

Использование искусственного интеллекта в творчестве сегодня стало встречаться все чаще и в развлекательных целях, и в коммерческих и уже перестало удивлять публику. С одной стороны — это инструменты смены стиля изображения типа Prizma. С другой — нейронная сеть, продукт работы которой был продан в виде картины на аукционе Christie?s за 432,5 тысячи долларов. Нельзя не вспомнить нашего отечественного специалиста по генерации музыки с помощью машинного обучения Ивана Ямщикова, несколько лет назад представившего проект «Нейронная оборона» (подробнее можно прочитать здесь, а это интервью Ивана на Хабре). Другим хорошим примером использования нейронных сетей для генерации музыки может быть статья «Мечтают ли андроиды об электропанке? Как я учил нейронную сеть писать музыку» эксперта Artezio.
Помимо понимания теории машинного обучения, использование искусственного интеллекта для решения творческих задач предполагает также наличие экспертизы в доменной области искусства. Это делает проект на стыке двух областей особенно многогранным и интересным, но и уязвимым для критики с двух сторон, т. к. проект может попасть под перекрестный огонь замечаний и от искусствоведов, и от data scientist-ов.
Расширяя свой кругозор в рамках темы использования искусственного интеллекта в музыке, я встретил статью «Создаем музыку: когда простые решения превосходят по эффективности глубокое обучение», перевод которой хотел бы представить сообществу Хабра. Одним из достоинств этой статьи для меня стало то, что автор не использует нейронные сети как черный ящик, а подходит к задаче генерации музыки, исходя из знания теории музыки, на основе мелодии и гармонии. В представленной статье не используются ни рекуррентные нейронные сети (RNN, LSTM), ни генеративные состязательные сети (GAN), — все эти методы дают поразительные результаты (например, в статье «Мечтают ли андроиды об электропанке? Как я учил нейронную сеть писать музыку»), и мы активно их используем в решении наших задач в компании CleverData. Автор сделал упор на модели на основе марковских цепей, дающих возможность работать с вероятностями перехода от текущего состояния музыкального произведения в последующее. В используемых автором методах есть дополнительное достоинство: автору не пришлось жертвовать интерпретируемостью результата в угоду использования модного и популярного алгоритма.
Другой особенностью статьи, привлекшей мое внимание, стал интересный метод сравнения музыкальных произведений на основе матриц самоподобия. Если структуру песни можно представить в виде матрицы самоподобия, то появляется еще одна количественная мера сравнения песен.

* * *
Краткое содержание: как я столкнулся с проблемой, используя глубокое обучение для создания музыки, и как я её решил, придумав собственное решение.
План
Задача: как я столкнулся с проблемами при использовании техник глубокого обучения для создания поп-музыки.
Решение: как я создал собственную машину для создания музыки, которая могла бы конкурировать с глубоким обучением, но на основе более простых решений.
Оценка: как я создал оценочную метрику, которая могла бы математически доказать, что моя музыка «больше похожа на поп», чем та, что создана при помощи глубокого обучения.
Обобщение: как я нашёл способ применять своё решение к проблемам, не связанным с созданием музыки.
Вишенка на торте
Я создал простую вероятностную модель, генерирующую поп-музыку. Также, используя объективную метрику, я могу с уверенностью сказать, что музыка, созданная моей моделью, больше похожа на поп-музыку, чем та, что была создана с применением техник глубокого обучения. Как я это сделал? Частично, я достиг этого, сфокусировавшись на том, что для меня – суть поп-музыки: на статистической взаимосвязи между гармонией и мелодией.

Задача
Прежде чем углубиться в их отношения, позвольте мне сначала очертить проблему. Проект начался с моего желания попробовать создать музыку при помощи глубокого обучения – ИИ, как называют это непрофессионалы. Довольно быстро я пришёл к LSTM (долгая краткосрочная память, long short-term memory), одной из версий рекуррентной нейронной сети (RNN), очень популярной при генерировании текстов и создании музыки.
Но чем больше я вчитывался в предмет, тем больше я стал сомневаться в логике применения RNN и их вариаций для создания поп-музыки. Эта логика, казалось, основывалась на нескольких предположениях о внутренней структуре (поп) музыки, с которой я не мог полностью согласиться.
Одно конкретное предположение — это независимая связь между гармонией и мелодией (определение этих двух см. выше).
Например, рассмотрим публикацию Университета Торонто от 2017 года «Song from Pi: A Musically Plausible Network for Pop Music Generation» (Хан Чу и др.). В этой статье авторы явно «предполагают… аккорды не зависимы от мелодии» (курсив мой). Основываясь на этом предположении, авторы построили сложную многослойную RNN-модель. Для мелодии выделен отдельный слой, где создаются ноты (слой key, слой press), не зависимый от слоя аккордов (Chord Layer). Помимо независимости, эта конкретная модель предполагает, что гармония опирается на мелодию. Другими словами, гармония зависит от мелодии при генерации нот.

Такой способ моделирования кажется мне очень странным, поскольку это совсем не похоже на то, как люди подходят к написанию поп-музыки. Будучи пианистом классической школы, я никогда не рассматривал сочинение мелодии без того, чтобы сначала обозначить гармонию. Гармония определяет и ограняет мелодию. Axis of Awesome в своём когда-то вирусном видео давно уже продемонстрировали правдивость этой идеи.
Это видео демонстрирует главное свойство западной поп-музыки: эта гармония, эти четыре аккорда сильно влияют на то, какой в итоге будет мелодия. Говоря языком Data Science, условная вероятность регулирует и определяет статистическую связь между гармонией и мелодией. Так происходит, потому что ноты мелодии, естественно, зависят от нот гармонии. Таким образом, можно утверждать, что ноты гармонии по своей сути указывают, какие мелодические ноты могут быть выбраны в конкретной песне.
