
Если вы когда-нибудь прослушивали музыку через наушники и через колонки, то наверняка обращали внимание, что звучит она по-разному. В наушниках часто возникает ощущение, что источник звука находится где-то внутри головы. Бывают и другие негативные эффекты: некоторые старые записи сделаны так, что, например, гитара полностью смикширована в левый канал, а ударные - в правый. На колонках это звучит нормально - как будто гитарист стоит примерно там где один из громкоговорителей, но в наушниках - это весьма неприятно, потому что неестественно: в природе не бывает такого, чтобы звук слышало только одно ухо.
Скажу больше: подавляющее большинство коммерческих аудиозаписей рассчитаны именно на прослушивание через колонки. То есть звукорежиссёр при подготовке записи делает всё, чтобы она правильно (в соответствии с задумками автора) звучала в студийных мониторах, а как оно будет в наушниках - с большой вероятностью даже не проверит.
Казалось бы, если нравится - всегда можно слушать через колонки. Но увы, бывают ограничения: хочется послушать музыку в офисе, в транспорте, да или просто поздно вечером, когда дети/родители/соседи уже давно спят. Кроме того, стоимость качественных акустических систем в разы превышает стоимость качественных наушников. А есть ещё может понадобиться отдельный усилитель, акустическая обработка комнаты и т. д. Иногда колонки просто негде разместить в квартире... С наушниками всё проще.
Что делать?
Одну минуточку! Но ведь когда мы слушаем музыку через колонки (или вообще сидим в концертном зале), каждого уха достигает совершенно определённый акустический сигнал. Значит если записать этот сигнал с помощью маленького микрофона, расположенного внутри каждой ушной раковины, и потом воспроизвести через хорошие наушники, то мы получим то же самое ощущение присутствия в зале. Разве что за исключением низкочастотных сигналов, ощущаемых грудной клеткой. Впрочем, это слишком сложная процедура, хотя такие записи (их называют бинауральными) иногда делают, и даже продают.
А что если воспроизвести через колонки какой-то тестовый сигнал, записать его этими самыми крошечными микрофонами в ушах, определить, как сигнал преобразовался, и потом аналогичным образом преобразовывать любимую музыку перед проигрыванием через наушники?
HRTF и HRIR
Представьте себе, что у вас есть только одна колонка, и она стоит, допустим, справа от вашего монитора. Подадим на неё короткий импульс. Излучаемый акустический сигнал обозначим как x(t). Тогда Вашего правого уха соответствующая акустическая волна достигнет чуть раньше, чем левого. Кроме того, от левого уха колонку будет заслонять ваша голова, в результате туда попадёт чуть более "глухой" и более тихий звук. На самом деле, до правого уха этот звук тоже не дойдёт неизменным: помимо прямого сигнала, будет ещё сигнал, отражённый от виска, от ушной раковины и т. д. Об отражениях от монитора, стола, стен, потолка, пола и мебели говорить пока не будем, представим себе, что их нет. Обозначим сигнал, принятый левым ухом, как XL(t), а правым ухом - XR(t). Эти сигналы можно представить как исходный сигнал, преобразованный двумя разными функциями: XL(t)=FL(x(t)) и XR(t)=FR(x(t)).

Подобные преобразования, вносимые в акустический сигнал можно описывать по-разному - можно нарисовать амплитудно-частотную и фазо-частотную характеристики, можно расписать передаточную функцию в виде многочленов, а можно задать импульсную характеристику и описать это преобразование как операцию свёртки (обозначим её символом *), тогда:
XL(t) = hL(t) * x(t) и XR(t) = hR(t) * x(t),
где hL(t) и hR(t) - импульсная характеристика фильтров соответственно для левого и правого уха.
Но как узнать вид этих передаточных функции или импульсных характеристик? К счастью, это уже было сделано (и не один раз). Например, в 2003-м году в институте IRCAM (Франция) были обследованы несколько десятков человек. Каждого из них сажали на стул в специальной акустической безэховой камере, устанавливали в уши крошечные микрофоны, а дальше воспроизводили тестовые сигналы с помощью небольшого, но сравнительно качественного студийного монитора, закреплённого на специальном сервоприводе так, чтобы можно было перемещать его в двух плоскостях, сохраняя неизменным расстояние до слушателя. Таким образом звук приходил к голове испытуемого под разными углами. Записанные сигналы обрабатывались, производилась коррекция для исключения неидеальности характеристик микрофонов и акустической системы. В результате для каждого человека было получено почти по две сотни импульсных характеристик. Их называют Head-Related Impulse Response - импульсная характеристика относительно головы. В литературе чаще встречается термин HRTF, это почти то же самое.
Казалось бы, задача решена. Ищем в базе данных IRCAM импульсную характеристику, снятую на уровне глаз с азимута, скажем, 30 градусов, всю прослушиваемую музыку пропускаем через соответствующий FIR-фильтр и подаём на хорошие наушники с плоской АЧХ. К сожалению, всё несколько сложнее…
Реальные наушники
В мире есть пара десятков крупных брендов, предлагающих качественные головные телефоны - Sennheizer, AKG, Beyerdynamic, Sony и т. д. Многие из них занимаются этим бизнесом не один десяток лет и придерживаются определённых традиций. Одна из них - фонограмма должна звучать в наушниках аналогично колонкам: никакие частоты не должны "выпячиваться" или "проваливаться" по сравнению с прослушиванием аналогичной фонограммы на качественных акустических системах с плоской АЧХ. Проблема в том, что для этого приходится делать наушники с кривой АЧХ. Например, часто в качестве оптимальной АЧХ наушников принимают одну из семейства кривых "Harman Target Curves". Таким образом, фактически, производители наушников уже давно и достаточно успешно рещают задачу имитации "прямой" импульсной характеристики, то есть звук из правой колонки воспринимается также, как звук из правого наушника. "Обратный" звук - такой, который попадает из правой колонки в левое ухо, в обычных наушниках отсутствует. Именно его нам и нужно сформировать, обладая знанием об HRTF.
На самом деле, помимо имитации "прямой" HRTF осуществляется ещё и некая стандартная эквализация, но об этом поговорим как-нибудь в другой раз.
Немного рассуждений
Если вы прониклись концепцией, но зеваете при виде формул - можете пропустить этот раздел.
Итак, у нас есть комплект импульсных характеристик: hR(t) и hL(t). Мы предполагаем, что "прямая" HRTF (то есть hR(t) в нашем примере) имитируется за счёт конструкции головных телефонов, иначе говоря, наушники производят преобразование вида FR(), то есть делают свёртку сигнала с hR(t). Теперь нам нужно придумать фильтр, который сделает так, чтобы в левое ухо попал сигнал XL(t) - как если бы мы слушали колонки. Обозначим импульсную характеристику этого фильтр как hcorr(t). Должно выполняться равенство: hcorr(t)*hR(t)*x(t)=hL(t)*x(t). Здесь появляется свёртка с hR(t), так как левый наушник имеет точно такую же конструкцию как правый и преобразует сигнал точно также. Сократим лишнее (со свёрткой так можно): hcorr(t)*hR(t)=hL(t).
