
Привет, Хабр!
Про такие ошибки обычно говорить не принято, потому что во всех интеграторах работают только безгрешные небесноликие люди. У нас, как известно, на уровне ДНК отсутствует возможность ошибаться или быть неправыми.
Но я рискну. Надеюсь, мой опыт кому-то будет полезен. Есть у нас один крупный заказчик, онлайн-розница, которому мы полностью поддерживаем фабрику Cisco ACI. Своего админа, компетентного по этой системе, у компании нет. Сетевая фабрика — это группа коммутаторов, которая имеет единый центр управления. Плюс ещё куча полезных фич, которыми очень гордится производитель, но в итоге, чтобы всё уронить, нужен один админ, а не десятки. И один центр управления, а не десятки консолей.
Начинается история так: заказчик хочет перенести на эту группу коммутаторов ядро всей сети. Такое решение обусловлено тем, что архитектура ACI, в которую «собрана» эта группа коммутаторов очень отказоустойчивая. Хотя это не типично и в целом фабрика в любом ЦОД не используется как транзитная сеть для других сетей и служит только для подключения конечной нагрузки (stub network). Но такой подход вполне имеет место быть, поэтому заказчик хочет — мы делаем.
Дальше произошло банальное — я перепутал две кнопки: удаления политики и удаления конфига фрагмента сети:
Ну а дальше по классике — нужно было собрать заново часть развалившейся сети.
Запрос заказчика звучал так: нужно было построить отдельные порт-группы под перенос оборудования непосредственно на эту фабрику.
