
Данный текст описывает общесистемные подходы, используемые при работе с брокером сообщений Kafka, и общие архитектурные подходы, применяемые при работе с системами, имеющими несовместимые транзакционные модели.
Преамбула или как было "до"
Когда деревья были большими, а сервер оставляли на улице, так как внести его в помещение не представлялось возможным из-за того, что, с одной стороны, разобрать его на более мелкие части не могли, а с другой стороны, здание не имело технологических проёмов достаточного размера, считалось, что нужная производительность системы достигалась количеством потраченных денег на одну приобретаемую железку. Конечно, это не так – и сейчас, и тогда было не так. Хотя бы потому, что если в такой железке все операции зависят от одного ресурса, то конкуренция за этот ресурс остановит любой по мощности сервер, как по команде "поезд, стой, раз, два". Не от хорошей жизни приходилось приобретать такие железки.
Но оставим лирику. Мне кажется, что сейчас есть один существенный момент, который поменялся в понимании того, как решать такие проблемы. А именно, пришло чёткое осознание того, что в большой системе в каждый момент времени не обязательно частное состояние отдельных её частей должно быть целостным. Но общее состояние системы в нужный момент времени должно быть целостным.
Это общие слова, и часто бывает сложно сходу их понять. Поэтому более подробно.
Чтобы связать компоненты внутри системы, поначалу использовались общие базы данных, которые совместно использовались всеми компонентами и обменивались данными через общие области в этой базе данных. По сути строили очереди с использованием таблиц. Если нагрузка была небольшой, такой подход был вполне допустим. Но при росте нагрузки возникали проблемы, связанные с двумя, на мой взгляд, наиболее существенными вещами: с одной стороны, стоимость железки под базой данных всё время росла, а с другой, было сложно работать несколькими клиентами (средний слой) с общими таблицами в этой базе данных так, чтобы не мешать друг другу. Последний момент был связан главным образом с тем, что из-за изоляции транзакций нельзя было определить, взята ли запись в работу кем-то другим или ещё нет (да, можно было пропускать заблокированные записи, но с этим были уже другие сложности).
Следующим шагом в развитии стала реализация полноценных очередей. Как правило, речь идёт обычно о JMS. Иногда они были встроены в базу данных, иногда – выполнены независимым решением. Общим моментом для них было то, что они позволяли выполнить изменение в БД и отправить или обработать сообщение в очереди, используя одну транзакцию. То есть нам гарантировали, что мы в любой момент времени после окончании транзакции либо получаем изменения во внутреннее состояние системы (БД) и обрабатываем/отправляем сообщение (очередь), либо теряем изменение и сообщение остаётся необработанным/неотправленным. То есть нельзя было, например, поймать такой момент времени, когда принимаемое сообщение переведено в состояние "обработано", а связанные изменения в БД потеряны. Решалось это за счёт распределённых транзакций (XA/JTA) и двухфазных протоколов фиксации транзакций. Всё было круто, если не читать текст в конце мелким шрифтом. По факту же, так называемая "задача двух генералов" строго решена не была. Например, можно было получить ситуацию, когда сообщение было отправлено (и даже уже пришёл ответ на него), а изменения в локальную БД ещё не внесены. Так или иначе эта проблема решалась, но решение в любом случае оставалась дорогим и/или неполноценным.
Текст до текущего места можно было не читать.
Сейчас...
...даже не пытаются получить гарантии того, чтобы в каждый момент времени состояние было определено.
Есть два основных сценария, которые должны обеспечиваться. Здесь и далее уже конкретно рассматривается брокер сообщений Kafka.
