
Привет, Хабр! Минул еще один богатый на интересные научные результаты в области рекомендательных систем год. Крупнейшая конференция по рекомендательным системам RecSys 2021 в этом году приняла рекордные 49 статей в основную программу, 3 – в трек воспроизводимости и 23 исследования – в late breaking results.
В традиционном разборе RecSys в Одноклассниках в этом году приняли участие коллеги из других проектов VK. Вместе мы выбрали 11 самых интересных на наш взгляд статей и сделали их конспекты, а теперь как и в прошлом году, делимся ими с вами.
Large-Scale Modeling of Mobile User Click Behaviors Using Deep Learning от @netcitizen
Matrix Factorization for Collaborative Filtering Is Just Solving an Adjoint Latent Dirichlet Allocation Model After All от @killjoykin
Accordion: A Trainable Simulator for Long-Term Interactive Systems от @anokhinn
Reverse Maximum Inner Product Search: How to efficiently find users who would like to buy my item? от @fanatique
Partially Observable Reinforcement Learning for Dialog-based Interactive Recommendation от @DaryaNikanorova
Learning a Voice-based Conversational Recommender using Offline Policy Optimization от @Nord786
Learning to Represent Human Motives for Goal-directed Web Browsing от @pekshechka
Denoising User-aware Memory Network for Recommendation от @pekshechka
A Case Study on Sampling Strategies for Evaluating Neural Sequential Item Recommendation Models от @ivan_bragin
A Constrained Optimization Approach for Calibrated Recommendations от@ivan_bragin
Follow the guides: disentangling human and algorithmic curation in online music consumption от @goodamigo
Large-Scale Modeling of Mobile User Click Behaviors Using Deep Learning
Работа зацепила постановкой задачи. В рекомендациях чаще всего мы работаем с отбором контента внутри какого-то приложения, а в этой статье авторы из Google Research берут уровень выше и пытаются смоделировать пользовательское поведение на мобильных устройствах с привязкой скорее к форме интерфейса, а не к его содержанию.
Краткое содержание
Пользовательское поведение авторы рассматривают как сессии состоящие из последовательности кликов по управляющим элементам.
В подобных данных обычно есть две основные проблемы: много разных приложений и разнообразный UI. Предыдущие подходы рассматривали UI-элементы как токены для языковой модели, но элементы слишком разные и их сложно генерализовать. Вторая - юзеры могут постоянно прерываться на переключения в другие приложения, что затрудняет подготовку чистых сессий для обучения и ухудшает предсказания.
В предложенном в статье подходе не нужен словарь UI-элементов и есть возможность докидывать в модель другие важные фичи, описывающие состояние среды.
Для исследования авторы с помощью 4000+ добровольцев и специального ПО, собрали датасет на 20 млн кликов сделанных в 13000+ разных приложениях.
Архитектура предложенной модели представляет собой каскад трансформерных энкодеров, который сначала кодирует историю предыдущих кликов пользователя, а затем, конкатенируя их с фичами глобального контекста вроде времени, дня недели и др., подает ее на вход глобального энкодера последовательности. Выход энкодера последовательности подается на вход генератора указателя, который уже используется для предсказания кликов.

Для честного сравнения с предыдущими подходами авторы воспроизвели самые успешные методы для решения подобных задач и побили их результаты по точности с хорошим отрывом. По итогу получилось достичь 48% и 71% точности для топ-1 и топ-3 предсказаний. Распределение точности внутри приложений получилось довольно ровное, разве что по понятным причинам не удалось предсказывать клики по кнопкам в приложении Калькулятора.