То есть они хотели перевести кластер серверов. Нужно было настроить новую виртуальную порт-группу под серверное окружение. По сути дела, это рутинная задача, простоя сервиса на такой задаче обычно нет. По сути своей порт-группа в терминологии APIC — это VPC, который собирается из портов находящихся физически на разных коммутаторах.
Проблема в том, что на фабрике настройки этих порт-групп привязаны к отдельной сущности (которая возникает вследствие того, что фабрика управляется с контроллера ). Этот объект называется port policy. То есть к группе портов, которые мы добавляем, нужно ещё сверху применить общую политику как сущность, которая будет управлять этими портами.
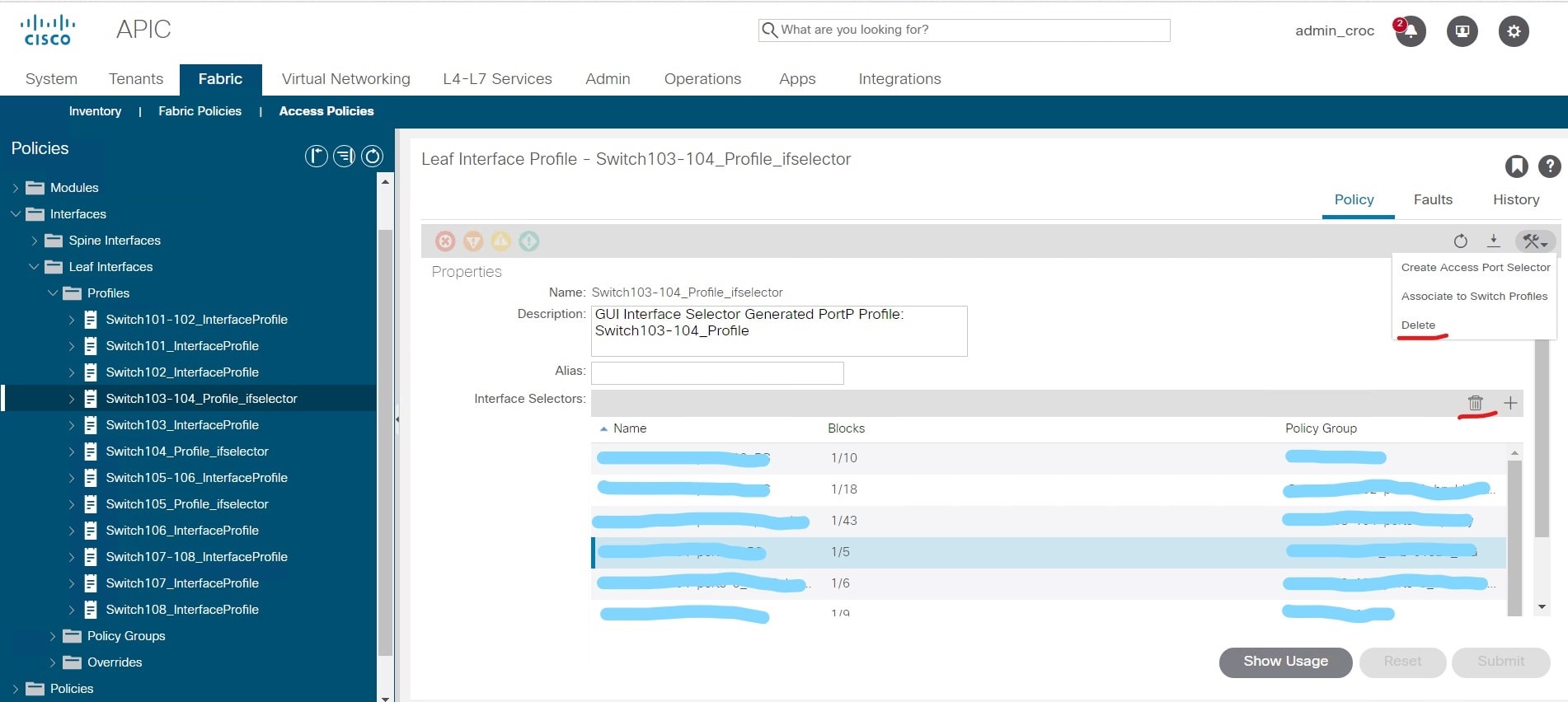
То есть нужно было сделать анализ, какие EPG используются на портах 43 и 44 на нодах 101 и 102 для того, чтобы собрать аналогичную конфигурацию на нодах 103-104. После анализа необходимых изменений я начал настраивать ноды 103-104. Для настройки нового VPC в существующей политике интерфейсов для нод 103 и 104 нужно было создать политику, в которую будут заведены интерфейсы 43 и 44.
И там есть в GUI один нюанс. Я создал эту политику и понял, что в процессе конфигурирования допустил незначительную ошибку, — назвал её не так, как принято у заказчика. Это не критично — потому что политика новая и ни на что не влияет. И мне эту политику нужно было удалить, поскольку изменения в неё уже внести нельзя (название не меняется) — можно только удалить и заново политику создать.
