

Введение
I/O реактор (однопоточный цикл событий) — это паттерн для написания высоконагруженного ПО, используемый во многих популярных решениях:
В данной статье мы рассмотрим подноготную I/O реактора и принцип его работы, напишем реализацию на меньше, чем 200 строк кода и заставим простой HTTP сервер обрабатывать свыше 40 миллионов запросов/мин.
Предисловие
- Статья написана с целью помочь разобраться в функционировании I/O реактора, а значит и осознать риски при его использовании.
- Для усвоения статьи требуется знание основ языка Си и небольшой опыт разработки сетевых приложений.
- Весь код написан на языке Си строго по (осторожно: длинный PDF) стандарту C11 для Linux и доступен на GitHub.
Зачем это нужно?
С ростом популярности Интернета веб-серверам стало нужно обрабатывать большое количество соединений одновременно, в связи с чем было опробовано два подхода: блокирующее I/O на большом числе потоков ОС и неблокирующее I/O в комбинации с системой оповещения о событиях, ещё называемой "системным селектором" (epoll/kqueue/IOCP/etc).
Первый подход подразумевал создание нового потока ОС для каждого входящего соединения. Его недостатком является плохая масштабируемость: операционной системе придётся осуществлять множество переходов контекста и системных вызовов. Они являются дорогими операциями и могут привести к недостатку свободной ОЗУ при внушительном числе соединений.
Модифицированная версия выделяет фиксированное число потоков (thread pool), тем самым не позволяя системе аварийно прекратить исполнение, но вместе с тем привносит новую проблему: если в данный момент времени пул потоков блокируют продолжительные операции чтения, то другие сокеты, которые уже в состоянии принять данные, не смогут этого сделать.
Второй подход использует систему оповещения о событиях (системный селектор), которую предоставляет ОС. В данной статье рассмотрен наиболее часто встречающийся вид системного селектора, основанный на оповещениях (событиях, уведомлениях) о готовности к I/O операциям, нежели на оповещениях об их завершении. Упрощённый пример его использования можно представить следующей блок-схемой:

Разница между данными подходами заключается в следующем:
- Блокирующие I/O операции приостанавливают пользовательский поток до тех пор, пока ОС должным образом не дефрагментирует поступающие IP пакеты в поток байт (TCP, получение данных) или не освободится достаточно места во внутренних буферах записи для последующей отправки через NIC (отправка данных).
- Системный селектор через некоторое время уведомляет программу о том, что ОС уже дефрагментировала IP пакеты (TCP, получение данных) или достаточно места во внутренних буферах записи уже доступно (отправка данных).
Подводя итог, резервирование потока ОС для каждого I/O — пустая трата вычислительной мощи, ведь на самом деле, потоки не заняты полезной работой (отсюда берёт свои корни термин "программное прерывание"). Системный селектор решает эту проблему, позволяя пользовательской программе расходовать ресурсы ЦПУ значительно экономнее.
Модель I/O реактора
I/O реактор выступает как прослойка между системным селектором и пользовательским кодом. Принцип его работы описан следующей блок-схемой:
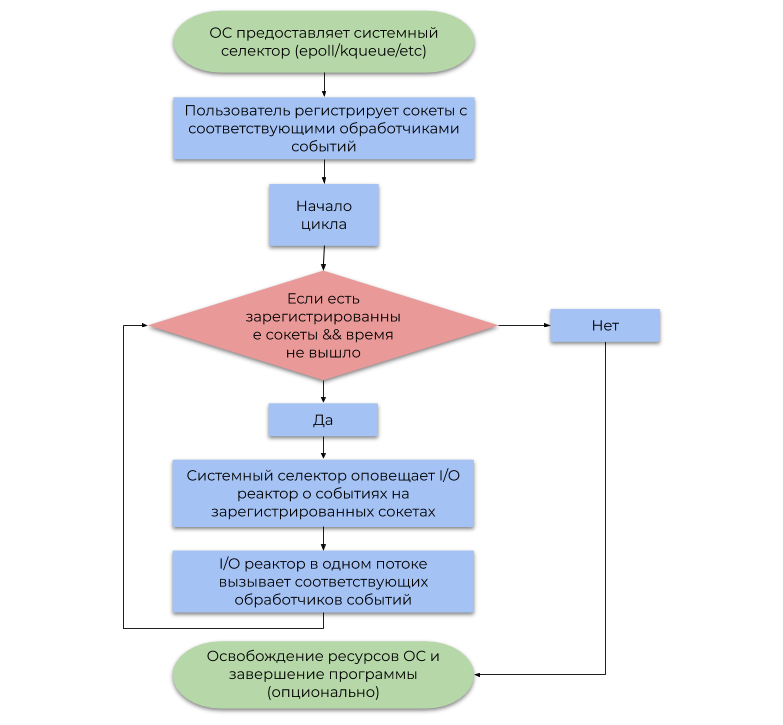
- Напомню, что событие — это уведомление о том, что определённый сокет в состоянии выполнить неблокирующую I/O операцию.
- Обработчик событий — это функция, вызываемая I/O реактором при получении события, которая далее совершает неблокирующую I/O операцию.
Важно отметить, что I/O реактор по определению однопоточен, но ничего не мешает использовать концепт в многопточной среде в отношении 1 поток: 1 реактор, тем самым утилизируя все ядра ЦПУ.
Реализация
Публичный интерфейс мы поместим в файл reactor.h, а реализацию — в reactor.c. reactor.h будет состоять из следующих объявлений:
typedef struct reactor Reactor;
/*
* Указатель на функцию, которая будет вызываться I/O реактором при поступлении
* события от системного селектора.
*/
typedef void (*Callback)(void *arg, int fd, uint32_t events);
/*
* Возвращает `NULL` в случае ошибки, не-`NULL` указатель на `Reactor` в
* противном случае.
*/
Reactor *reactor_new(void);
/*
* Освобождает системный селектор, все зарегистрированные сокеты в данный момент
* времени и сам I/O реактор.
