
Виртуальная машина представлена несколькими файлами, которые располагаются на жестком диске хоста, что позволяет производить над ней такие действия как копирование, удаление, восстановление. Все просто и понятно: есть некие файлы (конфигурация и жесткие диски) они запускаются в неком гипервизоре, и все работает как настоящий сервер. Это действительно экономит деньги предприятию и время админу. В особенности хорошее решение — это кластер, здесь объединяются несколько хостов и при выходе из строя одного виртуальные машины переходят на другой.
В нашей организации мы используем отказоустойчивый кластер на основе Windows Server 2012 R2 Data Center (Hyper-V кластер). По небольшому опыту могу сказать, что кластер довольно удобная вещь, так как есть возможность высвобождения каждого хоста для каких-либо административных задач простым переносом — миграцией виртуальных машин на другой хост — например, для установки обновлений или ПО, и плюс в том, что если «сгорит» один из хостов, то виртуальные машины продолжат работать практически без паузы — сработает миграция («главное чтобы она сработала») — все продолжит работать, но если она не сработает и виртуальная машина повредится, то данные можно будет вытащить непосредственно с файла жесткого диска.
Большинство проблем, которые у нас были это повреждение или исчезновение xml-файлов, являющиеся файлами конфигурации или частью информации снепшотов. Происходило это, в большинстве своем, при перезагрузке хоста, когда виртуальная машина не мигрировала на другой хост кластера (при этом все проблемные машины были 2008 сервера); заканчивалось место на виртуальном жестком диске и почему-то исчезал снепшот; после удаления снепшота — не происходило слияние, а снепшот удалялся. В чем проблемы и с каким бубном к ним подходить — каждый раз это выяснять не было желания. Поэтому сделали следующие шаги для оптимизации системы:
- переход всех виртуальных машин и хостов на 2012 R2 DATA CENTER, потому как он себя показал на практике довольно стабильно и более быстродейственно: быстро выключается, включается и перезагружается, экономит бюджет посредством AVMA-активации — неограниченная активация виртуальных машин 2012 R2 DATA CENTER внутри хоста;
- удаление всех снепшотов у виртуальных машин (за счет снепшотов виртуальная машина может значительно прибавить в размере);
- уменьшение размера статических жестких дисков виртуальных машин — выделение столько места сколько необходимо (например, для серверов баз данных), тем более при необходимости всегда можно увеличить;
- применение динамических жестких дисков для тех виртуальных машин, где не нужна быстрая скорость работы диска (например, контролеры домена, сервера лицензий и т. д.).
Наш парк виртуальных машин стал занимать меньше места на дисках, и машины были разделены по задачам и в соответствии с этим им было назначено необходимое количество ресурсов.
Все это было подготовкой к созданию системы резервного копирования виртуальных машин. Мы начали рассматривать существующие готовые системы, но столкнулись с основной проблемой — это деньги. Да как всегда они! Нам сказали: «Деньги есть, но их мало…» Что в переводе означает: «Не дадим ничего!». Но все-таки мы не теряли надежду на финансирование, поэтому стали рассматривать сначала платные варианты — первым был DPM от Microsoft. Читали о нем — есть много хороших отзывов, но есть много и проблем.
Попытались поставить, попытались несколько раз ставить: первый раз умер MS SQL не понятно почему, 2-ой раз самый эпичный исход, который только можно было ожидать — DPM убил сам себя! Создали 2 виртуальные машины: 1 — sql-server, 2 — dpm c прикрепленным физическим диском (машины располагались не в кластере, а на отдельном серваке Hyper-v Rezerv), в кластере установили агентов и начали тестировать, в результате все работает — все бекапит. Начали тестировать функции восстановления — восстанавливали на сервер Hyper-v Rezerv, но увидели надпись «виртуальная машина Sql-server будет удалена». Выяснилось что id машины, которую восстанавливали совпал с id машины sql-server, потому что тестировали восстановление на эталонной виртуальной машине, которую копируем путем экспорта и так создаем новые виртуальные машины, но в этот раз sql-server был создан путем регистрации по месту… Таким образом, получились две виртуальные машины с одинаковом id — одна эталонная в кластере, другая на резервном хосте Hyper-V Rezerv. При восстановлении виртуальной машины DPM «смотрит» на id и, если он совпадает, то удаляет виртуальную машину, а копию восстанавливает на ее место. Получилась очень злая и смешная ошибка. Запомнил навсегда, что нельзя допускать ситуаций, чтобы в системе виртуализации даже на разных хостах, кластерах, да где угодно были машины с одинаковыми id.
