
Инструменты Business Intelligence (BI) за последние несколько лет проникли почти во все виды бизнеса, а изучению данных уделяется все больше внимания и выделяется больше ресурсов. Если говорить об IT-компаниях, то здесь, наверное, большинству понятно предназначение Business Intelligence и то, какую ценность для компании представляет анализ внутренних данных.

В Playrix на подготовку и анализ данных выделяется значительное количество ресурсов, мы стараемся использовать передовые технологии и серьёзно подходим к обучению сотрудников. Компания входит в топ-3 разработчиков мобильных игр в мире, поэтому мы стараемся держать соответствующий уровень в анализе данных и конкретно в Business Intelligence. Ежедневно в наши игры играют более 27 млн пользователей, и эта цифра может дать примерное представление об объемах данных, генерируемых мобильными устройствами каждый день. Кроме этого, данные забираются из десятков сервисов в различных форматах, после чего они агрегируются и загружаются в наши хранилища. В качестве Data Lake мы работаем с AWS S3, а Data Warehouse на AWS Redshift и PostgreSQL применяется ограниченно. Эти базы данных мы используем для аналитики. Redshift быстрее, но дороже, поэтому там мы храним самые востребованные данные. PostgreSQL дешевле и медленнее, там хранятся либо небольшие объемы данных, либо данные, скорость чтения которых некритична. Для предагрегированных данных используем Hadoop кластер и Impala.
Основным инструментом BI в Playrix является Tableau. Этот продукт достаточно хорошо известен в мире, имеет широкие возможности для анализа и визуализации данных, работы с различными источниками. Кроме того, для простых задач анализа не приходится писать код, поэтому можно обучить пользователей разных отделов самостоятельно анализировать свои бизнес-данные. Сам вендор инструмента Tableau Software также позиционирует свой продукт как инструмент для самостоятельного анализа данных, то есть для Self-Service.
Есть два основных подхода анализа данных в BI:
Первый подход традиционный, и в большинстве компаний работает такая фабрика производства отчетов в масштабах всего предприятия. Второй подход относительно новый, особенно для России. Хорош он тем, что данные исследуют сами бизнес-пользователи – они намного лучше знают свои локальные процессы. Это помогает разгружать разработчиков, избавлять их от необходимости каждый раз погружаться в особенности процессов команд и заниматься созданием самых простых отчетов. Это помогает решить, наверное, самую большую проблему — проблему преодоления пропасти между бизнес-пользователями и разработчиками. Ведь основная проблема подхода Reporting Factory как раз в том, что большая часть отчетов может остаться невостребованной только из-за того, что программисты-разработчики неверно понимают проблемы бизнес-пользователей и, соответственно, создают ненужные отчеты, которые либо переделываются потом, либо просто не используются.
В Playrix изначально разработкой отчетов в компании занимались программисты и аналитики, то есть специалисты, ежедневно работающие с данными. Но компания развивается очень стремительно, и по мере роста потребностей пользователей в отчетах разработчики отчетов перестали успевать в срок решать все задачи по их созданию и поддержке. Тогда и встал вопрос либо о расширении группы разработки BI, либо о передаче компетенций в другие отделы. Направление Self Service нам казалось перспективным, поэтому мы решили научить бизнес-пользователей самостоятельно создавать свои проекты и анализировать данные.
В Playrix подразделение Business Intelligence (BI Team) работает над задачами:
Мы занимаемся автоматизацией внутренних процессов и аналитики. Упрощенно нашу структуру можно представить при помощи схемы:

Мини-команды BI Team
Прямоугольниками здесь обозначены мини-команды. Слева — команды бэка, справа — команды фронта. Каждая из них обладает достаточными компетенциями для работы с задачами смежных команд и берут их на себя при перегруженности остальных команд.
В BI Team построен полный цикл разработки: от сбора требований до разворачивания на продуктовом окружении и последующей поддержки. В каждой мини-команде есть свой системный аналитик, разработчики и инженеры по тестированию. Они выполняют функцию Reporting Factory, подготавливая данные и отчеты для внутреннего использования.
Здесь важно отметить, что в большинстве проектов Tableau мы разрабатываем не простые отчеты, которые обычно показывают на демонстрациях, а инструменты с богатым функционалом, большим набором контролов, широкими возможностями и подключением внешних модулей. Эти инструменты постоянно перерабатываются, добавляются новые фичи.
Однако приходят и простые локальные задачи, которые может решить сам заказчик.
По нашему опыту работы и общения с другими компаниями основными проблемами при передаче data-компентенций бизнес-пользователям становятся:
Поддержка со стороны менеджмента у нас колоссальная, более того, менеджмент и предложил внедрять Self-Service. Желание у пользователей изучать работу с данными и Tableau тоже есть — это ребятам интересно, плюс анализ данных сейчас — очень существенный скилл, который большинству точно пригодится в будущем.
Внедрение новой идеологии сразу во всей компании обычно требует много ресурсов и нервов, поэтому мы начали с пилота. Пилотный проект Self-Service запустили в отделе User Acquisition полтора года назад и в процессе пилота копили ошибки и опыт, чтобы передать их другим отделам в будущем.
Направление User Acquisition работает над задачами увеличения аудитории наших продуктов, анализирует пути закупки трафика и выбирает, в какие направления привлечения пользователей стоит инвестировать средства компании. Раньше для этого направления готовились отчеты командой BI, либо ребята сами обрабатывали выгрузки из базы при помощи Excel или Google Sheets. Но в динамичной среде развития такой анализ влечет задержки, а число анализируемых данных лимитировано возможностями этих инструментов.
На старте пилота мы провели базовое обучение сотрудников работе с Tableau, сделали первый общий источник данных — таблицу в базе Redshift, в которой было более 500 млн строк и необходимые метрики. Следует отметить что Redshift — это столбчатая (или колоночная) база данных, и эта база отдает данные намного быстрее реляционных БД. Пилотная таблица в Redshift была действительно большой для людей, которые никогда больше чем с 1 млн строк одновременно не работали. Но это был вызов для ребят, чтобы научиться работать с данными таких объемов.
Мы понимали, что проблемы с производительностью начнутся по мере усложнения этих отчетов. Доступа к самой БД пользователям мы не давали, но был реализован источник на сервере Tableau, подключенный в режиме live к таблице в Redshift. У пользователей были лицензии Creator, и они могли подключаться к этому источнику либо с сервера Tableau, разрабатывая отчеты там, либо с Tableau Desktop. Надо сказать, что при разработке отчетов в вебе (у Tableau есть режим web edit) на сервере есть некоторые ограничения. На Tableau Desktop же таких ограничений нет, поэтому мы преимущественно разрабатываем на Desktop. Кроме того, если анализ нужен только одному бизнес-пользователю, не обязательно такие проекты публиковать на сервере — можно работать локально.
У нас в компании принято проводить вебинары и knowledgе sharing, в которых каждый сотрудник может рассказать о новых продуктах, фичах или возможностях инструментов, с которыми он работает или которые исследует. Все такие активности записываются и хранятся в нашей базе знаний. Этот процесс работает и в нашей команде, поэтому мы периодически тоже делимся знаниями или готовим фундаментальные обучающие вебинары.
Для всех пользователей, у которых есть лицензии Tableau, мы провели и записали получасовой вебинар по работе с сервером и дашбордами. В нем рассказали о проектах на сервере, работе с нативными контролами всех дашбордов — это верхняя панель (refresh, pause, …). Об этом обязательно надо рассказывать всем пользователям Tableau, чтобы они полноценно могли работать с нативными возможностями и не делали запросы на разработку фич, которые повторяют работу нативных контролов.
