
Два года назад я писал на Хабр статью про Yargy-парсер и библиотеку Natasha, рассказывал про решение задачи NER для русского языка, построенное на правилах. Проект хорошо приняли. Yargy-парсер заменил яндексовый Томита-парсер в крупных проектах внутри Сбера, Интерфакса и РИА Новостей. Библиотека Natasha сейчас встроена в образовательные программы ВШЭ, МФТИ и МГУ.
Проект подрос, библиотека теперь решает все базовые задачи обработки естественного русского языка: сегментация на токены и предложения, морфологический и синтаксический анализ, лемматизация, извлечение именованных сущностей.

Для новостных статей качество на всех задачах сравнимо или превосходит существующие решения. Например с задачей NER Natasha справляется на 1 процентный пункт хуже, чем Deeppavlov BERT NER (F1 PER 0.97, LOC 0.91, ORG 0.85), модель весит в 75 раз меньше (27МБ), работает на CPU в 2 раза быстрее (25 статей/сек), чем BERT NER на GPU.
В проекте 9 репозиториев, библиотека Natasha объединяет их под одним интерфейсом. В статье поговорим про новые инструменты, сравним их с существующими решениями: Deeppavlov, SpaCy, UDPipe.

Содержание:

Раньше библиотека Natasha решала задачу NER для русского языка, была построена на правилах, показывала среднее качество и производительность. Сейчас Natasha — это целый большой проект, состоит из 9 репозиториев. Библиотека Natasha объединяет их под одним интерфейсом, решает базовые задачи обработки естественного русского языка: сегментация на токены и предложения, предобученные эмбеддинги, анализ морфологии и синтаксиса, лемматизация, NER. Все решения показывают топовые результаты в новостной тематике, быстро работают на CPU.
Natasha похожа на другие библиотеки-комбайны: SpaCy, UDPipe, Stanza. SpaCy инициализирует и вызывает модели неявно, пользователь передаёт текст в магическую функцию
Интерфейс Natasha более многословный. Пользователь явно инициализирует компоненты: загружает предобученные эмбеддинги, передаёт их в конструкторы моделей. Сам вызывает методы
Модуль извлечения именованных сущностей не зависит от результатов морфологического и синтаксического разбора, его можно использовать отдельно.
Natasha решает задачу лемматизации, использует Pymorphy2 и результаты морфологического разбора.
Чтобы привести словосочетание к нормальной форме, недостаточно найти леммы отдельных слов, для «МИД России» получится «МИД Россия», для «Организации украинских националистов» — «Организация украинский националист». Natasha использует результаты синтаксического разбора, учитывает связи между словами, нормализует именованные сущности.
Natasha находит в тексте имена, названия организаций и топонимов. Для имён в библиотеке есть набор готовых правил для Yargy-парсера, модуль делит нормированные имена на части, из «Виктор Федорович Ющенко» получается
В библиотеке собраны правила для разбора дат, сумм денег и адресов, они описаны в документации и справочнике.
Библиотека Natasha хорошо подходит для демонстрации технологий проекта, используется в образовании. Архивы с весами моделей встроены в пакет, после установки не нужно ничего скачивать и настраивать.
Natasha объединяет под одним интерфейсом другие библиотеки проекта. Для решения практических задач стоит использовать их напрямую:

Библиотека Razdel — часть проекта Natasha, делит русскоязычный текст на токены и предложения. Инструкция по установке, пример использования и замеры производительности в репозитории Razdel.
Современные модели часто не заморачиваются на счёт сегментации, используют BPE, показывают замечательные результаты, вспомним все версии GPT и зоопарк BERTов. Natasha решает задачи разбора морфологии и синтаксиса, они имеют смысл только для отдельных слов внутри одного предложения. Поэтому мы ответственно подходим к этапу сегментации, стараемся повторить разметку из популярных открытых датасетов: SynTagRus, OpenCorpora, GICRYA.
Скорость и качество Razdel сопоставимы или выше, чем у других открытых решений для русского языка.
Число ошибок среднее по 4 датасетам: SynTagRus, OpenCorpora, GICRYA and RNC. Подробнее в репозитории Razdel.
Зачем вообще нужен Razdel, если похожее качество даёт baseline с регулярочкой и для русского языка есть куча готовых решений? На самом деле, Razdel это не просто токенизатор, а небольшой сегментационный движок на правилах. Сегментация базовая задача, часто встречается на практике. Например, есть судебный акт, нужно выделить в нём резолютивную часть и поделить её на параграфы. Естественно, готовые решения так не умеют. Как писать свои правила читайте в исходниках. Дальше речь о том, как упороться и сделать на нашем движке топовое решение для токенов и предложений.
В русском языке предложения обычно заканчиваются точкой, вопросительным или восклицательным знаком. Просто разделим текст регулярным выражением
Cокращения
… любая площадка с аудиторией от 3 тыс.-человек является блогером.
… над ними с конца XVII в.-стоял бей;
… в Камерном музыкальном театре им.-Б.А. Покровского.
Инициалы
В след за операми «Идоменей» В.А.-Моцарта – Р.-Штрауса …
Списки
2.-думал будет в финское консульство красивая длинная очередь …
г.-билеты на поезда российских железных дорог …
В конце предложения смайлик или типографское многоточие
Кто предложит способ избавления от минусов — тому спасибо :)-Посмотрел, призадумался…-Вот это уже более неприятно, поскольку содержательность нарушится.
Цитаты, прямая речь, в конце предложения кавычка
— невесты у вас в городе есть?»-«Кому и кобыла невеста».
«Как хорошо, что я не такой!»-Сейчас при переводе сделал фрейдстскую ошибку:«идология».
Razdel учитывает эти нюансы, сокращает число ошибок c 76 до 43 на 1000 предложений.
С токенами аналогичная ситуация. Хорошее базовое решение даёт регулярное выражение
Дробные числа, сложная пунктуация
… В конце 1980--х — начале 1990--х
… БС--3 можно отметить слегка меньшую массу (3-,-6 т)
— да и умерла.-.-. Понял ли девку, сокол?-!
Razdel сокращает число ошибок до 7 на 1000 токенов.
Система построена на правилах. Принцип сегментации на токены и предложения одинаковый.
Находим в тексте всех кандидатов на конец предложения: точки, многоточия, скобки, кавычки.
6.-Наиболее частый и при этом высоко оцененный вариант ответов «я рада»-(13 высказываний, 25 баллов)-– ситуации получения одобрения и поощрения.-7.-Примечательно, что в ответе «я знаю»-оценен как максимально стереотипный, но лишь раз встречается ответ «я женщина»-;-присутствуют высказывания «один брак – это всё, что меня ждет в этой жизни»-и «рано или поздно придется рожать»-.-Составители: В.-П.-Головин, Ф.-В.-Заничев, А.-Л.-Расторгуев, Р.-В.-Савко, И.-И.-Тучков.
Для токенов дробим текст на атомы. Внутри атома точно не проходит граница токена.
В-конце-1980---х---начале-1990---х-
БС---3-можно-отметить-слегка-меньшую-массу-(-3-,-6-т-)-
-—-да-и-умерла-.-.-.-Понял-ли-девку-,-сокол-?-!
Последовательно обходим кандидатов на разделение, убираем лишние. Используем список эвристик.
Элемент списка. Разделитель — точка или скобка, слева число или буква
6.-Наиболее частый и при этом высоко оцененный вариант ответов «я рада» (13 высказываний, 25 баллов) – ситуации получения одобрения и поощрения. 7.-Примечательно, что в ответе «я знаю» …
Инициалы. Разделитель — точка, слева одна заглавная буква
… Составители: В.-П.-Головин, Ф.-В.-Заничев, А.-Л.-Расторгуев, Р.-В.-Савко, И.-И.-Тучков.
Справа от разделителя нет пробела
… но лишь раз встречается ответ «я женщина»-; присутствуют высказывания «один брак – это всё, что меня ждет в этой жизни» и «рано или поздно придется рожать»-.
Перед закрывающей кавычкой или скобкой нет знака конца предложения, это не цитата и не прямая речь
6. Наиболее частый и при этом высоко оцененный вариант ответов «я рада»-(13 высказываний, 25 баллов)-– ситуации получения одобрения и поощрения. … «один брак – это всё, что меня ждет в этой жизни»-и «рано или поздно придется рожать».
В результате остаётся два разделителя, считаем их концами предложений.
6. Наиболее частый и при этом высоко оцененный вариант ответов «я рада» (13 высказываний, 25 баллов) – ситуации получения одобрения и поощрения.-7. Примечательно, что в ответе «я знаю» оценен как максимально стереотипный, но лишь раз встречается ответ «я женщина»; присутствуют высказывания «один брак – это всё, что меня ждет в этой жизни» и «рано или поздно придется рожать».-Составители: В. П. Головин, Ф. В. Заничев, А. Л. Расторгуев, Р. В. Савко, И. И. Тучков.
Для токенов процедура аналогичная, правила другие.
Дробь или рациональное число
… (3-,-6 т) …
Сложная пунктуация
— да и умерла.-.-. Понял ли девку, сокол?-!
Вокруг дефиса нет пробелов, это не начало прямой речи
В конце 1980---х — начале 1990---х
БС---3 можно отметить …
Всё что осталось считаем границами токенов.
В-конце-1980-х---начале-1990-х-
БС-3-можно-отметить-слегка-меньшую-массу-(-3,6-т-)-
-—-да-и-умерла-...-Понял-ли-девку-,-сокол-?!
Правила в Razdel оптимизированы для аккуратно написанных текстов с правильной пунктуацией. Решение хорошо работает с новостными статьями, художественными текстами. На постах из социальных сетей, расшифровках телефонных разговоров качество ниже. Если между предложениями нет пробела или в конце нет точки или предложение начинается с маленькой буквы, Razdel сделает ошибку.
Как писать правила под свои задачи читайте в исходниках, в документации эта тема пока не раскрыта.

