

В ходе развития сервиса оптимизации затрат на сотовую связь Dr. Tariff (iOS, Android) для совместного пилота с одним из партнеров нам потребовалась большая и производительная реляционная база данных.
Производительности HDD диска было явно недостаточно. Размер базы должен был составить несколько сотен гигабайт, поэтому размещение ее в оперативной памяти было бы слишком дорого. SSD диск наилучшим образом подходит для этой задачи. Но одного SSD диска могло не хватить, поэтому было решено собрать RAID-0 массив из двух дисков. Пользуясь случаем мы решили провести тестирование производительности PostgreSQL на одном и двух SSD дисках.
Основные цели тестирования
1. Сравнить производительность PostgreSQL на SSD RAID-0 массиве с производительностью на одиночном SSD.
2. Изучить производительность базовых операций (SELECT и UPDATE) в зависимости от размера таблицы, количества подключений, настроек сервера и других параметров.
Тестирование проводилось в несколько итераций. По каждой части решено было написать подробную статью с отчетами:
- Тестирование одного SSD диска
- Тестирование RAID-0 массива из 2-х SSD дисков
- Влияние настроек сервера на производительность БД
- Сравнение SSD с HDD
Железная часть
Все тестирование производилось в следующей конфигурации:
- Intel i7 4770.
- 16 Gb RAM.
- Intel SSD для системного диска.
- Intel SSD 480 Gb 530 серии для диска в с базой данных. Model – SSDSC2BW480A401
- Toshiba HDD 3000 Gb. Model – DT01ACA300
- Файловая система всех разделов – Ext4. Диски подключены по интерфейсу SATA 3.
Софт
На тестовом компьютере установлена операционная система Linux Mint 17.2. Версия PostgreSQL — «PostgreSQL 9.4.4 on x86_64-unknown-linux-gnu, compiled by gcc (Ubuntu/Linaro 4.6.3-1ubuntu5) 4.6.3, 64-bit»
После форматирования на SSD диске доступно 440Гб. На графике ниже представлена производительность одного SSD диска.
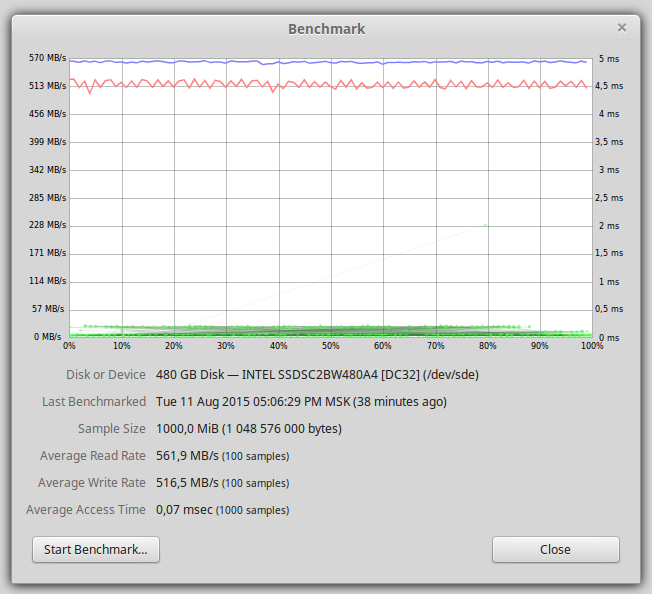
Производительность чтения и записи около 500 Мб/сек, узким местом является SATA интерфейс.
Настройки Postgres стандартные за исключением следующих параметров:
shared_buffers = 2048 Mb
port = 5400
max_connections = 1000
Тестирование
В качестве источника нагрузки было 3 варианта:
- стандартный pg_bench
- Python клиент с Psycopg2
- Python клиент с SQLAlchemy
Первые тесты pgBench показали хорошую производительность, но они работали на вновь сгенерированных таблицах. Нам хотелось, чтобы тест был максимально приближенным к реальным условиям. Конечно, можно написать собственный сценарий тестирования, но было отдано предпочтение Python клиенту.
Первым кандидатом в качестве клиента был SQLAlchemy. В нем есть возможность вызова сырых SQL команд через метод execute. Первые же тесты на маленькой выборке показали, что SQLAlchemy потребляет много (десятки процентов) CPU.
