
Сейчас новые версии Java выходят раз в полгода. В них время от времени появляются новые возможности: var в Java 10, switch-выражения в Java 14, рекорды и паттерны в Java 16. Про это всё, конечно, написано множество статей, блог-постов, сделано множество докладов на конференциях. Оказалось, однако, что мы все пропустили один очень крутой апгрейд языка, который произошёл в Java 14 - апгрейд обычного цикла for по набору целых чисел. Дело в том, что этот апгрейд случился не в языке, а в виртуальной машине, но заметно повлиял на то как мы можем программировать на Java.
Вспомним старый добрый цикл for:
for (int i = 0; i < 10; i++) {
System.out.println(i);
}У такого синтаксиса уйма недостатков. Во-первых, переменная цикла упоминается три раза. Очень легко перепутать и упомянуть не ту переменную в одном или двух местах. Во-вторых, такая переменная не является effectively final. Её не передашь в явном виде в лямбды или анонимные классы. Но ещё важнее: нельзя застраховаться от случайного изменения переменной внутри цикла. Читать код тоже трудно. Если тело цикла большое, не так-то легко сказать, изменяется ли она ещё и внутри цикла, а значит непонятно, просто мы обходим числа по порядку или делаем что-то более сложное. Есть ещё потенциальные ошибки, если необходимо сменить направление цикла или включить границу. Да и выглядит это старомодно.
Во многих языках уже отошли от тяжёлого наследия Си и предлагают более современный синтаксис, когда вы просто указываете диапазон чисел. Например, возьмём Котлин:
for (x in 0 until 10) {
println(x)
}Тут всё в шоколаде: переменная упоминается один раз, она неизменяемая внутри тела цикла, есть варианты для включения или исключения верхней границы, а также для задания шага. Красиво.
Можно ли приблизиться к этому варианту в Java? Да, с помощью цикла for-each, который появился в Java 5. Достаточно написать такой библиотечный метод в утилитном классе:
/**
* Возвращает диапазон целых чисел
* @param fromInclusive начальное значение (включительно)
* @param toExclusive конечное значение (не включается)
* @return Iterable, содержащий числа от fromInclusive до toExclusive.
*/
public static Iterable<Integer> range(int fromInclusive,
int toExclusive) {
return () -> new Iterator<Integer>() {
int cursor = fromInclusive;
public boolean hasNext() { return cursor < toExclusive; }
public Integer next() { return cursor++; }
};
}Никакого rocket science, исключительно тривиальный код, даже комментировать нечего. После этого вы легко можете писать красивые циклы и в Java:
for (int i : range(0, 10)) { // импортируем наш метод статически
System.out.println(i);
}Красиво. Можно явно объявить переменную final, чтобы запретить случайные изменения. Несложно сделать такие же методы с шагом или с включённой верхней границей и пользоваться ими. Почему же никто так до сих пор не делает? Потому что в данном случае из-за боксинга фатально страдает производительность. Давайте для примера посчитаем сумму кубов чисел в простеньком JMH-бенчмарке:
@Param({"1000"})
private int size;
@Benchmark
public int plainFor() {
int result = 0;
for (int i = 0; i < size; i++) {
result += i * i * i;
}
return result;
}
@Benchmark
public int rangeFor() {
int result = 0;
for (int i : range(0, size)) {
result += i * i * i;
}
return result;
}Тело цикла весьма быстрое и не выделяет никакой памяти, но при этом делает какую-то полезную работу, что не позволит JIT-компилятору выкинуть цикл совсем. Также я на всякий случай параметризовал верхнюю границу, чтобы JIT не заложился на конкретное значение количества итераций. Запустим на Java 8 и увидим безрадостную картину:
Benchmark (size) Mode Cnt Score Error Units
BoxedRange.plainFor 1000 avgt 30 622.679 ± 7.286 ns/op
BoxedRange.rangeFor 1000 avgt 30 3591.052 ± 792.159 ns/opИспользование метода range снизило производительность практически в шесть раз: тест выполняется 3,5 мкс вместо 0,6 мкс. Если посчитать аллокации с помощью -prof gc, мы обнаружим, что версия rangeFor выделяет 13952 байта, тогда как версия plainFor ожидаемо не выделяет памяти вообще. Легко понять, откуда взялось это число, если вспомнить, что целые числа до 127 кэшируются. Новые объекты Integer выделяются на итерациях 128-999, то есть создаётся 872 объекта по 16 байт. Заметьте, кстати, что ни объект Iterable, ни объект Iterator не создаются: здесь наш код прекрасно обрабатывается оптимизацией скаляризации (scalar replacement). Однако боксинг всё портит.
