
Вступление
Привет, Хабр!
Предыдущая часть понравилась многим, поэтому я снова перелопатил половину документации boost и нашёл о чем написать. Очень странно что вокруг boost.compute нету такого же ажиотажа как и вокруг boost.asio. Ведь достаточно, того эта библиотека кроссплатформенная, так ещё и предоставляет удобный (в рамках c++) интерфейс взаимодействия с параллельными вычислениями на GPU и CPU.
Все части
- Часть 1
- Часть 2
Содержание
- Асинхронные операции
- Пользовательские функции
- Сравнение скорости работы разных устройств в разных режимах
- Заключение
Асинхронные операции
Казалось бы, куда ещё быстрее? один из способов ускорить работу с контейнерами пространства имён compute это использование асинхронных функций. Boost.compute предоставляет нам несколько инструментов. Из них класс compute::future для контроля использования функций и функции copy_async(), fill_async() для копирования или заполнения массива. Конечно, существуют ещё и инструменты для работы с событиями, но их рассматривать нет необходимости. Дальше будет пример использования всего выше перечисленного:
auto device = compute::system::default_device();
auto context = compute::context::context(device);
auto queue = compute::command_queue(context, device);
std::vector<int> vec_std = {1, 2, 3};
compute::vector<int> vec_compute(vec_std.size(), context);
compute::vector<int> for_filling(10, context);
int num_for_fill = 255;
compute::future<void> filling = compute::fill_async(for_filling.begin(),
for_filling.end(), num_for_fill, queue); // асинхронно заполняет заданный вектор
compute::future<void> copying = compute::copy_async(vec_std.begin(),
vec_std.end(), vec_compute.begin(), queue); // асинхронно копирует следующий вектор
filling.wait();
copying.wait();
Пояснять тут особо нечего. Первые три строчки — стандартная инициализация необходимых классов, потом два векторы для копирования, вектор для заполнения, переменная которой будем заполнять предыдущий вектор и непосредственно функции для заполнения и копирования соответственно. Потом дожидаемся их выполнения.
Для тех, кто работал с std::future из STL, тут абсолютно всё тоже самое, только в другом пространстве имён и нет аналога std::async().
Пользовательские функции для вычислений
В предыдущей части я сказал, что поясню как использовать свои собственные методы для обработки массива данных. Я насчитал 3 способа как это можно сделать: использовать макрос, использовать make_function_from_source<>() и использовать специальный фреймворк для лямбда выражений.
Начну с самого первого варианта — макроса. Сначала приложу пример кода а потом поясню как работает.
BOOST_COMPUTE_FUNCTION(float,
add,
(float x, float y),
{ return x + y; });
Первым аргументом указываем тип возвращаемого значения, потом название функции, её аргументы и тело функции. Дальше под именем add, данную функцию можно использовать например в функции compute::transform(). Использование этого макроса очень похоже на обычное лямбда выражение, но я проверял, они работать не будут.
Второй и, наверное, самый сложный способ очень похож на первый. Я смотрел код предыдущего макроса и оказалось, что он использует именно второй способ.
compute::function<float(float)> add = compute::make_function_from_source<float(float)>
("add", "float add(float x, float y) { return x + y; }");
Здесь всё очевидней чем может показаться на первый взгляд, функция make_function_from_source(), использует всего два аргумента, один из которых название функции, а второй — её реализация. После объявления функции её можно использовать так же как и после реализации макросом.
Ну и последний вариант это фреймворк для лямбда выражений. Пример использования:
compute::transform(com_vec.begin(),
com_vec.end(),
com_vec.begin(),
compute::_1 * 2,
queue);
Четвёртым аргументом мы указываем что хотим умножить каждый элемент из первого вектора на 2, всё достаточно просто и делается на месте.
Этим же способом можно указывать логические выражения. Например в методе compute::count_if():
std::vector<int> source_std = { 1, 2, 3 };
compute::vector<int> source_compute(source_std.begin() ,source_std.end(), queue);
auto counter = compute::count_if(source_compute.begin(),
source_compute.end(),
compute::lambda::_1 % 2 == 0,
queue);
Таким образом мы посчитали все чётные числа в массиве, counter будет равен единице.
Сравнение скорости работы разных устройств в разных режимах
Ну и последнее, про что я хотел бы написать в этой статье, это сравнение скорости обработки данных на разных устройствах и в разных режимах(только для CPU). это сравнение докажет, когда есть смысл использовать GPU для вычислений и параллельные вычисления в целом.
Тестировать я буду так: с помощью compute для всех устройств вызову функцию compute::sort() для того чтоб отсортировать массив из 100 млн. значений типа float. Для теста однопоточного режима вызову std::sort для массива такого же размера. Для каждого устройства засеку время в миллисекундах с помощью стандартной библиотеки chrono и выведу всё в консоль.
Получился такой результат:

Теперь сделаю всё тоже самое только для тысячи значений. На этот раз время будет в микросекундах.

На этот раз процессор в однопоточном режиме опередил всех. Из этого делаем вывод что такого рода операции стоит делать только когда речь идёт о действительно больших данных.
Хотелось бы сделать ещё несколько тестов, поэтому сделаем тест на вычисление косинуса, квадратного корня и возведения в квадрат.
В вычислении косинуса разница очень большая (GPU работает в 60 раз быстрее CPU в одном потоке).
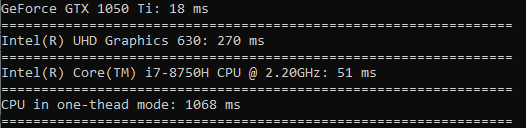
Квадратный корень считается почти с такой же скоростью как и сортировка.
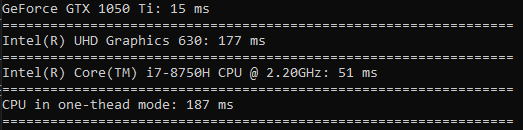
Время затраченное на возведение в квадрат имеет ещё меньше разницу чем сортировка(GPU быстрее всего в 3.5 раза).

