

В первой части статьи я рассказал про понятие градиентного бустинга, библиотеки, с помощью которых можно реализовать данный алгоритм и углубились в одну из этих библиотек. Сегодня продолжим разговор о CatBoost и рассмотрим Cross Validation, Overfitting Detector, ROC-AUC, SnapShot и Predict. Поехали!
До этого момента мы мерили качество на каком-то конкретном fold’e (конкретной выборке), то есть взяли разделили нашу выборку на обучающую и тестовую, это не совсем корректно, вдруг мы взяли какой-то непрезентативный кусок нашего датасета, на этом самом куске мы получим хорошее качество, а когда модель будет работать с реальными данными, то с качеством все будет крайне грустно. Дабы избежать этого, необходимо использовать Cross Validation.
Разобьём наш датасет на кусочки и дальше будем обучать модель столько раз, сколько у нас будет кусочков. Сначала обучаем модель на все кусках кроме первого, нам нем будет происходить валидация, потом на втором будет происходить такая же ситуация и все это дело будет повторяться до последнего кусочка нашей выборки:
from catboost import cv
params = {
'loss_function': 'Logloss',
'iterations': 150,
'custom_loss': 'AUC',
'random_seed': 63,
'learning_rate': 0.5
}
cv_data = cv(
params=params,
pool=Pool(X, label=y, cat_features=cat_features),
fold_count=5, # Разбивка выборки на 5 кусочков
shuffle=True, # Перемешаем наши данные
partition_random_seed=0,
plot=True, # Никуда без визуализатора
stratified=True,
verbose=False
)
Вновь видим визуализатор при запуске кода, только теперь он рисует не одну кривую, а среднюю кривую по всем fold’aм, но если убрать галочку с Standard Deviation, то увидим каждую кривую отдельно, можно будет проанализировать fold’ы, где качество плохое или хорошее.
Что возвращает функция Cross Validation? Если установлен pandas/polars (об этой библиотеке у меня есть отдельная статья), то DataFrame, если нет, то Python словарь, в котором лежит информация про метрики для каждой выборки:

Здесь мы видим значение каждой метрики по каждой выборке на всех fold’ах.
Давайте выведем Logloss и на каком шаге мы получили лучший результат:
best_value = np.min(cv_data['test-Logloss-mean'])
best_iter = np.argmin(cv_data['test-Logloss-mean'])
print("Best validation Logloss score, stratified: {:.4f}+/-{:.3f} on step {}".format(
best_value, cv_data['test-Logloss-std'][best_iter], best_iter))
Best validation Logloss score, stratified: 0.1577+/-0.002 on step 52Видим, что лучший Logloss равен 0.1577 и он был достигнут на 52 шаге со стандартным отклонением 0.002.
В конце первой части я затронул Overfitting Detector, что это такое? Это детектор переобучения, шикарная вещь, которая помогает сохранить время Data Scientist’a. Когда мы обучаем модель, все итерации после переобучения нам не нужны, так зачем мы будем тратить время и ждать пока пройдут все итерации после точки переобучения? В этом как раз нам поможет упомянутый выше Overfitting Detector.
При создании модели добавляется параметр early_stopping_rounds, который в этом случае равен 20, если на протяжении 20 итераций ошибка на валидационном множестве ухудшается, то обучение будет остановлено:
model_with_early_stop = CatBoostClassifier(
iterations=200,
random_seed=63,
learning_rate=0.5,
early_stopping_rounds=20
)
model_with_early_stop.fit(
X_train, y_train,
cat_features=cat_features,
eval_set=(X_test, y_test),
verbose=False,
plot=True
)
Здесь видно, что модель переобучилась на итерации 28, проходит еще 20 итераций, происходит ухудшение ошибки и обучение останавливается на 48 итерации. Вызовем функцию tree_count и посмотрим количество деревьев после обучения:
print(model_with_early_stop.tree_count_)
28Давайте посмотрим не только на Logloss, а на какую-то более осознанную метрику, в данном случае это будет AUC, чтобы использовать AUC в качестве метрики, воспользуемся параметром eval_metric. Отметим, что визуализатор будет выводить AUC в первую очередь:
model_with_early_stop=CatBoostClassifier(
eval_metric='AUC',
iterations=200,
random_seed=63,
learning_rate=0.3,
early_stopping_rounds=20)
model_with_early_stop.fit(
X_train,y_train,
cat_features=cat_features,
eval_set=(X_test, y_test),
verbose=False,
plot=True
)Видим, что переобучение произошло на итерации 44, прошло еще 20 и обучение было остановлено:

Вызовем tree_count_ и получим в ответе:
print(model_with_early_stop.tree_count_)
44Едем далее… Поговорим про функцию get_roc_curve, она возвращает нам ROC кривую (true positive rate, false positive rate и thresholds). ROC кривая – это зависимость tpr от fpr и каждая точка соответсвует собственной границе принятия решений.
