

В 2018 году мы взялись за первый большой контракт по созданию инструментов разработки для нейропроцессора. В то время я знал, что рынок AI быстро растёт и на нём существуют сотни компаний. Но я не подозревал, что к 2021 году на рынке возникнет ещё пара сотен новых чипмейкеров, разрабатывающих акселераторы для AI, что мы станем AI-партнёром Arm, а наши проекты с нейрочипейкерами вырастут в отдельное направление. Не уверен, что вопрос, который поднимаю, актуален для российской аудитории: не так много в России компаний (откровенно говоря – мало), которые выпускают собственные ускорители для нейросетей. Скорее, эта статья — попытка зафиксировать знания, которые мы получили на американском рынке в результате нескольких проектов и около сотни бесед с чипмейкерами. Но если эта статья нанесёт кому-то непоправимую пользу, буду очень рад.
Традиционно наши клиенты — это разработчики CPU, MCU или DSP из разных стран. В России самый известные – АО «ПКК Миландр», для которого мы делаем среду разработки и ОСРВ, и ЗАО «НТЦ Модуль». Из иностранных компаний – это Samsung Electronics, для которого мы портировали ещё в 2000 году собственный С-компилятор и поддерживали его в течение 15 лет. Потом появился LLVM, и Samsung перешёл на решения на базе Arm, но это совсем другая история.
Когда мы начинали проект по разработке компилятора нейронных сетей для тензорного чипа, казалось, что это разовая работа. Затем появился второй клиент. Потом мы пришли на американский рынок, где потенциальных клиентов оказались десятки. И сейчас количество производителей, разработчиков акселераторов для нейросетей быстро растёт: десяток за год появляется точно. На рынке сосуществуют вместе как «гиганты» — Arm, STMicroelectronics, Achronix, Andes, так и большие и маленькие стартапы, такие как Kneron, Areana AI, AlphaICs. И так как рынок нейрочипов только формируется, у таких производителей возникают проблемы, которые ещё никто не пытался решать.
Новые возможности – новые проблемы
Каждый разработчик/производитель собственных нейрочипов стремится расширить число клиентов. Для этого они пытаются предоставить пользователям максимально эффективные решения с минимальной стоимостью владения, в том числе подходящие удобные инструменты разработки, и обеспечить техподдержку. Ситуацию осложняет то, что на рынке существует множество ML-платформ: PyTorch, MXNet, Caffe2, ONNX, TensorFlow и другие. Каждая из них поддерживает очень ограниченный набор целевого железа.
Поэтому разработчик нейрочипа должен либо предоставить собственноручно написанные инструменты, либо использовать трансляторы (например, из ONNX). Оба варианта очень затратны, а кроме того, имеют технические ограничения и требуют дополнительных затрат на осуществление поддержки. Например, если выходит новая версия TensorFlow, разработчик вынужден выпускать апдейты, потребуются новые алгоритмы оптимизации. Поэтому для разработчика чипа поддерживать сразу много фреймворков невозможно, особенно если компания небольшая.
Беда в том, что пользователи обычно при выборе среды исполнения, отталкиваются от уже имеющихся разработанных и обученных сетей. В итоге, если производитель выбрал вариант поддержки какой-то одной платформы, он получает ограниченную аудиторию пользователей. Привлечь новую аудиторию, заставить пользователей использовать новый чип для разработки устройства чрезвычайно сложно.

Рисунок 1. Ограничение аудитории
Решение
Чтобы преодолеть это ограничение мы искали для своих проектов максимально универсальное решение, которое поддерживает максимальное количество ML-фреймворков.
В первом же проекте выбрали TVM и не прогадали.
