
В деле удалённого вызова процедур дела уже давно обстоят в точности как в известном комиксе «14 стандартов» — чего только тут ни напридумано: древние DCOM и Corba, странные SOAP и .NET Remoting, современные REST и AMQP (да, я знаю, что кое-что из этого формально не RPC, для того чтобы обсудить терминологию даже вот специальный топик недавно создали, тем ни менее всё это используется как RPC, а если что-то выглядит, как утка и плавает, как утка — ну, вы в курсе).
И конечно же, в полном соответствии со сценарием комикса, на рынок пришел Google и заявил что вот теперь наконец он создал ещё один, последний и самый правильный стандарт RPC. Google можно понять — продолжать в 21-ом веке гонять петабайты данных по старому и неэффективному HTTP+REST, теряя на каждом байте деньги — просто глупо. В то же время взять чужой стандарт и сказать «мы не смогли придумать ничего лучше» — совершенно не в их стиле.
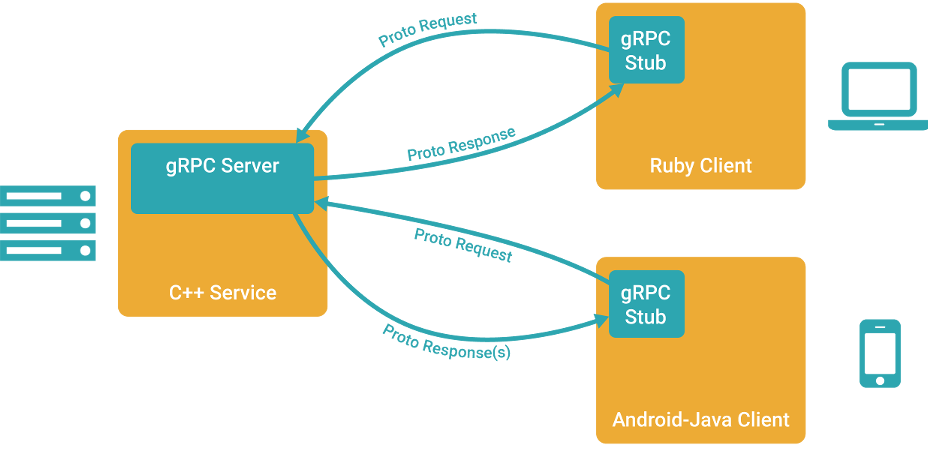
Поэтому, встречайте, gRPC, что расшифровывается как «gRPC Remote Procedure Calls» — новый фреймворк для удалённого вызова процедур от Google. В этой статье мы поговорим о том, почему же он, в отличии от предыдущих «14 стандартов» всё-таки захватит мир (ну или хотя бы его часть), попробуем собрать билд gRPC под Windows + Visual Studio (и даже не говорите мне, что инструкция не нужна — в официальной документации упущено штук 5 важных шагов, без которых ничего не собирается), а также попробуем написать простенький сервис и клиент, обменивающиеся запросами и ответами.
Зачем нужен ещё один стандарт?
Прежде всего давайте оглянемся вокруг. Что мы видим? Мы видим REST + HTTP/1.1. Нет, есть всякое, но именно эта туча закрывает добрых три четверти небосвода клиент-серверных коммуникаций. Присмотревшись ещё чуть пристальнее, мы видим, что REST в 95% случаев вырождается в CRUD.
В итоге мы имеем:
- Неэффективность протокола HTTP/1.1 — несжатые заголовки, отсутствие полноценной двусторонней связи, неэффективный подход к использованию ресурсов ОС, лишний трафик, лишние задержки.
- Необходимость натягивать нашу модель данных и событий на REST+CRUD, что часто получается, как воздушный шарик на глобус и вынуждает Яндекс писать вот такие, бесспорно, очень хорошие статьи, которые, однако, были бы не нужны, если бы людям не приходилось думать «Чем же вызвать заклинание для призыва элементаля — PUT'ом или POST'ом? И какой же HTTP-код вернуть, чтобы он означал „Перейдите на 3 клетки вперёд и тяните новую карту“ ?»