Понятно, что такие накладные расходы на обычный цикл for часто неприемлемы, поэтому программировать в таком стиле на Java никто всерьёз рекомендовать не будет. Однако давайте попробуем более новые версии Java:
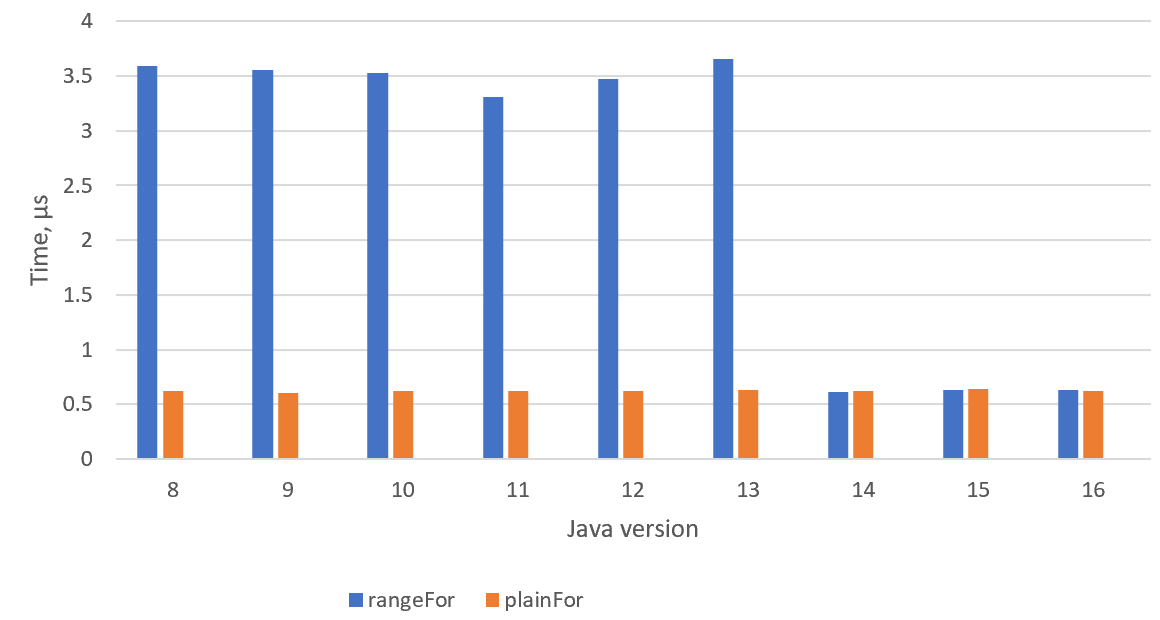
Вот тут нас ждёт приятный сюрприз: начиная с Java 14 производительность варианта с range сравнялась с простой версией! JIT-компилятор стал достаточно умным, чтобы сгенерировать настолько же хороший ассемблер, как и в простой версии.
На самом деле работа над оптимизацией по уничтожению ненужного боксинга велась много лет. Её плоды можно было пощупать ещё с версии Java 8 с помощью опций JVM -XX:+UnlockExperimentalVMOptions -XX:+AggressiveUnboxing. Мы можем попробовать запустить наш тест с этой опцией, и окажется, что с ней уже в восьмёрке производительность была существенно лучше:
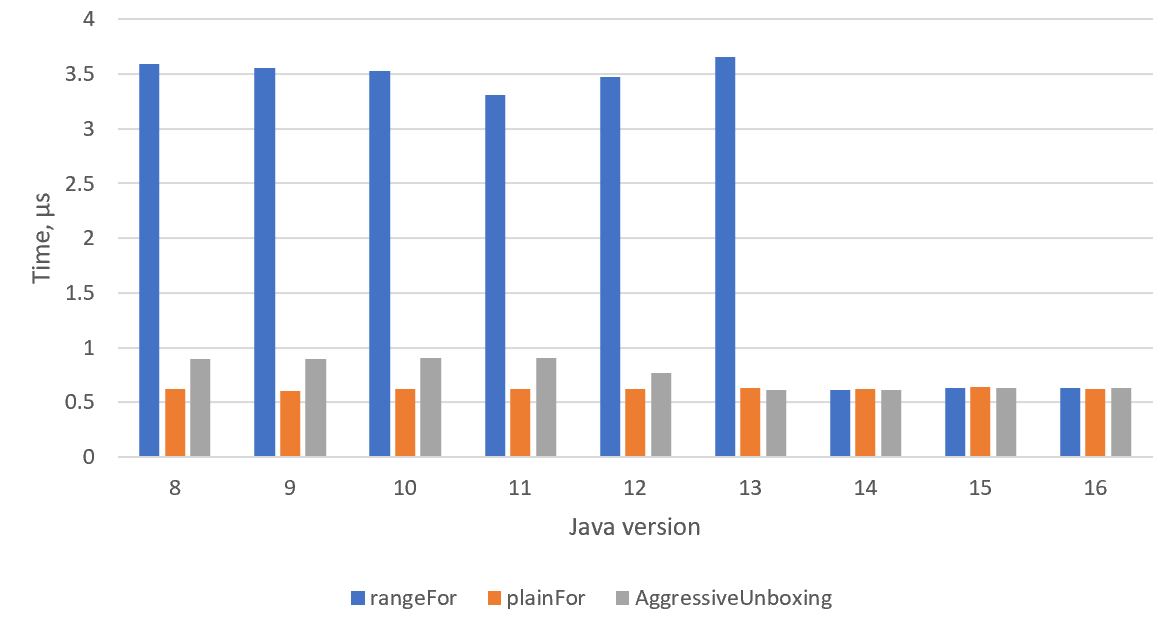
В Java 8-11 мы имели производительность на уровне 0,9 мкс, в 12 стало в районе 0,8, а начиная с 13 сравнялось с обычным циклом. И вот к Java 14 эта оптимизация стала достаточно стабильной, чтобы её включить по умолчанию. Вы можете пытаться сделать это и в более ранних версиях, но я бы не рекомендовал этого на серьёзном продакшне. Смотрите, например, какие страшные баги приходилось исправлять в связи с этой опцией.