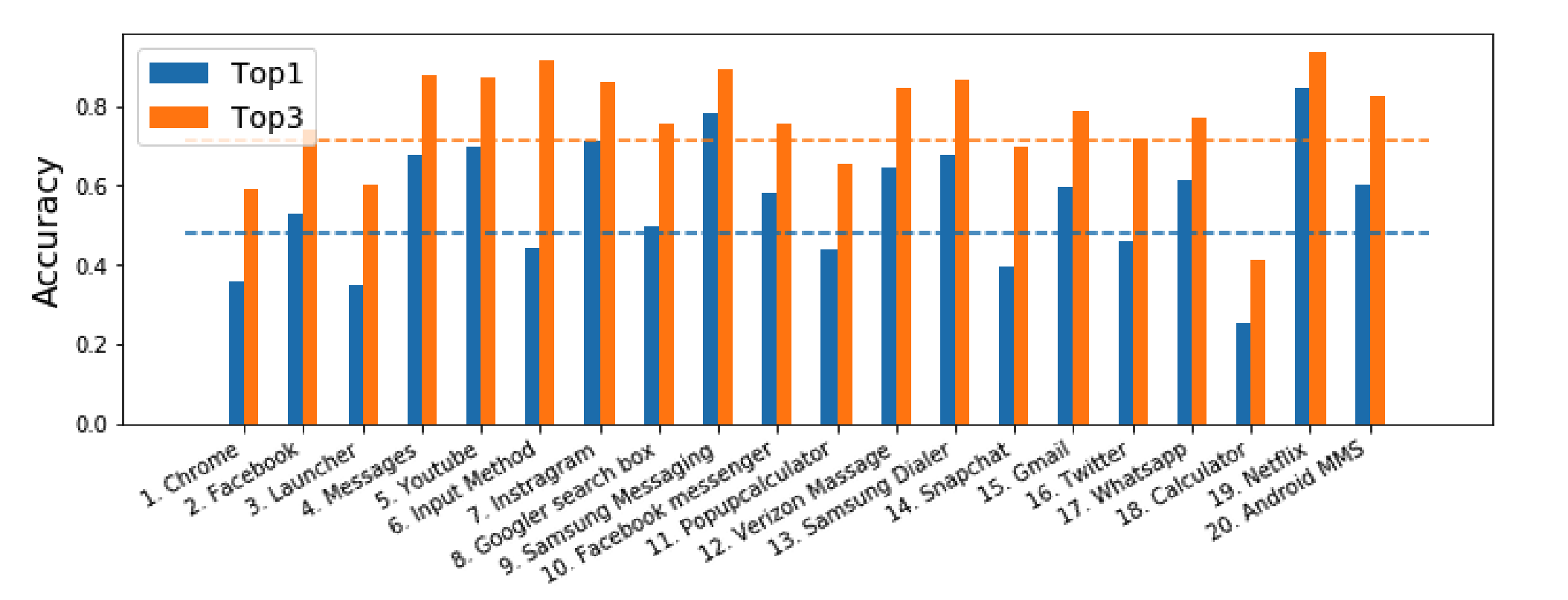
Выводы
Использовать эту модель можно напрямую, завернув ее в продукт. Среднее число последовательных переходов по управляющим элементам до нужного при голосовом управлении мобильным устройством составляет 9.04 перехода, а при использовании ранжирования вероятностей от этой модели можно снизить этот показатель до 2.61.
Предсказания модели можно использовать опосредованно, например, для заблаговременной предзагрузки ресурсов, если есть большой шанс, что пользователь нажмет на соответствующий управляющий элемент.
Matrix Factorization for Collaborative Filtering Is Just Solving an Adjoint Latent Dirichlet Allocation Model After All
В последнее время всё чаще возникает потребность том, чтобы объяснить, как тот или иной алгоритм машинного обучения принимает решения. Статья обещает дать интерпретацию эмбеддингам матричной факторизации.
Краткое содержание
В алгоритмах матричной факторизации (МФ) для каждого пользователя и каждого айтема необходимо дать числовую оценку, по которой потом проводится ранжирование айтемов в соответствии с предпочтениями пользователей. Причём используется вариант

В статье авторы приводят собственную модификацию латентного размещения Дирихле для рекомендательных систем. Затем они показывают, что по эмбеддингам МФ можно получить неотрицательные эмебеддинги пользователей и айтемов, которые вводят такое же упорядочивание, что и исходные. После этого приводится доказательство, что полученные неотрицательные эмбеддинги могут выступать параметром категориального распределения в порождающем процессе модели авторов.
Предполагается, что существует несколько латентных когорт пользователей, причём внутри каждой когорты частоты встречаемости айтемов фиксированные (подбираются в процессе обучения модели). Для каждого пользователя из распределения Дирихле сэмплируется параметр тета, который отвечает за принадлежность пользователя к когортам, а далее выполняется следующий порождающий процесс построения пула рекомендаций:
1) сэмплируется когорта из категориального распределения с параметром тета;
2) сэмплируется айтем из категориального распределения, учитывающего частоты встречаемости взаимодействий с айтемами в когорте, популярность айтема и желание пользователя получать рекомендации.

По мнению автора параметры фи, лямбда и дельта имеют логнормальные распределения, параметры которых также подбираются в процессе обучения.
Какие остаются вопросы
Нельзя быть уверенным, что объяснение тематического моделирования на языке смеси распределений будет более понятно для пользователей, чем объяснение на языке эмбеддингов.
Нет сравнения описанной модели с какими-либо методами, кроме методов матричной факторизации.
Accordion: A Trainable Simulator for Long-Term Interactive Systems
Онлайн эксперименты – рискованное занятие: когда изменения, которые мы тестируем, плохие, бизнес теряет пользователей и деньги. Авторы статьи предлагают обучить симулятор, который можно запускать офлайн и тестировать гипотезы безопасно для бизнеса. Выводы, полученные на этом симуляторе, точнее, чем выводы, полученные на других.
Детали
Симулятор - это система, которая умеет генерировать историю взаимодействия пользователя с сервисом. История состоит из записей вида время визита, ИД пользователя, рекомендация, реакция. Симуляторы, которые существовали раньше, либо были основаны на эвристиках, либо обучались только предсказывать реакцию пользователя на рекомендации. Авторы предлагают модель, которая умеет вдобавок генерировать реалистичное время визита. Время визита важно учитывать, потому что оно отражает, как пользователь реагирует на систему: если пользователь приходит часто, значит сервис нравится; а если все реже, то пользователь скоро уйдет. В итоге симулятор содержит три модели: модель времени визита, модель-имитатор рекомендера и модель, которая предсказывает реакцию пользователя на рекомендацию.

