
Проблема
Наравне с многими компаниями, занимающимися разработкой ПО, в качестве составления общей картины о затраченном сотрудниками времени (а также способа расчета заработной платы, что не слишком важно) на те или иные задачи использует таймшиты - записи с указанием проекта, длительности выполнения задачи и кратким описанием проделанных действий. Однако если с первыми двумя пунктами проблем зачастую не случается, то к “творческой” части проводки периодически возникают вопросы: из текстов не всегда понятно, что конкретно сделал человек за тот или иной промежуток времени, и это может привести к недопониманию и конфликтам со стороны заказчиков, а также банально помешает грамотному учету рабочих часов сотрудников.
В качестве способа смягчения ситуации было решено разработать классификатор текстов, который смог бы на этапе заполнения сориентировать работника по поводу корректности и доступности для понимания составленной им проводки. Что из этого получилось - читайте далее.
Цель исследования
Цель исследования - разработка модели для классификации проводок на валидные и не валидные, а также на 8 классов по смыслам, а именно: анализ данных, провел встречу, подготовил отчет, разработал функциональность, сделал документацию, развертывание сервера, тестирование, обучение. Также должны иметься 2 дополнительных класса: «Отпуск» и «Очень плохая проводка», если смысла текста проводки не понятен.
Подготовка данных
Был получен датасет, состоящий из 6000 текстов проводок из системы учета времени сотрудников компании НОРБИТ. Сет был размечен вручную в соответствии с описанной выше классификацией – получили 2297 экземпляров.
Датасет размечался порционально по 500 проводок, извлеченных из базы проводок Microsoft Axapta, которой пользуются сотрудники НОРБИТ на данный момент. Сейчас в нем содержится 3017 экземпляров, максимально отличающихся по смыслу друг от друга.

Датасет формировался и размечался с учетом сохранения баланса классов, на что пришлось потратить немало времени - необходимо было просмотреть и разметить примерно в два раза больше проводок, так как в исходных данных имел место перекос. Для удобства классы были пронумерованы от 0 до 7 и названы как “statusid”. Более подробная информация о текстах проводок является конфиденциальной и не может быть разглашена. Все тексты проводок в статье вымышленные.
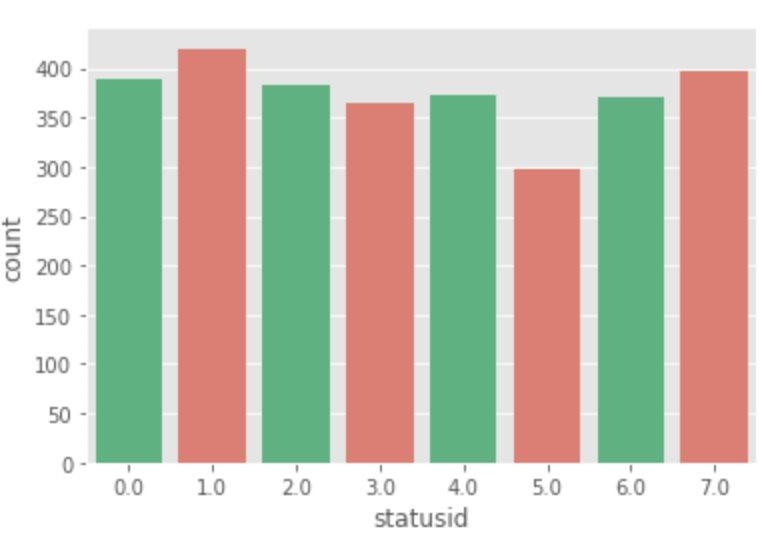
Пример класса проводок:
Адаптация. Проходил семинар по теме “R”. – классификация “Обучение” - Id 7.
Подготовил квартальный отчет по оттоку сотрудников. – классификация “Подготовил отчет” -Id 2.
Провел встречу с заказчиком. – классификация “Провел встречу” – Id 1.
Также были выделены классы валидных и невалидных проводок.