Решение
Мне нравится находить оригинальные решения для сложных проблем. Поэтому я решил построить свою собственную модель, которая могла бы по-своему отражать богатую структуру музыкальных данных. Я начал с того, что сосредоточился на предопределенной вероятностной силе, регулирующей отношения между различными видами музыкальных нот. Например, выше я уже упоминал «вертикальные» отношения между гармонией и мелодией.
(Обработка) данных
В качестве данных я использовал 20 разнообразных западных поп-песен в midi формате (полный список песен можно найти здесь).
Используя библиотеку music21 python, я проанализировал midi-файлы при помощи цепи Маркова. Это позволило мне выделить статистические взаимоотношения между разными типами нот в моих входящих данных. В частности, я рассчитал вероятности перехода моих музыкальных нот. По сути, это означает, что наблюдая переход нот от одной к другой, мы можем вычислить вероятность того, что этот переход произойдет. (Более подробное объяснение ниже)

Сначала я извлек «вертикальные» вероятности перехода между нотами гармонии и нотами мелодии. Я также рассчитал все «горизонтальные» вероятности перехода между нотами мелодии в соответствии с набором данных. Я провел эту процедуру и для нот гармонии. Таблица ниже демонстрирует пример трех разных переходных матриц между различными типами нот в музыкальных данных.
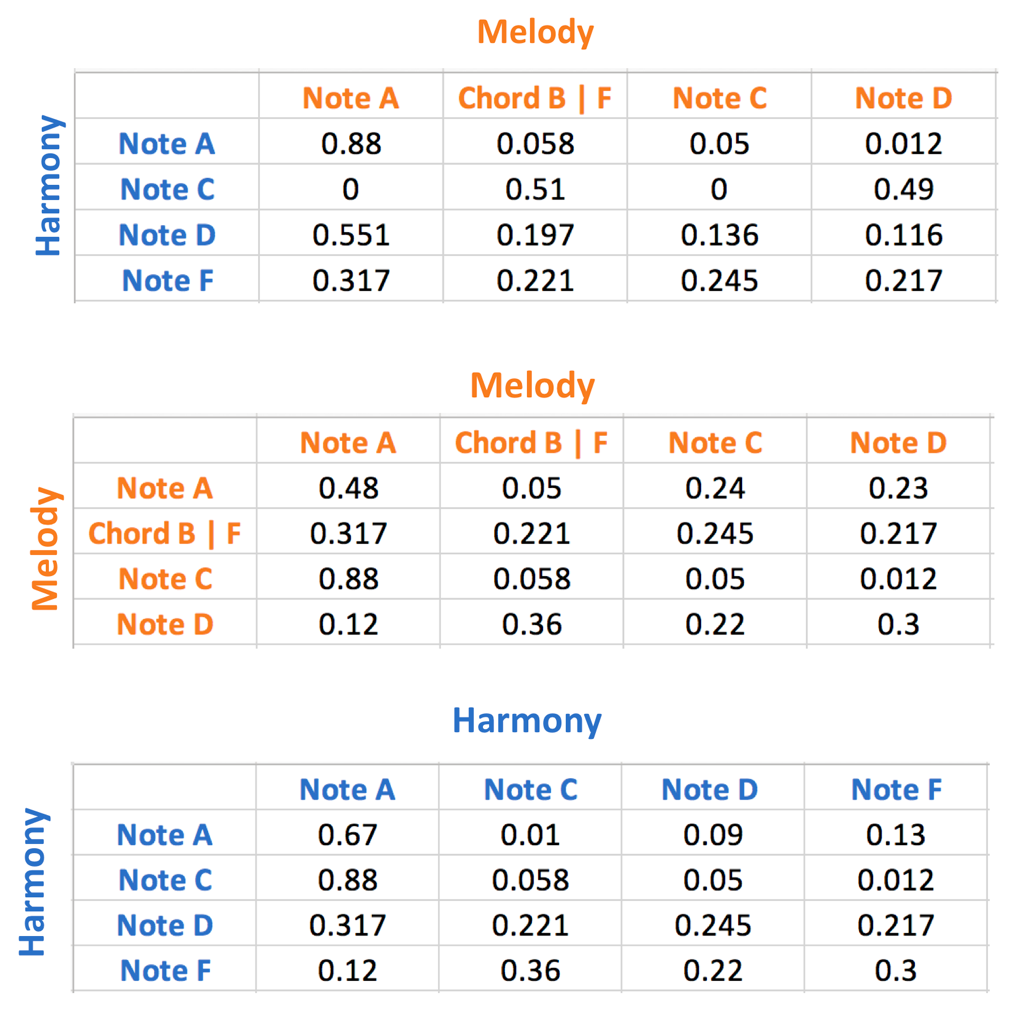
Модель
Опираясь на эти три модели вероятностей, моя модель будет действовать следующим образом:
- Выбирает произвольную доступную ноту гармонии;
- Выбирает ноту мелодии, основываясь на ноте гармонии, используя первую вероятностную матрицу;
- Выбирает ноту мелодии, опираясь на предыдущую ноту мелодии, согласно второй матрице вероятности;
- Повторяет шаг 3, пока не достигнет определённого завершения;
- Выбирает новую ноту гармонии, опираясь на предыдущую ноту гармонии, используя третью матрицу вероятности;
- Повторяет шаги 1-4, пока не достигнет завершения.


Конкретный пример применения алгоритма:
- Программа выбрала гармоническую ноту ( F ).
- У этой ноты есть 4 варианта нот мелодии. Используя первую матрицу переходов, система выбирает ноту ( C ), учитывая высокую вероятность её использования (24,5%).
- Эта нота ( C ) переходит ко второй матрице перехода, останавливая выбор на ноте мелодии (A), основываясь на её частотности (88%).