*
* Следующие функции возвращают -1 в случае ошибки, 0 в случае успеха.
*/
int reactor_destroy(Reactor *reactor);
int reactor_register(const Reactor *reactor, int fd, uint32_t interest,
Callback callback, void *callback_arg);
int reactor_deregister(const Reactor *reactor, int fd);
int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest,
Callback callback, void *callback_arg);
/*
* Запускает цикл событий с тайм-аутом `timeout`.
*
* Эта функция передаст управление вызывающему коду если отведённое время вышло
* или/и при отсутствии зарегистрированных сокетов.
*/
int reactor_run(const Reactor *reactor, time_t timeout);Структура I/O реактора состоит из файлового дескриптора селектора epoll и хеш-таблицы GHashTable, которая каждый сокет сопоставляет с CallbackData (структура из обработчика события и аргумента пользователя для него).
struct reactor {
int epoll_fd;
GHashTable *table; // (int, CallbackData)
};
typedef struct {
Callback callback;
void *arg;
} CallbackData;Обратите внимание, что мы задействовали возможность обращения с неполным типом по указателю. В reactor.h мы объявляем структуру reactor, а в reactor.c её определяем, тем самым не позволяя пользователю явно изменять её поля. Это один из паттернов сокрытия данных, лаконично вписывающийся в семантику Си.
Функции reactor_register, reactor_deregister и reactor_reregister обновляют список интересующих сокетов и соответствующих обработчиков событий в системном селекторе и в хеш-таблице.
#define REACTOR_CTL(reactor, op, fd, interest) if (epoll_ctl(reactor->epoll_fd, op, fd, &(struct epoll_event){.events = interest, .data = {.fd = fd}}) == -1) { perror("epoll_ctl"); return -1; }
int reactor_register(const Reactor *reactor, int fd, uint32_t interest,
Callback callback, void *callback_arg) {
REACTOR_CTL(reactor, EPOLL_CTL_ADD, fd, interest)
g_hash_table_insert(reactor->table, int_in_heap(fd),
callback_data_new(callback, callback_arg));
return 0;
}
int reactor_deregister(const Reactor *reactor, int fd) {
REACTOR_CTL(reactor, EPOLL_CTL_DEL, fd, 0)
g_hash_table_remove(reactor->table, &fd);
return 0;
}
int reactor_reregister(const Reactor *reactor, int fd, uint32_t interest,
Callback callback, void *callback_arg) {
REACTOR_CTL(reactor, EPOLL_CTL_MOD, fd, interest)
g_hash_table_insert(reactor->table, int_in_heap(fd),
callback_data_new(callback, callback_arg));
return 0;
}После того, как I/O реактор перехватил событие с дескриптором fd, он вызывает соответствующего обработчика события, в который передаёт fd, битовую маску сгенерированных событий и пользовательский указатель на void.
int reactor_run(const Reactor *reactor, time_t timeout) {
int result;
struct epoll_event *events;
if ((events = calloc(MAX_EVENTS, sizeof(*events))) == NULL)
abort();
time_t start = time(NULL);
while (true) {
time_t passed = time(NULL) - start;
int nfds =
epoll_wait(reactor->epoll_fd, events, MAX_EVENTS, timeout - passed);
switch (nfds) {
// Ошибка
case -1:
perror("epoll_wait");
result = -1;
goto cleanup;
// Время вышло
case 0:
result = 0;
goto cleanup;
// Успешная операция
default:
// Вызвать обработчиков событий
for (int i = 0; i < nfds; i++) {
int fd = events[i].data.fd;
CallbackData *callback =
g_hash_table_lookup(reactor->table, &fd);
callback->callback(callback->arg, fd, events[i].events);
}
}
}
cleanup:
free(events);
return result;
}Подводя итог, цепочка вызовов функций в пользовательском коде будет принимать следующий вид:
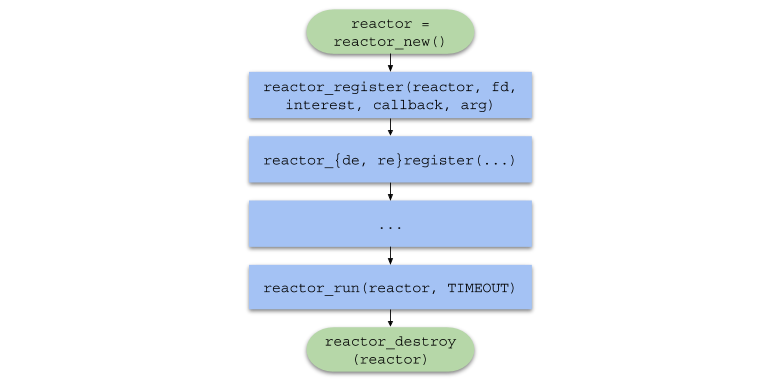
Однопоточный сервер
Для того чтобы протестировать I/O реактор на высокой нагрузке, мы напишем простой HTTP веб-сервер, на любой запрос отвечающий изображением.
HTTP — это протокол прикладного уровня, преимущественно использующийся для взаимодействия сервера с браузером.
HTTP можно с лёгкостью использовать поверх транспортного протокола TCP, отправляя и принимая сообщения формата, определённого спецификацией.
Формат запроса
<КОМАНДА> <URI> <ВЕРСИЯ HTTP>CRLF
<ЗАГОЛОВОК 1>CRLF
<ЗАГОЛОВОК 2>CRLF
<ЗАГОЛОВОК N>CRLF CRLF
<ДАННЫЕ>CRLF— это последовательность из двух символов:\rи\n, разделяющая первую строку запроса, заголовки и данные.<КОМАНДА>— одно изCONNECT,DELETE,GET,HEAD,OPTIONS,PATCH,POST,PUT,TRACE. Браузер нашему серверу будет отправлять командуGET, означающую "Отправь мне содержимое файла".<URI>— yнифицированный идентификатор ресурса. Например, если URI =/index.html, то клиент запрашивает главную страницу сайта.<ВЕРСИЯ HTTP>— версия протокола HTTP в форматеHTTP/X.Y. Наиболее часто используемая версия на сегодняшний день —HTTP/1.1.<ЗАГОЛОВОК N>— это пара ключ-значение в формате<КЛЮЧ>: <ЗНАЧЕНИЕ>, отправляемая серверу для дальнейшего анализа.<ДАННЫЕ>— данные, требуемые серверу для выполнения операции. Часто это просто JSON или любой другой формат.
