
Чуть больше года назад я столкнулся с тем, что на внутреннем проекте совсем не айтишной компании вырос целый отдел веб-разработки, которым мне и довелось руководить. Рабочий процесс вроде как устаканился и всех устраивал, но оставались проблемы:
- Проверка каждой ветки проходила локально. Приходилось откатывать базу от изменений с предыдущей проверки, билдить фронт. Когда несколько разработчиков вот-вот закончат работы и осталось проверить каждую по мелочи — это превращалось в ад;
- Различались окружения на проде и между разработчиками, что приводило к ошибкам: “у меня всё работает”.
Внутренний перфекционист жаждал организовать всё правильно. Делюсь результатами поисков ответа на вопрос: «а как, собственно, “правильно”»?
Мы добились
- Легкого и быстрого деплоя в production (ради эксперимента выводили каждый день две недели подряд);
- Гарантию защищённости от ошибок из-за различий в окружении приложения;
- Можем организовать эффективное взаимодействие с заказчиком:
- демонстрировать каждую feature-ветку;
- давать гостевой доступ для создания задач и наблюдения над ходом работ.
Данная статья будет полезна, если вы:
- начинающая IT-компания или в первый раз столкнулись с работой в команде над большим проектом;
- хотите обновить свой устаревший процесс разработки (workflow);
- ищете лучшие практики и хотите посмотреть, как у других;
- часто натыкаетесь на статьи про DevOps, CI/CD, облака и хотите, чтобы у вас одним нажатием кнопки создавались тестовые окружения, а очередное обновление прода не было рулеткой.
Под катом вы найдёте
- типовой рабочий процесс от постановки задач до релиза;
- инфраструктурное решение для построения любого современного процесса разработки с использованием минимального количества инструментов;
- пример для часто встречающегося кейса: разработка веб-приложения;
- видеозапись доклада, где вживую показывается результат.

Статья состоит из трех частей:
- Моё видение типичного процесса разработки;
- Инфраструктура для реализации любого современного рабочего процесса;
- Кейс для веб-разработки.
Поиск информации, актуальность вопроса
В процессе поиска лучших практик находилось много теории по методологиям, разным инструментам, но всё разрозненно. Не было чего-то, что показывало бы единый процесс, как он выглядит со стороны менеджера, разработчика и системного администратора (а-ля DevOps).
Например статьи, где абстрактно рассуждают о процессе разработки, оставляют открытыми вопросы: “ок, хорошо, так а с помощью каких инструментов это можно сделать?”.
Не хватает реального практического примера по реализации некоего “базового” процесса, от которого уже можно было бы строить собственный. Видимо, авторами статей он считается очевидным. Напрашивается вариант перенять опыт крупных компаний или нанять человека с таким опытом, но такой подход может оказаться неэффективным. Ведь у крупной компании инфраструктура скорее всего заточена под задачи гораздо сложнее ваших текущих потребностей и требует много ресурсов и знаний для её реализации.
В конце концов, я пересмотрел большое количество связанных с данной темой материалов, ознакомился с различными инфраструктурными инструментами, пропустил всё через собственный опыт. При реализации прошёлся по всем граблям, о которых в официальной документации было сказано мало, но грабли должны были быть пройдены во имя “best practices”. Также понадобилось время по наладке работы отдела по-новому.
И, хотя данный опыт был получен уже как год назад, гугл показывает, что ещё не появилось гайда, который я искал когда-то.
Итак, приступим.
Вам понадобится:
- Наличие каких-либо мощностей в распоряжении. Может быть свой сервер, а может быть и облачная инфраструктура;
- Знание вашего приложения, как оно работает, как сейчас разворачивается;
- Базовые знания сетей, git, Linux, Docker, GitLab, Traefik.
Типичный процесс разработки
Обязательные составляющие
1. Работа по классической модели в git

A successful Git branching model by Vincent Driessen
Необходимый минимум — иметь ветки: master, dev и feature.
Feature
В каждой feature-ветке ведется работа над каждым отдельным функционалом / исправлениями, создаются от dev-ветки. Прекращают существование после того, как изменения вольются в dev.
Dev
В dev происходит окончательная совместная отладка и тестирование всех новых изменений, после этого производится релиз в master.
Master
От этой ветки и происходит релиз на production-сервер. Также, при необходимости срочных исправлений, от неё создаются hotfix-ветки, вливаются в неё же и удаляются.
