
Привет, Хабр! Представляю вашему вниманию любительский перевод статьи “Rethinking the Java DTO” Стивена Уотермана, где автор рассматривает интересный и нестандартный подход к использованию DTO в Java.
Я провел 12 недель в рамках программы подготовки выпускников Scott Logic, работая с другими выпускниками над внутренним проектом. И был момент, который застопорил меня больше других: структура и стиль написания наших DTO. Это вызывало массу споров и обсуждений на протяжении всего проекта, но в итоге я понял, что мне нравится использовать DTO.
Данный подход не является единственно верным решением, но он довольно интересный и отлично подходит для разработки с использованием современных IDE. Надеюсь, что изначальный шок пройдет и вам он тоже понравится.
Что такое DTO (Data Transfer Object)?
Зачастую, в клиент-серверных приложениях, данные на клиенте (слой представления) и на сервере (слой предметной области) структурируются по-разному. На стороне сервера это дает нам возможность комфортно хранить данные в базе данных или оптимизировать использование данных в угоду производительности, в то же время заниматься “user-friendly” отображением данных на клиенте, и, для серверной части, нужно найти способ как переводить данные из одного формата в другой. Конечно, существуют и другие архитектуры приложений, но мы остановимся на текущей в качестве упрощения. DTO-подобные объекты могут использоваться между любыми двумя слоями представления данных.
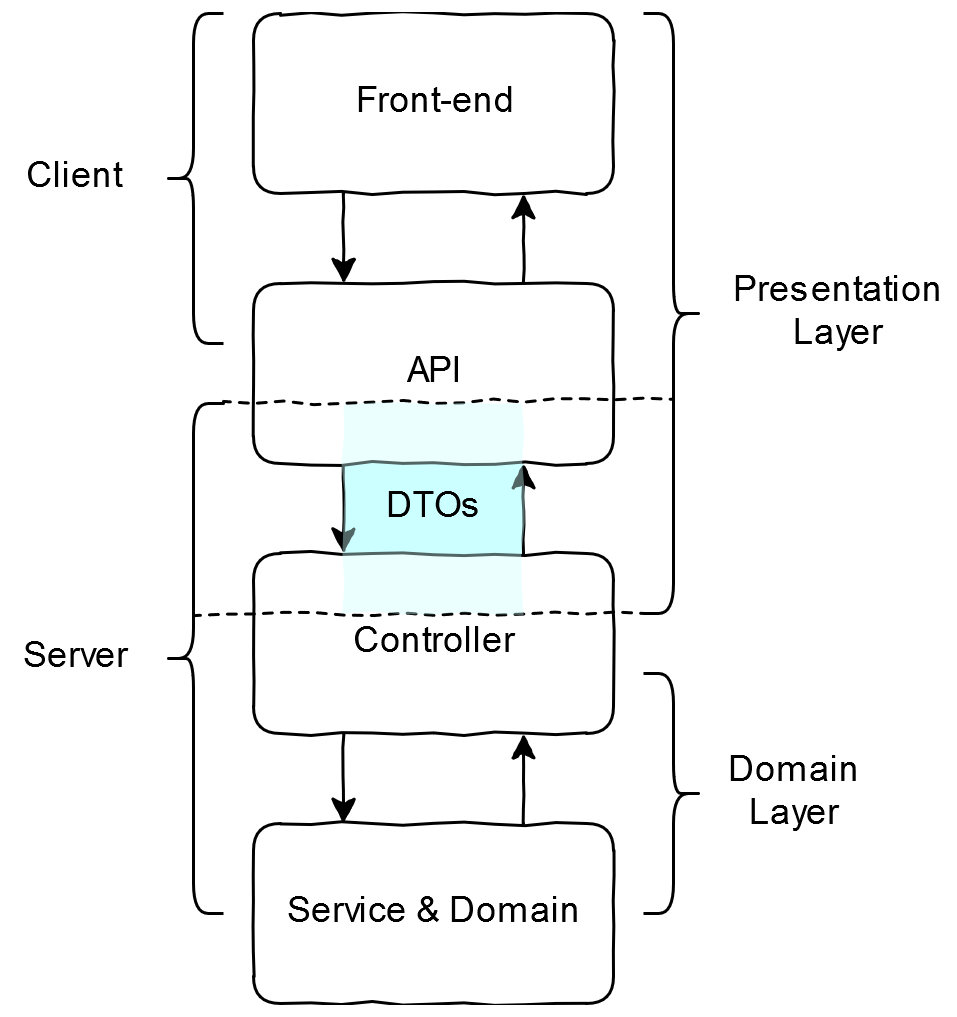
DTO — это так называемый value-object на стороне сервера, который хранит данные, используемые в слое представления. Мы разделим DTO на те, что мы используем при запросе (Request) и на те, что мы возвращаем в качестве ответа сервера (Response). В нашем случае, они автоматически сериализуются и десериализуются фреймворком Spring.
