
TL;DR: Cure — это функциональный язык программирования для виртуальной машины BEAM (Erlang/Elixir/Gleam/LFE), который привносит математические доказательства корректности кода прямо во время компиляции. Используя SMT-солверы (Z3/CVC5), Cure проверяет типы зависимые от значений, верифицирует конечные автоматы и гарантирует отсутствие целых классов ошибок ещё до запуска программы.
Что такое Cure и зачем он нужен?
Проблема современной разработки
Без тестов не обойтись, но для некоторых критически-важных частей кода хотелось бы каких-нибудь более веских гарантий, например — доказательств корректности. При прочих равных, это не имеет смысла для интернет-магазинчиков и сайтов-визиток, но биржевая платформа, система управления беспилотником, или медицинское ПО — заслуживают чего-то посерьезнее тяп-ляп тестов.
При этом, все существующие языки, позволяющие доказывать корректность, — либо не готовы к продакшену, либо написаны инопланетянами для инопланетян, либо заставят вас весь остальной проект писать на тех же условиях (HTTP-запросу от пользователя проверка типов и гарантии корректности не нужны, а накладные расходы на них, такие, как время компиляции и само время написания — довольно значительные, чтобы ими пренебречь).
Я годами писал критические подсистемы на идрисе, переводил ручками на эликсир, и меня это устраивало — но ужасно раздражало. Да, при переводе (на любой границе с внешним миром) — математическая доказательность теряется, но это допустимый риск (для меня). Я точно знаю, что если «спайка» тщательно проверена, то код внутри будет работать как надо.
Но у идриса хватает своих проблем, я не считаю хаскелеподобный синтаксис приемлемым для взрослого программирования, да и переводить каждый раз туда-сюда — довольно муторно. И я подумал: а что, если написать свой язык, который будет компилироваться в BEAM и прозрачно линковаться с эрлангом, эликсиром, глимом и даже лфе?
Мне от языка-то надо всего-навсего три вещи:
завтипы и солверы
FSM в корке, со всеми плюшками
отсутствие
if-then-else
И я просто создал Cure.
Традиционный подход:
%% Erlang - проверки только во время выполнения
safe_divide(A, B) when B =/= 0 ->
{ok, A / B};
safe_divide(_, 0) ->
{error, division_by_zero}.Да, это работает. Но что если вы забыли проверку? Что если логика усложнится и появится новый путь выполнения?
Подход Cure:
# Cure - математическое доказательство на уровне типов
def safe_divide(a: Int, b: {x: Int | x != 0}): Int =
a / b
# Компилятор ДОКАЖЕТ, что b никогда не будет нулём
# Или программа не скомпилируетсяФилософия Cure
Cure стоит на трёх китах:
Верификация важнее удобства — когда корректность критична, синтаксический сахар вторичен
Математические доказательства вместо надежд — компилятор не просто проверяет типы, он доказывает свойства программы
BEAM как фундамент — вся мощь Erlang OTP, но с гарантиями корректности на уровне типов
Зависимые типы: Что это и зачем?
Простой пример
Обычные типы говорят: «это целое число». Зависимые типы говорят: «это целое число больше нуля и меньше длины списка».
# Тип зависит от ЗНАЧЕНИЯ
def head(v: Vector(T, n)): T when n > 0 =
nth(v, 0)
# Компилятор ДОКАЖЕТ, что:
# 1. Вектор непустой (n > 0)
# 2. Индекс 0 всегда валиден
# 3. Результат имеет тип T
# Попытка вызвать head на пустом векторе?
# ❌ ОШИБКА КОМПИЛЯЦИИРеальный пример: безопасный доступ к списку
# Безопасный доступ - математически доказан
def safe_access(v: Vector(Int, n), idx: {i: Int | i < n}): Int =
nth(v, idx) # Без проверок - компилятор УЖЕ доказал безопасность!
# Использование
let my_vector = ‹5, 10, 15, 20› # Vector(Int, 4)
safe_access(my_vector, 2) # ✅ OK - 2 > 4
safe_access(my_vector, 10) # ❌ ОШИБКА КОМПИЛЯЦИИ - 10 ≥ 4Обратите внимание: никаких проверок в рантайме. Компилятор математически доказал, что idx всегда валиден. Это не просто «проверка типов» — это математическое доказательство.
SMT-солверы и формальная верификация
Что такое SMT-солвер?
SMT (Satisfiability Modulo Theories) — это математический движок, который проверяет, существует ли решение системы логических уравнений.
Представьте задачу:
Дано: x > 0, y > 0, x + y = 10
Вопрос: может ли x = 15?SMT-солвер математически докажет, что нет — если x = 15, то y = -5, что нарушает условие y > 0.
Как Cure использует Z3
Cure интегрирует Z3 — самый мощный SMT-солвер от Microsoft Research — прямо в компилятор:
# Функция с гардами
def classify_age(age: Int): Atom =
match age do
n when n < 0 -> :invalid
0 -> :newborn
n when n < 18 -> :minor
n when n < 65 -> :adult
n when n >= 65 -> :senior
endЧто делает компилятор с Z3:
-
Переводит гварды в SMT-формулы:
(assert (< n 0)) ; первый case (assert (= n 0)) ; второй case (assert (and (>= n 0) (< n 18))) ; третий case ... -
Z3 проверяет полноту покрытия:
Все ли случаи покрыты?
