
Вместо вступления
Когда заходит речь об обслуживании сетевого оборудования дата-центра, на ум сразу приходит слово "автоматизация". Действительно, вряд ли кому-то захочется вручную настраивать десятки, а то и сотни единиц "железа", особенно учитывая то, что конфигурация будет практически идентичной. Сейчас существует множество инструментов, чтобы формализовать и автоматизировать этот процесс - можно задействовать всю мощь bash-скриптинга и поддерживать пачку скриптов, можно воспользоваться Ansible с его плей-буками и еще много чего. Я же решил, что в деле автоматизации настройки и поддержики конфигурации в нужном состоянии поможет Kubernetes с его Custom Resources и самописными операторами.
Дисклеймер: приведенные ниже куски кода не претендуют на работоспособность, а призваны лишь иллюстрировать общую концепцию и еще разбавить повествование цветными вставочками.
С чего все началось
Первоначально, в голову пришла мысль "хочу, чтобы коммутаторы были настроены без моего участия, подключил и готово", поэтому пришлось потратить некоторое время на формулирование требований и ожидаемого конечного результата. Тут нужно сделать небольшое отступление и уточнить, что в качестве конечных устройств я буду рассматривать bare-metal свитчи с установленной NOS SONiС - это важно, потому что именно на тех возможностях, которые предоставляет SONiC, будет базироваться процесс настройки. А на SONiC выбор пал, потому что его можно запустить хоть в виртуальной машине, хоть в docker-контейнере, что весьма и весьма удобно в процессе тестирования и отладки. Однако, все по порядку.
Разберемся с тем, что мы хотим получить в сухом остатке и начнем выяснять, что для этого нужно. Конечный список требований:
отказоустойчивость
маршрутизация с использованием BGP
восстановление конфига, если он стал неактуален (перезагрузка, сброс вручную и т.п.)
обнаружение новых подключений - других свитчей и полезной нагрузки
Параллельно с разбором требований начнем развивать код нашего оператора.
Традиционно, для написания kubernetes-операторов используется ЯП Go и, в качестве генераторов кода
kubebuilderи/илиoperator-sdk(у которого под капотом все тот же kubebuilder). Все, что нужно, чтобы создать кастомный ресурс и обрабатывающий его контроллер - выполнить ряд команд с соответствующими параметрами:> operator-sdk init ...> operator-sdk create api --group ... --version ... --kind ... --controller --resource
Результатом будет структурированная папка с проектом, готовая для реализации пользовательской логики. В моем случае версия получила номерv1alpha1, а kind был названSwitch.
Также отмечу, что основным методом, отвечающим за обработку ресурса, выступает методReconcile(ctx context.Context, req ctrl.Request) (result ctrl.Result, err error) {...}
Отказоустойчивость
Первое требование не имеет прямого отношения к настройке свитчей, однако в значительной степени определяет, каким образом они будут между собой подключены. Для обеспечения упомянутой отказоустойчивости подключений, сеть гипотетического дата-центра будет представлять собой классическую Leaf-Spine сеть (достаточно хорошо описана в этой статье) - это, по одной терминологии "многокаскадная", по другой - "многоярусная", коммутационная сеть:

У нас есть «ярус» (или, скажем, уровень) за номером 1 – спайны самого высокого уровня, и «слой» 2, на котором расположились leaf’ы и edge-leaf’ы. Отличие между последними только в том, что через edge-leaf’ы происходит общение с внешним миром. По-хорошему, то, что на схеме названо «workload», не должно быть подключено к единственному коммутатору, но мешанина линий была бы лишней.
East-West vs North-South
На этом этапе нас не интересует трафик east-west, то есть тот, что ходит между устройствами, находящимися на одном уровне, будь то коммутаторы или серверы. Для нас гораздо интереснее north-south трафик, и даже не сам трафик, а интерфейсы коммутаторов, его передающие.
Тут становится понятно, зачем нужно определять на каком уровне находится коммутатор – чтобы назначить интерфейсу правильный адрес, надо знать, что находится на другой стороне провода. Если это сервер или нижележащий коммутатор, значит такой интерфейс будет «южным». Если же вышестоящий коммутатор, такой интерфейс будет «северным». В свою очередь от того, к какому «направлению» относится порт, зависит то, каким образом мы назначим ему IP адрес: если интерфейс «южный», он получит адрес из подсети назначенной коммутатору, если же интерфейс «северный» - ему назначит адрес его «северный» сосед.