Основным препятствием для освоения какого-то инструмента (да и вообще чего-то нового) обычно является страх того, что не получится разобраться и работать с этим функционалом. Поэтому обучение, пожалуй, является самым важным этапом внедрения подхода self-service BI. От него будет сильно зависеть результат внедрения этой модели — приживется ли она в компании вообще и если да, то насколько быстро. На стартовых вебинарах как раз и надо снять барьеры использования Tableau.
Можно выделить две группы вебинаров, которые мы проводили для людей, не знакомых с работами баз данных:
В первом стартовом вебинаре мы рассматриваем все, что касается подключения к данным и преобразования данных в Tableau. Поскольку у людей обычно есть базовый уровень владения MS Excel, то здеcь важно объяснить, чем принципиально отличается работа в Excel от работы в Tableau. Это очень важный пункт, поскольку нужно переключить человека с логики таблиц с раскрашенными ячейками на логику нормализованных данных БД. На этом же вебинаре мы объясняем работу JOIN, UNION, PIVOT, также затрагиваем Blending. На первом вебинаре мы практически не затрагиваем визуализацию данных, его цель — объяснить, как работать и преобразовывать свои данные для Tableau. Важно, чтобы люди понимали, что данные первичны и большинство проблем возникает на уровне данных, а не на уровне визуализаций.
Второй вебинар по Self-Service имеет целью рассказать о логике построения визуализаций в Tableau. Tableau сильно отличается от других BI инструментов именно тем, что имеет свой движок и свою логику. В других системах, например, в PowerBI, есть набор готовых визуалов (можно скачать дополнительные модули в магазине), но эти модули не кастомизируются. В Tableau же у вас есть фактически чистый лист, на котором можно строить все что угодно. Конечно же, в Tableau есть ShowMe — меню базовых визуализаций, но все эти графики и диаграммы можно и нужно строить по логике работы Tableau. По нашему мнению, если хотите научить кого-то работать с Tableau, то не нужно использовать ShowMe для построения графиков — большая их часть людям не пригодится на старте, а нужно учить именно логике построения визуализаций. Для бизнес-дашбордов достаточно знать, как построить:
Этого набора визуализаций вполне достаточно для самостоятельного анализа данных.
Time Series: в бизнесе применяются очень часто, поскольку интересно сравнивать метрики в различные периоды времени. У нас в динамике результаты бизнеса смотрят, наверное, все сотрудники компании. Bar Charts используем для сравнения метрик по категориям. Scatter Plots (диаграмма разброса) используются редко, обычно для нахождения корреляций между метриками. Таблицы: то, от чего в бизнес-дашбордах полностью избавиться не удается, но по возможности стараемся минимизировать их число. В таблицах собираем числовые значения метрик по категориям.
То есть мы отправляем людей в свободное плавание после 1 часа обучения работы с данными и 1 часа обучения базовым вычислениям и визуализациям. Далее ребята сами работают со своими данными некоторое время, сталкиваются с проблемами, накапливают опыт, просто набивают руку. Этот этап в среднем занимает 2-4 недели. Естественно, в этот период есть возможность проконсультироваться с командой BI Team, если что-то не получается.
После первого этапа у коллег возникает необходимость совершенствования навыков и изучения новых возможностей. Для этого мы подготовили вебинары углубленного обучения. В них мы показываем, как работать с функциями LOD, табличными функциями, скриптами Python для TabPy. Мы работаем с живыми данными компании, это всегда интереснее фейковых или данных базового датасета Tableau — Superstore. В этих же вебинарах мы рассказываем об основных фичах и трюках Tableau, которые используются на продовых дашбордах, например:
Все эти трюки и фичи было принято использовать пару лет назад, поэтому в компании все к ним привыкли, и мы приняли их в стандартах разработки дашбордов. Скрипты Python мы используем для расчета некоторых внутренних метрик, все скрипты уже готовы, и для Self-Service надо понимать, как их вставлять в свои вычисления.
Таким образом, мы проводим только 4 часа вебинаров для старта Self-Service, и этого обычно достаточно, чтобы мотивированный человек начал работать с Tableau и самостоятельно анализировать данные. Кроме того, для дата-аналитиков у нас есть свои вебинары, они находятся в открытом доступе, можно знакомиться и с ними.
После проведения пилотного проекта мы посчитали его успешным и расширили количество пользователей Self-Service. Одной из больших задач была подготовка источников данных для разных команд. Ребята в Self-Service могут работать с 200+ млн строк, поэтому команда Data Engineering должна была придумать, как реализовать такие источники данных. Для большинства аналитических задач мы используем Redshift из-за скорости чтения данных и удобства работы. Но выдавать доступ к базе каждому человеку из Self-Service было рискованно с точки зрения информационной безопасности.
Первой идеей было создание источников с живым подключением к БД, то есть на Tableau Server было опубликовано несколько источников, которые смотрели либо в таблицы, либо в подготовленные view Redshift. В этом случае мы не хранили данные на сервере Tableau, а пользователи через эти источники сами ходили со своих Tableau Desktop (клиентов) в базу. Это работает, когда таблицы небольшие (единицы миллионов) или запросы Tableau не слишком сложные. По мере развития ребята начали усложнять в Tableau свои дашборды, использовать LODы, кастомные сортировки, скрипты Python. Естественно, это привело к замедлению работы некоторых Self-Service дашбордов. Поэтому через несколько месяцев после старта Self-Service мы пересмотрели подход к работе с источниками.
В новом подходе, который мы применяем до сих пор, были реализованы опубликованные на Tableau Server экстракты. Надо сказать, что у Self-Service постоянно возникают новые задачи, и от них поступают запросы на добавление новых полей в источник, естественно, источники данных постоянно модифицируются. Мы выработали следующую стратегию работы с источниками:
Немного про пункт 7. Нативно Tableau позволяет создавать экстракты по расписанию с минимальной разницей в 5 минут. Если вы точно знаете, что ваши таблицы в БД обновляются всегда в 4 часа утра, то вам можно просто поставить экстракт на 5 часов утра, чтобы ваши данные собрались. Это покрывает ряд задач. В нашем случае таблицы собираются по данным от различных провайдеров в том числе. Соответственно, если один провайдер либо наш внутренний сервис не успели обновить свою часть данных, то вся таблица считается невалидной. То есть нельзя просто установить расписание на фиксированное время. Поэтому мы используем API Tableau для запуска экстрактов по готовности таблиц. Сигналы запусков экстрактов формирует наш сервис ETL после того, как убедится в том, что все новые данные пришли и они валидны.
Такой подход позволяет иметь в экстракте свежие валидные данные с минимальной задержкой.
