
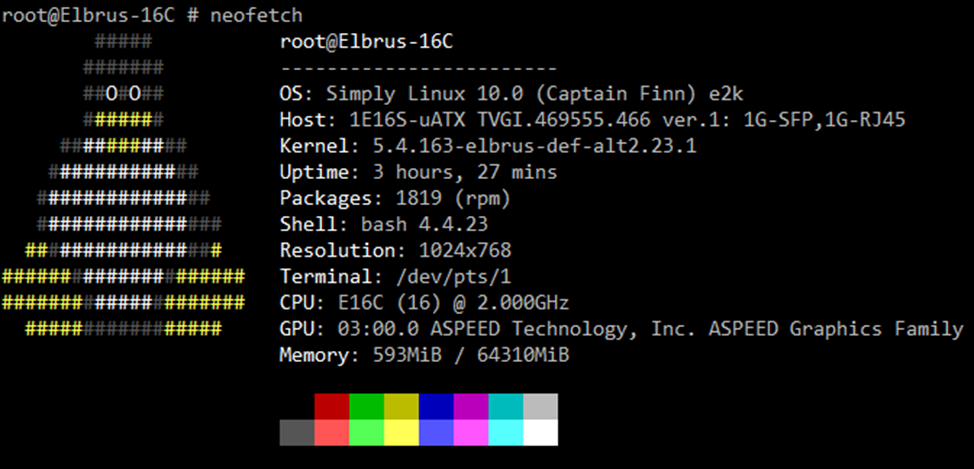
Появилась возможность протестировать инженерный процессор Эльбрус-16С и сравнить его с предыдущим процессором Эльбрус-8СВ.
Эта статья является продолжением моих предыдущих статей по бенчмаркам Эльбрусов:

Эльбрус-16С на архитектуре e2k-v6 является развитием процессора Эльбрус-8СВ (e2k-v5), который имеет 16 ядер на частоте 2 ГГц, поддержку аппаратной виртуализации, поддерживает до 4 ТБ оперативной памяти DDR4-3200, 32 линии PCIe 3.0.
Тестируемый процессор работает на материнской плате 1Э16С-mATX c с 2мя установленными модулями памяти DDR4 на частоте 2400.
Внимание: тестируется инженерный процессор с частично отключенным кешем, у серийного образца результаты должны быть лучше.
Фото инженерной платы из интернета (на фото плата не моего экземпляра):