В проекте Natasha Slovnet занимается обучением и инференсом современных моделей для русскоязычного NLP. В библиотеке собраны качественные компактные модели для извлечения именованных сущностей, разбора морфологии и синтаксиса. Качество на всех задачах сравнимо или превосходит другие отрытые решения для русского языка на текстах новостной тематики. Инструкция по установке, примеры использования — в репозитории Slovnet. Подробно разберёмся, как устроено решение для задачи NER, для морфологии и синтаксиса всё по аналогии.
В конце 2018 года после статьи от Google про BERT в англоязычном NLP случился большой прогресс. В 2019 ребята из проекта DeepPavlov адаптировали мультиязычный BERT для русского, появился RuBERT. Поверх обучили CRF-голову, получился DeepPavlov BERT NER — SOTA для русского языка. У модели великолепное качество, в 2 раза меньше ошибок, чем у ближайшего преследователя DeepPavlov NER, но размер и производительность пугают: 6ГБ — потребление GPU RAM, 2ГБ — размер модели, 13 статей в секунду — производительность на хорошей GPU.
В 2020 году в проекте Natasha нам удалось вплотную приблизится по качеству к DeepPavlov BERT NER, размер модели получился в 75 раз меньше (27МБ), потребление памяти в 30 раз меньше (205МБ), скорость в 2 раза больше на CPU (25 статей в секунду).
Качество Slovnet NER на 1 процентный пункт ниже, чем у SOTA DeepPavlov BERT NER, размер модели в 75 раз меньше, потребление памяти в 30 раз меньше, скорость в 2 раза больше на CPU. Сравнение со SpaCy, PullEnti и другими решениями для русскоязычного NER в репозитории Slovnet.
Как получить такой результат? Короткий рецепт:
Теперь по порядку. План такой: обучим тяжёлую модель c BERT-архитектурой на небольшом вручную аннотированном датасете. Разметим ей корпус новостей, получится большой грязный синтетический тренировочный датасет. Обучим на нём компактную примитивную модель. Этот процесс называется дистилляцией: тяжёлая модель — учитель, компактная — ученик. Рассчитываем, что BERT-архитектура избыточна для задачи NER, компактная модель несильно проиграет по качеству тяжёлой.
DeepPavlov BERT NER состоит из RuBERT-энкодера и CRF-головы. Наша тяжёлая модель-учитель повторяет эту архитектуру с небольшими улучшениями.
Все бенчмарки измеряют качество NER на текстах новостей. Дообучим RuBERT на новостях. В репозитории Corus собраны ссылки на публичные русскоязычные новостные корпуса, в сумме 12 ГБ текстов. Используем техники из статьи от Facebook про RoBERTa: большие агрегированные батчи, динамическая маска, отказ от предсказания следующего предложения (NSP). RuBERT использует огромный словарь на 120 000 сабтокенов — наследие мультиязычного BERT от Google. Сократим размер до 50 000 самых частотных для новостей, покрытие уменьшится на 5%. Получим NewsRuBERT, модель предсказывает замаскированные сабтокены в новостях на 5 процентных пунктов лучше RuBERT (63% в топ-1).
Обучим NewsRuBERT-энкодер и CRF-голову на 1000 статей из Collection5. Получим Slovnet BERT NER, качество на 0.5 процентных пункта лучше, чем у DeepPavlov BERT NER, размер модели меньше в 4 раза (473МБ), работает в 3 раза быстрее (40 статей в секунду).
Сейчас, для обучения моделей с BERT-like архитектурой, принято использовать Transformers от Hugging Face. Transformers — это 100 000 строк кода на Python. Когда взорвётся loss или на инференсе мусор, тяжело разобраться, что пошло не так. Ладно, там много кода дублируется. Пускай мы тренируем RoBERTa, довольно быстро локализуем проблему до ~3000 строк кода, но это тоже немало. С современным PyTorch, библиотека Transformers не так актуальна. С
Это не прототип, код скопирован из репозитория Slovnet. Transformers полезно читать, они делают большую работу, набивают код для статей с Arxiv, часто исходники на Python понятнее, чем объяснение в научной статье.
Разметим 700 000 статей из корпуса Lenta.ru тяжёлой моделью. Получим огромный синтетический обучающий датасет. Архив доступен в репозитории Nerus проекта Natasha. Разметка очень качественная, оценки F1 по токенам: PER — 99.7%, LOC — 98.6%, ORG — 97.2%. Редкие примеры ошибок:
С выбором архитектуры тяжёлой модели-учителя проблем не возникло, вариант один — трансформеры. С компактной моделью-учеником сложнее, вариантов много. С 2013 до 2018 год с появления word2vec до статьи про BERT, человечество придумало кучу нейросетевых архитектур для решения задачи NER. У всех общая схема:
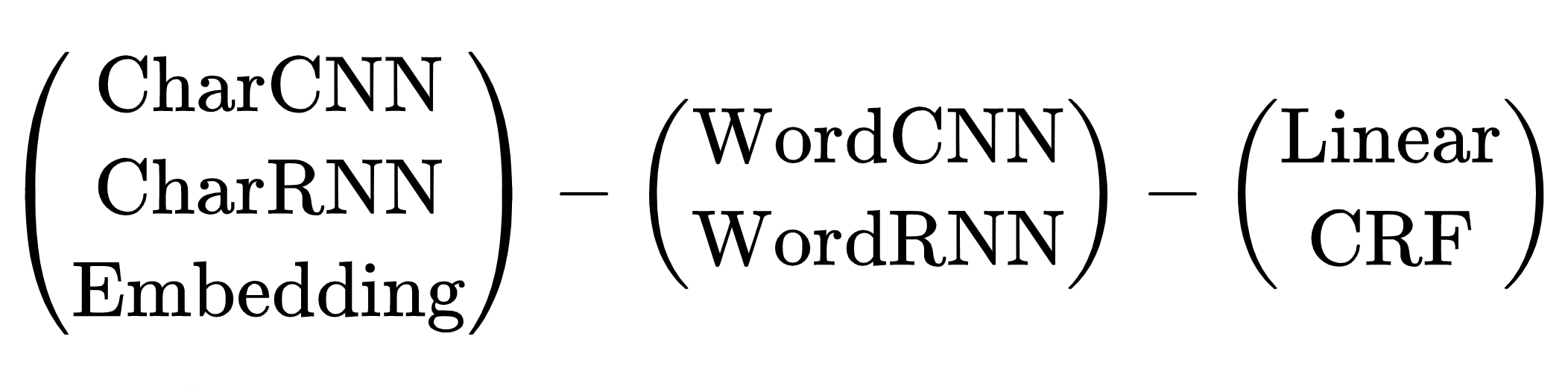
Схема нейросетевых архитектур для задачи NER: энкодер токенов, энкодер контекста, декодер тегов. Расшифровка сокращений в обзорной статье Yang (2018).
Комбинаций архитектур много. Какую выбрать? Например, (CharCNN + Embedding)-WordBiLSTM-CRF — схема модели из статьи про DeepPavlov NER, SOTA для русского языка до 2019 года.
Варианты с CharCNN, CharRNN пропускаем, запускать маленькую нейронную сеть по символам на каждом токене — не наш путь, слишком медленно. WordRNN тоже хотелось бы избежать, решение должно работать на CPU, перемножать матрицы на каждом токене медленно. Для NER выбор между Linear и CRF условный. Мы используем BIO-кодировку, порядок тегов важен. Приходится терпеть жуткие тормоза, использовать CRF. Остаётся один вариант — Embedding-WordCNN-CRF. Такая модель не учитывает регистр токенов, для NER это важно, «надежда» — просто слово, «Надежда» — возможно, имя. Добавим ShapeEmbedding — эмбеддинг с очертаниями токенов, например: «NER» — EN_XX, «Вайнович» — RU_Xx, "!" — PUNCT_!, «и» — RU_x, «5.1» — NUM, «Нью-Йорк» — RU_Xx-Xx. Схема Slovnet NER — (WordEmbedding + ShapeEmbedding)-WordCNN-CRF.
Обучим Slovnet NER на огромном синтетическом датасете. Сравним результат с тяжёлой моделью-учителем Slovnet BERT NER. Качество считаем и усредняем по размеченным вручную Collection5, Gareev, factRuEval-2016, BSNLP-2019. Размер обучающей выборки очень важен: на 250 новостных статьях (размер factRuEval-2016) средний по PER, LOC, LOG F1 — 0.64, на 1000 (аналог Collection5) — 0.81, на всём датасете — 0.91, качество Slovnet BERT NER — 0.92.
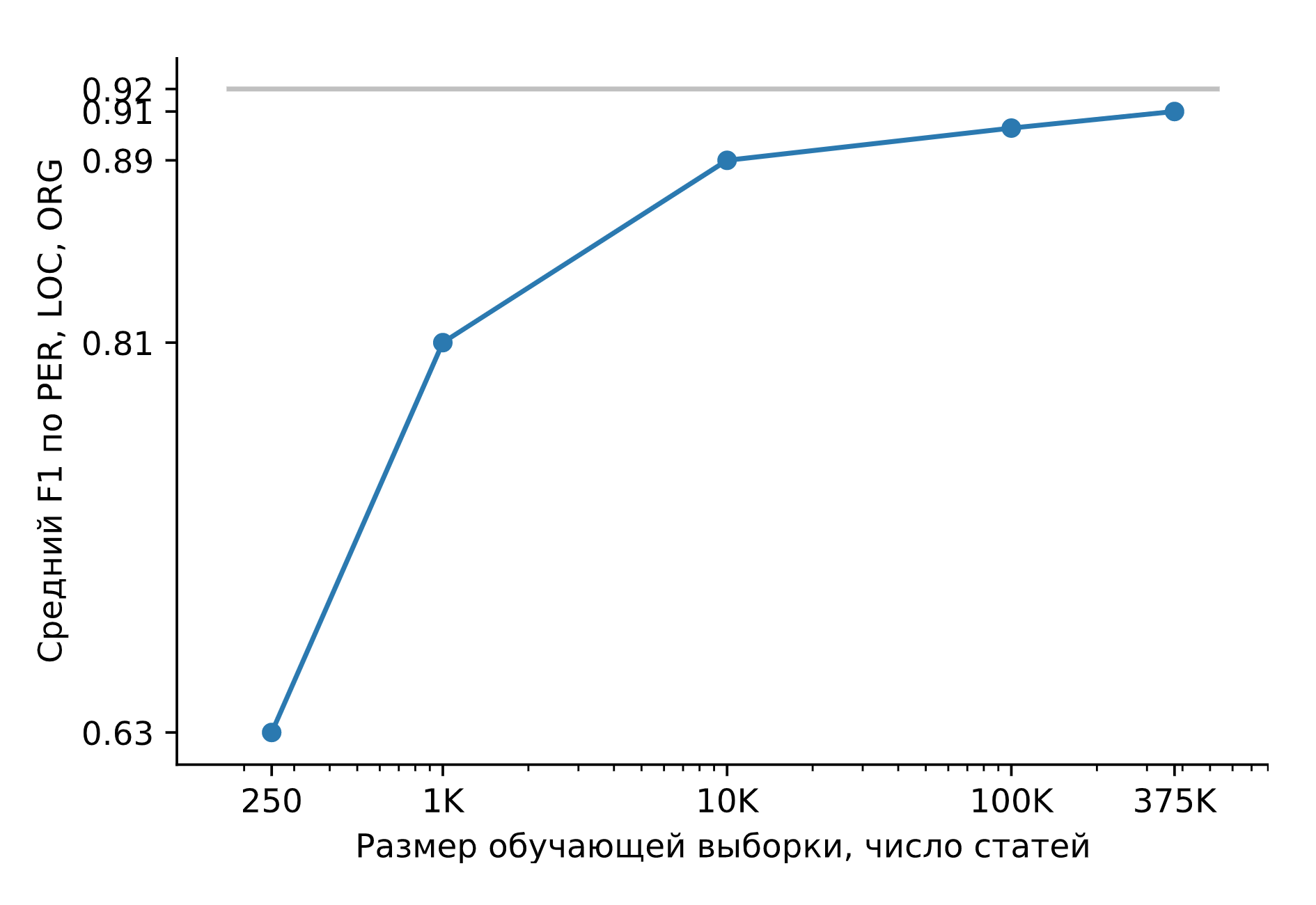
Качество Slovnet NER, зависимость от числа синтетических обучающих примеров. Серая линия — качество Slovnet BERT NER. Slovnet NER не видит размеченных вручную примеров, обучается только на синтетических данных.
Примитивная модель-ученик на 1 процентный пункт хуже тяжёлой модели-учителя. Это замечательный результат. Напрашивается универсальный рецепт:
В библиотеке Slovnet есть ещё две модели обученные по этому рецепту: Slovnet Morph — морфологический теггер, Slovnet Syntax — синтаксический парсер. Slovnet Morph отстаёт от тяжёлой модели-учителя на 2 процентных пункта, Slovnet Syntax — на 5. У обеих моделей качество и производительность выше существующих решений для русского на новостных статьях.
Размер Slovnet NER — 289МБ. 287МБ занимает таблица с эмбеддингами. Модель использует большой словарь на 250 000 строк, он покрывает 98% слов в новостных текстах. Используем квантизацию, заменим 300-мерные float-вектора на 100-мерные 8-битные. Размер модели уменьшится в 10 раз (27МБ), качество не изменится. Библиотека Navec — часть проекта Natasha, коллекция квантованных предобученных эмбеддингов. Веса обученные на художественной литературе занимают 50МБ, обходят по синтетическим оценкам все статические модели RusVectores.
Slovnet NER использует PyTorch для обучения. Пакет PyTorch весит 700МБ, не хочется тянуть его в продакшн для инференса. Ещё PyTorch не работает с интерпретатором PyPy. Slovnet используется в связке с Yargy-парсером аналогом яндексового Tomita-парсера. С PyPy Yargy работает в 2-10 раз быстрее, зависит от сложности грамматик. Не хочется терять скорость из-за зависимости от PyTorch.
Стандартное решение — использовать TorchScript или сконвертировать модель в ONNX, инференс делать в ONNXRuntime. Slovnet NER использует нестандартные блоки: квантованные эмбеддинги, CRF-декодер. TorchScript и ONNXRuntime не поддерживают PyPy.
Slovnet NER — простая модель, вручную реализуем все блоки на NumPy, используем веса, посчитанные PyTorch. Применим немного NumPy-магии, аккуратно реализуем блок CNN, CRF-декодер, распаковка квантованного эмбеддинга занимает 5 строк. Скорость инференса на CPU такая же как с ONNXRuntime и PyTorch, 25 новостных статей в секунду на Core i5.
Техника работает на более сложных моделях: Slovnet Morph и Slovnet Syntax тоже реализованы на NumPy. Slovnet NER, Morph и Syntax используют общую таблицу эмбеддингов. Вынесем веса в отдельный файл, таблица не дублируется в памяти и на диске:
Natasha извлекает стандартные сущности: имена, названия топонимов и организаций. Решение показывает хорошее качество на новостях. Как работать с другими сущностями и типами текстов? Нужно обучить новую модель. Сделать это непросто. За компактный размер и скорость работы мы платим сложностью подготовки модели. Скрипт-ноутбук для подготовки тяжёлой модели учителя, скрипт-ноутбук для модели-ученика, инструкции по подготовке квантованных эмбеддингов.

С компактными моделями удобно работать. Они быстро запускаются, используют мало памяти, на один инстанст помещается больше параллельных процессов.
В NLP 80-90% весов модели приходится на таблицу с эмбеддингами. Библиотека Navec — часть проекта Natasha, коллекция предобученных эмбеддингов для русского языка. По intrinsic-метрикам качества они чуть-чуть не дотягивают по топовых решений RusVectores, зато размер архива с весами в 5-6 раз меньше (51МБ), словарь в 2-3 раза больше (500К слов).
* Качество на задаче определения семантической близости. Усреднённая оценка по шести датасетам: SimLex965, LRWC, HJ, RT, AE, AE2
Речь пойдёт про старые добрые пословные эмбеддинги, совершившие революцию в NLP в 2013 году. Технология актуальна до сих пор. В проекте Natasha модели для разбора морфологии, синтаксиса и извлечения именованных сущностей работают на пословных Navec-эмбеддингах, показывают качество выше других открытых решений.
Для русского языка принято использовать предобученные эмбеддинги от RusVectores, у них есть неприятная особенность: в таблице записаны не слова, а пары «слово_POS-тег». Идея хорошая, для пары «печь_VERB» ожидаем вектор, похожий на «готовить_VERB», «варить_VERB», а для «печь_NOUN» — «изба_NOUN», «топка_NOUN».
На практике использовать такие эмбеддинги неудобно. Недостаточно разделить текст на токены, для каждого нужно как-то определить POS-тег. Таблица эмбеддингов разбухает. Вместо одного слова «стать», мы храним 6: 2 разумных «стать_VERB», «стать_NOUN» и 4 странных «стать_ADV», «стать_PROPN», «стать_NUM», «стать_ADJ». В таблице на 250 000 записей 195 000 уникальных слов.
Оценим качество эмбеддингов на задаче семантической близости. Возьмём пару слов, для каждого найдём вектор-эмбеддинг, посчитаем косинусное сходство. Navec для похожих слов «чашка» и «кувшин» возвращет 0.49, для «фрукт» и «печь» — ?0.0047. Соберём много пар с эталонными метками похожести, посчитаем корреляцию Спирмена с нашими ответами.
Авторы RusVectores используют небольшой аккуратно проверенный и исправленный тестовый список пар SimLex965. Добавим свежий яндексовый LRWC и датасеты из проекта RUSSE: HJ, RT, AE, AE2:
Таблица с разбивкой по датасетам в репозитории Navec.
Качество
Почему не word2vec? Эксперименты на большом датасете быстрее с GloVe. Один раз считаем матрицу коллокаций, по ней готовим эмбеддинги разных размерностей, выбираем оптимальный вариант.
Почему не fastText? В проекте Natasha мы работаем с текстами новостей. В них мало опечаток, проблему OOV-токенов решает большой словарь. 250 000 строк в таблице
Размер словаря
Заменим 32-битные float-числа на 8-битные коды: [??, ?0.86) — код 0, [?0.86, -0.79) — код 1, [-0.79, -0.74) — 2, …, [0.86, ?) — 255. Размер таблицы уменьшится в 4 раз (143МБ).
Данные огрубляются, разные значения -0.005 и -0.003 заменяет один код 127, -0.030 и -0.031 — 118
Заменим кодом не одно, а 3 числа. Кластеризуем все тройки чисел из таблицы эмбеддингов алгоритмом k-means на 256 кластеров, вместо каждой тройки будем хранить код от 0 до 255. Таблица уменьшится ещё в 3 раза (48МБ). Navec использует библиотеку PQk-means, она разбивает матрицу на 100 колонок, каждую кластеризует отдельно, качество на синтетических тестах падёт на 1 процентный пункт. Понятно про квантизацию в статье Product Quantizers for k-NN.
Квантованные эмбеддинги проигрывают обычным по скорости. Сжатый вектор перед использованием нужно распаковать. Аккуратно реализуем процедуру, применим Numpy-магию, в PyTorch используем torch.gather. В Slovnet NER доступ к таблице эмбеддингов занимает 0.1% от общего времени вычислений.
Модуль