Подумал: «Черт с ним, сейчас создам все заново.» Но вышло, что при всех последующих установках с разных дистрибутивов, даже на разных хостах выскакивала одна и та же неизвестная ошибка в процессе установки. На форумах писали: битый дистрибутив. Так ведь вчера было все нормально! Да и скачивал еще несколько раз… В общем, магия, сглаз, или же просто мелкософт… История трагична. Поэтому плюнули на мелкософтных и начали смотреть в другую сторону.
DPM довольно неплохая штука и не дорогая, но использует MS SQL-Server Standart, бекапы хранит на динамическом диске — почему я акцентирую внимание на этом, потому что это не удобно: SQL-Server стоит денег, сложен, а без его баз работа с динамическим диском становится бесполезной, то есть повреждается база и всё… Все бекапы потеряны… Или нужен очень сильный бубен… Не понятно почему не использовать статический диск, который можно было подключать куда угодно с легкостью, нежели динамический. И с ленточным хранилищем DPM не заработал: постоянно инвентаризировал ленты, но ничего не записывал.
Следующий продукт, который безусловно понравился — это Veeam. Он очень удобен и его зеленый цвет безусловно радует серый админский интерфейс, но цена для организации ошеломляющая (у нас кластер на 6 двухпроцессорных лезвиях). Мы его протестировали и были бы готовы использовать при наличии денег. Но увы.
В процессе рассмотрения продуктов для бекапов мы бекапили вручную, потом с помощью скрипта на PowerShell. И в последствии решили доделать скрипт, который бы и выполнял поставленные задачи.
Некоторые скажут, что зря… Что зачем изобретать велосипед… Что есть достойные бесплатные программы.
Я выбрал скрипт потому как не надо сервера баз данных. Все что нужно это табличка «что, когда бекапиться» и логи для отладки. И, собственно, это бесплатно и это саморазвитие.
Но есть один существенный минус: с помощью платных и бесплатных программ можно вытянуть с виртуальной машины непосредственно данные — файлы или базы, а скрипт позволяет делать копию только всей виртуальной машины. Но мы над этим работаем и возможно в следующих статьях я это продемонстрирую. Я еще новичок — 2 года в администрировании и 3 года работы с юзверями, и знаете, с серверами легче общаться.
Итак, мы планировали бекапить полностью виртуальные машины — почему? Да, потому, что
- нет смысла бекапить снепшоты виртуальных машин — настройка которых занимает час или 2, например, серверы лицензий, видеоконференций, даже терминалы (если они без данных) — легче сбекапить полностью сконфигурированную машину и быстро донастраивать, нежели играть в стратегию со снепшотами (от которых вм разрастается);
- если использовать динамические диски, то многие виртуальные машины без снепшотов весят до 20 Гб (например, контроллеры домена) — это от силы час экспорта — то есть час и у нас есть полная работоспособная копия виртуальной машины, которую мы можем развернуть по месту на резервном сервере за 2 минуты при условии, если она туда экспортировалась.
Что для этого метода критично — это время: какая бы быстрая сеть у вас не была, но построение экспортируемой копии по сети дело долгое для Hyper-V — примерно 40 Гб в час на гигабитной сетке — по крайней мере так у нас, если у вас быстрее, прошу в комментариях пояснить почему. Из этого расчета за ночь, с 00:00 до 7:00, у нас есть возможность сбекапить порядка 280 Гб, но это ночь и это мелкософтные, да и виртуальная машина в 300 Гб довольно большое и неповоротливое животное — поэтому после анализа наших задач ограничились размером в 100-120 Гб для виртуальных машин. В этот диапазон вошли почти все наши сервера, даже сервера баз данных. Настроили бекап в зависимости от изменчивости и важности виртуальной машины — чем чаще изменяется, тем чаще копируем, но это не касается сервера баз данных — его копируем раз в неделю, а сами базы средствами SQL — 4 раз в день — таким образом, полная копия есть недельной давности, а сами базы каждодневные.