Сразу нужно оговориться, что есть третий, самый приоритетный с точки зрения Kafka вариант, – это использование её в качестве источника событий или реализация принципа CQRS. При таком подходе типичная транзакция затрагивает только топики Kafka и выглядит так:
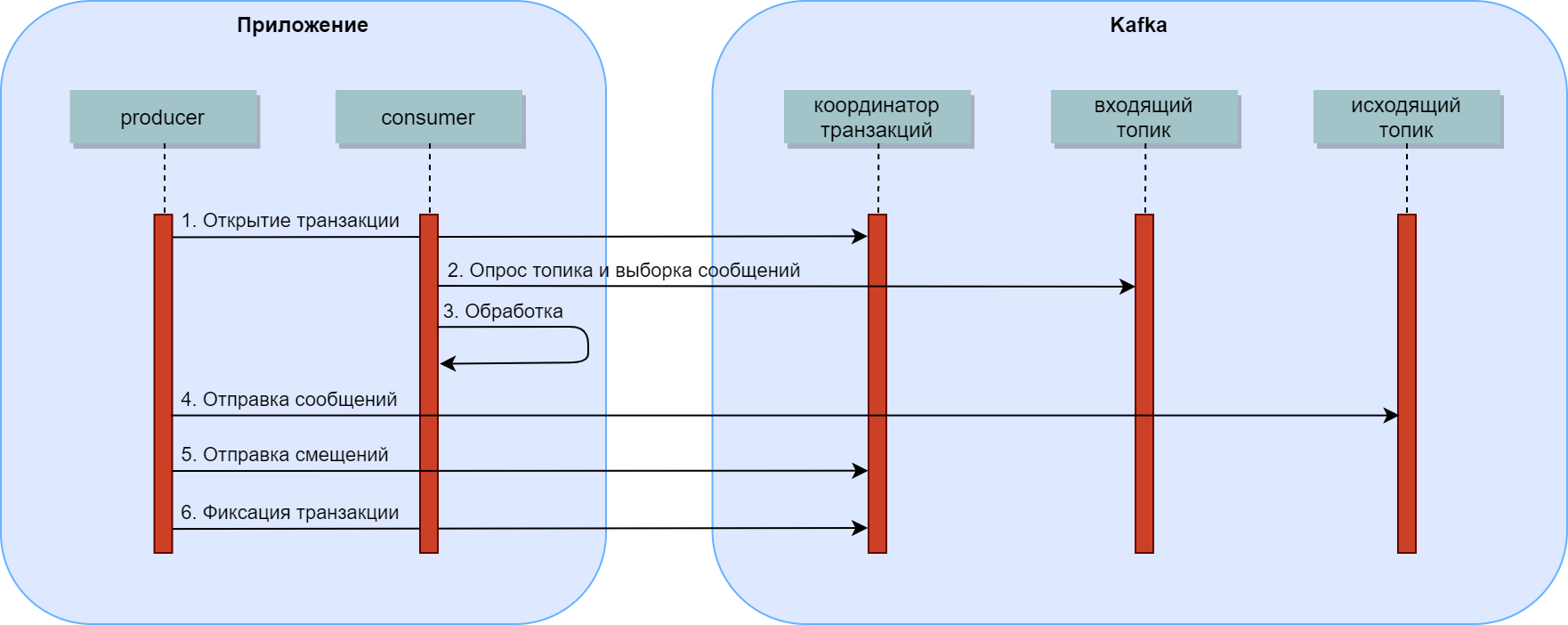
Открывается транзакция.
Начинается опрос топика, выступающего в данный момент входящим, на предмет наличия входящих сообщений.
Как только такие появляются, они выбираются и обрабатываются.
В результате обработки могут появиться исходящие сообщения. Они записываются в исходящий топик, но ещё не видны consumer'ам.
Отправляются смещения, которые указывают на то, что следующим для обработки является очередное за обработанным сообщение. Они также записываются, но ещё не видны. Да и прочитаны в текущей consumer group быть не могут.
При фиксации транзакции создаётся запись, которая указывает на то, что записанные к этому моменту сообщения и смещения становятся видимыми для всех consumer'ов.
Таким образом, смещение, указывающее на очередное сообщение, и все исходящие сообщения применяются и становятся видны одномоментно при сохранении записи о том, что транзакция в целом является зафиксированной. Если фиксация не происходит, они так и остаются в очереди ничего не значащими записями, которые пропускаются и не участвуют в обработке.