Master и dev защищены от прямых пушей, существуют всегда.
2. Совместная работа в трекере задач. Документация всех принятых решений.

Это очень важный момент. При переключении между несколькими feature ветками, программисты теряют контекст буквально на следующий день. Записать задачу с невысоким приоритетом в виде “глянуть, что не так с xxx” недостаточно, чтобы вспомнить, о чем идёт речь. Все замечания необходимо фиксировать в обсуждениях Merge Request-а данной ветки. Необходимо вести wiki проекта, чтобы ускорить адаптацию новичков и утверждать принятые решения.
Важно всегда помнить, что если что-то не записано — этого не существует.
Крайней степенью документирования может служить опыт GitLab, которая была компанией без офиса ещё до того, как это стало мейнстримом пандемии.
3. Автоматизация инфраструктуры для тестирования и релизов
Всё просто — чем быстрее вы можете выводить свои решения в продакшн, тем они надёжнее и вы конкурентоспособнее. Часто можно встретить статьи, где измеряется количество релизов в месяц/неделю/день.
Я считаю, что это и послужило катализатором развития всех современных IT-гигантов и то, что сформировало DevOps. Сперва они автоматизировали процесс тестирования и выкатки своего монолита. Появилась проблема ожидания и невозможности локально развернуть окружение для разработки. Решением стала идея микросервисной архитектуры, что принесло новые проблемы. Где-то тут появилась контейнеризация (LXC), затем Docker, оркестраторы и понеслось...
Функциональные роли
При совместной работе необходимо понимать, кто за что ответственный. Прошу обратить внимание, что это именно функциональные роли, а не должности. То есть, один человек может совмещать в себе несколько функциональных ролей. Уверен, в каждом проекте эти функции выполняются в какой-то мере, даже если об этом не подозревают. Привожу своё понимание, поскольку во многих статьях пишут так, будто все сразу родились со знанием, кто есть кто.
Менеджер проекта
Общается с ключевыми лицами заказчика, начальством, определяет ключевые показатели, ведёт документооборот, решает все финансовые и кадровые вопросы, занимается продвижением продукта — сам или взаимодействуя с другими отделами компании. Отвечает за коммерческий результат, прессует владельца продукта.
Владелец продукта
Представляет себе общий образ продукта, чем он должен стать, какие ценности нести для клиента. Ведет бэклог (список задач) продукта, определяет приоритеты задач, знает о всех функциях продукта, также, до определённой степени, с технической стороны. Должен иметь опыт разработки. Именно тот человек, который должен сказать, что “людей не хватает”. Ограждает команду от прессинга начальства.
Аналитик / Технический писатель
Всегда находится рядом с конечным пользователем продукта, изучает бизнес-процессы заказчика, собирает обратную связь после внедрения каждой фичи. Можно сказать, информатор владельца продукта, помогает формировать техническое задание. Также должен знать о всех функциях продукта. Участвует в обучении клиента, написании документации для передачи заказчику.
Дизайнер UI/UX
Ответственный за то, чтобы пользователям было удобно работать с продуктом. Критически важный элемент успеха (если вы не Microsoft, конечно).
Архитектор
Скорее всего работает на нескольких проектах. Самый опытный разработчик в компании. Консультирует тимлида.
Тимлид
Опытный разработчик, консультирует владельца продукта, оценивает трудоёмкость задач, распределяет их между разработчиками, занимается их дальнейшей декомпозицией и проработкой с технической стороны. Проводит финальную приёмку готовых работ.
Разработчик
Пишет и документирует код. Проводит код-ревью коллег.
Разработчики специализируются на своих направлениях: бэкенд, фронтенд, мобильная разработка и т.д., в зависимости от проекта.
Тестировщик (QA / QC)
Quality Control (QC) тестирует продукт. Как вручную, так и с помощью написания кода. Quality Assurance (QA) также участвует в разработке архитектуры и инфраструктуры проекта, чтобы получение качественного результата закладывалось в процессе производства (Дао Toyota — принцип встраивания качества). К примеру, тестировать именно тот docker-образ, который и будет выкачен на продакшн, а не пересобирать его после тестов.
Системный администратор (DevOps)
Как и архитектор, скорее всего работает на нескольких проектах. Создаёт инфраструктуру при старте проекта, вносит изменения по ходу его развития.
