
Всем привет. Сегодня мы хотели бы поговорить про выявления аномалий в микросервисной среде. Данный пост является краткой выжимкой нашего 40 минутного доклада, который мы делали на онлайн конференции DevOps Live 2020 и, чтобы не писать лонгрид, мы решили сфокусироваться на обзоре инструментов выявления аномалий в распределении значений метрик для автоматизации мониторинга микросервисов, которые возможно быстро начать использовать любой команде.
Тема детектирования аномалий сейчас очень актуальна, так как с переходом на микросервисы для SRE и DevOps приоритет задач, связанных с преобразованием алертов в осмысленный сигнал, снижением MTTD и упрощением настройки алертов в мониторинге распределенных сред значительно повысился.

С переходом на микросервисную инфраструктуру сервисов, как и контролируемых метрик, становится кратно больше, сложность контроля такой системы увеличивается экспоненциально.
Под "контролем" мы имеем ввиду получение осмысленного сигнала в случае деградации производительности сервисов или инфраструктуры.
Как правило, для получения оповещения необходимо настроить триггеры оповещений, то есть определить какое значение метрики считать пороговым.
Но как установить пороги срабатывания алертов на сотни сервисов и тысячи метрик?
И нужно ли это делать вручную?
Несколько примеров, в которых выявление аномалий может быть крайне полезным:
- увеличение latency на одном из сотни сервисов;
- увеличение количества ошибок на одном из тысяч эндпоинтов;
- снижение количества запросов в обычно высокий период.
Такие изменения могут "затеряться" в большом объеме данных, мы можем не настроить пороги срабатывания на все нужные метрики из-за их количества, просто забыть и так далее.
Итак, выявление аномалий в мониторинге производительности используется для:
- обнаружения проблем;
- автоматизации мониторинга, ухода от ручных порогов в алертах;
- выявления «слабых» сигналов, когда метрик очень много и не на все настроены пороги оповещений.
Допустим, идея интересна, хочется попробовать использовать механизмы выявления аномалий, с чего можно начать?
Существуют следующие варианты реализации выявления аномалий:
- cделай сам;
- как функционал APM систем;
- as a Service.
Давайте рассмотрим каждый из способов.
Сделай сам
Готовых реализаций алгоритмов выявления аномалий много для разных языков разработки, будь то Python или специфичный R.
Но даже в стандартном инструменте мониторинга Prometheus есть встроенные возможности и реализованы методы статистики, позволяющие находить аномалии в time series метриках.
Для каждой анализируемой метрики необходимо будет создать несколько recording rules, в целом, процесс кропотливый и трудоемкий.
Если принять гипотезу, что анализируемые данные имеют нормальное распределение, то применяя простую статистику, можно определить аномалию как выход значения за пределы трех стандартных отклонений (правило "трех сигм").
Таким образом, для базового сценария выявления аномалий достаточно вычислить и записать среднее значение, стандартное отклонение и z-оценку (z-score) — это мера относительного разброса наблюдаемого значения, которая показывает, сколько стандартных отклонений составляет его разброс относительного среднего значения.
Для примера возьмем метрику http_requests_total, для начала ее нужно агрегировать:
# агрегация за пять минут
- record: job:http_requests:rate5m
expr: sum by (app) (rate(http_requests_total[5m]))
Далее вычисляем три нужных нам набора данных:
# average - среднее значение
- record: job:http_requests:rate5m:avg_over_time_1w
expr: avg_over_time(job:http_requests:rate5m[1w])
# stddev - стандартное отклонение
- record: job:http_requests:rate5m:stddev_over_time_1w
expr: stddev_over_time(job:http_requests:rate5m[1w])
# z-оценка
(job:http_requests:rate5m - job:http_requests:rate5m:avg_over_time_1w
) / job:http_requests:rate5m:stddev_over_time_1w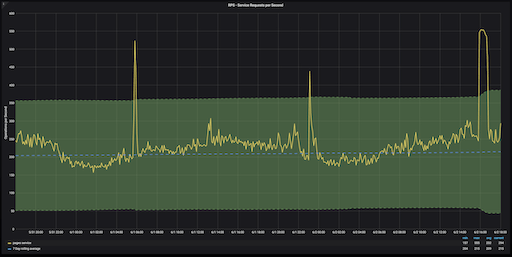
Большинство данных о производительности и нагрузке приложений (рейт запросов, latency) подвержены сезонности — нагрузка идет неравномерно в течение дня, недели, года.
Такие неравномерности имеют повторяющийся характер — это и есть сезонность.
Для учета сезонности необходимо предсказать значения на основе прошлых данных, и сравнивать значение уже с предсказанными данными.
Для предсказания можно использовать различные статистические методы или даже объеденить несколько предсказаний в один ряд.
После получения предсказанного значения необходимо определить, насколько точным оно может быть — для этого снова пригодится z-оценка.
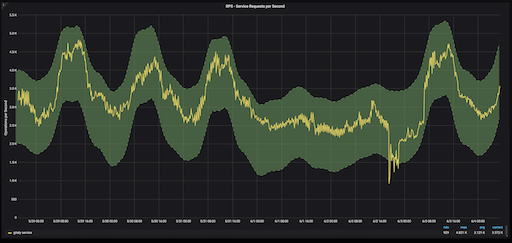
За более подробной информацией по настройке recording rules в Prometheus для вычисления верхних и нижних границ в случае сезонности можно обратиться к статье .
Prometheus на максималках — PAD
Проект Prometheus Anomaly Detector (PAD), находящийся под крылом Red Hat, автоматизирует действия, описанные в предыдущем разделе.
