
Представьте себе такую картину: пятничным вечером вы нажимаете кнопку воспроизведения видео на Netflix. Не проходит и нескольких секунд, как в ответ на это в недрах системы оживают сотни контейнеров. Обеспечение эффективной работы большого количества контейнеров в Netflix — это один из краеугольных камней обеспечения качественного потокового видео для миллионов пользователей со всего мира. Для того чтобы обеспечить высокую скорость реакции системы таких масштабов, мы модернизировали нашу среду выполнения контейнеров (контейнерный рантайм, container runtime), но, сделав это, мы столкнулись с неприятной неожиданностью, сдерживающей рост нашей системы. Это — архитектура процессоров.

Предлагаем вашему вниманию историю о том, как мы диагностировали эту проблему, и о том, что мы узнали о масштабировании контейнеров на аппаратном уровне.
Проявления проблемы
Когда приложение нуждается в том, чтобы мы увеличили наши серверные мощности — мы получаем новый экземпляр (инстанс, instance) сервера от AWS. Для эффективного использования новых ресурсов поды (pod) назначаются вычислительному узлу кластера (node) до тех пор, пока его ресурсы не будут признаны полностью распределёнными между потребителями. Уровень нагрузки узла может меняться от состояния, когда на узле вообще не выполняется никаких приложений, до состояния полной загруженности. Причём, приложения могут полностью исчерпать ресурсы узла буквально через мгновения после того, как он будет готов им эти ресурсы предоставить.
По мере того, как завершалась миграция со старой платформы поддержки контейнеров на новую, мы начали сталкиваться с кое-какими тревожными тенденциями. Некоторые узлы надолго подвисали, пребывая в таком состоянии, когда на них не работала даже обычная проверка работоспособности системы (health check), которая завершалась по тайм-ауту через 30 секунд. Первоначальное расследование этих инцидентов показало, что в подобных ситуациях очень сильно растёт размер таблицы монтирования (mount table), и только на то, чтобы прочитать эту таблицу, может уйти более 30 секунд. После анализа стека systemd стало ясно, что система, кроме того, была занята обработкой соответствующих событий монтирования, что и могло привести к её блокировке. В этот период основной агент Kubernetes — Kubelet тоже часто попадал под тайм-аут. У него не хватало времени на то, чтобы нормально взаимодействовать с containerd. Исследование таблицы монтирования сделало очевидным тот факт, что результаты операций монтирования, отражённые в ней, имеют отношение к созданию контейнеров.
Практически все узлы, которые затронула эта проблема, были представлена инстансами r5.metal. Они отвечали за выполнение приложений, образы контейнеров которых содержали множество (более 50) слоёв.
Суть проблемы
Состязания за блокировки монтирования
Флеймграф (flamegraph) (рис. 1) чётко демонстрирует задачи, на выполнение которых тратит время containerd. А именно — почти всё время уходит на попытки получения блокировки уровня ядра, относящейся к различным операциям, связанным с монтированием, выполняемым при сборке корневой файловой системы контейнера (rootfs)!