Процесс разработки
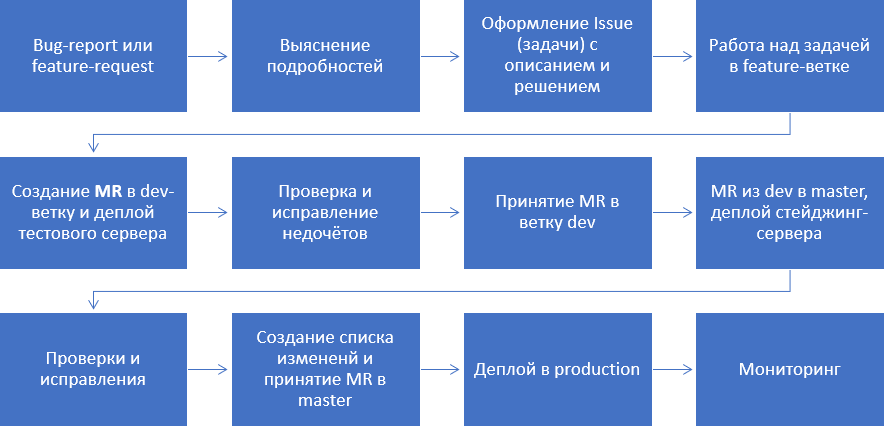
Этапы workflow
- Любая задача начинается с появления потребности в каком-то улучшении (feature) или отчёта об ошибке, которая сообщается владельцу продукта. Происходит фиксация в трекере.
- Владелец продукта сам или с помощью аналитика выясняет все подробности. Всё записывается в задачу. Проводится первичная оценка трудоёмкости. Определяются приоритеты, возможно уже ставится в план работ.
- Когда подходит время реализации, совместно с тимлидом производится декомпозиция (разбиение на подзадачи), определяются исполнители, совместно с ними она проговаривается, фиксируются достаточные для исполнителей описания по реализации. Если требуются уточнения по задаче — обращаются к владельцу продукта.
- Создаётся feature-ветка из dev и, собственно, пишется код. Если задача большая и состоит из подзадач, то выделяется основная feature-ветка, в которую вливаются ветки подзадач. Пишутся тесты, если для этой задачи было принято такое решение.
Примечание: для того, чтобы минимизировать конфликты при слияниях веток, необходимо, чтобы архитектура вашего приложения поддерживала минимальную связанность модулей. А также не стоит начинать работать над задачей, реализация которой приходится на тот же самый участок кода, который изменен в другой задаче, но по ней ещё не принят merge-request.
- Создаётся merge-request в dev-ветку, производится сборка, тестирование и деплой feature-ветки.
- Проводится ревью кода другими разработчиками, ручное тестирование. При наличии недочётов — снова авто-тесты, деплой, повторная проверка.
- Тимлид проводит финальную проверку и принимает готовую feature-ветку в dev.
- Когда приходит время очередного релиза, из dev-ветки со всеми последними изменениями создаётся merge-request в master и аналогичные пунктам 5, 6 действия.
- Аналогично пункту 7, возможно привлекается владелец продукта.
- Очень полезно сообщать пользователям, какие произошли изменения (формирование changelog-а), а также обновлять справку по продукту. Обновляем документацию и принимаем изменения в мастер.
- Автоматически или вручную, выкатываются изменения в production.
- Ведётся мониторинг приложения. В данной статье не рассмотрен.
Инфраструктура
При выборе инструментов использовались критерии:
- production-ready
- большое комьюнити
- невысокий порог входа относительно других инструментов
- как можно меньшее их количество (больше функциональности у каждого)
Итогом стал выбор технологий: Traefik, GitLab и Docker.