Пора добавить все, что мы придумали, в структуру нашего ресурса:
type SwitchSpec struct {
Layer uint8 `json:"layer"` // порядковый номер "яруса", на котором расположился свитч
Interfaces map[string]*InterfaceSpec `json:"interfaces"`
SubnetV4 string `json:"subnetV4,omitempty"`
SubnetV6 string `json:"subnetV6,omitempty"`
}
type InterfaceSpec struct {
IPv4 string `json:"ipV4,omitempty"`
IPv6 string `json:"ipV6,omitempty"`
Direction string `json:"direction"`
}
BGP
Что нужно для настройки BGP? Идентификатор роутера - им будет loopback-адрес подопытного, номер автономной системы (далее для краткости ASN) и IP адреса на интерфейсах свитча. Адреса интерфейсов мы уже добавили, добавим loopback-адреса и ASN и дело в шляпе. Хотя если подумать - зачем нам хранить ASN, если его можно легко вычислить, взяв за основу loopback-адрес, в момент применения конфигурации? Поскольку адрес должен быть уникален, разнообразная машинерия для отслеживания свободных адресов, резервированию, освобождению и тому подобным действиям будет реализована в рамках IPAM. Считать будем учитывая следующее:
ASN должен быть из диапазона 4200000000-4294967294 (RFC6996)
Адрес для loopback (да и вообще все адреса свитчей) возьмем из подсети 100.64.0.0/10 (RFC6598)
Как будем считать ASN? У нас 94967294 свободных номеров и IP адрес. Как насчет того, чтобы перевести двоичное представление адреса в десятичное? Адрес содержит 4 двоичных октета, можем ли мы использовать их все? 2^32 = 4294967295, слишком много вариантов для нас. Отбросим первый октет - вспомним, что у нас подсеть 100.64.0.0/10, - он все равно меняться не будет. 3 оставшихся октета дадут 2^24 = 16777216 номеров (а на самом деле еще меньше, потому что второй октет в используемой нами подсети принимает значения от 64 до 127), что вписывается в наш диапазон. Итого:
Переводим значение трех последних октетов loopback-адреса из двоичного представления в десятичное
Прибавляем полученное значение к базе 4200000000
Получаем уникальный ASN 42XXXXXXXX
PROFIT!
В качестве примера рассмотрим адрес 100.64.11.19:
Его двоичное представление: 1100100.01000000.00001011.00010011 => отбросим первый октет, получим 01000000.00001011.00010011, и переведя в десятичное представление - 4197139 => итоговым значением будет 4200000000 + 4197139 = 4204197139
Вернемся к нашему ресурсу - добавим loopback-адреса.
type SwitchSpec struct {
...
LoopbackV4 string `json:"loopbackV4,omitempty"`
LoopbackV6 string `json:"loopbackV6,omitempty"`
}
...
Отслеживание состояния свитча
Помните, что наши коммутаторы - white-box'ы с SONiC'ом? Это позволяет нам запускать на свитче Docker-контейнеры и этим-то мы и воспользуемся. Запустим в контейнерах две утилиты: одна будет применять конфиг, вторая - собирать данные о портах свитча и отправлять их в наш management-кластер. На самом деле, SONiC позволяет даже больше - присоединить коммутатор к кластеру в качестве ноды и, таким образом, можно будет централизованно запускать наши утилиты на каждом свитче, используя daemonset'ы. Но пока что это в планах.
Остановимся на том, какие данные о портах будут собираться на свитче. Чтобы мы могли взаимно идентифицировать подключенные друг к другу свитчи - это будет нужно при назначении IP адресов - нам нужно знать какой-нибудь идентификатор устройства и порт, который используется для подключения. Все эти сведения можно получить, используя LLDP, чем мы и воспользовались. Таким образом, наш сборщик информации будет периодически собирать и отправлять обновленные данные LLDP по каждому порту свитча.
С интерфейсами связан еще один нюанс, влияющий на назначение адресов: в наших коммутаторах установлены QSFP трансиверы, каждый из которых может использовать от 1 до 4 каналов или по другой терминологии линий. От количества задействованных линий зависит, какое смещение будет у адресов подсети коммутатора при назначении адреса интерфейса. Для IPv4 нам нужна подсеть с префиксом 30 на интерфейс, использующий одну линию: первый и последний – адрес подсети и широковещательный адрес, второй и третий – адреса соответственно интерфейса и его «соседа». Таким образом, если есть интерфейс с 4 задействованными линиями, следующий за ним интерфейс получит адрес со смещением в 16 адресов.
Дополним наши структуры:
type SwitchSpec struct {
...
ChassisID string `json:"chassisID"`
}
type InterfaceSpec struct {
...