В PAD вы можете выбрать существующие в Prometeheus метрики для анализиза, и PAD создаст необходимые recording rules, построит предсказания, нижние и верхние пороги, прогоняя значения через движок Prophet, который уже учитывает сезонность.

PAD создаст дашборды в Grafana и алерты для оповещения в случае выявленной аномалии.
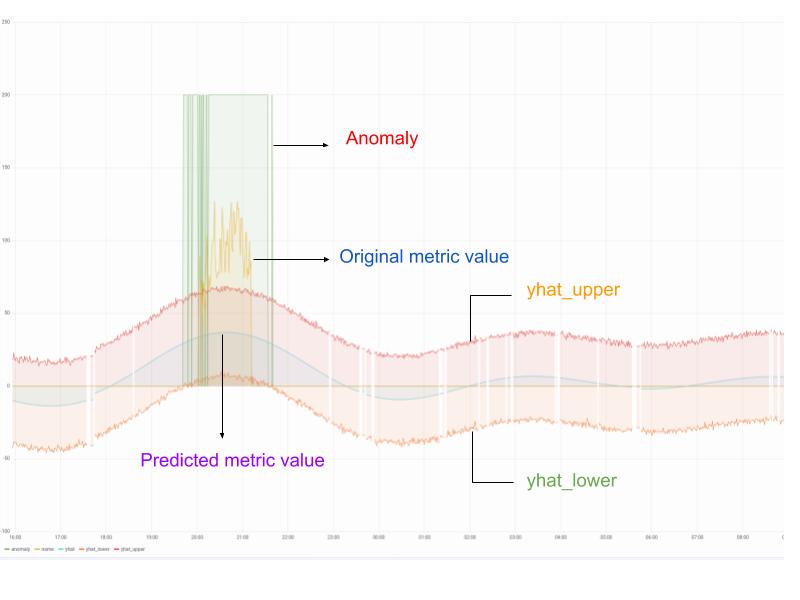
Пока это все же не промышленное решение, скорее proof of concept.
Обнаружение аномалий как часть APM системы
Системы мониторинга производительности (Application Performance Monitoring) обрастают функционалом AIOps — стремятся интегрировать механизмы машинного обучения и выявления аномалий, так как уже содержат в себе огромное количество информации, данных и метрик от приложений.
Посмотрим на реализации именно выявления аномалий и на то, насколько автоматизирован этот процесс с точки зрения настройки и постановки на мониторинг новых сервисов и метрик.
New Relic
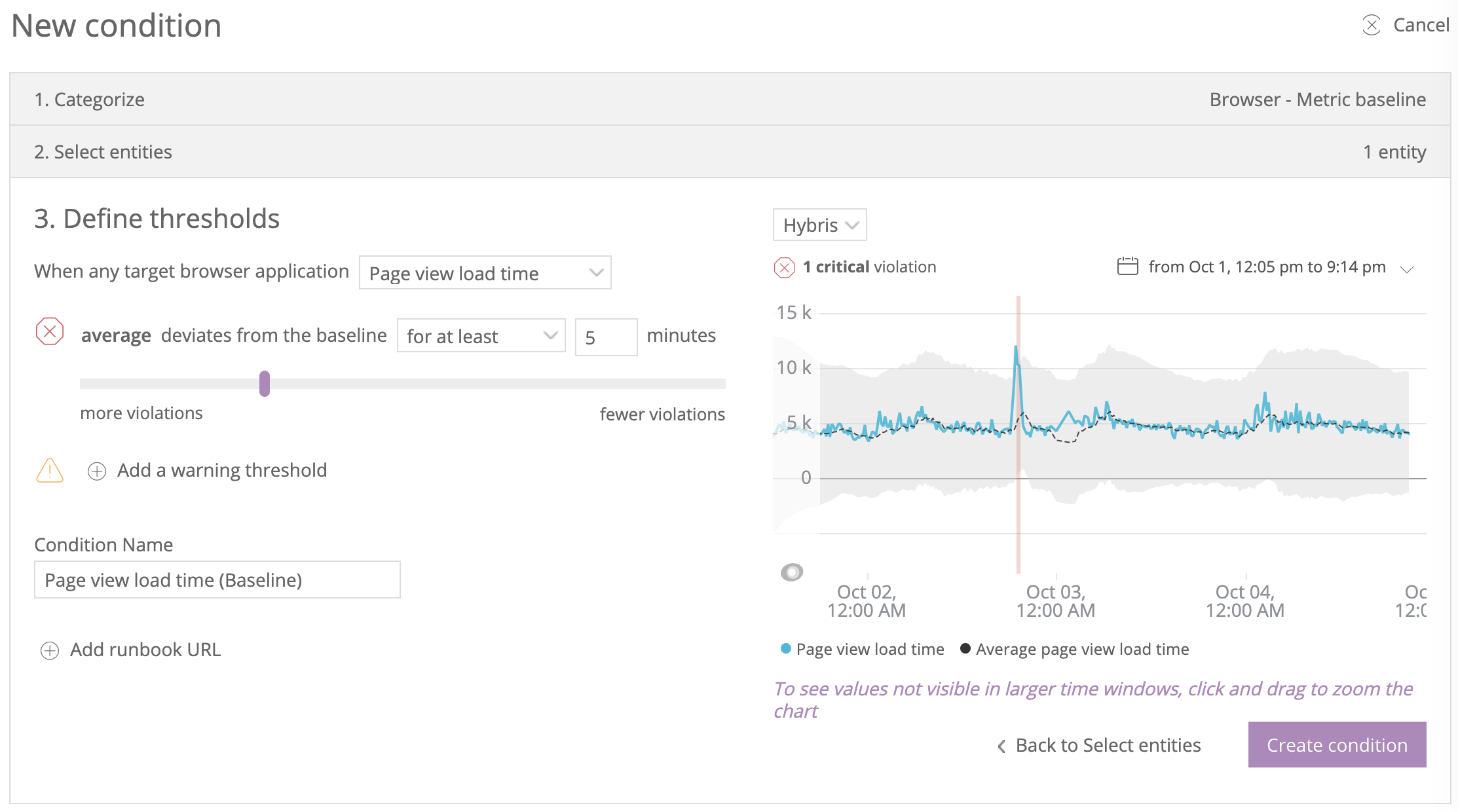
В платформе New Relic представлена возможность настройки политик оповещений по отклонению любых заданных метрик от baseline (предсказанных значений) — инфраструктурных, метрик EUM, бизнес метрик.