Нет ли пересечений?
Нет ли недостижимых веток?
-
Гарантирует:
✓ Все целые числа покрыты ✓ Каждое число попадёт ровно в один case ✓ Нет мёртвого кода
Верификация конечных автоматов
FSM (Finite State Machine) — это сердце многих систем на BEAM. Я лично написал ажно целую библиотеку поддержки FSM с «верификацмями» на эликсире, но это, конечно, были костыли, сделанные из палок. В Cure из коробки есть настоящие верифицируемые конечные автоматы (пример посложнее):
record TrafficLight do
cycles: Int
emergency_stops: Int
end
fsm TrafficLight{cycles: 0, emergency_stops: 0} do
Red --> |timer| Green
Green --> |timer| Yellow
Yellow --> |timer| Red
Green --> |emergency| Red
Yellow --> |emergency| Red
end
Z3 проверит, что: ① нет зацикливания (deadlock’ов), ② все состояния достижимы, ③ нет недоопределенных переходов, и ④ инварианты сохраняются. И всё это на этапе компиляции!
Пайпы
Я не пурист, я просто сделал пайпы монадическими. Подробнее вот тут.
Текущее состояние проекта
✅ Что работает (Версия 0.5.0 — Ноябрь 2025)
Полностью функциональная имплементация:
-
Компилятор (100% работоспособен)
Лексический анализ с отслеживанием позиций
Парсинг в AST с восстановлением после ошибок
Система зависимых типов с проверкой ограничений
Генерация байткода BEAM
Интеграция с OTP
-
Стандартная библиотека (12 модулей)
Std.Core— базовые типы и функцииStd.Io— ввод-вывод (в зачаточном состоянии, я не могу понять, нужен ли он мне вообще)Std.List— операции со списками (map/2,filter/2,fold/3,zip_with/2)Std.Vector— операции со списками определенной длиныStd.Fsm— работа с конечными автоматамиStd.Result/Std.Option— обработка ошибокStd.Vector— индексированные векторыИ другие...
-
FSM Runtime
Компиляция FSM в
gen_statembehaviorsMermaid-нотация для FSM (
State1 --> |event| State2)Runtime операции (spawn, cast, state query)
Интеграция с OTP supervision trees
-
Оптимизация типов (25-60% ускорение)
Мономорфизация
Специализация функций
Инлайнинг
Устранение мёртвого кода
-
Гарды функций с SMT-верификацией
def abs(x: Int): Int = match x do n when n < 0 -> -n n when n >= 0 -> n end # Z3 проверит полноту покрытия! -
Интеграция с BEAM
[×]Полная совместимость с Erlang/Elixir[ ]Hot code loading[?]Distributed computing — кхм :) почти[×]OTP behaviours
Не готово / не работает
Type Classes/Traits — полиморфные интерфейсы (парсер готов, ждёт реализации)
String interpolation — шаблонные строки
-
CLI интеграция SMT — запуск Z3 из командной строки (API готов)
LSP и MCP: Разработка с комфортом
И это, внезапно, еще не все. Мне самому приходится довольно много возиться с кодом на Cure, поэтому параллельно разрабатываются полноценный LSP и MCP.
Language Server Protocol (LSP)
Cure поставляется с неплохим LSP сервером для IDE:
Возможности:
Real-time диагностика — ошибки прямо в редакторе
Hover информация — типы и документация по Ctrl+hover
Go to definition — навигация по коду
Code completion (пока довольно средняя)
Code actions (всё, что может вывести солвер — из коробки)
Type holes —
_для вывода типов (как дырки в идрисе)
Интеграция: Гипотетически, должно работать в любом редакторе с поддержкой LSP. Протестировано только в NeoVim.
Пример:
# Дырка ⇓
def factorial(n: Int): _ =
match n do
0 -> 1
n -> n * factorial(n - 1)
end
# Hover покажет выведенный `Int`, а `<leader>ca` — вставит его по местуModel Context Protocol (MCP)
Cure поддерживает MCP — новый протокол от Anthropic для интеграции с AI-ассистентами:
Что это даёт (для особо одаренных: список с эмоджиками — это контекстная шутка):
? AI-assisted coding — Claude/GPT понимает контекст проекта
? Умный поиск — семантический поиск по кодовой базе
? Type-aware рефакторинг — AI знает о типах
? Документация на лету — генерация docs из кода
Архитектура:
┌─────────────┐
│ Claude │ ← MCP Protocol
│ /GPT │
└──────┬──────┘
│
┌──────▼──────────────┐
│ MCP Server │
│ (Cure integration) │
├─────────────────────┤
│ • Code search │
│ • Type queries │
│ • Documentation │
│ • Refactoring hints │
└─────────────────────┘
Как попробовать Cure
Установка
Требования:
Erlang/OTP 28+
Make
Git
(Опционально) Z3 для SMT-верификации
Шаги:
# 1. Клонируйте репозиторий
git clone https://github.com/am-kantox/cure-lang.git
cd cure-lang
# 2. Соберите компилятор
make all
# 3. Проверьте установку
./cure --version
# Cure v0.5.0 (November 2025)
# 4. Запустите тесты
make test
# ✓ All tests passedПервая программа
Создайте hello.cure:
module Hello do
export [main/0]
import Std.Io [println]
def main(): Int =
println("Привет из Cure!")