Видно, что демон containerd, если применяются пользовательские пространства имён, выполняет для каждого из слоёв образа следующие вызовы:
Вызов
open_tree()для получения ссылки на слой / директорию.Вызов
mount_setattr()для установки idmap в соответствии с диапазоном идентификаторов пользователей контейнера. Тут осуществляется перенос прав на владение файлами, в результате чего контейнер получает доступ к файлам.Вызов
move_mount()для создания bind-монтирования (bind mount) на хосте с применением новых данных idmap.
Владельцами bind-монтирований являются пользователи, входящие в диапазон идентификаторов пользователей контейнера. Эти монтирования потом используются в роли нижних каталогов (lowerdir) для создания корневых файловых систем для контейнера, основанных на файловой система OverlayFS. После того, как корневая файловая система, основанная на OverlayFS, смонтирована, bind-монтирования размонтируются, так как они уже не нужны.
Если узел одновременно запускает множество контейнеров — CPU оказывается завален работой по выполнению команд монтирования и размонтирования файловых систем. Виртуальная файловая система (VFS, Virtual File System) ядра имеет несколько глобальных блокировок, имеющих отношение к таблице монтирования. Для выполнения каждой из операций, связанных с монтированием, необходимо захватить соответствующую блокировку, что хорошо видно в верхней части вышеприведённого флеймграфа. Связанным с этим проблемам подвержены любые системы, пытающиеся быстро настроить множество контейнеров. Число блокировок, которые нужно захватить, а значит — и масштаб проблемы, зависит от количества слоёв образа контейнера.
Рассмотрим пример. Предположим — узел запускает 100 контейнеров, образ каждого из которых содержит 50 слоёв. Каждому контейнеру понадобится 50 bind-монтирований, чтобы настроить idmap для всех своих слоёв. Далее, с использованием этих bind-монтирований в роли нижних каталогов, будут созданы точки монтирования файловой системы OverlayFS контейнера. А затем, с помощью umount, могут быть уничтожены все 50 привязок монтирования. Демон containerd, на самом деле, дважды выполняет эту последовательность действий. Первый раз — для определения некоторой пользовательской информации в образе, а второй раз — для создания реальной rootfs. Это значит, что общее количество операций монтирования при запуске 100 контейнеров будет следующим: 100 2 (1 + 50 + 50) = 20200. И все эти операции требуют захвата тех или иных глобальных блокировок, связанных с операциями монтирования файловых систем!
Диагностика системы
Чем новый рантайм отличается от старого?
Как уже было сказано, Netflix выполняет модернизацию среды выполнения контейнеров, используемую в компании. В прошлом для этого использовалась решение, представляющее собой комбинацию Virtual Kubelet и Docker. А сейчас применяется система, основанная на Kubelet и containerd. И старая, и новая среды выполнения контейнеров используют пользовательские пространства имён, но при этом между ними имеются определённые различия.
Старый рантайм. Все контейнеры использовали единственный диапазон идентификаторов пользователей хоста. Перенос прав на владение файлами в слоях образа осуществлялся на этапе распаковки данных, в результате права соответствовали действительности при обращениях контейнеров к файлам. Эта система работала благодаря тому, что все контейнеры использовали одного и того же пользователя хоста.
Новый рантайм. Каждому контейнеру предоставляется уникальный диапазон идентификаторов пользователей хоста, что улучшает безопасность системы. Если контейнер «сбежит» — он сможет воздействовать только на собственные файлы. Для того чтобы избежать ресурсоёмкого процесса распаковки данных и переноса прав для каждого контейнера, новый рантайм использует механизм ядра idmap. Это позволяет осуществлять эффективное сопоставление идентификаторов пользователей (UID) для каждого из контейнеров, не прибегая к копированию или изменению сведений о владельцах файлов, что является причиной того, почему
containerdвыполняет так много операций монтирования.
На рис. 2 показан упрощённый пример того, как работает механизм idmap.

Почему важен тип экземпляра сервера?
Как уже было сказано, проблема, в основном, возникала на инстансах r5.metal. После того, как мы добрались до корня проблемы, мы легко смогли её воспроизвести, создавая образ контейнера с множеством слоёв и отправляя на тестовый узел сотни заданий, использующих этот образ.
Для того чтобы лучше разобраться с тем, почему проблема проявляется на одних инстансах сильнее, чем на других, мы замерили скорость запуска контейнеров на инстансах AWS разных типов:
r5.metal (Процессор Intel 5-го поколения, два сокета, несколько доменов NUMA)
m7i.metal-24xl (Процессор Intel 7-го поколения, один сокет, один домен NUMA)
m7a.24xlarge (Процессор AMD 7-го поколения, один сокет, один домен NUMA)
Базовые результаты
На рис. 3 показаны базовые результаты измерения показателей инстансов разных типов при запуске различного количества контейнеров.