Приём сообщения из Kafka
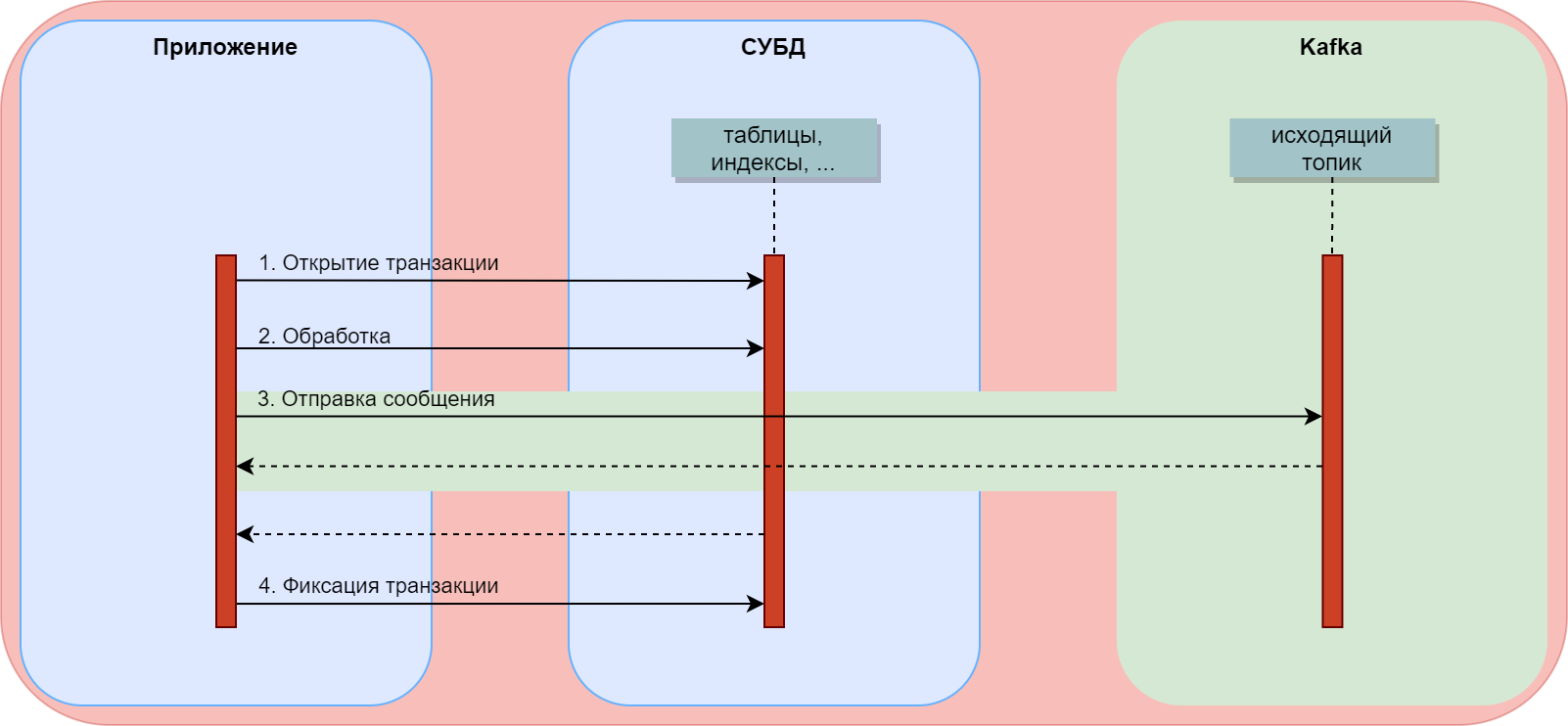
При приёме сообщения из Kafka внутри шага 3 (обработка) может понадобиться отразить изменения в СУБД.

В данной схеме взаимодействия в момент обработки сообщения открывается транзакция в СУБД и там выполняются изменения, которые фиксируются в независимой несовместимой с Kafka транзакции, то есть до выполнения шага 6.
Соответственно, имеем две проблемы:
Изменения в БД отражаются раньше момента, когда сообщение можно считать обработанным.
Изменения в БД могут произойти, а фиксацию изменений в Kafka мы сделать не успеем (падение приложения, закрытие приложения оркестратором контейнеров, падения железки, обрыв связи и т.д. и т.п.).
С первой проблемой нужно просто смириться. То есть мы всегда должны держать в голове, что изменения в БД чуть-чуть опережают состояние в очереди. Чтобы это "чуть-чуть" стало ещё меньше, нужно фиксацию изменений в БД максимально приближать по времени к фиксации изменений в очереди.