Отдельно настраиваются параметры политики оповещения — чувствительность отклонений относительно baseline, направления отклонений (только вниз, только вверх, в обе стороны).
Например, если выбрать в качестве метрики количество запросов, то система будет считать проблемой либо только увеличение количества запросов относительно ожидаемого, либо только снижение, либо любое изменение относительно baseline.
Для настройки оповещений необходимо создать политику оповещения, выбрать нужную метрику и указать параметры.
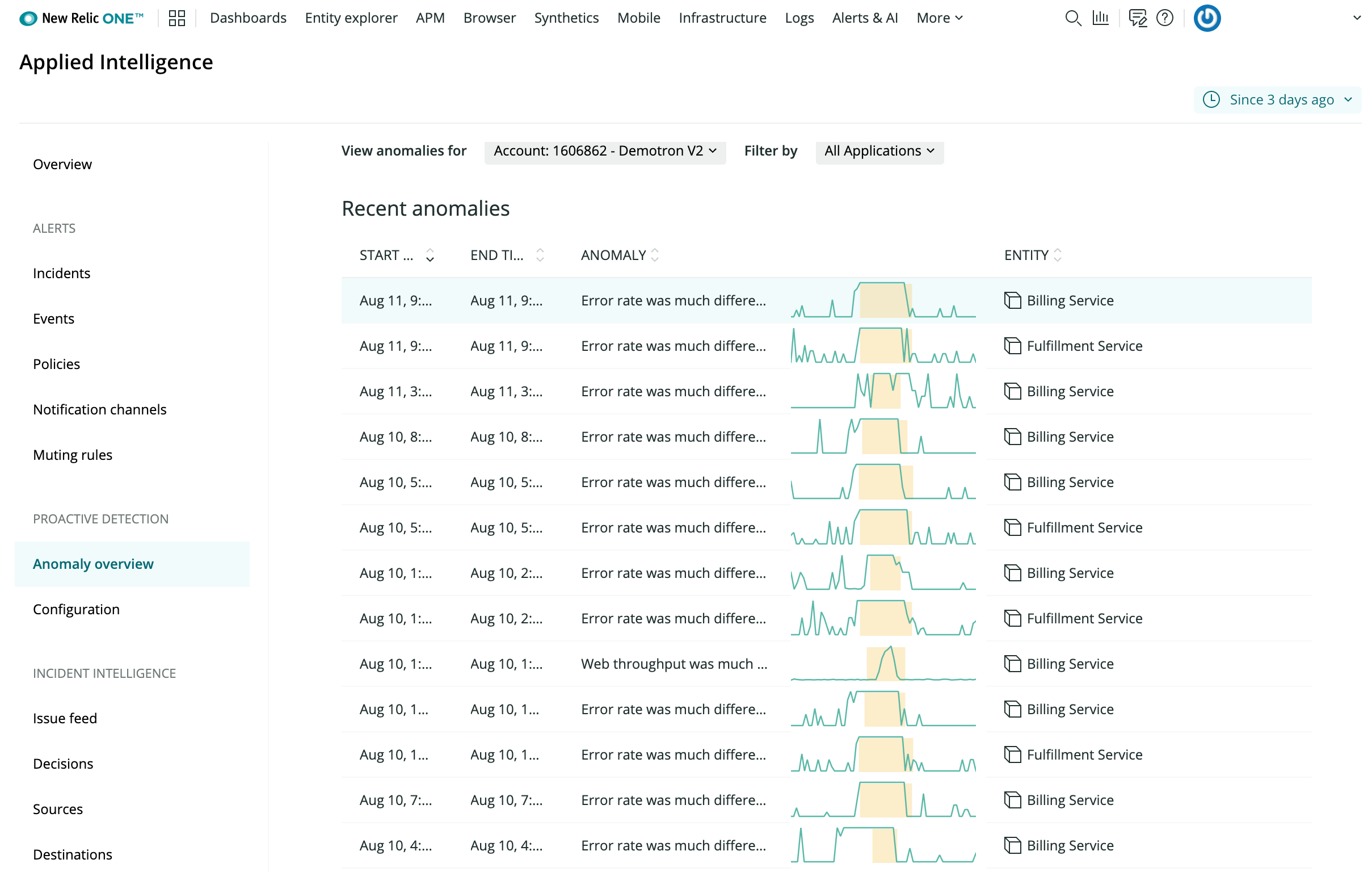
Также в апреле 2020 был представлен отдельный продукт для управления множеством метрик и их автоматического анализа с помощью алгоритмов машинного обучения — New Relic Applied Intelligence (AI).