Когда контейнеров не очень много (20 и менее) — все платформы ведут себя примерно одинаково.
По мере того, как растёт конкуренция за ресурсы, инстанс r5 начинает давать сбои на уровне примерно в 100 контейнеров.
Инстансы AWS, в которых используются процессоры Intel 7-го поколения, поддерживали более низкое время запуска контейнеров и более высокий уровень успешных запусков по мере роста конкуренции за ресурсы.
Инстансы m7a показали самое стабильное поведение. Они, кроме того, даже при высоких уровнях нагрузки, давали, в сравнении с другими платформами, более низкий процент отказов.
Углублённый анализ проблемы
Используя инструмент perf record и наши собственные микробенчмарки, мы смогли обнаружить самый нагруженный участок кода. Он находился в реализации VFS ядра Linux, а именно — в коде разрешения путей. В частности, речь идёт о компактном цикле в path_init(), где система активно ожидает освобождения последовательной блокировки (sequence lock). Процессор тратит большую часть времени, выполняя инструкцию pause. Это указывает на то, что множество потоков бездействуют, ожидая освобождения глобальной блокировки, как показано в следующем фрагменте кода:
path_init():
…
mov mount_lock,%eax
test $0x1,%al
je 7c
pause
…Мы, воспользовавшись методологией Intel Topdown Microarchitecture Analysis (TMA), выяснили следующее:
95,5% слотов конвейера простаивали в операциях доступа к данным в условиях конкуренции за ресурсы (tma_contested_accesses).
57% слотов занимали ложные операции совместного доступа к данным (несколько ядер одновременно обращается к одной и той же строке кэша).
Основными причинами проблем стали миграции строк кэша (cache line bouncing) и состязания за блокировки (lock contention).
Система много времени проводила в условиях состязательного доступа к данным. Поэтому мы, глядя на проблему с точки зрения аппаратных различий инстансов, пришли к мысли о необходимости исследования воздействия на происходящее технологий NUMA и Hyper-Threading.
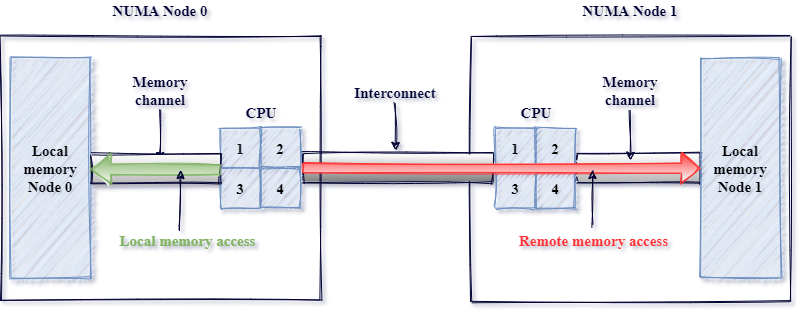
Воздействие NUMA
NUMA (Non-Uniform Memory Access, неоднородный доступ к памяти) — это такой подход к проектированию вычислительных систем, когда у каждого процессора имеется собственная быстрая локальная память, а для доступа к памяти, закреплённой за другими процессорами, используются специальные линии связи. Технология NUMA появилась в 1990-х годах. Она была рассчитана на улучшение масштабируемости многопроцессорных систем. Применение NUMA, с одной стороны, привело к повышению производительности компьютеров, а с другой — к росту задержек в ситуациях, когда одному процессору нужно обратиться к памяти, закреплённой за другим процессором. На рис. 4 показана упрощённая схема, демонстрирующая работу процессоров с собственной памятью и с памятью других процессоров.
")
{kind=link}
Инстансы AWS бывают очень разными. Мы, чтобы получить в своё распоряжение как можно большее количество ядер, протестировали двухсокетные инстансы, дающие прямой доступ к вычислительным ресурсам, обладающие процессорами Intel 5-го поколения (r5.metal). За оркестрацию контейнеров на них отвечал агент Titus. В современных двухсокетных серверах реализована система NUMA, что даёт ускоренный доступ к локальной памяти, но при этом ведёт к увеличение задержек при работе с удалённой памятью. Система оркестрации контейнеров может обеспечивать преимущественное использование локальной памяти. Но работа с глобальными блокировками легко может привести к значительному росту задержек из-за синхронизации удалённых и локальных данных. Для проверки того, как NUMA воздействует на наши системы, мы провели сравнительное тестирование инстанса AWS 48xl (два узла или сокета NUMA) и инстанса AWS 24xl (один узел NUMA). Как можно видеть на рис. 5 — необходимость передачи данных между узлами NUMA быстро приводит к повышению задержек, а значит — к сбоям.