У меня в институте не было курса по цифровой обработке сигналов, но о преобразовании Фурье нам, конечно, рассказывали в рамках курса мат. анализа. Поэтому я помню, что преобразование Фурье - это фактически переход из временной области в частотную, а свёртка во временной области эквивалентна умножению в частотной области. Обозначим преобразование Фурье как fft(). Тогда:
fft(hcorr(t)) ? fft(hR(t)) = fft(hL(t))
(символом ? обозначаем поэлементное умножение).
Тут здорово то, что в частотной области не возбраняется не только поэлементное умножение, но и деление:
fft(hcorr(t)) = fft(hL(t)) / fft(hR(t)).
Дальше остаётся перейти снова во временную область (выполнить обратное преобразование Фурье), и мы получаем импульсную характеристику необходимого нам фильтра!
Если углубиться в теорию, то выяснится, что такой фокус - перейти в частотную область, поделить и перейти обратно во временную область - не всегда возможен. Забегая вперёд скажу: в данном случае возможен.
Для полноты картины нужно отметить, что в итоге нужно к сигналу, подаваемому в левый наушник прибавить сигнал правого канала, пропущенный через найденный нами фильтр, а к сигналу, подаваемому в правый наушник прибавить сигнал левого канала, также пропущенный через этот фильтр.
Я считаю, что нахождение фильтра, определяющего именно разность между сигналами для каждого из ушей концептуально более правильно, чем раздельное преобразование сигналов для правого и левого уха. Ведь мозг ничего не знает об истинном характере звука в пространстве. Он воспринимает только сигналы от обоих ушей, и по разнице между этими сигналами пытается определить направление на источник звука.
Второй важный момент: для локализации звука (то есть определения направления) не имеет особого значения АЧХ самих наушников (как и их "target curve") - она сократилась в наших уравнениях. Однако, необходимо, чтобы левый и правый наушники были максимально похожи. Поэтому, никто не мешает до или после данного фильтра использовать обычную эквализацию, чтобы получить именно такой спектр звука, какой нам хочется. Заодно можно компенсировать недостатки АЧХ наушников и/или недостатки записи.
О существующих решениях
Я не претендую на полный обзор, но кое-что перечислить всё-таки нужно. Во-первых есть много плагинов для разных программных аудио-плееров и редакторов, осуществляющих так называемый cross-feed. Подавляющее большинство из них - просто подмешивают звук противоположного канала. Иногда слегка его фильтруют и/или добавляют задержку. К сожалению. я не нашёл ни одного плагина такого типа, позволяющего сформировать звуковую картину, аналогичную прослушиванию на хороших колонках, когда можно с закрытыми глазами показать, где "находится" каждый из исполнителей. Возможно, причина в том, что у меня не самая типичная голова - значительно шире среднестатистической (замучился выбирать велосипедный шлем для катания зимой).
Единственный готовый инструмент из тех, что я пробовал, обеспечивший хорошую локализацию в пространстве - Dolby Headphones. Существует плагин-обёртка для известного в узких кругах аудиоплеера foobar2000, позволяющая обрабатывать звук соответствующей библиотекой от Dolby. Но у неё есть два недостатка. Во-первых, она искажает АЧХ. Есть подозрение, что она рассчитана именно на наушники с ровной АЧХ (как в рассуждениях выше). Это можно выправлять эквалайзером, но как-то неаккуратненько. Второй недостаток - сомнительная легальность. Наверное, можно купить программный пакет, в который входит эта библиотека от Dolby, но не знаю, насколько будет правомерно использовать её отдельно. Также есть очевидные сложности с использованием на ОС, отличных от Windows. Можно, конечно, снять импульсные характеристики, и использовать их, но это уже reverse-engineering, что тоже не всегда легально.
Разбираемся в нюансах и кодим
Если хочется наконец попробовать, и лень читать все эти буквы - в конце есть ссылка на GitHub, но лучше всё-таки прочитать, т. к. комментариев в коде немного, а readme.md я пока не написал.
Традиционно подобные фильтры часто делают в Matlab. Я никогда раньше с ним не работал, но решил повозиться с открытым аналогом - GNU Octave. Итак, за дело.
Для начала посмотрим, как выглядят импульсы от IRCAM. Виртуальные колонки у меня будут стоять под углом +-30 градусов - это классическая расстановка, когда колонки и слушатель образуют равносторонний треугольник. Вначале был соблазн взять единственный стерео-файл, в котором записаны сигналы для правого и левого уха, но оказалось, что импульсы правого и левого каналов могут ощутимо различаться (вероятно, вследствие асимметрии головы у большинства людей), поэтому стоит брать один и тот же канал, например, левый и файлы, снятые под разными углами. Я после ряда проб и ошибок выбрал файлы IRC_1006_R_R0195_T030_P000.wav и IRC_1006_R_R0195_T330_P000.wav, но, повторюсь, у меня не самая типичная голова, поэтому Вам с большой вероятностью лучше подойдёт какая-нибудь другая пара импульсов.
Здесь 1006 - идентификатор испытуемого, 0195 - расстояние от громкоговорителя до головы в сантиметрах, 030/330 - азимут (0 - колонка ровно перед слушателем, 90 слева, 180 - сзади, 270 - справа), 000 - нулевой угол над горизонтом. Также на сайте IRCAM доступны xml-файлы с описанием испытуемых - рост, расстояние между ушами, длина волос, размер ушных раковин и т. п. Посмотрим как выглядят эти импульсы.


Длина импульсов составляет 8192 сэмпла, при частоте дискретизации 44.1кГц. Получается 186мс, что соответствует длине волны 63м. Очевидно, что длина сильно избыточна, поскольку при такой длине волны (на 2 с лишним порядка больше размера головы!) никакого стереоэффекта нет, и оба уха слышат идентичный сигнал. Поэтому при загрузке файлов их можно сразу обрезать до 1024..4096 семплов. Например так:
channel_idx = 1; % Channel index, used from input files: 1 - left, 2 - right
max_impulse_len = 4096;
[impulse, fs] = audioread(fname);
len = min(rows(impulse), max_impulse_len);Данные ненужного канала тоже выкинем.
impulse = impulse(1 : len, channel_idx);Далее проведём наши вычисления на основе быстрого преобразования Фурье:
fft_div = fft(impulse_opposite) ./ fft(impulse_direct);
impulse_tf = real(ifft(fft_div));По-умному это называется deconvolution или system identification (т. к. позволяет определить свойства системы на основе входного и выходного сигналов). Посмотрим, что получается:

Что-то получилось :) Скажу больше, оно в целом даже работает как ожидалось. Однако, отношение сигнал-шум в этом импульсе не радует глаз. Перфекционист внутри меня негодует... Можно провести свёртку, и проверить, что hcorr(t) * hR(t) = hL(t).