Ключевой элемент статьи - модель времени визита. Именно из-за нее предложенный симулятор точнее остальных. Время визита моделируется как сумма нескольких негомогенных пуассоновских процессов: таких, в которых частота возникновения события меняется со временем. Частоты каждого из этих пуассоновских процессов вычисляются feed-forward сетями, у которых на входе время и признаки, зависящие от предыдущей истории пользователя. Для этой модели получилось выписать функцию правдоподобия и оптимизировать её приближенно. Авторы предложили эффективный алгоритм сэмплирования из симулятора, основанный на технике rejection sampling.
В экспериментах авторы используют симулятор для двух задач: настройки гиперпараметров рекомендательной системы и предсказания результатов A/B теста. В первой задаче симулятор оказался более чувствительным к гиперпараметрам рекомендера, чем симулятор, который не учитывает время визита пользователя. Во второй задаче симулятор предсказал результат теста более точно, чем техника Norm-IPS.
Какие остались вопросы
Я не совсем понял из статьи, как соотносится выученная модель, имитирующая рекомендер, и рекомендеры, используемые в экспериментах. Либо это компоненты, которые существуют независимо, либо в экспериментах первое заменяется на второе.
Что можно использовать
Модель предсказания времени визита выглядит многообещающе - она может быть полезна, например, в задаче предсказания оттока.
Reverse Maximum Inner Product Search: How to efficiently find users who would like to buy my item?
Предпосылки:
задача рекомендации айтемов пользователю уже решена с помощью FM;
нужно быстро находить наилучшие рекомендации в реал-тайм проде;
пользователи и айтемы представлены векторами одинаковой размерности;
максимизация полезности происходит в пространстве дот-продакта векторов.
Нужно максимально быстро найти пользователей, для которых выбранный айтем будет входить в топ рекомендаций (k-Maximum Inner Product Search)
Приложения:
вовремя бустить новинки / скидочные товары / залежавшиеся на складе и т.д. в каталоге, рекомендациях, рекламе;
автороцентрированные рекомендации - работа над равномерностью рекомендаций авторов / магазинов в маркетплейсе и т.п.
Решение
Предлагается алгоритм Simpfer, обходящий по скорости не только проблемные и не очень эффективные решения (tree-index, LSH, straightforward MIPS), но и продвинутые поиски LEMP и FEXIPRO на несколько порядков.
Алгоритм имеет две части: оффлайн-препроцессинг и онлайн-поиск.
Оффлайн-препроцессинг строит необходимые для онлайн части структуры данных, суть которых заключается в возможности мгновенной O(1) фильтрации пользователей, для которых query item точно не попадёт в k лучших рекомендаций. Внутри этих структур данных лежат предпосчитанные теоретические нижние границы дот-продакта для каждого пользователя.
Также одна из наиболее важных структур, существенно ускоряющая вычисления - блоки, на которые бьются пользователи (размер - эвристика) таким образом, чтобы в онлайн части можно было убирать блок пользователей из рассмотрения за O(1), а не за O(размер блока).
Онлайн-поиск, основываясь на построенных структурах данных и на неравенстве Коши-Шварца (неравенстве треугольника), находит всех пользователей, рекомендации которым содержали бы query item, эвристически существенно быстрее, чем остальные известные алгоритмы (хотя теоретически верхняя граница времени вычисления совпадает с линейным поиском).
Чем заинтересовало?
Постановка задачи - поиск пользователя, для которого айтем окажется наилучшим, - намного ближе к бизнесу, чем косвенное "сделаем лучше пользователю, будет лучше нам". Вдобавок, я раньше мало что слышал про быстрый поиск в пространстве Inner Product, кроме как tree-index и LSH; а они, оказывается, помимо своих стандартных больных мест (проклятие размерности) ещё и медленные. Реал-тайм требует сублинейной сложности по времени, и этот алгоритм эвристически такую производительность даёт.
Какие увидел проблемы?
Вроде решение ищут строгое, но вот почему происходит сортировка по норме векторов (с фразой "чем больше норма, тем больше дот-продакт"), я не очень понял. Вроде ведь ещё угол важен, а он вообще 90° может быть.
Не сравнивали перфоманс с "приблизительными" алгоритмами (которые не ищут строгое решение) с формулировкой "мы же ищем строгое". Было бы интересно сравнить.