С файловыми серверами и такими монстрами, как сервера обновлений (все машины больше 200 Гб) поступили следующим образом — если к виртуальной машине не подключены физические диски, то бекапим раз в полгода или раз в три месяца, если же подключены, то бекапим 1 раз ради конфигурации виртуальной машины, потому как экспортировать физический диск невозможно. В таких машинах придется налаживать копирование файлов отдельным скриптом либо вручную — мы делаем это следующим батником:
xcopy F:\DATA H:\BackUP /H /Y /C /R /E
Диск H — это диск, подключенный по ISCSI.
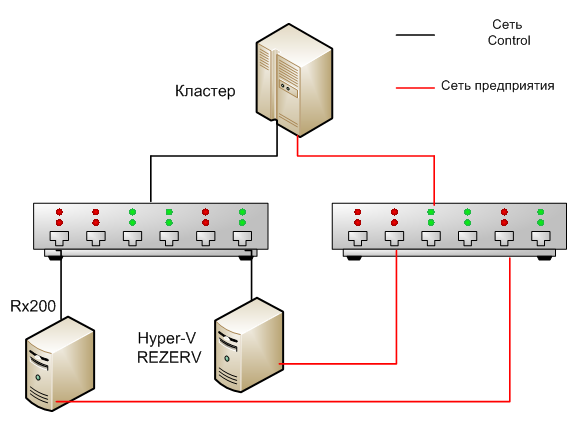
Таким образом, мы разграничили файловые бекапы и бекапы виртуальных машин. Кроме того, для большей надежности мы разграничили сети: сеть Control — для хостов и сеть предприятия — для виртуальных машин. Нет доступа к хостам из сети предприятия, что обеспечивает защиту как от несанкционированного доступа, так и от вирусов, которые удачно распространяются юзверями. Сеть Control отделена физически — это отдельные свитчи, подключенные к отдельным портам хостов, а при настройке виртуальных коммутаторов хостами используется только сеть control. Для сети предприятия создан отдельный виртуальный коммутатор, который не используется хостами. Также проблемы в сети предприятия, например кольца или же «взбесившаяся» сетевая карта, не повлияет на работоспособность сети Control.
Опишу конфигурацию. Сразу уточню, что операционная система на всех серверах — Windows Server 2012 R2 Data Center. Кластер состоит из 6 лезвий Fujitsu BX924 S3 (3 шт) и BX924 S4 (3 шт), которые располагаются в шасси BX900 S2. Посредством FC коммутатора лезвия подключаются к дисковой полке Eternus DX80, на которой выделены LUN-ы — по 250 Гб для операционки, 20 Гб кворум и 6 Тб — хранилище виртуальных машин. Кластер — Hyper-V кластер. Также имеется одноюнитовый сервер Fujitsu RX200 с ролью Hyper-V, на котором размещаются виртуальные машины: основные контроллеры домена предприятия и основной DC кластера, второстепенные размещаются в кластере. Еще в нашем парке серверов — сервер бекапов Supermicro с двумя процессорами и 196 Гб оперативной памяти — этот тот самый сервер Hyper-V Rezerv. На нем поднята роль Hyper-V и на него осуществляется экспорт виртуальных машин — в случае потери виртуальной машины можно из бекапа восстановить (импортировать в Hyper-V путем импорта с регистрацией по месту, если необходимо немедленно) всего за пару минут.
Сеть Control — одногигабитная сеть, сеть предприятия 10-гигабитная в пределах серверов и 1-гигабитная в остальных сегментах сети.
Теперь перейдем к самому скрипту. Я его писал так, чтобы он смог найти в кластере виртуальную машину, подключиться к узлу кластера, завершить работу или сохранить виртуальную машину и, собственно, экспортировать в шару на Hyper-V REZERV, а потом включить виртуальную машину.