В проекте Natasha анализ морфологии, синтаксиса и извлечение именованных сущностей делают 3 компактные модели: Slovnet NER, Slovnet Morph и Slovnet Syntax. Качество решений на 1–5 процентных пунктов хуже, чем у тяжёлых аналогов c BERT-архитектурой, размер в 50-75 раз меньше, скорость на CPU в 2 раза больше. Модели обучены на огромном синтетическом датасете Nerus, в архиве 700 000 новостных статей с CoNLL-U-разметкой морфологии, синтаксиса и именованных сущностей:
Slovnet NER, Morph, Syntax — примитивные модели. Когда в обучающей выборке 1000 примеров, Slovnet NER отстаёт от тяжёлого BERT-аналога на 11 процентных пунктов, когда примеров 10 000 — на 3 пункта, когда 500 000 — на 1.
Nerus — результат работы, тяжёлых моделей с BERT-архитектурой: Slovnet BERT NER, Slovnet BERT Morph, Slovnet BERT Syntax. Обработка 700 000 новостных статей занимает 20 часов на Tesla V100. Мы экономим время других исследователей, выкладываем готовый архив в открытый доступ. В SpaCy-Ru обучают на Nerus качественные русскоязычные модели для SpaCy, готовят патч в официальный репозиторий.

У синтетической разметки высокое качество: точность определения морфологических тегов — 98%, синтаксических связей — 96%. Для NER оценки F1 по токенам: PER — 99%, LOC — 98%, ORG — 97%. Для оценки качества мы размечаем SynTagRus, Collection5 и новостной срез GramEval2020, сравниваем эталонную разметку с нашей, подробнее в репозитории Nerus. Из-за ошибок в разметке синтаксиса встречаются циклы и множественные корни, POS-теги иногда не соответствуют синтаксическим рёбрам. Полезно использовать валидатор от Universal Dependencies, пропускать такие примеры.
Python-пакет Nerus организует удобный интерфейс для загрузки и визуализации разметки:
Инструкция по установке, примеры использования, оценки качества в репозитории Nerus.

Библиотека Corus — часть проекта Natasha, коллекция ссылок на публичные русскоязычные NLP-датасеты + Python-пакет с функциями-загрузчиками. Список ссылок на источники, инструкция по установке и примеры использования в репозитории Corus.
Полезные открытые датасеты для русского языка так хорошо спрятаны, что мало людей про них знает.
Хотим обучить языковую модель на новостных статьях, нужно много текстов. Первым приходит в голову новостной срез датасета Taiga (~1ГБ). Многие знают про дамп Lenta.ru (2ГБ). Остальные источники найти сложнее. В 2019 году на Диалоге проходил конкурс про генерацию заголовков, организаторы подготовили дамп РИА Новостей за 4 года (3.7ГБ). В 2018 году Юрий Бабуров опубликовал выгрузку с 40 русскоязычных новостных ресурсов (7.5ГБ). Волонтёры из ODS делятся архивами (7ГБ), собранными для проекта про анализ новостной повестки.
В реестре Corus ссылки на эти датасеты помечены тегом «news», для всех источников есть функции-загрузчики:
Хотим обучить NER для русского языка, нужны аннотированные тексты. Первым делом вспоминаем про данные конкурса factRuEval-2016. У разметки есть недостатки: свой сложный формат, спаны сущностей пересекаются, есть неоднозначная категориям «LocOrg». Не все знают про коллекцию Named Entities 5 наследницу Persons-1000. Разметка в стандартном формате, спаны не пересекаются, красота! Остальные три источника известны только самым преданным фанатам русскоязычного NER. Напишем на почту Ринату Гарееву, приложим ссылку на его статью 2013 года, в ответ получим 250 новостных статей с помеченными именами и организациями. В 2019 году проводился конкурс BSNLP-2019 про NER для славянских языков, напишем организаторам, получим ещё 450 размеченных текстов. В проекте WiNER придумали делать полуавтоматическую разметку NER из дампов Wikipedia, большая выгрузка для русского доступна на Github.
Ссылки и функции для загрузки в реестре Corus:
Перед тем как обзавестить загрузчиком и попасть в реестр, ссылки на источники копятся в разделе с Тикетами. В коллекции 30 датасетов: новая версия Taiga, 568ГБ русского текста из Common Crawl, отзывы c Banki.ru и Auto.ru. Приглашаем делиться находками, заводить тикеты со ссылками.
Код для простого датасета легко написать самому. Дамп Lenta.ru оформлен грамотно, реализация простая. Taiga состоит из ~15 миллионов CoNLL-U-файлов, запакованных в zip-архивы. Чтобы загрузка работала быстро, не использовала много памяти и не угробила файловую систему, нужно заморочиться, аккуратно на низком уровне реализовать работу с zip-файлами.
Для 35 источников в Python-пакете Corus есть функции-загрузчики. Интерфейс доступа к Taiga не сложнее, чем к дампу Lenta.ru:
Приглашаем пользователей делать пулл-реквесты, присылать свои функции-загрузчики, короткая инструкция в репозитории Corus.

Natasha — не научный проект, нет цели побить SOTA, но важно проверить качество на публичных бенчмарках, постараться занять высокое место, сильно не проиграв в производительности. Как делают в академии: измеряют качество, получают число, берут таблички из других статей, сравнивают эти числа со своими. У такой схемы две проблемы:
Naeval — часть проекта Natasha, набор скриптов для оценки качества и скорости работы открытых инструментов для обработки естественного русского языка:
Сетка решений и тестовых датасетов из репозитория Naeval. Инструменты проекта Natasha: Razdel, Navec, Slovnet.
Дальше подробнее рассмотрим задачу NER.
Для русскоязычного NER существует 5 публичных бенчмарков: factRuEval-2016, Collection5, Gareev, BSNLP-2019, WiNER. Ссылки на источники собраны в реестре Corus. Все датасеты состоят из новостных статей, в текстах отмечены подстроки с именами, названиями организаций и топонимов. Что может быть проще?
У всех источников разный формат разметки. Collection5 использует Standoff-формат утилиты Brat, Gareev и WiNER — разные диалекты BIO-разметки, у BSNLP-2019 свой формат, у factRuEval-2016 тоже своя нетривиальная спецификация. Naeval приводит все источники к общему формату. Разметка состоит из спанов. Спан — тройка: тип сущности, начало и конец подстроки.
Типы сущностей. factRuEval-2016 и Collection5 отдельно помечают полутопонимы-полуорганизации: «Кремль», «ЕС», «СССР». BSNLP-2019 и WiNER выделяют названия событий: «Чемпионат России», «Брексит». Naeval адаптирует и удаляет часть меток, оставляет эталонные метки PER, LOC, ORG: имена людей, названия топонимов и организаций.
Вложенные спаны. В factRuEval-2016 спаны пересекаются. Naeval упрощает разметку:
Naeval сравнивает 12 открытых решений задачи NER для русского языка. Все инструменты завёрнуты в Docker-контейнеры с веб-интерфейсом:
Некоторые решения так тяжело запустить и настроить, что мало людей ими пользуется. PullEnti — сложная система, построенная на правилах, заняла первой место на конкурсе factRuEval в 2016 году. Инструмент распространяется в виде SDK для C#. Работа над Naeval вылилась в отдельный проект с набором обёрток для PullEnti: PullentiServer — веб-сервер на С#, pullenti-client — Python-клиент для PullentiServer:
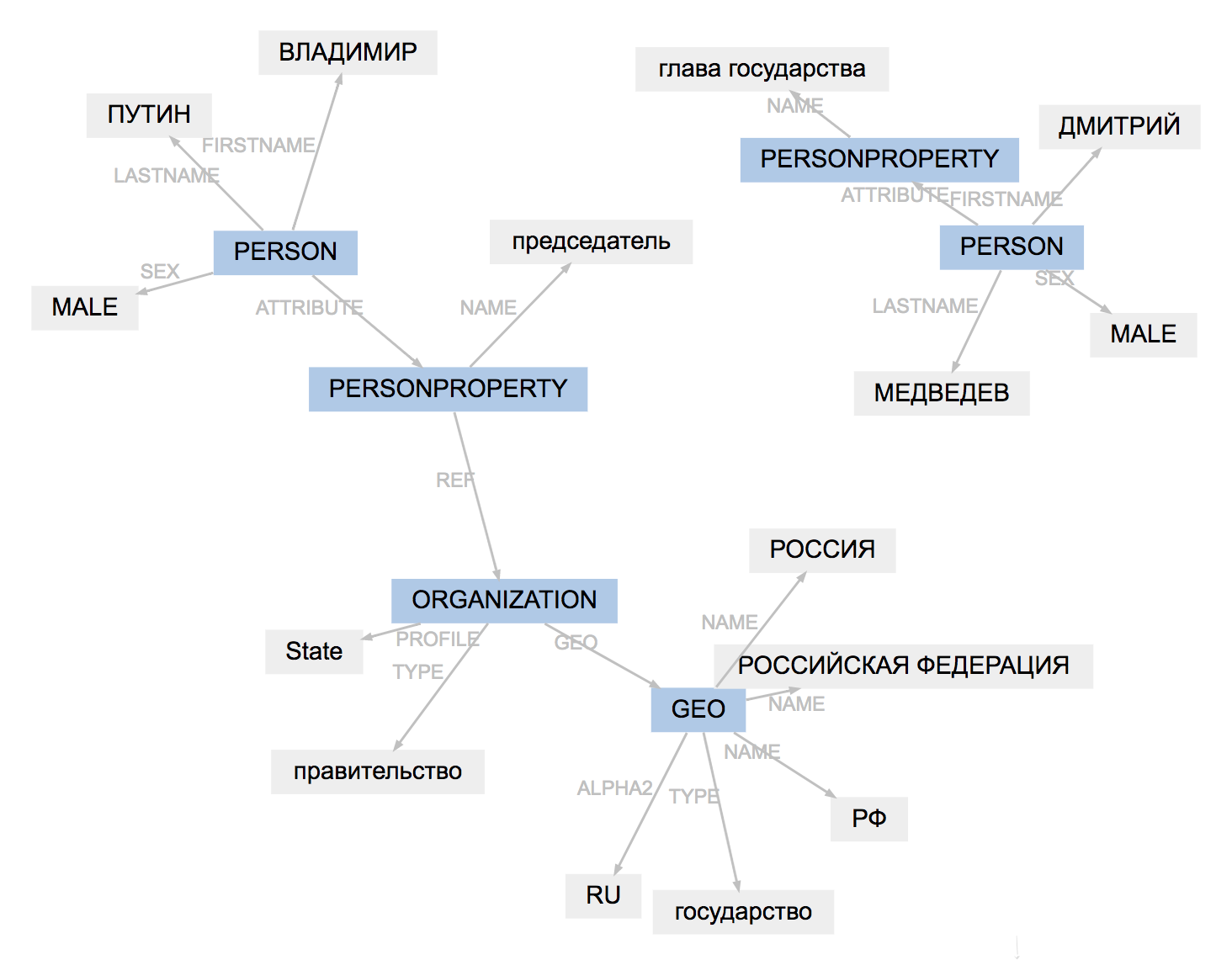
Формат разметки у всех инструментов немного отличается. Naeval загружает результаты, адаптирует типы сущностей, упрощает структуру спанов:
Результат работы PullEnti сложнее адаптировать, чем разметку factRuEval-2016. Алгоритм убирает тег PERSONPROPERTY, разбивает вложенные PERSON, ORGANIZATION и GEO на непересекающиеся PER, LOC, ORG.
Для каждой пары «модель, датасет» Naeval вычисляет F1-меру по токенам, публикует таблицу с оценками качества.
Natasha — не научный проект, для нас важна практичность решения. Naeval измеряет время старта, скорость работы, размер модели и потребление RAM. Таблица с результатами в репозитории.
Мы подготовили датасеты, завернули 20 систем в Docker-контейнеры и посчитали метрики для 5 других задач русскоязычного NLP, результаты в репозитории Naeval: токенизация, сегментация на предложения, эмбеддинги, анализ морфологии и синтаксиса.