Именно с этого места и начинается gRPC. Итак, из коробки мы имеем:
- Protobuf в качестве инструмента описания типов данных и сериализации. Очень классная и хорошо зарекомендовавшая себя на практике штука. Собственно говоря, те, кому была нужна производительность — и раньше брали Protobuf, а дальше уже отдельно заморачивались транспортом. Теперь всё в комплекте.
- HTTP/2 в качестве транспорта. И это невероятно мощный ход! Вся прелесть полного сжатия данных, контроля трафика, инициации событий с сервера, переиспользования одного cокета для нескольких параллельных запросов — красотища.
- Статические пути — никаких больше «сервис/коллекция/ресурс/запрос? параметр=значение». Теперь только «сервис», а что внутри — описывайте в терминах вашей модели и её событий.
- Никакого привязывания методов к HTTP-методам, никакого привязывания возвращаемых значений к HTTP-статусам. Пишите, что хотите.
- SSL/TLS, OAuth 2.0, аутентификация через сервисы Google, плюс можно прикрутить свою (например, двухфакторную)
- Поддержка 9-ти языков: C, C++, Java, Go, Node.js, Python, Ruby, Objective-C, PHP, C# плюс, конечно, никто не запрещает взять и реализовать свою версию хоть для брейнфака.
- Поддержка gRPC в публичных API от Google. Уже работает для некоторых сервисов. Нет, REST-версии, конечно, тоже останутся. Но посудите сами, если у вас будет выбор — использовать, скажем, из мобильного приложения REST-версию, отдающие данные за 1 сек или с теми же затратами на разработку взять gRPC-версию, работающую 0.5 сек — что вы выберете? А что выберет ваш конкурент?
Сборка gRPC
Нам понадобитья:
- Git
- Visual Studio 2013 + Nuget
- CMake
Забираем код
- Забираем репозипорий gRPC с Гитхаба
- Выполняем команду
git submodule update --init
— это нужно для того, чтобы скачать зависимости (protobuf, openssl и т.д.).
Собираем Protobuf
- Переходим в папку grpc\third_party\protobuf\cmake и создаём там папку build, переходим в неё.
- Выполняем команду
cmake -G «Visual Studio 12 2013» -DBUILD_TESTING=OFF… - Открываем созданный на предыдущем шаге файл protobuf.sln в Visual Studio и собираем (F7).
На этом этапе мы получаем ценные артефакты — утилиту protoc.exe, которая понадобиться нам для генерации кода сериализации\десериализации данных и lib-файлы, которая будут нужны при линковке gRPC. - Копируем папку grpc\third_party\protobuf\cmake\build\Debug в папку grpc\third_party\protobuf\cmake.
Ещё раз — папку Debug нужно скопировать на 1 уровень выше. Это какая-то неконсистентность в документациях gRPC и Protobuf. В Protobuf говорится, что всё билдить надо в папке build, а вот исходники проектов gRPC ничего об этой папке не знают и ищут библиотеки Protobuf прямо в grpc\third_party\protobuf\cmake\Debug
Собираем gRPC
- Открываем файл grpc\vsprojects\grpc_protoc_plugins.sln и собираем его.
Если вы верно прошли сборку Protobuf на предыдущем этапе — всё должно пройти гладко. Теперь у вас есть плагины к protoc.exe, которые позволяют ему не только генерировать код сериализации\десериализации, но и добавлять в него функционал gRPC (собственно говоря, удалённый вызов процедур). Плагины и protoc.exe нужно положить в одну папку, например, в grpc\vsprojects\Debug. - Открываем файл grpc\vsprojects\grpc.sln и собираем его.
По ходу сборку должен запуститься Nuget и скачать необходимые зависимости (openssl, zlib). Если у вас нет Nuget или он почему-то не скачал зависимости — будут проблемы.
По окончанию билда у нас появятся все необходимые библиотеки, которые мы сможем использовать в нашем проекте для коммуникаций через gRPC.