К результатам процессоров Эльбрус-16С и Эльбрус-8СВ добавляю процессор Intel Core i7-2600 для относительного сравнения.
Характеристики сравниваемых процессоров:
Эльбрус-16СВ |
Эльбрус-8СВ |
Core i7-2600 |
|
Семейство ISA |
VLIW |
VLIW |
CISC |
Архитектура |
e2k |
e2k |
x86-64 |
Микроархитектура |
elbrus-v6 |
elbrus-v5 |
Sandy Bridge |
Частота (МГц) |
2000 |
1500 |
3400* |
Ядра; Потоки |
16 |
8 |
4; 8 |
Техпроцесс (нм) |
16 |
28 |
32 |
TDP (Вт) |
130 |
80-90 |
95 |
Тип ОЗУ |
DDR4-3200 (2400) |
DDR4-2400 |
DDR3-1333 |
Год |
2021 |
2018 |
2011 |
* — У Intel Core i7-2600 частота бустится, ядер 4, но 8 потоков HT.
Список компилируемых тестов (на языках С и C++):
Dhrystone, Whetstone, Linpack 100, Scimark 2, SuperPI
MP MFLOPS
TLB test, STREAM
HPL (High Performance Linpack)
7zip встроенный бенчмарк
StockFish (встроенный тест шахматного движка)
Cpu Miner (minerd)
Рендеринг в Blender (Файл для теста)
Готовые результаты в SPEC 2006
Кроме того, я запускал тесты на языках программирования Java, C#, Python, PHP, Lua. Результаты: https://github.com/EntityFX/EntityFX-Bench/tree/master/results
Теперь сразу перейдём к сводной таблице с результатами.
Результаты
Компилируемые тесты
ВНИМАНИЕ: Сборка тестов производилась с подбором флагов оптимизации и использования профилировщика и на результаты влияет версия компилятора (я являюсь энтузиастом и собирал код своими силами и, надеюсь, МЦСТ смогут собрать более правильно). Архитектура Эльбруса предполагает, что вы будете оптимизировать производительность не только флагами сборки, но и менять сам код (для бенчмарков это запрещено делать).
Тест |
Эльбрус-16C |
Эльбрус-8СВ |
Core i7-2600 |
Dhrystone [DMIPS] (1 поток) |
8652 |
9077 |
22076 |
Whetstone [MWIPS] (1 поток) |
2667 |
2269 |
5729 |
Whetstone MP [MWIPS] |
42467 |
16495 |
31319 |
Linpack 100 [MFLOPS] |
1831 |
1723 |
4302 |
Scimark 2 [Composite score] (1 поток) |
923 |
908 |
2427 |
Coremark (1T;MT) |
6162; 96873 |
5500; 43008 / 61871* (rtc x86-64) |
22692; 119670 |
MP MFLOPS |
1010040 |
381326 |
81745 |
HPL [GFLOPS] (1T;MT) |
39; 561.6 |
32.3; 232.6 |
93.9 (MT) |
7zip (Comp; Decomp; Tot) (MT) |
19070; 33490; 26280 |
8461; 13638; 11049 |
18024; 13363; 18664 |
STREAM (Copy; Scale; Add; Triad) [MB/s] |
20090; 19408;21848;22284 |
23097; 23137; 25578; 25643 (4 modules DDR4) |
20860; 21838; 18512; 20452 |
SPEC 2006 INT |
24 |
18 |
44.6 |
SPEC 2006 FP (1T) |
30 |
22.5 |
|
Blender (RyzenGraphic_27) [min:sec] |
1:08 |
2:32 |
1:18 |
StockFish [nodes/sec] |
6193924 |
3123190 |
10860720 |
SuperPI [sec] (1 поток) (меньше – лучше) |
2.77 |
3.76 |
1.81 |
Minerd [sha256d khash/s] (1T;MT) |
8820; 141104 |
6840; 54714 |
5307; 21226 (Core i5-2500K) |
Minerd [scrypt khash/s] (1T;MT) |
11.52; 183.01 |
8.50; 68.24 |
19.54; 78.26 (Core i5-6500) |
* — В нативном режиме Эльбрус-8СВ в тесте Coremark показывает в 1,5 раза хуже результаты чем в режиме бинарной трансляции x86-64 кода (этот бинарный транслятор называется RTC). На Эльбрус-16С такой проблемы больше нет.
Результаты всех тестов здесь: https://github.com/EntityFX/anybench/tree/master/results
Geekbench 5 в бинарной трансляции RTC
ID |
Name |
Platform |
Architecture |
Single-core Score |
Multi-core Score |
MCST Elbrus 4C (х86 compatibility mode) 4 CPUs Intel Pentium II/III 750 MHz (1 cores) |
Linux 64 |