Формат ответа
<ВЕРСИЯ HTTP> <КОД СТАТУСА> <ОПИСАНИЕ СТАТУСА>CRLF
<ЗАГОЛОВОК 1>CRLF
<ЗАГОЛОВОК 2>CRLF
<ЗАГОЛОВОК N>CRLF CRLF
<ДАННЫЕ><КОД СТАТУСА>— это число, представляющее собой результат операции. Наш сервер будет всегда возвращать статус 200 (успешная операция).<ОПИСАНИЕ СТАТУСА>— строковое представление кода статуса. Для кода статуса 200 — этоOK.<ЗАГОЛОВОК N>— заголовок того же формата, что и в запросе. Мы будем возвращать заголовкиContent-Length(размер файла) иContent-Type: text/html(тип возвращаемых данных).<ДАННЫЕ>— запрашиваемые пользователем данные. В нашем случае это путь к изображению в HTML.
Файл http_server.c (однопоточный сервер) включает файл common.h, который содержит следующие прототипы функций:
/*
* Обработчик событий, который вызовется после того, как сокет будет
* готов принять новое соединение.
*/
static void on_accept(void *arg, int fd, uint32_t events);
/*
* Обработчик событий, который вызовется после того, как сокет будет
* готов отправить HTTP ответ.
*/
static void on_send(void *arg, int fd, uint32_t events);
/*
* Обработчик событий, который вызовется после того, как сокет будет
* готов принять часть HTTP запроса.
*/
static void on_recv(void *arg, int fd, uint32_t events);
/*
* Переводит входящее соединение в неблокирующий режим.
*/
static void set_nonblocking(int fd);
/*
* Печатает переданные аргументы в stderr и выходит из процесса с
* кодом `EXIT_FAILURE`.
*/
static noreturn void fail(const char *format, ...);
/*
* Возвращает файловый дескриптор сокета, способного принимать новые
* TCP соединения.
*/
static int new_server(bool reuse_port);Также описан функциональный макрос SAFE_CALL() и определена функция fail(). Макрос сравнивает значение выражения с ошибкой, и если условие выпонилось, вызывает функцию fail():
#define SAFE_CALL(call, error) do { if ((call) == error) { fail("%s", #call); } } while (false)Функция fail() печатает переданные аргументы в терминал (как printf()) и завершает работу программы с кодом EXIT_FAILURE:
static noreturn void fail(const char *format, ...) {
va_list args;
va_start(args, format);
vfprintf(stderr, format, args);
va_end(args);
fprintf(stderr, ": %s\n", strerror(errno));
exit(EXIT_FAILURE);
}Функция new_server() возвращает файловый дескриптор "серверного" сокета, созданного системными вызовами socket(), bind() и listen() и способного принимать входящие соединения в неблокирующем режиме.
static int new_server(bool reuse_port) {
int fd;
SAFE_CALL((fd = socket(AF_INET, SOCK_STREAM | SOCK_NONBLOCK, IPPROTO_TCP)),
-1);
if (reuse_port) {
SAFE_CALL(
setsockopt(fd, SOL_SOCKET, SO_REUSEPORT, &(int){1}, sizeof(int)),
-1);
}
struct sockaddr_in addr = {.sin_family = AF_INET,
.sin_port = htons(SERVER_PORT),
.sin_addr = {.s_addr = inet_addr(SERVER_IPV4)},
.sin_zero = {0}};
SAFE_CALL(bind(fd, (struct sockaddr *)&addr, sizeof(addr)), -1);
SAFE_CALL(listen(fd, SERVER_BACKLOG), -1);
return fd;
}- Обратите внимание, что сокет изначально создаётся в неблокирующем режиме с помощью флага
SOCK_NONBLOCK, чтобы в функцииon_accept()(читать дальше) системный вызовaccept()не остановил исполнение потока. - Если
reuse_portравенtrue, то данная функция сконфигурирует сокет с опциейSO_REUSEPORTпосредствомsetsockopt(), чтобы использовать один и тот же порт в многопоточной среде (смотреть секцию "Многопоточный сервер").
Обработчик событий on_accept() вызывается после того, как ОС сгенерирует событие EPOLLIN, в данном случае означающее, что новое соединение может быть принято. on_accept() принимает новое соединение, переключает его в неблокирующий режим и регистрирует с обработчиком события on_recv() в I/O реакторе.
static void on_accept(void *arg, int fd, uint32_t events) {
int incoming_conn;
SAFE_CALL((incoming_conn = accept(fd, NULL, NULL)), -1);
set_nonblocking(incoming_conn);
SAFE_CALL(reactor_register(reactor, incoming_conn, EPOLLIN, on_recv,
request_buffer_new()),
-1);
}Обработчик событий on_recv() вызывается после того, как ОС сгенерирует событие EPOLLIN, в данном случае означающее, что соединение, зарегистрированное on_accept(), готово к принятию данных.
on_recv() считывает данные из соединения до тех пор, пока HTTP запрос полностью не будет получен, затем она регистрирует обработчик on_send() для отправки HTTP ответа. Если клиент оборвал соединение, то сокет дерегистрируется и закрывается посредством close().