- Шаг 3 будет повторяться, пока процесс не достигнет предустановленной точки завершения;
- Нота гармонии (F), обратившись к третьей вероятностной матрице, выберёт следующую гармоническую ноту. Это будет либо ( F ), либо ( C ), учитывая их схожесть.
- Шаги 1-4 будут повторяться, пока процесс не завершится.
Здесь можно послушать пример поп-музыки, созданной подобным образом:
Оценка
Здесь начинается сложная часть – как оценить разные модели. В конце концов моя статья предполагает, что простые вероятности могут быть полезнее нейронных сетей. Но как нам оценить отличие моей модели от модели, построенной нейронной сетью? Как мы можем объективно заявить, что моя музыка больше похожа на поп, чем музыка, написанная ИИ?
Чтобы ответить на этот вопрос, мы должны прежде всего определить, что же такое поп-музыка. Первое определение я уже озвучил: статистическое соотношение между гармонией и мелодией. Но есть и другой определяющий фактор поп-музыки – это чётко выделенные начало, середина, конец песни (интро, куплет, бридж, припев, завершение и т.д.), повторяющиеся в течение песни.
Например, строчка «Let it go, let it go, can’t hold it back anymore…» скорее встретится в серединной части, чем в конце или начале. И трижды повторится в течение песни.
Держа это в уме, мы можем прибегнуть к так называемой матрице самоподобия. Говоря проще, матрица самоподобия математически выражает начало, середину, конец песни. Ниже представлена матрица для песни Falling Slowly из фильма «Однажды».
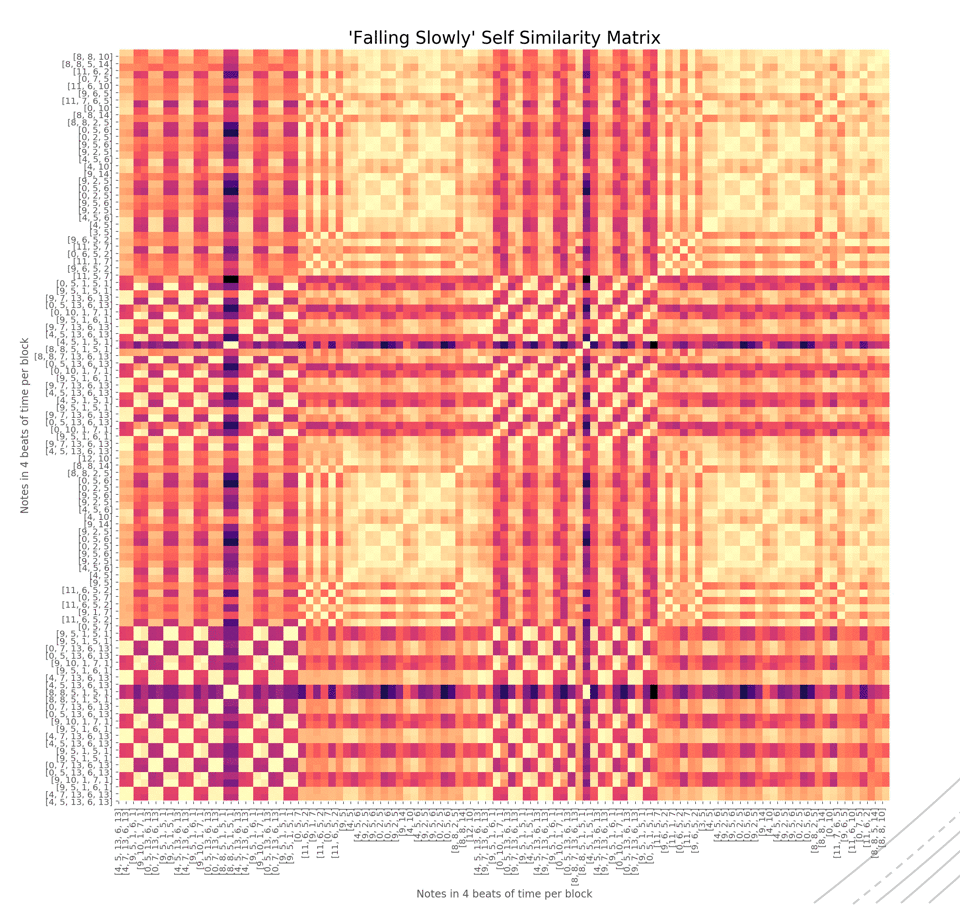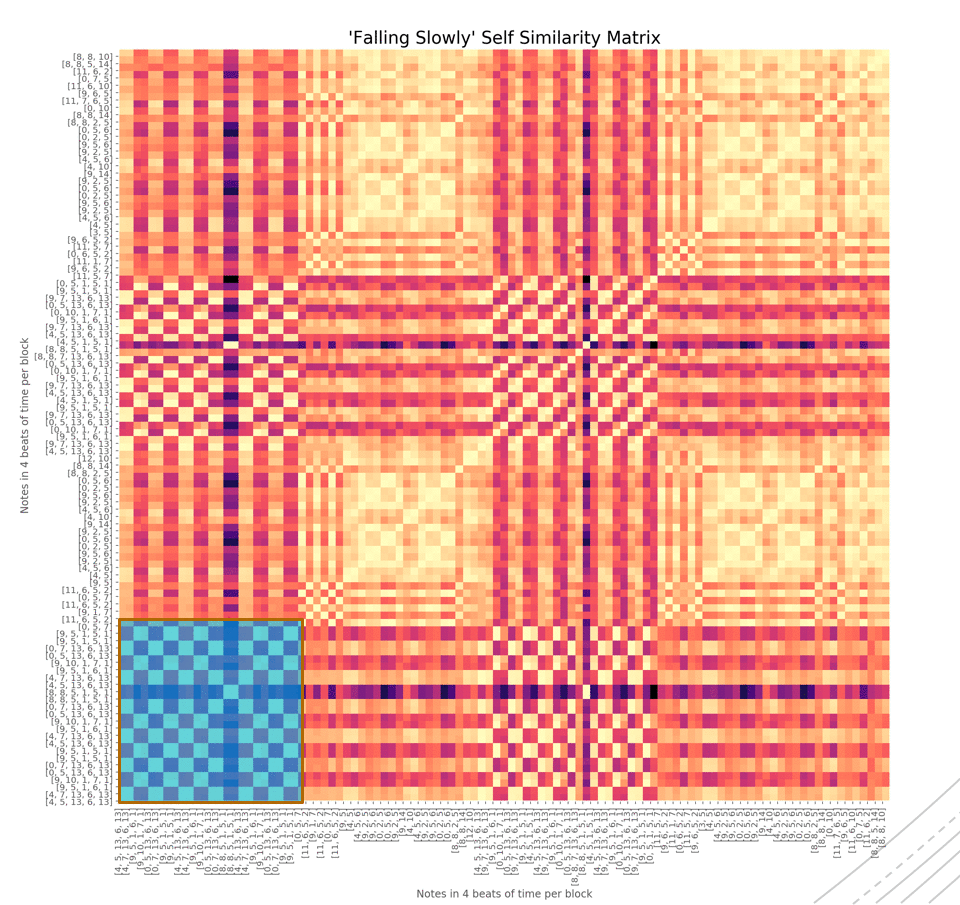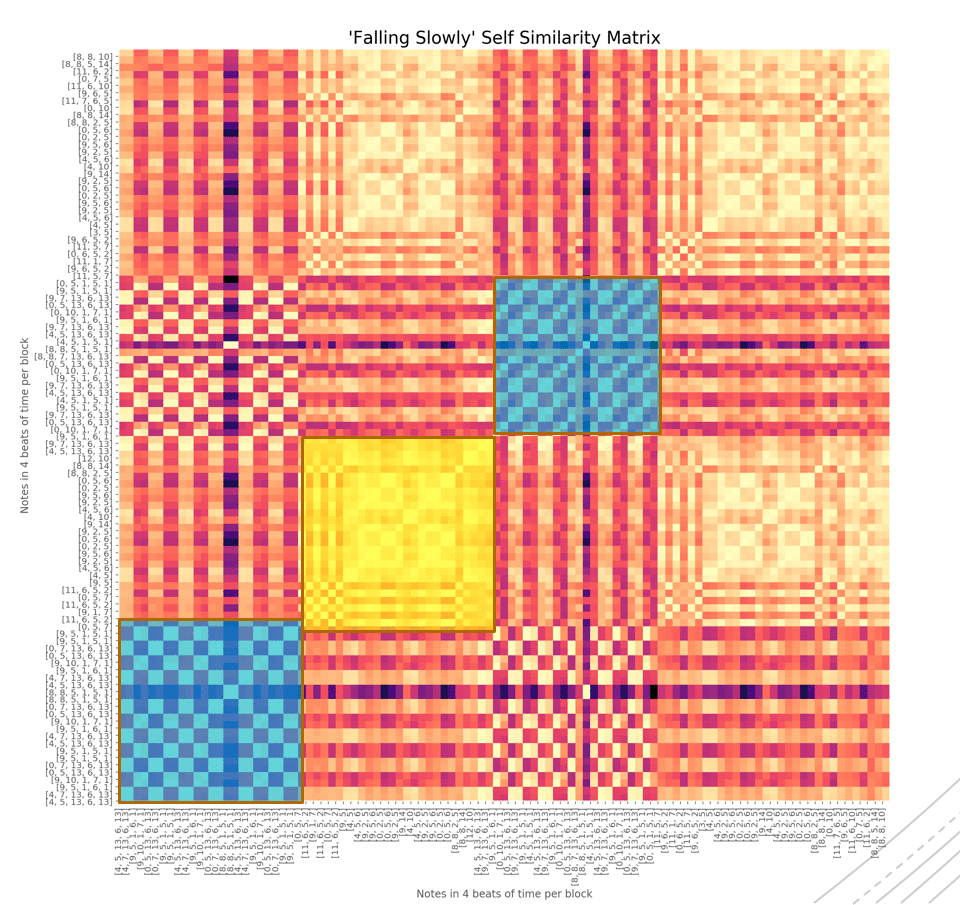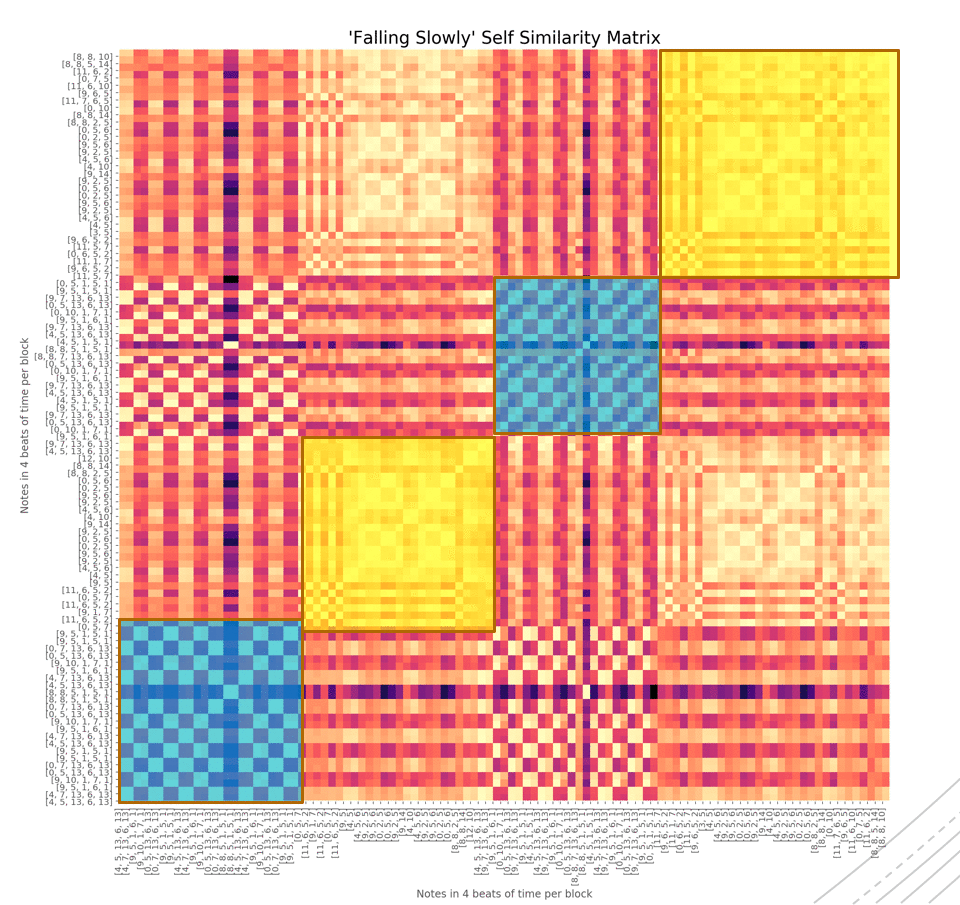
Каждый маленький сегмент представляет ноту. Каждый большой блок на 45 градусов представляет какую-то часть песни.