Проблема в том, что в GUI есть иконки удаления, которые относятся к политикам интерфейса, а есть иконки, которые относятся к политикам коммутатора. Визуально они почти идентичны. И я вместо того, чтобы удалить политику, которую я создал, удалил всю конфигурацию для интерфейсов на коммутаторах 103-104:
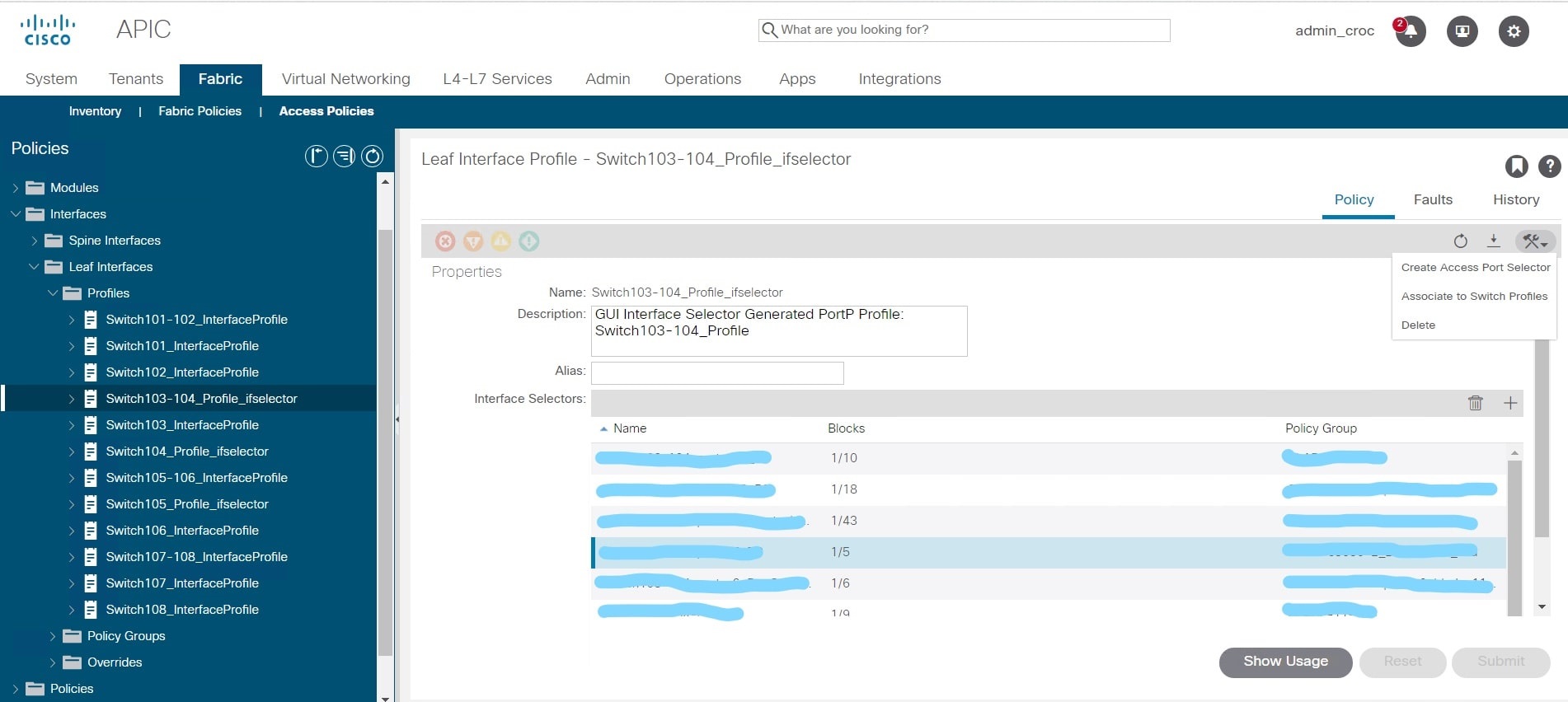
Вместо удаления одной группы фактически удалил все VPC из настроек ноды, использовал delete вместо trashbin.
В этих каналах были VLAN, чувствительные для бизнеса. По сути дела, после удаления конфига я отключил часть сетки. Причём это было не сразу заметно, потому что фабрика управляется не через ядро, а у неё отдельный менеджмент-интерфейс. Меня не выкинуло сразу, не произошло какой-то ошибки на фабрике, поскольку действие было предпринято администратором. И интерфейс считает — ну если вы сказали удалить, значит так надо. Никакой индикации ошибок не было. ПО решило, что идёт какая-то реконфигурация. Если админ удаляет профиль leaf, то для фабрики он перестаёт существовать и она не пишет ошибки о том, что он не работает. Он не работает — потому что его целенаправленно удалили. Для ПО он и не должен работать.
В общем, ПО решило, что я Чак Норрис и точно знаю, что делаю. Всё под контролем. Админ не может ошибаться, и даже когда он стреляет себе в ногу — это часть хитрого плана.