from catboost.utils import get_roc_curve
import sklearn
from sklearn import metrics
eval_pool = Pool(X_test, y_test, cat_features=cat_features)
curve = get_roc_curve(model, eval_pool)
(fpr, tpr, thresholds)=curve
roc_auc=sklearn.metrics.auc(fpr, tpr)Теперь визуализируем ROC кривую:
import matplotlib.pyplot as plt
plt.figure(figsize=(16, 8))
lw=2
plt.plot(fpr, tpr, color='darkorange',
lw=lw, label='ROC curve (area = %0.2f)' % roc_auc, alpha=0.5)
plt.plot([0, 1], [0, 1], color='navy', lw=lw, linestyle='--', alpha=0.5)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.grid(True)
plt.xlabel('False Positive Rate', fontsize=16)
plt.ylabel('True Positive Rate', fontsize=16)
plt.title('Receiver operating characteristic', fontsize=20)
plt.legend(loc="lower right", fontsize=16)
plt.show()
Площадь под ROC кривой называется AUC, чем больше площадь AUC, тем лучше, тем мы ближе к нашей идеальной точке (1.0).
Также есть функция, которая отдельно считает FPR, FNR и THRESHOLD:
from catboost.utils import get_fpr_curve
from catboost.utils import get_fnr_curve
(thresholds, fpr) = get_fpr_curve(curve=curve)
(thresholds, fnr) = get_fnr_curve(curve=curve)Визуализируем данную кривую:
plt.figure(figsize=(16, 8))
lw=2
plt.plot(thresholds, fpr, color='blue', lw=lw, label='FPR', alpha=0.5)
plt.plot(thresholds, fpr, color='green', lw=lw, label='FNR', alpha=0.5)
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xticks(fontsize=16)
plt.yticks(fontsize=16)
plt.grid(True)
plt.xlabel('Thresholds', fontsize=16)
plt.ylabel('Error rate', fontsize=16)
plt.title('FPR-FNR curves', fontsize=16)
plt.legend(loc='lower left', fontsize=16)
plt.show()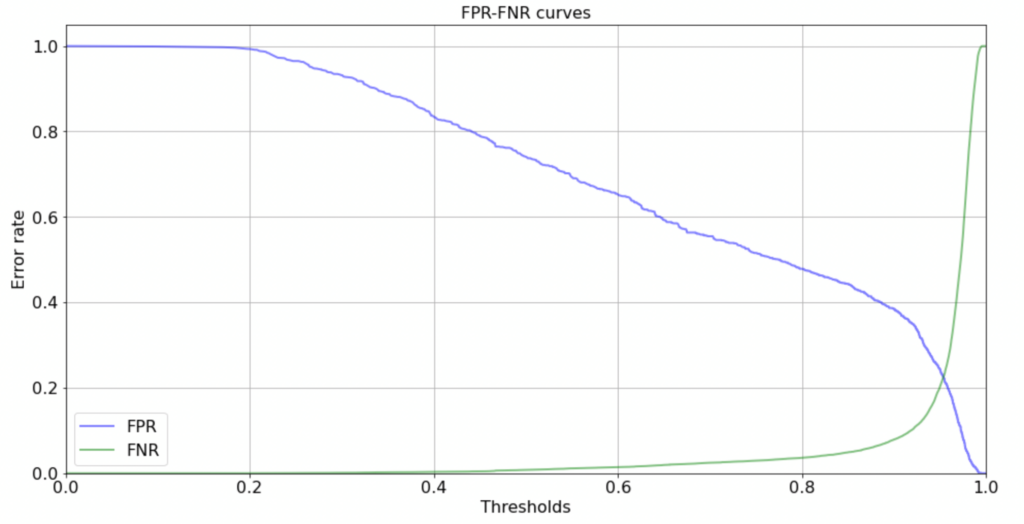
Чтобы определить оптимальную границу на графике, мы воспользуемся select_threshold:
from catboost.utils import select_threshold
print(select_threshold(model=model, data=eval_pool, FNR=0.01))
print(select_threshold(model=model, data=eval_pool, FPR=0.01))
0.5323909210615109
0.9895850986242051В первом случае нам необходимо выбрать границу в 0.5323, во втором случае 0.9895. Конечно же, необходимо понимать, что не всегда надо брать границу в 0.5, это зависит от задачи, где нам страшнее ошибиться, а где это не столь критично и исходя из этого принимать решение.