Первый темный кластер представляет начало песни, следующий жёлтый – следующий сегмент песни. Первый и третий кластеры похожи по цвету, так как они схожи друг с другом, равно как и второй и четвёртый.
Я проверил таким образом двадцать поп-песен, после чего создал машинную копию (насколько это возможно) их структур.
Результаты
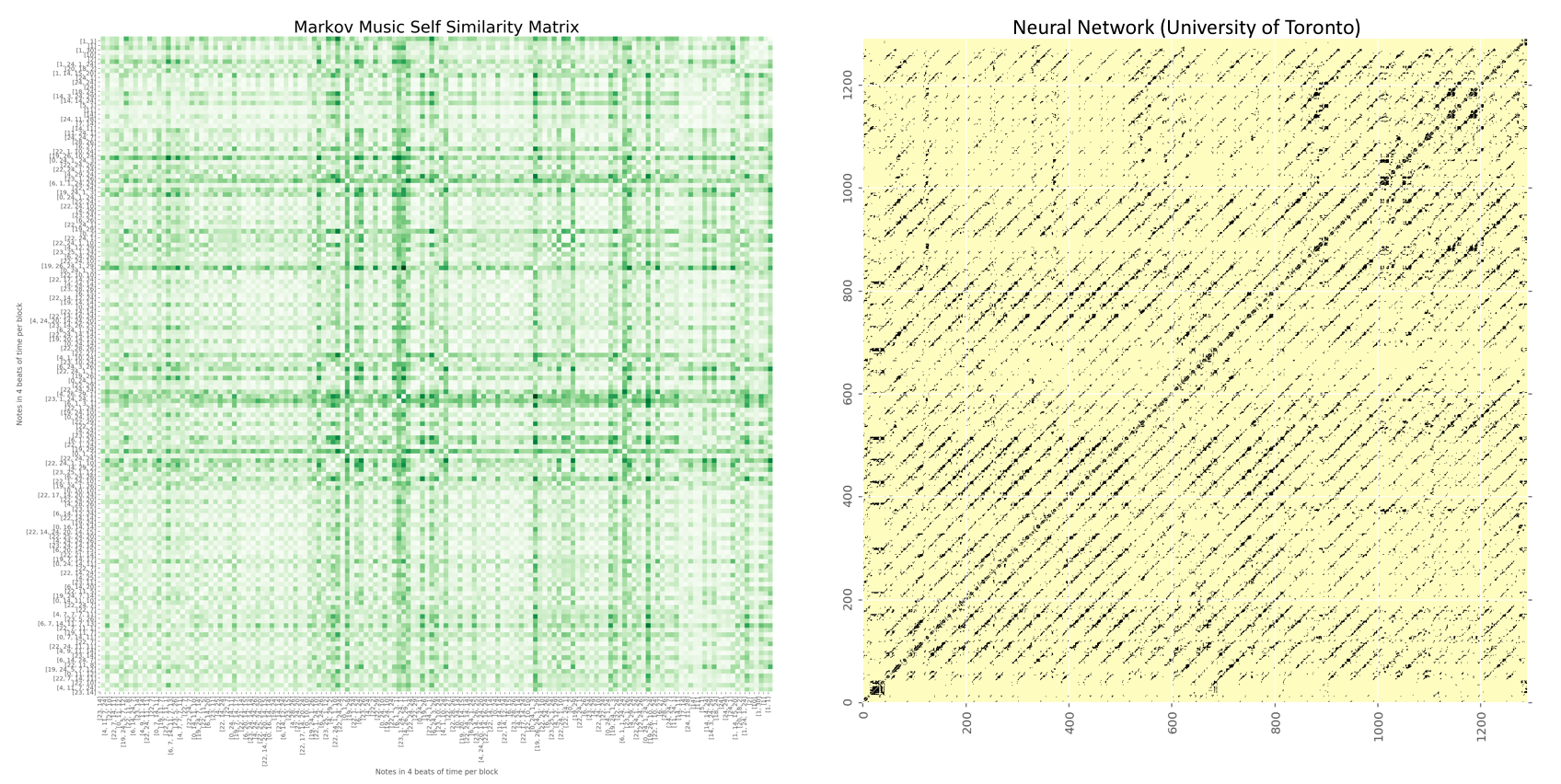
Результаты говорят сами за себя. До использования матрицы самоподобия моя программа выдала звуки без повторяющейся внутренней структуры. Однако после копирования структуры исходных данных моя музыка стала выглядеть следующим образом:

Сравните с матрицей самоподобия музыки, созданной нейронной сетью в Университете Торонто:
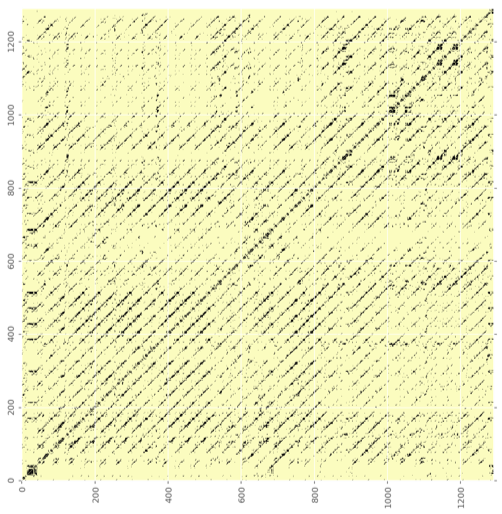
Именно таким образом можно сравнивать и оценивать разные модели – основываясь на их матрицах самоподобия!