Посмотрим, как будет выглядеть "сигнал ошибки":
plot(conv(impulsedirect, impulsetf)(1:4096) - impulseopposite);
Не скажу, что идеально, ошибка порядка нескольких процентов. Видимо не всё так просто...
Пришлось засесть за Гугл и найти учебники по цифровой обработке сигналов. Оказывается, проблема известна уже чуть ли не пол века: деконволюция через преобразование Фурье даёт большие ошибки. К счастью, более подходящие методы тоже давно известны. Один из классических - метод наименьших квадратов (МНК) с использованием матрицы Тёплица и её инверсией методом Дурбина-Левинсона. Было найдено несколько готовых реализаций для Matlab, из которых получилось сделать то, что хотелось (подробности здесь приводить не буду, если интересно - можно посмотреть на гитхабе).
Сам импульс, полученный с помощью МНК:

И "сигнал ошибки":

Теперь получше, ошибка около одного процента.
Попробуем увеличить масштаб картинки с полученным импульсом:

Мне кажется, в этом импульсе многовато высокочастотных составляющих. Что ж, попробуем обрезать всё, что выше 20кГц (за пределами диапазона слышимых частот) с помощью ФНЧ:
lpf = remez(2 * round(fs / 600), [0 20000 / (fs / 2) 21000 / (fs / 2) 1], [1 1 0 0]); % For Matlab environment change "remez" to "firpm".
filteredImpulse=conv(impulse_tf, lpf, 'same');
Выглядит ещё лучше.
Я слабо верю, что можно услышать разницу с использованием ФНЧ и без. На ресурсоёмкость это тоже не должно влиять. В общем, решение спорное, но я захотел сделать так.
Так, мы совсем забыли о длине… Мы же говорили, что 8192 сэмпла - это безумно большой запас, а сами сделали всего лишь вдвое меньше. Причём значительная часть энергии в импульсном отклике этого фильтра - банальный шум! Думаю, здесь стоит применить так называемую оконную функцию, например, функцию Блэкмана.
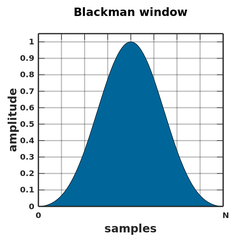
Честно говоря, я не стал выяснять, какая оконная функция здесь подходит лучше всего, но функция Блэкмана используется, например, в программе DRC, выполняющей похожую задачу, и я решил поступить также. Надеюсь, автор DRC посвятил этому вопросу больше времени :)
Не уверен, будет ли слышно разницу, но перфекционизм...
Сначала определим, где будет центр оконной функции. Для этого возьмём медиану группового времени задержки, которое даёт наш фильтр:
avgDelay = round(median(grpdelay(impulse_tf)));Теперь сформируем собственно оконную функцию и поэлементно умножим на неё наш импульс.
wnd = window(@blackman, 2 * (size(impulse_tf)(1) - avgDelay));
% Cut the window in size
wnd = flipud(wnd(1:size(impulse_tf)));
% Apply window
impulse_tf = impulse_tf .* wnd;
Неплохо. Часть лишнего удалось убрать. Думаю, если уменьшить длину импульса ещё в 2..4 раза, то будет совсем красиво. Но тут надо оценивать на слух - я отчётливо слышал разницу в зависимости от длины импульса. Впрочем, это могли быть артефакты фильтрации на лету при прослушивании.
Дальше имеет смысл визуально сравнить полученный импульс после свёртки с исходным (примерно это мы делали при попытке использовать FFT). Я вывел на один график сами импульсы, и их же в частотной области, то есть после преобразования Фурье - отдельно модуль (то есть по сути АЧХ), действительную часть и мнимую часть:

Выглядит годно. Заметные отличия (и то если увеличить :)) - в области самых верхних частот, где мы собственно применили ФНЧ. То есть, похоже, что всё правильно.
Осталось сохранить полученный импульс в два стерео-файла, отличающихся только переменой правого и левого каналов.
impulse_tf_stereo_L(:, 2) = impulse_tf;
impulse_tf_stereo_L(1, 1) = 1;
impulse_tf_stereo_R(:, 1) = impulse_tf;
impulse_tf_stereo_R(1, 2) = 1;
audiowrite(strcat(directory, fname_direct, '_TF_stereo_L.wav'), impulse_tf_stereo_L, fs);
audiowrite(strcat(directory, fname_direct, '_TF_stereo_R.wav'), impulse_tf_stereo_R, fs);Теперь осталось проверить, что собственно получилось. Для этого я использовал уже упоминавшийся аудиоплеер foobar2000 с плагином "Stereo Convolver". Настроен он у меня следующим образом:

Также рекомендую заняться эквализацией - значительных изменений тонального баланса от этого фильтра быть не должно, но тем не менее… Да и вообще, эквализация под свои вкусы никогда не помешает.
Если результат в плане пространственного разрешения фонограмм не понравился - можно попробовать выбрать другой импульс из базы IRCAM и попробовать снова. Либо закрыть эту страницу и заняться чем-нибудь более интересным.
Заключение
В общем, результаты этого хоббийного исследования меня удовлетворяют. Лучшего пространственного разрешения в наушниках я пока не слышал. Ну и заодно слегка подтянул знания в области цифровой обработки сигналов.
Есть и кое-какие мысли по дальнейшему развитию подхода.
Весь использованный код для GNU Octave выложен на GitHub.
Да, пара иллюстраций позаимствована с Википедии. Вроде бы лицензия это допускает.
Ссылки
http://recherche.ircam.fr/equipes/salles/listen/ - база данных измеренных HRIR реальных людей. Измерения проведены институтом IRCAM (Франция) в 2003г. На страничке LINKS есть ссылки на другие измерения HRTF.
https://ocw.mit.edu/courses/mechanical-engineering/2-161-signal-processing-continuous-and-discrete-fall-2008/lecture-notes/ - курс лекций MIT по цифровой обработке сигналов,
https://www.musicdsp.org/en/latest/ - база знаний по синтезу и обработке музыкальных сигналов,
https://en.wikipedia.org/wiki/Head-related_transfer_function - статья в Википедии о передаточных функциях человеческой головы.
https://www.headphones.com/pages/measurements-and-frequency-response - об амплитудно-частотных характеристиках наушников.
http://drc-fir.sourceforge.net/ - набор утилит для создания КИХ-фильтров, корректирующих искажения, вносимые акустикой комнаты.
https://hydrogenaud.io/index.php?topic=90662.0 - плагин Stereo Convolver для foobar2000.
Sap_ru
Зачем вам звук из правой колонки в левом ухе?! У вас есть стереозапись, где в каждом канале уже присутствует необходимая сумма звуковых волн!
Fullmoon
Затем, что, как написано в посте, стереозапись сведена для воспроизведения на колонках, а не в наушниках. Чтобы в уши приходила нужная сумма звуковых волн, на наущники и на колонки нужно подавать разный сигнал.