0
endСкомпилируйте и запустите:
./run_cure.sh hello.cure
# Привет из Cure!Примеры из коробки (они иногда ломаются)
# FSM: светофор
./cure examples/06_fsm_traffic_light.cure
erl -pa _build/ebin -noshell -eval "'TrafficLightFSM':main(), init:stop()."
# Работа со списками
./cure examples/01_list_basics.cure
erl -pa _build/ebin -noshell -eval "'ListBasics':main(), init:stop()."
# Pattern matching с гвардами
./cure examples/04_pattern_guards.cure
erl -pa _build/ebin -noshell -eval "'PatternGuards':main(), init:stop()."
# Обработка ошибок через Result
./cure examples/02_result_handling.cure
erl -pa _build/ebin -noshell -eval "'ResultHandling':main(), init:stop()."
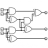
Архитектура компилятора
Pipeline компиляции
┌──────────────┐
│ hello.cure │ Source File
└──────┬───────┘
│
▼
┌──────────────────┐
│ Lexer │ Tokenization
│ (cure_lexer) │ • Keywords, operators
└──────┬───────────┘ • Position tracking
│
▼
┌──────────────────┐
│ Parser │ AST Generation
│ (cure_parser) │ • Syntax analysis
└──────┬───────────┘ • Error recovery
│
▼
┌──────────────────┐
│ Type Checker │ Type Inference
│(cure_typechecker)│ • Dependent types
│ │ • Constraint solving
│ ┌─────────────┐ │
│ │ Z3 Solver │ │ SMT Verification
│ │ (cure_smt) │ │
│ └─────────────┘ │
└──────┬───────────┘
│
▼
┌──────────────────┐
│ Optimizer │ Type-Directed Opts
│(cure_optimizer) │ • Monomorphization
└──────┬───────────┘ • Inlining
│
▼
┌──────────────────┐
│ Code Generator │ BEAM Bytecode
│ (cure_codegen) │ • Module generation
└──────┬───────────┘ • OTP integration
│
▼
┌──────────────────┐
│ Hello.beam │ Executable
└──────────────────┘
Интеграция Z3
%% Упрощённый пример из cure_guard_smt.erl
verify_guard_completeness(Guards, Type) ->
%% 1. Генерируем SMT формулы
SMTFormulas = lists:map(fun guard_to_smt/1, Guards),
%% 2. Проверяем покрытие
Coverage = z3_check_coverage(SMTFormulas, Type),
%% 3. Ищем пробелы
case Coverage of
complete ->
{ok, verified};
{incomplete, Gap} ->
{error, {missing_case, Gap}};
{overlapping, Cases} ->
{error, {redundant_guards, Cases}}
end.
FSM компиляция
# Исходный FSM
fsm Light do
Red --> |timer| Green
Green --> |timer| Red
end
# Компилируется в gen_statem
-module('Light').
-behaviour(gen_statem).
callback_mode() -> state_functions.
red({call, From}, {event, timer}, Data) ->
{next_state, green, Data, [{reply, From, ok}]}.
green({call, From}, {event, timer}, Data) ->
{next_state, red, Data, [{reply, From, ok}]}.
Для чего Cure вообще не впёрся?
Быстрое прототипирование (используйте Elixir)
Веб-разработка общего назначения (Phoenix отлично справляется)
Скрипты и glue code
Проекты с частыми изменениями требований
Сравнение с другими языками
Фича |
Cure |
Erlang |
Elixir |
Idris/Agda |
|---|---|---|---|---|
Зависимые типы |
✅ |
❌ |
❌ |
✅ |
SMT-верификация |
✅ |
❌ |
❌ |
Частично |
BEAM VM |
✅ |
✅ |
✅ |
❌ |
FSM как примитив |
✅ |
Библиотеки |
Библиотеки |
❌ |
OTP совместимость |
✅ |
✅ |
✅ |
❌ |
Production ready |
? |
✅ |
✅ |
Исследования |
Кривая обучения |
Высокая |
Средняя |
Низкая |
Очень высокая |
Философия проекта
Cure не пытается заменить Erlang или Elixir. Это специализированный инструмент для задач, где:
Корректность > Скорость разработки
Математические доказательства > Unit тесты
Compile-time гарантии > Runtime проверки
There are two ways of constructing a software design: One way is to make it so simple that there are obviously no deficiencies, and the other way is to make it so complicated that there are no obvious deficiencies. — Тони Хоар
Roadmap и будущее
Краткосрочные планы (2025–2026)
[ ]Typeclasses/Traits — полиморфные интерфейсы[ ]CLI SMT integration — Z3 прямо из командной строки[ ]Улучшение LSP — code completion, refactoring[ ]Расширение stdlib — больше утилитарных функций
Среднесрочные (2026)
[?]Effect system — трекинг эффектов как в Koka[ ]Package manager — управление зависимостями[ ]Distributed FSMs — верифицируемые распределённые автоматы[ ]Gradual typing — совместимость с динамическим Erlang[?]Macro system — compile-time метапрограммирование
Долгосрочное видение
Cure стремится стать языком выбора для критичных систем на BEAM:
Формальные методы становятся mainstream — не нишей для академиков, а стандартом индустрии
Математические гарантии на BEAM — reliability Erlang + correctness Cure
Инструментарий верификации — как сегодня unit тесты, завтра SMT-проверки
Ресурсы и ссылки
Документация
Полуофициальная документация:
/docsв репозиторииСпецификация языка:
docs/LANGUAGE_SPEC.mdРуководство по типам:
docs/TYPE_SYSTEM.mdFSM:
docs/FSM_USAGE.mdСтандартная библиотека:
docs/STD_SUMMARY.md
Примеры кода
Базовые примеры:
examples/01_list_basics.cureFSM демо:
examples/06_fsm_traffic_light.cureГарды и pattern matching:
examples/04_pattern_guards.cureЗависимые типы:
examples/dependent_types_demo.cure
Научные основы
(этой книге я обязан существованием языка в принципе) Alessandro Gianola: «SMT-based Safety Verification of Data-Aware Processes»
Z3 Solver: https://github.com/Z3Prover/z3
SMT-LIB Standard: http://smtlib.cs.uiowa.edu/
Idris tutorial: https://docs.idris-lang.org/
P.S. Частые вопросы
Q: Cure production-ready?