Обобщение
Последней частью задачи, которую я перед собой ставил, было обобщение. Под этим словом я имею в виду: как мы можем сделать универсальной мою модель, опирающуюся на входящие данные, чтобы её можно было применить к другим ситуациям, не связанным с генерацией поп-музыки? Другими словами, есть ли что-то ещё, структурно похожее на мой генератор поп-музыки?
После долгих размышлений я понял, что есть ещё одно изобретение человечества, схожее по структуре – тексты поп-песен!
Например, вот отрывок из I’ll Be Эдварда МакКейна:
I’ll be your cryin’ shoulder
I’ll be love suicide
I’ll be better when I’m older
I’ll be the greatest fan of your life
Разберём по косточкам текст, используя те же самые приёмы машинного обучения. Мы можем засчитать ‘I’ll be’ как первое исходное слово в языковой модели. Оно будет использовано для генерации ‘your’, из которого выходит ‘crying’, откуда уже появляется ‘shoulder’.

Далее возникает очень важный вопрос: зависит ли первое слово следующего предложения от последнего слова предыдущего? Другими словами, если ли зависимость между последним словом одного предложения и первым следующего?
Я считаю, что ответ – нет. Предложение заканчивается на ‘shoulder’, следующее начинается с повторения первого — ‘I’ll be’. Это связано с тем, что первые слова каждого предложения намеренно повторяются, что означает, что между первыми словами каждого предложения существует аналогичная условная связь. Эти первые слова становятся триггерной точкой для последовательности следующих слов.

Мне кажется, это потрясающее открытие. Похоже, что и поп-музыка, и тексты поп-песен имеют внутреннюю структуру, зависящую от содержания. Правда, здорово?
Смотреть проект на github
* * *
Безусловно, предлагаемый в статье подход нельзя считать исчерпывающим. Отдельно стоит заметить, что методы работы с текстами сейчас претерпевают подъем и активно развиваются, поэтому взгляд автора на тексты песен не удивит специалистов NLP (Natural Language Processing). Тем не менее, оригинальная статья автора выглядит как полезный промежуточный шаг для генерации качественной музыки методами машинного обучения.
За последнее время широкой публике был предложен ряд приложений на основе нейронных сетей, генерирующих музыку. Например, есть возможность генерировать техно музыку на сайте: eternal-flow.ru. Автор решения предлагает и мобильное приложение для генерации музыки. Известно и другое приложение для генерации музыки на мобильных устройствах: mubert.com. Любопытное решение посвящено более динамичному жанру death metal. Его создатели DadaBots стримят на youtube непрерывный поток музыки, генерируемой нейронной сетью. При том DadaBots на этом не останавливаются и открывают публике искусственные музыкальные произведения в стиле панк и прогрессив рок. И конечно нельзя обойти вниманием результаты от OpenAI, предлагающей всем желающим эксперименты с музыкой в широких жанровых рамках от Моцарта до The Beatles. На сайте openai.com можно послушать, как выглядело бы развитие темы Гарри Поттера в стиле Фрэнка Синатры или Петра Ильича Чайковского.
Успехи современных нейронных сетей в генерации музыки дают надежду на то, что в скором времени искусственный интеллект сможет сразиться на равных с человеком в еще одной области, помимо Го и Dota2. Возможно, нам повезет дожить до того момента, когда на Евровидении сможет выступить претендент от нейронных сетей и побороться с кожаными участниками за победу.
Вакансии ГК ЛАНИТ можно посмотреть здесь.
Комментарии (19)

LeshaVH
25.06.2019 19:58+6подгонка теории под результат — это псевдонаучный метод в чистом виде)))

dimaviolinist
25.06.2019 22:22+2Я ответственно заявляю. Теорией там и не пахнет. Там первобытные представления о музыке, основанные на простейшей попсе.
Музыкальные примеры — полная ахинея, ни формы, ничего вообще. Средне сымитирована фактура.art_pro Автор
26.06.2019 09:24+1Цитата из Элементарной Теории Музыки:
Слушая или исполняя музыкальное произведение, мы наблюдаем, что образующие его звуки находятся между собой в определенном соотношении. Это выражается прежде всего в том, что в процессе развития музыки, в частности мелодии, некоторые звуки, выделяясь из общей массы, приобретают характер опорных звуков.
Один из устойчивых звуков обычно выделяется больше, чем другие. Он является как бы главной опорой. Такой устойчивый звук называется тоникой.
В противоположность устойчивым звукам, другие звуки, участвующие в образовании мелодии, называются неустойчивыми. Неустойчивым звукам свойственно состояние тяготения к устойчивым звукам.