Давайте теперь рассмотрим про Snapshot. Бывают разные ситуации, отключили свет, завис компьютер/ноутбук или какая-то другая ситуация по которой упало обучение и тут приходится делать все по новой, но дабы избежать неприятной ситуации, в Catboost присутствует сохранение прогресса обучения модели:
from catboost import CatBoostClassifier
model = CatBoostClassifier(
iterations=150,
save_snapshot=True,
snapshot_file='shapshot.bkp', # В данный файл будем писать наш прогресс
snapshot_interval=1, # Интервал с которым необходимо делать снэпшот
random_seed=42
)
model.fit(
X_train, y_train,
eval_set=(X_test, y_test),
cat_features=cat_features,
verbose=True
)Смоделируем ситуацию, что у нас произошла какая-то ошибка при обучении на какой-то итерации:
1080: learn: 0.1174802 test: 0.1512820 best: 0.1506310 (585) total: 16.3s remaining: 13.9s
1081: learn: 0.1174613 test: 0.1512905 best: 0.1506310 (585) total: 16.3s remaining: 13.8s
1082: learn: 0.1174327 test: 0.1512617 best: 0.1506310 (585) total: 16.3s remaining: 13.8s
1083: learn: 0.1174143 test: 0.1512679 best: 0.1506310 (585) total: 16.3s remaining: 13.8s
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
<ipython-input-45-aab67cd70f42> in <module>
9 )
10
---> 11 model.fit(
12 X_train, y_train,
13 eval_set=(X_test, y_test),В этом случае мы просто запускаем ячейку опять и обучение начнется с 1083 итерации:
1083: learn: 0.1174143 test: 0.1512679 best: 0.1506310 (585) total: 16.3s remaining: 14.1s
1084: learn: 0.1173739 test: 0.1512903 best: 0.1506310 (585) total: 16.3s remaining: 14.1s
1085: learn: 0.1173333 test: 0.1512818 best: 0.1506310 (585) total: 16.4s remaining: 14s
1086: learn: 0.1172675 test: 0.1512872 best: 0.1506310 (585) total: 16.4s remaining: 14.1s
1087: learn: 0.1172435 test: 0.1512959 best: 0.1506310 (585) total: 16.4s remaining: 14.1s
1088: learn: 0.1171932 test: 0.1512984 best: 0.1506310 (585) total: 16.4s remaining: 14.1s
1089: learn: 0.1171045 test: 0.1513513 best: 0.1506310 (585) total: 16.4s remaining: 14s
1090: learn: 0.1170768 test: 0.1513511 best: 0.1506310 (585) total: 16.4s remaining: 14s
1091: learn: 0.1170621 test: 0.1513434 best: 0.1506310 (585) total: 16.5s remaining: 14s
1092: learn: 0.1170396 test: 0.1513455 best: 0.1506310 (585) total: 16.5s remaining: 14s
1093: learn: 0.1170104 test: 0.1513388 best: 0.1506310 (585) total: 16.5s remaining: 14s
1094: learn: 0.1169427 test: 0.1513257 best: 0.1506310 (585) total: 16.5s remaining: 14s
1095: learn: 0.1169269 test: 0.1513051 best: 0.1506310 (585) total: 16.5s remaining: 14sДалее стоит поговорить про предсказания. В Catboost’e есть такая функция, как predict_proba, она выдает предсказания в Scikit Learn формате, в первом столбце будут находится вероятности принадлежности к нулевому классу, а во втором столбце будут находится вероятности принадлежности к первому классу:
print(model.predict_proba(X_test))
[[0.0155 0.9845]
[0.0064 0.9936]
[0.0137 0.9863]
...