При тестировании Psycopg2 клиента потребление процессора было в районе 15%, что вполне приемлемо для тестирования, так как узким местом в большинстве случаев была дисковая подсистема. Все дальнейшие тесты были произведены с использованием Python клиента c Psycopg2. На каждое подключение к БД создавался отдельный Python процесс.
Схема тестовой таблицы:
CREATE TABLE numbers
(
"number" bigserial NOT NULL,
operator smallint,
region smallint,
CONSTRAINT numbers_pkey PRIMARY KEY (number)
)
Для тестирования чтения использовалась команда:
'SELECT * FROM numbers WHERE number=%d'
Номер выбирался случайный.
Для тестирования записи использовалась команда:
'UPDATE numbers set region=%d, operator=%d WHERE number=%d'
Все параметры случайные из допустимых диапазонов. UPDATE читает и пишет данные на диск при этом не изменяя размера БД, поэтому было решено использовать его для комплексной нагрузки на запись. INSERT и DELETE при тестировании не использовались. Каждый отдельный тест выполнялся несколько минут. Отдельные тесты запускались по несколько раз, и полученная производительность совпадала с точностью около 1%.
Для создания RAID-0 массива использовался mdadm. RAID создавался с использованием всего диска, а не поверх разделов.
Для записи большого количества строк использовалась функция COPY. Данные предварительно записывались во временный файл, а затем импортировались в базу. При таком подходе 1 миллиард записей заносился в базу чуть более 1-го часа.
Тестирование производилось на одном SSD диске сразу после заполнения БД. Размер таблицы – 1 миллиард записей. На диске 42Гб было занято под таблицу и 21Гб на индекс. Узким местом является дисковая подсистема. Рассмотрим, как меняется производительность БД в зависимости от количества активных подключений.
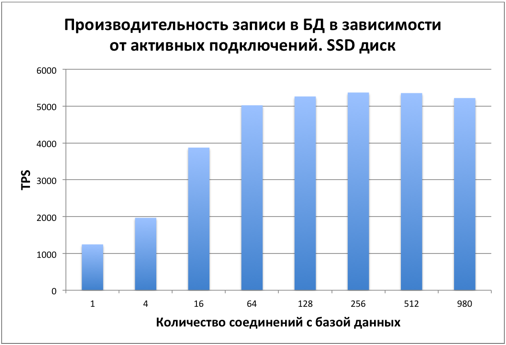
Производительность SELECT
Сначала производительность растет равномерно в зависимости от количества подключений. Начиная примерно с 16 подключений общая производительность стабилизируется, упираясь в диск.
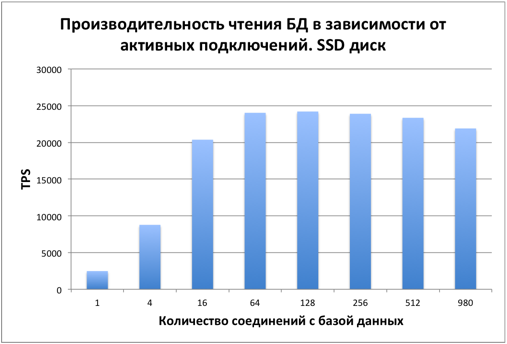
Производительность UPDATE
При обновлении записей картина аналогичная. С 16 пользователей производительность стабилизируется. Узкое место – диск.
PostgreSQL использует MVCC для обеспечения ACID. Этим в частности объясняется, что при изменении значения одного столбца во всей таблице размер этой таблицы изменяется примерно в 2 раза.
После обновления многих записей в таблице и индексах стало много dead-записей, что влияет на производительность. Рассмотрим, как это повлияло на производительность чтения.
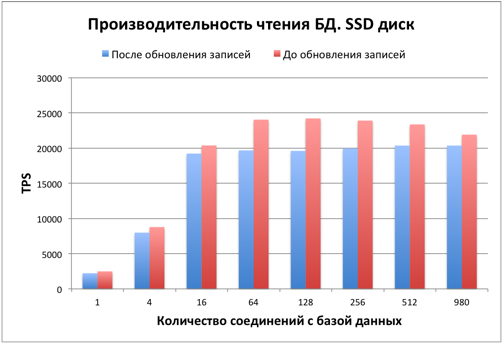
Как видим производительность чтения упала на 15-20%. Также база незначительно увеличилась в размерах. Для увеличения производительности и освобождения занятого места требуется выполнение команды VACUUM. Данный вопрос выходит за рамки статьи, более подробно о нем можно почитать в документации.