Наш проект
Давайте напишем такой себе API для Хабрахабра с применением gRPC
Методы у нас будут такие:
- GetKarma будет получать строку с именем пользователя, а возвращать дробное число со значением его кармы
- PostArticle будет получать запрос на создание новой статьи со всеми её метаданными, а возвращать результат публикации — структуру со ссылкой на статью, временем публикации ну и текстом ошибки, если публикация не удалась
Это всё нам нужно описать в терминах gRPC. Это будет выглядеть как-то так (описание типов можно посмотреть в документации на protobuf):
syntax = "proto3";
package HabrahabrApi;
message KarmaRequest {
string username = 1;
}
message KarmaResponse {
string username = 1;
float karma = 2;
}
message PostArticleRequest {
string title = 1;
string body = 2;
repeated string tag = 3;
repeated string hub = 4;
}
message PostArticleResponse {
bool posted = 1;
string url = 2;
string time = 3;
string error_code = 4;
}
service HabrApi {
rpc GetKarma(KarmaRequest) returns (KarmaResponse) {}
rpc PostArticle(PostArticleRequest) returns (PostArticleResponse) {}
}
Переходим в папку grpc\vsprojects\Debug и запускаем там 2 команды (кстати, обратите внимание, в официальной документации в этом месте ошибка, неверные аргументы):
protoc --grpc_out=. --plugin=protoc-gen-grpc=grpc_cpp_plugin.exe habr.proto
protoc --cpp_out=. habr.proto
На выходе мы получим 4 файла:
- habr.pb.h
- habr.pb.cc
- habr.grpc.pb.h
- habr.grpc.pb.cc
Это, как не сложно догадаться, заготовки наших будущих клиента и сервиса, которые смогут обмениваться сообщениями по описанному выше протоколу.
Давайте уже создадим проект!
- Создаём в Visual Studio новый solution, назовём его HabrAPI.
- Добавляем в него два консольных приложения — HabrServer и HabrClient.
- Добавляем в них сгенерированные на предыдущем шаге h и сс-файлы. В сервер надо включать все 4, в клиент — только habr.pb.h и habr.pb.cc.
- Добавляем в настройках проектов в Additional Include Directories путь к папкам grpc\third_party\protobuf\src и grpc\include
- Добавляем в настройках проектов в Additional Library Directories путь к grpc\third_party\protobuf\cmake\Debug
- Добавляем в настройках проектов в Additional Dependencies библиотеку libprotobuf.lib
- Выставляем тип линковки таким же, с каким был собран Protobuf (свойство Runtime Library на вкладке Code Generation). В этом месте может оказаться, что вы не собрали Protobuf в нужной вам конфигурации, и придётся вернуться и пересобрать его. Я выбирал и там и там /MTd.
- Добавляем через Nuget зависимости на zlib и openssl.
Теперь у нас всё собирается. Правда, ничего пока ещё не работает.
Клиент
Здесь всё просто. Во-первых, нам нужно создать класс, унаследованный от заглушки, сгенерированной в habr.pb.h. Во-вторых, реализовать в нём методы GetKarma и PostArticle. В-третьих, вызывать их и, к примеру, выводить результаты в консоль. Получится как-то так:
#include <iostream>
#include <memory>
#include <string>
#include <grpc/grpc.h>
#include <grpc++/channel.h>
#include <grpc++/client_context.h>
#include <grpc++/create_channel.h>
#include <grpc++/credentials.h>
#include "habr.grpc.pb.h"
using grpc::Channel;
using grpc::ChannelArguments;
using grpc::ClientContext;
using grpc::Status;
using HabrahabrApi::KarmaRequest;
using HabrahabrApi::KarmaResponse;
using HabrahabrApi::PostArticleRequest;
using HabrahabrApi::PostArticleResponse;
using HabrahabrApi::HabrApi;
class HabrahabrClient {
public:
HabrahabrClient(std::shared_ptr<Channel> channel)
: stub_(HabrApi::NewStub(channel)) {}
float GetKarma(const std::string& username) {
KarmaRequest request;
request.set_username(username);
KarmaResponse reply;
ClientContext context;
Status status = stub_->GetKarma(&context, request, &reply);
if (status.ok()) {
return reply.karma();
} else {
return 0;
}
}
bool PostArticle(const std::string& username) {
PostArticleRequest request;
request.set_title("Article about gRPC");
request.set_body("bla-bla-bla");
request.set_tag("UFO");
request.set_hab("Infopulse");
PostArticleResponse reply;
ClientContext context;