Мы сознательно не ограничиваем людей в экспериментах со своими данными и позволяем публиковать свои воркбуки, делиться ими. Внутри каждой команды, если человек посчитает, что его дашборд полезен другим, либо дашборд нужен этому сотруднику на сервере, он может его опубликовать. Команда BI не вмешивается во внутренние эксперименты команд, соответственно, всю логику работы дашбордов и вычисления они прорабатывают сами. Есть cлучаи, когда из Self-Service вырастает интересный проект, который потом полностью передается на поддержку команды BI и переходит на прод. Это как раз и есть тот самый эффект Self-Service, когда люди, хорошо разбираясь в своих бизнеc-задачах, начинают работать со своими данными и формируют новую стратегию своей работы. Исходя из этого мы сделали следующую схему проектов на сервере:
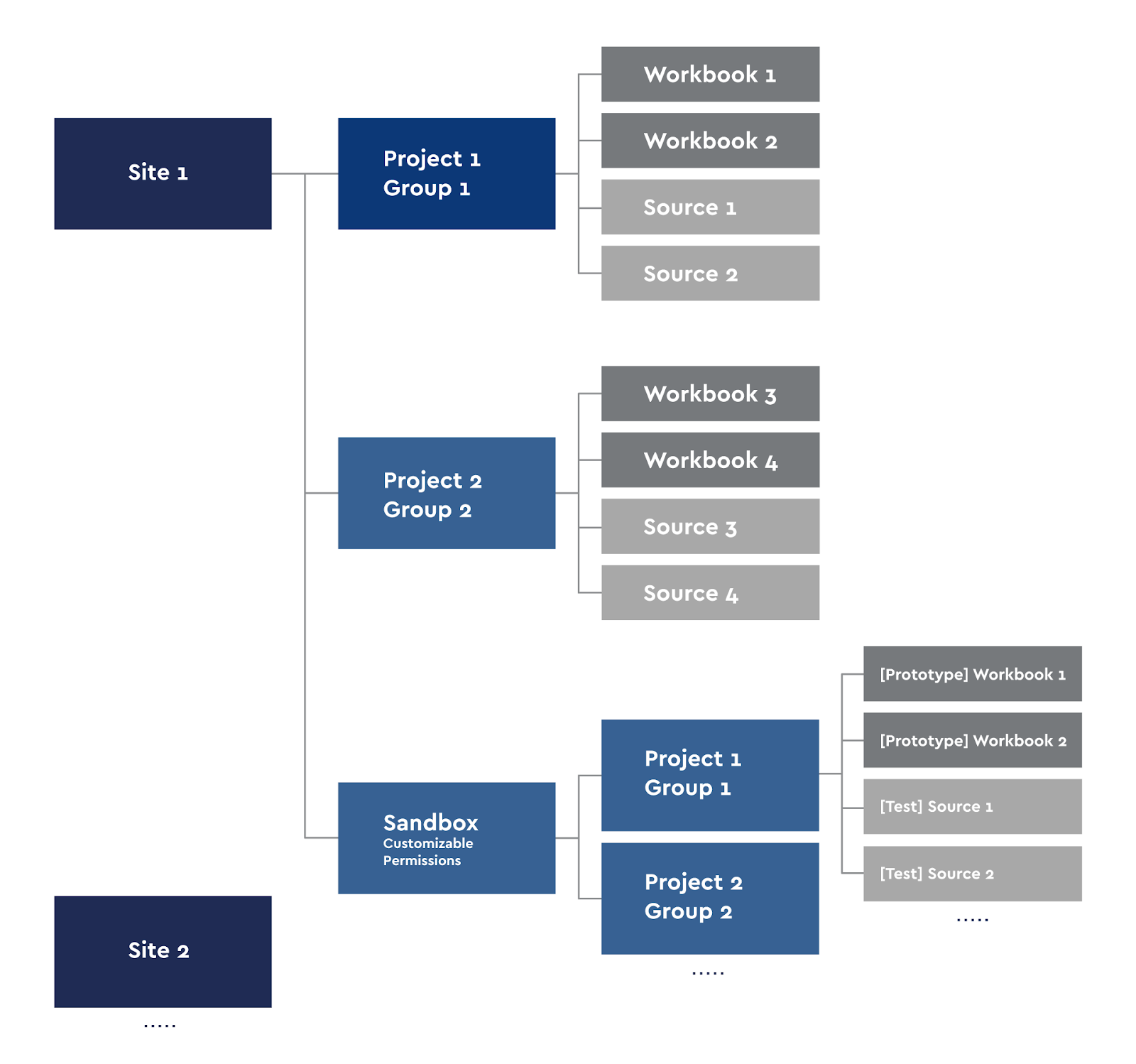
Схема проектов на Tableau Server
Каждый пользователь с лицензией Creator может публиковать свои воркбуки на сервер либо делать анализ локально. Для Self-Service мы сделали свою песочницу (Sandbox) со своими группами проектов.
Сайты в Tableau идеологически разделены так, чтобы пользователи одного сайта не видели контент другого, поэтому мы разделили сервер на сайты по направлениям, которые не пересекаются: например, игровая аналитика и финансы. Мы используем групповой доступ. В каждом сайте есть проекты, в которых права на их воркбуки и источники наследуются. То есть группa пользователей Group 1 видит только свои воркбуки и источники данных. Исключением из этого правила является сайт Sandbox, который имеет еще и подпроекты. Sandbox мы используем для прототипирования, разработки новых дашбордов, их тестирования и для нужд Self-Service. Все, у кого есть доступ на публикацию в своем проекте Sandbox, могут публиковать свои прототипы.
Поскольку мы перенесли нагрузку запросов Self-Service дашбордов с базы на Tableau Server, работаем с большими источниками данных и не ограничиваем людей по запросам к опубликованным источникам, то появилась другая проблема — мониторинг быстродействия таких дашбордов и мониторинг созданных источников.
Мониторинг быстродействия дашбордов и быстродействия серверов Tableau — задача, с которой сталкиваются средние и большие компании, поэтому про быстродействие дашбордов и его тюнинг написано достаточно много статей. Мы пионерами в этой области не стали, наш мониторинг — это несколько дашбордов на базе внутренней БД PostgreSQL Tableau Server. Этот мониторинг работает со всем контентом, но можно выделить дашборды Self-Service и посмотреть их быстродействие.
Проблемы оптимизации дашбордов команда BI Team решает периодически. Пользователи иногда приходят с вопросом «Почему медленно работает дашборд?», и нам нужно понимать, что такое «медленно» с точки зрения пользователя и какие числовые критерии могут характеризовать это «медленно». Чтобы не интервьюировать пользователя и не отнимать его рабочее время для подробного пересказа проблем, мы мониторим и анализируем http-запросы, находим самые медленные и выясняем причины. После чего оптимизируем дашборды, если это может привести к увеличению производительности. Понятно что при живом подключении к источникам будут задержки, связанные с формированием view в базе задержки получения данных. Есть еще сетевые задержки, которые исследуем с нашей командой поддержки всей IT инфраструктуры, но в этой статье на них мы останавливаться не будем.
Каждое взаимодействие пользователя с дашбордом в браузере инициирует свой http request, передаваемый на Tableau Server. Вся история таких запросов хранится во внутренней БД PostgreSQL Tableau Server, срок хранения по умолчанию — 7 дней. Этот срок можно увеличить изменениями настроек Tableau Server, но мы не хотели увеличивать таблицу http-запросов, поэтому просто собираем инкрементальный экстракт, в который укладываются только свежие данные каждый день, старые при этом не затираются. Это хороший способ с минимумом ресурсов держать в экстракте на сервере исторические данные, которых уже нет в базе.
Каждый http request имеет свой тип (action_type). Например, _bootstrap — первоначальная загрузка view, relative-date-filter — фильтр дат (слайдер). По названию можно определить большинство типов, поэтому понятно, что каждый пользователь делает с дашбордом: кто-то больше смотрит тултипы, кто-то меняет параметры, кто-то делает свои custom_view, а кто-то выгружает данные.
Ниже показан наш сервисный дашборд, который позволяет определять медленные дашборды, медленные типы запросов и пользователей, которым приходится ждать.