A: Компилятор функционален, stdlib работает, но проект молодой. Для критичных систем рекомендуется тщательное тестирование. Версия 1.0 ожидается в 2026.
Q: Нужно ли знать теорию типов?
A: Базовое использование не требует глубоких знаний. Для продвинутых возможностей (зависимые типы, SMT) желательно понимание основ.
Q: Совместим ли с Erlang/Elixir?
A: Да! Cure компилируется в BEAM bytecode и полностью совместим с OTP. Можно вызывать Erlang модули и наоборот.
Q: Почему не расширить Elixir вместо нового языка?
A: Зависимые типы требуют принципиально другой архитектуры компилятора. Добавить их в динамический язык невозможно без потери гарантий.
Q: Как быстро код на Cure?
A: Сопоставимо с Erlang. Оптимизации типов дают 25-60% ускорение. Zero runtime overhead от типов.
Q: Можно ли писать веб на Cure?
A: Возьмите Phoenix, напишите критические куски на Cure и слинкуйте BEAM из Elixir’а. Я сделаю этот процесс прозрачным для mix. В принципе, Cure имеет смысл использовать только для систем, где нужна верификация. Сайтег или приложулька прекрасно обойдутся без него.
Комментарии (60)

mbait
23.11.2025 08:15Наконец-то нормальная статья от вас. В адекватном тоне и без замашек на бога программирования. Завтипы это будущее, неистово одобряю.

cupraer Автор
23.11.2025 08:15В адекватном тоне и без замашек на бога программирования.
Значит, текст ужасен. Надо переписывать.
cupraer Автор
23.11.2025 08:15Завтипы это будущее, неистово одобряю.
Если серьезно, то я не согласен. К великому сожалению.
Критической массы заинтересованных в том, чтобы делать не тяп-ляп, а верифицировать — не честным словом и не одним крылом, — исчезающе мало. Бизнесу это не выгодно, потому что долго. Проще и выгоднее прилечь на полдня, или отправить пару доверчивых владельцев автопилотов сотого поколения — в столб на полной скорости.
Еще это всё слишком сложно. У меня высшее математическое образование, и то я в процессе слишком часто чувствовал себя имбецилом (особенно пока читал Джианолу).
Нет ни заказчика на этот волшебный инструмент, ни исполнителей. Иначе хотя бы Идрис допилили до хоть какого-нибудь состояния, похожего на «готов к продакшену в разумных пределах».

IUIUIUIUIUIUIUI
23.11.2025 08:15Нет ни заказчика на этот волшебный инструмент, ни исполнителей. Иначе хотя бы Идрис допилили до хоть какого-нибудь состояния, похожего на «готов к продакшену в разумных пределах».
Ну там в хаскеле что-то шевелится на тему dependent haskell. Может, придём к готовому к проду завтипизированному языку с хорошим компилятором, просто с другой стороны. Пропозалы крутятся, завтипы мутятся.
Правда, учитывая скорость принятия (маленькую) и скоуп (ещё меньше, по пропозалу на каждую пердюшку в синтаксисе), придём туда мы году к 2050-му, не раньше.
cupraer Автор
23.11.2025 08:15Поэтому я пошел на некоторое количество соглашений с совестью и чувством прекрасного. Я не стремлюсь сделать полностью математически корректно. На границе линковки с другим BEAM-кодом — по-прежнему всё можно сломать, как в похапе.
Но зато я уже сейчас, на полуживом компиляторе, могу генерировать BEAM, которые внутри себя худо-бедно верифицированы. И линковать их снаружи, из больших проектов на эликсире и эрланге. Мне показалось важнее сделать что-то, чем можно пользоваться, и что представляет более внятные гарантии, в сравнении с динамической типизацией стандартной BEAM-машины.

j123123
23.11.2025 08:15Обычные типы говорят: «это целое число». Зависимые типы говорят: «это целое число больше нуля и меньше длины списка».
Возможно я что-то путаю, но по-моему это называется refinement type (Как в Liquid Haskell) a не dependent type
cupraer Автор
23.11.2025 08:15Refinement type — это `type Positive = {i: Int | i > 0}`. Такие есть во всех недоязыках, претендующих на корректную имплементацию типов.