Но примерно через десять минут меня выкинуло из VPN, что я поначалу не связал с конфигурацией APIC. Но это как минимум подозрительно, и я связался с заказчиком, уточнить, что происходит. Причём следующие несколько минут я думал, что проблема в технических работах, внезапном экскаваторе или сбое питания, но никак не конфиге фабрики.
У заказчика сеть построена сложно. Мы по своим доступам видим только часть окружения. Восстанавливая события, всё похоже на то, что началась ребалансировка трафика, после чего через несколько секунд динамическая маршрутизация оставшихся систем просто не вывезла.
Тот VPN, на котором я сидел, — это был админский VPN. Обычные сотрудники сидели с другого, у них всё продолжало работать.
В общем, ещё пара минут переговоров ушла на то, чтобы понять, что проблема всё же в моём конфиге. Первое действие в бою в такой ситуации — сделать роллбек на прошлые конфиги, а только потом уже читать логи, потому что это прод.
На восстановление фабрики — с учётом всех звонков и сбора всех причастных — ушло 30 минут.
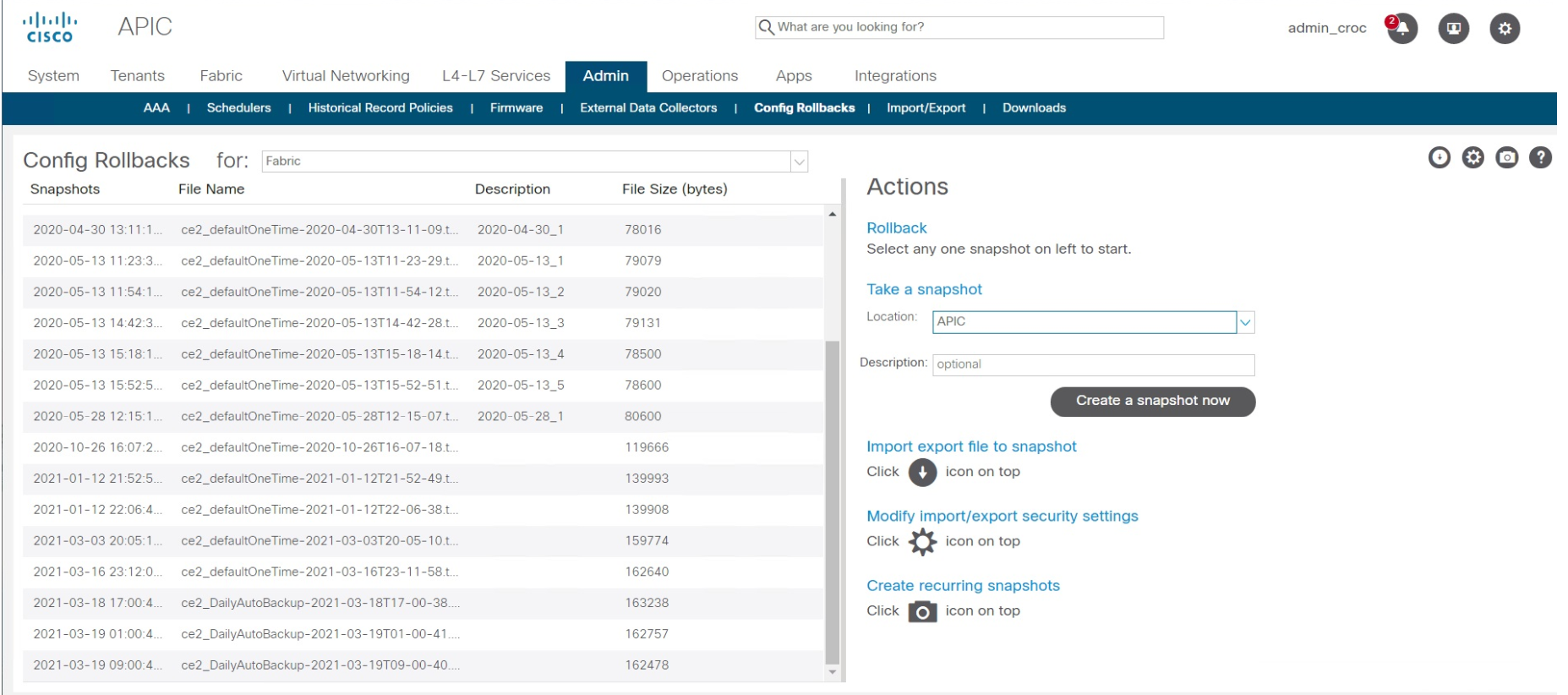
Нашли другой VPN, через который можно зайти (это потребовало согласования с безопасниками), и я откатил конфигурацию фабрики — в Cisco ACI это делается в два клика. Ничего сложного нет. Просто выбирается точка восстановления. Занимает это 10–15 секунд. То есть на само восстановление ушло 15 секунд. Всё остальное время было потрачено на то, чтобы понять, как получить удалённое управление.