x86_64 |
74 |
374 |
|
MCST Elbrus 8C (х86 compatibility mode) Intel Pentium II/III 1299 MHz (1 cores) |
Linux 64 |
x86_64 |
140 |
937 |
|
MCST Elbrus 8CB (х86 compatibility mode) Intel Pentium II/III 1549 MHz (1 cores) |
Linux 64 |
x86_64 |
159 |
1100 |
|
MCST Elbrus 16C (х86 compatibility mode) Intel Pentium II/III 2000 MHz (1 cores) |
Linux 64 |
x86_64 |
203 |
2821 |
|
Core i7-2600Intel Core i7-2600 3401 MHz (4 cores) |
Windows 64 |
x86_64 |
720 |
2845 |
Разбираем результаты
Логи результатов можете смотреть здесь
Dhrystone
Dhrystone достаточно древний тест 80х годов, написан на C. Тестирует целочисленную арифметику и работу со строками. Результаты измеряются в Dhrystone/s и DMIPS. (DMIPS = Dhrystone/s делить на 1757).
Эльбрус-16С немного показал хуже результаты чем Эльбрус-8СВ. Скорее всего, проблема с оптимизациями компилятором LCC, с новой версией будет перепроверяться.
Whetstone
Тестирует арифметику с плавающей/фиксированной запятой, математические функции, ветвления, вызовов функций, присваиваний, работы с числами с фиксированной запятой, ветвлений. Результаты измеряются в MMIPS.
Эльбрус-16С показывает результаты кратные частоте (2000 / 1500).
Coremark
Современный тест, который должен заменить Dhrystone и Whetstone. Написан на C. Считает различные массивы, матрицы, сортировка и т. д. Предназначался для запуска на всём: от микроконтроллеров до мощных процессоров.
Эльбрус-16С показывает гораздо лучшие результаты чем Эльбрус-8СВ. На 8СВ результаты в бинарной трансляции выходили лучше, чем нативные.
MP MFLOPS
Эльбрус-16С значительно обгоняет 8СВ, набирая более 1 ТFlops в числах с плавующей запятой одинарной точности.
HPL
HPL – переносимый высокопроизводительный тест, который используется для суперкомпьютеров. Решает системы линейных уравнений, использует библиотеки BLAS и MPI . Результаты выдаёт в GFLOPS.
Cpu |
Year |
Freq |
Cores |
1 thread (GFLOPS) |
Multithread (GFLOPS) |
Elbrus 2C+ |
2011 |
500 |
2 |
3.8 |
6.8 |
Elbrus 4C |
2014 |
800 |
4 |
6 |
21.6 |
Elbrus 1C+ |
2015 |
1000 |
1 |
10 |
10.0 |
Elbrus 8C |
2016 |
1300 |
8 |
13 |
96.00 |
Elbrus 8C |
2016 |
1200 |
8 |
12 |
82.5 |
Elbrus 8CB |
2018 |
1550 |
8 |
32.3 |
232.6 |
Elbrus 16C |
2021 |
2000 |
16 |
39 |
561.6 |
Elbrus 2C3 |
2021 |
2000 |
2 |
39 |
70.2 |
7zip
Встроенный тест архиватора. Тест особо не параллелится, результаты примерно равные на этих процессорах (частота одинаковая).
Cpu |
Year |
Freq |
Cores |
Total MT |
Comp Avr MT |
Dec Avr MT |
Total ST |
Elbrus 8CB |
2018 |
1500 |
8 |
12164 |
9975 |
14353 |
1894 |
Elbrus 8CB |
2018 |
1550 |
8 |
11049 |
8461 |
13638 |
1651 |
Elbrus 8C |
2016 |
1300 |
8 |
10865 |
8736 |
12994 |
1697 |
Elbrus 8C |
2016 |
1200 |
8 |
9031 |
6619 |
11442 |
1391 |
Elbrus 16C |
2021 |
2000 |
16 |
26280 |
19070 |
33490 |
1813 |
Elbrus 2C3 |
2021 |
2000 |
2 |
3448 |
2499 |
4396 |
1894 |
Elbrus 1C+ |
2015 |
1000 |
1 |
1277.5 |
1301 |
1254 |
1277.5 |
Elbrus 4C |
2014 |
800 |
4 |
2793 |
2065 |
3520 |
849 |
Elbrus 2C+ |
2011 |
500 |
2 |
1077 |
878 |
1276 |
645 |
Elbrus R2000 |
2018 |
2000 |
8 |
8728 |
5896 |
11560 |
1246 |
Elbrus R1000 |
2011 |
1000 |
4 |
2514 |
1959 |
3069 |
692 |
Baikal M1000 |
2019 |
1500 |
8 |
9868 |
8483 |
11252 |
1513 |
Baikal S |
2022 |
2000 |
48 |
90039 |
75097 |
1295732 |
2378 |
Huawei Kunpeng 920 |
2019 |