-
Перфоманс зависит от распределения векторов. Например, на датасете Yahoo! при увеличении CPU после 4 шт. прирост скорости практически нулевой. Вдобавок, не увидел никаких гипотез / объяснений на тему "почему так происходит". То есть поднимаются вопросы:
применимости в самый первый раз (затрат много, а стоит ли оно того)
применимости каждый следующий раз (распределение-то может съехать)
Partially Observable Reinforcement Learning for Dialog-based Interactive Recommendation
Интерактивные рекомендательные системы используют фидбек пользователя для подбора наиболее релевантного объекта. Сессия проходит следующим образом: пользователь отправляет запрос, рекомендер выдает подходящий объект. Если пользователь недоволен рекомендацией, он может дать рекомендеру уточняющий комментарий, содержащий информацию о том, по каким именно критериям рекомендованный товар не похож на желаемый. После нескольких подобных итераций, рекомендер показывает желаемый объект, и довольный пользователь завершает сессию.
В реальности сессия может затянуться и не привести к успеху. Во-первых, рекомендер склонен показывать одни и те же товары, во-вторых, с увеличением длины сессии рекомендер постепенно “забывает”, какой фидбек он получал ранее. В результате длина сессии и объем фидбека пользователя не конвертируется в успех, так как рекомендер способен построить рекомендации лишь на основании небольшой части недавних комментариев.
Long story short, авторы статьи применили Q-learning, позволяя рекомендеру делать более точные и полные выводы о предпочтениях пользователя, основываясь на всем фидбеке пользователя, собранном за сессию. Кроме того, они добавили простой фильтр, который отсекает айтемы, которые уже были рекомендованы, избавляя таким образом пользователя от повторяющихся рекомендаций.
Детали
Нетрудно догадаться, что подобные рекомендательные системы работают на основе обучения с подкреплением (Reinforcement learning, RL), где в роли агента выступает сам рекомендер, который совершает определенные действия - строит рекомендации, а возможные состояния среды определяются предпочтениями пользователя. Наградой рекомендеру служит увеличение ранга нужного айтема в течение сессии. Одним из примеров рекомендательных систем, использующих RL, является фреймворк Supervised Q-learning (SQN). Ключевым моментом является сочетание multilabel классификации и Q-learning слоя. Прелесть алгоритма заключается в том, что в качестве награды можно использовать все что угодно - клики, лайки, покупки - в общем, любой интересующий нас таргет.
По сути, авторы использовали готовый фреймворк SQN, используя в качестве награды линейную комбинацию двух наград: первая присуждается за увеличивающуюся в течение сессии схожесть рекомендованного айтема с целевым, а вторая поощряет за растущий ранг наиболее релевантного айтема в течение сессии. Итоговая функция потерь представляет собой комбинацию кросс-энтропии и one-step Temporal Difference (TD) error - лосс функции Q-learning слоя.
Результаты
Качество модели определяли с использованием метрик ранжирования NDCG@k, MRR@k и SR, на двух датасетах: Shoes и Fashion IQ dress. Предложенная модель работает лучше существующих. Интересно, что простое добавление фильтра против повторяющихся айтемов улучшает рекомендации и для уже существующих моделей. Кроме того, интересен вклад двух гиперпараметров модели: γ - отвечающей за то, насколько далекую награду агент будет учитывать и α - взвешивающий фактор для двух наград. Изменения γ возможны в пределах [0, 1], где γ = 0 означает, что модель учитывает только сиюминутный выигрыш, тогда как γ = 1 показывает, что агент учитывает всю возможную награду в будущем. В свою очередь, при α = 0, агент поощряется только за правильное ранжирование, а при α = 1, мы хвалим агента только за схожесть между рекомендуемым и желаемым объектом. Оказалось, что оптимальным значением γ в обоих случаях является 0.7, а вот оптимальное значение α варьирует, что еще раз доказывает необходимость подбора гиперпараметров модели при обучении.
Что можно применить
В целом, интересная механика сессии, которая способна облегчить пользователю процесс поиска товара на витрине (при условии, конечно, что процесс не затянется).
Learning a Voice-based Conversational Recommender using Offline Policy Optimization
В статье рассказывается о том, как в диалоговой системе (колонке) можно решить задачу подбора релевантной музыки для юзера, особенно когда нет какого-то визуального интерфейса, чтобы предложить варианты из чего выбрать. Так как пользователи колонок привыкли вести диалог с устройством, можно сделать отдельную команду “Алекса, помоги мне найти музыку” и колонка начнет с пользователем диалог - задавая вопросы вида:
Предложить послушать сэмпл трека - “How about this $track_sample Did you like it?” (положительный ответ на этот вопрос запускает похожую музыку - то есть он всегда последний в успешном диалоге).
Про настроение - “Something laid back? or more upbeat?“
Про жанры - “May I suggest some alternative rock? or perhaps electronic music?“
Про артистов - “How about $artist?”
Спрашиваем про настроение, жанр, артиста, эпоху - “Can you think of a mood or tempo you’d prefer? “
Открытый вопрос - “Do you have anything in mind?”
Каждый из этих вопросов формируется отдельно и для его формирования передается контекст юзера и его предыдущие ответы - на базе них и выбирается какой сэмпл музыки, жанр, артиста, настроение предложить. Далее надо выбрать какой из этих вопросов озвучить юзеру - изначально политика какие вопросы задавать и в каком порядке и тд была написана людьми в виде правил и задача стояла сделать это лучше при помощи ML.