После проведения всех тестов и остановки PostgreSQL мы решили повторить тест на скорость чтения с диска.
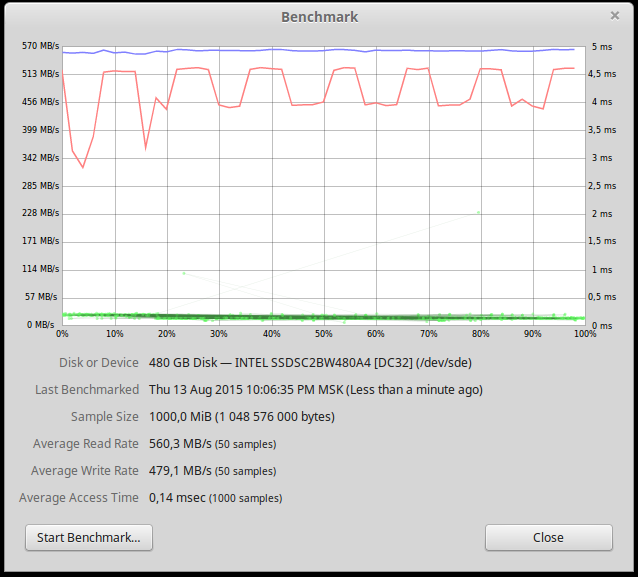
Как видим, производительность записи на диск упала. Данный график стабильно воспроизводился при различных размерах считываемых данных. Объяснений этому у нас нет. Будем рады, если кто-то объяснит причины падения скорости.
Резюме
Из данных тестов видно, что база данных хорошо работает на SSD диске при количестве записей в таблице до 1-го миллиарда.
Приятным результатом стало то, что производительность базы данных практически не уменьшилась даже при 980 активных подключениях. Скорее всего много активных подключений будут потреблять больше оперативной памяти и процессора, узким местом при количестве соединений менее тысячи является дисковая подсистема, но это тема отдельной статьи.
В следующей статье будет тестирование производительности базы данных на SSD RAID-0 массиве и размер таблицы будет увеличен до 10-ти миллиардов записей.
Ну, а наиболее выгодный тариф подскажет приложение Dr. Tariff на Android и на iOS.
Dr. Tariff посчитал у какого сотового оператора больше 4G интернета (часть 1)
Осторожно! Скрытые доходы операторов — следите за опциями «Вам звонили!», «Кто звонил+», «Будь в курсе+» (теперь платные)
История о том, как мобильный оператор списал деньги с разработчика Dr. Tariff (захватите попкорн)
Dr. Tariff 2.0: новые возможности для абонентов Билайн, МегаФон и МТС
Решили сменить оператора? Не забудьте подобрать выгодный тариф с помощью Dr. Tariff
Dr. Tariff (3 месяца спустя) — подобрать тариф можно в 80 регионах России на Android и iOS
Dr. Tariff (тарифы и баланс): Как я стал помогать людям экономить на мобильных затратах
Подписывайтесь на наши новости и делитесь информацией с друзьями в Вконтакте и Facebook.
Комментарии (15)

amarao
24.08.2015 23:40+3Условия теста совершенно не описаны. Какие значения writeback/readahead на устройствах? Какая глубина очереди? Какой линуксовый менеджер очереди — noop, deadline, cfq? На каком из дисков хранится bitmap рейда (обновление которого отдельный набор операций, влияющий на производительность). Какой контроллер? Где синтетические тесты устройства в отсутствие БД для идентификации узких мест? Где информация об утилизации дисков и CPU во время нагрузочного тестирования?
Вижу шаманство «и потыкались чуть-чуть».
Вы хотя бы проверили, что рейд в параллель не занимался consistency checking?