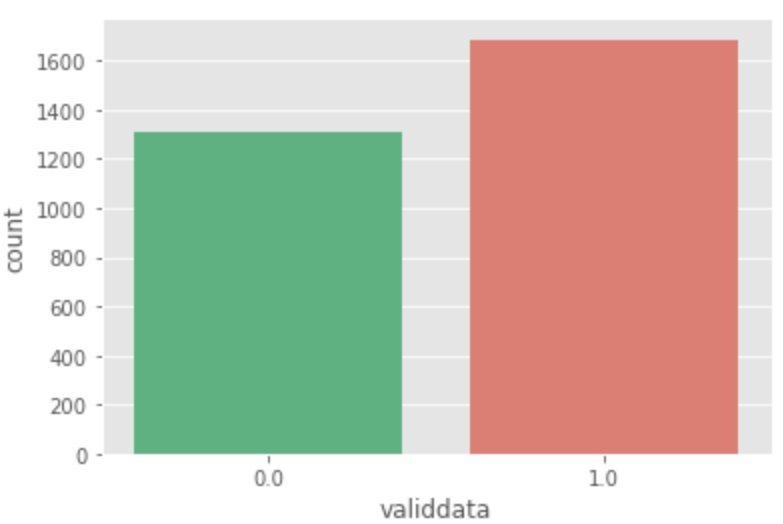
Примеры валидных и невалидных проводок:
Тестирование. Настройка. – Не валидная проводка
Тестирование нового сервера. Настройка работы сервиса. – Валидная проводка.
Создание модели
Предобработка текста
Обычно тексты содержат разные грамматические формы одного и того же слова, а также могут встречаться однокоренные слова. Лемматизация и стемминг преследуют цель привести все встречающиеся словоформы к одной, нормальной словарной форме.
Следующие краткие сводки взяты из этой статьи на хабре.
Примеры:
Приведение разных словоформ к одной:
dog, dogs, dog’s, dogs’ => dog
То же самое, но уже применительно к целому предложению:
the boy’s dogs are different sizes => the boy dog be differ size
Лемматизация и стемминг – это частные случаи нормализации, и они отличаются.
Стемминг – это грубый эвристический процесс, который отрезает «лишнее» от корня слов, часто это приводит к потере словообразовательных суффиксов.
Лемматизация – это более тонкий процесс, который использует словарь и морфологический анализ, чтобы в итоге привести слово к его канонической форме – лемме. Отличие в том, что стеммер действует без знания контекста и, соответственно, не понимает разницу между словами, которые имеют разный смысл в зависимости от части речи. Однако у стеммеров есть и свои преимущества: их проще внедрить и они работают быстрее. Плюс более низкая «аккуратность» может не иметь значения в некоторых случаях.
Теперь, когда мы знаем, в чем разница, давайте рассмотрим пример:
from nltk.stem import PorterStemmer, WordNetLemmatizer
from nltk.corpus import wordnet
def compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word, pos):
"""
Print the results of stemmind and lemmitization using the passed stemmer, lemmatizer, word and pos (part of speech)
"""
print("Stemmer:", stemmer.stem(word))
print("Lemmatizer:", lemmatizer.lemmatize(word, pos))
print()
lemmatizer = WordNetLemmatizer()
stemmer = PorterStemmer()
compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "seen", pos = wordnet.VERB)
compare_stemmer_and_lemmatizer(stemmer, lemmatizer, word = "drove", pos = wordnet.VERB)<w:Sdt SdtTag="goog_rdk_2" ID="1297018210">
Вывод:<o:p><w:sdtPr>
Stemmer: seen
Lemmatizer: see
Stemmer: drove
Lemmatizer: driveПредобработка текста проводилась при помощи библиотеки MySteam, все слова в проводках были лемматизированы. Тексты проводок были очищены от русских и английских стоп-слов, были удалены все знаки пунктуации и цифры слова в проводках были лемматизированы.
Причины по которым была выбрана библиотека MySteam от Яндекса:
Самая высокая скорость работы среди прочих лемматизаторов для рускоязычных слов.
Прост и удобен в использовании.
Легко ввести в эксплуатацию.
