
В данной работе авторы предлагают архитектуру Cascaded Factorized Atrous Spatial Pyramid Pooling (CF-ASPP) для семантической сегментации в реальном времени. Новый модуль CF-ASPP и использование super-resolution позволяют улучшить latency-accuracy trade-off. Обзор подготовил ведущий разработчик МТС Андрей Лукьяненко.
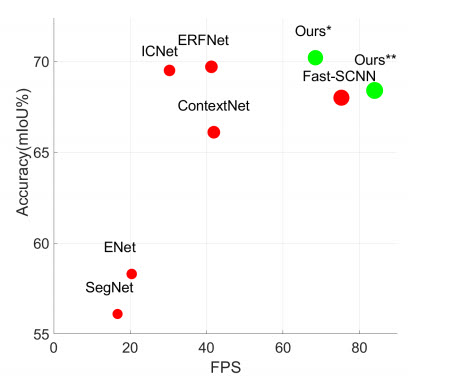
Семантическая сегментация в реальном времени очень нужна для многих задач, выполняемых на ограниченных ресурсах. Одна из больших сложностей — работа с объектами разных размеров и использованием контекста. В данной работе авторы предлагают архитектуру Cascaded Factorized Atrous Spatial Pyramid Pooling (CF-ASPP).
В наше время распространенным подходом является быстрое уменьшение размера изображений на начальных этапах, а затем маска исходного размера получается с помощью upsampling. Авторы предлагают использовать подходы super-resolution вместо простого upsampling.
Новый модуль и использование super-resolution позволяет улучшить latency-accuracy trade-off.
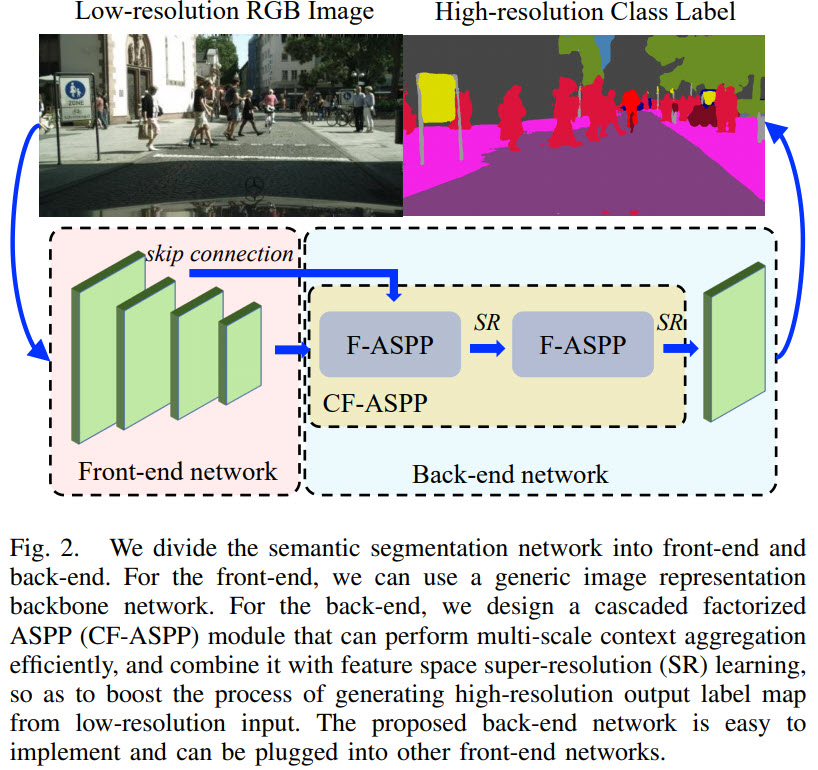
В терминологии авторов претренированная сеть для извлечения фичей называется front-end network, а остальная часть — back-end network.
Обоснование улучшений
Поскольку один и тот же объект на разных картинках может иметь разные размеры, очень важно уметь эффективно использовать контекстную информацию, особенно для маленьких и узких объектов. Front-end обычно делает агрегацию контекста с нескольких масштабов. Но обычно эти модули работают на глубоких уровнях нейронных сетей, где количество каналов высоко. В результате даже convolutional слои с размером кернела 3 требуют довольно много вычислительных ресурсов. Поэтому авторы предлагают свой модуль, который делает это эффективнее.
Еще одна проблема back-end для семантической сегментации заключается в том, что пространственный размер у feature maps знаительно уменьшается после front-end. Плюс многие подходы используют картинки с уменьшенным размером для повышения скорости. В результате размер получается еще меньше. Авторы предлагают во время тренировки использовать маску оригинального размера для supervision. Super-resolution позволяет эффективно восстанавливать маску высокого разрешения из маски с маленьким разрешением.
Суть улучшений
В качестве front-end может использоваться любая претренированная сетка, например VGG, ResNet, MobileNet.