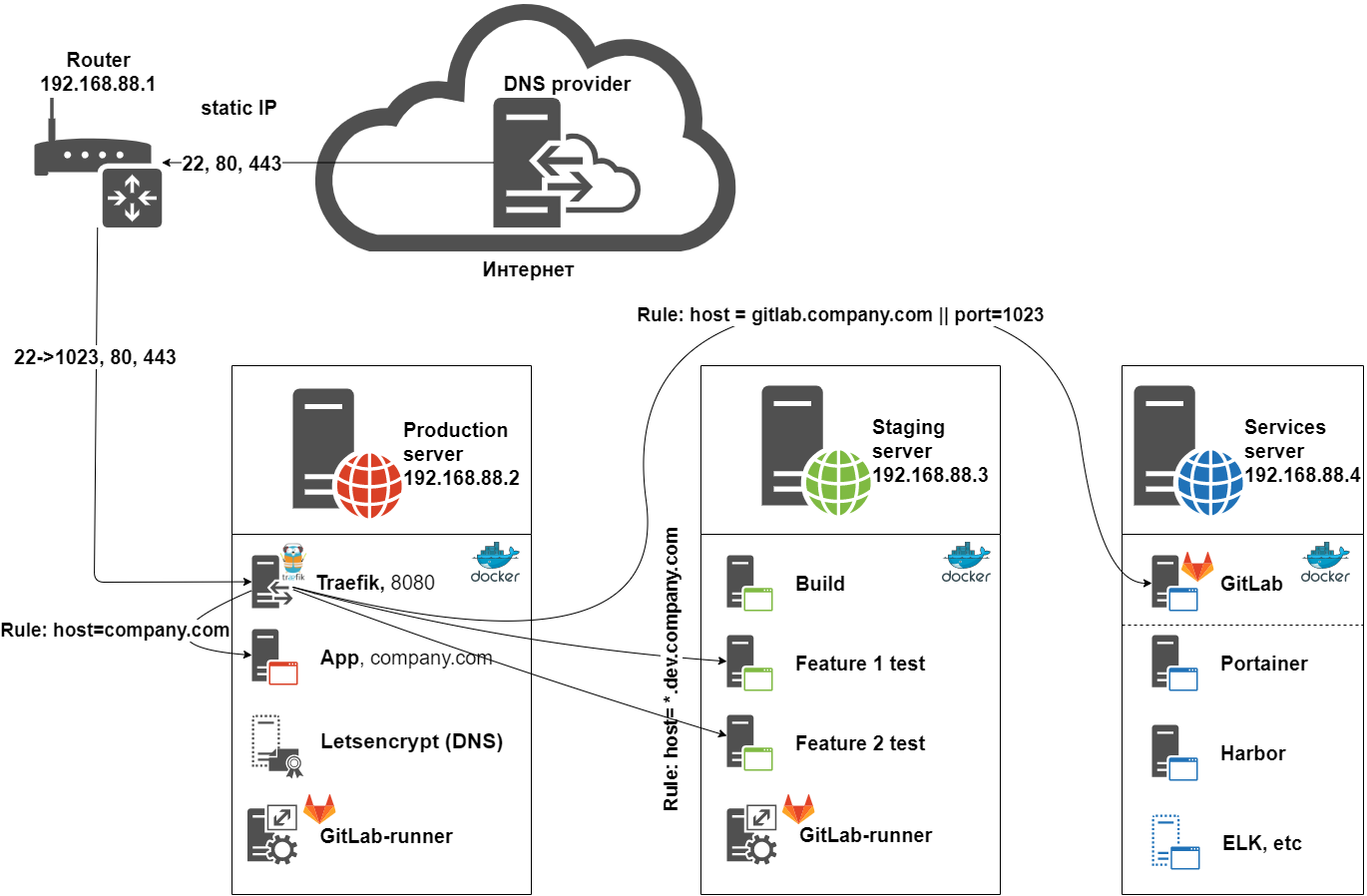
- Используется 3 сервера [Production], [Staging] и [Services]. Могут быть физическими или виртуальными машинами, количество может быть меньше и больше, может быть всё в облаке. Приведена наиболее эффективная конфигурация с точки зрения надёжность/цена. Главное, чтобы [Production] был отдельным и самым надёжным. На сервере [Services] установлен GitLab а также второстепенные сервисы (мониторинг, docker registry: Portainer, ELK, Harbor, etc), которые и будем называть Services. В данном примере их настройка не рассматривается. Все приложения работают в Docker-контейнерах. GitLab лучше установить отдельно, зависит от располагаемых мощностей.
- Traefik собирает информацию о запущенных динамических DNS-именах для
*.dev.company.ru, подключившись к докеру [Staging] по TCP и предоставляет к ним доступ. Также автоматически получает SSL сертификаты для приложения на [Production]. Wildcard (WC) сертификат*dev.company.ruполучается с помощью отдельного контейнера letsencrypt-dns, если ваш DNS-провайдер не поддерживается в Traefik. Traefik использует этот или самостоятельно полученный сертификат, обрезает SSL от клиентов и перенаправляет http запросы по доменным именам на соответствующие сервисы. Работает на [Production] вместе с основным приложением App. - GitLab на [Services] с помощью GitLab-runner-ов, установленных на остальных ВМ, по Merge Request-ам (МР) на ветки dev и master, управляет запущенными докер-образами на [Staging] и [Production] согласно файлам .gitlab-ci.yml проектов.