Ещё день мы разбирали логи и восстанавливали цепочку событий. Потом собрали звонок с заказчиком, спокойно изложили суть и причины инцидента, предложили ряд мер, чтобы свести к минимуму риски подобных ситуаций и человеческого фактора.
Договорились, что конфиги фабрики мы трогаем только в нерабочие часы: ночное и вечернее время. Проводим работы обязательно с дублирующим удалённым подключением (есть рабочие VPN-каналы, есть резервные). Заказчик получает от нас предупреждение и в это время наблюдает за сервисами.
Инженер (то есть я) на проекте остался тот же. Могу сказать, что по ощущениям доверия ко мне стало даже больше, чем до инцидента — думаю, как раз потому что мы быстро сработали в ситуации и не дали волне паники накрыть заказчика. Главное — не пытались спрятать косяк. По практике я знаю, что в этой ситуации легче всего попытаться перевалить на вендора.
Похожие политики работы с сетью мы применили и к другим заказчикам на аутсорсе: это тяжелее для заказчиков (дополнительные VPN-каналы, дополнительные смены админов в нерабочие часы), но многие поняли, зачем это нужно.
Так же мы покопались глубже в ПО Cisco Network Assurance Engine (NAE), где нашли возможность сделать на фабрике ACI две простые, но очень важные вещи:
Если интересно больше деталей — у нас завтра вебинар про внутреннюю кухню техподдержки, будем рассказывать, как всё устроено у нас и у вендоров. Ошибки тоже будем разбирать)
Про такие ошибки обычно говорить не принято, потому что во всех интеграторах работают только безгрешные небесноликие люди. У нас, как известно, на уровне ДНК отсутствует возможность ошибаться или быть неправыми.
Но я рискну. Надеюсь, мой опыт кому-то будет полезен. Есть у нас один крупный заказчик, онлайн-розница, которому мы полностью поддерживаем фабрику Cisco ACI. Своего админа, компетентного по этой системе, у компании нет. Сетевая фабрика — это группа коммутаторов, которая имеет единый центр управления. Плюс ещё куча полезных фич, которыми очень гордится производитель, но в итоге, чтобы всё уронить, нужен один админ, а не десятки. И один центр управления, а не десятки консолей.
Начинается история так: заказчик хочет перенести на эту группу коммутаторов ядро всей сети. Такое решение обусловлено тем, что архитектура ACI, в которую «собрана» эта группа коммутаторов очень отказоустойчивая. Хотя это не типично и в целом фабрика в любом ЦОД не используется как транзитная сеть для других сетей и служит только для подключения конечной нагрузки (stub network). Но такой подход вполне имеет место быть, поэтому заказчик хочет — мы делаем.
Дальше произошло банальное — я перепутал две кнопки: удаления политики и удаления конфига фрагмента сети:
Ну а дальше по классике — нужно было собрать заново часть развалившейся сети.
По порядку
Запрос заказчика звучал так: нужно было построить отдельные порт-группы под перенос оборудования непосредственно на эту фабрику.