После активации New Relic AI отслеживает и выявляет аномалии в основных KPI подключенных приложений и сигнализирует об аномалиях.
При добавлении в систему нового приложения/сервиса необходимо вручную добавить его к списку отслеживаемых.
AppDynamics
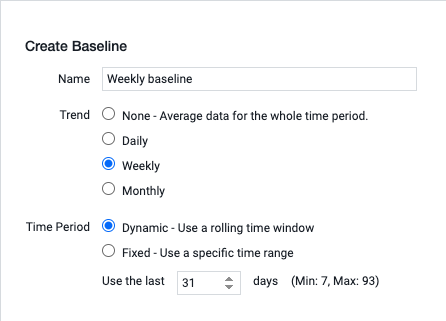
AppDynamics APM автоматически высчитывает baseline на основе стандартного отклонения для KPI-метрик подключенных приложений и отображает их на карте взаимодействия приложений.
Самих baseline для приложения может быть несколько, их можно настроить самостоятельно, выбрав тип (дневной, недельный и тд) и период времени, на котором будет просчитан baseline.
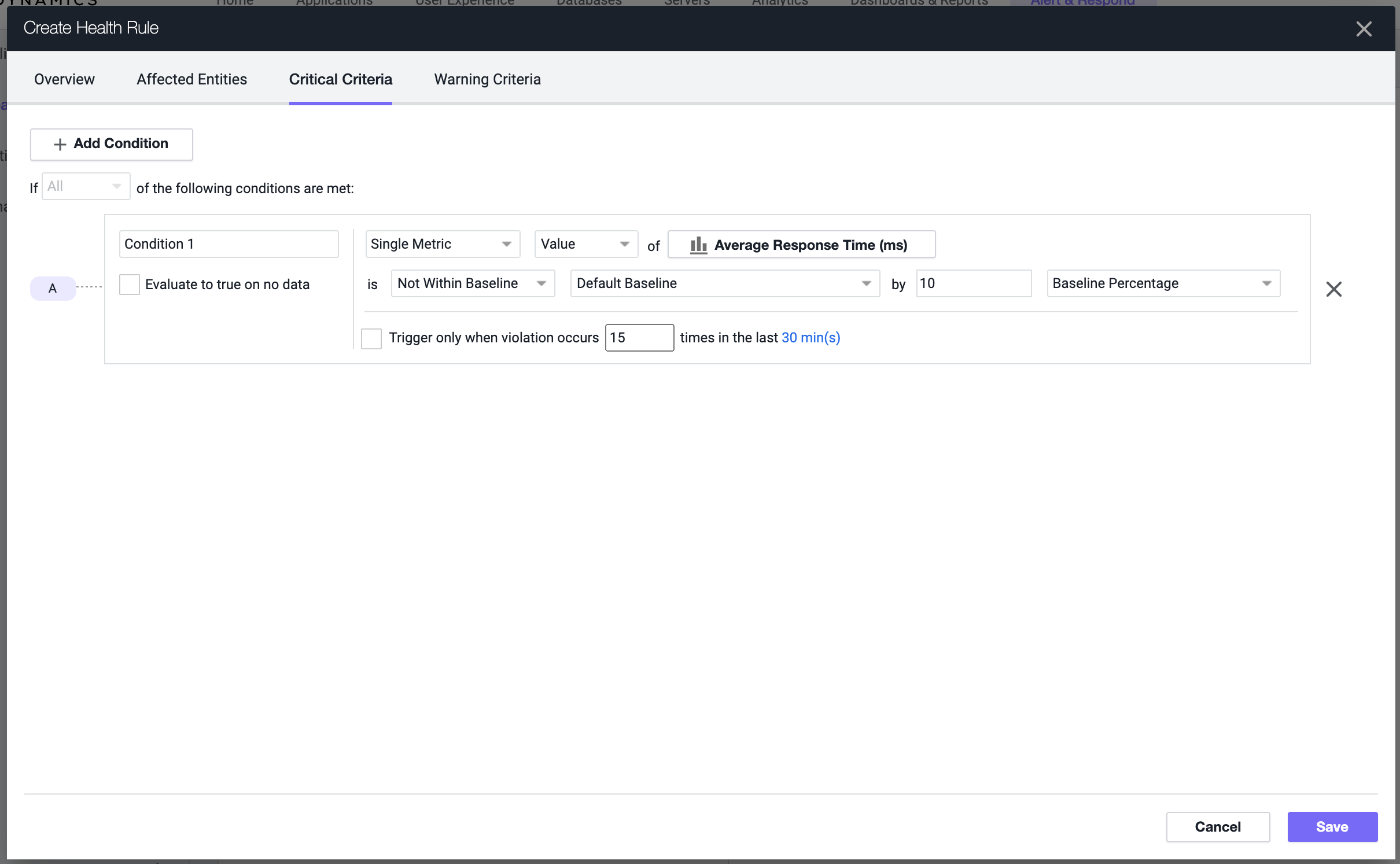
С точки зрения настройки алертинга по аномалиям процесс не автоматический, требуется настройка политики, health rule и условия.
В ходе настройки нужно выбрать одну метрику или группу метрик и указать процент, на который должно отклониться значение метрики от baseline для срабатывания условия в health rule.
Dynatrace
В Dynatrace "из коробки" заложено несколько правил обнаружения аномалий, по ним же сразу доступен алертинг.