Для обучения ML нужен был таргет - что такое хороший вопрос. Хорошим диалогом считается тот, в результате которого юзер включил и начал слушать музыку. Хорошим вопросом авторы предлагают считать не все реплики хорошего диалога, а только те - которые повлияли на итоговый сэмпл музыки, который согласился слушать юзер - по сути это положительные ответы на вопросы и если человек менял свое мнение про жанр или артиста - именно последнее мнение повлиявшее на выдачу. Таким образом получаем датасет хороших и плохих вопросов с учетом контекста.
В качестве фичей были взяты контекст диалога, тип устройства, история диалогов. Фичи диалога кодируются one_hot - тип вопросов предыдущих, one_hot тип ответа предыдущего (артист, жанр, эпоха, настроение).
На этих данных автор изначально пытался запустить различные алгоритмы связанные с reinforcement learning - Linear Thompson sampling contextual bandits, Neural bandits, Offline policy gradient - но в итоге наилучший результат получил на XGBoost модели.
В конечном счете ML решение вместо rule-bases в продакшене дало: +8% успешных диалогов, +18% прироста полезных фраз, -20% длина диалогов.
Learning to Represent Human Motives for Goal-directed Web Browsing
Авторы статьи (Microsoft Edge) ставят перед собой три основные задачи:
Рекомендация следующей страницы в веб-браузере Microsoft Edge. In-session Web Page Recommender.
Предсказание того, что пользователь вернется на страницу, которую он уже посещал в эту сессию. Re-visitation Prediction.
Группировка веб-страниц. Goal-based Web Page Grouping.
И все это с учетом “целей” юзера. Для этого они разработали архитектуру GoWeB (Goal-directed Web Browsing).
Под целями понимаются мотивы высокого порядка, такие как дружба, семья, здоровье. Цели имеют иерархическую структуру, эта иерархия была составлена авторами на основе нескольких статей по психологии.

Goal Estimator

Для представления иерархичной структуры существует прекрасный инструмент - эмбеддинги Пуанкаре. С помощью эмбеддингов Пуанкаре авторы статьи получают векторное представление целей.
Второй шаг - получение разметки страниц на классы (цели). Для этого авторы для каждой цели составляют ее описание, а затем используют описание как поисковой запрос. Выдача на запрос и есть позитивы: "We manually generate queries such as “how to be charismatic” and “how to meet new friends” to elicit the high-ordered goal of being likeable, making friends, drawing others near".
На основе такой разметки обучают Goal Estimator, который по бертовому представлению веб страницы и эмбеддингу хоста для каждой веб-страницы строит Visit Goal Representation (vGoalRep).
Архитектура модели GoWeB

В основе модели Goal-aware Browsing Session Modeling лежит multi-head self-attention поверх сессии юзера. Но в отличие от моделей типа Bert4Rec, SASRec, в качестве векторов страниц используется не просто обучаемый эмбеддинг айтема, но также и бертовое представление текста страницы
В основе Personal Goal Modeling также лежит механизм внимания. Целевые представления (gVisitRep) страниц текущей сессии агрегируются с помощью аттеншена. Полученный вектор используется в качестве query в аттеншене поверх целевых представлений страниц из всей истории пользователя. Таким образом получается вектор pGoalRep, который является session-aware репрезентацией целей юзера.
Итак, три задачи
In-session Web Page Recommender. Выбирают из топ-50к страниц веба. Для каждого кандидата получают gVisitRep страницы, подставляя последним в сессию. Если есть вектор юзера (pGoalRep), то gVisitRep конкатенируют с ним, используют пару dense слоев и предсказывают скор.
Re-visitation Prediction. Берут эмбеддинг юзерской сессии (gSessionRep - cls эмбеддинг), конкатенируют с эмбеддингом страницы от gVisitRep, используют пару dense слоев и предсказывают вероятность возвращения на страницу.
Goal-based Web Page Grouping. Кластеризация поверх vGoalRep.
Бенчмарки
На своем внутреннем датасете побили все SOTA модели вроде Bert4Rec, SASRec. Но стоит отметить, что эти модели не использовали семантическое представление страниц, а только обучаемые эмбеддинги страниц. Для более честного сравнения авторы ввели еще один бейзлайн - SemRec, архитектура которого почти полностью совпадает с GoWeB, за исключением того, что никаким образом не использует цели. SemRec оказалась лучшим из бейзлайнов, но GoWeB побил ее результаты на 15%
Что понравилось
Неожиданная и интересная идея, если это реально работает, то очень круто.
С алгоритмической точки зрения компоненты модели не особо оригинальные, но если есть хорошие стабильные алгоритмы, то зачем усложнять.
Есть инфографика по целям.
Чего хотелось бы / не понравилось
Все бейзлайны, с которыми сравнивались - коллаборативные модели. Единственный контентный бейзлайн основан на той же архитектуре, что и GoWeB. Вообще интересно было бы посмотреть, что будет, если использовать другие архитектуру, добавив в них контентный эмбеддинг.