Yargy-парсер — аналог яндексового Томита-парсера для Python. Инструкция по установке, пример использования, документация в репозитории Yargy. Правила для извлечения сущностей описываются с помощью контекстно-свободных грамматик и словарей. Два года назад я писал на Хабр статью про Yargy и библиотеку Natasha, рассказывал про решение задачи NER для русского языка. Проект хорошо приняли. Yargy-парсер заменил Томиту в крупных проектах внутри Сбера, Интерфакса и РИА Новостей. Появилось много образовательных материалов. Большое видео с воркшопа в Яндексе, полтора часа про процесс разработки грамматик на примерах:
Обновилась документация, я причесал вводный раздел и справочник. Главное, появился Cookbook — раздел с полезными практиками. Там собраны ответы на самые частые вопросы из t.me/natural_language_processing:
Yargy-парсер — сложный инструмент. В Cookbook описаны неочевидные моменты, который всплывают при работе с большими наборами правил:
У нас в лабе на Yargy работает несколько крупных сервисов. Перечитал код, собрал в Cookbook паттерны, которые не описаны в паблике:
После прочтения документации полезно посмотреть репозиторий с примерами:
Ещё в проекте Natasha есть репозиторий natasha-usage. Туда попадает код пользователей Yargy-парсера, опубликованный на Github. 80% ссылок учебные проекты, но есть и содержательные примеры:
Самые интересные кейсы использования Yargy-парсера, конечно, не публикуют открыто на Github. Напишите в личку, если компания использует Yargy и, если не против, добавим ваше лого на natasha.github.io.

Ipymarkup — примитивная библиотека, нужна для подсветки подстрок в тексте, визуализации NER. Инструкция по установке, пример использования в репозитории Ipymarkup. Библиотека похожа на displaCy и displaCy ENT, бесценна при отладке грамматик для Yargy-парсера.

В проекте Natasha появилось решение задачи синтаксического разбора. Понадобилось не только выделять слова в тексте, но и рисовать между ними стрелочки. Существует масса готовых решений, есть даже научная статья по теме.
Конечно, ничего из существующего не подошло, и однажды я конкретно заморочился, применил всю известную магию CSS и HTML, добавил новую визуализацию в Ipymarkup. Инструкция по использованию в доке.
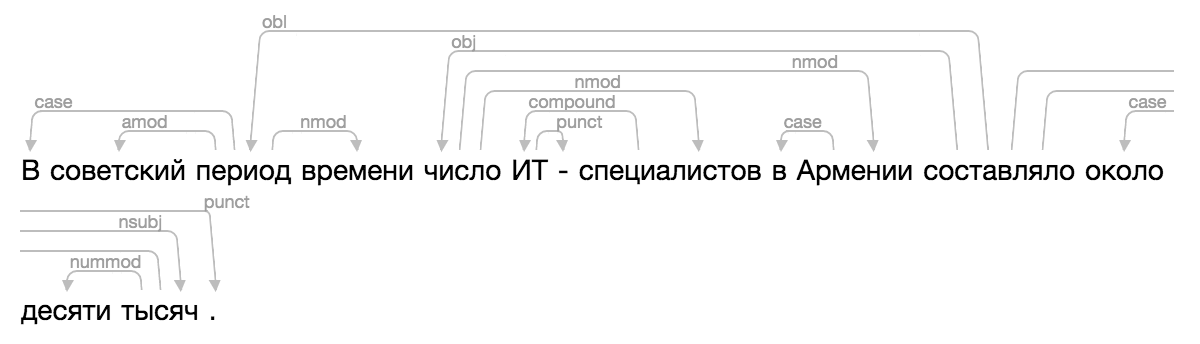
Теперь в Natasha и Nerus удобно смотреть результаты синтаксического разбора.