2600 |
48 |
126143 |
112386 |
139899 |
3177 |
Huawei Kunpeng 920 |
2019 |
2600 |
96 |
204155 |
153863 |
254447 |
3177 |
Apple M1 |
2020 |
3100 |
8 |
33034 |
38166 |
27903 |
4458 |
|
|
|
|
|
|
||
Celeron N3350 * |
2016 |
1100 |
2 |
3966 |
3568 |
4364 |
1961 |
Core i7 2600 |
2011 |
3400 |
8 |
16601 |
16179 |
17024 |
3773 |
Core(TM) i7-7820X ** |
2017 |
3600 |
16 |
47733 |
48501 |
46965 |
4982 |
Blender
Cpu |
Freq |
Cores |
Year |
Time (seconds) |
Time |
Core i7 2600 |
3400 |
8 |
2011 |
80 |
0:01:20 |
Elbrus 4C |
750 |
4 |
2014 |
811 |
0:13:31 |
Elbrus 4C x4 |
750 |
4 |
2014 |
223 |
0:03:43 |
Elbrus 4C |
800 |
4 |
2014 |
600 |
0:10:00 |
Elbrus 1C+ |
1000 |
1 |
2015 |
1916 |
0:31:56 |
Elbrus 8C |
1300 |
8 |
2016 |
172 |
0:02:52 |
Elbrus 8C |
1200 |
8 |
2016 |
216 |
0:03:36 |
Elbrus 8C x4 |
1200 |
32 |
2016 |
57 |
0:00:57 |
Baikal M1000 |
1500 |
8 |
2016 |
161 |
0:02:41 |
Elbrus 8CB |
1550 |
8 |
2018 |
152 |
0:02:32 |
Kunpeng 920 x2 |
2600 |
96 |
2019 |
8 |
0:00:08 |
Elbrus 16C |
2000 |
16 |
2021 |
68 |
0:01:08 |
Elbrus 2C3 |
2000 |
2 |
2021 |
544 |
0:09:04 |
SuperPI (1 млн)
1 поток:
Core(TM)2 Duo CPU T9400 @ 2.53GHz: 2.58 sec
Core i7 2600 3.4 GHz: 1.81 sec
Elbrus 2C+ 0.47 GHz: 18.05 sec
Elbrus 4C 0.75 GHz: 10.18 sec
Elbrus 8C 1.2 GHz: 5.20 sec
Elbrus 8CB 1.55 GHz: 3.76 sec
Elbrus 16C 2.0 GHz: 2.77 sec
Stockfish
Cpu |
Freq |
Cores |
Year |
Time (seconds) |
Core i7 2600 |
3400 |
4 (8) |
2011 |
10860720 |
Core(TM)2 Duo CPU T9400 |
2530 |
2 |
2007 |
1254341 |
Elbrus 4C |
750 |
4 |
2014 |
541039 |
Elbrus 8C |
1200 |
8 |
2016 |
1753143 |
Elbrus 8CB |
1550 |
8 |
2018 |
3123190 |
Elbrus 16C |
2000 |
16 |
2021 |
6193924 |
Baikal M1000 |
1500 |
8 |
2016 |
2750526 |
Minerd (Cpu miner)
./minerd --benchmark -a sha256d
Core i5-2500K:
thread 0: 26798032 hashes, 5307 khash/s
Total: 21226 khash/s
Эльбрус 8С (не оптимизирован):
thread 7: 2900420 hashes, 966.98 khash/s
Total: 7736 khash/s
Эльбрус 8СВ (оптимизирован):
thread 7: 34198012 hashes, 6840 khash/s
Total: 54714 khash/s
Эльбрус 16C (оптимизирован):
thread 7: 44098544 hashes, 8820 khash/s
Total: 141104 khash/s
Байкал-М 8 core 1.5 GHz, Cortex-A57:
thread 7: 4443436 hashes, 888.20 khash/s
Total: 7023 khash/s
Intel(R) Celeron(R) CPU N3350 @ 1.10GHz
thread 0: 2097152 hashes, 2403 khash/s
Total: 4808 khash/s
./minerd --benchmark -a scrypt
Core i5-6500 3.20GHz:
thread: 19.54 khash/s
total 78.26 khash/s
Core i7-9700K:
thread 7: 131280 hashes, 26.26 khash/s
Total: 211.68 khash/s
Эльбрус 8С (не оптимизирован +профиль):
thread 7: 6777 hashes, 2.26 khash/s
Total: 18.08 khash/s
Эльбрус 8СВ (оптимизирован):
thread 0: 4096 hashes, 8.50 khash/s
Total: 68.24 khash/s
Эльбрус 16C (оптимизирован под e2k-v5):
thread 0: 4096 hashes, 11.52 khash/s
Total: 183.01 khash/s
Байкал-М 8 core 1.5 GHz, Cortex-A57:
thread 7: 8875 hashes, 1.77 khash/s
Total: 14.03 khash/s
Intel(R) Celeron(R) CPU N3350 @ 1.10GHz
thread 0: 4104 hashes, 4.63 khash/s
Total: 9.25 khash/s
SPEC 2006 INT/FP
SPEC CPU2006 инструмент исследования производительности систем, который основан на коде реальных приложений, поставляются в виде исходного кода. Тест оценивает не только производительность процессора и памяти, но и показывает то, насколько компиляторы могут оптимизировать код.
Имеется 2 группы тестов:
SPEC INT 2006, измеряющий производительность целочисленных вычислительных задач (integer);
SPEC FP 2006, измеряющий производительность вычислительных задач с вещественными числами (числами с плавающей точкой, floating point).
Результаты производительности языков программирования
Логи результатов смотрите тут:
Java
1 поток:
Эльбрус 1С+ в 11 раз медленнее на 1 поток чем Core i7 2600
Эльбрус 4С в 10 раз медленнее на 1 поток чем Core i7 2600
Эльбрус 8С в 5,5 раз медленнее на 1 поток чем Core i7 2600
Эльбрус 8СВ в 4,5 раз медленнее на 1 поток чем Core i7 2600
Эльбрус 16С в 2,5 раз медленнее на 1 поток чем Core i7 2600
На всех потоках:
Эльбрус 1С+ в 18 раз медленнее чем Core i7 2600 на всех потоках
Эльбрус 4С в 12,5 раз медленнее чем Core i7 2600 на всех потоках
Эльбрус 8С в 3 раз медленнее чем Core i7 2600 на всех потоках
Эльбрус 8СВ в 2,5 раз медленнее чем Core i7 2600 на всех потоках
Эльбрус 16С равен Core i7 2600 на всех потоках
PHP
1 поток:
Эльбрус 2С+ в 15,5 раз медленнее чем Core i7 2600
Эльбрус 1С+ в 8 раз медленнее чем Core i7 2600
Эльбрус 4С в 4,5 раза медленнее чем Core i7 2600
Эльбрус 8С в 3 раза медленнее чем Core i7 2600
Эльбрус 8СВ в 2,5 раза медленнее чем Core i7 2600
Эльбрус 16С в 2 раза медленнее чем Core i7 2600
Python
1 поток:
Эльбрус R1000 в 12,5 раз медленнее чем Core i7 2600
Эльбрус 2С+ в 30 раз медленнее поток чем Core i7 2600 на 1 поток
Эльбрус 1С+ в 12,5 раз медленнее поток чем Core i7 2600 на 1 поток
Эльбрус 4С в 15,5 раз медленнее поток чем Core i7 2600 на 1 поток
Эльбрус 8С в 9 раз медленнее поток чем Core i7 2600 на 1 поток
Эльбрус 8СВ в 7,8 раз медленнее поток чем Core i7 2600 на 1 поток
Эльбрус 16С в 7 раз медленнее поток чем Core i7 2600 на 1 поток
На всех потоках:
Эльбрус 2С+ в 58 раз медленнее поток чем Core i7 2600 на всех потоках
Эльбрус 1С+ в 25 раз медленнее поток чем Core i7 2600 на всех потоках
Эльбрус 4С в 13,5 раз медленнее поток чем Core i7 2600 на всех потоках
Эльбрус 8С в 4,2 раза медленнее поток чем Core i7 2600 на всех потоках
Эльбрус 8СВ в 3,8 раза медленнее поток чем Core i7 2600 на всех потоках
Эльбрус 16С в 1,7 раза медленнее поток чем Core i7 2600 на всех потоках
Lua
1 поток:
Эльбрус 2С+ в 16 раз медленнее чем Core i7 2600
Эльбрус 1С+ в 6 раз медленнее чем Core i7 2600
Эльбрус 4С в 10 раз медленнее чем Core i7 2600
Эльбрус 8С в 6 раз медленнее чем Core i7 2600
Эльбрус 8СВ в 5 раз медленнее чем Core i7 2600
Эльбрус 16С в 4 раз медленнее чем Core i7 2600
Эльбрус R1000 в 9 раз медленнее чем Core i7 2600
C# NetCore (В режиме трансляции RTC)
1 поток:
Эльбрус 8С в 3,5 раз медленнее на 1 поток чем Core i7 2600
Эльбрус 8СВ в 3 раз медленнее на 1 поток чем Core i7 2600
Эльбрус 16С в 2 раза медленнее на 1 поток чем Core i7 2600
На всех потоках:
Эльбрус 8С в 2 раза медленнее чем Core i7 2600
Эльбрус 8СВ в 1,5 раз медленнее чем Core i7 2600
Эльбрус 16С в 1,25 раза быстрее Core i7 2600
Выводы
Эльбрус-16С на 33% быстрее Эльбрус-8СВ на 1 поток и имеет в 2 раза больше ядер. Есть задачи, где он очень эффективен, где-то не очень, думаю найдёт свою нишу.
Жду ваши предложения, какие ещё бенчмарки можно прогнать на этих компьютерах (желательно с простой сборкой).
P. S. Принимаю ваши предложения и правки, статья пополняется.
Стикеры Телеграм с Эльбрусами: https://telegram.me/addstickers/Elbrus2000 :-)
Комментарии (203)