Представим, что у нас есть endpoint и DTO для запроса и ответа:
// Getters & Setters, конструкторы, валидация и документация опущены
public class CreateProductRequest {
private String name;
private Double price;
}
public class ProductResponse {
private Long id;
private String name;
private Double price;
}
@PostMapping("/products")
public ResponseEntity<ProductResponse> createProduct(
@RequestBody CreateProductRequest request
) { /*...*/ }Что делают хорошие DTO?
Во-первых, очень важно понимать, что вы не обязаны использовать DTO. Это прежде всего паттерн и ваш код может работать отлично и без него.
- Если вы используете одно представление данных на оба слоя, вы вполне можете использовать ваши сущности в качестве DTO.
- Если вы хотите вручную заниматься сериализацией ваших сущностей в JSON, то я не могу вас остановить!
Они также помогают документировать слой представления в человеко читаемом виде. Мне нравится использовать DTO и, я думаю, вы тоже могли бы их использовать, ведь это к тому же способствует уменьшению зацепления (decoupling) между слоем представления и предметным слоем, позволяя приложению быть более гибким и уменьшая сложность его дальнейшей разработки.
Тем не менее, не все DTO являются хорошими. Хорошие DTO помогают создавать API согласно лучшим практикам и в соответствии с принципам чистого кода.
Они должны позволять разработчикам писать API, которое внутренне согласовано. Описание параметра на одной из конечных точек (endpoint) должно применяться и к параметрам с тем же именем на всех связанных точках. В качестве примера, возьмём вышепредставленный фрагмент кода. Если поле price при запросе определено как “цена с НДС”, то и в ответе определение поля price не должно измениться. Согласованное API предотвращает ошибки, которые могли возникнуть из-за различий между конечными точками, и в то же время облегчает введение новых разработчиков в проект.
DTO должны быть надёжными и сводить к минимуму необходимость в написании шаблонного кода. Если при написании DTO легко допустить ошибку, то вам нужно прилагать дополнительные усилия, чтобы ваше API оставалось согласованным. DTO должны “легко читаться”, ведь даже если у нас есть хорошее описание данных из слоя представления — оно будет бесполезно, если его тяжело найти.
Давайте посмотрим на примеры DTO, а потом определим, соответствуют ли они нашим требованиям.
Покажи нам код!
Этот код на первый взгляд может показаться довольно странным, но не переживайте. В оставшейся части поста я объясню почему я остановился на данной реализации и какие преимущества она дает. Надеюсь, что вам станет всё понятно и вы оцените данный подход.
Он частично основывается на реальном коде из нашего проекта для выпускников, переведенный в контекст интернет-магазина. В нём каждый продукт имеет название, розничную и оптовую цену. Для хранения цены мы используем тип данных Double, но в реальных проектах вы должны использовать BigDecimal.