ZayatzTV
Для звукорежа нет разницы между акустическими системами ака колонки и наушники…
В мониторной нет переотражений как в бытовом помещении, так что работу АС можно считать работой в свободном поле, что в точности равно подаче сигнала в наушниках..
SADKO
Не равно ибо дело не только в переотражениях, они лишь для реалистичности картины. А по факту в безэховой камере мы один монитор слышим двумя ушами, между которыми есть некое расстояние и голова :-) то есть в зависимости от угла будет задержка и частотная коррекция.
Для звукорежиссёра разница между мониторами и наушниками огромна. В наушниках можно выполнить какую-то часть работы, но с панарамированием и обьёмом, работают исключительно через мониторы, причём разные.
stlimafon
можно расшифровать часть фразы про «причём разные»?
stlimafon
Скажите, те умнейших чела, что поставили моему вопросу 2 минуса:
В вашей вселенной все являются экспертами по звуку? Вы представить не можете, что кто-то не понимает столь простейших по вашему мнению вещей?
Вы можете простым языком объяснить несведущему человеку, что такое «работают через разные мониторы».
В каком смысле они разные?
ZayatzTV
Мониторы бывают ближнего, среднего и дальнего поля.
Ближнее поле и среднее — это компактные мониторы, для контроля наличия сигнала. Работа на расстоянии не далее пары метров от дифов динамиков. Ущербны из-за ограничений по АЧХ, в соответствии с габаритами… На глаз можно определить как убожества с НЧ-динамиками размером не более 6-8". Их родственники — "столбиковые" АС из всяких магазинчиков..
Мониторы дальнего поля — полнодиапазонные… Для обычных помещений… Обычно выглядят как колонки с парой 12-15" динамиков в каждом кабинете. Пригодны для домашнего применения в качестве нормальных АС..
Как-то так, вкратце..
stlimafon
Означает ли, что звукорежиссеры проверяют все на 3 версиях?
Ну вот смотрите. Сижу я за компьютером в небольшом кабинете.
Хочу иметь не ущербный звук, могу себе позволить хорошее оборудование.
Вы меня убедили, что дального поля мониторы — то что нужно по звуку.
Однако меня смущает слово «дальнего».
Как это будет выглядеть в небольшом кабинете (там место буквально на 2 компьютерных стола плюс небольшой проход, но я там один)?
Есть ли смысл брать технику «дальнего поля» в столь небольшое помещение?
ZayatzTV
Ближнее поле, наушники — моментальная проверка некоторых фрагментов и контроль наличия какого-либо звука вообще…
Дальнее поле и наушники — на сведении, на финальном миксе… А так же для обычного меломанского прослушивания любых фонограмм.
Вопрос просто в одном — есть ли желание получить полноценную звуковую картину на частотах 200-150 гц и ниже, в том виде, как её задумал звукореж и лабухи?
Ну или ещё проще — довольствоваться ли АС, которые в принципе не могут полноценно воспроизвести звучание простого домашнего пианино или желается большего во всех смыслах — дальнего поля и его аналогов..
TitovVN1974
ИМХО дилетанта следует ещё учитывать рабочий уровень громкости АС
ZayatzTV
Ну так мощность — от нуля и до киловатт.
Сколько выдержит человечья тушка и конструкция помещения — это проверить надобно..))
int0Ah Автор
Тут проблема ещё и в том, что корректное воспроизведение ниже пары сотен Гц требует ещё и помещения, отличного от типовой комнаты в квартире.
В студиях контрольные мониторы тоже ставят в достаточно больших помещениях.
ZayatzTV
И типовая комната годится.
Небольшая подготовка помещения понадобится, но всё это вполне решаемо и необременительно, если вообще есть интерес..
int0Ah Автор
Не соглашусь.
Получить внятный звук на десятках-сотнях Гц сложно и, чёрт побери, дорого.
Во-первых, нужны большие динамики, т. к. для обеспечения звукового давления, аналогичного средним частотам нужно большое объёмное смещение (то есть площадь диффузора * на его ход). Кроме того, см. кривые равной громкости: чтобы звук на 40Гц было слышно с аналогичной громкостью, как 1кГц, звуковое давление должно быть значительно выше. Это дорого,
Идём дальше. Для исключения стоячих волн в помещении нужно либо поглощение, либо определённые виды коррекции АЧХ.
Поглощение на десятках Гц проблематично без существенного уменьшения объёма комнаты, т. к. поглотитель нужно размещать в «зонах максимальной скорости», а это 1/4 длины волны от стен, почти метр для 100Гц!
Активная коррекция сравнительно легко делается для единственной точки в пространстве (правда с оговорками).
Если нужна более широкая зона, то есть вариант «DBA»: en.wikipedia.org/wiki/Double_bass_array
Но для этого нужно несколько сабвуферов, что тоже не дёшево и влезет не в любую комнату, особенно если в квартире живёт кто-то ещё.
ZayatzTV
Понятно, что понадобятся и большие динамики и сотни ватт усиления для каждого канала и некая подготовка помещения.
Это нормально и естесственно.
Инструмент подбирается для решения задачи, как всегда.
Но никаких непреодолимых препонов для преобразования обычной жилой комнаты в "помещение для прослушивания" — нет. Многократно так делал, и не только для себя..
ZayatzTV
При чём тут безэховая камера, если говорим про мониторную?
И разных мониторов нет.
Боижнее поле работает только как сигналка, а вся работа на полноразмерных и полнодиапазонных в дальнем поле. И микс делается для АС и наушнмков одинаковый, отличий в этом случает нет и нет даже предпосылок для отличий..
SADKO
да при том что
а это мягко говоря не так, и отражений даже в контрольной комнате предостаточно, по этому я и привожу в пример безэховую, где всёравно подача не эквивалентна, по чисто физиологическим причинам.Вы слишком категоричны в своих суждениях, видимо в силу молодости.
Мониторы разные могут быть даже в пределах одного поля из-за особенностей восприятия в диаппазоне\ах раздела, в них имеется необходимость и по этой же причине всю работу нельзя сделать исключительно в дальнем поле.
Да и сами эти поля сегодня существуют не от не совершенства акустических систем, но для некоторых практических потребностей сведения.
ZayatzTV
Работать в столь лажовой мониторной — себя не уважать…
И вообще-то — не встречал таких киксов в своей практике..
Впрочем, есть же идиоты, ставящие ламповое усиление в контрольные тракты… Пути дебилов неисповедимы..)
int0Ah Автор
Я скажу ещё больше, отражения есть даже в безэховой камере.
Если посмотреть на те импульсы от IRCAM, то там кое-что видно, правда не факт, что это отражения от стен. Возможно работает оборудование, используемое в рамках исследования — собственно монитор, сервопривод, стул и т. п.
По словам людей, работавших в камерах (в т. ч. ещё более серьёзных), стоячие волны на НЧ заметны на измерениях абсолютно в любой безэховой камере, следовательно отражения есть.