Проект подрос, библиотека теперь решает все базовые задачи обработки естественного русского языка: сегментация на токены и предложения, морфологический и синтаксический анализ, лемматизация, извлечение именованных сущностей.
Для новостных статей качество на всех задачах сравнимо или превосходит существующие решения. Например с задачей NER Natasha справляется на 1 процентный пункт хуже, чем Deeppavlov BERT NER (F1 PER 0.97, LOC 0.91, ORG 0.85), модель весит в 75 раз меньше (27МБ), работает на CPU в 2 раза быстрее (25 статей/сек), чем BERT NER на GPU.
В проекте 9 репозиториев, библиотека Natasha объединяет их под одним интерфейсом. В статье поговорим про новые инструменты, сравним их с существующими решениями: Deeppavlov, SpaCy, UDPipe.
Этому лонгриду предшествовала серия публикация на сайте natasha.github.io:Если вас пугает размер текста ниже, посмотрите первые 20 минут лампового стрима про историю проекта Natasha, там короткий пересказ:
- Natasha — качественный компактный NER для русского языка
- Navec — компактные эмбеддинги для русского языка
- Corus — коллекция русскоязычных NLP-датасетов
- Razdel — сегментация русскоязычного текста на токены и предложения
- Naeval — количественное сравнение систем для русскоязычного NLP
- Nerus — большой синтетический русскоязычный датасет с разметкой морфологии, синтаксиса и именованных сущностей
В тексте использованы заметки и обсуждения из чата t.me/natural_language_processing, там же в закрепе появляются ссылки на новые материалы:
- Почему Natasha не использует Transformers. BERT в 100 строк
- BERT-модели Slovnet
- Ламповый стрим про историю проекта Natasha
- Обновлённая документация Yargy
- Дополнительные материалы по Yargy-парсеру
Содержание:
- Natasha — набор качественных открытых инструментов для обработки естественного русского языка. Интерфейс для низкоуровневых библиотек проекта
- Razdel — сегментация русскоязычного текста на токены и предложения
- Slovnet — deep learning моделирование для обработки естественного русского языка
- Navec — компактные эмбеддинги для русского языка
- Nerus — большой синтетический датасет с разметкой морфологии, синтаксиса и именованных сущностей
- Corus — коллекция ссылок на публичные русскоязычные датасеты + функции для загрузки
- Naeval — количественное сравнение систем для русскоязычного NLP
- Yargy-парсер — извлечение структурированное информации из текстов на русском языке с помощью грамматик и словарей
- Ipymarkup — визуализация разметки именованных сущностей и синтаксических связей
Natasha — набор качественных открытых инструментов для обработки естественного русского языка. Интерфейс для низкоуровневых библиотек проекта
Раньше библиотека Natasha решала задачу NER для русского языка, была построена на правилах, показывала среднее качество и производительность. Сейчас Natasha — это целый большой проект, состоит из 9 репозиториев. Библиотека Natasha объединяет их под одним интерфейсом, решает базовые задачи обработки естественного русского языка: сегментация на токены и предложения, предобученные эмбеддинги, анализ морфологии и синтаксиса, лемматизация, NER. Все решения показывают топовые результаты в новостной тематике, быстро работают на CPU.
Natasha похожа на другие библиотеки-комбайны: SpaCy, UDPipe, Stanza. SpaCy инициализирует и вызывает модели неявно, пользователь передаёт текст в магическую функцию
nlp, получает полностью разобранный документ.import spacy
# Внутри load происходит загрузка предобученных эмбеддингов,
# инициализация компонентов для разбора морфологии, синтаксиса и NER
nlp = spacy.load('...')
# Пайплайн моделей обрабатывает текст, возвращает разобранный документ
text = '...'
doc = nlp(text)
Интерфейс Natasha более многословный. Пользователь явно инициализирует компоненты: загружает предобученные эмбеддинги, передаёт их в конструкторы моделей. Сам вызывает методы
segment, tag_morph, parse_syntax для сегментации на токены и предложения, анализа морфологии и синтаксиса.>>> from natasha import (
Segmenter,
NewsEmbedding,
NewsMorphTagger,
NewsSyntaxParser,
Doc
)
>>> segmenter = Segmenter()
>>> emb = NewsEmbedding()
>>> morph_tagger = NewsMorphTagger(emb)
>>> syntax_parser = NewsSyntaxParser(emb)
>>> text = 'Посол Израиля на Украине Йоэль Лион признался, что пришел в шок, узнав о решении властей Львовской области объявить 2019 год годом лидера запрещенной в России Организации украинских националистов (ОУН) Степана Бандеры...'
>>> doc = Doc(text)
>>> doc.segment(segmenter)
>>> doc.tag_morph(morph_tagger)
>>> doc.parse_syntax(syntax_parser)
>>> sent = doc.sents[0]
>>> sent.morph.print()
Посол NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
Израиля PROPN|Animacy=Inan|Case=Gen|Gender=Masc|Number=Sing
на ADP
Украине PROPN|Animacy=Inan|Case=Loc|Gender=Fem|Number=Sing
Йоэль PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
Лион PROPN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
...
>>> sent.syntax.print()
---> Посол nsubj
¦ Израиля
¦ -> на case
¦ L- Украине
¦ -- Йоэль
¦ L> Лион flat:name
--------L--- признался
¦ ¦ ---> , punct
¦ ¦ ¦ -> что mark
¦ L>L-L- пришел ccomp
¦ ¦ -> в case
¦ L-->L- шок obl
...
Модуль извлечения именованных сущностей не зависит от результатов морфологического и синтаксического разбора, его можно использовать отдельно.
>>> from natasha import NewsNERTagger
>>> ner_tagger = NewsNERTagger(emb)
>>> doc.tag_ner(ner_tagger)
>>> doc.ner.print()
Посол Израиля на Украине Йоэль Лион признался, что пришел в шок, узнав
LOC---- LOC---- PER-------
о решении властей Львовской области объявить 2019 год годом лидера
LOC--------------
запрещенной в России Организации украинских националистов (ОУН)
LOC--- ORG---------------------------------------
Степана Бандеры...
PER------------
Natasha решает задачу лемматизации, использует Pymorphy2 и результаты морфологического разбора.
>>> from natasha import MorphVocab
>>> morph_vocab = MorphVocab()
>>> for token in doc.tokens:
>>> token.lemmatize(morph_vocab)
>>> {_.text: _.lemma for _ in doc.tokens}
{'Посол': 'посол',
'Израиля': 'израиль',
'на': 'на',
'Украине': 'украина',
'Йоэль': 'йоэль',
'Лион': 'лион',
'признался': 'признаться',
',': ',',
'что': 'что',
'пришел': 'прийти'
...
Чтобы привести словосочетание к нормальной форме, недостаточно найти леммы отдельных слов, для «МИД России» получится «МИД Россия», для «Организации украинских националистов» — «Организация украинский националист». Natasha использует результаты синтаксического разбора, учитывает связи между словами, нормализует именованные сущности.
>>> for span in doc.spans:
>>> span.normalize(morph_vocab)
>>> {_.text: _.normal for _ in doc.spans}
{'Израиля': 'Израиль',
'Украине': 'Украина',
'Йоэль Лион': 'Йоэль Лион',
'Львовской области': 'Львовская область',
'России': 'Россия',
'Организации украинских националистов (ОУН)': 'Организация украинских националистов (ОУН)',
'Степана Бандеры': 'Степан Бандера',
...
Natasha находит в тексте имена, названия организаций и топонимов. Для имён в библиотеке есть набор готовых правил для Yargy-парсера, модуль делит нормированные имена на части, из «Виктор Федорович Ющенко» получается
{first: Виктор, last: Ющенко, middle: Федорович}.>>> from natasha import (
PER,
NamesExtractor,
)
>>> names_extractor = NamesExtractor(morph_vocab)
>>> for span in doc.spans:
>>> if span.type == PER:
>>> span.extract_fact(names_extractor)
>>> {_.normal: _.fact.as_dict for _ in doc.spans if _.type == PER}
{'Йоэль Лион': {'first': 'Йоэль', 'last': 'Лион'},
'Степан Бандера': {'first': 'Степан', 'last': 'Бандера'},
'Петр Порошенко': {'first': 'Петр', 'last': 'Порошенко'},
'Бандера': {'last': 'Бандера'},
'Виктор Ющенко': {'first': 'Виктор', 'last': 'Ющенко'}}
В библиотеке собраны правила для разбора дат, сумм денег и адресов, они описаны в документации и справочнике.
Библиотека Natasha хорошо подходит для демонстрации технологий проекта, используется в образовании. Архивы с весами моделей встроены в пакет, после установки не нужно ничего скачивать и настраивать.
Natasha объединяет под одним интерфейсом другие библиотеки проекта. Для решения практических задач стоит использовать их напрямую:
- Razdel — сегментация текста на предложения и токены;
- Navec — качественный компактные эмбеддинги;
- Slovnet — современные компактные модели для морфологии, синтаксиса, NER;
- Yargy — правила и словари для извлечения структурированной информации;
- Ipymarkup — визуализация NER и синтаксической разметки;
- Corus — коллекция ссылок на публичные русскоязычные датасеты;
- Nerus — большой корпус с автоматической разметкой именованных сущностей, морфологии и синтаксиса.
Razdel — сегментация русскоязычного текста на токены и предложения
Библиотека Razdel — часть проекта Natasha, делит русскоязычный текст на токены и предложения. Инструкция по установке, пример использования и замеры производительности в репозитории Razdel.
>>> from razdel import tokenize, sentenize
>>> text = 'Кружка-термос на 0.5л (50/64 см?, 516;...)'
>>> list(tokenize(text))
[Substring(start=0, stop=13, text='Кружка-термос'),
Substring(start=14, stop=16, text='на'),
Substring(start=17, stop=20, text='0.5'),
Substring(start=20, stop=21, text='л'),
Substring(start=22, stop=23, text='(')
...]
>>> text = '''
... - "Так в чем же дело?" - "Не ра-ду-ют".
... И т. д. и т. п. В общем, вся газета
... '''
>>> list(sentenize(text))
[Substring(start=1, stop=23, text='- "Так в чем же дело?"'),
Substring(start=24, stop=40, text='- "Не ра-ду-ют".'),
Substring(start=41, stop=56, text='И т. д. и т. п.'),
Substring(start=57, stop=76, text='В общем, вся газета')]
Современные модели часто не заморачиваются на счёт сегментации, используют BPE, показывают замечательные результаты, вспомним все версии GPT и зоопарк BERTов. Natasha решает задачи разбора морфологии и синтаксиса, они имеют смысл только для отдельных слов внутри одного предложения. Поэтому мы ответственно подходим к этапу сегментации, стараемся повторить разметку из популярных открытых датасетов: SynTagRus, OpenCorpora, GICRYA.
Скорость и качество Razdel сопоставимы или выше, чем у других открытых решений для русского языка.
| Решения для сегментации на токены | Ошибки на 1000 токенов | Время обработки, секунды |
| Regexp-baseline | 19 | 0.5 |
| SpaCy |
17 | 5.4 |
| NLTK |
130 | 3.1 |
| MyStem |
19 | 4.5 |
| Moses |
11 | 1.9 |
| SegTok |
12 | 2.1 |
| SpaCy Russian Tokenizer |
8 | 46.4 |
| RuTokenizer |
15 | 1.0 |
| Razdel |
7 | 2.6 |
| Решения для сегментации на предложения | Ошибки на 1000 предложений | Время обработки, секунды |
| Regexp-baseline | 76 | 0.7 |
| SegTok |
381 | 10.8 |
| Moses |
166 | 7.0 |
| NLTK |
57 | 7.1 |
| DeepPavlov |
41 | 8.5 |
| Razdel | 43 | 4.8 |
Число ошибок среднее по 4 датасетам: SynTagRus, OpenCorpora, GICRYA and RNC. Подробнее в репозитории Razdel.
Зачем вообще нужен Razdel, если похожее качество даёт baseline с регулярочкой и для русского языка есть куча готовых решений? На самом деле, Razdel это не просто токенизатор, а небольшой сегментационный движок на правилах. Сегментация базовая задача, часто встречается на практике. Например, есть судебный акт, нужно выделить в нём резолютивную часть и поделить её на параграфы. Естественно, готовые решения так не умеют. Как писать свои правила читайте в исходниках. Дальше речь о том, как упороться и сделать на нашем движке топовое решение для токенов и предложений.
В чём сложность?
В русском языке предложения обычно заканчиваются точкой, вопросительным или восклицательным знаком. Просто разделим текст регулярным выражением
[.?!]\s+. Такое решение даст 76 ошибок на 1000 предложений. Типы и примеры ошибок:Cокращения
… любая площадка с аудиторией от 3 тыс.-человек является блогером.
… над ними с конца XVII в.-стоял бей;
… в Камерном музыкальном театре им.-Б.А. Покровского.
Инициалы
В след за операми «Идоменей» В.А.-Моцарта – Р.-Штрауса …
Списки
2.-думал будет в финское консульство красивая длинная очередь …
г.-билеты на поезда российских железных дорог …
В конце предложения смайлик или типографское многоточие
Кто предложит способ избавления от минусов — тому спасибо :)-Посмотрел, призадумался…-Вот это уже более неприятно, поскольку содержательность нарушится.
Цитаты, прямая речь, в конце предложения кавычка
— невесты у вас в городе есть?»-«Кому и кобыла невеста».
«Как хорошо, что я не такой!»-Сейчас при переводе сделал фрейдстскую ошибку:«идология».
Razdel учитывает эти нюансы, сокращает число ошибок c 76 до 43 на 1000 предложений.
С токенами аналогичная ситуация. Хорошее базовое решение даёт регулярное выражение
[а-яё-]+|[0-9]+|[^а-яё0-9 ], оно делает 19 ошибок на 1000 токенов. Примеры:Дробные числа, сложная пунктуация
… В конце 1980--х — начале 1990--х
… БС--3 можно отметить слегка меньшую массу (3-,-6 т)
— да и умерла.-.-. Понял ли девку, сокол?-!
Razdel сокращает число ошибок до 7 на 1000 токенов.
Принцип работы
Система построена на правилах. Принцип сегментации на токены и предложения одинаковый.
Сбор кандидатов
Находим в тексте всех кандидатов на конец предложения: точки, многоточия, скобки, кавычки.
6.-Наиболее частый и при этом высоко оцененный вариант ответов «я рада»-(13 высказываний, 25 баллов)-– ситуации получения одобрения и поощрения.-7.-Примечательно, что в ответе «я знаю»-оценен как максимально стереотипный, но лишь раз встречается ответ «я женщина»-;-присутствуют высказывания «один брак – это всё, что меня ждет в этой жизни»-и «рано или поздно придется рожать»-.-Составители: В.-П.-Головин, Ф.-В.-Заничев, А.-Л.-Расторгуев, Р.-В.-Савко, И.-И.-Тучков.
Для токенов дробим текст на атомы. Внутри атома точно не проходит граница токена.
В-конце-1980---х---начале-1990---х-
БС---3-можно-отметить-слегка-меньшую-массу-(-3-,-6-т-)-
-—-да-и-умерла-.-.-.-Понял-ли-девку-,-сокол-?-!
Объединение
Последовательно обходим кандидатов на разделение, убираем лишние. Используем список эвристик.
Элемент списка. Разделитель — точка или скобка, слева число или буква
6.-Наиболее частый и при этом высоко оцененный вариант ответов «я рада» (13 высказываний, 25 баллов) – ситуации получения одобрения и поощрения. 7.-Примечательно, что в ответе «я знаю» …
