
Мы в Netcracker активно деплоим свои приложения в Kubernetes и используем HTTP-пробы для сервисов. Однако, решили провести эксперимент с exec-пробами и… положили на лопатки кластер!
Как так? Ведь именно exec-пробы первыми описываются во всех руководствах и книгах по Kubernetes, включая официальные! Что же не так?
Вот вам свежая информация о граблях, которая может вас уберечь от потенциальных проблем и необдуманных решений. А в конце статьи – что же не так с HTTP-пробами, и зачем мы вообще экспериментировали с exec-ом.

Параметры эксперимента
Наш кластер:
Dev-cluster, используется командами разработки и тестирования. Прод-нагрузки нет, поэтому мы достаточно вольны в том чтобы что-то там попробовать;
Примерно 120 vCPU, 1Tb RAM на worker-нодах;
Примерно 1800 бегущих pod-ов. Каждый использует HTTP-пробы для lieveness/readiness/startup.
Наличие комплекта проб - обязательный стандарт для любого нашего сервиса. Если их нет, то сервис просто будет не допущен даже до внутреннего тестирования.
Средняя нагрузка по кластеру до эксперимента: 45% по CPU, около 50% по RAM. Системные процессы (включая systemd) потребляют около 10% от 1 ядра CPU.
Мы успели обновить примерно 490 сервисов для использования exec-проб, после чего нагрузка дошла до 68% (+23%) по CPU. И продолжала расти по мере раската проб. Потребление CPU на systemd возросло почти до 100%, что сделало кластер неотзывчивым практически для всех задач.
Так что же пошло не так? И почему все пришлось откатить обратно?
Как работает Kubernetes кластер?
Для понимания проблемы совсем коротко остановлюсь на том, а как вообще распределены роли процессов в кластере. Это, конечно, большая отдельная тема, достойная целой серии статей. Если она интересна сообществу – пишите в комментарии.
Нас будут интересовать основные игроки:
Я буду считать, что вы уже удалили docker из своего кластера и перешли на CRI имплементацию от containerd/cri-o, и про docker упоминаний не будет.
Коротко и упрощая, выглядит так:
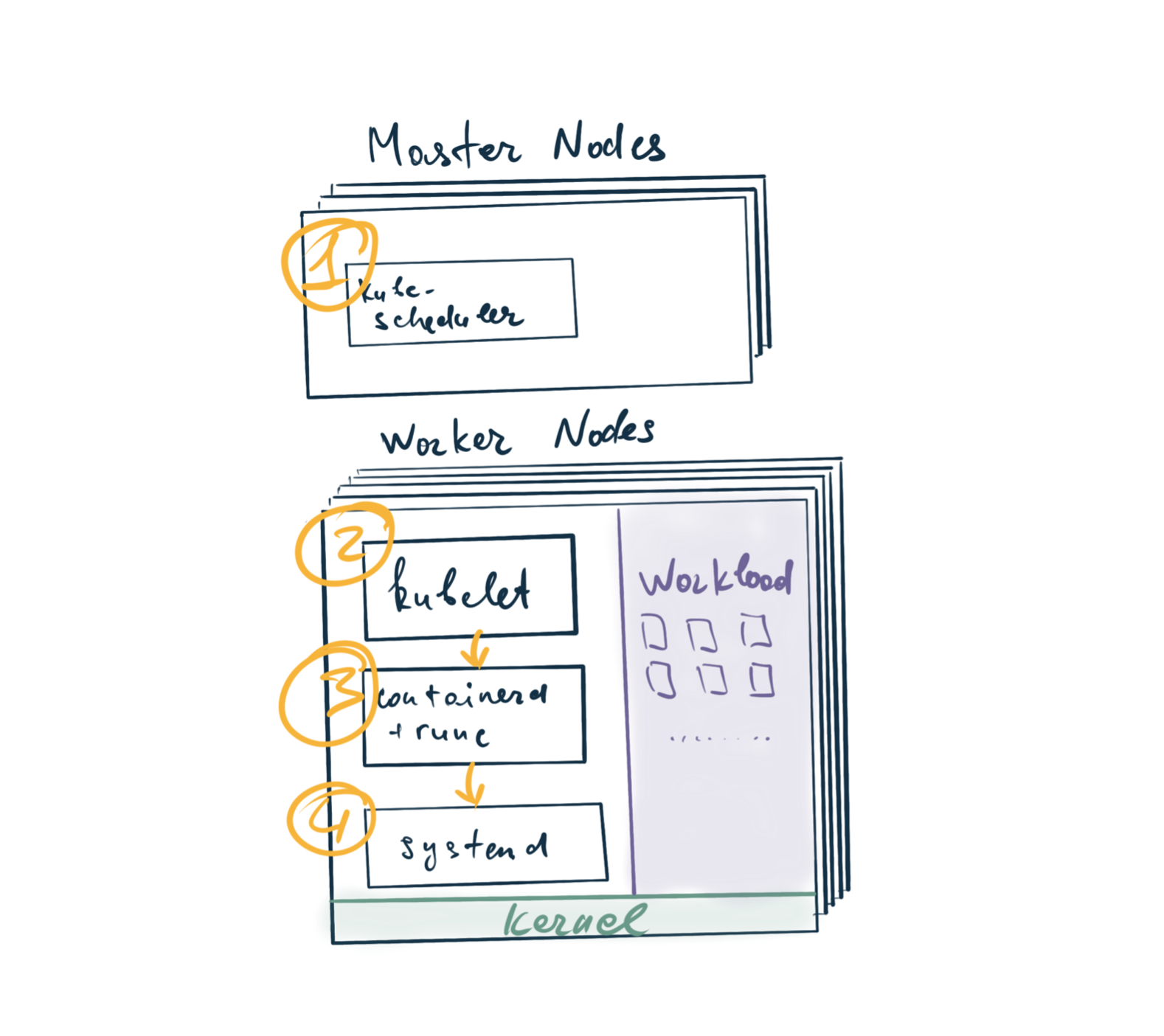
kube-scheduler назначает Pod на ноду. Это эдакий тимлид кластера. Если представить его в роли вашего тимлида, то это тот человек, который назначает поды как баги и истории на членов команды.
kubelet – исполнитель. Он подбирает назначенные ему задачи и исполняет то, что ему назначил kube-scheduler. Однако, он не делает этого сам. Он лишь раздает высокоуровневые указания вида “исполни контейнер” на CRI слой, в качестве которого выступает containerd/cri-o.
containerd/runc занимаются физической загрузкой контейнерных слоев, маунтом их друг на друга и прочей системщиной. Но тоже делают это не сами.
systemd же, наконец, исполняет все системные вызовы и выполняет низкоуровневые пожелания всех вышестоящих господ.
Как работает HTTP проба
HTTP проба работает до безобразия просто:

Код HTTP пробы находится в pkg/probe/http/http.go:91 и буквально делает следующее:
Подключается к pod-у по внутреннему адресу;
Запрашивает указанную страничку;
Определяет результат на основе HTTP-кода ответа.
В сокращенном виде это выглядит как-то так:
func DoHTTPProbe(url *url.URL, headers http.Header, client GetHTTPInterface) (probe.Result, string, error) {
req, err := http.NewRequest("GET", url.String(), nil)
res, err := client.Do(req)
b, err := utilio.ReadAtMost(res.Body, maxRespBodyLength)
body := string(b)
if res.StatusCode >= http.StatusOK && res.StatusCode < http.StatusBadRequest {
if res.StatusCode >= http.StatusMultipleChoices { // Redirect
return probe.Warning, body, nil
}
return probe.Success, body, nil
}
return probe.Failure, fmt.Sprintf("HTTP probe failed with statuscode: %d", res.StatusCode), nil
}
Как видите, все действительно очень просто и прямолинейно.
Некоторую проблему представляет последняя строчка. Но об этом позже. Сейчас нас интересует то, что это простой, понятный и легковесный запрос, не несущий никаких значимых оверхедов и вполне пригодный для применения в любых объемах.
Как работает exec проба?