Токенизация текста
Токенизация по предложениям
Токенизация (иногда – сегментация) по предложениям – это процесс разделения письменного языка на предложения-компоненты. Идея выглядит довольно простой. В английском и некоторых других языках мы можем вычленять предложение каждый раз, когда находим определенный знак пунктуации – точку.
Но даже в английском эта задача нетривиальна, так как точка используется и в сокращениях. Таблица сокращений может сильно помочь во время обработки текста, чтобы избежать неверной расстановки границ предложений. В большинстве случаев для этого используются библиотеки, так что можете особо не переживать о деталях реализации.
Чтобы сделать токенизацию предложений с помощью NLTK, можно воспользоваться методом nltk.sent_tokenize.
text = "Backgammon is one of the oldest known board games. Its history can be traced back nearly 5,000 years to archeological discoveries in the Middle East. It is a two player game where each player has fifteen checkers which move between twenty-four points according to the roll of two dice."
sentences = nltk.sent_tokenize(text)
for sentence in sentences:
print(sentence)
print()Токенизация по словам
Токенизация (иногда – сегментация) по словам – это процесс разделения предложений на слова-компоненты. В английском и многих других языках, использующих ту или иную версию латинского алфавита, пробел – это неплохой разделитель слов.
Тем не менее, могут возникнуть проблемы, если мы будем использовать только пробел – в английском составные существительные пишутся по-разному и иногда через пробел. И тут вновь нам помогают библиотеки.
Токенизер был создан на основе токенайзера keras и настроен на имеющиеся данные для обучения. Причины выбора токенизера keras в качестве основы:
Простой в использовании с высокой скоростью.
Поддержка разных движков и модульность.
Поддержка нескольких GPU.
from tensorflow.python.keras.preprocessing import sequence
from tensorflow.python.keras.preprocessing import text
TOP_K = 20000
MAX_SEQUENCE_LENGTH = 50
class CustomTokenizer:
def __init__(self, train_texts):
self.train_texts = train_texts
self.tokenizer = Tokenizer(num_words=TOP_K)
def train_tokenize(self):
# Get max sequence length.
max_length = len(max(self.train_texts , key=len))
self.max_length = min(max_length, MAX_SEQUENCE_LENGTH)
# Create vocabulary with training texts.
self.tokenizer.fit_on_texts(self.train_texts)
def vectorize_input(self, tweets):
# Vectorize training and validation texts.
tweets = self.tokenizer.texts_to_sequences(tweets)
# Fix sequence length to max value. Sequences shorter than the length are
# padded in the beginning and sequences longer are truncated
# at the beginning.
tweets = sequence.pad_sequences(tweets, maxlen=self.max_length, truncating='post',padding='post')
return tweets
tokenizer = CustomTokenizer(train_texts = X_train['cleaned_tweets'])
# fit o the train
tokenizer.train_tokenize()
tokenized_train = tokenizer.vectorize_input(X_train['cleaned_tweets'])
tokenized_val = tokenizer.vectorize_input(X_val['cleaned_tweets'])
tokenized_test = tokenizer.vectorize_input(test['cleaned_tweets'])Обучение модели
Сети LSTM
LSTM (long short-term memory, дословно (долгая краткосрочная память) — тип рекуррентной нейронной сети, способный обучаться долгосрочным зависимостям. LSTM были представлены в работе Hochreiter & Schmidhuber (1997), впоследствии усовершенствованы и популяризированы другими исследователями, хорошо справляются со многими задачами и до сих пор широко применяются.
LSTM специально разработаны для устранения проблемы долгосрочной зависимости. Их специализация — запоминание информации в течение длительных периодов времени, поэтому их практически не нужно обучать!
Все рекуррентные нейронные сети имеют форму цепочки повторяющихся модулей нейронной сети. В стандартных РНС этот повторяющийся модуль имеет простую структуру, например, один слой tanh.