Вот текст скрипта:
$LOG="C:\ClusterStorage\Volume1\ps\log\log.txt" //расположение логов
$h="Gse264-bl1","Gse264-bl2","Gse264-bl3","Gse264-bl4","Gse264-bl5","Gse264-bl6" //массив хостов кластера
$VmName="Stream.local.ru (2012r2)" // имя виртуальной машины
$blade= hostname // имя хоста, на котором запускается скрипт
$password = ConvertTo-SecureString "Ofiget_Arbuz" -AsPlainText —Force // пароль для учетной записи доменного администратора для сети Control
$cred= New-Object System.Management.Automation.PSCredential ("control", $password ) // переменная содержащая данные аутентификации
foreach($i in $h){ //для каждого хоста в кластере
$vms=Get-ClusterNode $i | Get-Clusterresource| ?{$_.ResourceType -eq 'Virtual Machine'}|Get-Vm //составляем список вм на хосте
foreach ($cn in $vms){ //для каждой вм на хосте
if ($cn.name -eq $VmName) осуществляем проверку: имя виртуальной машины совпадает с необходимым
{write "$(get-date -format "dd.MM.yy.HH.mm.ss") Обнаружена $VmName на $i" | out-file $LOG —append //пишим обнаружена вм
if ($i -eq $blade) //если хост является хостом, на котором запущен скрипт
{write "$(get-date -format "dd.MM.yy.HH.mm.ss") $cn.name располагается локально" | out-file $LOG -append
$path=get-date -format "dd.MM.yy.HH.mm" //имя папки
New-Item -Path \\Hyper-V REZERV\$blade\$path -ItemType "directory"
write "$(get-date -format "dd.MM.yy.HH.mm.ss") ______ЭКСПОРТ_____________" | out-file $LOG -append
Get-date | out-file $LOG -append
try {
$vmstate= get-vm $VmName
if ($vmstate.state -eq "running"){
write "$(get-date -format "dd.MM.yy.HH.mm.ss") завершаем работу $VmName" | out-file $LOG —append
Stop-VM $VmName -ErrorAction Stop}
write "$(get-date -format "dd.MM.yy.HH.mm.ss") $VmName была выключена ранее" | out-file $LOG -append
write "$(get-date -format "dd.MM.yy.HH.mm.ss") пытаемся экспортировать $VmName" | out-file $LOG -append
Export-VM -Name $VmName -Path \\Hyper-V REZERV\$blade\$path -ErrorAction Stop
write "$(get-date -format "dd.MM.yy.HH.mm.ss") Возобновляем работу $VmName" | out-file $LOG -append
Start-VM $VmName -ErrorAction Stop
write "$(get-date -format "dd.MM.yy.HH.mm.ss") ВСЕ ПРОШЛО УСПЕШНО!!!" | out-file $LOG -append
}
catch {$path | Out-File $LOG —append
"$_" | Out-File $LOG -append
Start-VM $VmName</br>
write "$(get-date -format "dd.MM.yy.HH.mm.ss") $VmName произошли ошибки!!!" | out-file $LOG -append </br>
}
}
else {
$s = New-PSSession -computerName $i -authentication CredSSP -credential $cred
Invoke-Command -Session $s -Scriptblock {
$blade= hostname
$LOG="C:\ClusterStorage\Volume1\ps\log\log.txt"
$path=get-date -format "dd.MM.yy.HH.mm"
New-Item -Path \\Hyper-V REZERV\$blade\$path -ItemType "directory"
$vm="Stream.local.ru (2012r2)"
write "$(get-date -format "dd.MM.yy.HH.mm.ss") ______ЭКСПОРТ_____________" | out-file $LOG -append
try {
$vmstate= get-vm $vm
if ($vmstate.state -eq "running"){
write "$(get-date -format "dd.MM.yy.HH.mm.ss") завершаем работу $vm" | out-file $LOG -append
Stop-VM $vm -ErrorAction Stop}
else {write "$(get-date -format "dd.MM.yy.HH.mm.ss") $vm была выключена ранее" | out-file $LOG -append}
write "$(get-date -format "dd.MM.yy.HH.mm.ss") пытаемся экспортировать $vm" | out-file $LOG -append
Export-VM -Name $vm -Path \\Hyper-V REZERV\$blade\$path -ErrorAction Stop
write "$(get-date -format "dd.MM.yy.HH.mm.ss") Возобновляем работу $vm" | out-file $LOG -append
Start-VM $vm -ErrorAction Stop
write "$(get-date -format "dd.MM.yy.HH.mm.ss") $vm ВСЕ ПРОШЛО УСПЕШНО!!!" | out-file $LOG —append
}
catch {$path | Out-File $LOG —append
"$_" | Out-File $LOG -append
Start-VM $vm
write "$(get-date -format "dd.MM.yy.HH.mm.ss") $vm произошли ошибки!!!" | out-file $LOG -append
}
}
Remove-PSSession $s}
}}
}