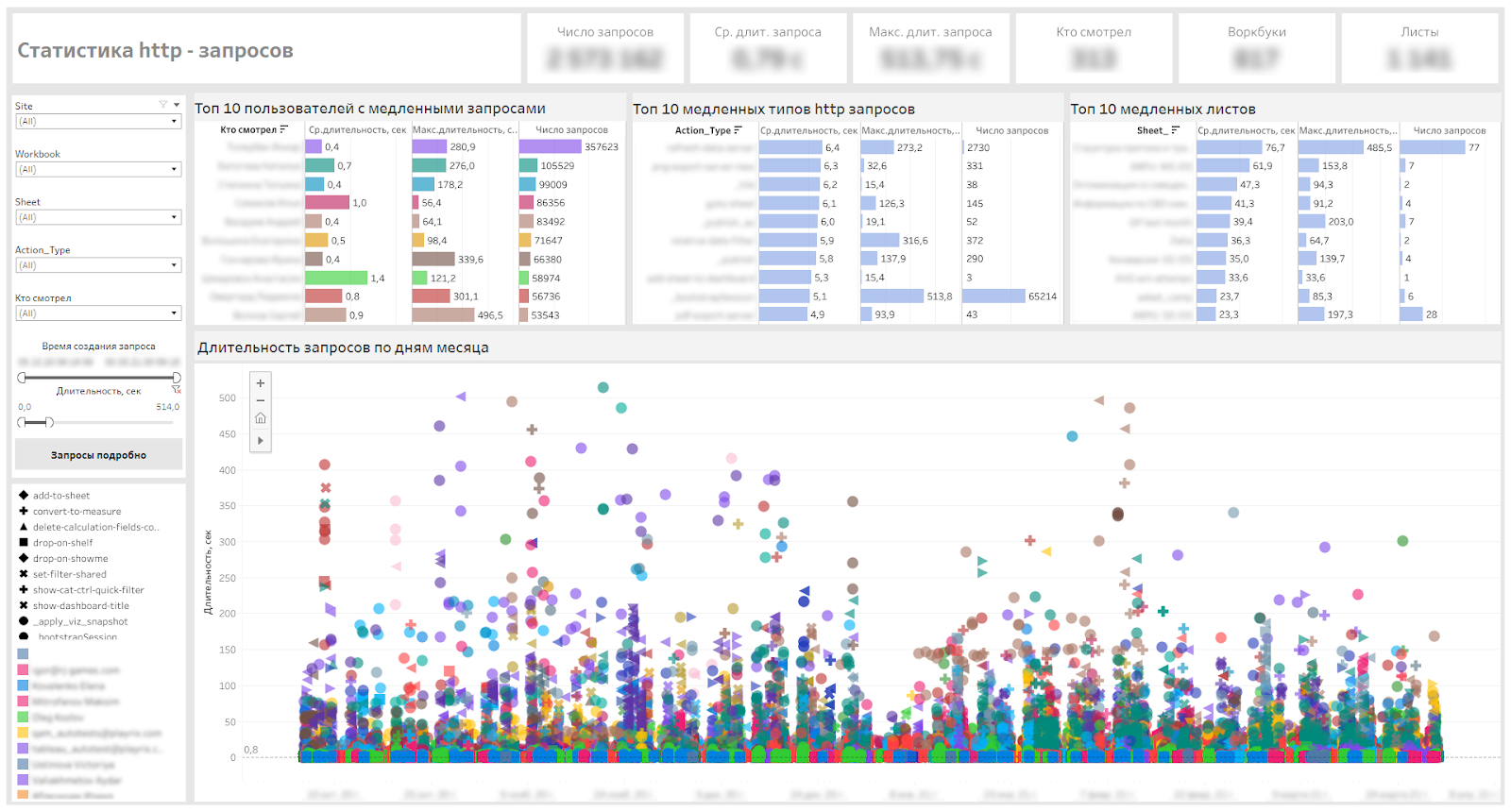
Дашборд мониторинга http-запросов
Когда открывается какой-то дашборд в браузере, на сервере Tableau запускается VizQL сессия, в рамках которой происходит отрисовка визуализаций, также выделяются ресурсы на поддержание сессии. Такие сессии отбрасываются через 30 минут простоя по умолчанию.
По мере увеличения пользователей на сервере и внедрения Self-Service мы получили несколько пожеланий для увеличения лимитов сессий VizQL. Проблема пользователей была в том, что они открывали дашборды, устанавливали фильтры, что-то смотрели и переходили к другим своим задачам вне Tableau Server, после какого-то времени они возвращались к открытым дашбордам, но они сбрасывались на дефолтный вид, и приходилось заново их настраивать. Наша задача была сделать работу пользователей более комфортной и убедиться, что нагрузка на сервер не возрастает критически.
Следующие два параметра на сервере можно менять, но при этом надо понимать, что нагрузка на сервер может вырасти.
Number of minutes of idle time after which a VizQL session is eligible to be discarded if the VizQL process starts to run out of memory.
vizqlserver.session.expiry.timeout 30 Number of minutes of idle time after which a VizQL session is discarded.
Поэтому мы решили сделать мониторинг VizQL сессий и отслеживать:
Кроме того, нам нужно было понимать, в какие дни и какие часы открывается самое большое количество сессий.
Получился такой дашборд:

Дашборд мониторинга VizQL сессий
C начала января этого года мы стали постепенно увеличивать лимиты и мониторить длительность сессий и нагрузку. Средняя длина сессии увеличилась с 13 до 35 минут — это видно на графиках средней длительности сессии. Конечные настройки такие:
После этого от пользователей мы получили положительный фидбэк, что работать стало намного приятнее — сессии перестали протухать.
Тепловые карты этого дашборда также позволяют нам планировать сервисные работы в часы минимальной востребованности сервера.
Изменение нагрузки на кластер — CPU и RAM — мы мониторим в Zabbix и AWS console. Значительных изменений нагрузки в процессе увеличения таймаутов мы не зафиксировали.
Если говорить о том, что может сильно нагнуть ваш Tableau сервер, то это может быть, например, неоптимизированный дашборд. Постройте, к примеру, в Tableau таблицу в десяток тысяч строк по категориям и id каких-нибудь событий, а в Measure используйте LOD вычисления на уровне id. С высокой вероятностью отображение таблицы на сервере не отработает, и вы получите вылет с Unexpected Error, поскольку все LODы в минимальной грануляции будут очень сильно потреблять память, и очень скоро процесс упрется в 100% потребления памяти.
Этот пример здесь приведен для того, чтобы было понятно, что один неоптимальный дашборд может съедать все ресурсы сервера, а даже 100 VizQL сессий оптимальных дашбордов не будут потреблять столько ресурсов.
Выше мы отмечали, что для Self-Service мы подготовили и опубликовали на сервере несколько источников данных. Все источники — экстракты данных. Опубликованные источники сохраняются на сервере, и к ним предоставляется доступ ребятам, которые работают с Tableau Desktop.
В Tableau есть возможность помечать источники как сертифицированные. Так делает команда BI, когда готовит источники данных для Self-Service. Это гарантирует, что сам источник был протестирован.
Опубликованные источники могут достигать 200 млн строк и 100 полей. Для Self-Service это очень большой объем, поскольку не так много компаний имеет источники таких объемов для самостоятельной аналитики.
Естественно, при сборе требований для формирования источника мы смотрим, как можно сократить объем данных в источнике, группируя категории, разбивая источники по проектам или ограничивая периоды времени. Но все равно, как правило, источники получаются от 10 млн строк.
Поскольку источники большие, занимают место на сервере, используют ресурсы сервера для обновления экстрактов, то все их нужно мониторить, смотреть, насколько часто они используются и как быстро растут в объеме., Для этого мы сделали мониторинг опубликованных источников данных. Он показывает пользователей, подключающихся к источникам, воркбуки, которые используют эти источники. Это позволяет находить неактуальные источники или проблемные источники, которые не могут собрать экстракт.