Dependent type — это типы, которые зависят от других типов, например `Vector(T, n)`, где
T— тип, аn— переменная типа, которая может проникать в рантайм:def length(v: Vector(T, n)): Nat = n(пример из стандартной библиотеки: https://github.com/am-kantox/cure-lang/blob/main/lib/std/vector.cure#L14).IUIUIUIUIUIUIUI
23.11.2025 08:15Refinement type — это
type Positive = {i: Int | i > 0}.Плюс движок для работы с refinement'ами, чтобы
Positiveспокойно передавалось в функцию, ожидающуюNonNegative. В этом основной смысл RT — можно сэкономить на доказательствах, которые спокойно дисчарджатся солвером.Такие есть во всех недоязыках, претендующих на корректную имплементацию типов.
Можно весь список плз? Потому что мне известно очень мало таких языков — по большому счёту из более-менее готовых к проду это LH и F*.
Dependent type — это типы, которые зависят от других типов
От других термов.
Зависимость от других типов — это простой параметрический полиморфизм, бастардизированная версия которого есть даже в плюсах.
n— переменная типаВ нормальных завтипизированных языках это обычный терм.
У вас можно считать
nиз файла (или из сети) в рантайме обычной функциейtoNat . readFile, получить вектор соответствующей длины (считав его тоже из файла, илиreplicate : (n : ℕ) → a → Vect n a) и что-то с ним сделать?Так-то в хаскеле тоже есть
DataKinds, но есть некоторые причины, почему он не завтипизированный.переменная типа, которая может проникать в рантайм
В 2025-м ожидаешь, что это можно контролировать. Например, ИМХО самая доступная статья на тему — https://dl.acm.org/doi/pdf/10.1145/3408973
cupraer Автор
23.11.2025 08:15У вас можно считать
nиз файла (или из сети) в рантаймеНет. И я не могу пока понять, зачем.
А вот за это — нечеловеческое спасибо.
Можно весь список плз?
Мы же не первый год знакомы, вы все еще наивно полагаете, что я в публичном пространстве — не умножу любую сущность на миллион?
Плюс движок для работы с refinement'ами […]
Я пока на стадии принятия. Я решил, что мне будет проще (по крайней мере, на первых порах) поддерживать код, в которых
NonNegativeбудет дисчарджиться разработчиком.IUIUIUIUIUIUIUI
23.11.2025 08:15Нет. И я не могу пока понять, зачем.
Считайте это тестом, что
n— действительно обычный терм, а не костыль уровняDataKinds.Я решил, что мне будет проще (по крайней мере, на первых порах) поддерживать код, в которых
NonNegativeбудет дисчарджиться разработчиком.Так а что у вас SMT-то тогда делает? Большая часть практических применений RT сводится к тому, что для использования { ν : T | ρ } там, где ожидается { ν : T | ρ' }, достаточно проверить ρ ⇒ ρ', а это вполне себе решается солверами в значимой части практически полезных применений.
cupraer Автор
23.11.2025 08:15Это костыль, по крайней мере пока, я это понимаю, и живу с этим безмятежно.
Так а что у вас SMT-то тогда делает?
Проверял FSM преимущественно. Но разница в часовых поясах — несомненное благо, и теперь он инферит типы как положено.
j123123
23.11.2025 08:15И зачем завязываться на SMT-солверы? Может быть какие-то вещи они доказать не осилят, и придется доказывать на
CoqRocq или чем-то подобном? Насколько я помню, Frama-C переводит свои ASCL-контракты в WhyML, и там он может быть оттранслирован в кучу разных автоматических и интерактивных пруверов https://www.why3.org/#provers. Может быть вам тоже стоит использовать такой подход?
redbeardster
23.11.2025 08:15Ну так WhyML далеко не всесилен и может разве что тактики подобрать, полное доказательство - это уже вручную. А Z3/CVC - хорошо, много лучше, чем ничего, но не идеал. Но идея, конечно, хорошая. Правда, если кому-то реально нужно, возьмет Lean4 с завтипами и HoTT(вроде бы) + будет иметь уже готовый к пуску бинарь. А Frama очень многого не поймет в простом сишном коде, афаир, уж проще сразу Isabelle/C или Autocorres :)
cupraer Автор
23.11.2025 08:15Какой еще бинарь? Нахрена мне бинарь? Что непонятного в постановке задачи:
компилироваться в BEAM и прозрачно линковаться с эрлангом, эликсиром, глимом и даже лфе
Я понимаю, что вы, наверное, погуглили ключевые слова, чтобы выглядеть поумнее, но я впервые слышу о том, что Lean4 способен верифицировать FSM, а при чем тут HoTT — вообще загадка.
redbeardster
23.11.2025 08:15Нет, не гуглю, вполне себе юзаю. Речь о другом, но объяснять не буду - многовато чести

lgorSL
23.11.2025 08:15Ну кстати возможно, что было бы интересно не только байткод для BEAM поддерживать, а иметь несколько таргетов (возможно, в виде простой генерации кода для Java/C++), потому что в программе вполне часто получается, что есть и какой-то стрёмный код который трогать не хочется, и какая-нибудь подсистема, которую наоборот хочется сделать максимально строгой и верифицируемой.
P.S. Прекрасно вас пойму, если будете поддерживать только BEAM, потому что много таргетов поддерживать сложнее.
cupraer Автор
23.11.2025 08:15Не получится, придётся всё, что за парсером и тайп-чекером — с нуля переписать. Да даже тайп-чекер: уже неясно, как реализовывать для нескольких голов функции, например. Но это бы и ладно.