Инициалы. Разделитель — точка, слева одна заглавная буква
… Составители: В.-П.-Головин, Ф.-В.-Заничев, А.-Л.-Расторгуев, Р.-В.-Савко, И.-И.-Тучков.
Справа от разделителя нет пробела
… но лишь раз встречается ответ «я женщина»-; присутствуют высказывания «один брак – это всё, что меня ждет в этой жизни» и «рано или поздно придется рожать»-.
Перед закрывающей кавычкой или скобкой нет знака конца предложения, это не цитата и не прямая речь
6. Наиболее частый и при этом высоко оцененный вариант ответов «я рада»-(13 высказываний, 25 баллов)-– ситуации получения одобрения и поощрения. … «один брак – это всё, что меня ждет в этой жизни»-и «рано или поздно придется рожать».
В результате остаётся два разделителя, считаем их концами предложений.
6. Наиболее частый и при этом высоко оцененный вариант ответов «я рада» (13 высказываний, 25 баллов) – ситуации получения одобрения и поощрения.-7. Примечательно, что в ответе «я знаю» оценен как максимально стереотипный, но лишь раз встречается ответ «я женщина»; присутствуют высказывания «один брак – это всё, что меня ждет в этой жизни» и «рано или поздно придется рожать».-Составители: В. П. Головин, Ф. В. Заничев, А. Л. Расторгуев, Р. В. Савко, И. И. Тучков.
Для токенов процедура аналогичная, правила другие.
Дробь или рациональное число
… (3-,-6 т) …
Сложная пунктуация
— да и умерла.-.-. Понял ли девку, сокол?-!
Вокруг дефиса нет пробелов, это не начало прямой речи
В конце 1980---х — начале 1990---х
БС---3 можно отметить …
Всё что осталось считаем границами токенов.
В-конце-1980-х---начале-1990-х-
БС-3-можно-отметить-слегка-меньшую-массу-(-3,6-т-)-
-—-да-и-умерла-...-Понял-ли-девку-,-сокол-?!
Ограничения
Правила в Razdel оптимизированы для аккуратно написанных текстов с правильной пунктуацией. Решение хорошо работает с новостными статьями, художественными текстами. На постах из социальных сетей, расшифровках телефонных разговоров качество ниже. Если между предложениями нет пробела или в конце нет точки или предложение начинается с маленькой буквы, Razdel сделает ошибку.
Как писать правила под свои задачи читайте в исходниках, в документации эта тема пока не раскрыта.
Slovnet — deep learning моделирование для обработки естественного русского языка
В проекте Natasha Slovnet занимается обучением и инференсом современных моделей для русскоязычного NLP. В библиотеке собраны качественные компактные модели для извлечения именованных сущностей, разбора морфологии и синтаксиса. Качество на всех задачах сравнимо или превосходит другие отрытые решения для русского языка на текстах новостной тематики. Инструкция по установке, примеры использования — в репозитории Slovnet. Подробно разберёмся, как устроено решение для задачи NER, для морфологии и синтаксиса всё по аналогии.
В конце 2018 года после статьи от Google про BERT в англоязычном NLP случился большой прогресс. В 2019 ребята из проекта DeepPavlov адаптировали мультиязычный BERT для русского, появился RuBERT. Поверх обучили CRF-голову, получился DeepPavlov BERT NER — SOTA для русского языка. У модели великолепное качество, в 2 раза меньше ошибок, чем у ближайшего преследователя DeepPavlov NER, но размер и производительность пугают: 6ГБ — потребление GPU RAM, 2ГБ — размер модели, 13 статей в секунду — производительность на хорошей GPU.
В 2020 году в проекте Natasha нам удалось вплотную приблизится по качеству к DeepPavlov BERT NER, размер модели получился в 75 раз меньше (27МБ), потребление памяти в 30 раз меньше (205МБ), скорость в 2 раза больше на CPU (25 статей в секунду).
| Natasha, Slovnet NER | DeepPavlov BERT NER | |
| PER/LOC/ORG F1 по токенам, среднее по Collection5, factRuEval-2016, BSNLP-2019, Gareev | 0.97/0.91/0.85 | 0.98/0.92/0.86 |
| Размер модели | 27МБ | 2ГБ |
| Потребление памяти | 205МБ | 6ГБ (GPU) |
| Производительность, новостных статей в секунду (1 статья ? 1КБ) | 25 на CPU (Core i5) | 13 на GPU (RTX 2080 Ti), 1 на CPU |
| Время инициализации, секунд | 1 | 35 |
| Библиотека поддерживает | Python 3.5+, PyPy3 | Python 3.6+ |
| Зависимости | NumPy | TensorFlow |
Качество Slovnet NER на 1 процентный пункт ниже, чем у SOTA DeepPavlov BERT NER, размер модели в 75 раз меньше, потребление памяти в 30 раз меньше, скорость в 2 раза больше на CPU. Сравнение со SpaCy, PullEnti и другими решениями для русскоязычного NER в репозитории Slovnet.
Как получить такой результат? Короткий рецепт:
Slovnet NER = Slovnet BERT NER — аналог DeepPavlov BERT NER + дистилляция через синтетическую разметку (Nerus) в WordCNN-CRF c квантованными эмбеддингами (Navec) + движок для инференса на NumPy.
Теперь по порядку. План такой: обучим тяжёлую модель c BERT-архитектурой на небольшом вручную аннотированном датасете. Разметим ей корпус новостей, получится большой грязный синтетический тренировочный датасет. Обучим на нём компактную примитивную модель. Этот процесс называется дистилляцией: тяжёлая модель — учитель, компактная — ученик. Рассчитываем, что BERT-архитектура избыточна для задачи NER, компактная модель несильно проиграет по качеству тяжёлой.
Модель-учитель
DeepPavlov BERT NER состоит из RuBERT-энкодера и CRF-головы. Наша тяжёлая модель-учитель повторяет эту архитектуру с небольшими улучшениями.
Все бенчмарки измеряют качество NER на текстах новостей. Дообучим RuBERT на новостях. В репозитории Corus собраны ссылки на публичные русскоязычные новостные корпуса, в сумме 12 ГБ текстов. Используем техники из статьи от Facebook про RoBERTa: большие агрегированные батчи, динамическая маска, отказ от предсказания следующего предложения (NSP). RuBERT использует огромный словарь на 120 000 сабтокенов — наследие мультиязычного BERT от Google. Сократим размер до 50 000 самых частотных для новостей, покрытие уменьшится на 5%. Получим NewsRuBERT, модель предсказывает замаскированные сабтокены в новостях на 5 процентных пунктов лучше RuBERT (63% в топ-1).
Обучим NewsRuBERT-энкодер и CRF-голову на 1000 статей из Collection5. Получим Slovnet BERT NER, качество на 0.5 процентных пункта лучше, чем у DeepPavlov BERT NER, размер модели меньше в 4 раза (473МБ), работает в 3 раза быстрее (40 статей в секунду).
NewsRuBERT = RuBERT + 12ГБ новостей + техники из RoBERTa + 50K-словарь.
Slovnet BERT NER (аналог DeepPavlov BERT NER) = NewsRuBERT + CRF-голова + Collection5.
Сейчас, для обучения моделей с BERT-like архитектурой, принято использовать Transformers от Hugging Face. Transformers — это 100 000 строк кода на Python. Когда взорвётся loss или на инференсе мусор, тяжело разобраться, что пошло не так. Ладно, там много кода дублируется. Пускай мы тренируем RoBERTa, довольно быстро локализуем проблему до ~3000 строк кода, но это тоже немало. С современным PyTorch, библиотека Transformers не так актуальна. С
torch.nn.TransformerEncoderLayer код RoBERTa-like модели занимает 100 строк:class BERTEmbedding(nn.Module):
def __init__(self, vocab_size, seq_len, emb_dim, dropout=0.1, norm_eps=1e-12):
super(BERTEmbedding, self).__init__()
self.word = nn.Embedding(vocab_size, emb_dim)
self.position = nn.Embedding(seq_len, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.drop = nn.Dropout(dropout)
def forward(self, input):
batch_size, seq_len = input.shape
position = torch.arange(seq_len).expand_as(input).to(input.device)
emb = self.word(input) + self.position(position)
emb = self.norm(emb)
return self.drop(emb)
def BERTLayer(emb_dim, heads_num, hidden_dim, dropout=0.1, norm_eps=1e-12):
layer = nn.TransformerEncoderLayer(
d_model=emb_dim,
nhead=heads_num,
dim_feedforward=hidden_dim,
dropout=dropout,
activation='gelu'
)
layer.norm1.eps = norm_eps
layer.norm2.eps = norm_eps
return layer
class BERTEncoder(nn.Module):
def __init__(self, layers_num, emb_dim, heads_num, hidden_dim,
dropout=0.1, norm_eps=1e-12):
super(BERTEncoder, self).__init__()
self.layers = nn.ModuleList([
BERTLayer(
emb_dim, heads_num, hidden_dim,
dropout, norm_eps
)
for _ in range(layers_num)
])
def forward(self, input, pad_mask=None):
input = input.transpose(0, 1) # torch expects seq x batch x emb
for layer in self.layers:
input = layer(input, src_key_padding_mask=pad_mask)
return input.transpose(0, 1) # restore
class BERTMLMHead(nn.Module):
def __init__(self, emb_dim, vocab_size, norm_eps=1e-12):
super(BERTMLMHead, self).__init__()
self.linear1 = nn.Linear(emb_dim, emb_dim)
self.norm = nn.LayerNorm(emb_dim, eps=norm_eps)
self.linear2 = nn.Linear(emb_dim, vocab_size)
def forward(self, input):
x = self.linear1(input)
x = F.gelu(x)
x = self.norm(x)
return self.linear2(x)
class BERTMLM(nn.Module):
def __init__(self, emb, encoder, head):
super(BERTMLM, self).__init__()
self.emb = emb
self.encoder = encoder
self.head = head
def forward(self, input):
x = self.emb(input)
x = self.encoder(x)
return self.head(x)
Это не прототип, код скопирован из репозитория Slovnet. Transformers полезно читать, они делают большую работу, набивают код для статей с Arxiv, часто исходники на Python понятнее, чем объяснение в научной статье.
Синтетический датасет
Разметим 700 000 статей из корпуса Lenta.ru тяжёлой моделью. Получим огромный синтетический обучающий датасет. Архив доступен в репозитории Nerus проекта Natasha. Разметка очень качественная, оценки F1 по токенам: PER — 99.7%, LOC — 98.6%, ORG — 97.2%. Редкие примеры ошибок:
Выборы Верховного совета Аджарской автономной республики
ORG-------------- LOC----------------------------
назначены в соответствии с 241-ой статьей и 4-м пунктом 10-й
статьи Конституционного закона Грузии <О статусе Аджарской
LOC--- LOC------
автономной республики>.
-----------~~~~~~~~~~~
Следственное управление при прокуратуре требует наказать
ORG--------------------~~~~~~~~~~~~~~~~
премьера Якутии.
LOC---
Начальник полигона <Игумново> в Нижегородской области осужден
~~~~~~~~ LOC------------------
за загрязнение атмосферы и грунтовых вод.
Страны Азии и Африки поддержали позицию России в конфликте с
~~~~ ~~~~~~ LOC---
Грузией.
LOC----
У Владимира Стржалковского появится помощник - специалист по
PER---------------------
проведению сделок M&A.
~~~
Постоянный Секретариат ОССНАА в Каире в пятницу заявил: Когда
~~~~~~~~~~~~ORG--- LOC--
Саакашвили стал президентом Грузии, он проявил стремление
PER------- LOC---
вступить в НАТО, Европейский Союз и установить более близкие
ORG- LOC-------------
отношения с США.
LOC
Модель-ученик
С выбором архитектуры тяжёлой модели-учителя проблем не возникло, вариант один — трансформеры. С компактной моделью-учеником сложнее, вариантов много. С 2013 до 2018 год с появления word2vec до статьи про BERT, человечество придумало кучу нейросетевых архитектур для решения задачи NER. У всех общая схема:
Схема нейросетевых архитектур для задачи NER: энкодер токенов, энкодер контекста, декодер тегов. Расшифровка сокращений в обзорной статье Yang (2018).
Комбинаций архитектур много. Какую выбрать? Например, (CharCNN + Embedding)-WordBiLSTM-CRF — схема модели из статьи про DeepPavlov NER, SOTA для русского языка до 2019 года.
Варианты с CharCNN, CharRNN пропускаем, запускать маленькую нейронную сеть по символам на каждом токене — не наш путь, слишком медленно. WordRNN тоже хотелось бы избежать, решение должно работать на CPU, перемножать матрицы на каждом токене медленно. Для NER выбор между Linear и CRF условный. Мы используем BIO-кодировку, порядок тегов важен. Приходится терпеть жуткие тормоза, использовать CRF. Остаётся один вариант — Embedding-WordCNN-CRF. Такая модель не учитывает регистр токенов, для NER это важно, «надежда» — просто слово, «Надежда» — возможно, имя. Добавим ShapeEmbedding — эмбеддинг с очертаниями токенов, например: «NER» — EN_XX, «Вайнович» — RU_Xx, "!" — PUNCT_!, «и» — RU_x, «5.1» — NUM, «Нью-Йорк» — RU_Xx-Xx. Схема Slovnet NER — (WordEmbedding + ShapeEmbedding)-WordCNN-CRF.
Дистилляция
Обучим Slovnet NER на огромном синтетическом датасете. Сравним результат с тяжёлой моделью-учителем Slovnet BERT NER. Качество считаем и усредняем по размеченным вручную Collection5, Gareev, factRuEval-2016, BSNLP-2019. Размер обучающей выборки очень важен: на 250 новостных статьях (размер factRuEval-2016) средний по PER, LOC, LOG F1 — 0.64, на 1000 (аналог Collection5) — 0.81, на всём датасете — 0.91, качество Slovnet BERT NER — 0.92.
Качество Slovnet NER, зависимость от числа синтетических обучающих примеров. Серая линия — качество Slovnet BERT NER. Slovnet NER не видит размеченных вручную примеров, обучается только на синтетических данных.
Примитивная модель-ученик на 1 процентный пункт хуже тяжёлой модели-учителя. Это замечательный результат. Напрашивается универсальный рецепт:
Вручную размечаем немного данных. Обучаем тяжёлый трансформер. Генерируем много синтетических данных. Обучаем простую модель на большой выборке. Получаем качество трансформера, размер и производительность простой модели.
В библиотеке Slovnet есть ещё две модели обученные по этому рецепту: Slovnet Morph — морфологический теггер, Slovnet Syntax — синтаксический парсер. Slovnet Morph отстаёт от тяжёлой модели-учителя на 2 процентных пункта, Slovnet Syntax — на 5. У обеих моделей качество и производительность выше существующих решений для русского на новостных статьях.
Квантизация
Размер Slovnet NER — 289МБ. 287МБ занимает таблица с эмбеддингами. Модель использует большой словарь на 250 000 строк, он покрывает 98% слов в новостных текстах. Используем квантизацию, заменим 300-мерные float-вектора на 100-мерные 8-битные. Размер модели уменьшится в 10 раз (27МБ), качество не изменится. Библиотека Navec — часть проекта Natasha, коллекция квантованных предобученных эмбеддингов. Веса обученные на художественной литературе занимают 50МБ, обходят по синтетическим оценкам все статические модели RusVectores.
Инференс
Slovnet NER использует PyTorch для обучения. Пакет PyTorch весит 700МБ, не хочется тянуть его в продакшн для инференса. Ещё PyTorch не работает с интерпретатором PyPy. Slovnet используется в связке с Yargy-парсером аналогом яндексового Tomita-парсера. С PyPy Yargy работает в 2-10 раз быстрее, зависит от сложности грамматик. Не хочется терять скорость из-за зависимости от PyTorch.