Система взаимоотношений между устойчивыми и неустойчивыми звуками называется ладом. В основе отдельной мелодии и музыкального произведения в целом всегда лежит определенный лад. Лад является организующим началом высотного соотношения звуков в музыке. Лад придает музыке, совместно с другими выразительными средствами, определенный характер, соответствующий ее содержанию.
Музыканту странно было бы отрицать описанную выше связь между звуками в произведении, и именно на исследование этой связи с точки зрения вероятностей перехода от одного устойчивого звука к другому, работает авторский подход. То, что мелодия в примере стала состоять из устойчивых звуков, сложно отрицать, а на большее пример и не рассчитан.
Если говорить на языке аналогий, то перед тем, как учить ребенка сочинять поэмы, надо научить его языку и лексике. Среднестатистический взрослый человек способен сочинять поэмы лучше среднестатистического ребенка из ясельной группы. В такой же степени не удивительна способность музыканта (использующего порядка 100 миллиардов нейронов) лучше играть, чем видевший 20 мелодий алгоритм.dimaviolinist
26.06.2019 21:48Как бы так это объяснить. С другими аналогиями. То, что вы привели, является «Цитата из Элементарной Теории Музыки». Но там есть чуть дальше, поверьте. Элементарная теория музыки позволяет вам сделать пять аккордов (ну как же без DD:). Дальше идёт ещё чуть-чуть учебников и курсов. 17 лет учатся инструменталисты и 17+3 дирижёры. Композиторы обычно учатся чуть больше. Это только начало.
Есть ещё «средства музыкальной выразительности».
Среднестатистический взрослый человек способен сочинять поэмы лучше среднестатистического ребенка из ясельной группы.
Это неверная лемма. Никто без обучения не способен сочинять поэмы.
с точки зрения вероятностей перехода от одного устойчивого звука к другому, работает авторский подход
Абсолютная чушь. Можно, конечно, вспомнить, когда была запрещена даже септима в доминантаккорде в церковной музыке, но сейчас (да и с начала 20го века) это не так.
На самом деле всё очень сильно сложнее, чем простоописанную выше связь между звуками в произведении
.
Там этих связей тысячи.art_pro Автор
27.06.2019 11:06Очень рад, что мы сходимся в том, что понимаем сложность задачи. Надеюсь следствие этого наблюдения достаточно очевидно: сложные задачи надо разделять на простые и решать их, постепенно двигаясь к основному результату.
Сейчас мы на том этапе, когда подопечный начинает произносить слова и мы радуемся, что слова у него получаются. Можно говорить, что выучить слова не значит — выучить язык, однако это постепенное приближение и промежуточные успехи. Здесь же уместно следующее наблюдение: учиться лучше на простых словах, постепенно внося усложнения. Сразу учить замечательные и прекрасные многобуквенные слова, пока не освоены односложные — забегание вперед. Конечно, все намного сложнее, но путь в тысячу ли начинается с одного шага. Перед нами еще один шаг, пусть отметка в тысячу ли еще за горизонтом.dimaviolinist
27.06.2019 14:35Чтобы понимать сложность задачи, для начала, неплохо было бы иметь знания в предметной области. Например, гармония, анализ форм, ИИИ (история исполнительского искусства, да это нужно, не спрашивайте почему, поверьте на слово) и ещё с десяток.
А если учить подопечного примитивной попсе, то он и будет выдавать примитивную попсу (причём, даже без формы, а это то, что делает музыку музыкой, которую могут воспринимать люди). Даже если подсунуть подопечному фактуру Шопена (это, кстати, про openai.com/blog/musenet), на выходе будет примитивная попса без формы с фактурой Шопена.
Постановка задачи изначально неверная.Нет ТЗ результат хз.
подопечный начинает произносить слова и мы радуемся, что слова у него получаются
Даже не близко. Неразборчивое мычание максимум.
или позволить сетям самостоятельно открывать эти свойства на основе больших массивов данных
Я боюсь представить себе необходимую для этого вычислительную мощь. Разве что запретить порно и котиков и направить все освободившиеся 90% мировых вычислительных ресурсов на эту задачу. А потом окажется, что её сформулировали люди, которые разбираются в музыке на уровне примитивной попсы. Упппсс.
P.S. Попса бывает же и не примитивная, чего бы на квинов не натравить? Страшно за результат? :)
Длинный разбор статьиОдним из достоинств этой статьи для меня стало то, что автор не использует нейронные сети как черный ящик, а подходит к задаче генерации музыки, исходя из знания теории музыки, на основе мелодии и гармонии.
Нет, даже и близко. Гениальная догадка о том, что мелодия зависит от аккомпанемента и наоборот, как бы помягче выразиться… Для этого даже в ДМШ необязательно заходить.
Я создал простую вероятностную модель, генерирующую поп-музыку.
Нет, не создал. Не генерирует.
Также, используя объективную метрику, я могу с уверенностью сказать, что музыка, созданная моей моделью, больше похожа на поп-музыку, чем та, что была создана с применением техник глубокого обучения.
И не больше и не меньше. Это даже отдалённо не похоже на музыку вообще. Музыка != набор нот (хотя многие современные нам композиторы… да блин, каюсь, иногда даже эти нейросети лучше пишут).
Таким образом, можно утверждать, что ноты гармонии по своей сути указывают, какие мелодические ноты могут быть выбраны в конкретной песне.
Или наоборот. Называется гармонизация. Да, представьте, у этого всего есть даже термины.
В качестве данных я использовал 20 разнообразных западных поп-песен в midi формате (полный список песен можно найти здесь).
Во-первых, ссылка не открывается (Mozilla 67, IE 10). Во-вторых, 20 песен это вообще ничтожно мало и непонятно, какая исследовательская задача ставилась. Просто поприкалываться? Получилось. Как подбирались песни? По настроению, тональнастям, количеству отклонений (модуляций там нету, только секвенционные изменения тональностей), размеру (ой, там же только 4/4), ещё сотни (не преувеличиваю) параметров.