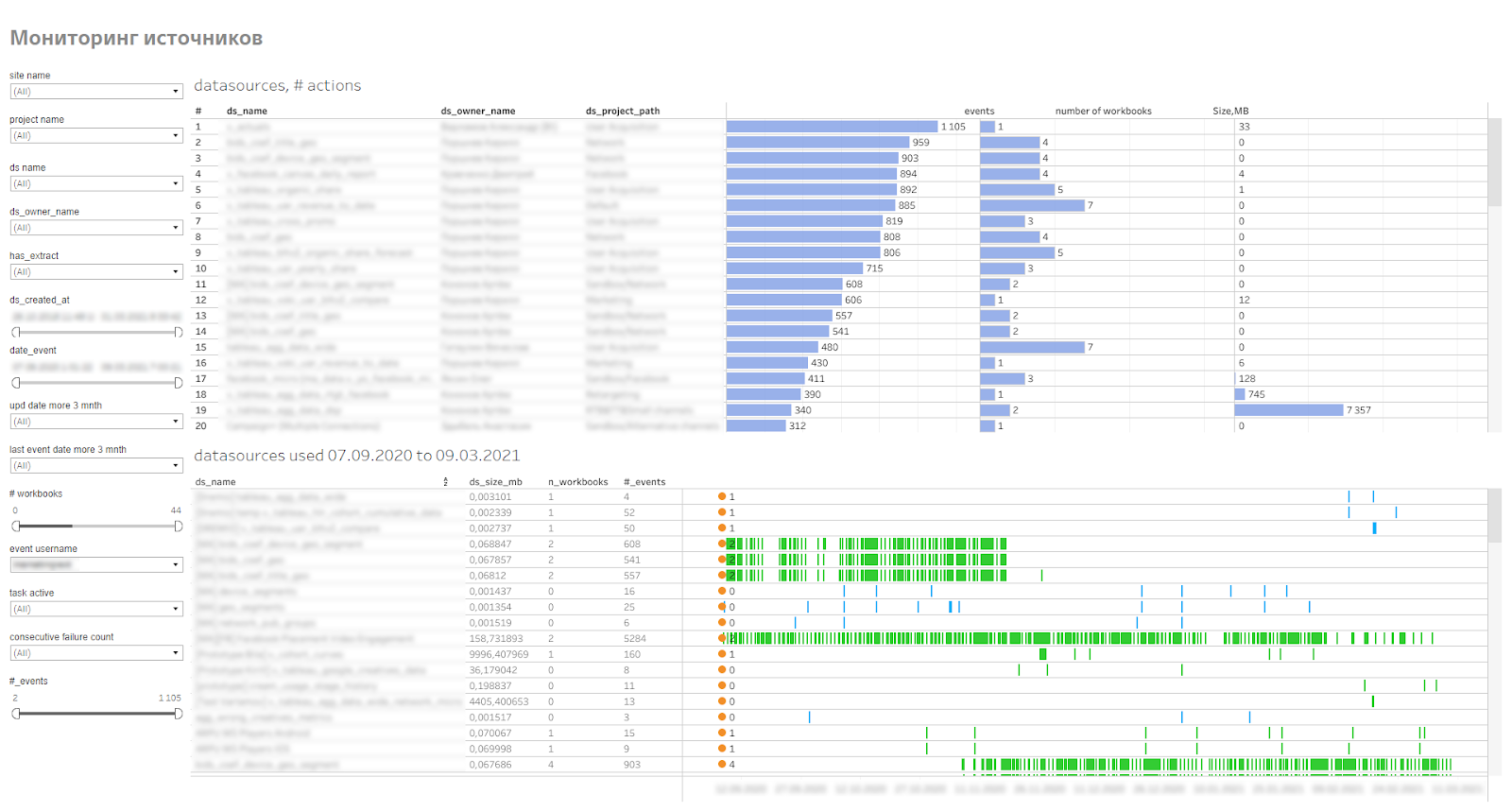
Дашборд мониторинга источников
Мы используем подход Self-Service 1,5 года. За это время 50 пользователей стали самостоятельно работать с данными. Это снизило нагрузку на BI Team и позволило ребятам не ждать, пока BI Team дойдет до конкретно их задачи по разработке дашборда. Примерно 5 месяцев назад мы стали подключать другие направления к самостоятельной аналитике.
В наших планах проведение обучения по data literacy и лучшим практикам визуализаций.
Важно понимать, что процесс Self-Service не может быть внедрен быстро во всей компании, это займет некоторое время. Если процесс перехода будет органичным, не шокируя сотрудников, то через пару лет внедрения можно получить принципиально другие процессы работы с данными в разных отделах и направлениях компании.
В Playrix на подготовку и анализ данных выделяется значительное количество ресурсов, мы стараемся использовать передовые технологии и серьёзно подходим к обучению сотрудников. Компания входит в топ-3 разработчиков мобильных игр в мире, поэтому мы стараемся держать соответствующий уровень в анализе данных и конкретно в Business Intelligence. Ежедневно в наши игры играют более 27 млн пользователей, и эта цифра может дать примерное представление об объемах данных, генерируемых мобильными устройствами каждый день. Кроме этого, данные забираются из десятков сервисов в различных форматах, после чего они агрегируются и загружаются в наши хранилища. В качестве Data Lake мы работаем с AWS S3, а Data Warehouse на AWS Redshift и PostgreSQL применяется ограниченно. Эти базы данных мы используем для аналитики. Redshift быстрее, но дороже, поэтому там мы храним самые востребованные данные. PostgreSQL дешевле и медленнее, там хранятся либо небольшие объемы данных, либо данные, скорость чтения которых некритична. Для предагрегированных данных используем Hadoop кластер и Impala.
Основным инструментом BI в Playrix является Tableau. Этот продукт достаточно хорошо известен в мире, имеет широкие возможности для анализа и визуализации данных, работы с различными источниками. Кроме того, для простых задач анализа не приходится писать код, поэтому можно обучить пользователей разных отделов самостоятельно анализировать свои бизнес-данные. Сам вендор инструмента Tableau Software также позиционирует свой продукт как инструмент для самостоятельного анализа данных, то есть для Self-Service.
Есть два основных подхода анализа данных в BI:
- Reporting Factory. В этом подходе есть отдел и/или люди, разрабатывающие отчеты для бизнес-пользователей.
- Self-Service. В этом подходе бизнес-пользователи делают отчеты и строят аналитику своих процессов самостоятельно.
Первый подход традиционный, и в большинстве компаний работает такая фабрика производства отчетов в масштабах всего предприятия. Второй подход относительно новый, особенно для России. Хорош он тем, что данные исследуют сами бизнес-пользователи – они намного лучше знают свои локальные процессы. Это помогает разгружать разработчиков, избавлять их от необходимости каждый раз погружаться в особенности процессов команд и заниматься созданием самых простых отчетов. Это помогает решить, наверное, самую большую проблему — проблему преодоления пропасти между бизнес-пользователями и разработчиками. Ведь основная проблема подхода Reporting Factory как раз в том, что большая часть отчетов может остаться невостребованной только из-за того, что программисты-разработчики неверно понимают проблемы бизнес-пользователей и, соответственно, создают ненужные отчеты, которые либо переделываются потом, либо просто не используются.