Заключение
Итак, прочитав эту статью, вы научились использовать асинхронные функции для копирования массивов и их заполнения. Узнали какими способами можно использовать свои собственные функции для проведения вычислений над данными. А также наглядно увидели когда стоит использовать GPU или CPU для параллельных вычислений, а когда можно обойтись одним потоком.
Буду рад позитивным отзывам, спасибо за уделённое время!
Всем удачи!


da-nie
537 мс ушло? И быстрее всего в 10 раз по сути, чем CPU? Что-то слабо как-то. А если в чистой CUDA написать сортировку?
lucky_rydar Автор
Скорее всего будет быстрее, а может это только с сортировкой так. Я на CUDA ничего ещё не писал, думаю пришло время что то попробовать. Наверное стоит добавить тесты разных функций.
da-nie
Попробуйте. Там нет ничего сложного. Надо лишь поставить компилятор от nVidia с их сайта. А вот оптимальное разделение на блоки (там матрица блоков 65536x65536), потоки (моя GTX 1060 может создать 1024 штуки для блока) и варпы (32 потока) — вот тут придётся подумать об оптимальном распределении — это может сильно повлиять на быстродействие.
Вообще, неплохая книжка есть. «Технология CUDA в примерах» Сандерс и Кэндрот.
agataremedy
Главная проблема этого бенчмарка в том, что вы не учитываете время компляции кернела.
Под капотом compute::sort компилирует кернел(для первого запуска), а для последущих запусков ищет скомпилированный кернел в кэше, что также очень медленно.
lucky_rydar Автор
Не беспокойтесь, я тестировал код со второго раза. Спасибо, что подметили.
agataremedy
Так в этом как раз и главная проблема использования алгоритмов boost::compute, функций и лямбд. Поиск кернела в кеше действительно тяжелая операция. Описание проблемы и бенчмарки здесь: github.com/boostorg/compute/issues/768 За два с половиной года ничего не изменилось.
Если действительно нужна производительность, то нужно использовать чистый opencl/ дефолтный opencl wrapper или только ограниченое подмножество boost::compute, но и тут есть проблемы.
Возьмем пример из начала статьи с асинхнронными операциями. К сожалению полной асинхронности тут нет, так как сначала выполнняется операция заполнения вектора, и только после завершения первой задачи выполняется копирование второго вектора. Эти две задачи не связаны между собой и могут быть выполнены параллельно. Для этого в opencl реализованы «out of order execution» очереди. Но в релизе boost compute эта функциональность нормально не поддерживается(хотя и исправлено в develop бранче на гитхабе пару лет назад).
Для прода boost compute бесполезен, так как медленный и не развивается.
P.S. Еще одна возможная причина такой маленькой разницы времени выполнения бенчмарка между cpu и gpu может быть в размере векторов. Из описания не ясно были ли вектора кратны 64(32/16 в зависимости от видяхи, можно проверить через clinfo). Это действительно значительно ускоряет время выполнения алгоритма, потому что кэш-фрэндли.
lucky_rydar Автор
Добавил больше тестов, возможно дело в том что ЦПУ не такой уж и слабый.
da-nie
Вряд ли. У меня с CUDA свёртки ускоряются в несколько сотен раз.
maaGames
Достаточно мощный CPU и очень слабый GPU. И то разница есть в пользу GPU.
Но объёмы вычислений всё-равно микроскопические в тестах, ещё и последовательно вычисления идут (идеально в плане кэширования). Хотелось бы что-нибудь типа умножения матриц размером 10К*10К. Там уже «в лоб» будут проблемы с кэшированием и процессор гарантированно начнёт страдать, а вот поведение GPU было бы интересно. Ну и с double проблемы возникнут уже на GPU (от NVidia), а особенно интересно именно вычисление даблами…
Мне интересно. Но я пока только с силами собираюсь, чтобы за изучение OpenCL взяться.
В любом случае, спасибо за статью. Не хватает исходников.
da-nie
А какие там с double проблемы? Оно давно ведь поддерживается.
maaGames
NVidia хочет деняк, поэтому на игровых GPU порезали скорость вычислений double. Хочешь считать double — покупай Quadro или как там у них про-карточки называются и внешние девайсы специальные.
da-nie
А где такое написано? Сходу пока не нашёл.
maaGames
В интернете… Я пока изучаю вопрос, личного опыта нет. Пишут, что float до 32 раз быстрее считает, в зависимости от размеров данных. Причём на TESLA (вспомнил название) разница в скорости не столь большая.
Так то очевидно, что double вдвое больше нагружает шину и, если объёмы огромные, то будет заметная разница в скорсоти из-за бОльших издержек. Потому я и пишу, что интересно сравнение именно на больших объёмах данных, а не на игрушечных массивах в 100 тыссяч элементов.
lucky_rydar Автор
Я пробовал, что будет с double, во всех тестах как CPU так и GPU в параллеле считают его в два раза дольше чем float
da-nie
Мне вот тоже такое помнится в CUDA. Откуда взялось в 32 раза замедление не знаю.
Может, кто-то неправильно потоки по блокам раскидал и получил тормоза?