Не стал писать об этом в основном тексте, но судя по всему, для ещё большего «эффекта присутствия» имеет смысл добавить как раз немного отражений. В Dolby Headphones они есть. Там на выбор несколько вариантов обработки, самый «прямой» из них называется как-то типа «studio», и там отражения тоже есть (по анализу импульсной характеристики), хотя ухом практически не слышны.
p_fox
"отличий в этом случает нет и нет даже предпосылок для отличий"
Ты хочешь нас убедить, что звук из левой колонки не попадает в правое ухо, а из правой колонки — в левое?
Законы акустики с тобой не согласны.
А вот в наушниках подобного смешения каналов нет. Потому там звук и отличается.
ZayatzTV
Акустика и разделение на каналы существуют для создания художником некоей звуковой "объёмной" картины.
И — помещения для прослушивания тоже требуют обработки, даже и архитектурной, дабы исключить порчу звучания фонограмм не предусмотренными партитурой отражениями/проникновениями и прочими искажениями ачх/фчх
Dolios
Никогда не приходилось встречать записи, в которых вокал, например, есть только в одном канале? Автор про это пишет.
adic3x
All My Loving — The Beatles / 1963 (0094638242024)
dimaviolinist
«записи, в которых вокал, например, есть только в одном канале»
Обычно это такой художественный приём, его не нужно «исправлять».
Если совсем это сложно слушать в наушниках, то либо просто в моно слушать, либо и правда, только на колонках.
Кроме того, у автора есть несколько наивнейших допущений.
Например, что звукорежиссёры и всякие продюссеры, которые говорят, как звукорежам работать, не знают, сколько телефонов продаётся в мире и сколько людей слушают музыку в наушниках.
Dolios
Его не нужно исправлять, когда оно играет из колонок. Потому что звук все равно дойдет до обоих ушей. А когда ты в наушниках, начинает казаться, что ты оглох на одно ухо или что наушники сломались. Так себе ощущения, я вам скажу.
Либо в наушниках, но с коррекцией, как у автора. Почему вы такой вариант не рассматриваете в принципе?
dimaviolinist
Конечно не рассматриваю. Даже автор прямым текстом пишет:
«Лучшего пространственного разрешения в наушниках я пока не слышал.»
(«лучшего, чем до того, ведь я правильно понимаю?»)
Скажите, а вы рассматриваете вариант, что сотни и тысячи инженеров и музыкантов за очень неплохие деньги уже работали над подобными проблемами?
int0Ah Автор
Конечно работали. Не просто так это исследование HRTF'ов в IRCAM проводилось совместно с AKG. Подозреваю, что именно на их деньги.
И существует даже небольшое количество «бинауральных записей», созданных именно ради объёмного звучания в наушниках.
Но насколько я знаю, там как правило именно *запись* производилась с помощью искуственной головы с микрофончиками в ушных раковинах.
kolu4iy
Пагадити. Про импульс я понял (ну так, но вроде достаточно для старта, если что). А что делать с реальным музыкальным файлом? Тоже через gnu octave его гонять? Или у вас в гитхабе волшебный инструмент, а я мякотку и упустил?
kolu4iy
… я буду дочитывать до конца. Понял, зачем нужен stereo convolver, спасибо.
Fullmoon
Воткнуть в плеер плагин от Dolby (через VST bridge, как я понимаю). Тут автор показывает, как такой плагин в принципе пишется.
Catslinger
Под винду есть фильтр HeSuVi. Устанавливать сложно, работает идеально.
DavisR
HeSUVi с GSX- шикарно работает
Причем даже на встроенной звуковушке 3D есть.
С хорошей картой и, главное, хорошими наушниками звучит лучше, чем Dolby Atmos Headphones, IMHO.
Ну и не привязана к источнику звука
Jamon
В свое время исследовал рынок по этому вопросу, самое годное (с т.зр. звука) решение здесь: newaudiotechnology.com
Тестировал их Sound Card Pro, там можно выбирать виртуализацию больших систем (а ля 20 колонок, и не только в горизонтальном поле) — и у них это реально работает, прям слышно.
Звук у них на голову лучше HeSuVi — а это ближайшее доступное что есть.
Но самая большая проблема (на ноябрь 19 года) — то что после перезагрузки их программа ломается, звук начинает производить с треском. Очень надеюсь, что починили, давно не проверял.
IgorPie
Статья — занятная и список материалов в конце понравился тоже.
Но, как понимаю, все сводится к FIR с разными коэффициентами для левого и правого канала?
Каков размер импульса? Вряд ли больше 30мс, тогда и FFT с его погрешностями, задержками и стыковкой кадров — не нужен, все, по идее, делается в лоб, через линейную свертку.
int0Ah Автор
Да, там длинный фильтр не нужен, т. к. на НЧ оба уха получают идентичный сигнал.
В плане «приготовления» фильтра — тоже верно, FFT «не нужен». Собственно в конечном итоге я и вычислял фильтр более «прямым» методом (МНК).
При realtime'овой обработке тоже можно считать свёртку «в лоб», но есть нюансы.
1. Более ресурсоёмко, даже при сравнительно небольшой длине фильтра.
2. Не всегда даёт более высокую точность по сравнению с хорошо реализованной FFT-свёрткой.
3. Банально существует гораздо меньше готовых инструментов. Stereo Convolver можно взять и скачать, а аналогичный по функциональности плагин, выполняющий свёртку во временной области придётся писать (как минимум — обёртку над готовыми движками). Ничего архисложного, но учитывая п.2, на это жаль времени.
IgorPie
В железе, в бюджетных DSP типа ADAU1701, 1401 и так далее — делается в лоб.
На ПК с SSE должно быть еще шустрее. Даже МК делают mac операцию за 1 такт.
С FFT разве нет сложностей с краями кадра и не пришлось делать перехлесты и прочий «кроссфэйдинг»?
Казалось, что плагинов, которые умеют в свертку действительно много. На столько, что они просто есть даже в бюджетных аудиоредакторах, как незначительный пункт меню. Поэтому их и трудно найти — под рукой.
int0Ah Автор
C FFT, насколько я знаю, именно так и делают — перехлёст с наложением подходящей оконной функции. И насколько я знаю, если всё сделано правильно, то получается свести погрешности к ошибкам округления (как и в случае свёртки «в лоб»).
Плагинов для свёртки — да, много, но 90% из них — как раз используют FFT, а другие 99% — не умеют накладывать один фильтр на «прямой» сигнал, а другой — на «перекрёстный», то есть непригодны «из коробки» для поставленной задачи (crossfeed с HRTF).
Можно организовать систему плагинов, примерно так:
— скопировать стереопару, то есть получить два идентичных стереосигнала — A(t) и A'(t),
— поменять в A'(t) каналы местами,
— исходную пару A(t) обработать одним фильтром (либо не обрабатывать вообще),
— клонированную пару A'(t) — обработать другим фильтром,
— снова сложить эти два стереосигнала.
Но подобное в realtime можно сделать тоже далеко не в любом плеере. С гирляндами vst-плагинов, прикрученными к плееру (уже не помню, с какими именно я это пробовал) у меня был в своё время негативный опыт, хотя возможно, в 2021 году с этим лучше.