Lanes uint8 `json:"lanes"`
Peer *PeerSpec `json:"peer"`
}
type PeerSpec struct {
ChassisID string `json:"chassisID"`
PortID string `json:"portID"`
Type string `json:"type"`
ResourceReference ResourceReferenceSpec `json:"resourceReference,omitempty"`
}
type ResourceReferenceSpec struct {
APIVersion string `json:"apiVersion"`
Kind string `json:"kind"`
Name string `json:"name"`
Namespace string `json:"namespace"`
}
Кроме этого, чтобы применять конфиг только в том случае, когда его вычисление закончено, добавим поле хранящее состояние процесса обработки ресурса, а чтобы не применять конфиг, когда в нем нет изменений, будем также хранить статус "примененности" конфига. Заодно еще добавим флаг указывающий, запущен ли конфигуратор на свитче, и отметку о времени последней проверки конфига:
type SwitchSpec {
...
State string `json:"state"`
Configuration ConfigurationSpec `json:"configuration"`
}
type ConfigurationSpec struct {
Managed bool `json:"managed"`
State string `json:"state"`
LastCheck string `json:"lastCheck,omitempty"`
}
Кажется, мы учли все минимально необходимые сведения, которые нам понадобятся для настройки коммутаторов, но почему-то результат не удовлетворял. В какой-то момент я задумался, а что будет, если пользователь захочет изменить существующий ресурс каким-нибудь kubectl edit? Если бездумно изменить настройки коммутатора, можно и сеть положить, а этого бы хотелось избежать. В качестве ответа на этот вызов было решено перенести всю вычисляемую конфигурацию в статус ресурса - изменить статус банальным edit'ом уже не получится.
В итоге получается следующее:
type SwitchSpec struct {
ChassisID string `json:"chassisID"`
}
type SwitchStatus struct {
Layer uint8 `json:"layer"`
Interfaces map[string]*InterfaceSpec `json:"interfaces"`
SubnetV4 string `json:"subnetV4,omitempty"`
SubnetV6 string `json:"subnetV6,omitempty"`
LoopbackV4 string `json:"loopbackV4,omitempty"`
LoopbackV6 string `json:"loopbackV6,omitempty"`
State string `json:"state"`
Configuration ConfigurationSpec `json:"configuration"`
}
type InterfaceSpec struct {
Lanes uint8 `json:"lanes"`
IPv4 string `json:"ipV4,omitempty"`
IPv6 string `json:"ipV6,omitempty"`
Direction string `json:"direction"`
Peer *PeerSpec `json:"peer,omitempty"`
}
type PeerSpec struct {
ChassisID string `json:"chassisID"`
PortID string `json:"portID"`
Type string `json:"type"`
ResourceReference ResourceReferenceSpec `json:"resourceReference,omitempty"`
}
type ResourceReferenceSpec struct {
APIVersion string `json:"apiVersion"`
Kind string `json:"kind"`
Name string `json:"name"`
Namespace string `json:"namespace"`
}
type ConfigurationSpec struct {
Managed bool `json:"managed"`
State string `json:"state"`
LastCheck string `json:"lastCheck,omitempty"`
}
Reconciliation
Пора переходить к, собственно, вычислению конфигурации. Определимся с последовательностью шагов: поскольку все значимые данные расположились в статусе, у только что созданного ресурса он будет пуст, а значит первым делом надо проинициализировать статус начальными значениями. Мы не сможем правильно определить уровень, на котором расположился обрабатываемый свитч, если у нас не будет данных о его соседях, а они, в свою очередь будут получены из переданных сведений о текущем состоянии интерфейсов. Назначение IP адресов интерфейсов также зависит от значения уровня свитча, так как только после этого будет ясно, какие интерфейсы "южные", а какие "северные". При этом независимо от всего остального можно назначить loopback-адреса и, собственно, подсеть свитча. В итоге получилась такая последовательность:
Проверить статуса свитча и, если нужно, инициализировать статус
Проверить, нужно ли обновить интерфейсы, и если нужно, обновить данные об интерфейсах
Проверить, нужно ли обновить данные о соседях, и если нужно, обновить данные о соседях
Проверить, нужно ли обновить уровень свитча, и если нужно, обновить
Проверить, назначены ли подсети, и если нет - назначить
Проверить, назначены ли IP адреса интерфейсам, и если нет - назначить
Проверить, определены ли loopback-адреса, и если нет - назначить и их
Проверить, что все ОК, и если да - обновить статусы свитча и конфигурации
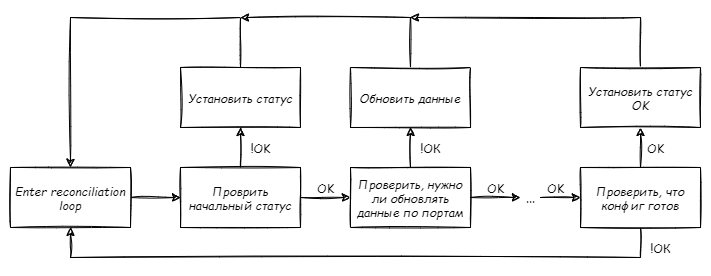
Плюс к этому, каждый шаг, приводящий к изменению статуса ресурса должен оканчиваться вызовом client.Status().Update(), чтобы при каждой итерации вычисления конфига, в случае, когда необходимо получить данные о других свитчах, эти данные были наиболее актуальными.