Стандартное решение — использовать TorchScript или сконвертировать модель в ONNX, инференс делать в ONNXRuntime. Slovnet NER использует нестандартные блоки: квантованные эмбеддинги, CRF-декодер. TorchScript и ONNXRuntime не поддерживают PyPy.
Slovnet NER — простая модель, вручную реализуем все блоки на NumPy, используем веса, посчитанные PyTorch. Применим немного NumPy-магии, аккуратно реализуем блок CNN, CRF-декодер, распаковка квантованного эмбеддинга занимает 5 строк. Скорость инференса на CPU такая же как с ONNXRuntime и PyTorch, 25 новостных статей в секунду на Core i5.
Техника работает на более сложных моделях: Slovnet Morph и Slovnet Syntax тоже реализованы на NumPy. Slovnet NER, Morph и Syntax используют общую таблицу эмбеддингов. Вынесем веса в отдельный файл, таблица не дублируется в памяти и на диске:
>>> navec = Navec.load('navec_news_v1_1B.tar') # 25MB
>>> morph = Morph.load('slovnet_morph_news_v1.tar') # 2MB
>>> syntax = Syntax.load('slovnet_syntax_news_v1.tar') # 3MB
>>> ner = NER.load('slovnet_ner_news_v1.tar') # 2MB
# 25 + 2 + 3 + 2 вместо 25+2 + 25+3 + 25+2
>>> morph.navec(navec)
>>> syntax.navec(navec)
>>> ner.navec(navec)
Ограничения
Natasha извлекает стандартные сущности: имена, названия топонимов и организаций. Решение показывает хорошее качество на новостях. Как работать с другими сущностями и типами текстов? Нужно обучить новую модель. Сделать это непросто. За компактный размер и скорость работы мы платим сложностью подготовки модели. Скрипт-ноутбук для подготовки тяжёлой модели учителя, скрипт-ноутбук для модели-ученика, инструкции по подготовке квантованных эмбеддингов.
Navec — компактные эмбеддинги для русского языка
С компактными моделями удобно работать. Они быстро запускаются, используют мало памяти, на один инстанст помещается больше параллельных процессов.
В NLP 80-90% весов модели приходится на таблицу с эмбеддингами. Библиотека Navec — часть проекта Natasha, коллекция предобученных эмбеддингов для русского языка. По intrinsic-метрикам качества они чуть-чуть не дотягивают по топовых решений RusVectores, зато размер архива с весами в 5-6 раз меньше (51МБ), словарь в 2-3 раза больше (500К слов).
| Качество* | Размер модели, МБ | Размер словаря, ?103 | |
| Navec | 0.719 | 50.6 | 500 |
| RusVectores | 0.638–0.726 | 220.6–290.7 | 189–249 |
Речь пойдёт про старые добрые пословные эмбеддинги, совершившие революцию в NLP в 2013 году. Технология актуальна до сих пор. В проекте Natasha модели для разбора морфологии, синтаксиса и извлечения именованных сущностей работают на пословных Navec-эмбеддингах, показывают качество выше других открытых решений.
RusVectores
Для русского языка принято использовать предобученные эмбеддинги от RusVectores, у них есть неприятная особенность: в таблице записаны не слова, а пары «слово_POS-тег». Идея хорошая, для пары «печь_VERB» ожидаем вектор, похожий на «готовить_VERB», «варить_VERB», а для «печь_NOUN» — «изба_NOUN», «топка_NOUN».
На практике использовать такие эмбеддинги неудобно. Недостаточно разделить текст на токены, для каждого нужно как-то определить POS-тег. Таблица эмбеддингов разбухает. Вместо одного слова «стать», мы храним 6: 2 разумных «стать_VERB», «стать_NOUN» и 4 странных «стать_ADV», «стать_PROPN», «стать_NUM», «стать_ADJ». В таблице на 250 000 записей 195 000 уникальных слов.
Качество
Оценим качество эмбеддингов на задаче семантической близости. Возьмём пару слов, для каждого найдём вектор-эмбеддинг, посчитаем косинусное сходство. Navec для похожих слов «чашка» и «кувшин» возвращет 0.49, для «фрукт» и «печь» — ?0.0047. Соберём много пар с эталонными метками похожести, посчитаем корреляцию Спирмена с нашими ответами.
Авторы RusVectores используют небольшой аккуратно проверенный и исправленный тестовый список пар SimLex965. Добавим свежий яндексовый LRWC и датасеты из проекта RUSSE: HJ, RT, AE, AE2:
| Среднее качество на 6 датасетах | Время загрузки, секунды | Размер модели, МБ | Размер словаря, ?103 | ||
| Navec | hudlit_12B_500K_300d_100q |
0.719 | 1.0 | 50.6 | 500 |
news_1B_250K_300d_100q |
0.653 | 0.5 | 25.4 | 250 | |
| RusVectores | ruscorpora_upos_cbow_300_20_2019 |
0.692 | 3.3 | 220.6 | 189 |
ruwikiruscorpora_upos_skipgram_300_2_2019 |
0.691 | 5.0 | 290.0 | 248 | |
tayga_upos_skipgram_300_2_2019 |
0.726 | 5.2 | 290.7 | 249 | |
tayga_none_fasttextcbow_300_10_2019 |
0.638 | 8.0 | 2741.9 | 192 | |
araneum_none_fasttextcbow_300_5_2018 |
0.664 | 16.4 | 2752.1 | 195 |
Качество
hudlit_12B_500K_300d_100q сравнимо или лучше, чем у решений RusVectores, словарь больше в 2–3 раза, размер модели меньше в 5–6 раз. Как удалось получить такое качество и размер?Принцип работы
hudlit_12B_500K_300d_100q — GloVe-эмбеддинги обученные на 145ГБ художественной литературы. Архив с текстами возьмём из проекта RUSSE. Используем оригинальную реализацию GloVe на C, обернём её в удобный Python-интерфейс.Почему не word2vec? Эксперименты на большом датасете быстрее с GloVe. Один раз считаем матрицу коллокаций, по ней готовим эмбеддинги разных размерностей, выбираем оптимальный вариант.
Почему не fastText? В проекте Natasha мы работаем с текстами новостей. В них мало опечаток, проблему OOV-токенов решает большой словарь. 250 000 строк в таблице
news_1B_250K_300d_100q покрывают 98% слов в новостных статьях.Размер словаря
hudlit_12B_500K_300d_100q — 500 000 записей, он покрывает 98% слов в художественных текстах. Оптимальная размерность векторов — 300. Таблица 500 000 ? 300 из float-чисел занимает 578МБ, размер архива с весами hudlit_12B_500K_300d_100q в 12 раз меньше (48МБ). Дело в квантизации.Квантизация
Заменим 32-битные float-числа на 8-битные коды: [??, ?0.86) — код 0, [?0.86, -0.79) — код 1, [-0.79, -0.74) — 2, …, [0.86, ?) — 255. Размер таблицы уменьшится в 4 раз (143МБ).
Было:
-0.220 -0.071 0.320 -0.279 0.376 0.409 0.340 -0.329 0.400
0.046 0.870 -0.163 0.075 0.198 -0.357 -0.279 0.267 0.239
0.111 0.057 0.746 -0.240 -0.254 0.504 0.202 0.212 0.570
0.529 0.088 0.444 -0.005 -0.003 -0.350 -0.001 0.472 0.635
------ ------
-0.170 0.677 0.212 0.202 -0.030 0.279 0.229 -0.475 -0.031
------ ------
Стало:
63 105 215 49 225 230 219 39 228
143 255 78 152 187 34 49 204 198
163 146 253 58 55 240 188 191 246
243 155 234 127 127 35 128 237 249
--- ---
76 251 191 188 118 207 195 18 118
--- ---
Данные огрубляются, разные значения -0.005 и -0.003 заменяет один код 127, -0.030 и -0.031 — 118
Заменим кодом не одно, а 3 числа. Кластеризуем все тройки чисел из таблицы эмбеддингов алгоритмом k-means на 256 кластеров, вместо каждой тройки будем хранить код от 0 до 255. Таблица уменьшится ещё в 3 раза (48МБ). Navec использует библиотеку PQk-means, она разбивает матрицу на 100 колонок, каждую кластеризует отдельно, качество на синтетических тестах падёт на 1 процентный пункт. Понятно про квантизацию в статье Product Quantizers for k-NN.
Квантованные эмбеддинги проигрывают обычным по скорости. Сжатый вектор перед использованием нужно распаковать. Аккуратно реализуем процедуру, применим Numpy-магию, в PyTorch используем torch.gather. В Slovnet NER доступ к таблице эмбеддингов занимает 0.1% от общего времени вычислений.
Модуль
NavecEmbedding из библиотеки Slovnet интегрирует Navec в PyTorch-модели:>>> import torch
>>> from navec import Navec
>>> from slovnet.model.emb import NavecEmbedding
>>> path = 'hudlit_12B_500K_300d_100q.tar' # 51MB
>>> navec = Navec.load(path) # ~1 sec, ~100MB RAM
>>> words = ['навек', '<unk>', '<pad>']
>>> ids = [navec.vocab[_] for _ in words]
>>> emb = NavecEmbedding(navec)
>>> input = torch.tensor(ids)
>>> emb(input) # 3 x 300
tensor([[ 4.2000e-01, 3.6666e-01, 1.7728e-01,
[ 1.6954e-01, -4.6063e-01, 5.4519e-01,
[ 0.0000e+00, 0.0000e+00, 0.0000e+00,
...Nerus — большой синтетический датасет с разметкой морфологии, синтаксиса и именованных сущностей
В проекте Natasha анализ морфологии, синтаксиса и извлечение именованных сущностей делают 3 компактные модели: Slovnet NER, Slovnet Morph и Slovnet Syntax. Качество решений на 1–5 процентных пунктов хуже, чем у тяжёлых аналогов c BERT-архитектурой, размер в 50-75 раз меньше, скорость на CPU в 2 раза больше. Модели обучены на огромном синтетическом датасете Nerus, в архиве 700 000 новостных статей с CoNLL-U-разметкой морфологии, синтаксиса и именованных сущностей:
# newdoc id = 0
# sent_id = 0_0
# text = Вице-премьер по социальным вопросам Татьяна Голикова рассказала, в каких регионах России зафиксирована ...
1 Вице-премьер _ NOUN _ Animacy=Anim|C... 7 nsubj _ Tag=O
2 по _ ADP _ _ 4 case _ Tag=O
3 социальным _ ADJ _ Case=Dat|Degre... 4 amod _ Tag=O
4 вопросам _ NOUN _ Animacy=Inan|C... 1 nmod _ Tag=O
5 Татьяна _ PROPN _ Animacy=Anim|C... 1 appos _ Tag=B-PER
6 Голикова _ PROPN _ Animacy=Anim|C... 5 flat:name _ Tag=I-PER
7 рассказала _ VERB _ Aspect=Perf|Ge... 0 root _ Tag=O
8 , _ PUNCT _ _ 13 punct _ Tag=O
9 в _ ADP _ _ 11 case _ Tag=O
10 каких _ DET _ Case=Loc|Numbe... 11 det _ Tag=O
11 регионах _ NOUN _ Animacy=Inan|C... 13 obl _ Tag=O
12 России _ PROPN _ Animacy=Inan|C... 11 nmod _ Tag=B-LOC
13 зафиксирована _ VERB _ Aspect=Perf|Ge... 7 ccomp _ Tag=O
14 наиболее _ ADV _ Degree=Pos 15 advmod _ Tag=O
15 высокая _ ADJ _ Case=Nom|Degre... 16 amod _ Tag=O
16 смертность _ NOUN _ Animacy=Inan|C... 13 nsubj _ Tag=O
17 от _ ADP _ _ 18 case _ Tag=O
18 рака _ NOUN _ Animacy=Inan|C... 16 nmod _ Tag=O
19 , _ PUNCT _ _ 20 punct _ Tag=O
20 сообщает _ VERB _ Aspect=Imp|Moo... 0 root _ Tag=O
21 РИА _ PROPN _ Animacy=Inan|C... 20 nsubj _ Tag=B-ORG
22 Новости _ PROPN _ Animacy=Inan|C... 21 appos _ Tag=I-ORG
23 . _ PUNCT _ _ 20 punct _ Tag=O
# sent_id = 0_1
# text = По словам Голиковой, чаще всего онкологические заболевания становились причиной смерти в Псковской, Тверской, ...
1 По _ ADP _ _ 2 case _ Tag=O
2 словам _ NOUN _ Animacy=Inan|C... 9 parataxis _ Tag=O
...Slovnet NER, Morph, Syntax — примитивные модели. Когда в обучающей выборке 1000 примеров, Slovnet NER отстаёт от тяжёлого BERT-аналога на 11 процентных пунктов, когда примеров 10 000 — на 3 пункта, когда 500 000 — на 1.
Nerus — результат работы, тяжёлых моделей с BERT-архитектурой: Slovnet BERT NER, Slovnet BERT Morph, Slovnet BERT Syntax. Обработка 700 000 новостных статей занимает 20 часов на Tesla V100. Мы экономим время других исследователей, выкладываем готовый архив в открытый доступ. В SpaCy-Ru обучают на Nerus качественные русскоязычные модели для SpaCy, готовят патч в официальный репозиторий.
У синтетической разметки высокое качество: точность определения морфологических тегов — 98%, синтаксических связей — 96%. Для NER оценки F1 по токенам: PER — 99%, LOC — 98%, ORG — 97%. Для оценки качества мы размечаем SynTagRus, Collection5 и новостной срез GramEval2020, сравниваем эталонную разметку с нашей, подробнее в репозитории Nerus. Из-за ошибок в разметке синтаксиса встречаются циклы и множественные корни, POS-теги иногда не соответствуют синтаксическим рёбрам. Полезно использовать валидатор от Universal Dependencies, пропускать такие примеры.
Python-пакет Nerus организует удобный интерфейс для загрузки и визуализации разметки:
>>> from nerus import load_nerus
>>> docs = load_nerus('nerus_lenta.conllu.gz')
>>> doc = next(docs)
>>> doc
NerusDoc(
id='0',
sents=[NerusSent(
id='0_0',
text='Вице-премьер по социальным вопросам Татьяна Голикова рассказала, в каких регионах России ...',
tokens=[NerusToken(
id='1',
text='Вице-премьер',
pos='NOUN',
feats={'Animacy': 'Anim',
'Case': 'Nom',
'Gender': 'Masc',
'Number': 'Sing'},
head_id='7',
rel='nsubj',
tag='O'
),
NerusToken(
id='2',
text='по',
pos='ADP',
...
>>> doc.ner.print()
Вице-премьер по социальным вопросам Татьяна Голикова рассказала, в каких регионах России зафиксирована наиболее
PER------------- LOC---
высокая смертность от рака, сообщает РИА Новости. По словам Голиковой, чаще всего онкологические заболевания
ORG-------- PER------
...
?
>>> sent = doc.sents[0]
>>> sent.morph.print()
Вице-премьер NOUN|Animacy=Anim|Case=Nom|Gender=Masc|Number=Sing
по ADP
социальным ADJ|Case=Dat|Degree=Pos|Number=Plur
вопросам NOUN|Animacy=Inan|Case=Dat|Gender=Masc|Number=Plur
Татьяна PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
Голикова PROPN|Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing
рассказала VERB|Aspect=Perf|Gender=Fem|Mood=Ind|Number=Sing
...
>>> sent.syntax.print()
->-------- Вице-премьер nsubj
¦ ¦ ¦ ---> по case
¦ ¦ ¦ ¦ -> социальным amod
¦ ¦ L>L-L- вопросам nmod
¦ L---->-- Татьяна appos
¦ L> Голикова flat:name
--L--------- рассказала
¦ -------> , punct
¦ ¦ ---> в case
¦ ¦ ¦ -> каких det
¦ ¦ ->L-L- регионах obl
¦ ¦ ¦ L--> России nmod
L-->L-L----- зафиксирована ccomp
¦ -> наиболее advmod
¦ ->L- высокая amod
L>--L--- смертность nsubj:pass
¦ -> от case
L-->L- рака nmod
-> , punct
----L- сообщает
¦ L>-- РИА nsubj
¦ L> Новости appos
L----> . punct
Инструкция по установке, примеры использования, оценки качества в репозитории Nerus.
Corus — коллекция ссылок на публичные русскоязычные датасеты + функции для загрузки
Библиотека Corus — часть проекта Natasha, коллекция ссылок на публичные русскоязычные NLP-датасеты + Python-пакет с функциями-загрузчиками. Список ссылок на источники, инструкция по установке и примеры использования в репозитории Corus.
>>> from corus import load_lenta
# Находим в реестре Corus ссылку на Lenta.ru, загружаем:
# wget https://github.com/yutkin/Lenta.Ru-News-Dataset/...
>>> path = 'lenta-ru-news.csv.gz'
>>> records = load_lenta(path) # 2ГБ, 750 000 статей
>>> next(records)
LentaRecord(
url='https://lenta.ru/news/2018/12/14/cancer/',
title='Названы регионы России с\xa0самой высокой ...',
text='Вице-премьер по социальным вопросам Татьяна ...',
topic='Россия',
tags='Общество'
)
Полезные открытые датасеты для русского языка так хорошо спрятаны, что мало людей про них знает.
Примеры
Корпус новостных статей
Хотим обучить языковую модель на новостных статьях, нужно много текстов. Первым приходит в голову новостной срез датасета Taiga (~1ГБ). Многие знают про дамп Lenta.ru (2ГБ). Остальные источники найти сложнее. В 2019 году на Диалоге проходил конкурс про генерацию заголовков, организаторы подготовили дамп РИА Новостей за 4 года (3.7ГБ). В 2018 году Юрий Бабуров опубликовал выгрузку с 40 русскоязычных новостных ресурсов (7.5ГБ). Волонтёры из ODS делятся архивами (7ГБ), собранными для проекта про анализ новостной повестки.