В Playrix изначально разработкой отчетов в компании занимались программисты и аналитики, то есть специалисты, ежедневно работающие с данными. Но компания развивается очень стремительно, и по мере роста потребностей пользователей в отчетах разработчики отчетов перестали успевать в срок решать все задачи по их созданию и поддержке. Тогда и встал вопрос либо о расширении группы разработки BI, либо о передаче компетенций в другие отделы. Направление Self Service нам казалось перспективным, поэтому мы решили научить бизнес-пользователей самостоятельно создавать свои проекты и анализировать данные.
В Playrix подразделение Business Intelligence (BI Team) работает над задачами:
- Сбора, подготовки и хранения данных.
- Разработки внутренних сервисов аналитики.
- Интеграции с внешними сервисами.
- Разработки web-интерфейсов.
- Разработки отчетности в Tableau.
Мы занимаемся автоматизацией внутренних процессов и аналитики. Упрощенно нашу структуру можно представить при помощи схемы:
Мини-команды BI Team
Прямоугольниками здесь обозначены мини-команды. Слева — команды бэка, справа — команды фронта. Каждая из них обладает достаточными компетенциями для работы с задачами смежных команд и берут их на себя при перегруженности остальных команд.
В BI Team построен полный цикл разработки: от сбора требований до разворачивания на продуктовом окружении и последующей поддержки. В каждой мини-команде есть свой системный аналитик, разработчики и инженеры по тестированию. Они выполняют функцию Reporting Factory, подготавливая данные и отчеты для внутреннего использования.
Здесь важно отметить, что в большинстве проектов Tableau мы разрабатываем не простые отчеты, которые обычно показывают на демонстрациях, а инструменты с богатым функционалом, большим набором контролов, широкими возможностями и подключением внешних модулей. Эти инструменты постоянно перерабатываются, добавляются новые фичи.
Однако приходят и простые локальные задачи, которые может решить сам заказчик.
Передача компетенций и запуск пилотного проекта
По нашему опыту работы и общения с другими компаниями основными проблемами при передаче data-компентенций бизнес-пользователям становятся:
- Нежелание самих пользователей изучать новые инструменты и работать с данными.
- Отсутствие поддержки со стороны менеджмента (инвестиции в обучение, лицензии и т.п.).
Поддержка со стороны менеджмента у нас колоссальная, более того, менеджмент и предложил внедрять Self-Service. Желание у пользователей изучать работу с данными и Tableau тоже есть — это ребятам интересно, плюс анализ данных сейчас — очень существенный скилл, который большинству точно пригодится в будущем.
Внедрение новой идеологии сразу во всей компании обычно требует много ресурсов и нервов, поэтому мы начали с пилота. Пилотный проект Self-Service запустили в отделе User Acquisition полтора года назад и в процессе пилота копили ошибки и опыт, чтобы передать их другим отделам в будущем.
Направление User Acquisition работает над задачами увеличения аудитории наших продуктов, анализирует пути закупки трафика и выбирает, в какие направления привлечения пользователей стоит инвестировать средства компании. Раньше для этого направления готовились отчеты командой BI, либо ребята сами обрабатывали выгрузки из базы при помощи Excel или Google Sheets. Но в динамичной среде развития такой анализ влечет задержки, а число анализируемых данных лимитировано возможностями этих инструментов.
На старте пилота мы провели базовое обучение сотрудников работе с Tableau, сделали первый общий источник данных — таблицу в базе Redshift, в которой было более 500 млн строк и необходимые метрики. Следует отметить что Redshift — это столбчатая (или колоночная) база данных, и эта база отдает данные намного быстрее реляционных БД. Пилотная таблица в Redshift была действительно большой для людей, которые никогда больше чем с 1 млн строк одновременно не работали. Но это был вызов для ребят, чтобы научиться работать с данными таких объемов.
Мы понимали, что проблемы с производительностью начнутся по мере усложнения этих отчетов. Доступа к самой БД пользователям мы не давали, но был реализован источник на сервере Tableau, подключенный в режиме live к таблице в Redshift. У пользователей были лицензии Creator, и они могли подключаться к этому источнику либо с сервера Tableau, разрабатывая отчеты там, либо с Tableau Desktop. Надо сказать, что при разработке отчетов в вебе (у Tableau есть режим web edit) на сервере есть некоторые ограничения. На Tableau Desktop же таких ограничений нет, поэтому мы преимущественно разрабатываем на Desktop. Кроме того, если анализ нужен только одному бизнес-пользователю, не обязательно такие проекты публиковать на сервере — можно работать локально.
Обучение
У нас в компании принято проводить вебинары и knowledgе sharing, в которых каждый сотрудник может рассказать о новых продуктах, фичах или возможностях инструментов, с которыми он работает или которые исследует. Все такие активности записываются и хранятся в нашей базе знаний. Этот процесс работает и в нашей команде, поэтому мы периодически тоже делимся знаниями или готовим фундаментальные обучающие вебинары.
Для всех пользователей, у которых есть лицензии Tableau, мы провели и записали получасовой вебинар по работе с сервером и дашбордами. В нем рассказали о проектах на сервере, работе с нативными контролами всех дашбордов — это верхняя панель (refresh, pause, …). Об этом обязательно надо рассказывать всем пользователям Tableau, чтобы они полноценно могли работать с нативными возможностями и не делали запросы на разработку фич, которые повторяют работу нативных контролов.
Основным препятствием для освоения какого-то инструмента (да и вообще чего-то нового) обычно является страх того, что не получится разобраться и работать с этим функционалом. Поэтому обучение, пожалуй, является самым важным этапом внедрения подхода self-service BI. От него будет сильно зависеть результат внедрения этой модели — приживется ли она в компании вообще и если да, то насколько быстро. На стартовых вебинарах как раз и надо снять барьеры использования Tableau.
Можно выделить две группы вебинаров, которые мы проводили для людей, не знакомых с работами баз данных:
- Стартовый набор знаний новичка:
- Подключение к данным, типы соединений, типы данных, базовые преобразования данных, нормализация данных (1 час).
- Базовые визуализации, агрегация данных, базовые вычисления (1 час).
- Сложные вычисления и базовые трюки/элементы, принятые в компании (2 часа).
В первом стартовом вебинаре мы рассматриваем все, что касается подключения к данным и преобразования данных в Tableau. Поскольку у людей обычно есть базовый уровень владения MS Excel, то здеcь важно объяснить, чем принципиально отличается работа в Excel от работы в Tableau. Это очень важный пункт, поскольку нужно переключить человека с логики таблиц с раскрашенными ячейками на логику нормализованных данных БД. На этом же вебинаре мы объясняем работу JOIN, UNION, PIVOT, также затрагиваем Blending. На первом вебинаре мы практически не затрагиваем визуализацию данных, его цель — объяснить, как работать и преобразовывать свои данные для Tableau. Важно, чтобы люди понимали, что данные первичны и большинство проблем возникает на уровне данных, а не на уровне визуализаций.
Второй вебинар по Self-Service имеет целью рассказать о логике построения визуализаций в Tableau. Tableau сильно отличается от других BI инструментов именно тем, что имеет свой движок и свою логику. В других системах, например, в PowerBI, есть набор готовых визуалов (можно скачать дополнительные модули в магазине), но эти модули не кастомизируются. В Tableau же у вас есть фактически чистый лист, на котором можно строить все что угодно. Конечно же, в Tableau есть ShowMe — меню базовых визуализаций, но все эти графики и диаграммы можно и нужно строить по логике работы Tableau. По нашему мнению, если хотите научить кого-то работать с Tableau, то не нужно использовать ShowMe для построения графиков — большая их часть людям не пригодится на старте, а нужно учить именно логике построения визуализаций. Для бизнес-дашбордов достаточно знать, как построить:
- Time Series. Line/Area Charts (линейные графики),
- Bar Charts (столбчатые диаграммы),
- Scatter Plots (диаграммы разброса),
- Tables (таблицы).