Набросали скелет обработки нашего кастомного ресурса:
type SwitchReconciler struct {
client.Client
Log logr.Logger
Scheme *runtime.Scheme
}
func (r *SwitchReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
obj := &switchv1alpha1.Switch{}
if err = r.Get(ctx, req.NamespacedName, obj); err != nil {
return ctrl.Result{}, client.IgnoreNotFound(err)
}
if obj.State == "" {
obj.FillInitialStatus()
if err := r.Status().Update(); err != nil {
return ctrl.Result{Requeue: true}, err
}
return ctrl.Result{Requeue: true}, nil
}
if !obj.InterfaceOk {
if err := r.updateInterfaces(ctx, obj); err != nil {
return ctrl.Result{Requeue: true}, err
}
if err := r.Status().Update(); err != nil {
return ctrl.Result{Requeue: true}, err
}
return ctrl.Result{Requeue: true}, nil
}
... // дабы не растягивать листинг, за многоточием спрятаны остальные 5 идентичных проверок состояния свитча, обозначенных выше
if obj.AllGood {
obj.Status.State = "ready"
obj.Status.Configuration.State = "ready"
if err := r.Status().Update(); err != nil {
return ctrl.Result{Requeue: true}, err
}
return ctrl.Result{Requeue: true}, nil
}
return ctrl.Result{Requeue: true}, nil
}
Что ж, получилось длинно и однообразно, но для проверки теории подойдет.
Довольно быстро стало понятно, что определение иерархии подключений без дополнительных сведений невозможно. Единственным маркером роли коммутатора – leaf или spine – выступает наличие подключенной полезной нагрузки, однако, если к leaf-коммутатору на этапе сбора сведений ничего не подключено (или вся подключенная нагрузка выключена), он будет ошибочно определен как spine и, что особенно важно, нет способа определить, какие из коммутаторов являются top-level spines. Придя к такому неутешительному выводу, я решил, что нужен дополнительный ресурс, который будет отвечать за определение top-level коммутаторов. Все, что он содержит – chassis ID коммутатора. Назовем его SpineAssignment.
Кроме это, поскольку часто в процессе обработки свитча периодически нужны данные о других ресурсах, было решено получить их на старте обработки. Дополнили структуру SwitchReconciler и добавили получение нужных данных в Reconcile:
type background struct {
switches *switchv1alpha1.SwitchList // здесь храним лист всех имеющихся свитчей
assignment *switchv1alpha1.SpineAssignment // здесь либо относящийся к обрабатываемому свитчу assignment, либо nil
inventory *inventoryv1.Inventory // в CR Inventory сохраняется собранная с железа информация, в том числе об интерфейсах
}
type SwitchReconciler struct {
client.Client
Log logr.Logger
Scheme *runtime.Scheme
Background *background
}
func (r *SwitchReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
obj := &switchv1alpha1.Switch{}
if err = r.Get(ctx, req.NamespacedName, obj); err != nil {
return ctrl.Result{}, client.IgnoreNotFound(err)
}
// здесь должен быть finalizer, но он не представляет интереса, поэтому просто скажу, что он действительно здесь есть
if err := r.prepareBackground(ctx, obj); err != nil {
return ctrl.Result{Requeue: true}, err
}
...