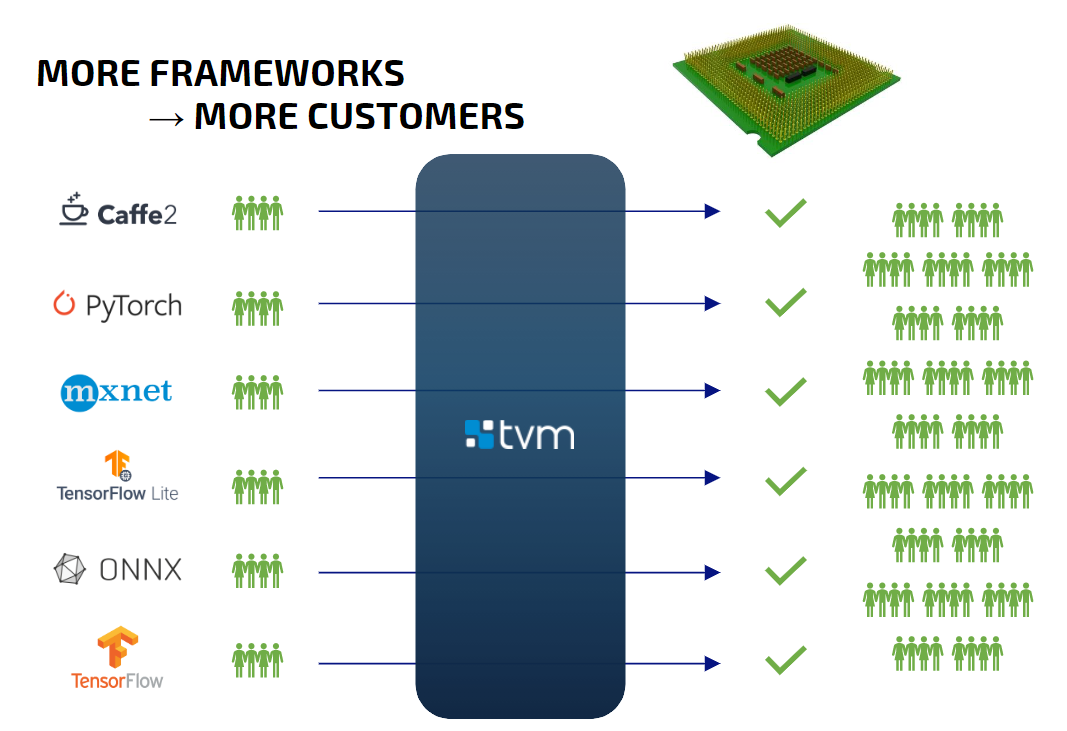
Рисунок 2. Аудитория универсального решения
Если просто, то TVM обеспечивает инференс обученных сетей разных форматов на выбранном железе, в том числе на специализированных и уникальных чипах (естественно, после его соответствующей доработки).
Из рисунка ниже видно, что TVM имеет несколько вариантов расширения существующими инструментами и алгоритмами и может быть модифицирован в разных точках для обеспечения поддержки нового чипа.
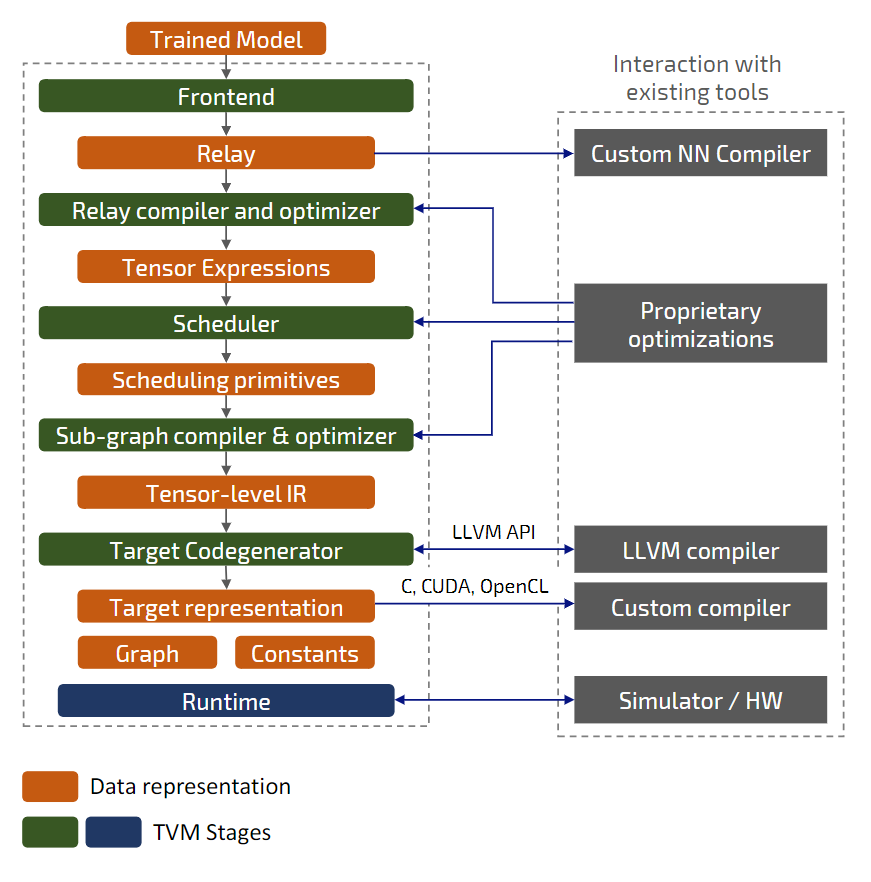
Рисунок 3. Уровни преобразований в TVM и потоки данных
Возможные шаги по доработке:
- добавить новую архитектуру/устройство в TVM,
- добавить/изменить проходы оптимизатора,
- разделить операции уровня хоста и устройства,
- добавить/изменить сценарии планировщика для операций,
- реализовать механизм кодогенерации,
- доработать среду исполнения,
- реализовать/доработать симулятор (функциональный или потактовый).