Коллеги, просьба перенести настройки портов Leaf 1-1 101 и leaf 1-2 102, порты 43 и 44, на Leaf 1-3 103 и leaf 1-4 104, порты 43 и 44. К портам 43 и 44 на Leaf 1-1 и 1-2 подключён стек 3650, он пока не введён в эксплуатацию, переносить настройки портов можно в любое время.
То есть они хотели перевести кластер серверов. Нужно было настроить новую виртуальную порт-группу под серверное окружение. По сути дела, это рутинная задача, простоя сервиса на такой задаче обычно нет. По сути своей порт-группа в терминологии APIC — это VPC, который собирается из портов находящихся физически на разных коммутаторах.
Проблема в том, что на фабрике настройки этих порт-групп привязаны к отдельной сущности (которая возникает вследствие того, что фабрика управляется с контроллера ). Этот объект называется port policy. То есть к группе портов, которые мы добавляем, нужно ещё сверху применить общую политику как сущность, которая будет управлять этими портами.
То есть нужно было сделать анализ, какие EPG используются на портах 43 и 44 на нодах 101 и 102 для того, чтобы собрать аналогичную конфигурацию на нодах 103-104. После анализа необходимых изменений я начал настраивать ноды 103-104. Для настройки нового VPC в существующей политике интерфейсов для нод 103 и 104 нужно было создать политику, в которую будут заведены интерфейсы 43 и 44.
И там есть в GUI один нюанс. Я создал эту политику и понял, что в процессе конфигурирования допустил незначительную ошибку, — назвал её не так, как принято у заказчика. Это не критично — потому что политика новая и ни на что не влияет. И мне эту политику нужно было удалить, поскольку изменения в неё уже внести нельзя (название не меняется) — можно только удалить и заново политику создать.
Проблема в том, что в GUI есть иконки удаления, которые относятся к политикам интерфейса, а есть иконки, которые относятся к политикам коммутатора. Визуально они почти идентичны. И я вместо того, чтобы удалить политику, которую я создал, удалил всю конфигурацию для интерфейсов на коммутаторах 103-104:
Вместо удаления одной группы фактически удалил все VPC из настроек ноды, использовал delete вместо trashbin.
В этих каналах были VLAN, чувствительные для бизнеса. По сути дела, после удаления конфига я отключил часть сетки. Причём это было не сразу заметно, потому что фабрика управляется не через ядро, а у неё отдельный менеджмент-интерфейс. Меня не выкинуло сразу, не произошло какой-то ошибки на фабрике, поскольку действие было предпринято администратором. И интерфейс считает — ну если вы сказали удалить, значит так надо. Никакой индикации ошибок не было. ПО решило, что идёт какая-то реконфигурация. Если админ удаляет профиль leaf, то для фабрики он перестаёт существовать и она не пишет ошибки о том, что он не работает. Он не работает — потому что его целенаправленно удалили. Для ПО он и не должен работать.
В общем, ПО решило, что я Чак Норрис и точно знаю, что делаю. Всё под контролем. Админ не может ошибаться, и даже когда он стреляет себе в ногу — это часть хитрого плана.
Но примерно через десять минут меня выкинуло из VPN, что я поначалу не связал с конфигурацией APIC. Но это как минимум подозрительно, и я связался с заказчиком, уточнить, что происходит. Причём следующие несколько минут я думал, что проблема в технических работах, внезапном экскаваторе или сбое питания, но никак не конфиге фабрики.
У заказчика сеть построена сложно. Мы по своим доступам видим только часть окружения. Восстанавливая события, всё похоже на то, что началась ребалансировка трафика, после чего через несколько секунд динамическая маршрутизация оставшихся систем просто не вывезла.
Тот VPN, на котором я сидел, — это был админский VPN. Обычные сотрудники сидели с другого, у них всё продолжало работать.
В общем, ещё пара минут переговоров ушла на то, чтобы понять, что проблема всё же в моём конфиге. Первое действие в бою в такой ситуации — сделать роллбек на прошлые конфиги, а только потом уже читать логи, потому что это прод.