Вся суть заключается в back-end:
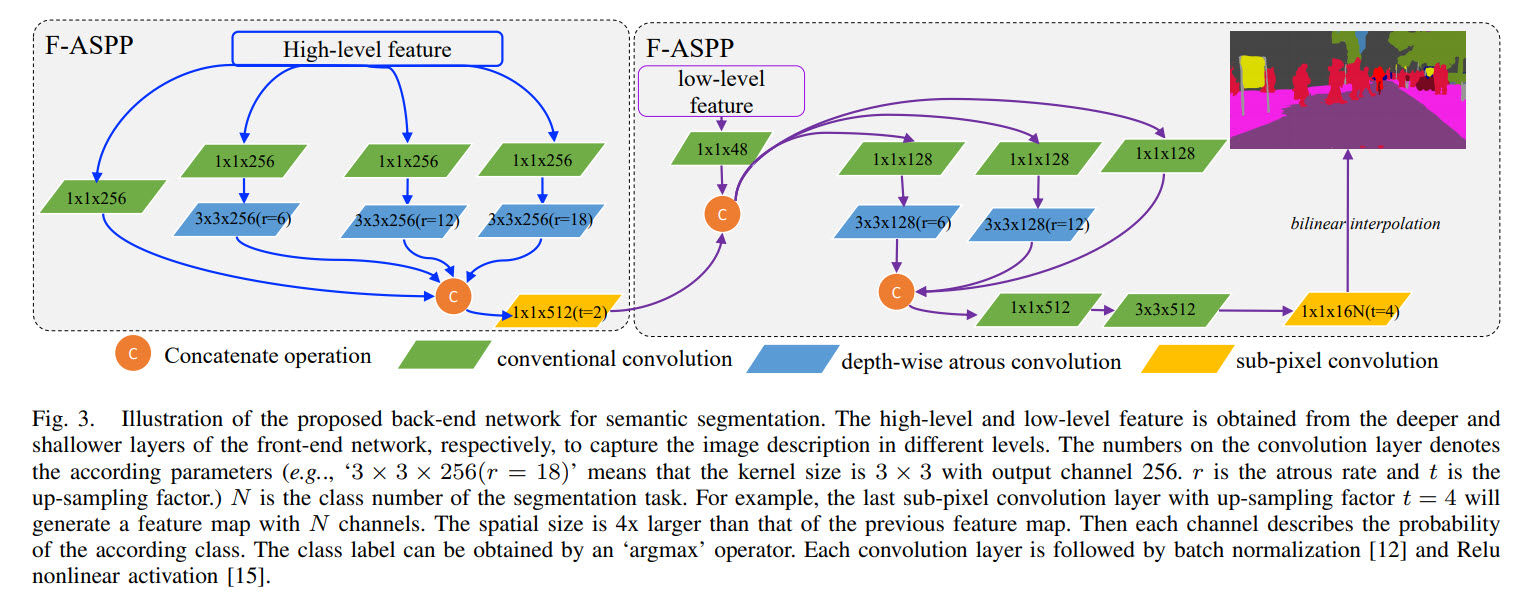
Cascaded Factorized ASPP
В семантической сегментации часто используют atrous convolutions — их отличие от стандартного подхода заключается в том, что между фильтрами добавляют r — 1 нулей. Это позволяет значительно увеличить обозрение каждого фильтра без увеличения вычислительных затрат. Но поскольку atrous convolutions применяются к feature maps большого размера, вычисления все равно получаются затратными.
Авторы предлагают декомпозировать 3 ? 3 atrous convolution на 2 части: point-wise convolution для уменьшения количества каналов, а затем depth-wise and atrous convolution для уменьшения вычислительных затрат. В результате требуется примерно в 8.8 раз меньше вычислений.
Кроме того, модуль ASPP применяется два раза каскадно. С одной стороны, модель получает больше контекстов разного масштаба, с другой стороны, на второй ASPP приходят картинки меньшего размера, поэтому сетка не очень сильно замедляется, а точность повышается.
Feature Space Super-resolution
В результате работы front-end размер изображений сильно уменьшается, и нам надо на основе этого уменьшенного изображения получить результат с высоким разрешением. Авторы используют для этого подход super-resolution.
На этапе тренировки уменьшенное изображение используется в качестве входных данных, а оригинальное изображение — в качестве ground truth.
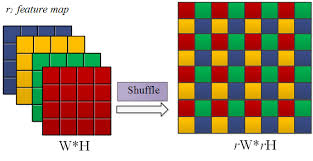
В модуле back-end upsampling делается с помощью sub-pixel convolution, что как раз используется в задачах super-resolution.
Эксперименты
В качестве датасета использовали cityscapes. Код был написан на Pytorch 1.1, CuDNN v7.0. Инференс делали на Nvidia Titan X (Maxwell). Использовали ResNet-18 в качестве претренированной сетки. Фичи брали с последнего слоя перед average pooling и со слоя conv3_x.
SGD, 400 эпох и много аугментаций.