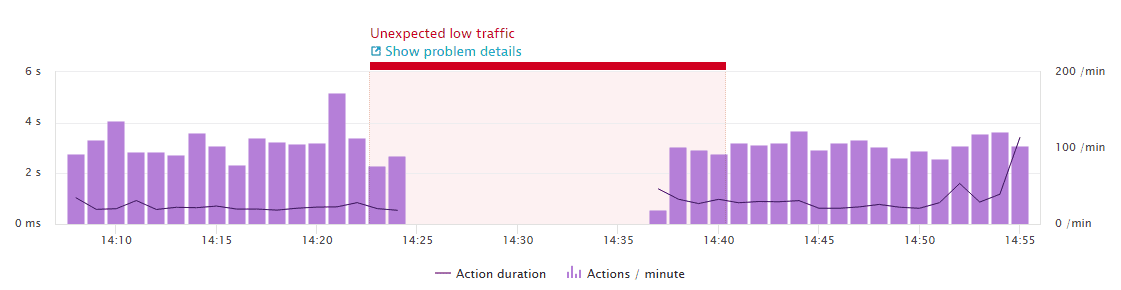
Доступны несколько правил:
- обнаружение деградации KPI производительности
- обнаружение падения трафика
- обнаружение ухудшения времени исполнения трангзакций
Основные возможности и настройки представлены на скриншоте.

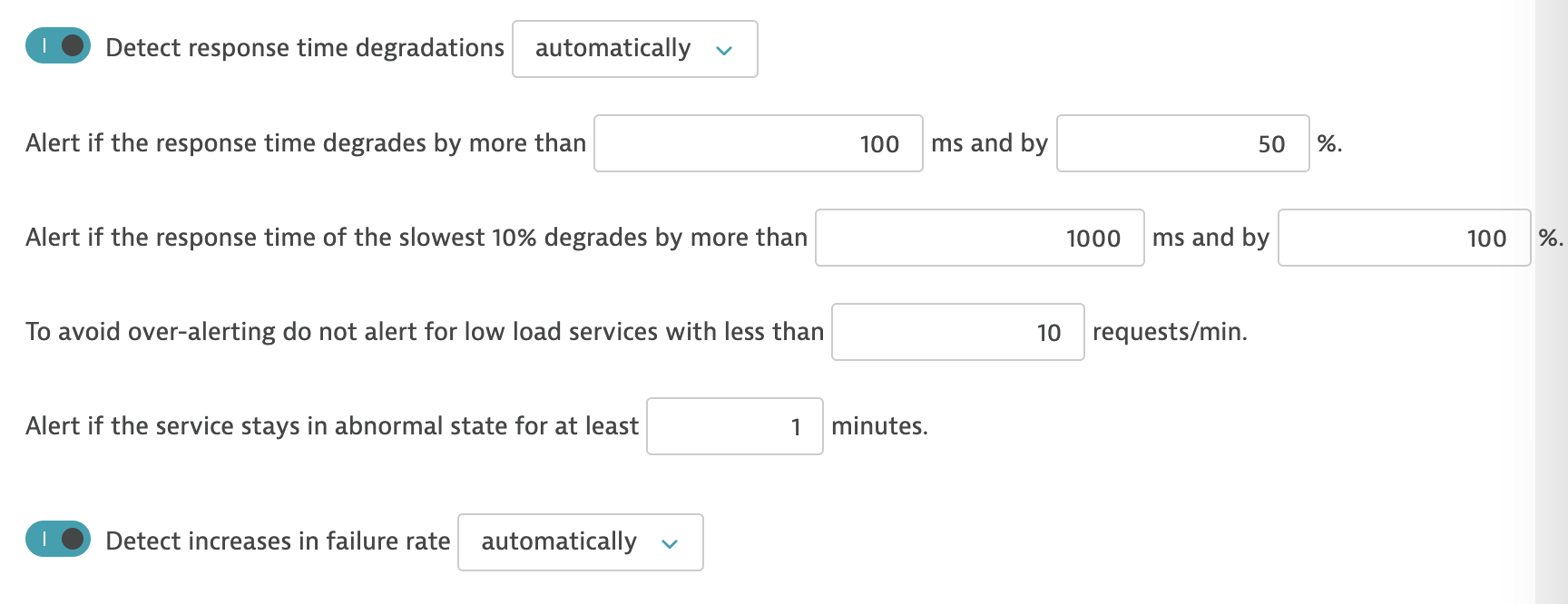
Instana
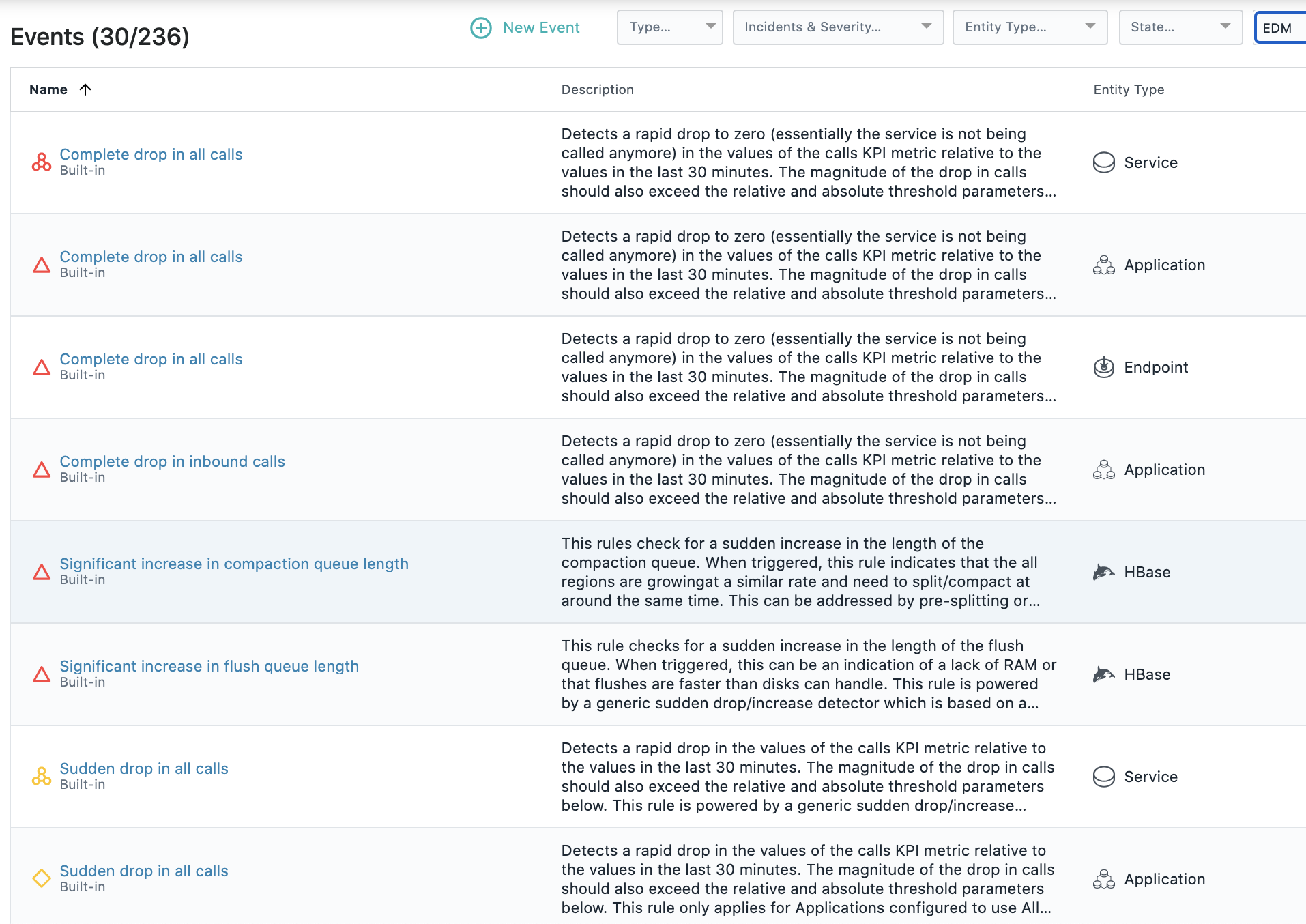