Восстановление фабрики
На восстановление фабрики — с учётом всех звонков и сбора всех причастных — ушло 30 минут.
Нашли другой VPN, через который можно зайти (это потребовало согласования с безопасниками), и я откатил конфигурацию фабрики — в Cisco ACI это делается в два клика. Ничего сложного нет. Просто выбирается точка восстановления. Занимает это 10–15 секунд. То есть на само восстановление ушло 15 секунд. Всё остальное время было потрачено на то, чтобы понять, как получить удалённое управление.
После инцидента
Ещё день мы разбирали логи и восстанавливали цепочку событий. Потом собрали звонок с заказчиком, спокойно изложили суть и причины инцидента, предложили ряд мер, чтобы свести к минимуму риски подобных ситуаций и человеческого фактора.
Договорились, что конфиги фабрики мы трогаем только в нерабочие часы: ночное и вечернее время. Проводим работы обязательно с дублирующим удалённым подключением (есть рабочие VPN-каналы, есть резервные). Заказчик получает от нас предупреждение и в это время наблюдает за сервисами.
Инженер (то есть я) на проекте остался тот же. Могу сказать, что по ощущениям доверия ко мне стало даже больше, чем до инцидента — думаю, как раз потому что мы быстро сработали в ситуации и не дали волне паники накрыть заказчика. Главное — не пытались спрятать косяк. По практике я знаю, что в этой ситуации легче всего попытаться перевалить на вендора.
Похожие политики работы с сетью мы применили и к другим заказчикам на аутсорсе: это тяжелее для заказчиков (дополнительные VPN-каналы, дополнительные смены админов в нерабочие часы), но многие поняли, зачем это нужно.
Так же мы покопались глубже в ПО Cisco Network Assurance Engine (NAE), где нашли возможность сделать на фабрике ACI две простые, но очень важные вещи:
- первое – NAE позволяет сделать анализ планируемого изменения, еще до того, как мы его выкатили на фабрику и отстрелили себе все, спрогнозировав как позитивно или негативно изменение скажется на существующей конфигурации;
- второе – NAE уже после изменения позволяет измерить общую температуру фабрики и увидеть как это изменение в конечном счете повлияло на состояние ее здоровья.
Если интересно больше деталей — у нас завтра вебинар про внутреннюю кухню техподдержки, будем рассказывать, как всё устроено у нас и у вендоров. Ошибки тоже будем разбирать)













Jsty
У вас картинки маленькие и некликабельные. Не разобрать.
А если бы через консоль все настройки делались, ошибок бы не было, правильно?
Тут только вопрос качества проработки интерфейса?
MFCKR Автор
Через консоль тоже можно ошибок навалять безусловно, но там будет другой характер и будет касаться в основном copy-paste, случайно удалить интерфейс гораздо сложнее. А вот с интерфейсом да, было бы удобнее, если бы инструменты удаления разных политик были бы разнесены подальше.
karabanov
Я однажды вместо switchport trunk allowed vlan add ввёл switchport trunk allowed vlan и отрубил себе управление и интернет у 5000 человек. Циска и в консоли коварная.
anonymous
Пфф, а кто не накатывал deny all all на циске за много-много километров?
karabanov
Комментарий был не про "достижения", а про неоднозначный дизайн в том числе и в консоли.
ColdSUN
Такую ошибку совершали многие. Я в том числе.
Tamahome
Я думаю это делал каждый, поэтому вариант с commit конфига и автоматическим rollback если не было confirm/save ИМХО лучшее, что спасёт.
scruff
Гораздо фатальнее накатить кривой IOS — тогда вечер точно перестанет быть томным от слова совсем, если девайс расположен хотя бы сотне км, и превратиться в пляски с консольным кабелем на пару с уборщицей/дворником/мерчендайзером/бухгалтером.