return ctrl.Result{Requeue: true}, nil
}
Казалось бы, всё было готово, но внутренний перфекционист не дремал, и я решил слегка переписать эти повторяющиеся обработки ресурса. Поскольку операции однотипные и отличаются только функциями проверки и вычисления актуального состояния, написал небольшую стейт-машину, которая спрячет в себе эту нудную последовательность проверок:
type executable interface {
execute(context.Context, *switchv1alpha1.Switch) error
setNext(executable)
getNext() executable
}
type setStateStep struct {
stateCheckFunc func(*switchv1alpha1.Switch) bool
stateComputeFunc func(context.Context, *switchv1alpha1.Switch) error
resourceUpdateFunc func(context.Context, *switchv1alpha1.Switch) error
next executable
}
func newStep(
stepCheckFunc func(*switchv1alpha1.Switch) bool,
stepComputeFunc func(context.Context, *switchv1alpha1.Switch) error,
stepResUpdateFunc func(context.Context, *switchv1alpha1.Switch) error,
nextStep executable) *setStateStep {
return &processingStep{
stateCheckFunc: stepCheckFunc,
stateComputeFunc: stepComputeFunc,
resourceUpdateFunc: stepResUpdateFunc,
next: nextStep,
}
}
func (s *setStateStep) setNext(step executable) {
s.next = step
}
func (s *setStateStep) getNext() executable {
return s.next
}
func (s *setStateStep) execute(ctx context.Context, obj *switchv1alpha1.Switch) (err error) {
if s.stateCheckFunc(obj) {
return
}
if err = s.stateComputeFunc(ctx, obj); err != nil {
return
}
if s.resourceUpdateFunc != nil {
s.setNext(nil)
err = s.resourceUpdateFunc(ctx, obj)
}
return
}
type stateMachine struct {
executionPoint executable
}
func newStateMachine(startPoint executable) *stateMachine {
return &stateMachine{
executionPoint: startPoint,
}
}
func (s *stateMachine) launch(ctx context.Context, currentState *switchv1alpha1.Switch) (ctrl.Result, error) {
previousState := currentState.DeepCopy()
if err := s.executeStep(ctx, currentState); err != nil {
return ctrl.Result{Requeue: true}, err
}
if reflect.DeepEqual(currentState.Status, previousState.Status) {
return ctrl.Result{Requeue: true}, nil
}
return ctrl.Result{}, nil
}
func (s *stateMachine) executeStep(ctx context.Context, obj *switchv1alpha1.Switch) (err error) {
if err = s.executionPoint.execute(ctx, obj); err != nil {
return
}
s.executionPoint = s.executionPoint.getNext()
if s.executionPoint == nil {
return
}
return s.executeStep(ctx, obj)
}
Таким образом, наша стейт-машина при создании получает точку отсчета, с которой нужно начинать обработку, а при запуске - исходное состояние объекта. В процессе работы она выполнит проверку и, при необходимости, изменит состояние объекта. В этом случае сбросим следующий шаг в nil и завершим обработку, поставив объект в очередь на обработку, вернув ctrl.Result{Requeue: true}. Поправим метод Reconcile:
func (r *SwitchReconciler) Reconcile(ctx context.Context, req ctrl.Request) (ctrl.Result, error) {
obj := &switchv1alpha1.Switch{}
if err = r.Get(ctx, req.NamespacedName, obj); err != nil {
return ctrl.Result{}, client.IgnoreNotFound(err)
}
// здесь должен быть finalizer, но он не представляет интереса, поэтому просто скажу, что он действительно здесь есть
if err := r.prepareBackground(ctx, obj); err != nil {
return ctrl.Result{Requeue: true}, err
}
stateMachine := r.prepareStateMachine(obj)
return stateMachine.launch(ctx, obj)
}
func (r *SwitchReconciler) prepareStateMachine(obj *switchv1alpha1.Switch) *stateMachine {
updateStatus := newStep(r.stateReadyOk, r.completeProcessing, r.updateResStatus, nil)
updateLoAddresses := newStep(r.loopbackAddressesOk, r.updateLoopbacks, r.updateResStatus, updateStatus)
updateNICsAddresses := newStep(r.nicsAddressesOk, r.updateNICsAddresses, r.updateResStatus, updateLoAddresses)
updateSubnets := newStep(r.subnetsOk, r.setSubnets, r.updateResStatus, updateNICsAddresses)
updateLayer := newStep(r.layerOk, r.updateLayer, r.updateResStatus, updateSubnets)
updatePeers := newStep(r.peersOk, r.fillPeersInfo, r.updateResStatus, updateLayer)
updateInterfaces := newStep(r.interfacesOk, r.setInterfaces, r.updateResStatus, updatePeers)
updateInitialStatus := newStep(r.stateOk, r.setInitialStatus, r.updateResStatus, updateInterfaces)
return newStateMachine(updateInitialStatus)
}
Теперь, если понадобится добавить новый вычисляемый параметр в конфигурацию свитча, достаточно написать метод проверки его значения, метод его изменения и добавить одну строчку в метод prepareStateMachine, чтобы свеже добавленный параметр считался в нужное время и в нужном месте. В основном, описанные шаги вычисления конфига по отдельности не представляют особого интереса, но к одному из них - обновлению положения свитча на "карте подключений" - присмотримся чуть пристальнее. Особенно учитывая связанный с ним плавающий баг, на объяснение и искоренение которого у меня ушло довольно много времени (хотя сам по себе баг был мелкий, так, бажок, не более).
