

Итак, продолжим исследовать характеристики работы PostgreSQL на SSD и HDD дисках с целью повышения производительности системы. Первую часть можно почитать здесь.
В ходе развития сервиса оптимизации затрат на сотовую связь Dr. Tariff (iOS, Android) для совместного пилота с одним из партнеров нам потребовалась большая и производительная реляционная база данных.
В этот раз мы протестировали PostgreSQL на RAID-0 массиве из двух SSD дисков. RAID массив собирался с помощью mdadm. Размер страйпа (блока информации, который распределяется на все диски массива) – 512k.
Нагрузка на диски мониторилась с помощью команды iostat (пакет sysstat). При тестировании на одном ssd диске утилизация диска составляла 95-100%. При тестировании на RAID массиве утилизация каждого из дисков в среднем была 90%. Нагрузка на процессор измерялась с помощью htop. Во время большинства тестов, если не оговорено иное, нагрузка составляла 30-50%. Python-клиент, с помощью которого нагружалась база данных запускался с этой же машины и до 20% процессора потреблялась им. Таким образом, производительность системы упирается в скорость работы диска.
Benchmark
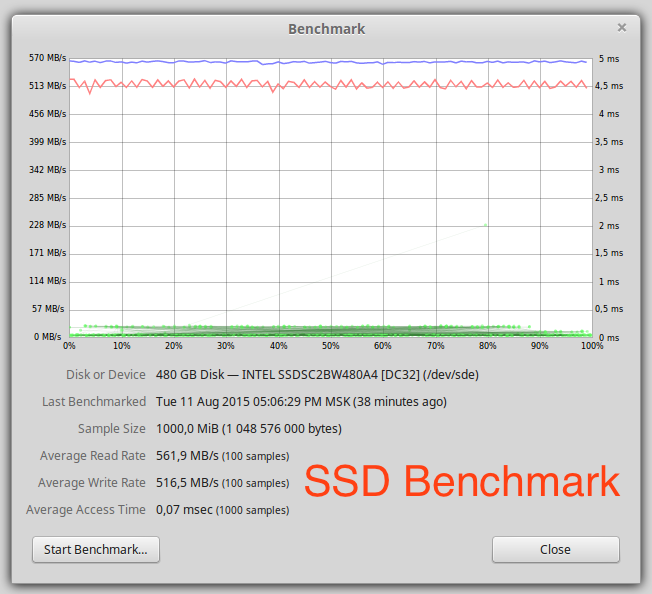
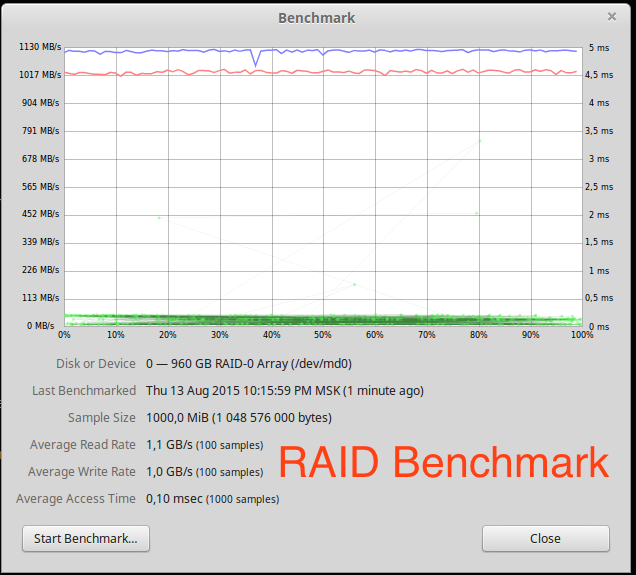
Скорость линейного чтения почти в два раза выше, чем у одного диска. Масштабирование почти линейное для двух дисков.
Производительность PostgreSQL на RAID массиве
Размер и настройки БД точно такие же как в первой части.
Производительность чтения

В среднем производительность чтения оказалась на 15% выше, чем для отдельного диска. Это объясняется различной задержкой при чтении случайных блоков. Утилизация каждого из дисков по iostat доходила до 90%, хотя при тестировании одиночного диска она почти всегда составляла 100%. На хабре есть отличная статья на эту тему.
Производительность записи
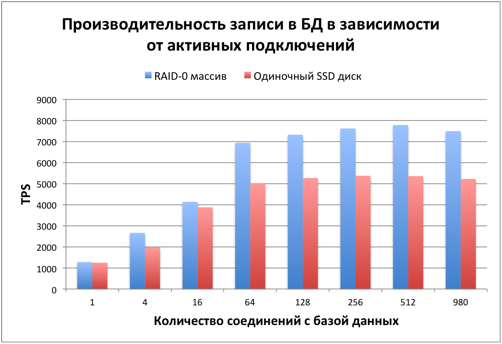
Скорость записи уже на 40% выше, чем у одного диска. Это сильно лучше, чем чтение, но еще далеко до линейного масштабирования, при котором скорость должна быть в 2 раза выше.
Нагружаем диски. 10 миллиардов записей
Время нагрузить диски и базу данных. Тестовый размер таблицы – 10 миллиардов записей. На диске сразу после заполнения 423 Гб было занято под таблицу и 212 Гб на индекс. Процесс заполнения БД занял около 14 часов.
Первым интересующим вопросом стало падение производительности при увеличении количества записей в 10 раз.
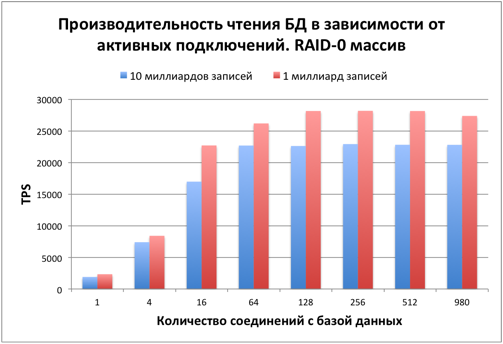
Скорость чтения уменьшилась примерно на 20% в сравнении с БД с 1 миллиардом записей.
