

TLDR: приложение можно скачать и потестить тут
Эта статья является дополненной и сильно расширенной версией моей статьи в TowardsDataScience о создании приложения, использующем новейшую мультимодальную нейросеть от OpenAI
В чем проблема классификаторов?
Многие заметили, что в последние годы все чаще для обработки изображений используется нейросетевой подход. Одной из простейших (по формулировке) задач является задача классификации изображений. В ней необходимо определить, к какому из заданных классов относится изображение. Стандартный подход с использованием сверточных нейросетей предполагает использование большого количества последовательных преобразований - сверток, с добавлением простых нелинейных функций, в результате которых изображение превращается в многомерный набор признаков. Далее эти признаки анализируются полносвязной нейросетью. Для обучения подобной нейросети обычно требуется большое количество обучающих примеров - размеченных изображений и сбор данных для конкретной задачи может являться наиболее трудоемким этапом для решения задачи классификации. Чтобы сократить количество необходимых размеченных данных, обычно используется подход переноса обучения (transfer learning). Для этого в качестве сверточной части используют сеть, предварительно обученную для решения задачи классификации на большом датасете (обычно ImageNet). Использование предобученной части позволяет выделять значимые признаки на любом изображении. Далее используется небольшая полносвязная сеть для решение задачи классификации. Использование такого подхода позволяет снизить размер обучающей выборки до нескольких тысяч или даже сотен примеров каждого класса. Тем не менее у вышеописанного подхода есть два существенных недостатка:
Если к сети, обученной определять 1000 классов необходимо добавить еще один класс, нужно существенно менять архитектуру сети и заново переобучать ее с использованием полного датасета, а не только изображений из добавленных классов (есть трюки, чтоб ослабить эту проблему но они не сильно меняют общее положение дел).
Для некоторых задач сбор данных может быть очень затруднительным
Поэтому чашей грааля для решения задачи классификации является реализации концепции Zero shot learning - создание классификатора, способного решить произвольную задачу классификации без обучающих примеров. Звучит немного фантастично и малопонятно, как это может быть реализовано. Многие считают, что для создания такого рода классификатора необходимо привлечь "понимание" естественного языка. К счастью, последние пару лет был достигнут большой прогресс в использовании нейросетей типа Transfirmer для обработки естественного языка. Кроме того, сейчас растет популярность и использования трансформеров для обработки изображений.
Почему CLIP?
В январе этого года был сделан прорыв в области обработки изображений - OpenAI представила новый генератор изображений Dall-E, который может генерировать изображение на основе текстового описания. Несмотря на название OpenAI, код Dall-E не является открытым. Тем не менее, меня очень заинтересовала вспомогательная нейронная сеть для обучения Dall-E и отбора лучших примеров. Это сеть CLIP. CLIP, в отличие от Dall-E, проект с открытым исходным кодом, опубликованный под лицензией MIT, поэтому его можно легко использовать в своих целях. Эта нейронная сеть выглядит не столь впечатляющей для демонстраций публике, но меня она очень удивила. В целом, это двухмодульный проект. Первый модуль - эффективная нейронная сеть Image Transformer. Этот модуль использует State-of-Art механизм внимания для кодирования изображения в 512-мерное пространство. Другая часть - нейросеть-трансформер для обработки текста, который преобразует текст в вектор в то же 512-мерное пространство. Сеть обучалась на большом массиве изображений (каком именно я не нашел, но, похоже, что это что-то типа "весь интернет", "вся википедия" или "весь инстаграм", как недавно сделали в Facebook AI). Процедура обучения не раскрывается, но предполагаю, что использовался loss типа Cosface или Arcface и различные параметры обучения для каждого из модулей. При обучении картинка с подходящей подписью должны быть близки, а с неподходящей - максимально далеки в пространстве embedding-ов.
CLIP хорошо работает для решения задачи zero-shot learning. Для этого необходимо создать набор предложений с использованием шаблона. Предложения могут быть типа "This is a photo of OBJECT", где OBJECT - название одного из множества классов. Набор предложений можно превратить при помощи текстового модуля transformer в набор векторов. Далее смотрится на какой из векторов больше всего похоже закодированное при помощи второго модуля изображение. Если нормировать близость векторов при помощи Softmax, то можно интерпретировать результат как вероятность того, что изображение принадлежит к какому-то классу.