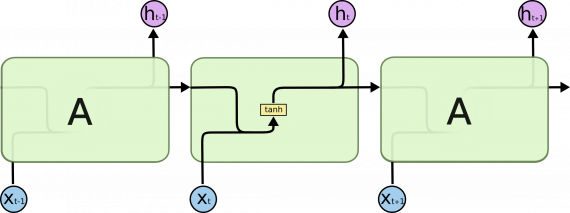
Повторяющийся модуль стандартной РНС состоит из одного слоя

На приведенной выше диаграмме каждая линия является вектором. Розовый круг означает поточечные операции, например, суммирование векторов. Под желтыми ячейками понимаются слои нейронной сети. Совмещение линий есть объединение векторов, а знак разветвления — копирование вектора с последующим хранением в разных местах.
Подробнее о сетях LSTM можно узнать тут.
y_trainmatrix = tensorflow.keras.utils.to_categorical(y_trainplu, 9)
y_valmatrix = tensorflow.keras.utils.to_categorical(y_valplu, 9)
modelplu=Sequential()
optimzerplu=Adam(clipvalue=0.5)
modelplu.add(Embedding(len(tokenizer.tokenizer.word_index)+1, EMBEDDING_VECTOR_LENGTH, input_length=MAX_SEQUENCE_LENGTH,trainable=True))
modelplu.add(Dropout(0.2))
modelplu.add(LSTM(64, dropout=0.2, recurrent_dropout=0.5))
#model.add(GRU(64, return_sequences=True))
modelplu.add(Dense(9,activation='softmax'))
# compile the model
modelplu.compile(optimizer=optimzerplu,
loss='categorical_crossentropy',
metrics=[tensorflow.keras.metrics.AUC()])
historyplu=modelplu.fit(tokenized_train, y_trainmatrix,
batch_size=64, epochs=600,
validation_data=(tokenized_val,y_valmatrix),
verbose=2)Модели для классификации основываются на LSTM-модели, которые были взяты из-за принципа её работы и приоритетного списка плюсов, конкретно:
Требуется всего несколько строк кода для создания сложной архитектуры нейронной сети.
Легко интегрировать / использовать в полнофункциональных проектах.
Очень проста в использовании.
Был также взят оптимизатор Adam и использованы функции ошибок категориальная кросентропия и бинарная кроссентропия для мультиклассовой и бинарной классификаций, а также классическая метрика Roc Auc.
modelbin=Sequential()
optimzerbin=Adam(clipvalue=0.5)
modelbin.add(Embedding(len(tokenizer.tokenizer.word_index)+1, EMBEDDING_VECTOR_LENGTH, input_length=MAX_SEQUENCE_LENGTH,trainable=True))
modelbin.add(Dropout(0.1))
modelbin.add(LSTM(32, dropout=0.2, recurrent_dropout=0.5))
modelbin.add(Dense(1, activation='sigmoid'))
# compile the model
modelbin.compile(optimizer=optimzerbin,
loss='binary_crossentropy',
metrics=[tensorflow.keras.metrics.AUC()])
historybin=modelbin.fit(tokenized_train,y_trainbin,
batch_size=32, epochs=100,
validation_data=(tokenized_val, y_valbin),
verbose=2)Валидации
По результатам на валидационной выборке точность по auс составила 70% для сети бинарного классификатора и 72% - для мультиклассовой классификации.
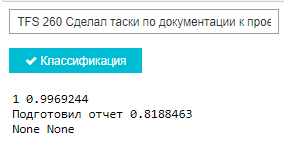
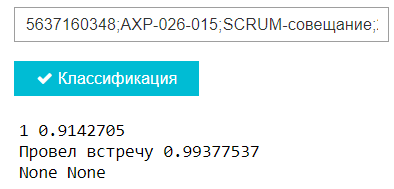
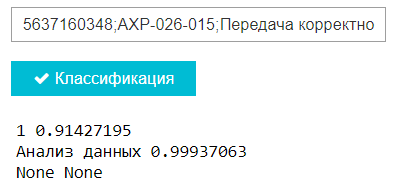
Пример работы классификатора
По итогу 63% проводок тестовой выборки верно классифицированы моделью для многоклассовой классификации и 90% - для бинарной классификации, что в целом является результатом нас вполне устраивающим.