Благодаря модульной структуре и гибкости TVM позволяет внедрить разные типы бэкендов для различных архитектур. И даже комбинировать их, чтобы обеспечить самый эффективный вариант, исходя из того, что уже есть у разработчика чипа.
Ниже несколько вариантов подходов к разработке бэкенда:
BYOC
- Обработка на уровне Relay-представления
- Замена операций или набора операций (слоёв) на составные целевые функции
- Собственная среда исполнения для внедрённых интринсик (intrinsic)
LLVM
- Использование существующих бэкендов LLVM
- Инфраструктура LLVM используется через API
- Компиляция в бинарный код (библиотеки), биткод LLVM, LLVM IR
Source
- Генерация исходного кода для использования со сторонним компилятором
- Поддерживается: C, CUDA, METAL, OpenCL, Vivado HLS
VTA
- Собственный дизайн ускорителя линейной алгебры с полной интеграцией в TVM
- Готовые реализации на Vivado HLS C++, Chisel, OpenCL
- Функциональный симулятор и симулятор на базе Verilator
- Потенциальная возможность использовать множественные VTA-ядра
- Может быть использован в качестве базового для похожих архитектур
Custom
- Внедрение целевых интринсик через механизм Tensorization — на основе сопоставления паттернов на уровне планировщика
- Интринсики могут быть выражены через внешние вызовы, фрагменты кода на целевом ассемблере или LLVM IR/bitcode
Варианты внедрения
Таким образом, проекты по доработке TVM могут быть разными и зависят от уже созданных чипмейкером элементов SDK.
Если у разработчика есть NN-компилятор, то он может внедрить конвертер из Relay и использовать TVM для расширения фронтенда.
- Поддержка большого количества входных NN форматов
- Общие оптимизации на уровне графа
Обычно такие проекты занимают месяца четыре командой из двух разработчиков.
Если у производителя есть C/C++ / OpenCL / CUDA -компилятор, он может использовать существующий бэкенд TVM для генерации исходников или интегрировать компилятор LLVM в LLVM-бэкенд TVM, настроить планировщик под особенности целевой архитектуры.
- Возможности планировщика TVM по распределению ресурсов на модули устройства
- Переиспользование конфигураций планировщика из других бэкендов
- Общие оптимизации на уровне подграфов
По трудозатратам и срокам такой проект аналогичен предыдущему.
В случае, если у разработчика чипа ещё нет компилятора, лучше всего дополнить TVM новым бэкендом для поддержки целевой архитектуры.
- Несколько вариантов реализации бэкенда, наличие готовых бэкендов для различных архитектур, которые можно использовать в качестве базы
- Реализации среды исполнения для различных типов железа
Обычно это достаточно сложные проекты, которые длятся полгода и требуют команду побольше, чем предыдущие варианты.
Почему мы выбрали TVM
Первая причина, как я писал выше, количество поддерживаемых ML-платформ: Keras, MXNet, PyTorch, TensorFlow, CoreML, DarkNet. Это решает первую проблему – увеличение числа потенциальных клиентов. Чем разнообразнее инструменты, которые могут использовать клиенты производителя ускорителя, тем больше клиентов может быть.
Вторая причина – большое комьюнити TVM. Сейчас в нем 500+ контрибьюторов, разработка спонсируется в том числе гигантами (Amazon, ARM, AMD, Microsoft, Xilinx). Благодаря этому разработчик чипа автоматически получает все новые оптимизации и компоненты TVM, включая поддержку новых версий фронтендов. При этом TVM — под лицензией Apache, это позволяет без проблем использовать его в любых коммерческих проектах, и в то же время обеспечивает независимость от крупных корпораций. Разработчик нового нейрочипа владеет всеми IP и сам решает, чем делиться с сообществом.
Более того, экосистема TVM постоянно расширяется. Существуют компании, такие как OctoML, Imagination Technologies, да, собственно, и наша. Это позволяет чипмейкеру предлагать пользователям большое количество разных инструментов и сервисов, чтобы максимизировать производительность их моделей, что даёт преимущества по сравнению с конкурентами.