В решении для мониторинга производительности Instana "из коробки" доступно более 230 правил обнаружения проблем "здоровья" сервисов и приложений, часть из них относится к выявлению аномалий в KPI сервисов.
Используется анализ метрик latecy, error rate, traffic (количество запросов).
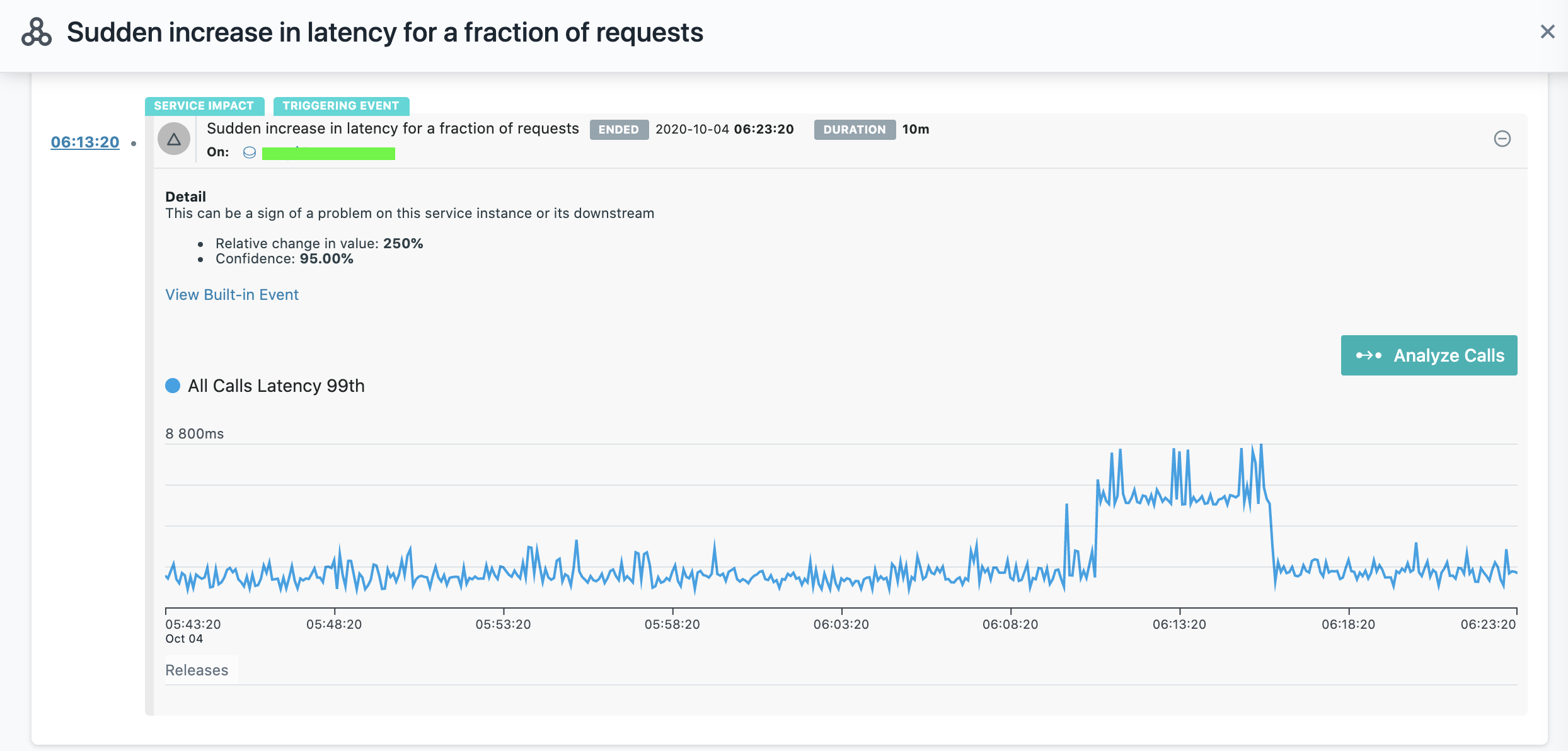
Большинство правил обнаруживают аномалии в распределении значений метрик с помощью модифицированного алгоритма E-Divisive with Medians (EDM).