Оказалось, что для многих задач Zero-shot learning работает даже лучше, чем натренированные на специально отобранных датасентах state-of-art сверточные нейросети.
Архитектура приложения
С учетом вышесказанного, приложение для классификации может работать следующим образом.
Телефон обладает доступом к изображениям (с камеры или из хранилища). После предварительной обработки (изменения разрешения и перенормировки каналов) изображение при помощи нейросети-трансформера превращается в 512-мерный вектор. Данный вектор сравнивается с каждым из векторов одного из предварительно сгенерированных наборов. Выдается описание 5 наиболее близких векторов.
Кроме того, существует возможность отправить запрос на сервер для генерации собственного классификатора. Отправляется строка - шаблон и набор классов. С сервера возвращается и сохраняется простой torchScript модуль, содержащий набор векторов и необходимые действия с ними. У пользователя появляется собственный классификатор! Работа с CLIP была на python, Android приложение - на JAVA. Серверная часть - Python/FLASK. Архитектура показана на рисунке.
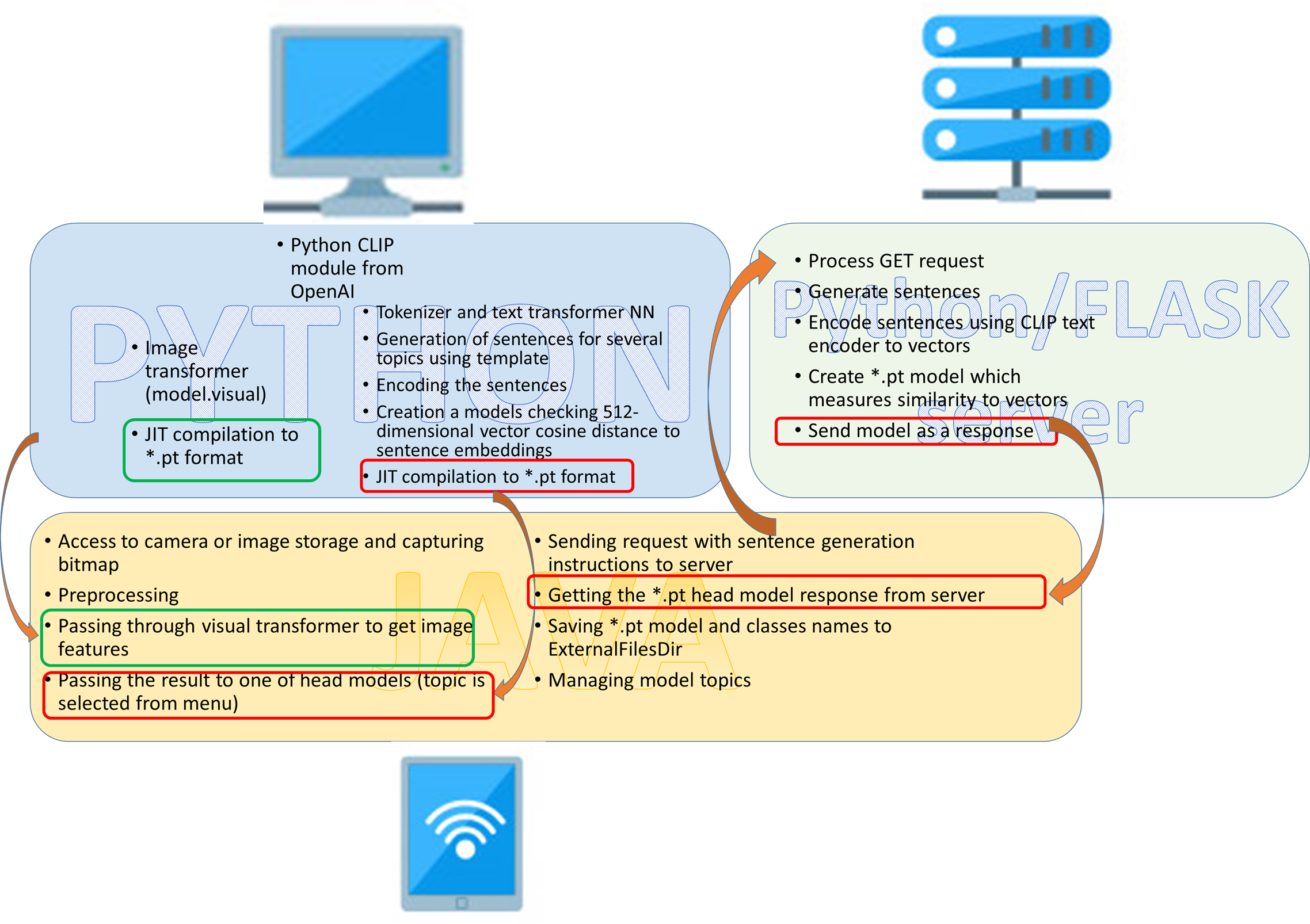
Работаем с CLIP (Python)
Для разработки я использовал дистрибутив Anaconda python. Установим необходимые библиотеки
conda create - name pytorch
conda activate pytorch
conda install - yes -c pytorch pytorch=1.7.1 torchvision cudatoolkit=11.0
conda create - name pytorch
pip install ftfy regex tqdm
pip install git+https://github.com/openai/CLIP.git
conda install -c conda-forge notebookПосле установки необходимых библиотек импортируем их в проект:
И создаем модель CLIP. Работу с ним будем вести на GPU:
Нейросеть для обработки изображений - это модуль clipmodel.visual. Попробуем скомпилировать его и сохранить его отдельно в виде модуля TorchScript. Для этого используется JIT компилятор библиотеки torch (torch.jit). Для JIT компиляции необходимо запустить модуль visual на каком-либо изображении:
Найдем несколько списков названий классов (я использовал 4000 наиболее часто используемых существительных в английском языке, список пород кошек, список 10000 самых известных людей, список названий еды, национальностей и еще несколько других). Функция create_pt_xml создает предложения по шаблону, разбивает их на части (токенизирует), превращает в набор векторов, создает и сохраняет TorchScript модуль для сравнения любого вектора с векторами из набора и нахождения 5 ближайших векторов. create_pt_xml также сохраняет xml файл для чтения названий классов. Сгенерированные файлы будут использованы в приложении:
Создаем приложение для Android (Java)
Так как у меня нет опыта разработки на быстро набирающем популярность языке Kotlin, я использовал Java. В отличии от python, код на Java гораздо более громоздкий и менее выразительный. Поэтому, чтобы не перегружать пост оставлю только 2 наиболее важные части кода. Остальные части - описание работы кнопок/интерфейс - достаточно стандартные для любого приложения.
Первая важная часть - загрузка *.pt модели из папки assets и получение ответа в виде строки в TextView:
В качестве бонуса я добавил модуль, натренированный классическим образом (на большом датасете) для определения вероятности наличия пневмонии (python код не приведен) по флюорографии - сейчас такую задачку очень любят решать.
Вторая важная часть - отправление запроса на сервер и сохранения ответа (модели) в ExternalFilesDir. Список классов и название модели сохраняются в той же директории:
Серверная часть (Python/flask)
Я арендовал VPS на одном из сервисов. О системе - я запустил сервер apache 2.0 с WSGI / Flask под Centos 7 (для меня это была самая сложная часть проекта, поскольку я никогда раньше не работал с развертыванием сервера, на это ушло несколько дней постоянного поиска в Google/StackOverflow). Серверная часть Python очень похожа на функцию cerate_xml. Единственная разница заключается в обработке запросов и отправке сгенерированного файла модели. К сожалению, сервер работает не так быстро, как хотелось бы. Возможно, если приложение будет популярным, мне стоит перенести наиболее тяжелые вычисления (кодирование текста через текстовый трансформер) в AWS Lambda:

Буду смотреть по нагрузке.
Крутая часть! Тестируем!
Приложение работает на удивление хорошо. Сначала давайте повторим удивительные результаты OpenAI, который обнаружил схожие активации нейронов в одной концепции, представленной разными способами:

Общий классификатор NOUN использует 4000 наиболее часто используемых английских существительных и предложений, сгенерированных шаблоном «This is an image of NOUN».
Приложение определенно «понимает», что все эти понятия относятся к паукам. Интересно, что оно распознает текст, поэтому я решил протестировать его на работах бельгийского художника Рене Магритта, чьи работы в значительной степени наполнены взаимодействием слов и изображений:

Ничего особо интересного. Интересное начинается, когда я пытаюсь описать этот образ, используя национальность или использовать модель, которая может выдать только названия коктейлей или породы собак:

Здесь есть что-то определенно французское) Мне стало особенно любопытно, можно ли описывать любые изображения, используя названия коктейлей:

Список похожих коктейлей меня порадовал. Зеленый гоблин? Кажется у сети все неплохо со знанием вселенной Marvel) Также очевидно, что это изображение чего-то красного и большого, летающего или даже похожего на насекомое. Чтобы протестировать серверную часть, я создал на телефоне классификатор, определяющий профессию по изображению. Я нашел список из 30 профессий в одном из учебников английского языка и добавил их. Модель была успешно сгенерирована на сервере и загружена. К сожалению, на это ушла пара минут (

Проверим, как работает созданная на сервере модель:
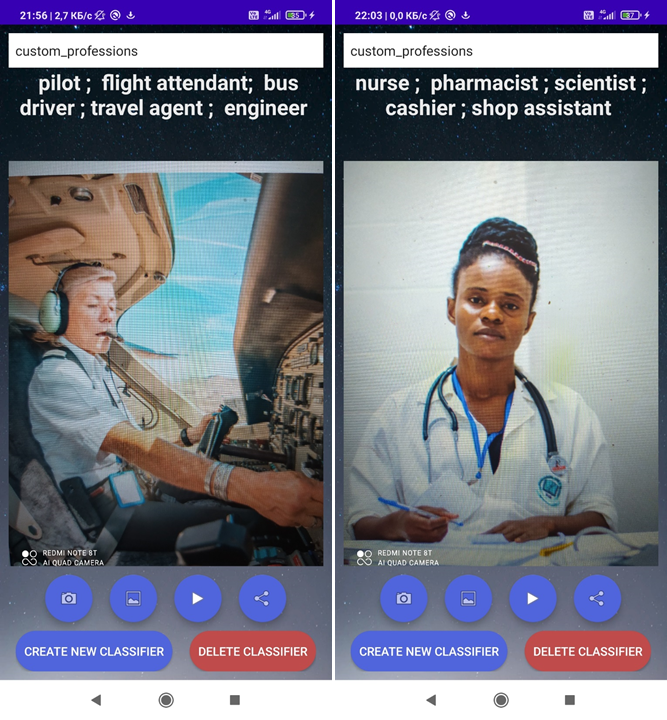
Видим, что приложение неплохо определяет профессии.
А кто по профессии Человек-Паук?