Воздействие Hyper-Threading
Отключение технологии Hyper-Threading (HT, гиперпоточность) на инстансе m7i.metal-24xl (Intel) улучшило задержки запуска контейнера на 20-30% (рис. 6), так как гиперпотоки конкурируют друг с другом за совместно используемые ресурсы, ухудшая ситуацию с состязаниями за блокировки. Когда технология HT включена — каждое физическое ядро CPU делится на 2 логических процессора (может обрабатывать два гиперпотока), которые совместно используют большую часть вычислительных ресурсов ядра. Это — кэш-память, исполнительные блоки, ресурсы памяти. Хотя такой ход может увеличить пропускную способность системы для нагрузок, которые не полностью используют ядро, он серьёзно усложняет работу программ, которые интенсивно используют глобальные блокировки. При отключении HT каждый поток выполняется на собственном физическом ядре, что ликвидирует конкуренцию гиперпотоков за ресурсы, используемые совместно. В результате потоки могут быстрее захватывать и освобождать глобальные блокировки. Это снижает остроту состязаний за ресурсы и улучшает задержки при выполнении операций, которые обычно совместно используют базовые ресурсы.

Почему архитектура аппаратного обеспечения — это важно?
Централизованные архитектуры кэш-памяти
В некоторых современных серверных процессорах используются сетчатые (mesh) структуры, соединяющие ядра и сегменты кэша. При таком подходе каждый узел поддерживает когерентность кэша для некоего подмножества адресов памяти. В подобных архитектурах все сеансы обмена данными осуществляются с использованием централизованной структуры, обеспечивающей работу очереди. Такая структура способна за один раз обрабатывать лишь один запрос на доступ к определённому адресу памяти. Когда за глобальную блокировку (вроде блокировки, связанной с операциями монтирования файловых систем) состязаются несколько сущностей, все атомарные операции, нацеленные на использование этой блокировки, проходят через единственную очередь. Это приводит к накоплению запросов, к простоям памяти, к взрывному росту задержек.
В некоторых хорошо известных «сетчатых» архитектурах (рис. 7) эту центральную очередь называют «таблицей запросов» (Table of Requests, TOR). Она может неожиданно стать «узким местом» системы в ситуации, когда множество потоков «сражается» за одну и ту же блокировку. Если у вас когда-нибудь возникал вопрос о том, почему некоторые CPU, как кажется, «берут передышку» в условиях, когда потоки отчаянно друг с другом за что-то соревнуются — знайте, что часто это происходит именно из-за TOR.
")
{kind=link}
Распределённые архитектуры кэш-памяти
В некоторых современных серверных CPU используются распределённые архитектуры, реализованные на основе чиплетов (chiplet) — рис. 8. Здесь несколько CCX (Core Complex, блок, объединяющий несколько ядер и кэш-память), каждый — с собственным кэшем последнего уровня, соединены высокоскоростной межкомпонентной сетью. В таких архитектурах когерентность кэша поддерживается внутри каждого CCX, а за передачу данных между ними отвечает масштабируемая управляющая сеть. В отличие от «сетчатых» архитектур с централизованными структурами-очередями, такой вот распределённый подход разносит «борьбу за ресурсы» по нескольким узлам, что снижает вероятность возникновения серьёзных простоев системы из-за состязаний за блокировки. Те, кому интересны технические подробности о распределённом кэше и чиплетах, могут найти их в общедоступных документах производителей CPU.
")
Ниже приведено сравнение результатов испытаний нашей рабочей нагрузки на инстансе m7i (централизованная архитектура кэша) и на инстансе m7a (распределённая архитектура кэша). Обратите внимание: мы, чтобы обеспечить сравнимость результатов и избежать их ухудшения из-за Hyper-Threading (рис. 6), отключили HT на инстансе m7i. Эксперименты проходили с использованием одинакового количества ядер. В результате на рис. 9 хорошо видна достаточно устойчивая разница в производительности разных инстансов, составляющая примерно 20%.

Результаты микробенчмарков
Для того чтобы доказать выдвинутую выше теорию падения производительности, касающуюся NUMA, HT и микроархитектур процессоров, мы разработали компактный микробенчмарк. Он создаёт заданное количество потоков, которые состязаются за глобальную блокировку. Запуск бенчмарка со всё возрастающим количеством потоков позволяет выявить особенности возникновения задержек в системе, работающей в условиях разных сценариев использования. Например, на рис. 10 показаны результаты испытаний для различных инстансов с разными настройками NUMA и HT, а так же — с разными микроархитектурами.