public enum ProductDTO {;
private interface Id { @Positive Long getId(); }
private interface Name { @NotBlank String getName(); }
private interface Price { @Positive Double getPrice(); }
private interface Cost { @Positive Double getCost(); }
public enum Request{;
@Value public static class Create implements Name, Price, Cost {
String name;
Double price;
Double cost;
}
}
public enum Response{;
@Value public static class Public implements Id, Name, Price {
Long id;
String name;
Double price;
}
@Value public static class Private implements Id, Name, Price, Cost {
Long id;
String name;
Double price;
Double cost;
}
}
}Мы создаем по одному файлу для каждого контроллера, который содержит базовый enum без значений, в нашем случае это ProductDTO. Внутри него, мы разделяем DTO на те, что относятся к запросам (Request) и на те, что относятся к ответу (Response). На каждый endpoint мы создаем по Request DTO и столько Response DTO сколько нам необходимо. В нашем случае у нас два Response DTO, где Public хранит данные для любого пользователя и Private который дополнительно содержит оптовую цену продукта.
Для каждого параметра мы создаем отдельный интерфейс с таким же именем. Каждый интерфейс содержит один единственный метод — геттер для параметра, который он определяет. Любая валидация осуществляется через метод интерфейса. В нашем примере, аннотация @NotBlank проверяет что название продукта в DTO не содержит пустую строку.
Для каждого поля который входит в DTO мы реализовываем соответствующий интерфейс. В нашем случае аннотация @Value из библиотеки Lombok делает это за нас, автоматически генерируя геттеры.
Для полного сравнения, с использованием документации, вы можете посмотреть на примеры до и после. Также необходимо понимать, что это небольшие примеры и разница становится более наглядной как только вы начнете добавлять больше DTO.
“Это ужасно!”
Это на самом деле выглядит странно и здесь много необычных моментов. Давайте обсудим несколько из них подробнее.
Три enum и ни один из них не имеет значений! На самом деле мы используем небольшую хитрость для создания namespace-а, т.е. мы можем обращаться к DTO как ProductDTO.Request.Create. Данный “трюк” возможен благодаря тому, что мы ставим ; после каждого enum. Точка с запятой указывает на конец (пустого) списка значений! Использование таких namespace-ов ускоряет поиск нужного DTO, а также можно воспользоваться подсказками в IDE для получения полного списка. Есть и другие возможности добиться того же эффекта, но текущий подход выглядит лаконично, ведь нам не нужно будет использовать конструкции вроде new ProductDTO() и new Create(). Честно говоря, это моё личное предпочтение и вы можете организовать классы как вам угодно.
Мы используем слишком много интерфейсов — по одному на каждый параметр! Мы делаем это потому что считаем данные интерфейсы единственным источником описательной информации относительно параметра который он определяет. Далее мы поговорим об этом чуть больше, но поверьте мне, это принесет свои плоды.
Мы не реализовали методы интерфейсов. Да, выглядит немного странно и я хотел бы найти решение получше. Сейчас мы используем автогенерацию геттеров при помощи Lombok для закрытия контракта и это небольшой хак. Выглядело бы лучше, если бы мы могли объявлять поля сразу в интерфейсе, что позволяло бы создавать DTO в одной строчке кода. Однако, в java нет возможности интерфейсам иметь не статические поля. Если вы будете использовать этот подход в других языках, то возможно ваш код будет более лаконичным.
Это (почти) идеально
Давайте вернемся к нашим требованиям к созданию хорошего DTO. Соотвествует ли им наш подход?
Согласованный синтаксис
Мы определенно улучшили согласованность синтаксиса и это главное почему мы могли бы начать использовать данный паттерн. Каждый API параметр теперь имеет свой синтаксис, определенный через интерфейс. Если DTO содержит опечатку в имени параметра или некорректный тип — код просто не скомпилируется и IDE выдаст вам ошибку. Для примера:
@Value public static class PatchPrice implements Id, Price {
String id; // Должен быть тип Long;
Double prise; // Опечатка в слове price
}PatchPrice is not abstract and does not override abstract method getId() in Id
PatchPrice is not abstract and does not override abstract method getPrice() in PriceК тому же, когда мы используем валидацию на уровне интерфейса, мы исключаем ситуацию, когда один и тот же параметр на одном endpoint проходит валидацию и не проходит её на другом.