Status status = stub_->PostArticle(&context, request, &reply);
return status.ok() && reply.posted();
}
private:
std::unique_ptr<HabrApi::Stub> stub_;
};
int main(int argc, char** argv) {
HabrahabrClient client(
grpc::CreateChannel("localhost:50051", grpc::InsecureCredentials(),
ChannelArguments()));
std::string user("tangro");
std::string reply = client.GetKarma(user);
std::cout << "Karma received: " << reply << std::endl;
return 0;
}
Сервер
С сервером похожая история — мы наследуемся от класса сервиса, сгенерированного в habr.grpc.pb.h и реализуем его методы. Дальше мы запускаем слушателя на определённом порту, ну и ждём клиентов. Как-то вот так:
#include <iostream>
#include <memory>
#include <string>
#include <grpc/grpc.h>
#include <grpc++/server.h>
#include <grpc++/server_builder.h>
#include <grpc++/server_context.h>
#include <grpc++/server_credentials.h>
#include "habr.grpc.pb.h"
using grpc::Server;
using grpc::ServerBuilder;
using grpc::ServerContext;
using grpc::Status;
using HabrahabrApi::KarmaRequest;
using HabrahabrApi::KarmaResponse;
using HabrahabrApi::PostArticleRequest;
using HabrahabrApi::PostArticleResponse;
using HabrahabrApi::HabrApi;
class HabrahabrServiceImpl final : public HabrApi::Service {
Status GetKarma(ServerContext* context, const KarmaRequest* request,
KarmaResponse* reply) override {
reply->set_karma(42);
return Status::OK;
}
Status PostArticle(ServerContext* context, const PostArticleRequest* request,
PostArticleResponse* reply) override {
reply->set_posted(true);
reply->set_url("some_url");
return Status::OK;
}
};
void RunServer() {
std::string server_address("0.0.0.0:50051");
HabrahabrServiceImpl service;
ServerBuilder builder;
builder.AddListeningPort(server_address, grpc::InsecureServerCredentials());
builder.RegisterService(&service);
std::unique_ptr<Server> server(builder.BuildAndStart());
std::cout << "Server listening on " << server_address << std::endl;
server->Wait();
}
int main(int argc, char** argv) {
RunServer();
return 0;
}
Удачи вам в использовании gRPC.
Комментарии (40)

deleted-lucky_brick
31.08.2015 18:05-5Мы тут с коллегой думали думали и придумали.
Гугл засчет написаного ими же бинарного транспорта для протобаф экономят трафик. Простой пример:
структура из 50 флагов. true это бит в бинарном транспорте, а в сжатом xml это все равно чуть больше потому что это в заголовке архива вся строка а дальше флаги по всему архиву.
учитывая что они посылают очень много таких структур в секунду… экономия трафика очевидна…
а морочиться с бинарным транспортом XML им просто не захотелось ну или они посчитали это костылем.
вот и изобрели свое… (это ж еще и маркетинг: «покупай мою шаверму»)
раньше у них не было самого RPC… и люди пользовались сомнительными решениями в своих протобаф-системах… ну теперь все будет энтерпразненько.
Rathil
01.09.2015 02:44Точно, взяли и придумали протобаф, потому что им было лень «морочиться». Остаётся только вопрос, а что было лень делать фейсбуковцам, когда они придумывали трифт?
И ещё, так, для справки, RPC был с первой версии протобафа ещё…
deleted-lucky_brick
31.08.2015 18:11-14Меня минусуют хипстеры =)
Докера вам с протобафом и шлюхами.
tangro
31.08.2015 19:29+6Я думаю вас минусуют потому, что вы пишете, во-первых, очевидные, а во-вторых, написанные во втором абзаце статьи вещи.

mkarev
31.08.2015 19:27+5пришел Google и заявил что вот теперь наконец он создал ещё один, последний и самый правильный стандарт RPC
Видимо, то же самое произошло, когда Google не устроил стандарт OpenCL для Android и родился «самый правильный» стандарт RenderScript.
igor_suhorukov
31.08.2015 22:00+3При том что под капотом используется OpenCL, но не выставляется как публичный API

igor_suhorukov
31.08.2015 22:02+4А есть ли возможность использовать другие варианты транспорта?

LeshiyUrban
31.08.2015 22:46+4Меня, честно говоря, тоже сильно напрягает протокол HTTP/2. Да, я знаю, что за ним будущее. Но после поверхностной оценки RFC для него, мне стало не очень ясно, как впихнуть его поддержку во все популярные языки?