Например, компания OctoML предлагает сервис для улучшения производительности нейросетей. Работает с большинством ML-фреймворков и платформ: Arm (A class CPU/GPU, ARM M class microcontrollers), Google Cloud Platform, AWS, AMD, Azure, and others. Клиенты получают возможность автоматической настройки моделей на целевом железе, за счёт чего экономят время инженеров, которое обычно тратиться на ручную оптимизацию и тестирование производительности. Быстрее выходят на рынок. Наша компания как партнёр обеспечивает поддержку новых чипов в сервисе.
Третья причина (это скорее комплекс причин) – технические возможности TVM. Вот список наиболее важных, по нашим наблюдениям:
- TVM предоставляет инфраструктуру для автоматической генерации и оптимизации тензорных операций,
- поддержка гетерогенных платформ (системы, объединяющие управляющий процессор и нейроакселератор),
- наличие Auto Scheduler (Ansor) и других инструментов, призванных облегчить жизнь разработчика.
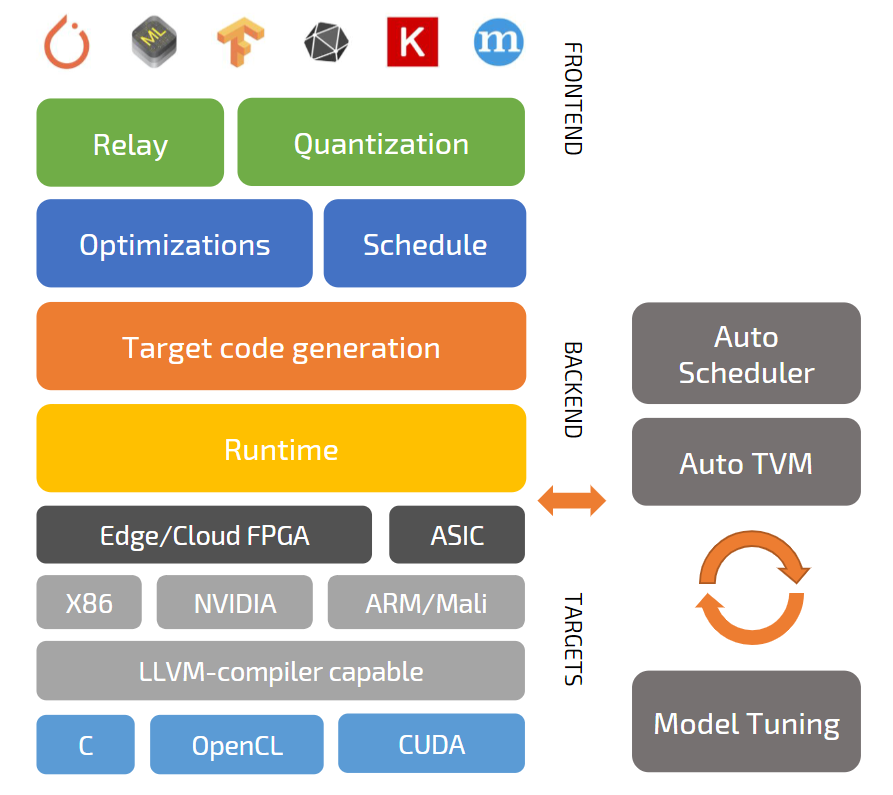
Рисунок 4. Структура и компоненты TVM
Relay — статически типизированное, чисто функциональное, дифференцируемое высокоуровневое промежуточное представление. Auto TVM / Auto Scheduler — фреймворки для оптимизации тензорных программ с использованием машинного обучения.
Всё это даёт возможность создавать полнофункциональные SDK для новых нейрочипов, оставаясь в сроках и бюджете. При этом клиент получает даже больше.
Потенциально – он сокращает расходы на разработку SDK благодаря тому, что использует быстро развивающийся opensource фреймворк и может привлекать внешние высококвалифицированные команды на аутсорс (для наших американских заказчиков это оказалось очень важным). При этом свою ключевую core-технологию сохраняют внутри. Понятно, что снижается стоимость поддержки по сравнению с собственным кастомным решением.
И, что самое главное, клиент получает расширение своей базы потенциальных пользователей благодаря тому, что нет необходимости привязывать решение к конкретной ML-платформе. И даже появляется новый инструмент привлечения пользователей – через сообщество TVM.
Заключение
Перечитал получившуюся статью – получилась хвалебная ода TVM. Цели такой не было, тем более что мы напрямую с TVM никак не связаны, всего лишь используем его в проектах наряду с другими инструментами, например MLIR. Но инструмент действительно отличный. Впрочем, сделал беглый поиск по статьям на Хабре. Про TVM ничего не нашёл, так что оставляю это здесь как «вводную» в тему статью. Ну а дальше — в зависимости от вашего интереса, можем опубликовать материалы, посвященные отдельным проектам и техническим проблемам.