
Вопрос производительности все чаще обсуждается во фронтенд сообществе, поскольку продукты, приложения и сайты становятся сложнее — данные, графика, онлайн взаимодействие большого количества пользователей. Это, а также резкая цифровизация всех оффлайн процессов из-за локдауна, привело к тому, что текущие решения требуют доработки и оптимизации под возросшие нагрузки.
Так случилось и с нашим продуктом: 2020 год стал для Miro годом оптимизации производительности. Чем больше пользователей взаимодействуют на одной доске, тем больше контента генерируется, тем больше данных браузеру каждого пользователя нужно получить, обработать и отобразить в реальном времени.
Интро
Я работаю в команде Canvas Widgets, мы занимаемся разработкой виджетов на канвасе (доска с виджетами). Однажды к нам пришёл продакт мобильной команды с обратной связью от пользователей. Суть её сводилась к одному: на iPad при большом количестве виджетов рисования — так мы называем pen tool — элементы интерфейса начинали "моргать", пропадать и приложением невозможно было пользоваться.

Что говорила статистика:
130 тикетов в баг репортере с января по октябрь 2020, это около 13 тикетов в месяц;
35% всего фидбека по iPad — негативный фидбек, который описывает данную проблему;
89% всех создаваемых виджетов на iPad за месяц — виджет рисования;
Виджет рисования занимает второе место по частоте использования на iPad.
Гипотезу искать долго не пришлось, её принесли в той же корзине, что и проблему — нехватка оперативной памяти на некоторых моделях iPad.
Мы начали наше исследование. Первое, что пришло на ум, — лоды.
Лод (или корректнее Level of Detail, LoD) — концепция, которая обеспечивает кэширование на уровне отрисовки. Последовательность изображений, которая заменяет исходный контент виджета на определенных уровнях приближения. Каждое изображение — это уменьшенная в 2 раза копия предыдущего.
