and Andrey Morevsky for supporting me in my role.
Great thanks to Dasha Bayanova, our first full-time Scrum Master, who believed me and always helps and supports me with all our initiative. Your help is hard to overestimate.
Special huge thank you to Johanna Rothman who helped me with writing this report in any condition: being on vacation, recovering after illness. Johanna, it was a great pleasure working with you. Your help, advice, attention to details and diligence are very much appreciated.