Работает только с английским языком (описание целей на английском, значит и классифицировать по целям хорошо умеют только страницы на английском). Грустно, что разработчики глобального сервиса не мыслят глобально.
Denoising User-aware Memory Network for Recommendation
В статье описывается Sequence-based recommendation system с двумя подзадачами:
денойзинг (неявного фидбека - кликов и просмотров);
учесть long-term пользователя.

Входные данные - последовательность эмбеддингов кликов и просмотров (неявный фидбек), лайков и дизлайков. Эмбеддинги юзера и айтема - кандидата последовательности проходят через multi-head self-attention. Далее идет “денойзинг” кликов и просмотров. Потом добавляется long-term через memory механизм. Затем все финальные эмбеддинги конкатенируются и предсказывается скор айтема.
Multi-head self-attention

На скрине приведены формулы подсчета вектора кликов. (1) - (2) представляет собой обычный mhsa для получения session-aware эмбеддингов айтемов сессии oj.
На (3) - (5) происходят странные вещи.
Во-первых, авторы используют relu перед софтмаксом - я лично не знаю смысла использовать две нелинейности подряд, и даже если он есть, было бы неплохо о нем рассказать.
Во-вторых, авторы используют обычный, ванильный аттеншен. Проблема такого подхода в том, что скор аттеншена aj должен понять значимость айтема для сессии. Но при этом через входные данные (эмбеддинг юзера, таргета, айтема) модели сложно уловить значимость айтема для сессии. Да, oj может неявно содержать в себе эту информацию, но тем не менее, это явно не лучший метод построения эмбеддинга сессии.
Есть метод через cls эмбеддинг (правда, желательно сделать несколько слоев аттеншена), есть mean pulling. Можно использовать в качестве query эмбеддинги юзера и/или таргета, что с учетом того, что задача не построить эмбеддинг сессии, а определить скор айтема, кажется наиболее оптимальным решением.
Также отмечу, что конкатенация - не самый лучший способ для feature interaction, не просто так в query-attention используется дот-продакт.
Такой подход авторов наталкивает на мысль, что они не до конца понимают, как работает mhsa и в чем его основные преимущества.
Feature Orthogonal Mapping Component (denoising)
(Denoise на схеме)
Авторы считают клик неявным позитивным фидбеком, а просмотр (без клика) - неявным негативным. Но этот фидбек, по их мнению, сильно зашумлен. Для того, чтобы избавиться от шума, они делают ортогональную проекцию кликов на дизлайки (и просмотров на лайки), чтобы новый вектор кликов был ортогонален вектору дизлайков. Ортогональность кажется мне спорным решением. Ортогональность - полная независимость векторов. Но есть смещение потребления, люди редко смотрят нерелевантный контент, соответственно редко его дизлайкают. Если вы смотрите чехлы на телефон и дизлайкаете чехлы с аниме, то едва ли ваша «проекция» будут чехлы с медведями. Там будет что-то типа семян для рассады.
Я бы не стала делать такое жесткое раздвижение и попробовала учесть вектор дизлайков в аттеншене, а потом наложить штраф на косинус между векторами кликов и дизлайков. Штрафы лучше жестких правил.
Не до конца понимаю, откуда у авторов уверенность, что вектора будут в одном пространств, потому что сеть не сиамская, а эмбеддинги сессии были получены независимыми преобразованиями.
User Memory Network Layer
Авторы не хранят эмбеддинг истории юзера напрямую, а строят кэширование, используемое в Neural turing machines. И пытаются восстановить старую сессию, используя текущую. Такой подход мог бы объясняться ограничениями по памяти (эмбеддинг юзера, который используется в модели, сильно меньше по размерности чем эмбеддинг сессии), но авторы говорят, что причина - this way is more generalized than using only user_id embedding. Но доказательства их словам не приводят.
Preference-aware Interactive Representation Component

Для того, чтобы объединить long-term и текущую сессию пользователя, авторы используют механизм гейтов, знакомый многим по LSTM, правда после этого не складывают вектора, а конкатенируют их (не очень понятен смысл гейтов в этом случае). При этом необходимость линейного преобразования объясняется тем, что вектора должны быть одинаковой размерности, но и внутри сигмоиды, и снаружи используется один и тот же вектор, так что это объяснение выглядит несостоятельным.
Моё мнение
Несмотря на то, то авторы утверждают, что значительно побили все модели по всем параметрам и каждый их invention, вроде денойзинга, улучшает показатели модели, у меня есть сильные сомнения на этот счет. Несмотря на то, что в тексте статьи указано, что The code of model has been uploaded as an additional material, в открытом доступе я его не нашла.
A Case Study on Sampling Strategies for Evaluating Neural Sequential Item Recommendation Models
В статье рассматривается проблема сравнения алгоритмов рекомендаций в современных статьях. При подсчете метрики качества бывает сложно отранжировать все объекты для каждого юзера. Обычно при создании валидационного сета используются все релевантные юзеру объекты и некоторый поднабор нерелевантных объектов. Таким образом, по каждому пользователю оценивается метрика, основываясь на ранжировании только части нерелевантных объектов.