static void on_recv(void *arg, int fd, uint32_t events) {
RequestBuffer *buffer = arg;
// Принимаем входные данные до тех пор, что recv возвратит 0 или ошибку
ssize_t nread;
while ((nread = recv(fd, buffer->data + buffer->size,
REQUEST_BUFFER_CAPACITY - buffer->size, 0)) > 0)
buffer->size += nread;
// Клиент оборвал соединение
if (nread == 0) {
SAFE_CALL(reactor_deregister(reactor, fd), -1);
SAFE_CALL(close(fd), -1);
request_buffer_destroy(buffer);
return;
}
// read вернул ошибку, отличную от ошибки, при которой вызов заблокирует
// поток
if (errno != EAGAIN && errno != EWOULDBLOCK) {
request_buffer_destroy(buffer);
fail("read");
}
// Получен полный HTTP запрос от клиента. Теперь регистрируем обработчика
// событий для отправки данных
if (request_buffer_is_complete(buffer)) {
request_buffer_clear(buffer);
SAFE_CALL(reactor_reregister(reactor, fd, EPOLLOUT, on_send, buffer),
-1);
}
}Обработчик событий on_send() вызывается после того, как ОС сгенерирует событие EPOLLOUT, означающее, что соединение, зарегистрированное on_recv(), готово к отправке данных. Эта функция отправляет HTTP ответ, содержащий HTML с изображением, клиенту, а затем меняет обработчик событий снова на on_recv().
static void on_send(void *arg, int fd, uint32_t events) {
const char *content = "<img "
"src=\"https://habrastorage.org/webt/oh/wl/23/"
"ohwl23va3b-dioerobq_mbx4xaw.jpeg\">";
char response[1024];
sprintf(response,
"HTTP/1.1 200 OK" CRLF "Content-Length: %zd" CRLF "Content-Type: "
"text/html" DOUBLE_CRLF "%s",
strlen(content), content);
SAFE_CALL(send(fd, response, strlen(response), 0), -1);
SAFE_CALL(reactor_reregister(reactor, fd, EPOLLIN, on_recv, arg), -1);
}И наконец, в файле http_server.c, в функции main() мы создаём I/O реактор посредством reactor_new(), создаём серверный сокет и регистрируем его, запускаем реактор с помощью reactor_run() ровно на одну минуту, а затем освобождаем ресурсы и выходим из программы.
#include "reactor.h"
static Reactor *reactor;
#include "common.h"
int main(void) {
SAFE_CALL((reactor = reactor_new()), NULL);
SAFE_CALL(
reactor_register(reactor, new_server(false), EPOLLIN, on_accept, NULL),
-1);
SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1);
SAFE_CALL(reactor_destroy(reactor), -1);
}Проверим, что всё работает как положено. Компилируем (chmod a+x compile.sh && ./compile.sh в корне проекта) и запускаем самописный сервер, открываем http://127.0.0.1:18470 в браузере и наблюдаем то, что и ожидали:
Замер производительности
$ screenfetch
MMMMMMMMMMMMMMMMMMMMMMMMMmds+. OS: Mint 19.1 tessa
MMm----::-://////////////oymNMd+` Kernel: x86_64 Linux 4.15.0-20-generic
MMd /++ -sNMd: Uptime: 2h 34m
MMNso/` dMM `.::-. .-::.` .hMN: Packages: 2217
ddddMMh dMM :hNMNMNhNMNMNh: `NMm Shell: bash 4.4.20
NMm dMM .NMN/-+MMM+-/NMN` dMM Resolution: 1920x1080
NMm dMM -MMm `MMM dMM. dMM DE: Cinnamon 4.0.10
NMm dMM -MMm `MMM dMM. dMM WM: Muffin
NMm dMM .mmd `mmm yMM. dMM WM Theme: Mint-Y-Dark (Mint-Y)
NMm dMM` ..` ... ydm. dMM GTK Theme: Mint-Y [GTK2/3]
hMM- +MMd/-------...-:sdds dMM Icon Theme: Mint-Y
-NMm- :hNMNNNmdddddddddy/` dMM Font: Noto Sans 9
-dMNs-``-::::-------.`` dMM CPU: Intel Core i7-6700 @ 8x 4GHz [52.0°C]
`/dMNmy+/:-------------:/yMMM GPU: NV136
./ydNMMMMMMMMMMMMMMMMMMMMM RAM: 2544MiB / 7926MiB
\.MMMMMMMMMMMMMMMMMMMИзмерим производительность однопоточного сервера. Откроем два терминала: в одном запустим ./http_server, в другом — wrk. Спустя минуту во втором терминале высветится следующая статистика:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive"
Running 1m test @ http://127.0.0.1:18470
8 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 493.52us 76.70us 17.31ms 89.57%
Req/Sec 24.37k 1.81k 29.34k 68.13%
11657769 requests in 1.00m, 1.60GB read
Requests/sec: 193974.70
Transfer/sec: 27.19MBНаш однопоточный сервер смог обработать свыше 11 миллионов запросов в минуту, исходящих из 100 соединений. Неплохой результат, но можно ли его улучшить?
Многопоточный сервер
Как было сказано выше, I/O реактор можно создавать в отдельных потоках, тем самым утилизируя все ядра ЦПУ. Применим данный подход на практике:
#include "reactor.h"
static Reactor *reactor;
#pragma omp threadprivate(reactor)
#include "common.h"
int main(void) {
#pragma omp parallel
{
SAFE_CALL((reactor = reactor_new()), NULL);
SAFE_CALL(reactor_register(reactor, new_server(true), EPOLLIN,
on_accept, NULL),
-1);
SAFE_CALL(reactor_run(reactor, SERVER_TIMEOUT_MILLIS), -1);
SAFE_CALL(reactor_destroy(reactor), -1);
}
}Теперь каждый поток владеет собственным реактором:
static Reactor *reactor;
#pragma omp threadprivate(reactor)Обратите внимание на то, что аргументом функции new_server() выступает true. Это значит, что мы присваиваем серверному сокету опцию SO_REUSEPORT, чтобы использовать его в многопоточной среде. Подробнее можете почитать тут.
Второй заход
Теперь измерим производительность многопоточного сервера:
$ wrk -c100 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive"
Running 1m test @ http://127.0.0.1:18470
8 threads and 100 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 1.14ms 2.53ms 40.73ms 89.98%
Req/Sec 79.98k 18.07k 154.64k 78.65%
38208400 requests in 1.00m, 5.23GB read
Requests/sec: 635876.41
Transfer/sec: 89.14MBКоличество обработанных запросов за 1 минуту возросло в ~3.28 раза! Но до круглого числа не хватило всего ~два миллиона, попробуем это исправить.