Решение второй проблемы – это использование ключей идемпотентности. Вкратце: на основании данных из обрабатываемого сообщения мы получаем или однозначно вычисляем значение, которое сохраняем вместе с теми изменениями, которые производим на стороне БД. Таким образом, если мы видим, что такое значение ключа идемпотентности уже ассоциировано с изменяемым объектом в БД, то это изменение уже было выполнено. Это указывает на то, что сообщение обрабатывается не первый раз, а предыдущий раз по какой-то причине его обработка была прервана. То есть её можно пропустить в штатном режиме и перейти к следующем сообщению.
Для активно изменяемых объектов в БД может накапливаться большое количество ключей идемпотентности. Поэтому имеет смысл задуматься над тем, как их хранить и очищать старые. Возможные варианты: в составе полей объекта или в отдельной таблице, в текстовом поле или в структурированном поле, например, jsonb.
Отдельная таблица, хотя и универсальная для всех информационных объектов, но потребует организации дополнительной связи с ней и более тяжёлого обслуживания, так как со временем станет очень большой. Поэтому имеет смысл хранить ключи в составе полей самого информационного объекта. Для универсализации имеет смысл определить для поля стандартное название и тип.
Поскольку старые ключи идемпотентности имеет смысл очищать при добавлении нового ключа, с ключом должна быть ассоциирована какая-то дата, на основании которой можно принять решение, что ключ более не актуален. В случае ULID такая дата у нас есть, но у нас нет гарантии, что во всех поступающих сообщения будет доступен такой ULID и его можно будет использовать. Поэтому речь идёт всё-таки о нескольких значениях. Например, также может понадобиться сохранять сведения об ответе, который нужно предоставить вызывающей стороне при повторных вызовах. Для удобства хранения и работы с такими структурами (список пар "ключ-дата") на мой вкус и цвет удобнее использовать jsonb.
Отправка сообщения в Kafka
Существует также обратная ситуация, когда открывается транзакция в СУБД, во время которой требуется отправить сообщение в Kafka.
Ключи идемпотентности, используемые в предыдущем случае, не сильно помогают, если вложенная транзакция – в Kafka, так как мы не можем искать в очереди старое сообщение и анализировать его ключ. Очередь постоянно изменяется, сообщения могут из неё вытесняться. Кроме того, действие, вызвавшее транзакцию в СУБД, может быть пользовательским и не повториться в конечном счёте.
Если отправлять сообщение без учёта того, как оно будет обрабатываться при получении, в том числе потенциальных дублей, то будут возникать проблемы. Или принимающая сторона должна учитывать возможность дублей.
Мне известны две корректных схемы реализации такого типа взаимодействия. В обоих случаях внутри БД используется своего рода очередь, записи из которой становятся сообщениями в Kafka. Общая схема выглядит так:

В одном случае эта очередь организуется разработчиком, то есть создаётся соответствующая таблица. В другом используется встроенная в СУБД очередь – так называемый журнал опережающей записи или WAL.
Принципиальные различие между этими подходами:
Таблица |
WAL |
|---|---|
Организуется разработчиком и представляет собой частное решение |
Управляется СУБД и представляет собой решение класса CDC |
Может содержать любую удобную структуру, в том числе содержащую данные из нескольких таблиц |
Структурно представляет собой отражение каждой таблицы БД в отдельности |
Нужно заботиться об упорядоченности записей в таблице |
СУБД сама управляет журналом |
Может содержать LOB и даже состоять из LOB-поля |
Может иметь проблемы с обработкой LOB |
Нужно заботиться об очистке таблицы от старых записей |
СУБД сама управляет журналом |
Более подробно о варианте с таблицей. Работа разделена на две активности: в рамках первой наполняется очередь внутри БД, вторая ответственна за чтение и очистку очереди.