[0.0472 0.9528]
[0.0091 0.9909]
[0.0121 0.9879]]Далее про метод predict. Он возвращает непосредственно классы, в таком случае граница принятия решений будет составлять 0.5:
print(model.predict(X_test))
[1 1 1 ... 1 1 1]Также можно выбрать тип предсказания «RawFormulaVal», что это такое? Бустинг трудно заставить предсказывать числа в диапазоне от 0 до 1, результат работы бустинга этот результат значений каждого из деревьев, проходим по каждому дереву и получаем сумму, поэтому внутри мы предсказываем числа от минус бесконечности до плюс бесконечности, когда нам нужна вероятность, то мы можем применить функцию сигмойды, чтобы получить результаты в диапазоне от 0 до 1.
raw_pred = model.predict(
X_test,
prediction_type='RawFormulaVal'
)
print(raw_pred)
[4.1528 5.0524 4.2755 ... 3.0048 4.6904 4.4035]Воспользуемся функцией сигмойды, чтобы получить нужные нам предсказания:
from numpy import exp
sigmoid = lambda x: 1 / (1 + exp(-x))
probabilities = sigmoid(raw_pred)
print(probabilities)
[0.9845 0.9936 0.9863 ... 0.9528 0.9909 0.9879]И еще один способ, чтобы получить вероятности:
X_prepared = X_test.values.astype(str).astype(object)
fast_prediction = model.predict_proba(
FeaturesData(
cat_feature_data=X_prepared,
cat_feature_names=list(X_test)
)
)
print(fast_prediction)
[[0.0155 0.9845]
[0.0064 0.9936]
[0.0137 0.9863]
...
[0.0472 0.9528]
[0.0091 0.9909]
[0.0121 0.9879]]Бывают случаи, когда у вас какая-то особая метрика, но Catboost ее не поддерживает, а вы хотите посмотреть на какой итерации вы переобучились, в таких моментах стоит использовать Stage Prediction, она возвращает результат работы на каждой итерации от ntree_start до ntree_end с eval_period, давайте посмотрим на то, как это работает:
prediction_gen = model.staged_predict_proba(
X_test,
ntree_start=0,
ntree_end=5,
eval_period=1
)
try:
for iteration, predictions in enumerate(prediction_gen):
print(f"Iteration: {str(iteration)}, predictions: {predictions}")
except Exception:
pass
Iteration: 0, predictions: [[0.4689 0.5311]
[0.4689 0.5311]
[0.4689 0.5311]
...
[0.4689 0.5311]
[0.4689 0.5311]
[0.4689 0.5311]]
Iteration: 1, predictions: [[0.439 0.561]
[0.439 0.561]
[0.439 0.561]
...
[0.439 0.561]
[0.439 0.561]
[0.439 0.561]]
Iteration: 2, predictions: [[0.4113 0.5887]
[0.4113 0.5887]
[0.4113 0.5887]
...
[0.4113 0.5887]
[0.4113 0.5887]
[0.4113 0.5887]]
Iteration: 3, predictions: [[0.384 0.616]
[0.384 0.616]
[0.384 0.616]
...
[0.384 0.616]
[0.384 0.616]
[0.384 0.616]]
Iteration: 4, predictions: [[0.359 0.641]
[0.359 0.641]
[0.359 0.641]
...
[0.359 0.641]
[0.359 0.641]
[0.359 0.641]]Далее можно посчитать метрику и определить какая итерация по вашей метрике наилучшая.
На этом заканчивается вторая часть статьи про градиентный бустинг с CatBoost. В последней части я затрону MultiClassification, Metric Evaluation, Eval Metrics и Parameter Tuning.