Alusar
27.01.2022 19:56+6Интересно.
Хотя пока слабо представляю в каких именно решениях может быть использован подобный камень.

EntityFX Автор
27.01.2022 19:57+10В считалках, в хранилках, БД сервера, защищённые компы, ну как Intel Itanium.

Neo28
28.01.2022 10:21+10Итаниум, сдох де-факто ещё в 2010 году, когда я оттуда уходил) интел его тянул ещё долго ибо были уже клиенты жирные, в основном япошки, которым по контракту интел был обязан поставлять чипы ещё несколько лет. Звучит странно но кто с Япошками работал поймёт, им что то продать сложно, но если продал они это годы будут пользовать.

vanxant
28.01.2022 00:06+1Во всех, где не любят Intel ME и прочие зонды, например.
quwy
28.01.2022 02:05+10RISC-V. И доступнее, и его производители синдромом вахтера не страдают.
vanxant
28.01.2022 03:01+11Доступнее? Назовите любой один сервер на RISC-V, чтобы можно было прям купить.
quwy
29.01.2022 14:41А много Эльбрусов можно вот прям купить? Чтобы без совдеповского маразма с обиванием порогов и подписыванием кипы бредовых бумажек?
Я не зря предложил именно "виртуальный" RISC-V, а не свободно продающийся ARM, например. Просто потому что при всей своей текущей виртуальности RISC-V все равно доступнее. Не сейчас, так в перспективе ближайшого времени.
А этих вахтеров с неблагозвучным названием и десятиление не научит простому правилу: на конкурентном рынке продавец бегает за покупателем, а не наоборот.
P.S. Ответ в том числе и на реплику@Am0ralistниже.

Am0ralist
29.01.2022 14:50На госзакупках вполне себе будет реально.
Лично вам? А зачем лично вам он? Государство для своих структур делать хочет свои решения. Это не обязательное к исполнению всем физикам и большинству юриков вещь.
Может быть риск5 от ядра станет более широко применим, и его с удовольствием станут и коммерческие структуры себе брать. А может быть — нет. Вот только эльбрусы уже есть, а рисков5 нет вообще и не будет минимум года 3 ещё.
По вашему что лучше — синица в руках илиутка под кроватьюжуравль в небе?
И кто сказал, что оные риски можно будет свободно купить?
JerleShannara
29.01.2022 15:00-2Хинт: если я не могу купить байкал, я иду и покупаю бродком/медиатек/рокчипс/аллвинер. Если я не смогу в будущем купить ядропуперриск я пойду и куплю хайфайв и прочих. Если я не могу купить эльбрус, ну да, ну да, пошёл я.
Am0ralist
29.01.2022 15:05+1А если вы не можете купить винду, то куда вы пойдёте, особенно если ваше ПО к нему прибито разработчиком всё это время было?
JerleShannara
29.01.2022 15:09-1Достану из сундука попугая и повязку, если не найду решений, которые можно будет заюзать.
П.С. Дам подсказку — в компуктерном магазине можно спокойно купить коробочку с надписью Microsoft Windows 10 Professional и даже с Microsoft Windows Server 2019. И никто вам там не скажет: руки вверх, подлая морда, покажи докУмент, что ты не МГУ.Am0ralist
29.01.2022 15:15Ну, пошла фантастика.
Да проще тогда объявить трофейной, ага.
Вас спрашиваешь про реальность, вы уходите в выдуманные миры, извините, но я сверну общение с вами, ибо на таком уровне аргументация является попыткой убедить, что бога нет, того, кто искренне верит.
Реальность — по ссылке.JerleShannara
29.01.2022 15:20-2Реальность такова, что винду (а вы про неё и спрашивали) можно купить в магазине — попробуйте, я так делал, это реально возможно.
JerleShannara
29.01.2022 17:00-2Подсказка: после покупки в зубы берётся чек с накладной, коробка с виндус. Далее идём бухгалтерию и опа, теперь это не у частника, а у организации на балансе. Если же нам надо 20000 виндусов, то есть фирмы, управляемые зицпредседателями фунтами, которые с радостью за +х% купят и перепродадут вам много чего интересного. Это если вернуться в реальность из розовых мечт, в которых ограничения действительно работают.

saboteur_kiev
30.01.2022 17:49осле покупки в зубы берётся чек с накладной, коробка с виндус. Далее идём бухгалтерию и опа, теперь это не у частника, а у организации на балансе
Простите, вьюноша.
Но потом к вам приходит аудит, находит что у вас ОС не по ГОСТ, и впаивает вам миллионный штраф. А если вы работаете в военке, то и уголовку за подрыв государственной деятельности.
Вы вообще думайте шире, а не о своем личном компьютере где-то дома или о маленькой ООО "рога и копыта". Там где нет запретов - там их нет. Там где есть - они есть.
И если уж надо работать на винде там, где нельзя, это решается другими способами, а не те варианты, которые вы предлагаете и которые выглядят как детский лепет.
JerleShannara
30.01.2022 18:09Я этим кстати реальность описывал. И если в инструкции на АРМ указана «Виндус Восемь», то ставить туда надо именно её, а за другую вам и прилетит всё, что вы наобещали. Плюс если прочитать внимательнее, с чего пошёл посыл про «купить за нал в магазе, а бухи поставят на учёт» или «заказать через фирму-прокладку», то он был про то, что делать, если используемый в производственной цепочке софт «Виндуз онли» и не хочет идеально работать при помощи всяких wine. Можете недавний скандал про турбины сименс вспомнить к примеру такого решения проблемы.