Наполнение очереди происходит при выполнении некоторой операции в приложении или обработке действия пользователя: открывается транзакция, выполняется логика обработки, выполняется запись сообщения в таблицу-очередь, выполняется фиксация транзакции СУБД. Запись сообщения может выполняться как в приложении, так и внутри СУБД с помощью триггера. Запись может содержать все необходимые поля, а может представлять собой LOB поле, например, с json внутри. Первым важным моментом при этом является то, что записи внутри таблицы-очереди должны быть упорядочены по времени возникновения. В СУБД это делается достаточно легко с использованием sequence, записи текущей даты и времени или ключа в формате ULID, который гарантирует уникальность и включает в себя дату и время. Вторым важным моментом является то, что генерация идентификатора, времени создания кортежа и запись в таблицу-очередь должна происходить как можно позже (об этом далее).
В итоге:
Запись включается в себя 1) монотонно возрастающий идентификатор, 2) время, 3) поля для переноса в Kafka или одно большой поле со всеми необходимыми значениями.
Транзакция внутри СУБД гарантирует нам, что изменения, производимые в таблицах БД и таблице-очереди сообщений для отправки в Kafka, будут выполнены одновременно и целостно с точки зрения внешних пользователей СУБД.
Далее, включается работа приложения, которое опрашивает таблицу-очередь и отправляет сообщения в Kafka. Процесс выглядит следующим образом: с некоторой периодичностью выбираются из очереди записи старше некоторого значения идентификатора/метки времени. При этом важно, что:
Максимальный идентификатор или метка времени, обработанная на предыдущем шаге, хранится в Kafka. То есть обновление этого значения будет произведено в той же транзакции Kafka, что и запись сообщений в исходящий топик.
Записи для обработки выбираются не только больше некоторого идентификатора, но и меньше некоторого времени, которое отводится на завершение всех транзакций в БД, начатых внутри обрабатываемого интервала времени. Если это условие не выполнить, то потенциально долгая транзакция может начаться в интервал времени, обрабатываемый приложением-poller'ом, а закончиться уже тогда, когда обработка интервала закончится. То есть запись останется невидимой для обработчика и останется необработанной. Чтобы сузить этот интервал, генерация идентификатора (метки времени) и запись в журнал должна происходить как можно позже, как уже писалось выше. Идеальным вариантом здесь выглядит использование ULID, так как он уже совмещается в себе и идентификатор, и метку времени. На этом же шаге можно удалить старые записи из журнала внутри БД. Например, те, которые меньше упомянутого выше идентификатора (минус интервал удерживания, если требуется).
Далее, выбранные сообщения переносятся в топик Kafka. Также в отдельный compacted-топик сохраняется максимальный (последний) идентификатор из обработанного диапазона и транзакция фиксируется.
Отправка нескольких связанных сообщений в Kafka, формируемых в разных транзакциях СУБД, очевидно, должна выполняться аналогично: сообщения накапливаются в промежуточных таблицах, а затем при общей готовности к отправке (формирование последнего сообщения из серии) переносятся в таблицу-очередь, опрашиваемую приложением-poller'ом.
зы. Кстати, определение последнего сообщения из серии – ещё одна интересная задача как при работе с обычными СУБД, так и при работе с Kafka.
Комментарии (14)

aa0ndrey
21.10.2021 13:17Скажите, что вы думаете по поводу следующего подхода?
Для всех сообщений в брокере затребовать, чтобы указывался id сообщения из кода приложения (это важный момент). Для всех потребителей сообщений сделать так, чтобы они реализовывали механизм идемпотентности относительно id сообщения.
При этом обработка любого сообщения будет следующей: выполнение всех бизнес действий под транзакцией БД, сохранение в той же БД для входящего сообщения для его ID все другие сообщения, которые необходимо отправить с фиксированным ID. Затем фиксация транзакции в БД. Затем отправка сообщений. Затем отправка acknowledge для исходного сообщения запустившего процесс.
При этом, если в самом начале для сообщения с заданным ID уже есть информация об обработке в БД, то действия для БД пропускаются, из БД извлекаются сообщения, которые должны были быть отправлены в брокер и они отправляются. Затем отправка acknowledge для исходного сообщения запустившего процесс.
Фокус тут в том, что если критерием идемпотентности является генерированный ID из кода, который сохраняется в БД, то в брокер могут попасть более одного сообщения с одинаковым ID, но т.к. каждый консьюмер умеет откидывать уже обработанные сообщения, то в случае попадание дубликата выполнение повторных действий не будет.