Генерация кода — тупиковый путь, у меня не случайно свой компилятор: сгенерированный байт-код уже не подвергнется насилию со стороны умного компилятора, а код — запросто, и я навскидку не могу сказать, не испортит ли это гарантии (кажется, что не должно, но доказать за минутку я не умею).
Можно было бы подумать про генерацию AST, но Java/C++ — не умеют на уровне языка работать с AST.
А самое главное — передо мной совершенно другая задача: у меня есть экосистема, в которой меня устраивает всё, кроме отсутствия верификации. Акторную модель мне с собой предлагаете нести в C++? Работать с Akka в Java — ну ёлки, это вообще сторонняя библиотека.
Я не хочу захватить мир, я хочу облегчить жизнь себе и тем людям, которые выбрали отказоустойчивость, параллелизм и горизонтальное масштабирование из коробки.


Dhwtj
23.11.2025 08:15Мне бы хватило такого если б заморочился на раст написать макрос
refinement_type! { PositiveUsize(u64) where |x| x > 0, "must be positive" }Который разворачивался бы до
#[derive(Debug, Clone, Copy, PartialEq, Eq)] pub struct PositiveUsize(pub u64); #[derive(Debug)] pub struct PositiveUsizeError(pub &'static str); impl std::fmt::Display for PositiveUsizeError { fn fmt(&self, f: &mut std::fmt::Formatter<'_>) -> std::fmt::Result { write!(f, "{}", self.0) } } impl std::error::Error for PositiveUsizeError {} impl PositiveUsize { pub fn new(value: u64) -> Result<Self, PositiveUsizeError> { if value > 0 { Ok(PositiveUsize(value)) } else { Err(PositiveUsizeError("must be positive")) } } pub fn get(&self) -> u64 { self.0 } pub fn into_inner(self) -> u64 { self.0 } }А дальше что-то вроде From для проброса ошибок куда-то наверх типа контроллера. Вручную, но не сложно
cupraer Автор
23.11.2025 08:15def length(_v: Vector(T, n)): Nat = nгораздо нужнее.Dhwtj
23.11.2025 08:15struct Vector<T, const N: usize> { data: [T; N], }Или
impl<T, const N: usize> Vector<T, N> { pub const fn length(&self) -> usize { N } }Но только если число известно на стадии компиляции
Что-то сложнее только в рантайм
Арифметика complile time выглядела бы так
fn append<T, const N1: usize, const N2: usize>( a: Vector<T, N1>, b: Vector<T, N2>, ) -> Vector<T, { N1 + N2 }> // ← пока НЕ поддерживается в стабильном Rust
MasterMentor
За попытку +.
По делу:
1.
Зачем было делать "костыли из палок", когда 50% статей на Хабре выражает призыв не делать костылей, + плач Ярославны (Иеремии в девичестве) что массовый IT - это сфера костылестроения.
2
Хэлоуворд
record TrafficLight do
cycles: Int
emergency_stops: Int
end
fsm TrafficLight{cycles: 0, emergency_stops: 0} do
Red --> |timer| Green
Green --> |timer| Yellow
Yellow --> |timer| Red
Green --> |emergency| Red
Yellow --> |emergency| Red
end
Ставший порочной традицией пример с хэлоувордом на новом языке не убеждает, а вызывает непонимание и недоверие.
FSM - это идея, правда описанная на языке математики, как оформлять объекты, чьё пространство состояний заранее определено (известно).
Вы берёте объект из двух элементарных множеств "cycles" и " emergency_stops" задаёте на нём функцию переходов отношением (ака "таблицей" сопоставлений, говоря по-народному).
Но даже в простых реальных задачах функция переходов задана составными математическими функциями. И хэлоувордные примеры имеют к ним то же отношение, что программа выводящая известную строку к реальной программе на языке программирования.
Пример. Сейчас дабы позабавиться и поучиться оформляем набором конечных автоматов игру. В тетрисном "стакане", вместо фигургок падает квадрат с игрой крестики-нолики. При проигрыше он падает вниз и складывается вниз "как песок", при выигрыше игрок может "вычеркнуть" любую строку квадратиков с дна стакана.
Очевидно, что уже в этом достаточно простом учебном примере пространство состояний объекта гораздо сложнее хэлоувордного. А функция переключения состояния при падении квадрата - отнюдь не похожа на отношение, заданное вручную над двумя элементарными множествами из 2-х и 3-х элементов. (пикантности добавляет и отображение геометрических множеств в алгебраические/элементарные - и обратно).
Вопросы: как Cure справляется с просчётом таких пространств состояний? чем Cure может помочь при алгоритмическом оформлении клсса подобных задач? (фактически все "клеточные" игры: тетрисы, минёры, питоны, бомберы, итп.)
cupraer Автор
Спасибо, век такой доброты не забуду.
Потому что на неверифицируемых языках иначе не получится.
Я не читаю Хабр, я читаю профессиональные форумы.
Бывает. Я не ставил перед собой цель убедить, и, тем паче, завоевать доверие.
Конечно. В тексте есть ссылка на сложный пример с обработчиками переходов.
Никак. Cure делегирует это SMT-солверу (Z3 по умолчанию). Об этом написано в тексте выше. Как справляется Z3? — Да неплохо, вроде.