А вот тут все гораздо сложнее, интереснее и многослойнее:
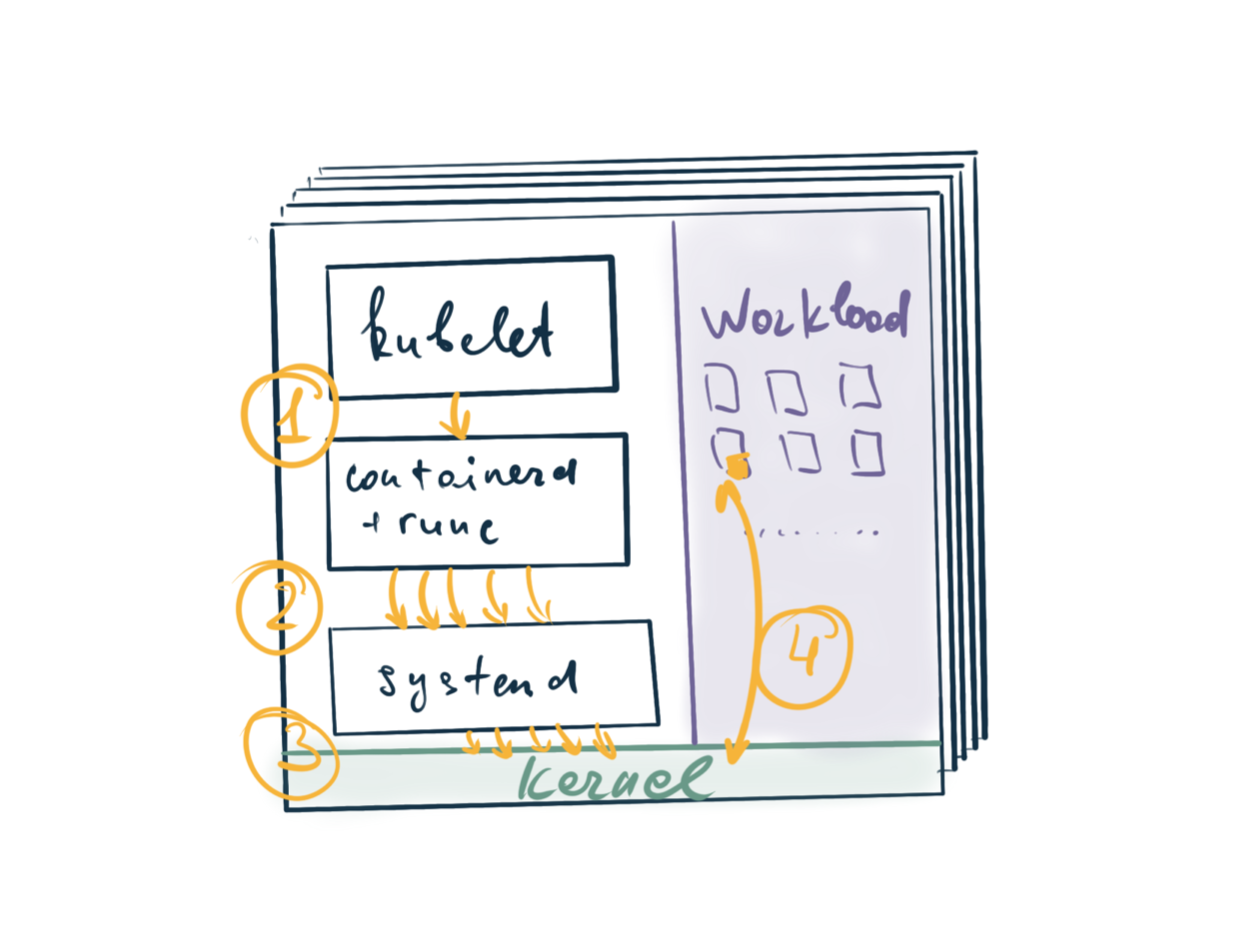
Kubelet выдает задачу на исполнение команды в рамках уже существующего pod sandbox’а на нижележащий слой CRI - pkg/kubelet/prober/prober.go#L160.
Containerd производит целую серию взаимодействий с нижестоящими слоями, включающую в себя поиск активного sandbox’a, аттач к сендбоксу, аллокация там команды, буферов ввода-вывода, осуществление исполнения и последующий cleanup. Все вместе это дает примерно 5-7 вызовов на нижележащие слои и описано где-то примерно тут: pkg/cri/server/container_execsync.go#L196-L211
Systemd все это исполняет, транслируя в вызовы ядра Linux.