Что касается других классификаторов, то они работают хорошо:

Или, как выяснили исследователи OpenAI, мы можем использовать их для выявления некоторых географических ассоциаций:

Думаю ассоциативному мышлению неизбежно сопутствует предвзятость, поэтому от нее невозможно полностью избавиться в сложных системах типа нейросетей:

Посмотрим, понимает ли нейросеть русский язык. Если использовать стандартный классификатор, результаты не очень. Если уточнить, что это животное - уже лучше:

При этом с пониманием английского проблем нет, а с китайским - есть:

А можно ли превратить приложение в переводчик? Ограничимся названием животных. Шаблон: This is NAME in russian. NAME - список из 100 часто встречающихся животных:

/

Загрузка на Google Play market
Основной проблемой стало ограничение на размер загружаемого *.aab файла. Из-за большого размера трансформерной нейросети приложение пришлось разбить на 2 части с использованием механизма Asset Delivery. Оказалось, что оно некорректно доставляет Assets при внутреннем тестировании - отправил запрос в техподдержку, но ответа не получил. Я подключил firebase для сбора аналитики, нарисовал простую страничку с описанием и отправил приложение в Play Market, где оно проверялось в течение 1 недели.
Монетизация
Если приложение будет пользоваться популярностью, я собираюсь добавить пару баннеров из AdMob, чтобы оплатить сервер и заработать немного денег)
Проблемы
В описываемом приложении есть несколько проблем. Во-первых, я обнаружил медленный (5 с) холодный запуск на нескольких устройствах из-за загрузки преобразователя изображений в оперативную память при запуске приложения. Вторая проблема - медленный ответ сервера на запросы новых классификаторов. Эту проблему можно решить, перенеся вычисления в облако (я думаю о сервисе AWS-lambda), но сейчас мне сложно оценить стоимость AWS. Мне, вероятно, следует ограничить ежедневные запросы к серверу для каждого пользователя или взимать плату с пользователей за расширение лимита, чтобы покрыть расходы AWS и обеспечить лучший UX. Третья проблема возникла сегодня - нестабильный доступ к серверу. Похоже связано с "замедлением Твиттера".
Что можно добавить
Еще подумываю добавить режим one-shot (одна фотография используется для создания классификатора). Это улучшение можно легко реализовать в приложении.
Если говорить непосредственно о перспективах CLIP - я много играл с комбинацией CLIP и BERT для генерации описания изображения на естественном языке и уже получил некоторые многообещающие результаты. Но BERT определенно нельзя запускать на телефонах, и даже на моей rtx3080 (успел купить за 80!) есть некоторые проблемы для быстрого прототипирования таких систем. Также пробовал реализовать CLIP Style transfer с описанием обработки фото естественным языком - результат пока не очень, на это следовало бы потратить больше времени. Кроме того подозреваю, что использование CLIP для покадровой обработки видео и анализа потока векторов при помощи трансформеров или LSTM (почему-то кажется, что LSTMы будут лучше работать) может привести к прорыву в нейросетевом описании видео - сейчас результаты в этой области достаточно скромные.
Спасибо!
Не стесняйтесь обращаться ко мне в случае новых идей, предложений или вопросов!
Полезные Ссылки:
О Dall-e:
О CLIP
О мультимодальных нейронах CLIP
Github CLIP


george3
Спасибо за статью! 1. Мне кажется, что генерация модели Текст-вектор можно избежать) Есть же универсальная, по ней получаем N векторов для классификации и получив вектор картинки ищем ближайшие классификатора, причем расстояние до них — мера вероятности. 2. Много интересней лично мне поиск картинка — ближайшие картинки по 2-4 примерам. Слова искажают смысл больше чем изображения, а выявить общность по минимуму изображений в векторах аналитически — интересно. Предварительно CLIP вполне годится для этого. Согласны?
Sakhar Автор
Да, согласен, как раз планирую добавить р — это и подразумевается под one-shot learning в последней части статьи. Тем более для её реализации не нужна серверная часть. Пока самое большое препятствие для реализации — непонятно, как должен выглядеть интерфейс, чтобы было удобно и надо ли на один класс позволять грузить несколько фото (тогда это уже не one-shot learning и будет громоздко). Кроме того, до добавления этой идеи следует её потестировать на компе — могут возникнуть некоторые принципиальные проблемы с тем, на что именно обращается внимание. К примеру, если показать бородатого доктора в белом халате, то что будет ближе — фото бороды, халата или доктора-женщины? Ответ мне пока непонятен
george3