В чём была сложность реализации автоматического удаления боксинга? Одна из основных проблем - как раз тот самый кэш объектов Integer до 127. При боксинге целых чисел выполняется нетривиальный метод valueOf (цитата по Java 16):
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}Как видно, этот метод берёт значения в диапазоне от IntegerCache.low до IntegerCache.high из кэша, который заполняется на ранней стадии инициализации виртуальной машины. Поэтому, если у нас происходит боксинг с последующим анбоксингом, нельзя просто положиться на механизм скаляризации: иногда мы должны возвращать закэшированные объекты. В режиме AggressiveUnboxing JIT-компилятор принудительно начинает игнорировать этот кэш, если может доказать, что ссылка на объект никуда не уплывает. В этом можно убедиться, написав какой-нибудь такой код:
Field field = Class.forName("java.lang.Integer$IntegerCache").getDeclaredField("cache");
field.setAccessible(true);
Integer[] arr = (Integer[]) field.get(null);
arr[130] = new Integer(1_000_000);
for (int i = 0; i < 10000; i++) {
int res = rangeFor();
if (res != -1094471800) {
System.out.println("oops! " + res + "; i = " + i);
break;
}
}Мы грязным рефлекшном подменяем одно из чисел в кэше на другое, а затем в цикле сравниваем результат с тем, который должен получиться в результате подмены. В честной Java if не должен выполняться. Но с опцией AggressiveUnboxing мы получаем результат в духе
oops! 392146832; i = 333
То есть когда JIT-компилятор C2 добирается до метода rangeFor, он выкидывает обращение к испорченному кэшу, и начинает выдавать правильный ответ, который должен получаться, если бы мы не залезли в кэш грязными руками.
Однако хоть кэш и игнорируется, до Java 12 включительно я вижу в ассемблерных листингах инструкции вида cmp r10d,7fh, то есть счётчик сравнивается с числом 127 (=0x7f). Похоже, условие полностью выкинуть удалось только в Java 13. Я могу спекулировать, что эти лишние проверки не только отъедают такты процессора, но и занимают дополнительные регистры, из-за чего страдает уровень развёртки цикла. Во всяком случае, до Java 12 цикл с rangeFor разворачивается по 8 итераций, а начиная с Java 13 лишние проверки исчезают и развёртка уже охватывает 16 итераций, сравниваясь с plainFor.
Так или иначе, мы видим результат: агрессивное уничтожение боксинга стало поведением по умолчанию с Java 14, что позволяет гораздо чаще наплевать на боксинг и пользоваться удобными конструкциями. В связи с этим цикл вида for (int i : range(0, 10)) должен стать каноническим в новых версиях Java и должен заменить динозавра for (int i = 0; i < 10; i++), в том числе в учебниках по языку.
Окончательное решение проблемы с боксингом должно прийти к нам после специализации дженериков в проекте Valhalla. Тогда можно будет возвращать Iterable<int>, и боксинг в данном случае не потребуется вообще. Вероятно, мы не увидим в стандартной библиотеке методов вроде range пока этого не случится. Однако боксинг уже не так страшен и с Iterable<Integer> можно комфортно жить.









23derevo
А что нам по поводу range предлагает стандартная библиотека?
Endeavour
IntStream.range(a, b).forEach(i -> ...);Интересно, как у этого варианта с бенчмарком. Боксинга здесь нет.
lany Автор
У forEach другие проблемы.
foal
Ничего, про это написано в последнем абзаце.