Тема уже поднималась в прошлые годы, и в этом году авторы перепроверили SOTA алгоритмы, используя различные методы сэмплирования.
Подход к проверке
Задача авторов заключается в том, чтобы подтвердить или опровергнуть возможность честно сравнивать алгоритмы, используя поднабор нерелевантных объектов. Чаще всего используются два подхода:
равновероятно выбираются k=1000 нерелевантных объектов;
также выбирается k=1000 нерелевантных объектов, но вероятность попадания в выборку зависит от популярности объекта.
Необходимо проверить, будут ли лучшие алгоритмы, оцененные на части объектов, оставаться лучшими, если их оценить на всем наборе объектов.
Оценка результатов
Для проверки авторы воспроизвели статьи по BERT4Rec, GRU, NARM, SASRec, и посчитали метрики на нескольких популярных датасетах, используя различное семплирование.

Из таблицы видно, что при сэмплировании по популярности всегда побеждает BERT4Rec, но при подсчете метрики без семплирования лидеры меняются и в одном случае даже побеждает GRU.
Может мы просто взяли маленькую k, поэтому получили нечестные результаты?
Давайте посмотрим, как меняются позиции алгоритмов при использовании разных k. Рассмотрим пример на одном датасете Amazon Beauty, а остальные можно увидеть в оригинальной статье.

Видно, что имея k=25000 при максимальном 40000 мы не можем честно определить, какой алгоритм находится на 3-й, а какой - на 4-й строчке.
Выводы
При анализе стоит обратить внимание на то, какой использовался подход при подготовке валидационного датасета, BERT4Rec не всегда побеждает при честном сравнении. Для честного сравнения можно использовать только все объекты, так как даже при большом k остается высокий шанс ошибиться.
A Constrained Optimization Approach for Calibrated Recommendations
Задача рекомендательных систем не только в повышении точности модели, но и в оптимизации других показателей, например fairness, popularity, diversity. Один из интересных показателей который был представлен на RecSys 18, - calibration. Идея в том, чтобы в рекомендациях показывать типы объектов в той же пропорции, в которой пользователь их смотрел или лайкал.

С чем будем сравнивать
В 2018 году было предложено решение на основе жадного добавления k элементов, максимизируя сумму скоров модели и минимизируя KL-distance.
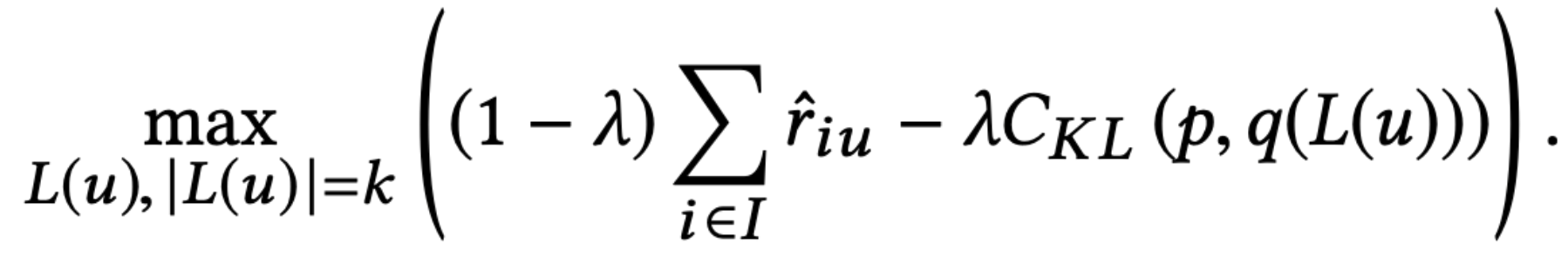
Параметр lambda отвечает за соотношения важности калибровки и качества модели.
Собирать топ-k объектов жадным алгоритмом неоптимально, в статье предлагают искать оптимум в значительно большем пространстве вариантов.
Предложенный алгоритм
Для оптимизации авторы статьи выбрали библиотеку gurobi Branch and bound алгоритм. В качестве функции оптимизации выбрали очень похожий подход, но вместо KL-distance использовали L1 норму между распределениями. По словам авторов, такая функция проще для понимания и быстрее при оптимизации.
Оценка результатов
На графиках новый предложенный алгоритм обозначается Opt, жадный алгоритм обозначается H. Можно заметить, что максимальное значение precision и recall достигаются в новом алгоритме. Что более интересно, значения precision и recall максимальны при lambda != 0. Это значит что калибровка не только выравнивает распределение типов, но и улучшает качество модели.

Значение KL-distance тоже получаем лучше, хотя в новом алгоритме не оптимизируем его непосредственно.
В оригинальной статье можно увидеть графики, показывающие, что калибровка положительно влияет на другие важные показатели: fairness, popularity, diversity.
