

Во многих компаниях для сбора и анализа логов используют такой инструмент как Kibana. Но существует проблема которая выражается в том, что этим инструментом редко или почти не пользуются. Почему же так происходит? Дело в том, что человек привык анализировать логи непосредственно на инстансе. Читать логи так сказать из первоисточника. Безусловно это самый лучший способ. И мало кто не любит менять свои привычки. Потому что это своего рода выход из зоны комфорта и к этому не все и не всегда готовы.
Кейсы чтения логов
Но бывают ситуации, когда нет возможности зайти непосредственно на инстанс. Например необходимо проанализировать инцидент случившийся на продакшене и у нас нет доступа к этому окружению по известным всем причинам. Другая ситуация, если сервис работает на операционной системе Windows, а доступ нужен для трех и более сотрудников одновременно. Как мы все хорошо знаем у компании Windows есть политика одновременной работы не более двух человек при входе по RDP (Remote Desktop Protocol). Для того чтобы получить одновременный доступ по RDP большему количеству сотрудников, необходимо купить лицензию, а на это готова пойти далеко не каждая компания.
Стек ELK
Таким образом мы возвращаемся к нашему замечательному инструменту Kibana. Kibana это часть стека ELK, в который помимо неё входят Elasticsearch и Logstash. Kibana используется не только для визуализации данных в различных форматах, но также и для быстрого поиска и анализа логов. И сегодня речь пойдет о том, как комфортно перейти на этот инструмент и какие у него есть скрытые возможности для этого.
Способы и лайфхаки
Для начала можно ввести в поле Search номер какой-нибудь операции и выбрать промежуток времени за который необходимо произвести поиск. В результате этого запроса отобразиться временной график с количеством совпадений этого номера.