Сперва посмотрим на статистику, сгенерированную perf:
$ sudo perf stat -B -e task-clock,context-switches,cpu-migrations,page-faults,cycles,instructions,branches,branch-misses,cache-misses ./http_server_multithreaded
Performance counter stats for './http_server_multithreaded':
242446,314933 task-clock (msec) # 4,000 CPUs utilized
1?813?074 context-switches # 0,007 M/sec
4?689 cpu-migrations # 0,019 K/sec
254 page-faults # 0,001 K/sec
895?324?830?170 cycles # 3,693 GHz
621?378?066?808 instructions # 0,69 insn per cycle
119?926?709?370 branches # 494,653 M/sec
3?227?095?669 branch-misses # 2,69% of all branches
808?664 cache-misses
60,604330670 seconds time elapsedИспользование аффинности ЦПУ, компиляция с -march=native, PGO, увеличение числа попаданий в кеш, увеличение MAX_EVENTS и использование EPOLLET не дало значительного прироста в производительности. Но что получится, если увеличить количество одновременных соединений?
Статистика при 352 одновременных соединениях:
$ wrk -c352 -d1m -t8 http://127.0.0.1:18470 -H "Host: 127.0.0.1:18470" -H "Accept-Language: en-US,en;q=0.5" -H "Connection: keep-alive"
Running 1m test @ http://127.0.0.1:18470
8 threads and 352 connections
Thread Stats Avg Stdev Max +/- Stdev
Latency 2.12ms 3.79ms 68.23ms 87.49%
Req/Sec 83.78k 12.69k 169.81k 83.59%
40006142 requests in 1.00m, 5.48GB read
Requests/sec: 665789.26
Transfer/sec: 93.34MBЖеланный результат получен, а вместе с ним и интересный график, демонстрирующий зависимость числа обработанных запросов за 1 минуту от количества соединений:
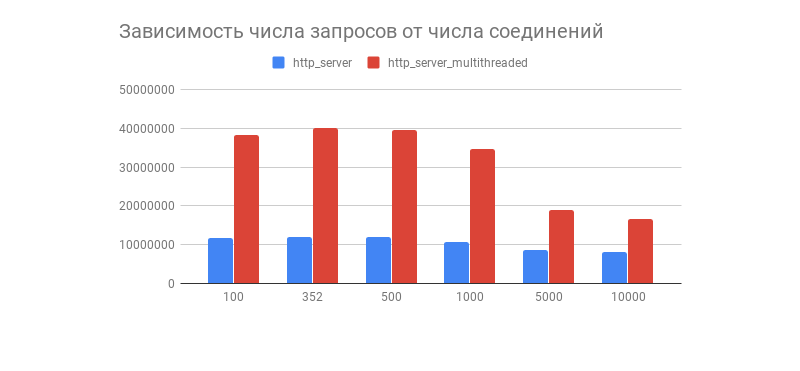
Видим, что после пары сотен соединений число обработанных запросов у обоих серверов резко падает (у многопоточного варианта это более заметно). Связано ли это с реализацией TCP/IP стека Linux? Свои предположения насчёт такого поведения графика и оптимизаций многопоточного и однопоточного вариантов смело пишите в комментариях.
Как отметили в комментариях, данный тест производительности не показывает поведения I/O реактора на реальных нагрузках, ведь почти всегда сервер взаимодействует с БД, выводит логи, использует криптографию с TLS и т.д., вследствие чего нагрузка становится неоднородной (динамической). Тесты вместе со сторонними компонентами будут проведены в статье про I/O проактор.
Недостатки I/O реактора
Нужно понимать, что I/O реактор не лишён недостатков, а именно:
- Пользоваться I/O реактором в многопоточной среде несколько сложнее, т.к. придётся вручную управлять потоками.
- Практика показывает, что в большинстве случаев нагрузка неоднородна, что может привести к тому, что один поток будет проставивать, пока другой будет загружен работой.
- Если один обработчик события заблокирует поток, то также заблокируется и сам системный селектор, что может привести к трудноотлавливаемым багам.
Эти проблемы решает I/O проактор, зачастую имеющий планировщик, который равномерно распределяет нагрузку в пул потоков, и к тому же имеющий более удобный API. Речь о нём пойдёт позже, в моей другой статье.
Заключение
На этом наше путешествие из теории прямиком в выхлоп профайлера подошло к концу.
Не стоит на этом останавливаться, ведь существуют множество других не менее интересных подходов к написанию сетевого ПО с разным уровнем удобства и скорости. Интересные, на мой взгляд, ссылки приведены ниже.
До новых встреч!
Интересные проекты
Что ещё почитать?
- https://linux.die.net/man/7/socket
- https://stackoverflow.com/questions/1050222/what-is-the-difference-between-concurrency-and-parallelism
- http://www.kegel.com/c10k.html
- https://kernel.dk/io_uring.pdf
- https://aturon.github.io/blog/2016/09/07/futures-design/
- https://tokio.rs/blog/2019-10-scheduler/
- https://www.artima.com/articles/io_design_patterns.html
- https://habr.com/en/post/183832/
Комментарии (53)

uvelichitel
14.11.2019 22:40+1В моем понимании вся магия в reactor_run()
while (true) { ... int nfds = epoll_wait(reactor->epoll_fd, events, MAX_EVENTS, timeout - passed); switch (nfds) { ... case event: callback(event); ... } }
Ну вроде, да, так работают вообще все современные (epoll/kqueue) сeрверы под капотом и это всем известно. В async фреймворках и/или специализированных языках этот цикл просто обмазан слоем абстракций разной толщины для удобства пользования. Или что я упускаю?
Hippolot Автор
14.11.2019 22:45В целом, да. Разве что в I/O проакторе блок с вызовом событий заменяется хитрым планировщиком с пулом потоков для исполнения обработчиков событий.