При этом обеспечивается гарантия, что если произошла фиксация данных в БД, то отправка из приложения точно когда-то произойдёт, возможно более одной.
Разница с использования ID сообщения из брокера или offset-а в качестве ключа идемпотентности в том, что для них повторная успешная отправка одного и того же сообщения со стороны producer-а не обладает идемпотентностью, т.к. для каждого успешно отправленного сообщения будет присвоен уникальный ID из брокера и offset.
Как вы считаете можно ли рассматривать данное решение как альтернативу CDC описанного вами второго случая?

svaor Автор
21.10.2021 13:54Вы описали как раз первый сценарий: приём сообщений из Kafka. У меня в тексте это описано так:
...на основании данных из обрабатываемого сообщения мы получаем или однозначно вычисляем значение, которое сохраняем вместе с теми изменениями, которые производим на стороне БД. Таким образом, если мы видим, что такое значение ключа идемпотентности уже ассоциировано с изменяемым объектом в БД, то это изменение уже было выполнено. Это указывает на то, что сообщение обрабатывается не первый раз, а предыдущий раз по какой-то причине его обработка была прервана. То есть её можно пропустить в штатном режиме и перейти к следующем сообщению.
Вы просто предложили использовать в качестве ключа идемпотентности идентификатор сообщения. В комментариях выше и статье на medium, на которую ссылался автор, также шла речь о таком же подходе. Только в качестве ключа там предлагалось использовать не только идентификатор сообщения, но и наименование топика. Вариант вполне допустимый на мой взгляд.
Навскидку, что тут может пойти не так: например, идентификатор сообщения может измениться:
in case of error, commit offset, but enqueue the message again at the end of your Kafka Topic (maybe store how many times this operation was tried)
Это не проблема, но должно учитываться.
Теперь касательно CDC. Во втором случае говорится об отправке сообщения в Kafka. Это другой кейс. Он никак не связан с первым:
Существует также обратная ситуация, когда открывается транзакция в СУБД, во время которой требуется отправить сообщение в Kafka.
Ключи идемпотентности, используемые в предыдущем случае, не сильно помогают, если вложенная транзакция – в Kafka, так как мы не можем искать в очереди старое сообщение и анализировать его ключ. Очередь постоянно изменяется, сообщения могут из неё вытесняться. Кроме того, действие, вызвавшее транзакцию в СУБД, может быть пользовательским и не повториться в конечном счёте.
Если отправлять сообщение без учёта того, как оно будет обрабатываться при получении, в том числе потенциальных дублей, то будут возникать проблемы. Или принимающая сторона должна учитывать возможность дублей.Альтернативы просты: либо принимающая сторона должна учитывать возможность появления дублей сообщений, либо нужно строить очередь в БД. Это построение очереди в моём тексте и описывается.
aa0ndrey
21.10.2021 14:42Ну вот получается, что тут я больше ссылался именно на второй кейс. Что отправка сообщений в kafka можно делать без CDC, используя всюду ID идемпотентности.
//метод getId возвращает ID, не который установлен брокером, //а который установлен в коде, когда сообщение отправлялось. var consumedMessage = consumer.consume(); //допустим есть таблица consumed_message c колонками //id - id строки в БД (ни на что не влияет) //consumed_message_id: UNIQUE INDEX - id обрабатываемого сообщения //и есть таблица produced_message с колонками //id - id строки в БД (ни на что не влияет) //consumed_message_id - id обрабатываемого сообщения //produced_message_id - id отправляемого сообщения //produced_message_body: JSON - тело отправляемого сообщения var messageWasConsumed = select count(*) > 0 from consumed_message where consumed_message_id = consumedMessage.getId(); //здесь сообщения которые необходимо отправить List producedMessage = new ArrayList<>(); if (!messageWasConsumed) { TRANSACTION BEGIN; //здесь любая бизнесовая логика с сохранениями в БД //и например в рамках этой логики необходимо отправить //несколько сообщений, поэтому здесь происходит наполнение //массива producedMessages //с генерированными в коде id - producedMessage.getId() //и с телом - producedMessage.getBody() insert into consumed_message (consumed_message_id) values (consumedMessageId); for(var producedMessage in producedMessages) { insert into produced_message (consmed_message_id, produced_message_id, produced_message_body) values (consmedMessage.getId(), producedMessage.getId(), producedMessage.getBody()); } TRANSACTOIN COMMIT; } else { producedMessages = select produced_message_id, produced_message_body from produced_message where consumed_message_id = consumedMessage.getId(); } for(var producedMessage in producedMessages) { producer.produce(producedMessage); } consumer.ack(message);Тут важно, что каждый консьюмер имеет точно такую же структуру. Разница только внутри блока с бизнес-логикой.