DrTariff
25.08.2015 00:46Это первая часть статьи, тестирование на рейд массиве будет в следующей статье. Менеджер I/O — deadline. Загрузка процессора во время тестов составляла 30-50% с учетом того, что клиент запускался на этой же машине. За время указанного в статье теста процессор не становился узким местом.
amarao
25.08.2015 02:50+2А что становилось узким местом? Вы даже близко не показали чем вы мониторили утилизацию во время теста. С учётом что у вас все графики со странным графическим менеджером, то у меня даже возникает вопрос: а вы на происходящее на хосте вообще смотрели-то?
Ну там хотя бы что-то примитивное, вида atop'а, не говоря уже про более точные замеры io flight time.
Какая нагрузка доходила до SSD? Сколько IOPS, какая средняя глубина очереди, какой размер блока? Хотя бы сравнение поведения СУБД на одной SSD против двух.
То есть «посмотреть для себя» как оно работает — да, отлично, можно эти цифры использовать для прикидки конфигурации.
Для презентации результатов на публику — слишком много «я запустил крайсис и он не тормозит, значит моё водное охлаждение офигенное»DrTariff
25.08.2015 11:43Утилизация дисков мониторилась через iostat. В дальнейшем учтем замечание и будем давать более подробное описание инструментов с помощью которых производился мониторинг.
iops на диск был в районе 10-20к. Размер блока стандартный — 512k.
Сравнение производительности на одном SSD и RAID будет в ближайшее время следующей статье.amarao
25.08.2015 14:35Как вы сумели узнать «стандартный размер блока», да ещё так ровно кратно 512? Вы не путаете с размером страйпа рейда?
DrTariff
25.08.2015 14:57Действительно имел в виду размер страйпа. Размер взят из /proc/mdstat
amarao
25.08.2015 17:33А я говорил про средний размер блока, который писался на диск во время теста.
DrTariff
25.08.2015 22:20PostgreSQL был инициализирован с размером блока по умолчанию — 8кб. Согласно другим тестам postgres на SSD при изменении размера блока производительность не сильно изменяется, поэтому в завивимости от этого параметра тестирование не производилось.
amarao
26.08.2015 15:27Но блок postgres не определяет средний размер блока IO (если только вы noop в дисковом скедулере не включили). BIO могут объединяться для уменьшения числа операций.
DrTariff
26.08.2015 17:16При тестировании основной задачей было измерение производительности базы данных, определение узких мест, влияние настроек постгриса, сравнение различных конфигураций железа SSD/RAID-0 SSD/HDD.
Измерение «размера блока, который писался на диск» не было целью тестирования. Будем благодарны, если подскажите способы переконфигурирования системы для повышения производительности.amarao
26.08.2015 18:36Чтобы повысить производительность надо найти то, во что упирается система. Вы же не смотрели на утилизацию системы во время тестов. Из очевидного — попробовать поиграть с размером readahead'а, разными типами дисковых скедулеров (может быть noop будет быстрее), попробовать вынести метаданные рейда с массива.
Но ключевое — нужно найти «чего не хватает» чтобы получить более высокую производительность.

igordata
25.08.2015 00:36+1А разве в ОС или в PostgreSQL нет кеширования файловых операций? Как вы выяснили, что всё именно в диск упирается? Какая была загрузка процессора? А пропускная способность оперативки не может быть узким местом?
Не в смысле, что я дико сомневаюсь. Я просто не понимаю, из чего это следует. Я вижу, что операции упираются в потолок, но из чего это следует?
DrTariff
25.08.2015 00:52И ОС и PostgreSQL имеют кеширование, просто размер базы и характер нагрузки таковы, что для большей части запросов требуемого блока не оказывается в кеше и его нужно считать с диска.
В данном тесте диск точно является узким местом — утилизация по iostat составляла 95-100%. Загрузка процессора с учетом клиента составляла 30-50%.
MikeGav
Странно, меня одного это не удивило, наверно начитался всяких обзоров
На самом деле причин много:
Кто-то пишет:
Еще это могут объяснять логикой работы контроллера
DrTariff
> Еще это могут объяснять логикой работы контроллера.
Понятно, что просадка в производительности зависит от логики контроллера. Непонятно от каких алгоритмов произошла характерная периодичная просадка, зависящая от адреса блока.
Падение скорости при заполнении диска действительно существует и начинается примерно при использовании 80-90% от емкости диска. В данном тесте 42гб ушло на данные и 21гб на индекс, итого было занято 63гб из доступных 440гб.