DungeonLords
30.01.2022 05:51Поддерживаю топик стартера ссылкой на компьютер на risc v. Купить можно хоть на али
Allwinner D1
Am0ralist
28.01.2022 13:12+4RISC-V. И доступнее, и его производители синдромом вахтера не страдают.
Ок, покажите в реальности а) доступный и б) производительнее уже сейчас?
А когда-нибудь — так Ядро уже начали проектировать. Через 3-5 лет увидим.

Wan-Derer
28.01.2022 15:58+2каких именно решениях может быть использован подобный камень
В любых. Это ЦП общего назначения. А то что производительность ниже..... Ну сколько реальных задач, на которых ЦП загружен круглосуточно на 100% на все ядра? Сколько задач где жизненно важная скорость обработки? Я не спорю, такие есть, но каков их процент в реальной жизни?
Интересно было бы взглянуть на такой тест, который бы учитывал производительность системы с учётом реального соотношения работы и простоя.
Alusar
28.01.2022 16:02Ну сколько реальных задач, на которых ЦП загружен круглосуточно на 100% на все ядра?
Я не говорил об этом)
Просто рассуждаю не только со стороны тех.параметров, но еще с немаловажной финансовой стороны.
Neo28
29.01.2022 07:50Не могу сказать сколько в %% по рынку. Но где сервер работает с загрузкой 80% я видел очень много. Это я бы сказал это типичный кейс для сколь-нибудь серьёзной инфраструктуры, где хотя бы пол-сотни серверов есть. 20% оставляется на нежданчики обычно. И народ да, прям вот планирует нагрузку и бюджет. Круг задач весьма высок, от стриминга киношек до ERP систем крупных контор. Да могут быть просадки в нагрузке в течении суток, но в целом сервер колбасит под нагрузкой
Wan-Derer
29.01.2022 08:21-1Хорошо. Но что мешает на такую задачу поставить два сервера вместо одного?
Занимаемое место? Ну мы же не Сингапур! Мы 8 тыс км только в ширину :) Уж под ЦОД местечко найдётся! :)
Потребляемое электричество? Ну так мы - ресурсодобывающая страна. И турбины крутить тоже умеем.
Избыточное тепло? Ну так у нас обычно холодно! Почему бы не совместить приятное с полезным? :)
В плюсах - резервирование.
Конечно, не стоит ждать что так будут мыслить обычные эксплуатанты. Им чем проще/быстрее/стандартней - тем лучше. МЦСТ и Байкал - тоже не МикроИнтел, они эту тему субсидировать не могут. Здесь должно играть государство. А государство играет пока очень вяло. Я согласен с тем одним госзаказом отрасль не вытянуть. Так же одними запретами задачу не решить. А вот если добавить сюда пряник - может получиться. Если обычному коммерческому заказчику предложить хорошие условия приобретения и дальнейшего владения - он подумает-подумает, да и решится на эксперимент. А дальше уже дело производителей - сделать так чтобы эксперимент прошёл успешно.
И во избежание бессмысленной дискуссии: я тут ни за что не "топлю", я пытаюсь ответить на вопрос "где этот камень можно применить".

Paul_Arakelyan
29.01.2022 12:29+2В настольном сегменте - производительность 1 ядра, пока что, важнее всего. Тут ситуация "ужас ужасный". И в БД - она тоже, часто, не редкая. Грубо говоря, то, что ты можешь отработать 100 параллельных запросов на 100 ядрах за 5 секунд, затратив Х Вт, не всегда компенсирует тот факт, что 1 запрос ты будешь отрабатывать те же 5 секунд, пусть даже конкурент сжирает 2*Х Вт на отработке 100 запросов, но если он это делает быстрее - юзер убежит к конкуренту и энергоэффективность не поможет.
Am0ralist
29.01.2022 13:56Стоп, нет, если именно в настольном сегменте, то там продаётся почему-то всяких силеронов, пеньков и прочего намного больше, чем топовых коре i7, у которых на ядро максимальные частоты и производительность оказывается.
Вы уже приводите в пример уже более специализированного сегмента, кому нужны мало быстрых ядер в основном.
А так даже на серверах стоят процы в основном с базовыми частотами по всем ядрам, а буст там хоть и есть, но далеко не у всех он требуется, так что даже те же армы, имея меньшее на ядро, таки в том же амазоне пошли, потому что в задачах параллельных нормально себя показали.