Этот синтетический бенчмарк (pause_bench) подтвердил следующие наблюдения:
Отказ от NUMA на инстансе r5.metal (путём использования только одного сокета) значительно снижает задержки при высоком количестве потоков.
Отключение HT на инстансе m7i.metal-24xl ещё сильнее улучшает ситуацию в условиях роста количества потоков.
Лучше всего в деле обработки большого количества потоков показывает себя инстанс m7a.24xlarge. Это указывает на то, что распределённая архитектура кэша в данном случае стабильнее ведёт себя в ситуации, когда потоки конкурируют друг с другом за доступ к строкам кэша.
Улучшение программной архитектуры
Понимание аппаратной архитектуры — это важно для оценки возможных способов смягчения проблем. Но в нашем случае суть проблемы заключается не в архитектуре, а в том, что потоки состязаются за доступ к глобальной блокировке. Мы, взаимодействуя с разработчиками containerd, пришли к двум возможным вариантам решения этой проблемы:
Использование опций монтирования lowerdir+, поддерживаемых более новым API уровня ядра для управления монтированием
fsconfig(). Это позволяет передавать нижние каталоги после применения idmap в виде файловых дескрипторов (fd), а не путей в файловой системе. Такой подход позволяет избежать выполнения вышеупомянутого системного вызоваmove_mount(), которому, чтобы сделать запись о каждом из слоёв в таблице монтирования, требуется захват глобальной блокировки.Сделать мэппинг общего родительского каталога для всех слоёв. Это снизит количество операций монтирования на контейнер с O(n) до O(1), где n — количество слоёв в образе.
Так как применение более нового API требует и использования нового ядра, мы решили реализовать второе решение, что, кроме того, принесёт пользу сообществу. Когда это изменение вступило в силу, мы больше не сталкивались с флеймграфами containerd, самое заметное место в которых занимают операции, имеющие отношение к монтированию файловых систем. На самом деле, как видно на рис. 11, нам, чтобы вообще их разглядеть, даже пришлось их выделить фиолетовым цветом!

Итоги
Переход на современный рантайм, представленный связкой Kubelet и containerd, показал то, как тесно связаны программные и аппаратные части систем, работающих под высокой нагрузкой. Хотя переход на эту связку улучшил безопасность за счёт применения для контейнеров уникальных пользователей, он выявил новые ограничивающие факторы, кроющиеся в архитектурах ядра Linux и CPU. Особенно ярко эти факторы проявляются при параллельном запуске сотен контейнеров, образы которых содержат множество слоёв. Наше расследование указало на то, что не все процессоры одинаково хороши под подобными нагрузками. А именно, централизованный подход к управлению кэш-памятью лишь ухудшил ситуацию с конкуренцией за доступ к кэшу, а распределённый подход позволил системе стабильнее справляться с высокими нагрузками.
В итоге самое лучшее решение проблемы совместило в себе учёт особенностей «железа» с улучшениями программной части системы. Для того чтобы немедленно улучшить ситуацию, мы решили перенаправить соответствующие задания на инстансы с процессорами, архитектуры которых лучше соответствуют нашей нагрузке. Поменяв программную часть системы так, чтобы минимизировать операции монтирования, выполняемые при обработке каждого из слоёв образа, мы избавились от фактора, ухудшающего производительность при запуске системы, снизив её зависимость от глобальной блокировки. Это позволило нам быстрее и надёжнее наращивать мощность системы вне зависимости от архитектуры используемых процессоров. Опыт оптимизации нашей системы подчёркивает важность целостного подхода к проектированию систем с учётом их производительности. Сюда входят понимание и оптимизация как программного стека, так и аппаратного обеспечения, на котором он работает. Это — ключ к качественному обслуживанию пользователей в масштабах Netflix.
Мы уверены в том, что наши находки помогут другим в их путешествии по постоянно развивающейся экосистеме контейнеров, помогут превращать потенциальные проблемы в возможности, ведущие к созданию надёжных и высокопроизводительных платформ.
О, а приходите к нам работать? ? ?
Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
homm
Представил. Безумие чистой воды