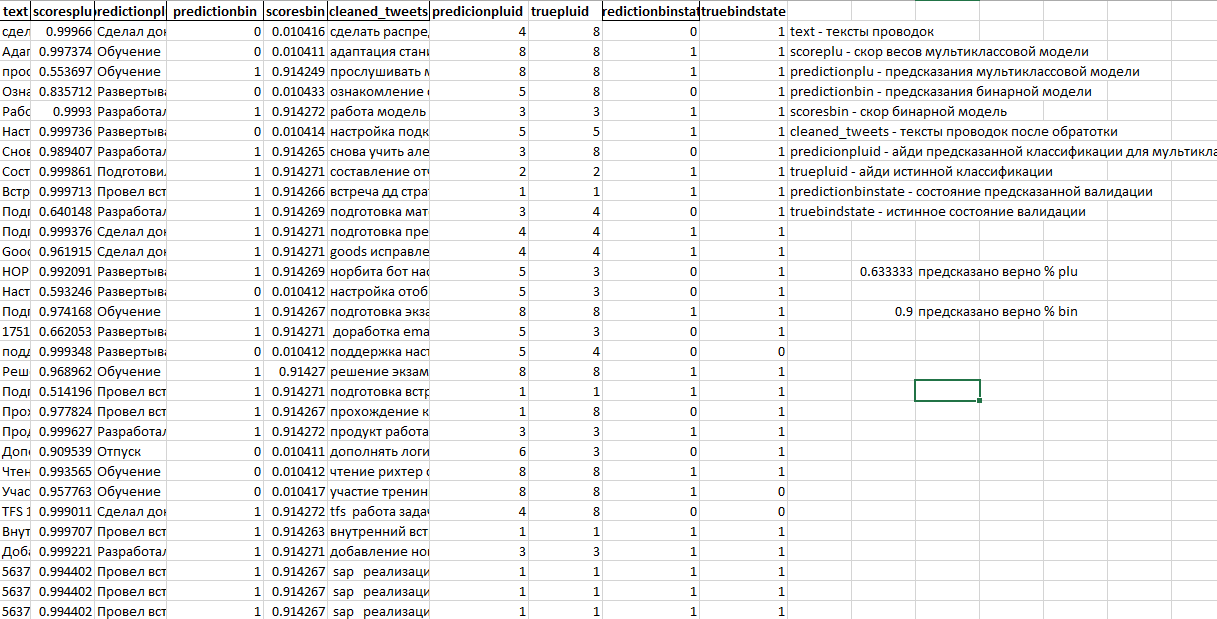
В ходе работы моделей формируется таблица:
text - тексты проводок;
scoreplu - скор весов мультиклассовой модели;
predictionplu - предсказания мультиклассовой модели;
predictionbin - предсказания бинарной модели;
scoresbin - скор бинарной модели;
cleaned_tweets - тексты проводок после обработки;
predicionpluid - ID предсказанной классификации для мультиклассового классификатора;
truepluid - ID истинной классификации;
predictionbinstate - состояние предсказанной валидации;
truebindstate - истинное состояние валидации.
И пример записи в полученной таблице:
text |
Сделал документацию по проекту R. |
scoreplu |
0.9996314
|
predictionplu |
Сделал документацию
|
predictionbin |
1 |
scoresbin |
0.99997133
|
cleaned_tweets |
сделать документация проект r |
predicionpluid |
4 |
truepluid |
4 |
predictionbinstate |
1 |
truebindstate |
1 |
Итоги
Создана модель на основе LSTM (рекуррентной нейронной сети с памятью) для классификации текстов проводок в журнале записей Axapta. Для того, чтобы проследить фактические улучшения качества списываемых данных после введения решения в оборот, требуется существенное количество времени, однако если вас это заинтересует - статистику также выложим на хабр (вместе с негодующими комментариями сотрудников, которых ИИ заставляет переформулировать описание выполненной работы).
Комментарии (2)

TakashiNord
26.09.2021 11:35порой не знаешь, что хуже: предательство Родины или вот такие подсчеты занятости.
amarao
таймшит является лишь частным случаем для целого класса шит-задач. Хотя микроменеджмент времени сотрудников - это, наверное, одна из самых шит-задач, которую можно только придумать.