Скажем, для базового уровня поддержки HTTP/1.0 нужна лишь базовая поддержка TCP и работа со строками в минимальном варианте. Это позволяет реализовать его хоть в IoT. С другой стороны, множественные потоки, приоритеты и т.п. ввергают меня в пучину ужаса, при мысли о том, как все это впихнуть в 32КБ памяти. А тот-же gRPC в этой области избавил бы от множества проблем…
Поэтому, также прошу знающих людей разъяснить момент с альтернативным транспортом прикладного уровня.tangro
01.09.2015 00:30Не так уж много нынче устройств с 32КБ на борту, в основном помощнее. А что касается поддержки в языках — понаписывают библиотек для всех. Да в принципе уже понаписывали. Ну, а то, что теперь телнетом к серверу не приконектишься запросик-другой написать, это да, слишком сложно теперь. Но это уж с любой технологией так — либо просто, либо эффективно.
igor_suhorukov
01.09.2015 00:35В low latency мире выбор транспорта — решает многое! В grpc отличная реализация IDL сервисов и структур данных на основе protobuf
tangro
01.09.2015 00:27+1Ну, если из gRPC убрать транспорт — останется голый Protobuf, сериализуйте себе данные на здоровья и гоняйте как хотите.

mialinx
31.08.2015 23:25+2А что на счет отладки?
Сделать запрос из telnet?
Кинуть коллеге запрос «Copy-as-curl»?
Посмотреть сниффером что там ходит по сети?
Научным тыком исследовать плохо (не) документированное API?
Отдельным пунктом:
Одно API для браузера (JS) и всего остального?tangro
01.09.2015 00:37Отладка чего именно? Гугловского транспорта? А как будто вы сейчас можете отладить, что, скажем внутри браузерного XMLHTTPRequest происходит. Вам приходит строка результата — вы её анализируете. А тут будет приходить сразу структура — отлаживайте себе.
Запрос из телнет — нет, никак. Наверняка будет что-то типа конструктора пакетов.
«Copy-as-curl» — я уверен, что в curl добавят поддержку HTTP/2. Ну или форк будет.
«Посмотреть сниффером что там ходит по сети? » — посмотрите на Wireshark c его системой плагинов — расшифровывает всё, что угодно. И для этого будет плагин.
«Научным тыком исследовать плохо (не) документированное API?» — а с протобафом не может быть «плохо документированного API». Если у вас есть proto-файл, то у вас есть все методы, параметры и ответы. Если у вас его нет — вы ничего не сделаете в любом случае.
«Одно API для браузера (JS) и всего остального?» — с приходом в EcmaScript полноценных классов, бинарных буферов, а в браузеры — HTTP/2, вскоре появится и поддержка gRPC.
lair
01.09.2015 01:07А вы думаете, что методы, параметры и ответы — это документация? Нет, это всего лишь интерфейс (даже не контракт). И в вопросах исследования «методом тыка» текстовые протоколы легче бинарных.
tangro
01.09.2015 09:52Я не очень понимаю что такое «исследование методом тыка». Если это от начала до конца ваша система — вы сами себе проектируете и документируете интерфейсы как хотите. Если вы используете чей-то публичный API — у него будет описание, иначе это не публичный API, а хрень какая-то. Если вы реверсите чужой трафик между компонентами, куда в теории никто не должен вклиниваться — так это никогда не было простым делом и там всегда была нужна какая-то расшифровка, декомпрессия, дизасамблирование клиента или сервера и т.д.
lair
01.09.2015 11:12К сожалению, все далеко не так прекрасно. Публичные API оказываются недодокументированными. От своих собственных API, разработанных год назад, документация утеряна, код нечитаем, разбирайся, как хочешь. Два ближайших интегратора не могут понять формализованное описание и просят примеры, которые они могут запустить через SoapUI/curl. Два других интегратора все «понимают», но шлют фигню, единственный способ разобраться с которой — это поймать ее на лету и посмотреть, что же в ней не так.