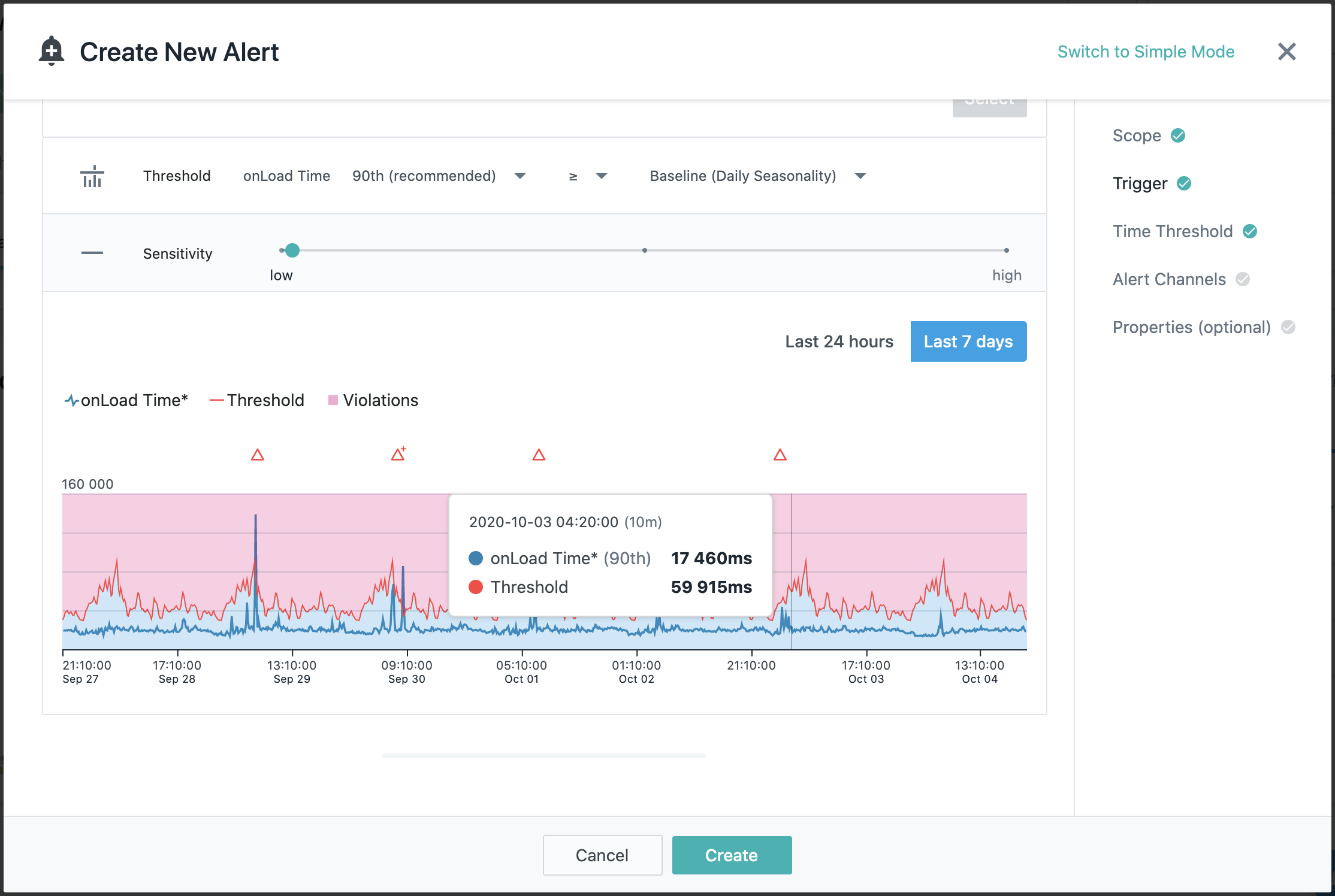
Реализован конструктор создания пользовательских правил оповещения, в дополнение к встроенным правилам, в котором используются условия отклонения значений метрик от baseline.
Настройку можно выполнить в "простом" и "продвинутом" режиме, во втором доступно больше опций для выбора.
Доступны два baseline на выбор — дневной и недельный на все основные метрики.
Подробне про мастер создания правил оповещений мы писали в статье про EUM.
Обнаружение аномалий as a Service
Если APM решение не внедрено, настраивать вручную Prometheus нет желания, хочется быстро попробовать посмотреть на свои данные и получить выявление аномалий как сервис, доступны готовые SaaS решения.