catharsis
14.11.2019 23:28А мне понравилось, как лабораторная работа по epoll.
Понятно, что в настоящем сервере нужно ещё много всего, но надо же с чего-то начинать.
И ни одного упоминания nginx ;)
tmaxx
15.11.2019 00:50Если добавить планировщик для таймеров (priority queue, из которой берётся следующий тайм-аут на epoll), то получится вполне рабочее ядро для простенького однопоточного сервера.

arilou_camper
15.11.2019 02:28Боюсь, что вы в этом понимаете больше, чем я, но я бы посоветовал сделать следующее. Запустите в одной консоли тест, а в другой помониторьте состояние сокетов (количество по статусу).
Может быть у вас сокеты подвисают в состоянии ожидания закрытия, и поэтому увеличение кол-ва приводит к наблюдаемому эффект падения производительности.
Последний раз я тюнил сетевой код на Java два года назад, поэтому пишу без подробностей, испытывая ностальгические чувства)lega
15.11.2019 13:38Судя по результату — тут нет закрытия сокетов (keep-alive), иначе производительность была бы в 10-100 раз меньше.
vlad49
15.11.2019 07:16+1Есть важная деталь — пользовательский код тоже должен быть неблокируемым. И если он получает данные с диска (сюрприз) — то в линукс это сделать было до последнего времени нельзя. Только костыли в виде тех же тредпулов, которые тоже не спасают от полного вставания колом из-за одного тупящего или перегруженного диска, даже nginx. Как отстоят дела с асинхронным дисковым i/o в последних ядрах? Почему разработчики ядра упорно игнорируют то, что давно есть во FreeBSD и даже в Windows?
masterspline
15.11.2019 08:20> Как отстоят дела с асинхронным дисковым i/o в последних ядрах?
Гугли по io_uring. Хотя, IMHO, это больше актуально для случайного чтения. Для задачи «считать данные с диска последовательно и отдать в сеть», достаточно встроенного в ядро упреждающего чтения (readahead) и костылей в виде тредпулов, как в nginx (а для большинства серверов даже пулы не нужны). Впрочем, в задачах мегапроизводительных серверов, могут быть актуальны описанные вами трудности.Gryphon88
15.11.2019 15:34Не подскажете кроссплатформенное решение для readahead?
masterspline
15.11.2019 18:19readahead (упреждающее чтение) в Linux работает само (внутри ядра ОС). В случае последовательного чтения, количество считываемых данных увеличивается. Им можно управлять.
Про кроссплатформенное решение не интересовался, поэтому, ничего не знаю.
Zekori
15.11.2019 09:09Довольно поверхностный и типичный подход. Уж извините.
1. Добавьте для сокетов SOCK_CLOEXEC опцию
2. Хендлите ситуацию закрытия\подвисания сокета (EPOLLRDHUP | EPOLLHUP)
3. Почитайте про edge\level triggered, дайте другим сокетам право на жизнь избавясь от лишнего вызова while(read(...)) => EAGAIN || EWOULDBLOCK
4. ну и надеется на то что в вашем http сервере, все запросы\ответы будут ограниченной длины в 1024 байт — наивно. Тут у вас и появятся вопросы с аллоцированием\реалоцированием памяти, просадки
5. http сервер, не ограничивается только приемом данных, данные нужно как-то обработать, выше писали, про тот же парсинг и т.д.
…
N. А есть медленные клиенты, почитайте про TCP_KEEPALIVE
N+1. позже вы дойдете, до того, что не все клиенты честные, они откроют десятки тысяч соединений и на вашем сервере закончатся сокеты. Подумайте над этим когда будете развивать ваш проектHippolot Автор
15.11.2019 10:10- Я пробовал с EPOLLET делать (секция «Второй заход»), это ощутимых результатов не дало (но должно проявится с парсером, БД и т.д.). Level-Triggered идёт по-умолчанию в epoll, поэтому этот цикл чтения убрать можно.
Спасибо аз советы.
iboltaev
18.11.2019 14:493. Если сокет создается с NONBLOCKING, тогда можно и в цикле и в Edge-Triggered. Вроде он быстрее.
xnko
15.11.2019 09:54У меня тоже есть реализация, крос платформенный и с coroutine-ами, так что пишешь тоже, но без коллбеков.
Hippolot Автор
15.11.2019 12:58Можете привести пример использования? Из списка публичных функций пока неясно как Вашу библиотеку можно использовать.
xnko
15.11.2019 19:23Вот пример как хостить простой todomvc приложение.
> make > bin/file-server samples/todomvc/ # open browser and navigate to http://localhost:8080
Идея состоит в том что на голом C пишете код вроде
while (condition) { io_stream_read(stream, buffer, sizeof(buffer), 0); io_stream_write(stream, RESPONSE, sizeof(RESPONSE) - 1); }
и этот код будет работат в этквиваленте следующего кода на C# или JavaScript
while (condition) { await ReadAsync(stream, buffer, sizeof(buffer), 0); await WriteAsync(stream, RESPONSE, sizeof(RESPONSE) - 1); }
без каких либо препроцессоров или других модификаторов кода.
lega
15.11.2019 13:54Requests/sec: 665789.26
Вам удалось выяснить во что упирается производительность? Сколько CPU используется (при 80% и 100% производительности)?
Я производил подобный тест — на максимуме производительности используются не все ресурсы, поэтому пришел к выводу, что упирается в сетевой стек, может локи внутри epoll или т.п.
Ещё я заметил, что более 60% CPU уходит на отправку (send), есть идея вынести recv и send по разным epoll, что может дать ещё производительности.
Как вариант, вместо SO_REUSEPORT, можно использовать один (отдельный) поток/epoll для приема всех соединений, и потом уже передавать в менее нагруженный epoll.Hippolot Автор
16.11.2019 11:40Вам удалось выяснить во что упирается производительность? Сколько CPU используется (при 80% и 100% производительности)?
topпоказывает числа в районе 400% нагрузки ЦПУ (сwrkиhttp_server_multithreaded). Как версия с прибитыми к ядрам потоками, так и простойhttp_server_multithreaded.