Этого набора визуализаций вполне достаточно для самостоятельного анализа данных.
Time Series: в бизнесе применяются очень часто, поскольку интересно сравнивать метрики в различные периоды времени. У нас в динамике результаты бизнеса смотрят, наверное, все сотрудники компании. Bar Charts используем для сравнения метрик по категориям. Scatter Plots (диаграмма разброса) используются редко, обычно для нахождения корреляций между метриками. Таблицы: то, от чего в бизнес-дашбордах полностью избавиться не удается, но по возможности стараемся минимизировать их число. В таблицах собираем числовые значения метрик по категориям.
То есть мы отправляем людей в свободное плавание после 1 часа обучения работы с данными и 1 часа обучения базовым вычислениям и визуализациям. Далее ребята сами работают со своими данными некоторое время, сталкиваются с проблемами, накапливают опыт, просто набивают руку. Этот этап в среднем занимает 2-4 недели. Естественно, в этот период есть возможность проконсультироваться с командой BI Team, если что-то не получается.
После первого этапа у коллег возникает необходимость совершенствования навыков и изучения новых возможностей. Для этого мы подготовили вебинары углубленного обучения. В них мы показываем, как работать с функциями LOD, табличными функциями, скриптами Python для TabPy. Мы работаем с живыми данными компании, это всегда интереснее фейковых или данных базового датасета Tableau — Superstore. В этих же вебинарах мы рассказываем об основных фичах и трюках Tableau, которые используются на продовых дашбордах, например:
- Sheet Swapping (замена листов),
- Агрегация графиков при помощи параметров,
- Форматы дат и метрик,
- Отбрасывание неполных периодов при недельных/месячных агрегациях.
Все эти трюки и фичи было принято использовать пару лет назад, поэтому в компании все к ним привыкли, и мы приняли их в стандартах разработки дашбордов. Скрипты Python мы используем для расчета некоторых внутренних метрик, все скрипты уже готовы, и для Self-Service надо понимать, как их вставлять в свои вычисления.
Таким образом, мы проводим только 4 часа вебинаров для старта Self-Service, и этого обычно достаточно, чтобы мотивированный человек начал работать с Tableau и самостоятельно анализировать данные. Кроме того, для дата-аналитиков у нас есть свои вебинары, они находятся в открытом доступе, можно знакомиться и с ними.
Разработка источников данных для Self-Service
После проведения пилотного проекта мы посчитали его успешным и расширили количество пользователей Self-Service. Одной из больших задач была подготовка источников данных для разных команд. Ребята в Self-Service могут работать с 200+ млн строк, поэтому команда Data Engineering должна была придумать, как реализовать такие источники данных. Для большинства аналитических задач мы используем Redshift из-за скорости чтения данных и удобства работы. Но выдавать доступ к базе каждому человеку из Self-Service было рискованно с точки зрения информационной безопасности.
Первой идеей было создание источников с живым подключением к БД, то есть на Tableau Server было опубликовано несколько источников, которые смотрели либо в таблицы, либо в подготовленные view Redshift. В этом случае мы не хранили данные на сервере Tableau, а пользователи через эти источники сами ходили со своих Tableau Desktop (клиентов) в базу. Это работает, когда таблицы небольшие (единицы миллионов) или запросы Tableau не слишком сложные. По мере развития ребята начали усложнять в Tableau свои дашборды, использовать LODы, кастомные сортировки, скрипты Python. Естественно, это привело к замедлению работы некоторых Self-Service дашбордов. Поэтому через несколько месяцев после старта Self-Service мы пересмотрели подход к работе с источниками.
В новом подходе, который мы применяем до сих пор, были реализованы опубликованные на Tableau Server экстракты. Надо сказать, что у Self-Service постоянно возникают новые задачи, и от них поступают запросы на добавление новых полей в источник, естественно, источники данных постоянно модифицируются. Мы выработали следующую стратегию работы с источниками:
- По ТЗ на источник со стороны Self-Service собираются данные в таблицах баз данных.
- Создается нематериализованное представление (view) в тестовой схеме БД Redshift.
- Представление тестируется на корректность данных командой QA.
- В случае положительного результата проверки представление поднимается на продовой схеме Redshift.
- Команда Data Engineering берет view на поддержку — подключаются скрипты анализа валидности данных, сигналы алармирования ETL, выдаются права на чтение команде Self-Service.
- На Tableau Server публикуется источник (экстракт), подключенный к этому представлению.
- Заводятся сигналы ETL на запуск экстракта.
- Источник описывается в базе знаний.
- Описание источника, вся информация для подключения и работы передается команде Self-Service.
Немного про пункт 7. Нативно Tableau позволяет создавать экстракты по расписанию с минимальной разницей в 5 минут. Если вы точно знаете, что ваши таблицы в БД обновляются всегда в 4 часа утра, то вам можно просто поставить экстракт на 5 часов утра, чтобы ваши данные собрались. Это покрывает ряд задач. В нашем случае таблицы собираются по данным от различных провайдеров в том числе. Соответственно, если один провайдер либо наш внутренний сервис не успели обновить свою часть данных, то вся таблица считается невалидной. То есть нельзя просто установить расписание на фиксированное время. Поэтому мы используем API Tableau для запуска экстрактов по готовности таблиц. Сигналы запусков экстрактов формирует наш сервис ETL после того, как убедится в том, что все новые данные пришли и они валидны.
Такой подход позволяет иметь в экстракте свежие валидные данные с минимальной задержкой.
Публикация дашбордов Self-Service на Tableau Server
Мы сознательно не ограничиваем людей в экспериментах со своими данными и позволяем публиковать свои воркбуки, делиться ими. Внутри каждой команды, если человек посчитает, что его дашборд полезен другим, либо дашборд нужен этому сотруднику на сервере, он может его опубликовать. Команда BI не вмешивается во внутренние эксперименты команд, соответственно, всю логику работы дашбордов и вычисления они прорабатывают сами. Есть cлучаи, когда из Self-Service вырастает интересный проект, который потом полностью передается на поддержку команды BI и переходит на прод. Это как раз и есть тот самый эффект Self-Service, когда люди, хорошо разбираясь в своих бизнеc-задачах, начинают работать со своими данными и формируют новую стратегию своей работы. Исходя из этого мы сделали следующую схему проектов на сервере:
Схема проектов на Tableau Server
Каждый пользователь с лицензией Creator может публиковать свои воркбуки на сервер либо делать анализ локально. Для Self-Service мы сделали свою песочницу (Sandbox) со своими группами проектов.
Сайты в Tableau идеологически разделены так, чтобы пользователи одного сайта не видели контент другого, поэтому мы разделили сервер на сайты по направлениям, которые не пересекаются: например, игровая аналитика и финансы. Мы используем групповой доступ. В каждом сайте есть проекты, в которых права на их воркбуки и источники наследуются. То есть группa пользователей Group 1 видит только свои воркбуки и источники данных. Исключением из этого правила является сайт Sandbox, который имеет еще и подпроекты. Sandbox мы используем для прототипирования, разработки новых дашбордов, их тестирования и для нужд Self-Service. Все, у кого есть доступ на публикацию в своем проекте Sandbox, могут публиковать свои прототипы.
Мониторинг источников и дашбордов на Tableau Server
Поскольку мы перенесли нагрузку запросов Self-Service дашбордов с базы на Tableau Server, работаем с большими источниками данных и не ограничиваем людей по запросам к опубликованным источникам, то появилась другая проблема — мониторинг быстродействия таких дашбордов и мониторинг созданных источников.