Ablation Study on Network Structure
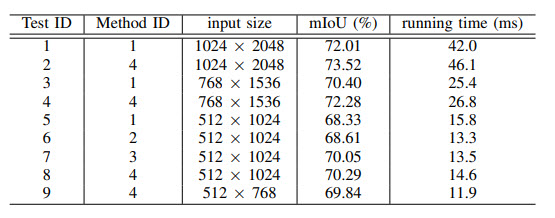
Проверяли 4 подхода:
Сравнение с другими подходами
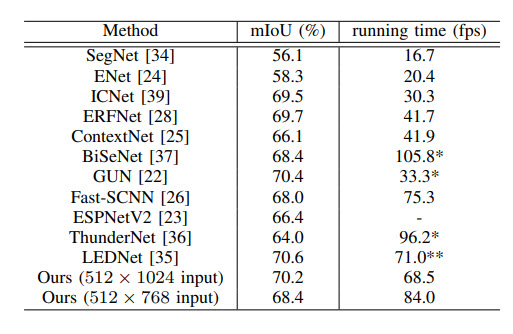
Качество реально высокое и скорость инференса почти лучшая.

Семантическая сегментация в реальном времени очень нужна для многих задач, выполняемых на ограниченных ресурсах. Одна из больших сложностей — работа с объектами разных размеров и использованием контекста. В данной работе авторы предлагают архитектуру Cascaded Factorized Atrous Spatial Pyramid Pooling (CF-ASPP).
В наше время распространенным подходом является быстрое уменьшение размера изображений на начальных этапах, а затем маска исходного размера получается с помощью upsampling. Авторы предлагают использовать подходы super-resolution вместо простого upsampling.
Новый модуль и использование super-resolution позволяет улучшить latency-accuracy trade-off.
В терминологии авторов претренированная сеть для извлечения фичей называется front-end network, а остальная часть — back-end network.
Обоснование улучшений
Поскольку один и тот же объект на разных картинках может иметь разные размеры, очень важно уметь эффективно использовать контекстную информацию, особенно для маленьких и узких объектов. Front-end обычно делает агрегацию контекста с нескольких масштабов. Но обычно эти модули работают на глубоких уровнях нейронных сетей, где количество каналов высоко. В результате даже convolutional слои с размером кернела 3 требуют довольно много вычислительных ресурсов. Поэтому авторы предлагают свой модуль, который делает это эффективнее.
Еще одна проблема back-end для семантической сегментации заключается в том, что пространственный размер у feature maps знаительно уменьшается после front-end. Плюс многие подходы используют картинки с уменьшенным размером для повышения скорости. В результате размер получается еще меньше. Авторы предлагают во время тренировки использовать маску оригинального размера для supervision. Super-resolution позволяет эффективно восстанавливать маску высокого разрешения из маски с маленьким разрешением.
Суть улучшений
В качестве front-end может использоваться любая претренированная сетка, например VGG, ResNet, MobileNet.
Вся суть заключается в back-end:
Cascaded Factorized ASPP
В семантической сегментации часто используют atrous convolutions — их отличие от стандартного подхода заключается в том, что между фильтрами добавляют r — 1 нулей. Это позволяет значительно увеличить обозрение каждого фильтра без увеличения вычислительных затрат. Но поскольку atrous convolutions применяются к feature maps большого размера, вычисления все равно получаются затратными.
Авторы предлагают декомпозировать 3 ? 3 atrous convolution на 2 части: point-wise convolution для уменьшения количества каналов, а затем depth-wise and atrous convolution для уменьшения вычислительных затрат. В результате требуется примерно в 8.8 раз меньше вычислений.
Кроме того, модуль ASPP применяется два раза каскадно. С одной стороны, модель получает больше контекстов разного масштаба, с другой стороны, на второй ASPP приходят картинки меньшего размера, поэтому сетка не очень сильно замедляется, а точность повышается.
Feature Space Super-resolution
В результате работы front-end размер изображений сильно уменьшается, и нам надо на основе этого уменьшенного изображения получить результат с высоким разрешением. Авторы используют для этого подход super-resolution.
На этапе тренировки уменьшенное изображение используется в качестве входных данных, а оригинальное изображение — в качестве ground truth.
В модуле back-end upsampling делается с помощью sub-pixel convolution, что как раз используется в задачах super-resolution.
Эксперименты
В качестве датасета использовали cityscapes. Код был написан на Pytorch 1.1, CuDNN v7.0. Инференс делали на Nvidia Titan X (Maxwell). Использовали ResNet-18 в качестве претренированной сетки. Фичи брали с последнего слоя перед average pooling и со слоя conv3_x.
SGD, 400 эпох и много аугментаций.
Ablation Study on Network Structure
Проверяли 4 подхода:
- Front-end — ResNet-18, back-end — ASPP, decoder — DeeplabV3+
- Front-end — ResNet-18, back-end — one F-ASPP, decoder — DeeplabV3+
- Front-end — ResNet-18, back-end — CF-ASPP (без feature space resolution)
- Полный подход.
Сравнение с другими подходами
Качество реально высокое и скорость инференса почти лучшая.
oaiuvvkn
Почему для лейблов выбраны именно такие цвета? Как их вообще выбирают?
Artgor Автор
Насколько я знаю, выбор цвета делают сами авторы — нет каких-либо четких принципов выбора цвета для лейблов.
Artgor Автор
Уточню, вроде выбирают не авторы статей, а авторы датасетов. И дают api, с помощью которого это можно вытащить.