Выводы
Калибровка - это не сложная в реализации техника, которая может дешево повысить различные важные метрики ранжирования.
Follow the guides: disentangling human and algorithmic curation in online music consumption
В статье оценивается влияние рекомендательной системы на разнообразие потребляемого пользователями контента на примере музыкального сервиса. Авторы рассматривают разные сценарии поведения пользователей в зависимости от интенсивности пользования рекомендациями. Также авторами проводится сравнение с рекомендациями которые составляют люди. Подобное сравнение выглядит интересным, поскольку рекомендательные системы регулярно критикуются за формирование “контентных пузырей” и хотелось бы понять насколько данная критика обоснована.
Детали
Авторы рассматривают историю прослушивания пользователей на музыкальном сервисе и пытаются разделить пользователей в несколько когорт по поведению. Сценарии прослушивания разделяются на три вида:
Алгоритмический - прослушивание треков рекомендованных алгоритмом;
Редакторский - прослушивание редакторских подборок от экспертов;
Органический - прослушивание музыки через прямой поиск треков и исполнителей. Прослушивание своих плейлистов.
Для каждого пользователя строится вектор его активности из долей пришедших от конкретного сценария треков по отношению ко всем трекам. Полученные вектора кластеризуются k-means с k=4. Выделяются несколько основных когорт пользователей:
Алгоритмическая (a) - преимущественно слушают треки пришедшие от рекомендательной системы;
Редакторская (e) - преимущественно слушают треки по экспертным сборкам;
Органический (o) - преимущественно слушают треки по органическому сценарию, но также пользуются и другими источниками;
Органическая+ (o+) - преимущественно слушают треки по органическому сценарию, крайне редко пользуются другими источниками.
Авторы рассматривают разнообразие прослушивания треков через разброс, вычисляемый по формуле S/P, где S - количество уникальных треков, P - общее количество прослушанных треков. Для (a) пользователей дисперсия при фиксированном количестве прослушиваний самая высокая, для (о) она чуть ниже, для (е) еще ниже, самая низкая у (o+). Это позволяет говорить что рекомендательные системы дают наибольшее разнообразие по трекам.
Затем авторы рассматривают дает ли когорта пользователя сдвиг на популярных авторов. Исследование показало что пользователи, слушающие преимущественно редакторские выборки (е) имеют сдвиг в сторону треков от более популярных авторов. Далее авторы сравнивают профили прослушивания пользователей с историей ротации треков на различных музыкальных радиостанциях. Разные станции показали близость к различным сценариям поведения, поэтому авторы делают вывод о том что в целом пользовательские сценарии прослушиваний треков на сайте по заданным статистикам не выделяются из наборов радиостанций.
Вопросы и замечания
Авторы не рассматривают возможность того, что некоторые пользователи могут быть ботами, созданными с целью раскрутки треков. Это могло бы объяснить большое количество o+ пользователей - боты слушают целевые треки. Тем не менее, боты могут демонстрировать и другие сценарии поведения, которые могут существенно влиять на результаты. Однако стоит отметить, что частичной защитой от ботов является то, что авторы выбрали только платных подписчиков.
При рассмотрении радиостанций авторы считают статистики по сценариям поведения пользователей против статистик конкретных радиостанций, что может показаться некорректным - статистики по сценариям гораздо более усреднены чем статистики по одной радиостанции. Авторы не рассматривали жанровую составляющую среди сценариев поведения пользователей, однако при сравнении с радиостанциями этого не хватает.
Заключение
Подводя итоги разбора, можно выделить несколько общих впечатлений прошедшего RecSys:
Доминирование трансформеных моделей становится еще более очевидной теперь и для рекомендательных систем.
Расширяется спектр областей и сценариев применения рекомендательных систем, описываемых в статьях, благодаря большему вовлечению индустрии.
В области рекомендательных систем на данный момент растет число качественных исследований: в этом году в основной трек было принято 49 статей против 39 в прошлом году. При этом география авторов довольно обширная (в том числе есть статья от коллег из России).
pekshechka
Кстати а почему авторы A Case Study on Sampling Strategies for Evaluating Neural Sequential Item Recommendation Models не считают, что причина в лоссе?
Разница между BERT4Rec и SASRec (кроме BERT > SA) только в лоссе. Причем интуитивно ожидаемо, что на сходимость/стабильность/ и т д бинарной кросс-энторпии из сасрека количество сэмплов плохо повлиять не может, на вот на софтмакс-лосс из BERT4Rec может. Возможно именно поэтому SASRec оказывается лучше берта при большем количестве сэмплов
pekshechka
Авторы пишут, что SASRec uses the BPR loss. Лол, это не так. В бпр сигмоида разницы предсказаний, а в сасреке обычная кросс-энтропия для каждого предсказания отдельно
pekshechka
Статьи все больше разочаровывают((
pekshechka
Не, я и так люблю авторов статьи про BPR за то, что они назвали свой алгоритм Bayesian из-за байесовского объяснения л2 регуляризации. Но то, что кто-то решил, что они придумали кросс-энтропию - это двойное уважение