Так же можно составлять сложные поисковые запросы. Существует специальный язык запросов, называемый KQL (Kibana Query Language). С помощью этого языка можно составлять многоуровневые запросы, которые помогают отфильтровывать нужную информацию. Например можно выбрать тестовое окружение и задать конкретное его имя. Если необходимо найти какое-нибудь словосочетание, то нам на помощь приходят двойные кавычки. При заключении двух и более слов в двойные кавычки происходит поиск всей фразы целиком.
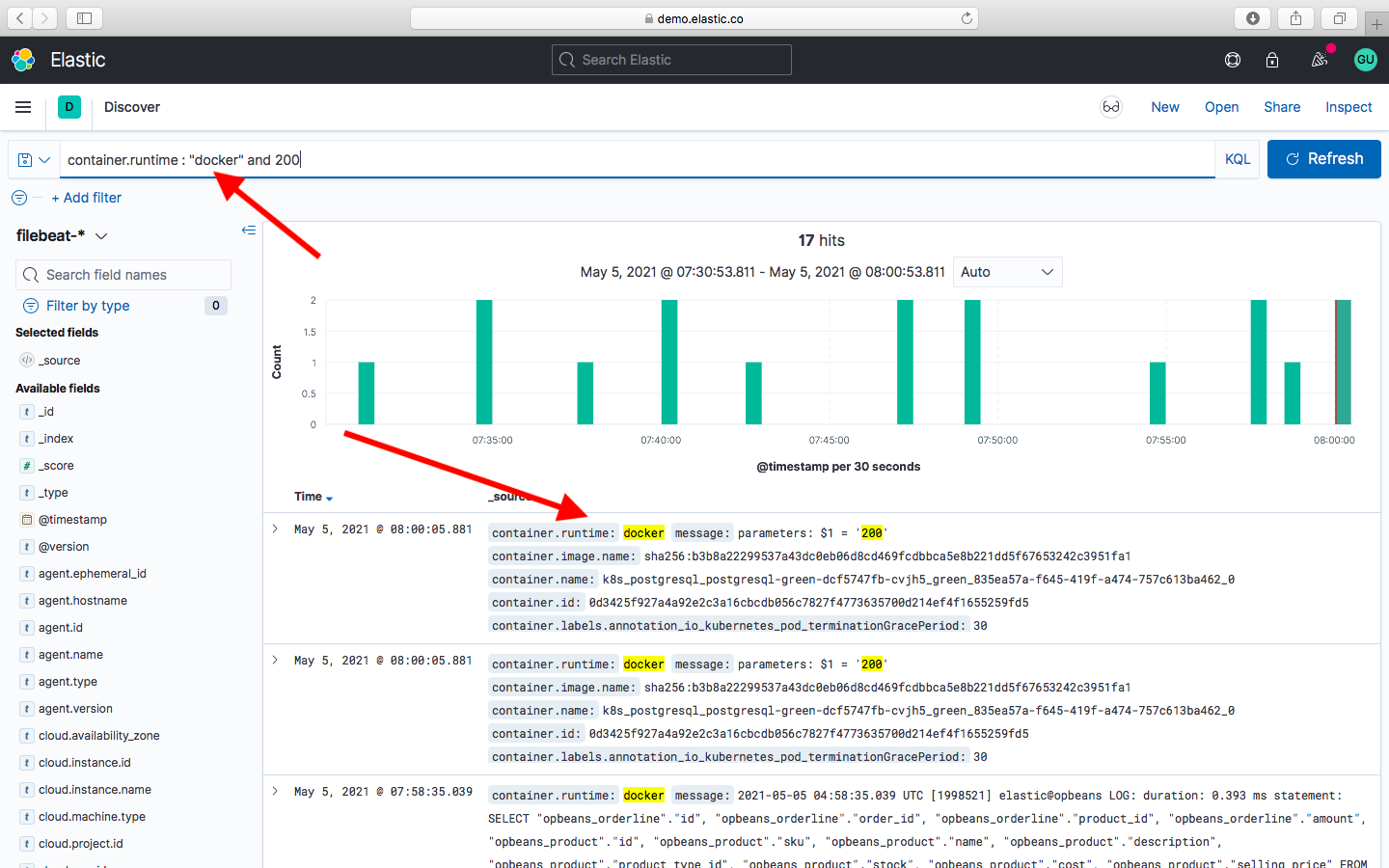
Более подробную информацию по составлению сложных запросов можно найти на официальном сайте elastic. Для тех кто привык изучать логи в хронологическом порядке, в Kibana тоже есть такая возможность. При нахождении конкретной ошибки в нашем логе, хотелось бы увидеть что происходило до этого и после. Для этого необходимо кликнуть на найденный фрагмент лога и далее нажать на Просмотр. Перед вами откроется список логов, в котором ваш запрос будет подсвечен серым цветом. И будет загружено несколько строчек лога которые предшествовали нашей ошибке.