В частности, я рассчитал вероятности перехода моих музыкальных нот. По сути, это означает, что наблюдая переход нот от одной к другой, мы можем вычислить вероятность того, что этот переход произойдет.
Это даже для примитивной попсы достаточно сложная задача. Переходы нот подчиняются некоторым законам, с которыми желательно хотя бы поверхностно ознакомиться ДО постановки ТЗ.
Резюме.
Переходы нот, строение и изменение гармонии (гармонический план) — это не вероятности, а строгие законы. Я пытался это алгоритмизировать (поверьте, за решение задачек по гармонии теоретики (не педагоги) дерут большие деньги, нет я не пользовался, решал сам, хотел помочь некоторым несчастным духовикам :).
Тут желателен состоявшийся математик, который пройдёт полный курс теории музыки. Наоборот, к сожалению, не выйдет. Энштейн мог играть на скрипке, а Ойстрах не был мастеромнадпо шахматам.
art_pro Автор
26.06.2019 09:51+1Полностью согласен, подгонка теории под результат ненаучна. В статье упрощенная модель на основе марковских цепей строится на фрагменте элементарной теории музыки, а после обучения на 20 песнях алгоритм дает пусть наивные, но результаты. Вопрос не в том, хорошие результаты получаются, или наивные. Вопрос скорее в том, стоит ли акцентировано закладывать эти фрагменты теории музыки в нейронные сети для улучшения их результатов, или позволить сетям самостоятельно открывать эти свойства на основе больших массивов данных. Ответ на этот вопрос нам даст время: рано или поздно алгоритмы научатся сочинять музыку, которая будет нравиться людям.

dim2r
26.06.2019 09:55а где на сайте Ланита вакансии по данной специальности?
art_pro Автор
26.06.2019 13:37вакансию видят только роботы, не способные пройти тест на капчу :)
dim2r
26.06.2019 19:31я имел в виду эту ссылку, где я не нашел ничего по поводу машинного обучения

art_pro Автор
27.06.2019 11:14Спасибо за интерес! Даже если и нет вакансий в открытом доступе сейчас, мы будем рады познакомиться с Вами и возможно мы сможем сотрудничать в будущем. Можете писать на почту a.prosvetov@cleverdata.ru, буду рад.
IrinaB
27.06.2019 10:35Добрый день, в данный момент в группе компаний ЛАНИТ нет открытых вакансий по данной специальности. На нашем карьерном портале job.lanit.ru Вы можете ознакомиться с другими вакансиями компании. Также Вы можете направить нам свое резюме и мы с радостью рассмотрим его при появлении вакансий в этой области. Адрес для резюме job@lanit.ru.
balamutang
26.06.2019 13:32Все это круто, но только копаете не туда.
Во-первых на дворе уже 21 век, а не конец 19го (с акустическими инструментами, издающими простые тональные звуки), обычная музыкальная теория это только малая часть современной поп-музыки. Большое значение имеют сэмплы и шумы, которые являясь некими отсылками к слышанному ранее (пережитому жизненному опыту) — создают нужное настроение в песне (например телефонный разговор, шумы аэропорта, райзы и дропы или небольшой сэмпл старой песни). Никаких нот не хватит чтобы это описать.
Во-вторых поп-музыка это отнюдь не какое-то там высокое искусство, это просто аккомпанемент к брачным танцам высокоразвитых приматов и ее задача — быть максимально простой, запоминающейся, создающей нужное настроение, (в т.ч. и с помощью текста про любовь-морковь). Золотое правило хорошего хука — не более 3-4 нот, иначе он не будет прилипчивый.
Также важной частью этого аккомпанемента к брачным танцам является видеоряд. Показанная в нужный момент в этом видеоряде упругая задница может дать большее преимущество этой композиции в хит-парадах, нежели какие-либо там композиторские ходы и исполнительское мастерство :)
Может нейросети/алгоритмы и смогут что-то сгенерировать в мудреных жанрах вроде блек/дет/прог металла, классики и тп, но до секса в поп-музыке им еще очень далеко.art_pro Автор
26.06.2019 15:03Машинное обучение наступает широким фронтом. Отчасти роль в формировании пикантных изображений на себя взял Deepfake и судя по широкому резонансу, успехи нейронок продолжат нас радовать. Кроме того, в этой задаче есть место и для обучения с подкреплением: чем больше слушают синтезированный трек, тем больше может быть за него награда синтетическому автору. Таким образом, только вопрос времени, когда появится подходящий рецепт смеси слоев и лоссов для нейронки, чтобы нужный эффект был достигнут.
balamutang
26.06.2019 19:06Даже лучшие из пикантных картинок дипфейка выглядят крипово, об остальном вообще молчу, тем более что пикантные картинки — это не сексуальность и харизма фронтмена, а только картинки.
Понятно что мощности систем растут и однажды получится закидать шапками любую задачу, но это все какой-то экстенсивный путь.
Что касается видео мне кажется правильнее будет построить 3д модель (а не генерить картинку нейросетью) и научить стильным модным жестам и движениям, тем более что и 3д модели сейчас есть с успехом в инстаграме и с жестами все хорошо получается.
kwayne
26.06.2019 14:56«Машины» лишены творческой составляющей
Пока что сгенеренные композиции слишком примитивны — невозможно слушать.
В музыку должен закладываться смысл, философия...сейчас это похоже на набор бессмысленных слов, которые просто рифмуются… и то не очень.
Уверен, в недалёком будущем результаты будут намного лучше.
Daddy_Cool
Послушал результат — очень похоже на мои наигрыши на ф-но, хотя нет — у меня пожалуй лучше получается. Если что, я не умею играть на фортепиано.