Итак, закончив с написанием логики и обильно покрыв код тестами, я приступил к опытной эксплуатации оператора и я заметил странную вещь - если добавлять свитчи по одному, их конфиги считаются правильно на каждом этапе обработки, во всяком случае в watch kubectl get ... все выглядит именно так, но стоит создать сразу пачку свитчей, как время от времени начинает неверно определяться layer некоторых (иногда одного, иногда нескольких) свитчей. Посмотрим как проверяется корректность layer'а:
func (r *SwitchReconciler) layerOk(obj *switchv1alpha1.Switch) (result bool) {
switch {
case r.Background.assignment != nil:
result = obj.Status.Layer == 0
case r.Background.assignment == nil:
layerOk := obj.Status.Layer != 255
matchPeers := obj.LayerMatchPeers(r.Background.switches)
result = layerOk && matchPeers
}
return
}
Что ж, проверка предельно простая. Если на старте в полученном бэкграунде нет, относящегося к обрабатываемому свитчу, ресурса SpineAssignment, проверяем. что layer не равен 255 и значение layer'а соответствует этому же параметру соседей (то есть, для "северных" соседей оно на единицу меньше, а для южных - на единицу больше), в противном случае проверяем, что layer равен 0, то есть свитч является top-spine'ом.
Значения параметра
layerравные 0 для top-spine'ов и 255 для "необработанных" свитчей, возможно, выглядят, как будто взятые с потолка, просто как минимальное и максимальное возможные значения типа, однако определенная логика за этими значениями есть - для последующей обработки мне нужно было, чтобы первыми обрабатывались "находящиеся на самом верху" свитчи, а те, у которых их уровень не определен, обрабатывались последними.
На первый взгляд ничего криминального. Посмотрим, как этот параметр обновляется:
func (r *SwitchReconciler) updateLayer(ctx context.Context, obj *switchv1alpha1.Switch) (err error) {
if r.Background.assignment != nil && obj.Status.Layer != 0 {
obj.Status.Layer = 0
err = r.processAssignment(ctx, obj) // здесь соответствующему ресурсу SpineAssignment обновляется статус - оставлено исключительно для того, чтобы избежать вопросов, почему метод никогда не вернет ошибку
}
obj.ComputeLayer(r.Background.switches)
return
}
и считается:
func (in *Switch) ComputeLayer(list *SwitchList) {
connectionsMap, keys := list.buildConnectionMap()
if _, ok := connectionsMap[0]; !ok {
return
}
if in.Status.Layer == 0 {
for _, nicData := range in.Status.Interfaces {
nicData.Direction = "south"
}
return
}
for _, layer := range keys {
if layer == 255 {
break
}
if layer >= in.Status.Layer {
break
}
switches := connectionsMap[layer]
northPeers := in.getPeers(switches)
if len(northPeers.Items) == 0 {
continue
}
in.Status.Layer = layer + 1
in.fillNorthPeers(northPeers)
in.setNICsDirections(list)
}
}
Сначала узнаем, используя сохраненный в контексте список существующих свитчей, определенные к этому моменту значения layer других коммутаторов:
func (in *SwitchList) buildConnectionMap() (ConnectionsMap, []uint8) {
connectionsMap := make(ConnectionsMap)
keys := make([]uint8, 0)
for _, item := range in.Items {
list, ok := connectionsMap[item.Status.Layer]
if !ok {
list = &SwitchList{}
list.Items = append(list.Items, item)
connectionsMap[item.Status.Layer] = list
keys = append(keys, item.Status.Layer)
continue
}
list.Items = append(list.Items, item)
}
sort.Slice(keys, func(i, j int) bool {
return keys[i] < keys[j]
})
return connectionsMap, keys
}
Получив на выходе отсортированный список layer’ов и относящиеся к ним ресурсы, проверим два условия – наличие ключа «0» и значение .Status.Layer обрабатываемого ресурса. Если первое условие не соблюдено, значит ни один свитч не был определен как top-level и обработку можно прекращать. Следующая проверка покажет, является ли обрабатываемый свитч top-spine'ом, и если да, прекращаем обработку предварительно определив все интерфейсы коммутатора как «южные».