Я производил подобный тест — на максимуме производительности используются не все ресурсы, поэтому пришел к выводу, что упирается в сетевой стек, может локи внутри epoll или т.п.
Я тоже думаю, что упирается в сетевой стек Linux.
Как вариант, вместо SO_REUSEPORT, можно использовать один (отдельный) поток/epoll для приема всех соединений, и потом уже передавать в менее нагруженный epoll.
Идея, но это уже будет нечто похожее на проактор.
mvv-rus
15.11.2019 16:12Модифицированная версия выделяет фиксированное число потоков (thread pool), тем самым не позволяя системе аварийно прекратить исполнение, но вместе с тем привносит новую проблему: если в данный момент времени пул потоков блокируют продолжительные операции чтения, то другие сокеты, которые уже в состоянии принять данные, не смогут этого сделать.
Тут есть ещё одна проблема (или другая сторона той же проблемы): число потоков для такой архитектуры подобрать трудно. Если потоков будет слишком мало, то пул часто будет истощаться из-за того, что они ожидают завершения блокирующих операций ввода/вывода. Если много, то избыточное число активных потоков приведет к потерям на частое переключение между ними.
Для эффективной реализации парадигмы пула потоков нужен механизм в ОС, который, даже при наличии задач в очереди обработки, реализует запуск на обработку только ограниченного (например, равного числу ядер в системе) числа активных потоков, меньшего полного числа потоков в пуле. Такой механизм должен отслеживать число активных (не заблокированных на вводе/выводе) потоков, и если их становится мало, запукать обработку в дополнительных потоках из пула. При наличии такого механизма истощение пула потоков становится менее вероятным, при том что потери на конкуренцию между активными потоками остаются на приемлемом уровне, т.к. число активных потоков привышает желательное только на короткое время.
В Windows такой механизм — IO сompletion port — есть уже довольно давно. Но вот в часто используемом для создания веб-серверов Linux с таким механизмом, насколько мне известно(если я ошибаюсь — просьба поправить), есть (или были до недавнего времени) проблемы, а потому подход с пулом потоков в Linux работает (или работал) сильно хуже событийно-ориентированного неблокирующего подхода (как в этой статье).
PS А ещё меня в очередной раз умилил пример «проектирования на основе паттернов» (наиболее заметной частью которого IMHO является назначение красивых имен давно известным приемам программирования) из названия статьи: в данном случае красивым словом Реактор(Reactor) названо давно и хорошо известное (в частности, GUI Windows реализован именно в этой парадигме) событийно-ориентированное программирование. С одной стороны, конечно, не могу отрицать полезность паттернов — красивые имена повзоляют легче запоминать приемы (действительно полезные), но вот с другой стороны не умеющему «в паттерны» трудно сразу понять, что речь на самом деле идет о чем-то хорошо ему знакомом.mayorovp
15.11.2019 17:04Ну нет, реактор — это не СОП. Всё-таки надо различать общий принцип и обособленную часть программы.
mvv-rus
15.11.2019 17:26Объясните, пожалуйста, что вы считаете в данном случае обособленной частью программы.
mayorovp
15.11.2019 18:24Реактор, разумеется.
mvv-rus
15.11.2019 19:50В данном случае вы заблуждаетесь. Reactor pattern(та самая ссылка, которая в статье) — это именно общий принцип, «паттерн»(шаблон проектирования, если по-русски), «повторяемая архитектурная конструкция, представляющая собой решение проблемы»(из Википедии).
А частью программы (реализацией этого общего принципа), причем, в данном случае — коренной, составляющей основную её логику, являются struct reactor и работающие с ними функции в программе автора.
В более сложных программах разные её части могут реализовывать разные общие принципы. Например, в одной и той же программе для современных (в смысле не 3.x) версий Windows может быть, например, как графическая часть на основе событийно-ориентированного программирования, так и логика обработки подключений клиентов по сети с использованием Winsock, использующая другую парадигму. Например — выделенные потоки для каждого клиента, такие программы можно легко и просто клепать в Delphi: там графические и сетевые компоненты для накидывания на форму берутся из одной кучи.

nuclight
16.11.2019 20:09-2Вот неистово плюсую. В нашу молодость это никакими "реакторами" не называлось, да и вообще никак особо не называлось, а было просто нормой. Хоть классическую библию Стивенса по сетевому программированию взять, просто неблокирующиеся сокеты, да и всё (и кстати, в статье гвоздями прибито к epoll, не лучшей реализации, хотя на картинке их было больше — почему не libevent было рассмотреть хотя б?). Складывается впечатление, что чем больше людей и проектов в отрасли, тем больше им нужно как-то оправдывать своё существование громкими словами.
Hippolot Автор
16.11.2019 21:15Вот неистово плюсую. В нашу молодость это никакими "реакторами" не называлось, да и вообще никак особо не называлось, а было просто нормой. Хоть классическую библию Стивенса по сетевому программированию взять, просто неблокирующиеся сокеты, да и всё
Мне больше нравятся термины "однопоточный цикл событий" и "I/O реактор". Второй легче звучит и проще запомнить. Неблокирующие сокеты, ИМХО, неполностью описывают саму суть подхода, т.к. можно пользоваться неблокирующими сокетами и без самого цикла событий.
и кстати, в статье гвоздями прибито к epoll, не лучшей реализации, хотя на картинке их было больше — почему не libevent было рассмотреть хотя б?
Потому что libevent — это реализация I/O реактора, а не системный селектор, и тоже далеко не самая лучшая.
nuclight
18.11.2019 01:55-1Не легче, потому что по каждой конкретной реализации начнутся споры — реактор ли это, а может проактор, а может еще какие-то нюансы схоластические не учли...
т.к. можно пользоваться неблокирующими сокетами и без самого цикла событий.
Ну, попытайтесь =) Неизбежно будет некое подобие такого цикла в итоге. Или можно было сразу прочитать Стивенса и знать, что и как имеется, и какие подводные камни.