Azure Metric Advisor
Один из сервисов Microsoft — Azure Metric Advisor позволяет использовать множество источников метрик и типов данных.
Основная ориентация, судя по документации, на e-commerce.
Доступна поддержка множества источников (SQL Server, ElasticSearch, InfluxDB, MongoDB, MySQL, PostgreSQL и другие), нет поддержки Prometheus как источника метрик.
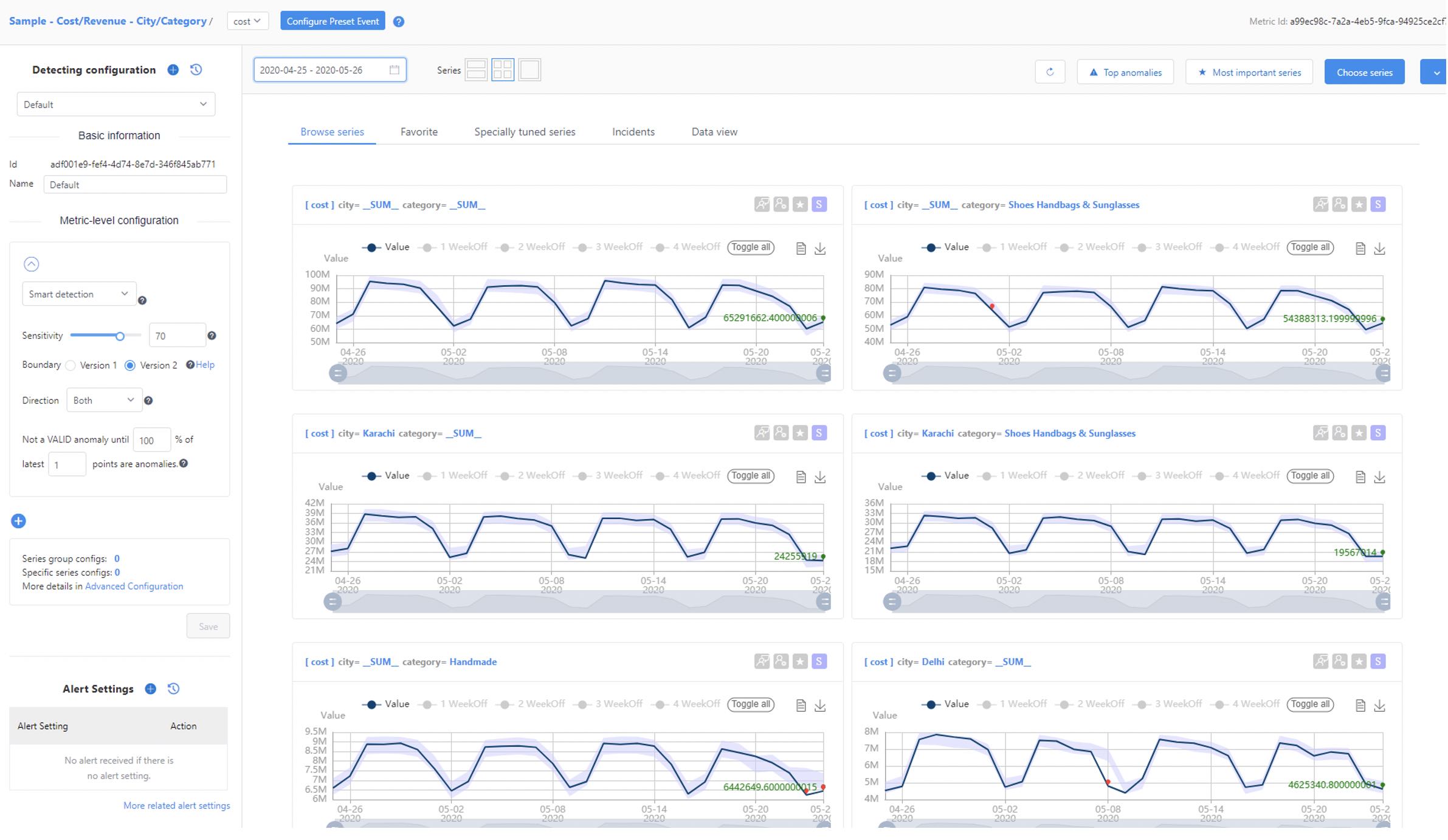
Anodot
Сервис умеет интегрироваться со множеством источников метрик и данных — от Prometheues до систем бизнес-аналитики.
Ориентирован как на бизнес-пользователей, так и SRE инженеров.
Доступно описание кейсов для e-commerce, gaming и других отраслей.

AnomalyIO
Сервис по анализу данных и выявлюению аномалий, работает, в основном, с метриками, хранящимися в InfluxDB.
Легко интегрируется со всем, что умееет отправлять метрики в InfluxDB, например, можно отправлять данные для анализа напрямую из приложений с помощью сторонних библиотек интеграций.
Вместо заключения
- Использование механизмов выявления аномалий позволяет выявлять проблемы в инфраструктуре и приложениях без установки статических порогов в триггерах оповещений.
- Необходимость выявления аномалий обусловлена спецификой самой микросервисной среды – сервисов много, метрик еще больше.
- Если в компании используется Prometheus — можно начать с простых примеров и ручной настройкой данных для анализа.
- Большинство промышленных APM решений интегировали функционал AIOps, уже собирают множество необходимых данных для анализа и умеют выявлять аномалии в метриках из коробки.
Спасибо за внимание.