Если мы до сих пор не вышли из функции, определим уровень нашего свитча, путем обхода полученной мапы. Проходя по списку ключей – известных значений layer'ов среди всех имеющихся коммутаторов (помним, что он отсортирован, поэтому на каждой итерации мы как бы спускаемся на уровень ниже) – проверяем, что текущий ключ не равен 255, потому что в противном случае у нас список коммутаторов, для которых layer не определен и дальше двигаться некуда. Затем проверяем, что текущий ключ меньше layer'а нашего свитча. Так как свитчи на одном уровне не соединены между собой, в случае если мы оказались на уровне обрабатываемого коммутатора, вышестоящих соседей не обнаружено и обработку надо прекращать. Это сделано для того, чтобы последовательно вычислять уровень коммутаторов. начиная с top-spine'ов.
Если мы проскочили обе проверки, значит у нас появился шанс определить положение нашего коммутатора. Сперва пройдемся по списку известных коммутаторов на этом уровне и посмотрим, есть ли среди них те, у которых в информации об интерфейсах засветился идентификатор нашего свитча. Если нет – «спускаемся на уровень ниже», в противном случае, назначаем обрабатываемому свитчу .Status.Layer равный key + 1 и обновляем информацию о сетевых интерфейсах - заполняем ResourceReference для интерфейсов, подключенных к "серверным" соседям и изменяем у этих интерфейсов значение поля Direction на north.
Вернемся к упомянутому багу. Все дело в том, что при создании ресурса, статус заполняется "нулевыми" значениями, соответствующими типу каждого поля структуры статуса. Таким образом, возникала ситуация, когда в списке свитчей, сохраненных в бэкграунде, оказывались ресурсы, у которых статус еще не был заполнен нашими "стартовыми" значениями, а нулевые значения уже были и эти свитчи воспринимались как top-spine'ы, что в свою очередь приводило к неверному результату работы функции buildConnectionMap. В качестве решения добавил дополнительную проверку:
func (in *SwitchList) buildConnectionMap() (ConnectionsMap, []uint8) {
connectionsMap := make(ConnectionsMap)
keys := make([]uint8, 0)
for _, item := range in.Items {
if item.Status.State == CEmptyString {
continue
}
...
}
...
return connectionsMap, keys
}
то есть перестали учитывать свитчи, у которых статус не был нами инициализирован.
После того, как определен уровень коммутатора и информация о его соседях, переходим к назначению адресов. Сначала коммутатору назначается подсеть из заданного диапазона, подходящая по количеству доступных адресов – помните, что один физический порт может быть разделен по количеству используемых каналов, а на каждый канал мы резервируем по 4 адреса? Исходя из этого считается количество адресов и через IPAM резервируется подсеть с нужным префиксом.
Следующим шагом надо зарезервировать подсети с префиксом /30 для интерфейсов и назначить адреса. Для «южных» интерфейсов подсети назначаются из общей подсети, назначенной коммутатору, и назначается первый адрес хоста из выделенной подсети, а для «северных» только запрашивается адрес у его вышестоящего соседа, который является вторым адресом хоста из подсети /30, назначенной порту соседа. Последним шагом коммутатору назначаются loopback-адреса – они выделяются из предварительно созданной подсети. Плюс выбранного подхода в том, что мы в любой момент времени можем сказать, какой адрес будет назначен любому интерфейсу. Например, у нас есть 4 интерфейса, каждый из которых задействует все 4 канала:
Ethernet0 100.64.0.1/30
Ethernet4 100.64.0.17/30
Ethernet8 100.64.0.33/30
Ethernet12 100.64.0.49/30
если мы заменим трансивер интерфейса Ethernet8 и разделим его на 4 интерфейса, использующих по 1 каналу, адресация все равно сохранится:
Ethernet0 100.64.0.1/30
Ethernet4 100.64.0.17/30
Ethernet8 100.64.0.33/30
Ethernet9 100.64.0.37/30
Ethernet10 100.64.0.41/30
Ethernet11 100.64.0.45/30
Ethernet12 100.64.0.49/30
Итак, к этому моменту у нас есть ресурс, описывающий подготовленный к настройке L3-коммутатор: адреса назначены, состояние интерфейсов известно и у нас есть все для настройки маршрутизации. О применении конфигурации непосредственно на свитче расскажу в следующей части.
Комментарии (12)

sYB-Tyumen
23.12.2021 05:29Я правильно понял, что у каждого коммутатора свой номер AS и на аплинках он использует eBGP? Это типовая практика в ЦОДах вообще или в ЦОДах Вашей организации?