Ядро исполняет все что сказали товарищи выше по стеку и отдает результаты обратно.
Таким образом, по сравнению с простой и примитивной HTTP пробой, исполняющей всего лишь один запрос, при exec-пробе выполняется целый ансамбль действий на уровне systemd и ядра.
К чему это привело?
Простая математика привела к следующему:
490 проб, исполняющиеся каждые 3 секунды, каждая включает в среднем 7 systemd вызовов => 1 143 вызовов systemd в секунду на кластер;
Для кластера из 11 нод это составляет примерно 100 вызовов systemd в секунду на каждой ноде.
И вот результат:

systemd занимает около 70% одного CPU. И это далеко не самый неудачный скриншот. Самый неудачный я, увы, потерял, и там было видно как он упирается в полку 100% CPU.
Важно: systemd – однопоточный процесс. И когда он упирается в 100%, то это не просто потребляет ресурсы кластера. Но и делает его абсолютно неотзывчивым даже для простых рутинных задач вида разворота новых контейнеров.
Итог? Практически весь workload перестал работать. Кластером просто стало невозможно пользоваться. Т.к. он практически все ресурсы systemd направил на обслуживание проб.
Зачем было вообще этим заниматься?
А теперь вы спросите “так а зачем вы вообще полезли в exec-пробы, если у вас уже был работающий HTTP”?
Ответ кроется в вот этой части кода kubernetes – pkg/probe/http/http.go#L138.
body := string(b)
if res.StatusCode >= http.StatusOK && res.StatusCode < http.StatusBadRequest {
if res.StatusCode >= http.StatusMultipleChoices { // Redirect
return probe.Warning, body, nil
}
return probe.Success, body, nil
}
return probe.Failure, fmt.Sprintf("HTTP probe failed with statuscode: %d", res.StatusCode), nil
Как вы видите, при неудачной пробе он полностью выкидывает прочитанный body и возвращает ни о чем не говорящее сообщение вида “HTTP probe failed with statuscode: 500”.
А хочется, чтобы в интерфейсе было видно внятную и понятную ошибку для траблшутинга о том, почему именно данная проба не смогла исполниться. Нам совершенно не сложно выводить эту информацию в body пробы, но нужно чтобы kubrenetes ее оттуда читал.
Exec-пробы этого недостатка лишены и выводят полную информацию, которую мы предоставим в stderr, что выглядит гораздо удобнее для эксплуатации.
Кажется, гораздо более правильным решением был бы просто pull request в kubernetes.
Выводы
Exec-пробы – широко документированный инструмент Kubernetes. Даже в официальной статье “Настройка Liveness, Readiness и Startup проб” именно exec-пробы используются, как обучающие примеры. Мы, наивно положившись на них, получили веселые последствия, чем я с вами и поделился. И ведь нигде не сказано о возможных последствиях в виде неработоспособного кластера. Но теперь вы предупреждены, а значит вооружены!
После отката назад в сторону HTTP проб, кластер вернулся в работоспособное состояние со средней нагрузкой на systemd около 10%.
Если у вас был похожий опыт, делитесь в комментариях!
Комментарии (9)

Eugene_Burachevskiy
14.09.2021 20:02Я так понимаю эта ситуация коррелирует и с размером инстанса. Если у вас большие ноды на которых крутятся сотни подов, то могут быть проблемы, но если на ноде крутится с десяток тяжеловесных подов, то проблем не будет?
По моему опыту для большинства нагрузок оптимальный размер нод, если в классификации Амазона, это xlarge и 2xlarge. И те же крупные дев кластера лучше скейлить горизонтально.

alexey_uzhva
16.09.2021 16:10Да, стараемся делать относительно небольшие ноды. Это рассказ про внутренний кластер, там что-то похожее на 2xlarge.
Если крутится с десяток подов, то проблемы бы не было.
Однако архитектура биллингового решения такая, что на один сетап крутится около двух десятков сервисов, написанных достаточно оптимально на C++ и Go. Они рассчитаны на нагрузки в сколько-то тысяч запросов в секунду, поэтому вялые функциональные юнит-тесты они просто не замечают как нагрузку. И потребляют что-то типа скольки-то миликор ядра и 128мб памяти.