- Сборка, тест и стейджинг происходят на [Staging].
- В данном решении GitLab также работает как Docker Registry, где хранятся собранные образы приложений.
- Сами GitLab, Traefik и Gitlab-runner-ы также работают в docker-контейнерах, что позволяет легко обновлять и переносить инфраструктуру.
Привожу ссылку на github-репозиторий, в котором пошагово описан процесс создания данной инфраструктуры. Дабы не раздувать ещё больше этот лонгрид, прошу читать их там:
https://github.com/Akkarine/demo_cicd
Предупреждение
- Данное инфраструктурное решение является скорее стартовой площадкой для понимания основных принципов, нагрузочных тестирований не проводилось. Очень многое зависит от железа и архитектуры приложения. Для больших нагрузок, повышения надёжности и работы в облаке рекомендуется рассмотреть Enterprise версии Traefik и GitLab и воспользоваться консультациями специалистов.
- В репозитории содержатся части конфигурации, которые очевидно нужно будет изменить под себя. Например, временная зона, почтовые адреса, домены и т.п.
- Так как работа была проведена год назад, Traefik и GitLab заметно развились за это время и уже многие вещи можно оптимизировать. Так, Traefik уже поддерживает DNS Yandex (не без моего скромного участия) и больше не нужен промежуточный сервис. А в GitLab появились более гибкие возможности конфигурирования. Например, rules.
- Также стоит обратить внимание на секцию “Что можно сразу улучшить”.
Кейс для веб-разработки
https://github.com/Akkarine/demo_cicd_project
Пример приводится для небольшого веб-приложения, также для понимания основных принципов, так как предполагает:
- Недоступность приложения при обновлениях. Для организации выкатки без downtime потребуется поддержка со стороны кода приложения (версионность API бэкенда, поэтапные миграции БД), более сложные настройки load-balancer-а и алгоритма выкатки, а в идеале — переход на другой уровень инфраструктуры — kubernetes. Так что это уже далеко не уровень “для начинающих”
- Запуск базы данных в докере (влияет на производительность)
- Копирование production-базы данных для стейджинга (конфиденциальность данных, проблемы при большой базе)
- Вызов команд от root в контейнерах (совершенно не лучшая практика)
Самое главное в репозитории — файл .gitlab-ci.yml. Рассмотрим стадии pipeline-а и входящие в них задачи на соответствие шагам в рабочем процессе:
- base-img-rebuild
- rebuild-base-backend
Для ускорения сборка разбита на два этапа. На текущем — первом, строится базовый образ, который будет запускаться только при изменении файлов с описанием зависимостей. Во втором (стадия build), уже самого приложения.
- rebuild-base-backend
- rebuild-dev-db
- rebuild-dev-db
В данной задаче подготавливается общий образ базы данных для тестовых веток с бэкапом базы данных, развёрнутой прямо внутри образа.
- rebuild-dev-db
- build
- rebuild-proxy-img
Так как образ прокси-сервера nginx будет обновляться крайне редко, то данный образ можно сразу создавать с тэгом latest - build-backend
Происходит сборка приложения с текущими изменениями, пока тегируется номером задачи (уникально для всего GitLab)
- rebuild-proxy-img
- test
- testing
Запуск автоматических тестов
- testing
- deploy-review
- deploy_review
Поднимается тестовый сервер, практически идентичный production, только с конфигурациями серверов, менее агрессивными к ресурсам.
- deploy_review
- skip_review
Используется для того, чтобы пропустить создание тестового сервера, если он на данном этапе разработки не нужен. - review
- approve-dev
Вызывается вручную. Когда Merge-request идёт в dev (т.е. текущая ветка — feature), то можно не нажимать. Задача просто для зелёной галочки на пайплайне. - approve-staging
Вызывается вручную. Когда Merge-request идёт в master (т.е. текущая ветка — hotfix или dev и идёт релиз), то протестированный образ с этапа build тегируется latest и заменяет предыдущую версию в репозитории. Для того, чтобы не затёрлась следующей latest версией, также заливается и с тэгом — номером задачи. - reject
Вызывается вручную. Просто отображает красный крест на пайплайне. Так из списка Merge Request-ов будет видно, что с данной веткой что-то не так. - stop_review
Может быть вызвана как автоматически, так и вручную. Останавливает поднятый тестовый сервер.