timmer Автор
23.12.2021 08:29Да, все верно. Не берусь утверждать насчет типичности подобного решения, но уверен, что оно достаточно распространено. Все равно существует конечное количество решений по дизайну underlay сети. Почему был выбран именно eBGP? Потому что в случае с iBGP, потребовался бы, во-первых, IGP - т.к. маршруты строим на loopback'ах и кто-то должен сообщать, как до них добраться, во-вторых, либо full-mesh топология, либо делать спайны route-reflector'ом. В случае же с eBGP в этом нет необходимости.

iddqda
23.12.2021 10:09ну так spine-ы назначаешь RR и тоже никаких проблем.
единственно нужно чтоб они next-hop-self еще меняли на свойесть еще компромиссная архитектура когда спайны все в одной ASN, а все лифы в другой ASN, общей для всех.
Тут тебе и eBGP без фулмешей или RR,
и при этом не нужно париться выдумывать номер ASN для каждого лифаА лично мне и OSPF на андерлее норм (разумеется unnumbered). Но у меня не ЦОД, а так - цодик
timmer Автор
23.12.2021 20:15есть еще компромиссная архитектура когда спайны все в одной ASN, а все лифы в другой ASN, общей для всех.Тут тебе и eBGP без фулмешей или RR,и при этом не нужно париться выдумывать номер ASN для каждого лифа
да, но тогда надо поддерживать список уже назначенных ASN, на случай если у меня будет два дерева свитчей
iddqda
23.12.2021 10:36Спасибо! Уже жду продолжения
И вопрос:
>> Единственным маркером роли коммутатора – leaf или spine – выступает наличие подключенной полезной нагрузки
ну ... эээ ... но зачем же так ?
А если немного приземлиться из облаков и куберов этих ваших хипстерских. Ну ведь там же на земле еще кто-то кейблингом занимается. А значит должен отличать лиф от спайна по этикетке, модели или цвету свича. Ну и вам там высоко в облаках кто мешает заранее свич пометить? Например в имени свича роль лиф/спайн закодировать пока IP адрес управления ему задаете, ну и/или ориентироваться по железу ведь на роли лиф/спайн ставят разные по модели свичи примерно всегда. Хотя самое простое и очевидное брать роль по cерийнику из того же IPAM/DCMNtimmer Автор
23.12.2021 20:32Я как раз об этом дальше пишу:
...нужен дополнительный ресурс, который будет отвечать за определение top-level коммутаторов. Все, что он содержит – chassis ID коммутатора.
Хотя вот очень хотелось найти способ определять это без человеческого вмешательства, но нет)
iddqda
24.12.2021 12:44ненене не надо так
динамика хороша в изменчивой среде. но на самом нижнем уровне, самый фундамент, он должен быть железобетонным и потом еще прикручен синей изолентой, для надежности
Shaz
А что делать если для запуска кубернетес надо настроить свитчи, а их не настроить потому что нужен кубернетес?
timmer Автор
В статье я исхожу из того, что в рассматриваемой инфраструктуре есть сеть управления, к которой подключены свитчи, требующие настройки, и в которой развернут кубернетис. То есть добиться полной и бесповоротной автоматизации, как мне кажется, невозможно. Об этом, конечно, нужно было упомянуть.
iddqda
так ZTP же
оно как раз под нулевой уровень деплоймента придумано (настройка интерфейса управления, авторизации итп)
а я как раз хотел вопрос задать где в ваших структурах поля для OOB интерфейсов :)
а оно уже задеплойменд (тоже кубернетисом?)
ну ок тогда другой вопрос:
А не думали BGP unnumbered использовать?
Насколько я знаю Sonic умеет в FRR а тот в свою очередь в BGP unnumbered
используя который отпадает необходимость возиться с пиринговыми /30 сетками
А где у вас оверлей? на лифах или дальше на хостах с куберами?
timmer Автор
про ZTP вообще не думал, если честно. Но это все же несколько другое - как раз на случай предподготовки. А у меня уже дальнейшая настройка рассматривается. Но вообще идея мне нравится, надо будет подумать, можно ли вписать ZTP в процесс онбординга оборудования.
Думал и как раз его и буду использовать. Об этом речь пойдет во второй части, когда дойду до непосредственной настройки свитча. Что касается /30 подсетей - знаю, что Cumulus на случай BGP Unnumbered имеет пул ipv6 адресов из которых назначает адреса на интерфейсы, чтобы строить соседство. Возможно SONiC действует подобным образом,но это вносит некую долю неопределенности в части адресов. А я таким образом лишаю этот момент неопределенности и в любой момент времени могу точно сказать, какой адрес на интерфейсе и у соседа.
iddqda
этот пул ipv6 адресов это обычные linklocal unicast fe80::/10
поэтому никакой неопределенности
какой-то адрес там обязательно будет, но при этом настраивать его нет необходимости