В реестре Corus ссылки на эти датасеты помечены тегом «news», для всех источников есть функции-загрузчики:
load_taiga_*, load_lenta, load_ria, load_buriy_*, load_ods_*.NER
Хотим обучить NER для русского языка, нужны аннотированные тексты. Первым делом вспоминаем про данные конкурса factRuEval-2016. У разметки есть недостатки: свой сложный формат, спаны сущностей пересекаются, есть неоднозначная категориям «LocOrg». Не все знают про коллекцию Named Entities 5 наследницу Persons-1000. Разметка в стандартном формате, спаны не пересекаются, красота! Остальные три источника известны только самым преданным фанатам русскоязычного NER. Напишем на почту Ринату Гарееву, приложим ссылку на его статью 2013 года, в ответ получим 250 новостных статей с помеченными именами и организациями. В 2019 году проводился конкурс BSNLP-2019 про NER для славянских языков, напишем организаторам, получим ещё 450 размеченных текстов. В проекте WiNER придумали делать полуавтоматическую разметку NER из дампов Wikipedia, большая выгрузка для русского доступна на Github.
Ссылки и функции для загрузки в реестре Corus:
load_factru, load_ne5, load_gareev, load_bsnlp, load_wikiner.Коллекция ссылок
Перед тем как обзавестить загрузчиком и попасть в реестр, ссылки на источники копятся в разделе с Тикетами. В коллекции 30 датасетов: новая версия Taiga, 568ГБ русского текста из Common Crawl, отзывы c Banki.ru и Auto.ru. Приглашаем делиться находками, заводить тикеты со ссылками.
Функции-загрузчики
Код для простого датасета легко написать самому. Дамп Lenta.ru оформлен грамотно, реализация простая. Taiga состоит из ~15 миллионов CoNLL-U-файлов, запакованных в zip-архивы. Чтобы загрузка работала быстро, не использовала много памяти и не угробила файловую систему, нужно заморочиться, аккуратно на низком уровне реализовать работу с zip-файлами.
Для 35 источников в Python-пакете Corus есть функции-загрузчики. Интерфейс доступа к Taiga не сложнее, чем к дампу Lenta.ru:
>>> from corus import load_taiga_proza_metas, load_taiga_proza
>>> path = 'taiga/proza_ru.zip'
>>> metas = load_taiga_proza_metas(path)
>>> records = load_taiga_proza(path, metas)
>>> next(records)
TaigaRecord(
id='20151231005',
meta=Meta(
id='20151231005',
timestamp=datetime.datetime(2015, 12, 31, 23, 40),
genre='Малые формы',
topic='миниатюры',
author=Author(
name='Кальб',
readers=7973,
texts=92681,
url='http://www.proza.ru/avtor/sadshoot'
),
title='С Новым Годом!',
url='http://www.proza.ru/2015/12/31/1875'
),
text='...Искры улыбок...\n... затмят фейерверки..\n...
)
Приглашаем пользователей делать пулл-реквесты, присылать свои функции-загрузчики, короткая инструкция в репозитории Corus.
Naeval — количественное сравнение систем для русскоязычного NLP
Natasha — не научный проект, нет цели побить SOTA, но важно проверить качество на публичных бенчмарках, постараться занять высокое место, сильно не проиграв в производительности. Как делают в академии: измеряют качество, получают число, берут таблички из других статей, сравнивают эти числа со своими. У такой схемы две проблемы:
- Забывают про производительность. Не сравнивают размер модели, скорость работы. Упор только на качество.
- Не публикуют код. В расчёте метрики качества обычно миллион нюансов. Как именно считали в других статьях? Неизвестно.
Naeval — часть проекта Natasha, набор скриптов для оценки качества и скорости работы открытых инструментов для обработки естественного русского языка:
| Задача | Датасеты | Решения |
| Токенизация | SynTagRus, OpenCorpora, GICRYA, RNC |
SpaCy, NLTK, MyStem, Moses, SegTok, SpaCy Russian Tokenizer, RuTokenizer, Razdel |
| Сегментация предложений | SynTagRus, OpenCorpora, GICRYA, RNC |
SegTok, Moses, NLTK, RuSentTokenizer, Razdel |
| Эмбеддинги | SimLex965, HJ, LRWC, RT, AE, AE2 |
RusVectores, Navec |
| Анализ морфологии | GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga) |
DeepPavlov Morph, DeepPavlov BERT Morph, RuPosTagger, RNNMorph, Maru, UDPipe, SpaCy, Stanza, Slovnet Morph, Slovnet BERT Morph |
| Анализ синтаксиса | GramRuEval2020 (SynTagRus, GSD, Lenta.ru, Taiga) |
DeepPavlov BERT Syntax, UDPipe, SpaCy, Stanza, Slovnet Syntax, Slovnet BERT Syntax |
| NER | factRuEval-2016, Collection5, Gareev, BSNLP-2019, WiNER |
DeepPavlov NER, DeepPavlov BERT NER, DeepPavlov Slavic BERT NER, PullEnti, SpaCy, Stanza, Texterra, Tomita, MITIE, Slovnet NER, Slovnet BERT NER |
Дальше подробнее рассмотрим задачу NER.
Датасеты
Для русскоязычного NER существует 5 публичных бенчмарков: factRuEval-2016, Collection5, Gareev, BSNLP-2019, WiNER. Ссылки на источники собраны в реестре Corus. Все датасеты состоят из новостных статей, в текстах отмечены подстроки с именами, названиями организаций и топонимов. Что может быть проще?
У всех источников разный формат разметки. Collection5 использует Standoff-формат утилиты Brat, Gareev и WiNER — разные диалекты BIO-разметки, у BSNLP-2019 свой формат, у factRuEval-2016 тоже своя нетривиальная спецификация. Naeval приводит все источники к общему формату. Разметка состоит из спанов. Спан — тройка: тип сущности, начало и конец подстроки.
Типы сущностей. factRuEval-2016 и Collection5 отдельно помечают полутопонимы-полуорганизации: «Кремль», «ЕС», «СССР». BSNLP-2019 и WiNER выделяют названия событий: «Чемпионат России», «Брексит». Naeval адаптирует и удаляет часть меток, оставляет эталонные метки PER, LOC, ORG: имена людей, названия топонимов и организаций.
Вложенные спаны. В factRuEval-2016 спаны пересекаются. Naeval упрощает разметку:
Было:
Теперь, как утверждают в Х5 Retail Group, куда входят
org_name-------
Org------------
сети магазинов "Пятерочка", "Перекресток" и "Карусель",
org_descr----- org_name- org_name--- org_name
Org----------------------
org_descr-----
Org-------------------------------------
org_descr-----
Org--------------------------------------------------
о повышении цен сообщили два поставщика рыбы и
морепродуктов и компания, поставляющая овощи и фрукты.
Стало:
Теперь, как утверждают в Х5 Retail Group, куда входят
ORG------------
сети магазинов "Пятерочка", "Перекресток" и "Карусель",
ORG------ ORG-------- ORG-----
о повышении цен сообщили два поставщика рыбы и
морепродуктов и компания, поставляющая овощи и фрукты.
Модели
Naeval сравнивает 12 открытых решений задачи NER для русского языка. Все инструменты завёрнуты в Docker-контейнеры с веб-интерфейсом:
$ docker run -p 8080:8080 natasha/tomita-algfio
2020-07-02 11:09:19 BIN: 'tomita-linux64', CONFIG: 'algfio'
2020-07-02 11:09:19 Listening http://0.0.0.0:8080
$ curl -X POST http://localhost:8080 --data 'Глава государства Дмитрий Медведев и Председатель Правительства РФ Владимир Путин выразили глубочайшие соболезнования семье актрисы'
<document url="" di="5" bi="-1" date="2020-07-02">
<facts>
<Person pos="18" len="16" sn="0" fw="2" lw="3">
<Name_Surname val="МЕДВЕДЕВ" />
<Name_FirstName val="ДМИТРИЙ" />
<Name_SurnameIsDictionary val="1" />
</Person>
<Person pos="67" len="14" sn="0" fw="8" lw="9">
<Name_Surname val="ПУТИН" />
<Name_FirstName val="ВЛАДИМИР" />
<Name_SurnameIsDictionary val="1" />
</Person>
</facts>
</document>
Некоторые решения так тяжело запустить и настроить, что мало людей ими пользуется. PullEnti — сложная система, построенная на правилах, заняла первой место на конкурсе factRuEval в 2016 году. Инструмент распространяется в виде SDK для C#. Работа над Naeval вылилась в отдельный проект с набором обёрток для PullEnti: PullentiServer — веб-сервер на С#, pullenti-client — Python-клиент для PullentiServer:
$ docker run -p 8080:8080 pullenti/pullenti-server
2020-07-02 11:42:02 [INFO] Init Pullenti v3.21 ...
2020-07-02 11:42:02 [INFO] Load lang: ru, en
2020-07-02 11:42:03 [INFO] Load analyzer: geo, org, person
2020-07-02 11:42:05 [INFO] Listen prefix: http://*:8080/
>>> from pullenti_client import Client
>>> client = Client('localhost', 8080)
>>> text = 'Глава государства Дмитрий Медведев и ' ... 'Председатель Правительства РФ Владимир Путин ' ... 'выразили глубочайшие соболезнования семье актрисы'
>>> result = client(text)
>>> result.graph
Формат разметки у всех инструментов немного отличается. Naeval загружает результаты, адаптирует типы сущностей, упрощает структуру спанов:
Было (PullEnti):
Напомним, парламент Южной Осетии на состоявшемся 19 декабря
ORGANIZATION----------
GEO---------
заседании одобрил представление президента Республики
PERSON----------------
PERSONPROPERTY-------
Леонида Тибилова об отставке председателя Верховного суда
---------------- PERSON-----------------------
PERSONPROPERTY--------------
ORGANIZATION---
Ацамаза Биченова.
----------------
Стало:
Напомним, парламент Южной Осетии на состоявшемся 19 декабря
ORG------ LOC---------
заседании одобрил представление президента Республики
Леонида Тибилова об отставке председателя Верховного суда
PER------------- ORG------------
Ацамаза Биченова.
PER-------------
Результат работы PullEnti сложнее адаптировать, чем разметку factRuEval-2016. Алгоритм убирает тег PERSONPROPERTY, разбивает вложенные PERSON, ORGANIZATION и GEO на непересекающиеся PER, LOC, ORG.
Сравнение
Для каждой пары «модель, датасет» Naeval вычисляет F1-меру по токенам, публикует таблицу с оценками качества.
Natasha — не научный проект, для нас важна практичность решения. Naeval измеряет время старта, скорость работы, размер модели и потребление RAM. Таблица с результатами в репозитории.
Мы подготовили датасеты, завернули 20 систем в Docker-контейнеры и посчитали метрики для 5 других задач русскоязычного NLP, результаты в репозитории Naeval: токенизация, сегментация на предложения, эмбеддинги, анализ морфологии и синтаксиса.
Yargy-парсер — извлечение структурированное информации из текстов на русском языке с помощью грамматик и словарей
Yargy-парсер — аналог яндексового Томита-парсера для Python. Инструкция по установке, пример использования, документация в репозитории Yargy. Правила для извлечения сущностей описываются с помощью контекстно-свободных грамматик и словарей. Два года назад я писал на Хабр статью про Yargy и библиотеку Natasha, рассказывал про решение задачи NER для русского языка. Проект хорошо приняли. Yargy-парсер заменил Томиту в крупных проектах внутри Сбера, Интерфакса и РИА Новостей. Появилось много образовательных материалов. Большое видео с воркшопа в Яндексе, полтора часа про процесс разработки грамматик на примерах:
Обновилась документация, я причесал вводный раздел и справочник. Главное, появился Cookbook — раздел с полезными практиками. Там собраны ответы на самые частые вопросы из t.me/natural_language_processing:
- как пропустить часть текста;
- как подать на вход токены, а не текст;
- что делать, если парсер тормозит.
Yargy-парсер — сложный инструмент. В Cookbook описаны неочевидные моменты, который всплывают при работе с большими наборами правил:
У нас в лабе на Yargy работает несколько крупных сервисов. Перечитал код, собрал в Cookbook паттерны, которые не описаны в паблике:
- генерация правил;
- наследование fact (особенно полезно, ни одно решение на практике без этого приёма не обходится).
После прочтения документации полезно посмотреть репозиторий с примерами:
Ещё в проекте Natasha есть репозиторий natasha-usage. Туда попадает код пользователей Yargy-парсера, опубликованный на Github. 80% ссылок учебные проекты, но есть и содержательные примеры:
- разбор фида о работе метро в Спб;
- парсинг объявлений о сдаче жилья в соцсетях;
- извлечение атрибутов из названий авто покрышек;
- парсинг вакансий из канала jobs чата ODS;
Самые интересные кейсы использования Yargy-парсера, конечно, не публикуют открыто на Github. Напишите в личку, если компания использует Yargy и, если не против, добавим ваше лого на natasha.github.io.
Ipymarkup — визуализация разметки именованных сущностей и синтаксических связей
Ipymarkup — примитивная библиотека, нужна для подсветки подстрок в тексте, визуализации NER. Инструкция по установке, пример использования в репозитории Ipymarkup. Библиотека похожа на displaCy и displaCy ENT, бесценна при отладке грамматик для Yargy-парсера.
>>> from yargy import Parser
>>> from ipymarkup import show_span_box_markup as show_markup
>>> parser = Parser(...)
>>> text = '...'
>>> matches = parser.findall(text)
>>> spans = [_.span for _ in matches]
>>> show_markup(text, spans)
В проекте Natasha появилось решение задачи синтаксического разбора. Понадобилось не только выделять слова в тексте, но и рисовать между ними стрелочки. Существует масса готовых решений, есть даже научная статья по теме.
Конечно, ничего из существующего не подошло, и однажды я конкретно заморочился, применил всю известную магию CSS и HTML, добавил новую визуализацию в Ipymarkup. Инструкция по использованию в доке.
>>> from ipymarkup import show_dep_markup
>>> words = ['В', 'советский', 'период', 'времени', 'число', 'ИТ', '-', 'специалистов', 'в', 'Армении', 'составляло', 'около', 'десяти', 'тысяч', '.']
>>> deps = [(2, 0, 'case'), (2, 1, 'amod'), (10, 2, 'obl'), (2, 3, 'nmod'), (10, 4, 'obj'), (7, 5, 'compound'), (5, 6, 'punct'), (4, 7, 'nmod'), (9, 8, 'case'), (4, 9, 'nmod'), (13, 11, 'case'), (13, 12, 'nummod'), (10, 13, 'nsubj'), (10, 14, 'punct')]
>>> show_dep_markup(words, deps)
Теперь в Natasha и Nerus удобно смотреть результаты синтаксического разбора.





zodiak
Хотелось бы все-таки увидеть сравнение razdel с другими системами на текстах соц. сетей
alexanderkuk Автор
Для соцсетей нужно делать кастомное решение, использовать статистические методы, не правила
zodiak
>>Кажется, не существует датасетов с эталонной разметкой с текстами из соцсетей
Хотя бы на подкорпусе тайги, который выложен в Universal Dependencies
>>Понятно, что будет плохо. «Правила в Razdel оптимизированы для аккуратно написанных текстов с правильной пунктуацией»
Разумеется понятно. Но было бы здорово понимать что считать вариантом «б».