Лоды хранятся в оперативной памяти и включаются в определенные моменты времени — как правило, когда реальный размер виджета на экране уменьшается относительно его заданного размера. На каждый виджет рисования приходилось одно изображение для iPad и два изображения для десктопной версии и веба.
Кажется это оно: мы нашли потенциальную причину, давайте просто отключим люды. Но если отключаем лоды — падает FPS при работе на доске, а мы этого не хотим.
Первое решение "Векторные лоды"
Решение довольно быстро пришло нам в голову. Сейчас отрисовывается кривая Безье, затем создается изображение и в определенные моменты отображается вместо виджета.
Но что, если вместо изображения рисовать не кривую Безье, а просто соединять точки кривой. Плавность линий пропадет, но в момент, когда пользователь этого не заметит.
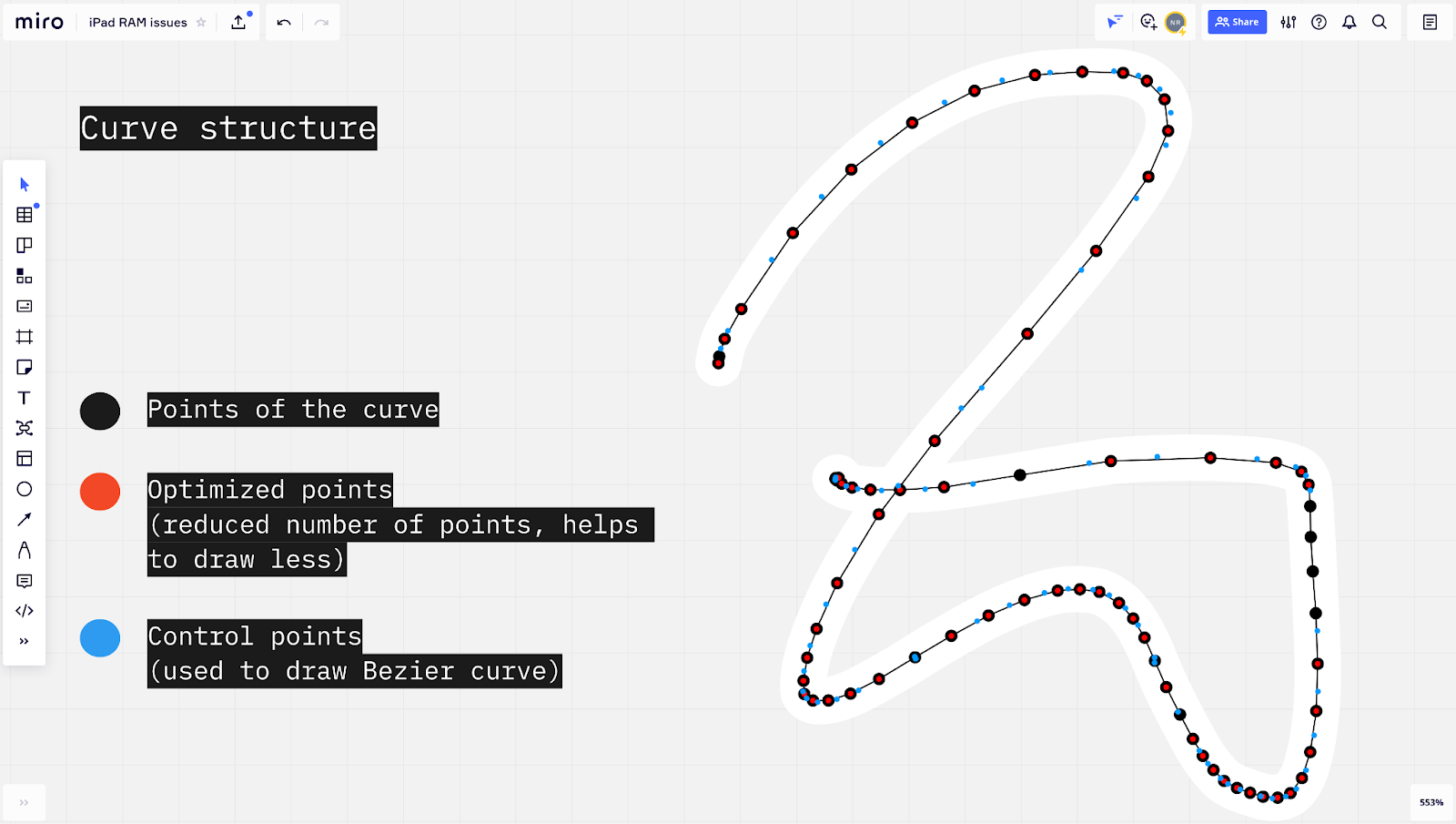
Мы назвали это решение "Векторные лоды", сделали прототип и замерили:
Для тестирования мы взяли доску и создали на ней 4000 однотипных кривых.
Векторные лоды. Потребляемая память ~256 Mb.
Растровые лоды (изображения). Потребляемая память ~316 Mb.
Итого, уменьшили количество потребляемой памяти на ~20% — немного.
Мы понимали, что это не сильно поможет страждущим пользователям, поэтому продолжили поиск точек оптимизации.
Сейчас, при рисовании, когда вы отпускаете кнопку мыши, создаётся новый виджет. Каждый виджет имеет данные: точки, стили, скейл, размеры, позиция.
Второе решение "Объединение кривых"
В большинстве случаев при написании текста довольно редко меняются стили, поэтому создавать новый виджет после каждого отпускания кнопки мыши/стилуса выглядит не оптимально. Действительно, зачем выделять точку в символе i в отдельный виджет?

Вместо этого можно создавать виджет, когда прошло какое-то значительное время после последней нарисованной кривой, либо по расстоянию от последней созданной кривой. Таким образом можно сэкономить на метаданных, которые содержит каждая кривая. Данное решение затрагивает процесс создания виджета, поэтому сработает оно только для новых виджетов, на текущих проблемных досках это никак не отразится.