ComodoHacker
01.09.2015 09:31Надеюсь, вы сообщили об ошибках в документации авторам?
tangro
01.09.2015 09:54У них своё виденье «ошибок». К примеру, если C++ код собирается под gcc, но не собирается под винду — они это ошибкой не считают. Точно также не являются ошибкой по их мнению отсутствие в пошаговой инструкции пунктов, которые находятся в других документах (которые могут быть даже в других репозиториях) или пункты, которые написаны туманно, но объясняются в темах на форуме.

JC_Piligrim
01.09.2015 23:25Все эти игрушки тупо копируют друг друга вместо того чтобы предлагать киллер-фичи. Что это, что Thrift, что ещё куча rpc не умеют простую вещь — чтобы когда 2 проги соединялись друг с другом можно было дёргать функции и слать сообщения из одной в другую, и неважно, кто из них к кому подцепился — чтобы каждый был и клиентом и сервером. Сейчас такое можно только через гемор с программированием на сокетах иметь, либо AMQP. А вот чтобы both-direction RPC из коробки с сериализацией объектов между экосистемами (C#, Java, ObjC, Javascript, Python, Ruby, C) — есть ли где-то такое вообще?
mayorovp
02.09.2015 06:03Да, есть. SOAP over MQ. Или любая другая реализация RPC over MQ.
JC_Piligrim
02.09.2015 16:13Киньте ссылкой, пожалуйста, на конкретную реализацию. Потому что тот же Thrift over MQ очень крутая затея, но требующая писать всю имплементацию ручками. Есть что-нибудь уже готовое, чтобы «взял и заюзал»?
tangro
02.09.2015 19:31gRPC это умеет: «gRPC supports streaming semantics, where either the client or the server (or both) send a stream of messages on a single RPC call. The most general case is Bidirectional Streaming where a single gRPC call establishes a stream where both the client and the server can send a stream of messages to each other. The streamed messages are delivered in the order they were sent.»

speakingfish
02.09.2015 20:17Тоже копал в эту сторону. В результате пока сделал обмен через стандартные пайпы ввода-вывода на Java/C++/Pascal Linux/Windows intel/ARM. Но у меня пока синхронный rpc. Делал для простого разделения на процессы, миграции по частям, заворачивания ненадёжных dll в перезапускаемые процессы… Пока в планах стыки на javascript и python. Вообще, дальше в планах добавить к этому shared memory для текущего обрабатываемого пула данных на memory-mapped файлах, чтобы в части случаев не просто сократить передачу данных через пайпы но и вообще избежать её.

Balek
02.09.2015 20:52Некоторые имплементации JSON-RPC это умеют. А ещё лучше взгляните на WAMP.

aleks_raiden
02.09.2015 22:43вот на WAMP смотреть не надо как раз — из первой версии, идеально простой и понятной, он эволюционировал во вторую — которую мало кто поддерживает и монструозно-непонятную фигню
JC_Piligrim
03.09.2015 02:04А чем вторая хуже первой?
И какую альтернативу вы видите?
Требования:
1. Сериализация между C#/.NET, Python, Javascript, PHP, Java, ObjC
2. Двухсторонний RPC между тем, кто подключился, и тем, к кому подключились с киданием засериализованных структур и автоматической десериализацией в нативные структуры.
Balek
03.09.2015 09:00Сегодня же куча реализаций уже есть: wamp.ws/implementations. Монструозность обусловлена только сложностью задачи, потому что WAMP не взваливает огромное количество смежных подзадач на программиста, а решает их сам. К тому же протокол разбит на две части: basic и advanced.
aleks_raiden
03.09.2015 09:05в том и дело — то по сути, задача тривиальная, и первой версией решалась на ура. Вторая все испортила. И да, качество этих реализаций для разных платформ очень разное. JS библиотек только две, с поддержкой сложно, РНР только одна и то плохо поддерживаемая и без документации
mayorovp
Если убрать Protobuf и поддержку в веб-сервисах гугла — получатся обычные веб-сервисы. Поэтому перед тем, как использовать очередной нестандартный стандарт в своем проекте, я бы посоветовал вспомнить про WS и SOAP — если, конечно, серверная часть своя.
shamanis
Можно отказаться от SOAP во пользу JSON-RPC. Меньше ненужного трафика, который есть в XML из-за тегов, ибо тег может быть огромным, а содержаться в нем может одна цифра. А вообще, мне уже давненько не нравится технология/архитектура RPC.