Мониторинг быстродействия дашбордов и быстродействия серверов Tableau — задача, с которой сталкиваются средние и большие компании, поэтому про быстродействие дашбордов и его тюнинг написано достаточно много статей. Мы пионерами в этой области не стали, наш мониторинг — это несколько дашбордов на базе внутренней БД PostgreSQL Tableau Server. Этот мониторинг работает со всем контентом, но можно выделить дашборды Self-Service и посмотреть их быстродействие.
Проблемы оптимизации дашбордов команда BI Team решает периодически. Пользователи иногда приходят с вопросом «Почему медленно работает дашборд?», и нам нужно понимать, что такое «медленно» с точки зрения пользователя и какие числовые критерии могут характеризовать это «медленно». Чтобы не интервьюировать пользователя и не отнимать его рабочее время для подробного пересказа проблем, мы мониторим и анализируем http-запросы, находим самые медленные и выясняем причины. После чего оптимизируем дашборды, если это может привести к увеличению производительности. Понятно что при живом подключении к источникам будут задержки, связанные с формированием view в базе задержки получения данных. Есть еще сетевые задержки, которые исследуем с нашей командой поддержки всей IT инфраструктуры, но в этой статье на них мы останавливаться не будем.
Немного о http requests
Каждое взаимодействие пользователя с дашбордом в браузере инициирует свой http request, передаваемый на Tableau Server. Вся история таких запросов хранится во внутренней БД PostgreSQL Tableau Server, срок хранения по умолчанию — 7 дней. Этот срок можно увеличить изменениями настроек Tableau Server, но мы не хотели увеличивать таблицу http-запросов, поэтому просто собираем инкрементальный экстракт, в который укладываются только свежие данные каждый день, старые при этом не затираются. Это хороший способ с минимумом ресурсов держать в экстракте на сервере исторические данные, которых уже нет в базе.
Каждый http request имеет свой тип (action_type). Например, _bootstrap — первоначальная загрузка view, relative-date-filter — фильтр дат (слайдер). По названию можно определить большинство типов, поэтому понятно, что каждый пользователь делает с дашбордом: кто-то больше смотрит тултипы, кто-то меняет параметры, кто-то делает свои custom_view, а кто-то выгружает данные.
Ниже показан наш сервисный дашборд, который позволяет определять медленные дашборды, медленные типы запросов и пользователей, которым приходится ждать.
Дашборд мониторинга http-запросов
Мониторинг VizQL-сессий
Когда открывается какой-то дашборд в браузере, на сервере Tableau запускается VizQL сессия, в рамках которой происходит отрисовка визуализаций, также выделяются ресурсы на поддержание сессии. Такие сессии отбрасываются через 30 минут простоя по умолчанию.
По мере увеличения пользователей на сервере и внедрения Self-Service мы получили несколько пожеланий для увеличения лимитов сессий VizQL. Проблема пользователей была в том, что они открывали дашборды, устанавливали фильтры, что-то смотрели и переходили к другим своим задачам вне Tableau Server, после какого-то времени они возвращались к открытым дашбордам, но они сбрасывались на дефолтный вид, и приходилось заново их настраивать. Наша задача была сделать работу пользователей более комфортной и убедиться, что нагрузка на сервер не возрастает критически.
Следующие два параметра на сервере можно менять, но при этом надо понимать, что нагрузка на сервер может вырасти.
vizqlserver.session.expiry.minimum 5Number of minutes of idle time after which a VizQL session is eligible to be discarded if the VizQL process starts to run out of memory.
vizqlserver.session.expiry.timeout 30 Number of minutes of idle time after which a VizQL session is discarded.
Поэтому мы решили сделать мониторинг VizQL сессий и отслеживать:
- Количество сессий,
- Количество сессий на пользователя,
- Среднюю длительность сессий,
- Максимальную длительность сессий.
Кроме того, нам нужно было понимать, в какие дни и какие часы открывается самое большое количество сессий.
Получился такой дашборд:
Дашборд мониторинга VizQL сессий
C начала января этого года мы стали постепенно увеличивать лимиты и мониторить длительность сессий и нагрузку. Средняя длина сессии увеличилась с 13 до 35 минут — это видно на графиках средней длительности сессии. Конечные настройки такие:
vizqlserver.session.expiry.minimum 120
vizqlserver.session.expiry.timeout 240
После этого от пользователей мы получили положительный фидбэк, что работать стало намного приятнее — сессии перестали протухать.
Тепловые карты этого дашборда также позволяют нам планировать сервисные работы в часы минимальной востребованности сервера.
Изменение нагрузки на кластер — CPU и RAM — мы мониторим в Zabbix и AWS console. Значительных изменений нагрузки в процессе увеличения таймаутов мы не зафиксировали.
Если говорить о том, что может сильно нагнуть ваш Tableau сервер, то это может быть, например, неоптимизированный дашборд. Постройте, к примеру, в Tableau таблицу в десяток тысяч строк по категориям и id каких-нибудь событий, а в Measure используйте LOD вычисления на уровне id. С высокой вероятностью отображение таблицы на сервере не отработает, и вы получите вылет с Unexpected Error, поскольку все LODы в минимальной грануляции будут очень сильно потреблять память, и очень скоро процесс упрется в 100% потребления памяти.
Этот пример здесь приведен для того, чтобы было понятно, что один неоптимальный дашборд может съедать все ресурсы сервера, а даже 100 VizQL сессий оптимальных дашбордов не будут потреблять столько ресурсов.
Мониторинг источников данных сервера
Выше мы отмечали, что для Self-Service мы подготовили и опубликовали на сервере несколько источников данных. Все источники — экстракты данных. Опубликованные источники сохраняются на сервере, и к ним предоставляется доступ ребятам, которые работают с Tableau Desktop.
В Tableau есть возможность помечать источники как сертифицированные. Так делает команда BI, когда готовит источники данных для Self-Service. Это гарантирует, что сам источник был протестирован.
Опубликованные источники могут достигать 200 млн строк и 100 полей. Для Self-Service это очень большой объем, поскольку не так много компаний имеет источники таких объемов для самостоятельной аналитики.
Естественно, при сборе требований для формирования источника мы смотрим, как можно сократить объем данных в источнике, группируя категории, разбивая источники по проектам или ограничивая периоды времени. Но все равно, как правило, источники получаются от 10 млн строк.
Поскольку источники большие, занимают место на сервере, используют ресурсы сервера для обновления экстрактов, то все их нужно мониторить, смотреть, насколько часто они используются и как быстро растут в объеме., Для этого мы сделали мониторинг опубликованных источников данных. Он показывает пользователей, подключающихся к источникам, воркбуки, которые используют эти источники. Это позволяет находить неактуальные источники или проблемные источники, которые не могут собрать экстракт.
Дашборд мониторинга источников
Итог
Мы используем подход Self-Service 1,5 года. За это время 50 пользователей стали самостоятельно работать с данными. Это снизило нагрузку на BI Team и позволило ребятам не ждать, пока BI Team дойдет до конкретно их задачи по разработке дашборда. Примерно 5 месяцев назад мы стали подключать другие направления к самостоятельной аналитике.
В наших планах проведение обучения по data literacy и лучшим практикам визуализаций.
Важно понимать, что процесс Self-Service не может быть внедрен быстро во всей компании, это займет некоторое время. Если процесс перехода будет органичным, не шокируя сотрудников, то через пару лет внедрения можно получить принципиально другие процессы работы с данными в разных отделах и направлениях компании.

mmpmaxim
Заманчиво