Кажется, что данная структура позволяет решить оба кейса. И прием сообщения из kafka с записью в БД (первый кейс), который у вас описан, и одновременно отправку в kafka и запись в БД (второй кейс) без использования CDC.
svaor Автор
21.10.2021 15:04var consumedMessage = consumer.consume();
Ещё раз. Я говорю о CDC и очереди в БД в сценарии, когда нет никакого входящего сообщения из Kafka. Например, пользователь жмёт на сайте на кнопку "Отправить сообщение", далее средний слой обрабатывает http запрос, пишет что-то в БД и возвращает пользователю ответ "Отправлено". А уже потом должна появиться Kafka, очереди, обработка этого сохранённого в БД сообщения и пр.
aa0ndrey
21.10.2021 15:13Ага, я вас понял. А если на любой HTTP запрос отправлять сообщение сразу в kafka и уже полностью асинхронно производить обработку. То есть заведомо приводить систему к кейсу, когда одновременная обработка базой и очередью возможна только тогда, когда исходным запросом тоже было сообщение
svaor Автор
21.10.2021 15:16Да, это у меня тоже описано :)
Сразу нужно оговориться, что есть третий, самый приоритетный с точки зрения Kafka вариант, – это использование её в качестве источника событий или реализация принципа CQRS. При таком подходе типичная транзакция затрагивает только топики Kafka и выглядит так...
OhSirius
Еще есть интересный вариант - хранить offset-ы Kafka в БД, который позволяет не делать poller. Но наверное имеет проблемы с масштабированием, т.к. вы замыкаетесь на одну БД.
svaor Автор
Я сходу не понял, что нам даёт значение смещения в Kafka... Можно поподробнее описать Ваш вариант?
OhSirius
Имел ввиду, что организация распределенных транзакций через Кафка имеет много болерплейта и сложностей (вы их разобрали)
Хочется что-то вроде гарантии exactly ones для событий + единая транзакция для бизнес моделей в БД. Наткнулся на интересную статью, которая решает ряд проблем за счёт хранения offsets-ов Kafka вне брокера прям в БД
https://medium.com/p/91042e81c095
svaor Автор
Прочитал по диагонали. Насколько я вижу, речь идёт о получении сообщений из Kafka и отражении полученной информации в Postgres. В моём тексте это первый кейс, покрываемый за счёт ключей идемпотентности. На medium, если я правильно понимаю, в качестве ключа идемпотентности используется смещение и топик. Вполне допустимо в общем случае, как мне кажется.
Poller же требуется для кейса выгрузки данных из PostgreSQL в Kafka, то есть в обратную сторону.
OhSirius
В своих проектах тоже использовал ключи идемпотентности, но всегда хотелось как-то более бесшовно интегрировать Kafka в бизнес-процессы. Например, можно было "забить" на poller + таблицу очередь и сразу отправлять события, если использовать гарантии доставки exactly once - в этом случае события, кот. отправляет продюсер маркируются транзакцией Kafka и будут доступны всем коньюмерам уже после фиксации офсетов консьюмеров. А если добавить офсеты в базу, то ключи идемпотентности вообще не нужны чисто теоретически.
svaor Автор
Мне кажется, какая-то путаница возникла.
Ключи идемпотентности нужны при взаимодействии Kafka->DB. Смещение в этом кейсе – это и есть ключ.
Poller нужен при взаимодействии DB->Kafka.
У Вас же всё смешалось в кучу...
OhSirius
Пардон за поток сознания - что-то и хочу в этом роде - смешать базу и Kafka и получить все из "коробки": расширить возможности ACID-транзакций базы транзакциями Kafka (как-то заюзать https://habr.com/ru/company/badoo/blog/333046/).