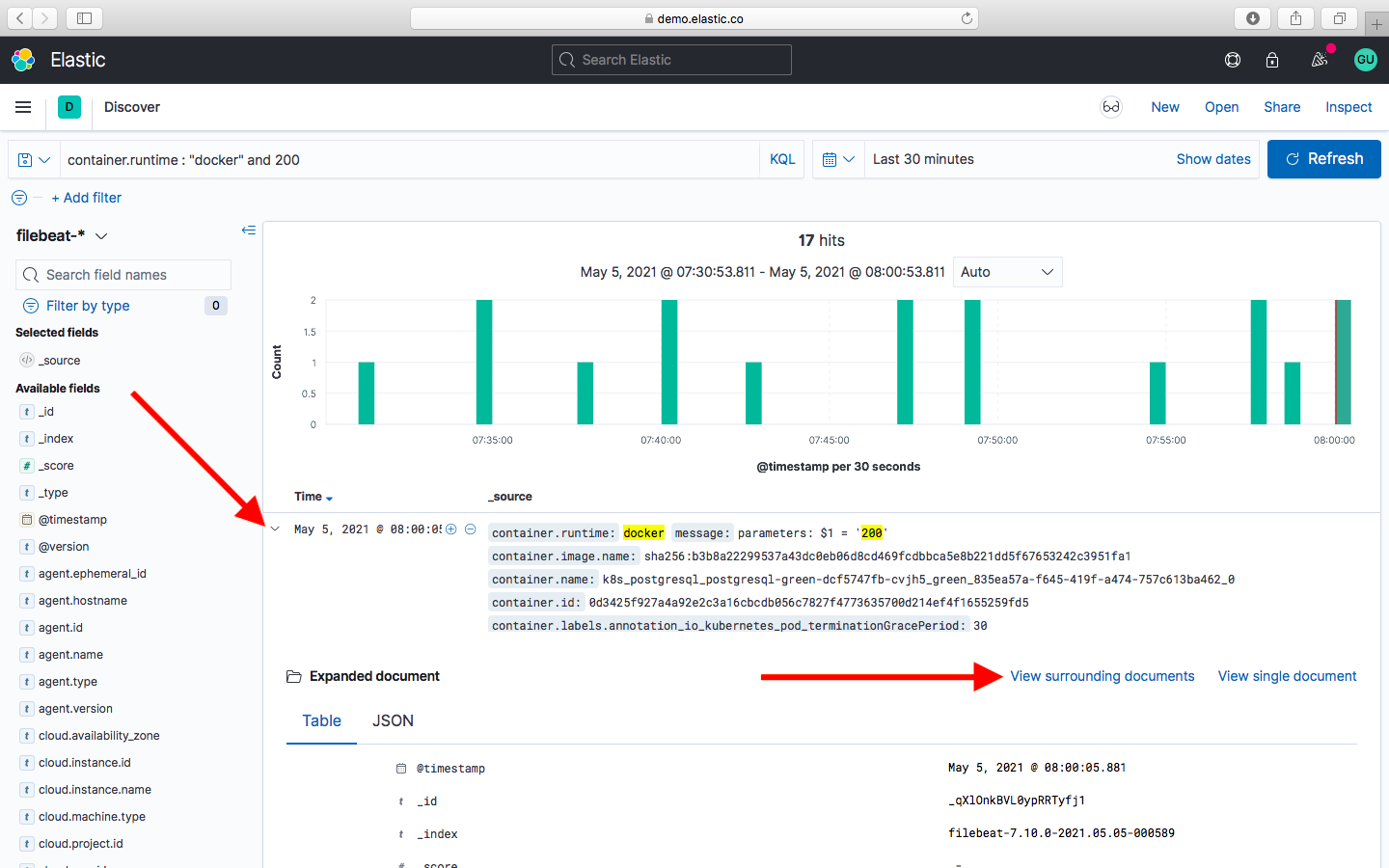
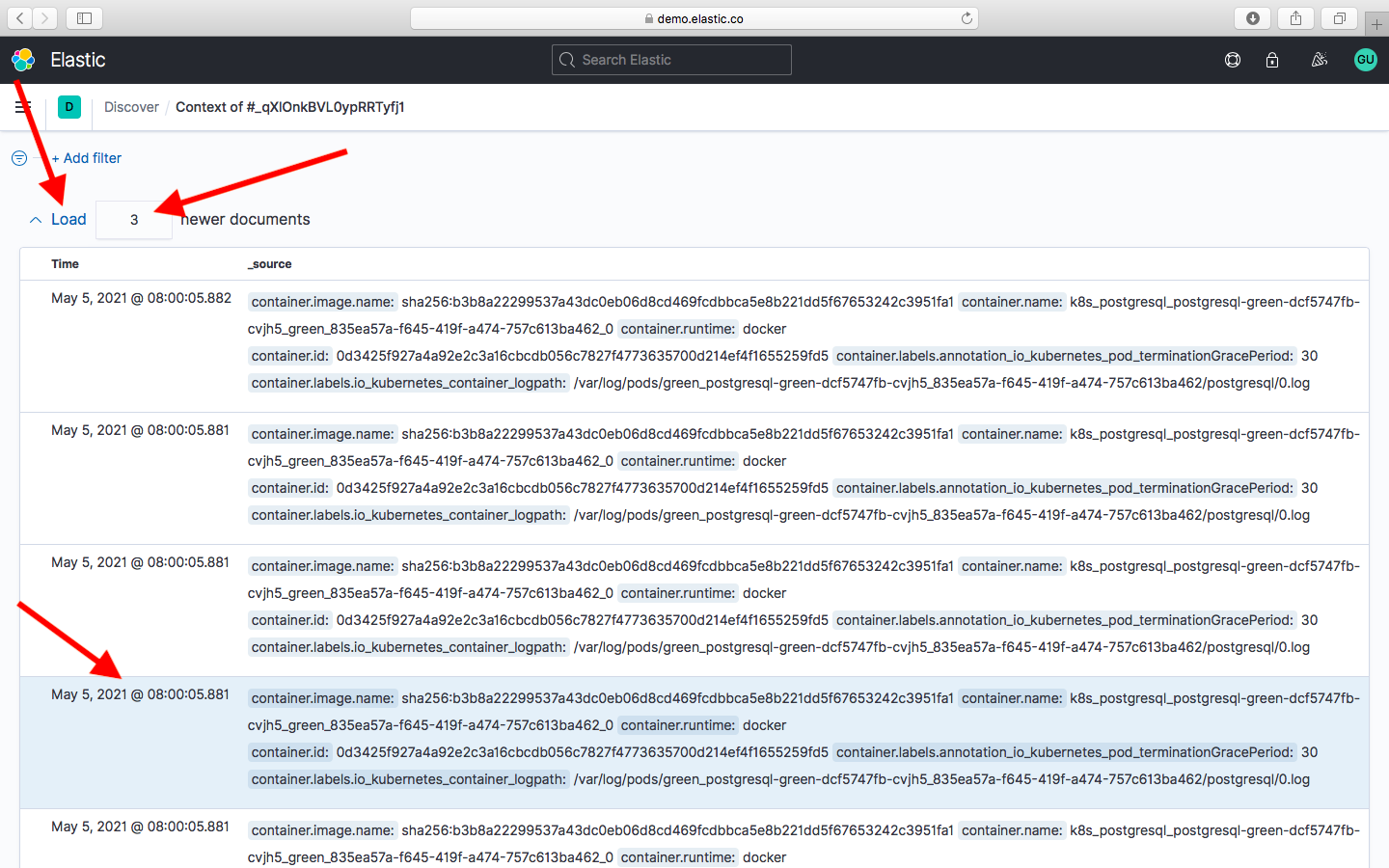
Эти логи будут внизу. И несколько строчек которые были после нашей ошибки. Эти строчки будут выше нашей ошибки. В Kibana логи читаются снизу вверх в отличии от логов на инстансе, где логи идут сверху вниз. По умолчанию загружаются 5 строчек до и 5 после, но это значение можно изменить и затем нажать кнопку Загрузка. После чего произойдет загрузка указанного количества строк лога выше нашей ошибки. Тоже самое можно сделать и с предыдущими логами.
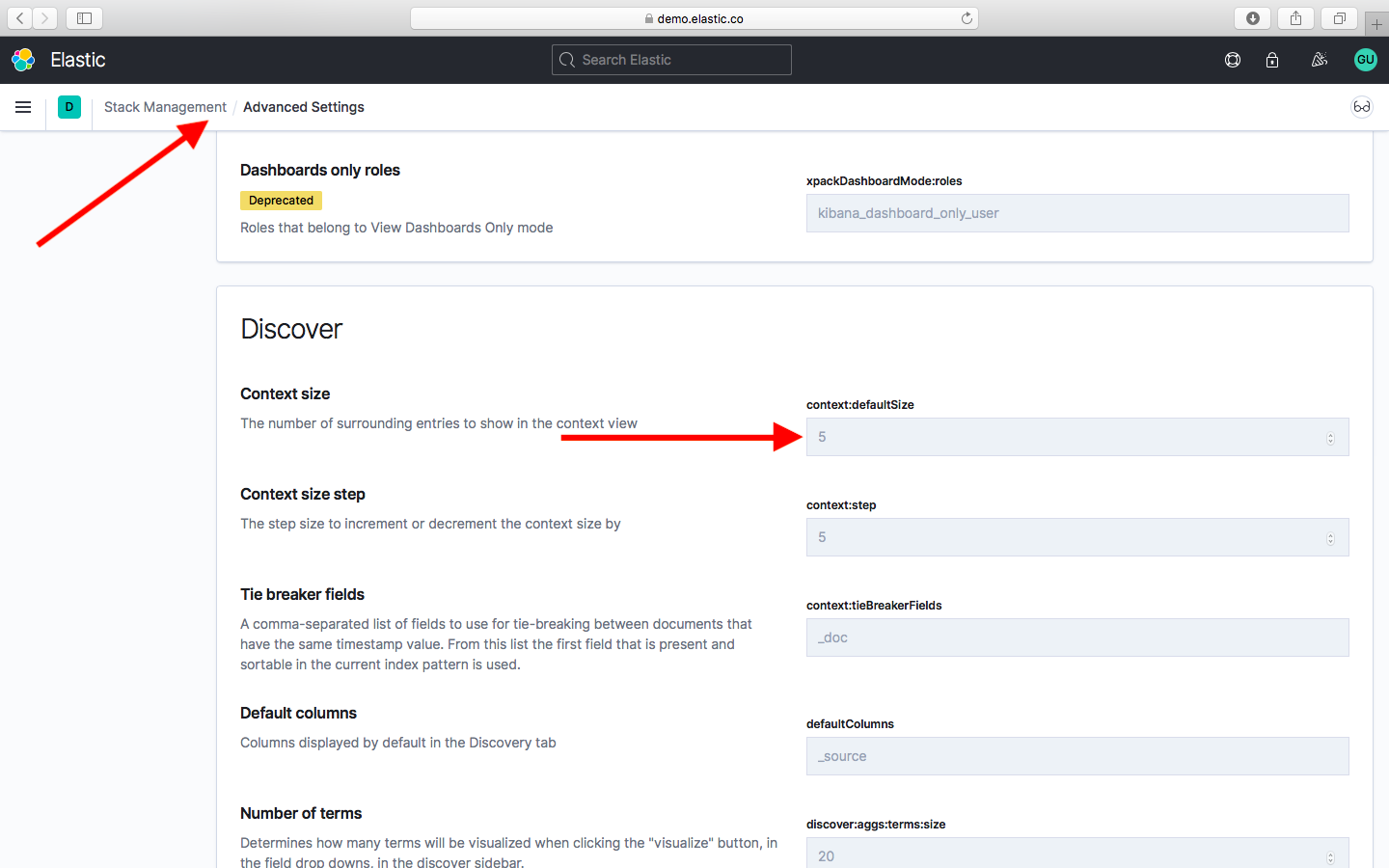
Дефолтное значение 5 можно изменить в настройках системы перейдя Stack Management > Advanced Settings
Заключение
В данной статье я не преследовал цель научить пользоваться инструментом Kibana. В интернете очень много подробных статей и видео об этом. Да и на официальном сайте elastic есть предостаточно информации. Мне хотелось показать, как комфортно и без особых усилий можно начать пользоваться другим способом чтения логов. И при этом можно решить одновременно несколько задач, начиная от выхода из зоны комфорта и заканчивая сложнейшими запросами в совокупности с быстродействием получения результата.
В преддверии старта курса "Java QA Engineer. Basic" приглашаем всех желающих на двухдневный онлайн-интенсив «Теория тестирования и практика в системах TestIT и Jira».
На интенсиве вы узнаете, что такое тестирование и откуда оно появилось, кто такой тестировщик и что он делает. Изучим модели разработки ПО, жизненный цикл тестирования, чек листы и тест-кейсы, а также дефекты. На втором занятии познакомимся с одним из главных трекеров задач и дефектов — Jira, а также попрактикуемся в TestIT — отечественной разработке для решения задач по тестированию и обеспечению качества ПО.




sedyh
Функционал KQL и Lucene довольно беден для поиска чего-либо сложнее пары подстрок. Искать вложенные объекты очень неудобно, а регулярки сделаны кое-как и к ним нужно привыкать.