- approve-dev
- rebuild-approved-db-img
- rebuild-approved-db-img
Если review был успешен и было обновление файлов в контексте создания образа БД, то создаётся новый образ с меткой latest и заливается в репозиторий.
- rebuild-approved-db-img
- deploy-prod
- deploy-production
На проде делается бэкап базы данных и обновляются контейнеры до latest. Если бэкап был неудачен, выкатка не происходит. - deploy-production-wo-containers
В случае, если не поднята базы данных для бэкапа, пропускается это действие.
- deploy-production
- clear
Происходит очистка серверов staging и production от хлама
- clean-staging
- clean-prod
- restore-db
- restore-db
Для первого деплоя или крайне неудачного обновления — восстанавливает базу данных из бэкапа.
- restore-db
И в заключение привожу видео митапа в феврале этого года, где показывается результат вживую. В части с экраном чуть рассинхрон с рассказом — пришлось потом повторить, забыл включить запись. Первое выступление на публике, волновался.
Материалы
Traefik
Альтернативный вариант reverse proxy + SSL на nginx
- https://habr.com/ru/post/328048/
- https://habr.com/ru/post/445448/
- https://github.com/jwilder/nginx-proxy
- https://github.com/JrCs/docker-letsencrypt-nginx-proxy-companion
GitLab
GitLab SSL config
- https://docs.gitlab.com/omnibus/settings/ssl.html
- Конфигурация за reverse-proxy https://docs.gitlab.com/omnibus/settings/nginx.html#supporting-proxied-ssl
GitLab Registry
- https://docs.gitlab.com/ce/administration/container_registry.html#configure-container-registry-under-its-own-domain
- Удаление образов: https://docs.gitlab.com/omnibus/maintenance/#container-registry-garbage-collection
Gitlab-runner
- Установка с помощью образа докера
- https://docs.gitlab.com/runner/install/docker.html
- Использование Docker Executor https://docs.gitlab.com/runner/executors/docker.html
- Использование SSH Executor https://docs.gitlab.com/runner/executors/ssh.html
- Регистрация раннера https://docs.gitlab.com/runner/register/index.html#docker
- Создание образов Docker с помощью GitLab CI/CD https://docs.gitlab.com/ce/ci/docker/using_docker_build.html
- Создание образов Docker внутри Docker без использования priveleged mode и кэшированием в registry
(полезно для работы в облаке) https://docs.gitlab.com/ce/ci/docker/using_kaniko.html - Пригодится для создания файла конфигурации https://docs.gitlab.com/runner/configuration/advanced-configuration.html
- CLI https://docs.gitlab.com/runner/commands/README.html
Docker
- Действия после установки https://docs.docker.com/install/linux/linux-postinstall/
- docker-compose файл https://docs.docker.com/compose/reference/overview/
- Полезно использовать при отладке https://docs.docker.com/compose/reference/config/
- Подключение к удаленному Docker с сертификатами (TCP + TLS): https://docs.docker.com/engine/security/https/
Прочее полезное
Анализ докер-образов: https://github.com/wagoodman/dive
# Команда для анализа docker образов (утилита запускается в докере) sudo docker run --rm -it -v /var/run/docker.sock:/var/run/docker.sock wagoodman/dive:latest gitlab/gitlab-runner:latest
Генератор конфигов различных серверов для работы с SSL: https://ssl-config.mozilla.org/#server=traefik&server-version=2.1&config=intermediate
GitLab Shell Runner. Конкурентный запуск тестируемых сервисов при помощи docker-compose https://habr.com/ru/post/449910
Группы в телеграмме:
Доклады Дмитрия Столярова из компании "Флант"






jetcar
Тестирование новых фич отдельно конечно круто, до первого глобального рефакторинга…
Akkarine Автор
К такой эпической задаче нужно готовиться — закончить и слить все открытые ветки. А после этого все разработчики работают над рефакторингом, как я описал в 4м пункте процесса разработки. Или у вас есть опыт других граблей, кроме вылезающих повсюду конфликтов?
VolCh
Какая качественная разница разрабатывать в отдельных ветках или разрабатывать и тестировать?