Поэтому на девелоперских кластерах мы можем размещать большое количество подов на одной ноде. Просто потому что им на дев-нагрузках много ресурсов и не надо.
Поэтому даже 2xlarge объем в нашем мире – это примерно 250 подов.

kshvakov
14.09.2021 23:55+1Не раскрыта тема: "Почему?". Что такое происходило (да и происходит) в systemd, что он есть столько CPU. 10% - это тоже сильно много, не говоря уже о полке в 100%. Надо было тыкать в него strace'ом и смотреть. Хотя, если он и сейчас ест больше 1%, то смело можно это делать.
Почему вообще в данном сетапе такие проблемы, я про связку kubernetes и systemd?
GrgPlus93
15.09.2021 11:05+1Я поддерживаю вопрос. Если по http пробам вот даже кусочек кода выложили, то каким образом связан runc (а я так понимаю любой exec из containerd спускается туда) и исполнение systemd я так и не понял. Может дадите пояснение?
alexey_uzhva
17.09.2021 19:06Добрый день. Куски кода по этим частям - по ссылкам из статьи. Там в целом достаточно разветвленная структура как все устроено, проще выкачать их репо и разобрать в идее/голанде.
Хттп проба элементарна, поэтому с ней проще.
Вот эти штуки бегут в runc и далее в systemd - https://github.com/containerd/containerd/blob/36cc874494a56a253cd181a1a685b44b58a2e34a/pkg/cri/server/container_execsync.go#L109
Их там достаточно много вокруг.
saboteur_kiev
Полезная статья, спасибо.
Но "490 проб, исполняющиеся каждые 3 секунды" меня сразу смущает, когда мониторинг выполняется чаще, чем раз в минуту, а обычно стараюсь делать максимально редко (например свободное место на дисках - раз в 10 минут или даже реже).
А каждые 3 секунды, чтобы это ни было, мне кажется это больше режим отладки, чем нормальный мониторинг.
Я даже подозреваю, что 490 http проб каждые 3 секунды, это тоже весьма немалая нагрузка, вполне даже сопоставимая с нагрузкой пользователей не самого маленького сервиса.
Можете детальнее пояснить, зачем нужно так много и так часто?
GrgPlus93
Странный вопрос
Дело тут не в мониторинге, а в readinessprobe, которая отвечает за наличие ip пода в списке эндпоинтов сервиса. Иначе говоря, под, у которого зафейлилась риднеспроба, должен быть оперативно выкинут из балансировщика.
rtfm: https://kubernetes.io/docs/tasks/configure-pod-container/configure-liveness-readiness-startup-probes/
saboteur_kiev
Я знаю, что такое пробы.
Но вопрос - оперативность должна составлять 3 секунды?
Если у вас 490/3 = 163 запроса в секунду создает 10% нагрузки на ваши сервисы, то я бы и http пробы попробовал оптимизировать. Может быть ендпоинты у вас "тяжелые", может с них можно снять https, или проверить вдруг там авторизация включена, облегчить по максимуму. Либо поднимать мощность самих нод, снижать количество подов на одной ноде. Ибо мониторинг не должен столько есть...
Либо может быть просто не нужна такая оперативность, можно подождать 10 секунд, 20 секунд?
Что касается exec проб, я в продакшене их не использовал, и тоже подозревал что они конечно больше нагружают, и спасибо за статью, что прояснили сколько под капотом идет служебной нагрузки до собственно самой команды внутри exec. Но я подсознательно явно был бы против делать exec каждые 3 секунды. Я просто интуитивно понимаю, что я бы сперва померял производительность, а уже потом бы делал.
alexey_uzhva
Выше написано совершенно верно. Речь идет в том числе про readiness пробы. Задача которых убрать нездоровый сервис из раутера траффика как можно быстрее. Поэтому readiness реже чем раз в 3 секунды делать не хотим.
Что касается нагрузки, 10% при HTTP создаются не именно пробами. Это общая нагрузка на systemd, которая включает в себя множество всего. А вот дельта 10% → почти 100% была от exec проб.
Что касается решения на продакшне - да, было смутное подозрение. Вот проверили. И спешим поделиться граблями. Про что и статья :D