Сам по себе скрипт не сложный, в нем есть функционал для отслеживания ошибок — try catch, есть ряд сообщений, которые записываются в лог и дают понять насколько успешно прошел экспорт. Есть одна загвоздка — данный скрипт запускается от имени доменного администратора, необходимо поставить галочки: «для пользователей вошедших в систему» и «выполнить с наивысшими правами». Без этих галочек удаленное подключение к другому хосту не будет выполнено. Также необходимо произвести настройку Powershell для осуществления экспортирования виртуальной машины с одного удаленного компьютера на шару другого — multi-hop authentication. настраивал по этой статье. Чтобы hyper-v смог осуществить экспорт в сетевую папку необходимо в настройках ее безопасности добавить имя хоста, с которого осуществляется экспорт и дать полный доступ. На сервере бекапов Hyper-V REZERV запущен скрипт, выполняющий удаление файлов и папок, дата изменения которых больше 63 дней. На нем же установлен Veeam Backup Free edition, который раз в месяц записывает на магнитные ленты по fiber channel все папки с виртуальными машинами, которые экспортировали в течение месяца.
Подведу итоги: создан скрипт для полного экспорта виртуальной машины — с одной стороны это не удобно, с другой дает шанс моментально восстановить полную работоспособность сервера. Полная копия — это действительно долго, но так как хосты выделены в отдельную сеть, которая имеет небольшие размеры и отделена физически от сети предприятия, то это не ухудшает производительность работы в предприятии. Некоторые машины необходимо выключать перед экспортом, например, такие как, сервера баз данных, чтобы получить работоспособный бекап, поэтому советую такие сервера делать небольшими, ну а если этого не получается, то бекапить только базы данных, например, по расписанию средствами MS SQL. Для небольших виртуальных машин лучше использовать динамические диски — так экспорт займет мало времени.
К примеру, все наши контроллеры домена используют динамические диски, и поэтому весят такие виртуальные машины до 20 Гб — экспорт занимает минут 30-40. Также некоторые машины можно бекапить «на горячую», не переводя машину в состояние сохранена или без завершения работы, но подробных статей, где описывались тесты такого экспорта я не нашел, если Вам больше известно поэтому поводу прошу пишите в комментариях. Также все, что мне нужно делать это проверять логи — отработал скрипт или нет, так что я считаю что такая система действительно сможет обеспечить предприятию защиту от потери данных и сэкономить деньги.
P.S.: Выражаю огромную благодарность пользователям форума Technet, без их помощи постройка моего первого кластера и настройка бекапов была бы намного сложней. Надеюсь, что данная статья пока что неопытного админа будет полезна и интересна!
Комментарии (19)

realscorp
17.09.2015 14:07+1Следующий продукт, который безусловно понравился — это Veeam. Он очень удобен и его зеленый цвет безусловно радует серый админский интерфейс, но цена для организации ошеломляющая (у нас кластер на 6 двухпроцессорных лезвиях). Мы его протестировали и были бы готовы использовать при наличии денег. Но увы.
В бесплатной версии всего два ограничения, емнип:
1. Нет инкрементных бэкапов
2. Невозможно создать расписание из GUI
Первое ограничение для вас не так уж и важно, если по итогу вы все равно делаете полные бэкапы для всех машин. А второе можно обойти использованием Powershell-скриптов, т.к. у Veeam есть Powershell API.
А вообще по статье очень сложно понять общую схему бэкапа. Например, непонятно, куда что бэкапится. Такое ощущение, что все лежит на одном хранилище и только раз в месяц уходит на ленты.
Поэтому сложно что-то покритковать или чему-то научиться.
А так — могу посоветовать пристальнее присмотреться к встроенному Windows Backup в WS2012. Например, с его помощью можно делать инкрементальные бэкапы на отдельное хранилище по iscsi. Для бэкапа больших файл-серверов работает просто отлично и люто экономит место плюс можно без проблем восстанавливать отдельные объекты ФС.