Просто сейчас я не вижу в этом необходимости — мне проще взять Stereo Convolver и просто использовать.
Явной разницы между фильтрацией «в лоб» и через Stereo Convolver я не услышал. Но да, на досуге будет интересно сравнить более вдумчиво на слух и на глаз (в аудиоредактори или в том же GNU Octave).
IgorPie
VST-то как раз делается несложно из примеров, которые дает Steinberg. И свертку в лоб с разными коэффициентами на каждый канал можно сделать за пару вечеров.
Другое дело, что плагин построения АЧХ проверяемого плагина довольно непросто найти, есть только 32 бит.
int0Ah Автор
Я не говорю, что сложно, я говорю, что это не особо нужно, по крайней мере, мне.
Как вариант — взять тот же Stereo Convolver (по ссылке в посте выложен код на сях) и вместо FFT вкрутить обычную свёртку. Это и за один вечер не проблема сделать, даже если немного повозиться с оптимизацией.
А ради построения АЧХ что-то писать — вообще не вижу смысла (если не на коммерческой основе). Достаточно пропустить через испытуемый плагин единичный импульс и посмотреть FFT в любом аудио-редакторе.
adic3x
Это признак очень плохо тракта. Буквально уровень наушников "купить за $5 в переходе метро" и например встроенный звук в материнскую плату пк, который сделан максимально экономно, лишь бы был.
Уже с более-менее среднего уровня сцена становится читаемой, а на приличной аппаратуре и наушниках можно легко понять, где какой инструмент играет, как он расположен в пространстве.
Из записей когда гитары в один канал и вокал в другой я помню только ранние Битлз, тогда я так понимаю стерео ещё не успели толком использовать. Пинк Флоид 70-тых уже звучит отлично. Можно ещё привести записи эпохи войны громкости, но так они везде будут звучать как говно. Там сцены вообще нет.
Что у вас за наушники и какой источник?
adic3x
Хабр такой Хабр.
Намного интереснее, если кто-то не согласен с мнением — написать, с чем именно не согласен, почему и как.
int0Ah Автор
Сейчас слушаю ЦАП на AK4490 с достаточно сильноточным выходом (не хочу писать здесь марку, но это не Китай/Алиэкспресс), наушники — Fostex T50RP mk3.
Также всё это прверялось с доп. усилителем (композит с AD815 на выходе) и AKG k-501.
adic3x
Ясно, аппаратура как бы совсем не слабая. У меня наушники AKG K612 (501 вроде же их дальний предшественник), которые как бы одни из лучших по сцене, по крайней мере за вменяемые деньги и карточка Asus STX II, и я нормально воспринимаю сцену. Возможно это привычка из-за длительного прослушивания музыки в наушниках, но по сравнению с «трешевыми» вариантами, где музыка действительно играет внутри головы, а стерео воспринимается как «играет левый динамик» и «играет правый динамик» мне сцена кажется по крайней мере читаемой.
int0Ah Автор
Да, думаю, это вопрос привычки.
Когда речь идёт о звуковом восприятии, привычка вообще играет ключевую роль.
FilCattish
Интересная работа, но зачем же изобретать велосипед?
Есть очень годный плагин для foobar2000:
Bauer stereophonic-to-binaural DSP (http://bs2b.sourceforge.net).
ИМХО на голову выше, чем Dolby Headphones.
int0Ah Автор
Пробовал, у меня сложилось противоположное мнение. Повторюсь, возможно, это связано с моей анатомией.
arkserg
В том то и дело, что тут очень многое зависит от того, насколько голова пользователя близка к той «референсной» под которую затачивалась та или иная технология. К примеру для меня самый достоверный результат с точки зрения локализации источников звука выдаёт DTS Headphone:X, но я читал отзывы людей, которым она совсем не подходит, а больше всего нравится Dolby Headphones или Dolby Atmos for headphones. Именно поэтому по-настоящему универсальной может быть только технология, учитывающая анатомические особенности конкретного слушателя. Например DTS еще на релизе Headphone:x обещала, что добавит возможность такой настройки, однако прошло уже несколько лет, а заветной вкладки в плагине так и не появилось, есть только компенсация АЧХ популярный наушников, видимо что-то пошло не так. Также Марк Церни из Sony на технической презентации PS5 говорил, что они работают над технологией персонализации их Tempest Engine, в частности предполагал, что они либо будут обрабатывать фото головы и ушей пользователя, либо сделают интерактивную мини игру для настройки параметров фильтра, однако пока в PS5 есть только несколько (3?) зашитых профилей и никакой кастомизации. Из известных мне решений есть только упоминаемая уже где-то здесь в комментариях Creative Super X-FI, у которой смешанные отзывы на зарубежных форумах, да Smyth Realizer за 4 тысячи евро. Так или иначе очень радует, что к теме опять появился интерес у крупных кампаний, может быть в ближайшем будущем всё-таки увидим хорошее и доступное решение для массового потребителя.
MikeVC
Тема очень интересная.
Действительно, ушная раковина немного изменяет звук, приходящий с разных направлений и так мозг понимает откуда пришел звук. В некоторых записях я слышал интересные эффекты, построенные на этом принципе. Это когда играет стерео в колонках, но кажется что звук идет сзади. При этом сзади никаких колонок нет!
Но с реализацией этого всего есть куча проблем.
У всех уши разные и мозг «приучен» к своим ушам. Так что универсальности не будет.
А сйчас этим вобще никто заморачиваться не будет т.к музыкальная индустрия деградирует и качественный звук мало кому нужен.
stlimafon
Гуглить «barber shop 3d sound»
Великолепный пример объемного звука, умещенного в обычные стереонаушники. Слушать в наушника.
Причем это файл был создан еще в древние времена, когда техника была куда как менее совершенной.
MikeVC
В древние времена люди очень серъезно занимались качественным звуком.
Было квадро и много эксперементов интересных.
Сейчас это вобще никому не интересно. Все сидят в соцсетях и слушают с стрим телепончиков.
Просто преобразовать звук с помощью фильтров для своих ушей не получится. Т.к это надо сводить запись сразу с применением этих фильтров для разных источников звука с разных направлений. Этим точно никто заниматься не будет.
Так что тема интересна для своих эксперементов не более.
IgorPie
Еще как занимаются, гасеров — тысячи, десятки тысяч. И каста модулярщиков и много кого еще. И VST плагинов делается миллион, конкуренция — жуткая, даже бесплатно влезть.
MikeVC
Софт делают.
А музыку кто писать будет качественную?
Динозавры еще пишутся качественно. Издают SACD, винил и концерты с многоканальными дорожками на блю рей. Они уйдут на пенсию и что будет дальше?
Где материал брать нормальный для прослушивания?
int0Ah Автор
Угу, придумано всё было очень давно. См., например, en.wikipedia.org/wiki/Ambisonics
Но это дорого, и мало кому нужно.
p_fox
"Это когда играет стерео в колонках, но кажется что звук идет сзади."