Там в тексте есть ссылки на математическое обоснование. Пересказывать курс теорката и диссер Алессандро Джианолы я тут не планировал. Если вкратце — вместо вашего велосипеда из палок, Cure поможет сделать настоящий верифицированный конечный автомат.
Tzimie
А если я напишу программу, которая будет в цикле для всех целых применять шаги последовательности коллаца, то солвер докажет, что это всегда придет к последовательности 1-2-4-1... ?)))
cupraer Автор
Нет, отвалится по таймауту и сообщит о нетотальности вашей функции. Нетотальные функции априори не годятся в качестве инструмента построения прикладного ПО.
Заметьте, я серьёзно ответил на ваши неудачные потуги сострить.
Tzimie
Это не потуги, а намек на то что проблема останова (то есть достижения любого состояния) является классической алгоритмически неразрешимой проблемой, соответственно весь путь тупиковый - будет работать только на игрушечных примерах
cupraer Автор
Это облыжный вывод. Хотя бы потому, что тогда в принципе программирование — будет работать только на игрушечных примерах.
Cure пока не умеет выводить тотальность, но научится. На идрисе (как я говорил в тексте) я годами проектировал критические части далеко не игрушечных примеров.
Если ножом можно зарезать человека, это не значит, что ножи нужно изъять из обращения, или что они бесполезны. По такой логике в первую голову бесполезны тесты, потому что не существует гарантий полного покрытия (даже с мутациями и property-based тестированием).
JuPk
Можете рассказать подробнее какого рода проектирование вы делали на идрисе? И собственно почему там была важна формальная верификация.
Язык (идрис) вообще классный, вот только развивается очень медленно. Искренне надеюсь что ваш проект будет развиваться быстрее.
cupraer Автор
Да любого; триггернулось что-нибудь для клиета — у него должно особенным образом измениться состояние трех счетов и пятнадцати правил, но так, чтобы всё осталось консистентным.
Прям совсем подробности не могу, наверное, да и не очень нужно, надеюсь, смысл понятен.
Нужно это было потому, что цена вопроса измерялась миллионами.
vanxant
Да нет, конечно. В системах с конечной памятью (т.е. на всех реальных) проблема останова отсутствует.
cupraer Автор
Проблема останова отсутствует, проблема тотальности функций (завершения за конечное время) — нет. Я так понял, речь про второе.
IUIUIUIUIUIUIUI
Если к системам с конечной памятью относиться не как к реальным реализациям идеализированной бесконечной МТ, то на этих системах даже коммутативность сложения на ℕ не докажешь, потому что непонятно, терм
тотален «потому», что он логически консистентен и действительно выражает известное утверждение о ℕ, или же потому, что на данной конкретной машине просто тупо перебрали все влезающие в память натуральные числа, и утверждение это, соответственно, не о всех натуральных числах, а о числах меньше данного.
Зачем такое нужно, непонятно.
Правда, зачем называть обёртку над SMT прувером и ставить её в один ряд с завтипами, тоже непонятно, но это уже вопрос ОПу. Среди других вопросов ОПу: @cupraer, типобезопасный printf на вашей версии завтипов пишется? Какой положняк по экстенсиональности и всяким другим умным словам?
cupraer Автор
Я вроде не называл SMT прувером, я использовал слово «солвер». Завтипы — завтипами, солвер — солвером. Я не стремился поставить их в один ряд, скромно через запятую.
Нет. И я не уверен, «пока нет», или «вообще нет». Я практик, и я вынужден признать, что основы математики слишком сильно подзабыл, или просто отупел с годами (хотя был бы очень рад подсказкам, советам и критике). На данном этапе мне проще полностью отказаться от эффектов и IO. Сейчас
printсуществует только ради отладки, в дальнейшем я пока планирую его выкинуть и добавить отсылку сообщения (акторная модель же).Цель этого языка существенно отличается от академических (я где-то на эрланг-форуме даже написал, что мой девиз — «succeed at any cost»). Я решал свою задачу: кусок кода, подсистема, которая компилируется в BEAM, и которую можно легко и прозрачно слинковать снаружи хоть из эликсира, хоть из глима, хоть из лфе. хоть из эрланга.
У меня даже есть
curifyфункция, которая возьмет код на эрланге и скажет тайп-чекеру: тут чувак знает, что делает, типы вот такие, отстань.IUIUIUIUIUIUIUI
Тут дело не в IO (считайте, что это sprintf, а не printf), а в том, что в полноценных завтипах вы можете написать функцию вроде
и потом
после чего, скажем, у
printf "Age: %d, weight: %f"будет типInt → Float → Stringcupraer Автор
А, в этом смысле. Нет.
Меня Брэди покорил именно этим примеров в своей книжке, но я до сих пор не понимаю, зачем оно нужно в реальной жизни.
У меня на балконе растет гранат и перец, а не роза. Я никогда не сталкивался с примерами, когда оно действительно нужно. Но у меня кругозор — так себе.
IUIUIUIUIUIUIUI
Один из вариантов — таки типобезопасный printf. Вон, плюсисты нетривиально приседают, чтобы в std::fmt (или как его там, не игрался на практике с этой частью новых плюсов) известные в компилтайме строки позволяли проверять типы аргументов. В шланге и gcc добавили проверки (и аннотации для кастомных строк), чтобы проверять соответствие строки формата аргументам у обычного сишного printf. Наверное, это нужно.