Да, собственно, для бэкапа почти любых серверов работает хорошо — к примеру, можно без остановки делать application-consistent бэкапы серверов БД и Exchange.
Более того, бэкапы можно делать не только, запуская WB из гостевой машины, но и из хоста тоже, и даже остается возможность инкрементальных бэкапов. Правда, насколько я знаю, консистентные бэкапы серверов БД так уже не сделать.
Из минусов — полное восстановление сервера из бэкапа может быть весьма медленным и, в некоторых случаях, небеспроблемным.

Botkin
17.09.2015 14:31+1Позволю себе несколько замечаний.
1.«сгорит» один из хостов, то виртуальные машины продолжат работать практически без паузы — сработает миграция («главное чтобы она сработала») — все продолжит работать
Это не так, после отработки отказа виртуальные машины будут в состоянии как после hard reset. И отработает она не мгновенно, а через несколько минут.
2. Снапшоты для бекапов не предназначены.
3. По гигабиту должно копироваться около 400 Гб в час (120 МБ/с * 60 * 60 / 1024), т.е. в 10 раз быстрее, чем у вас. При этом Windows Backup сервера exchange у нас отдаёт по 100 гигабайт в час примерно, что тоже не 400, но там большую часть времени занимает «подготовка».
На всякий случай Windows Server 2012 умеет агрегировать каналы, поэтому можно легко сделать 2 гигабита.
4. Динамические диски вроде как не рекомендуют использовать в продакшне
По возможности рекомендую бекапить всё-таки рабочие нагрузки, а не виртуальные машины. SQL server прекрасно умеет это делать самостоятельно, домен-контроллеры и exchange — средствами windows backup. Многие продукты имеют встроенные механизмы бекапа. Скрипту остаётся лишь забрать бекапы и куда-нибудь сложить для хранения.
YuriSerpinsky
18.09.2015 00:401. hard reset — долго думал, термин из области мобильных устройств :)
4. насколько я помню, для vhdx эту тему отменили и теперь можно, не рекомендуется использовать динамическую памятьBotkin
18.09.2015 08:46А как ещё назвать reset по кнопке? :)
Про динамическую память, пожалуй, попрошу пруфов. Потому что у меня прямо противоположная информация, если в гайде к приложению явно не указано, что динамическую память использовать нельзя (например Exchange)
stigory
20.09.2015 03:18А как ещё назвать reset по кнопке?
На IBM PC-совместимых компьютерах с древности прижились термины «cold reboot» и «warm reboot».
P.S — Но, случайно заглянув в русскоязычную версию этой статьи, увидел термины «hard reboot», «soft reboot».
Ощутил себя динозавром.

shmelfrol
17.09.2015 14:59По гигабиту должно копироваться около 400 Гб в час (120 МБ/с * 60 * 60 / 1024), т.е. в 10 раз быстрее, чем у вас.
копировать можно с такой скоростью, а экспортировать виртуальную машину нет — выходит намного медленнее: эскпорт происходит по сети в расшаренную папку. Даже интересно можно ли ускорить этот процесс?