Это называется бинауральное стерео.
Некоторое время назад искал плагины для плееров, чтобы звук 5.1 / 7.1 в бинауральное стерео конвертировать для просмотра фильмов. Но ничего нормально работающего не нашел.
int0Ah Автор
Ещё лет 20 назад была демка от компании A3D (они тогда пилили эту технологию для компьютерных игр). Там можно было менять характеристики своей головы (было доступно несколько слайдеров — типа размер головы и т. п.), и можно было двигать виртуальный источник звука вокруг виртуального себя в произвольную точку. Получалось весьма неплохо!
wmgeek
Creative Super X-FI позволяет воссоздать характеристики высококачественной профессиональной мульти-акустической системы и обеспечивает невероятную симфонию звука в ваших наушниках, используя сложные алгоритмы и объемные вычисления для индивидуальной настройки звучания с помощью составления карты головы и ушей.
ChaoticSys
Что вы думаете по поводу «Wave NX»? Этот плеер учитывает размер головы и расстояние между ушами — а также может следить за положением головы в пространстве с помощью стороннего трекера. (По ссылке есть бесплатные версии для андроида и айфона.)
У меня на телефоне она немного глючит: каждый раз при запуске нужно открывать настройки — хоть они и не сбрасываются, но плеер их сразу читать не хочет, работает с дефолтными. Размер комнаты — ноль — тогда нету эха.
int0Ah Автор
Всё попробовать — жизни не хватит :)
Поставил в очередь.
arkserg
Я пробовал на ПК, для моей головы и ушей результат был на уровне с другими хорошими технологиями. При этом я подключал веб камеру для трекинга — получалась небольшая задержка, но даже так трекинг очень сильно добавлял реализма. Для меня технология очень хорошо работала для боковых и тыловых каналов, но центральный и фронтальные традиционно «прилипали» к голове немного сверху, соответственно когда виртуальный источник звука перемещался из-за спины вперед, вся иллюзия моментально рушилась. Кастомизация размера головы, к сожалению, не дала никакой прибавки в реализме, так как моя голова оказалась именно того размера, который там был выставлен по умолчанию. В итоге отказался от покупки их трекера именно из-за плохой виртуализации фронтальных колонок, которые отвечают, наверное, за 90% звуковой картины будь то фильм, игра или музыка.
arkserg
Всем интересующимся реальным применением данной технологии советую обратить внимание на проект impulcifer С помощью данной программы можно в домашних условиях записать поканальные данные для совственных ушей и использовать их в hesuvi. Я сам в прошлом году заморочился: купил недорогой аудиоинтерфейс для пк, пару микрофонных модулей Primo 258N, спаял микрофонный усилитель к ним и произвел тестовые замеры. Результат получился ошеломительным, никакие Dolby Atmos for Headphones и DTS Headphone:X рядом не стояли. Более того, не поворачивая головы невозможно определить, идет ли звук через наушники или играют колонки, иногда я надевал наушники, садился играть или смотреть фильм и специально снимал их на секунду, чтобы убедиться, что у меня не включены колонки и я не разбужу соседей.
У данной технологии есть несколько недостатков по сравнению с небезызвестным Smyth Realizer:
В общем всем советую, микрофоны стоят копейки, звуковую карту можно у кого-нибудь одолжить, разве что пред собрать может быть проблема, но можно купить\одолжить готовое решение для конденсаторных микрофонов.
int0Ah Автор
Тоже интересно. Но не совсем то, что я хочу. У меня нет «контрольной комнаты», в которой всё звучит заведомо круто, и нет колонок такого уровня. Мне интереснее симулировать в наушниках «идеальную контрольную комнату». Понятно, что утопия, но тем не менее.
PS: Прошу прощения, проморгал когда пост извлекли из песочницы, а тут уже столько обсуждений! :)
arkserg
В этом проекте есть не только модуль подготовки фильтров для эмуляции многоканальной системы в наушниках, но и модуль коррекции виртуального помещения. Я сам эту часть не изучал и не использовал, но знаю, что для неё требуется откалиброванный измерительный микрофон. А вообще можно взять ноутбук, бинауральные микрофоны и сходить записать чью-нибудь чужую систему или, например, демо рум в фирме, торгующей HiFi оборудованием, а потом спокойно использовать её дома.
int0Ah Автор
Коррекция помещения — отдельная очень обширная тема. И интересная — собственно из неё я в своё время и узнал о DRC. Имеется даже весьма неплохой измерительный конденсаторный микрофон от RFT. Но с момента рождения ребёнка слушать через колонки практически не приходилось. Да что там… колонки года 2 простояли где-то на антресолях, а потом были извлечены исключительно ради прослушивания сказок.
С бинауральными микрофонами мысль хорошая, оказывается, уже есть вполне доступные для хобби варианты.
arkserg
Тут смысл не в том, чтобы компенсировать аккустику помещения при прослушивании через колонки, а в том, чтобы скорректировать проведенные измерения с учетом особенностей помещения и всего звукового тракта.
Условно измерения можно разбить на 3 этапа:
Если применить свертку (в терминологии не уверен, потому что математическую часть не знаю) сигналов из п.1 и п.2, то получим отклик, который внутри себя содержит информацию об всем воспроизводящем тракте, включая саму колонку, о комнате, ну и об ухе пользователя. Соответственно при прослушивании будет полная иллюзия того, что мы слушаем конкретные колонки в конкретной комнате. При этом АЧХ самих внутриушных микрофонов значения не имеет, так как её влияние «самоуничтожается» за счет того, что оба измерения мы производили ими.
Но, если в вычисления добавить запись из п.3, то можно избавиться от влияния комнаты и оборудования воспроизведения, и оставить только отклик уха слушателя. То есть при прослушивании аудиоматериала через наушники будет имитироваться именно «безэховая» камера и «идеальный» громкоговоритель. Вот к такому сигналу уже можно применить импульсы записанных «правильных» помещений и наслаждаться прослушиванием.
Конечно прямо идеального результата такими домашними измерениями добиться не получится, всё равно набежит какая-то погрешность на каждом измерении, но отзывы от тех, кто этим заморачивался очень положительные.
int0Ah Автор
Увы, всё не так просто.
Полностью компенсировать отклик комнаты — практически невозможно, там есть как математические ограничения, так и физические.
Например, не любое преобразование вообще можно инвертировать.
Другой пример: в точке прослушивания может быть очень сильный провал на АЧХ за счёт влияния помещения, и если пытаться его полностью компенсировать, начнуться проблемы с переполнением разрядной сетки, увеличением погрешностней, размахом результирующего сигнала и т. п.
Собственно, всё это и определяет сложность систем типа DRC.
arkserg
Вы правы. Я согласен, что не получится записать дешевые колонки в неподготовленном помещении и получить хороший результат, а также очевидно, что дребезжащие в шкафу бокалы никакой фильтр не исправит (утрирую).