Согласованная семантика
Такой стиль написания DTO улучшает понимание кода через наследование документации. Каждый параметр имеет свою семантику которая определена в геттер методах соответствующего ему интерфейса. Пример:
private interface Cost {
/**
* The amount that it costs us to purchase this product
* For the amount we sell a product for, see the {@link Price Price} parameter.
* <b>This data is confidential</b>
*/
@Positive Double getCost();
}Как только в DTO мы реализовали данный интерфейс, наша документация автоматически стала доступна через геттер.

Теперь вы гарантировано получаете актуальную и целостную документацию во всех DTO, которые реализовали данный интерфейс. В редких случаях, когда вам нужно добавить API, параметр с уже используемым наименованием и разной семантикой, вам придется создать отдельный интерфейс. Хоть это и неудобно, но заставляет разработчиков задуматься в таких ситуациях, а будущим читателям этого кода понять разницу между схожими параметрами.
Читабельность & Поддерживаемость
Будем честны: в нашем подходе достаточно много шаблонного кода. У нас есть 4 интерфейса, без которых не обойтись, и каждый DTO имеет длинную строку с перечислением интерфейсов. Мы можем вынести интерфейсы в отдельный пакет, что поможет избежать лишних “шумов” в коде c описанием DTO. Но даже после этого, бойлерплейт остается главным недостатком данного подхода, что может оказаться веской причиной для того чтобы использовать другой стиль. Для меня, эти затраты все еще стоят того.
Наш стиль проявляет себя с лучшей стороны, когда нам нужно создать новый DTO. Вы просто пишете @Value public static class [name] implements, перечисляете нужные вам интерфейсы. Далее, добавляете поля пока ваша IDE не перестанет ругаться. Готово! У вас есть DTO с валидацией и документацией.
К тому же, мы видим всю структуру наших DTO классов. Посмотрите на код и вы увидите все что вам нужно знать из сигнатуры класса. Каждое поле указано в списке реализованных интерфейсов. Достаточно нажать ctrl + q в IntelliJ и вы увидите список полей.

В нашем подходе мы пишем валидацию единоразово, т.к. она реализуется через методы интерфейса. Создали новое DTO — получили валидацию в подарок, после реализации интерфейса.
И в заключении, благодаря нашим интерфейсам, мы способны писать переиспользуемые утилитные методы. В качестве примера, рассмотрим ситуацию, когда нам нужно посчитать наценку на товар:
markup = (sale_price - cost_price) / cost_priceВ java, мы можем реализовать это используя обобщение:
public static <T extends Price & Cost> Double getMarkup(T dto){
return (dto.getPrice() - dto.getCost()) / dto.getCost();
}Входной аргумент имеет тип T, который является обобщением с пересечением типов. dto обязано реализовать оба интерфейса Price и Cost — это означает, что мы не можем использовать данный метод для Public ответа (т.к. он не реализовывает интерфейс Cost). В стандартном подходе, мы должны были бы добавить метод с двумя аргументами и перегруженные методы для каждого dto (пример). Это переносит работу на вызывающую сторону и добавляет риски возникновения ошибок.
Вывод
Я не жду, что вы сразу же пойдете переписывать все ваши DTO. Но есть несколько деталей которые вы можете почерпнуть для себя:
- Установите единственный источник информации о вашем API параметре.
- Маленькие интерфейсы лучше.
- Попробуйте быть странным, возможно, вам понравится!
P.S. Спасибо, что дочитали до конца мой первый пост на Хабре. Буду рад любой критике относительно перевода, т.к. приходилось немного отходить от оригинала из-за нехватки знаний и опыта.

surly
Не слишком ли много повторяющегося boilerplate code требует этот подход?
SlavniyTeo
А сколько шаблонного кода требует Java для описания стандартных DTO?
По мне, этот подход решает конкретные (и не надуманые) задачи. Плюс создает некоторое подобие
type aliasиз Haskell (еще один аналог — DOMAIN в SQL), что значительно (субъективно) усиливает систему типов Java.kacetal
Не так уж и много если использовать Mapstruct и Lombok. Хотя решение автора с валидацией в интерфейсе довольно элегантное.