Другой вариант из личной практики, когда я по фану делал на идрисе обёртку вокруг постгреса — можно описать структуру таблицы обычным языком термов, и потом обычными функциями
Schema → Typeсоздать что тип, значения которого соответствуют схеме, что все эти обёртки над create table / insert / update / etc.В мейнстримных языках для этого обмазываются какой-нибудь рефлексией, и всё даёт нечитаемые ошибки и разваливается (в рантайме, если рефлексия — рантайм).
cupraer Автор
Вы все время забываете (намеренно игнорируете) то, что я не хочу построить язык общего назначения. Можно сказать, что добавляю «верификационный сахар» в существующие и использующиеся эликсир/эрланг.
Я сознательно не хочу реализовывать всё правильно, «как надо». Во-первых, я не смогу, мне не хватит остатков образования. Во-вторых, мне нужен рабочий прототип вчера, а не план на 2037.
У меня в эликсире есть очень хорошие макросы, если мне втемяшится сделать что-то похожее, я нагенерирую весь этот код в процессе компиляции, с правильными рантайм-проверками с адекватными сообщениями (или компайл-тайм проверками, если надо, обернув каждый терм в структуру, которую умеет понимать компилятор).
Конкретно этот тип доказательного програмирования я при этом считаю бессмысленным. А в языке, который я пишу (надеюсь, пока) в одно рыло, — мой голос сука решающий.
vanxant
Да какое нафиг
ℕна машинах с конечной памятью, о чём вы? Речь может идти только о кольце остатков по модулю (Zm), а в этом случае всё хорошо доказывается.IUIUIUIUIUIUIUI
Обычное ℕ. На машинах с конечной памятью (и в тетрадках с конечным числом листов) вы вполне себе можете доказывать вещи про бесконечный ℕ.
И это на самом деле полезно, потому что как-то очень глупо перепроверять все доказательства и ждать 2^100500 времени после того, как вы просто купили железку с памятью чутка побольше.
IUIUIUIUIUIUIUI
И, кстати, совсем забыл: там ещё доказывается, что ∃ n. n + 1 = 0, что неверно для натуральных чисел. Поэтому, короче, это очень вредная модель.
vanxant
Да нет, модель как раз крайне полезная. Примерно всё вокруг вас посчитано с её помощью.
А вот где на практике нужна мощность натуральных чисел за пределами Zm с технически доступным модулем — я представить не могу.
IUIUIUIUIUIUIUI
Я на всякий случай уточню: вы правда не понимаете, что доказательства могут быть не только про тот диапазон чисел, чем я считаю сдачу в магазине?
Проверка тотальности через прямой перебор состояний не доступна ни для какого полезного на практике в более чем полутора приложениях m.
cupraer Автор
Булевы значения вышли из чата.
vanxant
Ну для начала, на практике всё-таки обычно программисты работают с частично-рекурсивными функциями, и при нормально написанных предусловиях контракта (автор для этого пытается использовать завтипы, но это не единственный способ) полный перебор 2^64 комбинаций каждого параметра — это немножко overkill.
Во-вторых, арифметика остатков примерно такая же, как и арифметика натуральных чисел. Там есть свои тонкости с целочисленным переполнением, например, или с кривым делением на 0 в х86, но в целом — примерно такая же по сложности с точки зрения автоматического доказательства теорем.
Tzimie
Теоретически - да. Практически - разницы нет, пара вложенных циклов по bigint уже превышает время жизни вселенной на порядки
vanxant
Так задача вроде не выполнить цикл, а доказать, что он не выполнится.
Просто как бы куча различных линтеров и компиляторов именно этим и занимаются, в т.ч. умеют детектировать бесконечные циклы
Tzimie
Только в общем виде эта задача не решается
vanxant
В реальности всё не так, как на самом деле © В смысле на практике всё лучше, чем в теории.
IUIUIUIUIUIUIUI
Имея и ложноположительные, и, что хуже, ложноотрицательные срабатывания.
j123123
Зачем коллаца? Рассмотрим какую-нибудь сортировку. Вот например такая реализация на Haskell:
Такой код может быть переписан на STMLib относительно легко
Вроде всё корректно. Тут я для примера сортирую список 9 2 4 1 3 5 7 8 6 0. Можно запустить это в Z3 и он действительно сортирует, только он не сможет доказать, что такая сортировка работает для общего случая. Для проверки сортировки тут требуется функция для проверки упорядоченности (для любых двух соседних элементов
a, bдолжно быть верно, чтоa <= b) и что массив после сортировки является перестановкой изначального массива, и что для любых списков любой длины эти оба условия выполняются. Если так сделать, Z3 просто зависнет или отвалится по таймауту. Такое надо через Rocq, Idris, Agda и прочие proof assistant доказыватьcupraer Автор
Я пока поеду, а вы ждите на обочине под Саровом в три часа ночи — мерседес с шашечками.
kulity
Это, например, какие?
cupraer Автор
https://erlangforums.com/, https://elixirforum.com/, https://devtalk.com/, и типа того.
whoisking
Для не-хеллоуворлдов есть HSM/statecharts
cupraer Автор
HSM — это избыточный формализм. Кроме того, если даже предположить, что он зачем-то нужен, его тоже придется реализовывать.