Преимущество вертуализации в том, что можно один раз заморочиться при замерах: убрать из комнаты всё лишнее, умеренно заглушить, найти удачную точку для записи и удачное расположение для колонки (нужна только одна, остальные записываются методом поворота слушателя вокруг своей оси), и в итоге получить хорошие отклики, которыми можно с комфортом пользоваться всю оставшуюся жизнь в наушниках.
Кроме того корректировки в «виртуальной» комнате делаются проще, чем в реальной. Например для того, чтобы скомпенсировать провал АЧХ в реальном помещении при прослушивании на колонках, нужно поднять соответствующие частоты в источнике, что может привести к указанным вами негативным последствиям, я же описывал пример, когда мы убираем этот провал не с помощью предварительного усиления определенных частот, а с помощью вырезания этого провала из замера колонки бинауральным микрофоном. То есть в итоговом отклике этого провала не должно быть в принципе.
int0Ah Автор
Я не спорю, можно.
Просто АФАИК, проблема как раз в том, что если есть отражения, то полностью их инвертировать не получится, а в комнате они есть всегда.
То есть полностью заменить измерения в безэховой камере математической обработкой — нельзя. Насколько можно приблизится, и в каких случаях этого достаточно — вопрос дискуссионный.
Что можно попробовать — это снять отклик в большом зале, чтобы до прихода первых отражений от стен и потолка у нас уже было достаточно информации. Вот только с полом так просто не получится…
Этот метод часто используют разработчики акустических систем (особенно DIY) для оценки АЧХ. Но если это коммерческая разработка, то хотя бы в конце обычно снимают АЧХ «правильно», то есть в безэховой камере за деньги.
Saiho
Насколько понимаю, запись отклика на короткий импульс имеет только одно преимущество — скорость проведения измерений. Во всем остальном этот метод проигрывает измерению по тональному сигналу от ГКЧ. Если вы захотите сделать свой личный профиль, а не подобрать похожий по ощущениям от прослушивания сэмплов (это самый слабый момент в вашей истории с точки зрения объективности измерений), то с продолжительным временем измерений можно и смириться. Кроме того, не нужно тягать монитор на сервоприводе — достаточно менять только расстояние и измерять или изменять положение головы. Отражения от стен можно учесть например по сигналу с дополнительных внеушных микрофонов. Итого — сравнительно простое оборудование, разумная подготовка помещения и немного терпения. И уж точно измерять амплитуду и фазу достаточно продолжительного синусоидального сигнала мы умеем как мало что другое. Скорее размер внутриушных микрофонов будет вносить погрешность в измерения на самых высоких частотах, изменяя резонансную частоту ушного канала. Хорошо что реально выше 10кГц мы разбираем детали очень плохо.
Но вижу и один неучтенный эффект при измерении внутриушными микрофонами. Дело в том, что мы слышим не только колебания давления воздуха, но и приходящие через кости и плоть на косточку, стремя, улитку механические колебания. А вот как это измерить представить себе не могу. Поэтому видимо разница между мониторами и наушниками будет оставаться всегда. Вся надежда на то, что это слабый эффект. Вы много прочли по теме. Не встречали оценку его величины?
Ну и конечно остается вопрос о самом аудиоматериале. На мой взгляд, мы просто вынуждены формулировать задачу как «услышать то, что было задумано звукорежем» т. к. ничего большего нам не светит и проверить что добились цели невозможно. Настоящий аудиоматериал появится только когда технология с объективным контролем доставки заданного звукового давления до каждого уха с коррекцией индивидуальных особенностей станет доступной. Это была бы очередная революция в аудио и наверное самая удивительная после патефона. Вот тогда и появятся настоящие произведения искусства, заточенные сначала под реализм, а потом и под всякие извращения, как это уже можно было наблюдать в живописи. Хорошая тема! Спасибо, автор!
arkserg
Я как раз так и записывал профиль своих ушей: брал 2 колонки а сам крутился на офисном кресле в точке прослушивания. Могу сказать, что я не слышу разницу между колонками и наушниками с примененным фильтром вообще. Точнее слышу на частотах ниже 100Гц, но это уже ограничения самих наушников. Однако замечу, что я вообще не слышу частот выше 16кГц, а также не могу в слепом тесте отличить mp3 320kbps от CD, так что возможно более «ушастые» люди будут эту разницу замечать. Чего реально не хватает, дак это трекинга положений головы: пока сидишь неподвижно, иллюзия 100%, как только начинаешь вертеть головой, мозг сразу сигнализирует, что что-то не так.
int0Ah Автор
1. Про импульсный отклик.
На самом деле, обычно его измеряют не прямым способом (подачей короткого импульса на колонку и записью результата с микрофона), а как раз с помощью свип-тона (почти то же, что ГКЧ). Просто от записанного свип-тона переходят к импульсной характеристике, т. к. с ней удобно работать, и она полностью описывает АФЧХ, отражения и пр. Кроме того, по сравнению с прямым измерением импульсного отклика, значительно улучшается соотношение сигнал/шум.
2. Про косточки.
ИМХО, то, что происходит с сигналом начиная со слухового канала в данном случае не имеет значения, т. к. там эффекты будут одинаковы при прослушивании через колонки и наушники.
Другое дело, что самые правильные с этой точки зрения — внутриканальные наушники-«затычки». А с большими наушниками всё становится менее строго…
3. Про революцию
Слабо в это верю, т. к. нет спроса. В качестве иллюстрации: ТТХ аппаратуры (особенно массовой) за последние 20 лет значительно улучшились, а качество фонограмм — нет…
chnav
Подскажите где можно посмотреть работу звукорежиссёра, сводящего разные дорожки и работающим над панорамой с мониторными динамиками. Потому-что все ролики, что я видел, обычно с «лопухами».
Касаемо классики. Как я понимаю часть работы дирижёра как раз заключается в регулировании громкости отдельных инструментов в оркестре. Интересно что будет, если поставить стереомикрофон рядом с ним, чтобы послушать, так сказать, оригинал. Или он всё-же «крутит уровни» отдельных музыкантов с учётом того, как музыка будет звучать в зале?
int0Ah Автор
Насчёт дирижёров — не знаю.
А что Вы подразумеваете под «мониторными динамиками» и под «лопухами»?
Размер НЧ-головки? В контрольных мониторах она вполне может быть 15", тем не менее, это вроде как «мониторный динамик».
Мониторы большого размера — стоят дороже и требуют бОльшего помещения для нормальной работы. И в целом они лучше, т. к. позволяют получить достоверный звук на более низких частотах. Полагаю, по этой причине «для ролика» чаще выбирают более качественные, то есть более крупные и более дорогие мониторы.
chnav
Извините, под динамиками имелись в виду мониторные колонки. написал так потому-что вроде есть и мониторные наушники (лопухи).
Ролики — ролики на ютубе, когда звукорежиссёр работает в наушниках. Колонки не видел. Вот и хотел увидеть описываемую вами работу звукорежиссёра, просто интересно.