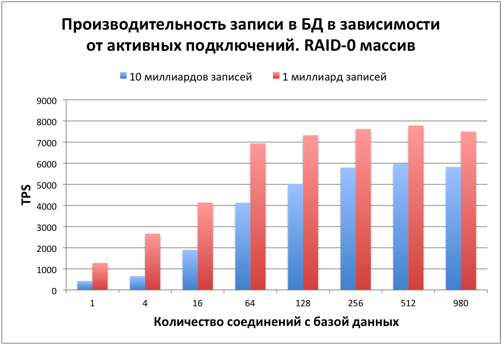
Скорость записи уменьшилась на 20-40%.
Падение производительности объясняется:
- Большим размером индексов
- Меньшей долей оперативной памяти от всего размера БД
При размерах таблицы в 10 миллиардов строк практически любое чтение происходит с диска.
Варьируем количество записей в таблице
После проведенных тестов стало интересно, при каких размерах БД дисковая система становится определяющим фактором. Исходя из предыдущих тестов количество одновременных подключений было выбрано равным 64. Shared_buffers = 2048mb.
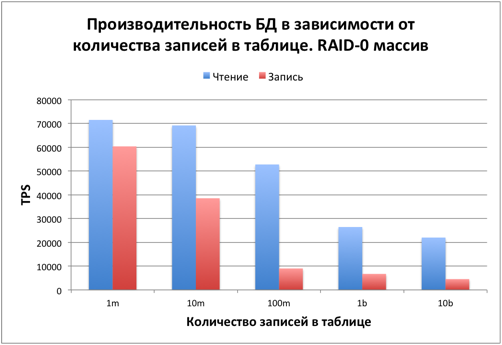
При количестве записей в таблице до 10 миллионов, данные полностью умещаются в оперативную память. Чтение и запись происходят быстро. В этом случае узким местом является процессор. Нагрузка по htop доходила до 100%. Во время тестирования около 20% процессора потреблялось Python-клиентом. Если клиент перенести на другую машину, то производительность будет пропорционально выше.
При 100 миллионах записей размер БД составляет около 6-7 Гб. Поместить БД в shared_buffers уже не получается, но при этом высокую роль играет дисковый кэш в оставшейся оперативной памяти. Примерно с таких размеров роль процессора становится менее значительной и на производительность влияет диск.
При 1 и 10 миллиардах записей в оперативную память помещается только незначительная часть данных и индекса. Узким местом является дисковая подсистема.
Стоит отметить, что данное тестирование синтетическое. Вероятность чтения каждой записи одинаковая. В большинстве реальных случаев в базе данных идет работа с небольшой долей записей от всего объема данных, поэтому будет больший выигрыш за счет их кэширования.
Резюме
Производительность БД на SSD RAID-0 массиве оказалась выше, чем на одиночном диске, но далека от линейного масштабирования. Если на данном железе требуется еще большая скорость работы, то лучше разделить данные на несколько баз данных и разместить их отдельно на каждом из дисков.
В комментариях к первой части MikeGav упомянул, что производительность SSD падает при заполнении диска. По ряду других тестирований SSD эта проблема наступает при заполнении на 85-90%. Во всех наших тестах общее место, занимаемое базой данных не превышало 75%. В следующей части будет тестирование производительности базы данных на SSD RAID-0 массиве в зависимости от настроек PostgreSQL.
А наиболее выгодный тариф подскажет приложение Dr. Tariff на Android и на iOS.
Другие статьи о возможностях Dr. Tariff и аналитике сотовых услуг из нашего блога
Dr. Tariff посчитал у какого сотового оператора больше 4G интернета (часть 2)
Dr. Tariff посчитал у какого сотового оператора больше 4G интернета (часть 1)
Осторожно! Скрытые доходы операторов — следите за опциями «Вам звонили!», «Кто звонил+», «Будь в курсе+» (теперь платные)
История о том, как мобильный оператор списал деньги с разработчика Dr. Tariff (захватите попкорн)
Dr. Tariff 2.0: новые возможности для абонентов Билайн, МегаФон и МТС
Решили сменить оператора? Не забудьте подобрать выгодный тариф с помощью Dr. Tariff
Dr. Tariff (3 месяца спустя) — подобрать тариф можно в 80 регионах России на Android и iOS
Dr. Tariff (тарифы и баланс): Как я стал помогать людям экономить на мобильных затратах
Dr. Tariff посчитал у какого сотового оператора больше 4G интернета (часть 1)
Осторожно! Скрытые доходы операторов — следите за опциями «Вам звонили!», «Кто звонил+», «Будь в курсе+» (теперь платные)
История о том, как мобильный оператор списал деньги с разработчика Dr. Tariff (захватите попкорн)
Dr. Tariff 2.0: новые возможности для абонентов Билайн, МегаФон и МТС
Решили сменить оператора? Не забудьте подобрать выгодный тариф с помощью Dr. Tariff
Dr. Tariff (3 месяца спустя) — подобрать тариф можно в 80 регионах России на Android и iOS
Dr. Tariff (тарифы и баланс): Как я стал помогать людям экономить на мобильных затратах
Подписывайтесь на наши новости и делитесь информацией с друзьями в Вконтакте и Facebook.
z0rg
У меня только один вопрос, откуда у вас миллиарды записей? Все данные биллинга пользователей, которые заюзали ваш сервис?
DrTariff
Нет, информация о клиентах нашего крупного партнера.