Мы назвали это решение "Объединение кривых", сделали прототип и замерили:
Для тестирования взяли доску и нарисовали на ней 1000 квадратов с одинаковым количеством точек. Каждая сторона квадрата — отдельная кривая (виджет), так как квадрат нарисован с прерыванием — отпусканием кнопки мыши/стилуса.
Текущая версия. Потребляемая память ~160 Mb.
Объединение виджетов. Потребляемая память ~105 Mb.
Итого, уменьшили количество потребляемой памяти на ~35%.
В совокупности с оптимизацией лодов, которую мы провели ранее, потребление памяти удалось сократить на ~50% — отлично, не правда ли? Вплоть до этого момента описывая все решения я употреблял слово прототип — решение сделанное "на коленке", лишь бы работало, чтобы проверить гипотезу. И если в случае с оптимизацией лодов всё довольно прозрачно — оценить, выполнить и довести до релиза все изменения не составило труда. Решение с объединением виджетов не выглядит так безоблачно, у нас сразу возникли вопросы касательно UX:
Нужно ли передвигать сегменты отдельно? Как?
Какой ставить таймаут создания?
Как удалять сегменты — отдельно или все сразу?
Как виджет появляется у коллаборатора: сразу весь после создания или посегментно — каждый раз после отпускания мыши?
Из этого возникают и технические вопросы:
Как записывать в историю: 1 шаг или количество шагов равняется количеству сегментов?
Как хранить данные: одномерный массив с разделителем, двумерный массив или иначе?
В итоге, поскольку ресурса для UX проработки в тот момент у нас не было, мы сохранили результаты аналитики, прототип и отправились искать относительно быстрый способ решить проблему потребления памяти.
Третье решение "Меняем структуру данных"
К этому моменту мы обратили внимание на то, как хранятся точки кривых в памяти. Каждая точка хранится в объекте примитива рисования, который предоставляет фреймворкPIXI.js, а именно — в объекте PIXI.Point. В свою очередь каждый виджет имеет 2 массива:
points: PIXI.Point[]— массив точек кривой;controlPoints: PIXI.Points[][]— двумерный массив контрольных точек для отрисовки кривых Безье.
Для тестирования мы взяли доску и нарисовали на ней 4000 кривых, каждая содержит ~100 точек. После мы изучили снимки памяти и получили:
Объект | Количество | Занимаемая память (Мб) | Удерживаемая память (Мб) |
PIXI.Point | 580482 | 12 | 30 |
Array | 307854 | 35 | 53 |
Всего выделено памяти на доску (heap): 165 мегабайт.
На хранение одной точки, в виде объекта PIXI.Point, отводится:
20 байт— вес самого объекта (shallow size);88 байт— вес объектов, которые удерживаются текущим и не могут быть собраны GC (retained size).
Поскольку мы храним данные одного типа и заранее можем вычислить необходимый объем памяти для хранения точек кривой — 64-битные числа с плавающей запятой, то в этом случае мы можем использовать typed arrays.
Typed arrays— массивоподобные объекты, которые позволяют работать с бинарными данными. В то время как обычные массивы могут расти, уменьшаться и хранить данные любого типа,typed arraysпозволяют хранить числа отint8доfloat64и заранее аллоцировать необходимое количество памяти.
О том, как работают typed arrays, можно почитать тут. Если кратко, то их архитектура имеет 2 основных части:
buffer— хранит данные в бинарном формате;view— отображение, позволяющее интерпретировать данные буфера как определенный тип —int8, uint8, int16, uint16, ....
Настало время проверить гипотезу, что этот формат хранения данных позволит сэкономить еще несколько мегабайт памяти и научит наш код работать с typed arrays.
Каждый виджет кривой хранит точки в формате:
interface IPoint {
x: number
y: number
}
interface ICurveWidgetJson {
points: IPoint[]
}
Каждая точка — это 2 float64, поэтому все точки будем хранить как Float64Array. Следовательно, на хранение одной точки теперь отводится 16 байт.