fleaump
18.09.2015 10:18Конфигурация полкиPDs for VD 0:
# cat /etc/redhat-release
CentOS Linux release 7.1.1503 (Core)
— DG Arr Row EID:Slot DID Type State BT Size PDC PI SED DS3 FSpace
— 0 — - — - RAID60 Optl N 29.107 TB dflt N N none N
============
Basics:
======
Controller = 0
Model = LSI MegaRAID SAS 9261-8i
— EID:Slt DID State DG Size Intf Med SED PI SeSz Model Sp
— 252:0 0 Onln 0 7.276 TB SATA HDD N N 512B ST8000AS0002-1NA17Z U
252:1 1 Onln 0 7.276 TB SATA HDD N N 512B ST8000AS0002-1NA17Z U
252:2 2 Onln 0 7.276 TB SATA HDD N N 512B ST8000AS0002-1NA17Z U
252:3 3 Onln 0 7.276 TB SATA HDD N N 512B ST8000AS0002-1NA17Z U
252:4 4 Onln 0 7.276 TB SATA HDD N N 512B ST8000AS0002-1NA17Z U
252:5 5 Onln 0 7.276 TB SATA HDD N N 512B ST8000AS0002-1NA17Z U
252:6 6 Onln 0 7.276 TB SATA HDD N N 512B ST8000AS0002-1NA17Z U
252:7 7 Onln 0 7.276 TB SATA HDD N N 512B ST8000AS0002-1NA17Z U
# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda1 30T 15T 15T 50% /mnt/lun
ethtool enp4s0f1
Settings for enp4s0f1:
Supported ports: [ FIBRE ]
Supported link modes: 10000baseT/Full

Ghool
21.09.2015 18:04Ну, миграция наживую есть и в HyperV (пока все хосты живы — мигрирует, а в случае падения гипервизора — да, резетится на другом гипервизоре)
А с USB — да, беда.fleaump
21.09.2015 18:47когда переходил, не было миграции, но тогда главный был вопрос USB ключи для 1ски, программными нет возможности обойтись изза «особенной» редакции

Sergey-S-Kovalev
18.09.2015 06:38+4Простите, я не смог удержаться :)
Ниже вполне здоровая критика и направления куда копать.
| В общем, магия, сглаз, или же просто мелкософт
В темные века природные явления были магией и результатом деятельности богов, а болезни результатом сглаза. С тех времен человечество выросло и разобралось в причине и следствиях многих вещей.
Так и у вас, вы не можете объяснить причину, поэтому по дефолту виноват микрософт, а на кривизну собственных рук никто внимания обращать не хочет. Частое явление :)
| экономит бюджет посредством AVMA-активации — неограниченная активация виртуальных машин 2012 R2 DATA CENTER внутри хоста;
только если двухсокетный хост может держать более 14 гостевых систем начинается профит от покупки редакции Data Center
| удаление всех снепшотов у виртуальных машин
не используйте снапшоты сами по себе
| за счет снепшотов виртуальная машина может значительно прибавить в размере
совсем не обязательно, больше проблем может вызвать время консолидации и проседание производительности хранилища в этот момент
| применение динамических жестких дисков для тех виртуальных машин, где не нужна быстрая скорость работы диска
фиксированный размер жестких дисков нужен только для разделов с базами данных, в остальных случаях вполне позволительно использовать динамически расширяемые диски. а для файлохранилищ еще и включить дедупликацию на разделе
| 2-ой раз самый эпичный исход, который только можно было ожидать — DPM убил сам себя!
прощальную записку с признанием оставил? или вы сделали настройки и нажали кнопки не до конца понимая, что то делаете на так?
| Выяснилось что id машины, которую восстанавливали совпал с id машины sql-server
[/facepalm], но рад, что вы быстро усвоили урок, и не на продакшене.
| MS SQL-Server Standart,
[grammar nazi]
D. Все англицкие «стандарт» заканчиваются на D. SQL Server Standard
[/grammar nazi]
| DPM [bla bla bla] бекапы хранит на динамическом диске
DPMу презентуется хранилище (к примеру локальный диск без файловой системы), а там он уже сам нарезает динамические разделы, и могу сказать, что их там могут быть сотни на одном диске.
| то есть повреждается база и всё… Все бекапы потеряны
тсс, парень, базу DPM тоже можно бэкапить
| Не понятно почему не использовать статический диск, который можно было подключать куда угодно с легкостью, нежели динамический.
обычная фобия. пройдет с годами :) да и SAS диски куда угодно тоже не подключишь
| Я выбрал скрипт потому как не надо сервера баз данных. Все что нужно это табличка «что, когда бекапиться» и логи для отладки. И, собственно, это бесплатно и это саморазвитие.