тоже далеко не самая лучшая.
Потому и "хотя б", только это не имеет особого значения уже.

orignal
15.11.2019 20:16+1>CallbackData *callback = g_hash_table_lookup(reactor->table, &fd);
Не лучше ли сразу держать указатель на коллбэк в events[i].data.ptr и обойтись без лишнего поиска в хэше?Hippolot Автор
15.11.2019 21:17Не будет ли утечек памяти?
masterspline
15.11.2019 21:32Если вместо удаления CallbackData* из хеша освобождать память, то не будет. По сути разница только в том, что вместо поиска CallbackData* в хеше ты будешь получать этот указатель из epoll_event.data.ptr. Однако, в этом случае в epoll_data не будет fd и его нужно будет откуда-то получить, например, из того же CallbackData.
В результате такой оптимизации исчезает хеш и операции работы с ним (добавление/удаление данных, поиск CallbackData в хеше).Hippolot Автор
15.11.2019 23:24По сути разница только в том, что вместо поиска CallbackData* в хеше ты будешь получать этот указатель из epoll_event.data.ptr.
Как я его буду получать, например, если я хочу уничтожить реактор?
masterspline
15.11.2019 23:29Для этого я в аналогичной ситуации сделал двусвязный список (интрузивный) для объектов-подключений. В данном случае это будут CallbackData. Вставка и удаление такого объекта не сильно отличаются от хеша (я не придумал более оптимального способа хранения объектов типа CallbackData, чтобы их можно было удалить, например, при остановке приложения). Зато поиска по хешу не будет.
Самое неприятное, что остановка реактора (или приложения) чуть ли не единственный случай кроме обработки события epoll, когда требуется указатель на CallbackData. И ради этого приходится держать где-то эти указатели, а значит добавлять и удалять эти указатели из какой-то структуры.
tuleman
16.11.2019 21:09Говоря про недостатки событийного подхода, думаю имеет смысл упомянуть те, которые поднимались в академической среде в конце прошлого/начале текущего столетия и описаны в работе «Why Events Are A Bad Idea (for high-concurrency servers)»
Это stack ripping и inversion of control
Альтернатива — сопрограммы и легкие потоки, реализованные на их основе.
Они дают удобство написания thread-based подхода и скорость работы за счёт асинхронности «под капотом» и той самой популярной ныне кооперативной многозадачности, которая многим нравится в golang, kotlin и т.д.
В них можно полностью отказаться от привычных примитивов синхронизации типа мьютексов и условных переменных.
Хорошо описано в цикле статей «Асинхронность: назад в будущее» Григория Демченко
kdmitrii
Нуууу такими темпами можно было и вообще написать return 0; в обработчик и посчитать производительность.
Что тут нужно сделать:
Вот после этого можно будет ооооооооочень примерно померить производительность этого сервера.
Hippolot Автор
Динамическую (неоднородную) нагрузку, скорее всего, покажу в статье про I/O проактор, где и сравню его с обычным I/O реактором. Тут проблема ещё в том, что вместе с нашим кодом мы будем измерять производительность библиотеки TLS, базы данных, логгера и т.д.
euroUK
Я думаю, автор комментария имел ввиду, что это абсолютно бесполезное занятие сравнивать голую производительность через сокет. Ведь хотя бы для того, чтобы правильно организовать работу с хедерами, вам придется написать кучу кода. Там всякие кодировки, сжатие, HTTPS и прочее. А если говорить вообще о том, что нужно в общем случае, то и с базой надо работать, и с шаблонизатором.
Реализуете все это на С, и удивитесь, что какой-нибудь .Net Core из коробки работает быстее.
Hippolot Автор
Осознал, в статье про I/O проактор исправлюсь)
catharsis
Веб-сервера так и меряются производительностью.
.Net нет причин быть медленнее, как ниже заметили, сейчас все сервера так работают.
mi76554
>Реализуете все это на С, и удивитесь, что какой-нибудь .Net Core из коробки работает быстее.
Написал как-то микросервис на С для контроля контроллеров =), libressl, простейший парсинг, реактор модель. Там всего с пяток страниц кода.
Ради интереса сделал нагрузочный тест. Сопоставим по скорости обработки на 2-3 тыс конкурентных запросов был только минимальный koa.js на node.js, ну так там libuv под капотом.
Net Core и рядом не стоял.
euroUK
Как это прекрасно сравнивать код 5 страниц с полнофункциональным веб-фреймворком. Если все отрезать — node.js медленнее dotnetcore
mi76554
>Как это прекрасно сравнивать код 5 страниц с полнофункциональным веб-фреймворком.
В этом коде есть все что упомянуто вами — преобразования, криптография, «разбор хидеров».
Сожалею, что затронул чувства в отношении «полнофункционального веб-фреймворка»
euroUK
Я как-то на бейсике под дос сделал все что упомянуто вами — преобразования, криптография, «разбор хидеров». Бейсик конечно не очень быстрый, но зато все уложилось в 5 строчек кода.
Мне продолжать или вы поняли, где тут проблема?
П.С. Это шутка, если что.
talbot
У автора как раз очень интересная задача на простом примере показать, из чего состоит I/O Reactor. Это не про тестирование на динамической нагрузке, а про алгоритмы и upper bounds.
Hippolot Автор
Тем не менее, результаты тестов производительности сферического коня в ваакуме от нагрузок из реального мира сильно отличаются. Думаю, что стоило или сделать тест со сторонними компонентами (БД, логгер, etc), или не делать тестов вовсе.
Динамический тест в статью про I/O проактор хорошо впишется, т.к. концепт проактора и был придуман для неоднородных нагрузок.
catharsis
Так вот и меряются производительностью "убийцы nginx".
Sabubu
Для нагрузки в миллионы запросов в секунду, наверно, подойдет бинарный протокол, а не HTTP, чтобы не тратить время на парсинг.
iboltaev
добавив работу с БД, мы померяем производительность БД, а не сервера.