Для удобства работы с точками кривой абстрагируем код виджета от особенностей хранения, создания и доступа к данным создадим удобный интерфейс для взаимодействия как с массивом:
type ToArrayResult<PointType, SerializedType> = PointType extends [] ? SerializedType[][] : PointType[]
interface IOptimizedPoints<Data> {
length: number
toArray<OutPoint extends IPoint>(
pointConstructor?: new (x: number, y: number) => OutPoint
): ToArrayResult<Data, OutPoint>
forEach(callbackfn: (data: Data, index: number) => void): void
some(predicate: (value: Data, index: number) => boolean): boolean
}
Далее этот интерфейс реализуют два класса:
Points— массив основных точек кривой;ControlPoints— двумерный массив контрольных точек для отрисовки (генерируются на клиенте).
Итоговый размер вычисляем так:
pointsCount * POINT_ELEMENTS_COUNT * Float64Array.BYTES_PER_ELEMENT
pointsCount— количество точек кривой;POINT_ELEMENTS_COUNT— количество элементов (чисел) для хранения точки (по-умолчанию 2);Float64Array.BYTES_PER_ELEMENT— количество байт на один элемент массива (8 байт).
Основное отличие этих двух классов — ControlPoints принимает и выдает данные в формате двумерного массива:
// 'in/out':
[[p1, p2] [p3], [p4, p5]]
// 'store as':
[p1.x, p1.y, p2.x, p2.y, p3.x, p3.y, p4.x, p4.y, p5.x, p5.y]
Тестирование проводим на той же доске, что и раньше.
Итоговый снимок heap'a показал следующие результаты:
Объект | Количество | Занимаемая память (Мб) | Удерживаемая память (Мб) |
PIXI.Point | 184048 | 4 | 8 |
Array | 255144 | 29 | 46 |
Всего выделено памяти (heap): 130 мегабайт.
Что касается количества памяти, выделенной под хранение данных точек кривой в виде typed arrays:
Объект | Количество | Занимаемая память (Мб) | Удерживаемая память (Мб) |
Points | 8024 | 0.11 | 8 |
ControlPoints | 4012 | 0.09 | 2 |
Отказавшись от хранения точек в виде массивов объектов PIXI.Point нам удалось в 3 раза сократить занимаемую ими память. Поскольку данные теперь хранятся в typed arrays, количество массивов также уменьшилось и, следовательно, память выделяемая под них.
Итого, уменьшили количество потребляемой памяти на ~20%.
Вывод
В итоге мы провели две небольших оптимизации:
Заменили растровые лоды на векторные;
Изменили способ хранения данных кривых в памяти.
Совокупно эти оптимизации позволили сократить потребление памяти на ~40%.
Спустя несколько месяцев после внедрения оптимизаций мы имеем следующую картину:
15 тикетов в баг репортере за 2 месяца, а это ~7 тикетов в месяц, что в 2 раза меньше исходной точки;
Количество алертов, посылаемых при достижении лимита по памяти, упало с 21к до 15к за месяц.
Позволил ли результат работы с уверенностью сказать, что проблема больше никогда не возникнет? Нет, но она возникнет гораздо позже, позволив пользователям, которые столкнулись с ней, продолжить работу, а также создаст плацдарм для дальнейшего развития виджета рисования.

Alexufo
Делать слои, вынести сложные вычисления в воркер и работать через OffscreenCanvas?
Сложные по памяти расчеты класть в wasm? Например, расчет растра?
undermuz
Как это уменьшит потребление оперативной памяти?
Alexufo
Ну блин, есть разница где делать ресайз того же полотна в js или в плюсах. Или вычисление формы каких нибудь кривых от 1000 точек, если инструмент влияет на них всех. Память уменьшается не только оптимальной структурой хранения но и более низкоуровневыми механизмами вычислений.
Например, при захвате канваса можно отключать альфа канал итого у вас 3 канала, дальше ресайз происходит c поддержкой векторной оптимизации simd. В сумме все это даст память.