у вас много свободного времени, когда его не станет, такой самопал исчезнет.
| а скрипт позволяет делать копию только всей виртуальной машины
эм. диск виртуальной машины Hyper-V можно подключить виртуальным жестким диском в любой винде начиная с вин7 через powershell, или через диспетчер управления дисками
| построение экспортируемой копии по сети дело долгое для Hyper-V — примерно 40 Гб в час на гигабитной сетке
а нет ли у вас затыка на датасторе или в сети? у меня даже банальный экспорт с хоста полностью утилизирует гигабитный интерфейс, это порядка 350 гигабайт в час
|xcopy F:\DATA H:\BackUP /H /Y /C /R /E
переходите уже на robocopy, если сильно хочется копировать встроенными средствами
| Сеть Control отделена физически
вы либо не знакомы с парктикой использования VLAN, либо у вас нет управляемого сетевого оборудования, что вполне объясняет проблемы с скоростью копирования по сети
| проблемы в сети предприятия, например кольца
ага. нет управляемого сетевого оборудования
| выделены LUN-ы — по 250 Гб для операционки, 20 Гб кворум и 6 Тб — хранилище виртуальных машин.
нарезая кучу мелких лунов вы убиваете производительность схд. надеюсь вы не отдали под маленькеи луны ссд накопители? %)
| Supermicro с двумя процессорами и 196 Гб [bla bla bla] На нем поднята роль Hyper-V и на него осуществляется экспорт виртуальных машин
в Windows Server 2012 R2 Hyper-V есть host-2-host миграция. зачем вы делаете экспорт, если можете настроить миграцию между хостами и сократить время возможного простоя до десятков секунд?
| Также некоторые машины можно бекапить «на горячую»,
да они все должны бэкапиться на горячую.realscorp
18.09.2015 07:04+1для файлохранилищ еще и включить дедупликацию на разделе
Вот, кстати, очень дельный совет. Рекомендую всем опробовать. У меня на нескольких терабайтах видео (нет, не того самого, а рекламных роликов и блоков) дедупликация сэкономила 47% объема раздела. И, т.к. это оффлайновая дедупликация, требования к ресурсам совершенно приемлемые. Опять же, можно настраивать расписание.
nelsh
18.09.2015 07:50+1Еще до появления на Хабре компании Veeam нашел на Codeplex утилиту «HV Backup» — не требует остановки виртуальных машин, сразу пакует в zip-архивы. На powershell написал небольшую обертку для вызова и отправки отчета на почту. Так с тех пор и пользуюсь.
Ссылки- hypervbackup.codeplex.com
- github.com/nelsh/HVbackupLaunch — в качестве примера для создания своего отчета
shmelfrol
21.09.2015 09:36немного поясню конфигурацию, описанную в статье.
во-первых, есть две сети физически разделенные — сеть предприятия и сеть control. кластер построен на основе шасси fujitsu bx900s2 с блейдами bx924s3-s4, в нем же (в шасси) стоят 2 свитча — 10G свитч и 1G свитч. 10g свитч подсоеинен к сети предприятия через 10 гигабитную циску, а 1g свитч воткнут в сеть control в 1гигабитный hp свитч. то есть не нужны никакие виланы. все разделено отдельным оборудованием — это дороже, это проще, и это надежней. таким образом у блейдов активны 2 сетевые карты, на основе которых сделано 2 hyper-v коммутатора, 10g используется только виртуальными машинами, 1g только хостами. также в сети control есть сервер бекапов hyper-v reserv — на него с помощью скрипта экспортируются виртуальные машины, и если виртуальная машина на кластере сдохла можно либо скопировать с hyper-v rezerv, либо восстановить на нем по месту если необходимо срочно.
во-вторых, ваши расчеты верны на счет скорости копирования, но насчет экспорта у меня выходит намного медленней, если я копирую по сети — то да почти весь гигабитный канал задействован, но ежели экспортирую виртуалку по сети то 40-60 гиг в час.Sergey-S-Kovalev
21.09.2015 10:42| то есть не нужны никакие виланы. все разделено отдельным оборудованием — это дороже, это проще, и это надежней.
ошибаетесь, очень сильно ошибаетесь
shmelfrol
22.09.2015 09:48по поводу экспорта по сети — провел эксперимент — подсоединил напрямую гигабитным патчкордом к хосту hyper-v сетевое хранилище — подключил iscsi-диск — копирование 112 Мбайт\сек, экспорт виртуальной машины 150 Мбит/сек… ведать дело все-таки в hyper-v. и наверное будет правильнее и быстрее экспортировать сначала на локальный диск, а потом копировать на сетевое хранилище.

YuriSerpinsky
SQL бесплатен для использования в составе продуктов MS System Center, т.е. для DPM не требуется покупать доп. лицензии да БД.