Rezzet
27.01.2022 20:01+10Возможно ошибаюсь, но мне кажется что там где идет простое числодробление без сложных переходов, там Эльбрус показывает себя достаточно уверено, но там где появляются условные переходы и наверно кеш-мисы, становится все плохо. Возможно дело в плохом предсказание переходов и загрузке кеша?
Если бы мне дали принимать решение о политике полупроводниковой отрасли, то наверно смотрел в сторону RISC-V.

lamerok
27.01.2022 20:08+1Насколько я понял из пресс-релиза, где то к этому и идёт, микс RISC-V и родное ядро. Первое для всего, второе для спец задач.
EntityFX Автор
27.01.2022 20:08+7У Эльбруса нет предсказателя переходов, переупорядочивания инструкций. Прямое исполнение, микрокода нет, это и требуется для защищённого исполнения кода, 3 аппаратных стека и т.д.
JerleShannara
28.01.2022 14:17+5И до сих пор нет операционной системы, которая это бы всё смогла полноценно использовать.
EntityFX Автор
27.01.2022 20:48+1RISC-V интересна, на неё плохой код вертеть самое то, если сделают процессор 256 простых risc-v ядер, но серверного исполнения (даже без SIMD). PHP, NodeJS, Python будет нормально работать.
Rezzet
27.01.2022 21:20+1Как по мне, так RISC-V интересна тем что есть огромная куча фирм которые делают блоки процессора разного назначения и фактически можно собрать современный процессор как конструкто лего. Алибаба вообще открыла свои ядра которые по их заявлениям быстре ARM A73. https://www.opennet.ru/opennews/art.shtml?num=56010
Есть разные блоки под разными лицензиями, открытые/закрытые.
Плюс софт который уже портирован на данную архитектуру.
EntityFX Автор
27.01.2022 23:24+5Кстати, МЦСТ могли бы вместо своей линейки SPARC перейти на RISC-V. И деньги бы пошли, наверное.

akaAzazello
28.01.2022 11:07+4RISC-V только-только закончил формирование спецификаций - векторное расширение(RVV), без которого он был неполным для ниши HPC, в 2021 довели до версии 1.0 - так что сейчас очень подходящее время для перехода.
Am0ralist
28.01.2022 13:14+2Ну так этим же не обязательно МЦСТ должна заниматься) У нас и другие есть. Байкаловцы ж армы делали не оглядываясь на Эльбрусы. Ядро собирается.
Это ж хорошо, если будет несколько команд и будет из чего выбирать.akaAzazello
28.01.2022 16:45+3Как заметил автор, в МЦСТ (как минимум раньше было) 2 команды разработчиков - Е2К и (Sun) Spark - и было бы логично, чтобы знакомые с RISC архитектурой спарковцы занялись бы близкой (разработанной в том же Berkeley) и свободной RISC-V архитектурой, а не, скажем, ARM или слились с E2K командой
Am0ralist
28.01.2022 17:09+1Это если есть, если есть в достаточном количестве и т.п. У них с 15 года новостей нет, да и откуда им взяться, если для военки чипы делаются вроде как «тут», а «тут» нет лучших техпроцессов. То есть в данном случае они должны будут потом соперничать с тем же Ядром по рискам, которые более коммерчески ориентированные, а я не очень в это верю — мцст слишком долго с военными чисто варилась...

amartology
28.01.2022 17:52если для военки чипы делаются вроде как «тут»
С чего вы взяли?Am0ralist
29.01.2022 11:07из интернетов, где пишут:
Выпускаются небольшими партиями по несколько десятков комплектов в месяц, часть процессоров для удешевления производятся на Тайване по российской документации, но в вычислительных комплексах СПРН применяются исключительно отечественные изделия.
amartology
29.01.2022 11:59Не стоит верить всему, что пишут в интернетах. Особенно если это не официальный пресс-релиз МЦСТ или Микрона об освоении серийного производства процессора на отечественной фабрике. Ну или, на худой конец, ТЗ на ОКР по адаптации дизайна с TSMC на Микрон.

nixtonixto
28.01.2022 09:27Смотреть лучше в сторону ARM, Apple не даст соврать. Даже здесь в тестах их процессор для мобильных телефонов оказался в разы производительней этого десктопного Эльбруса. Хотелось бы ещё увидеть не только абсолютные цифры результатов тестов, а в пересчёте на ватт потребляемой мощности. Для серверов это очень важно.
Neo28
28.01.2022 11:05+4В серверах важна не только производительность на ватт, но и скалируемость. У арма с этим печалька. Поэтому истории арм для серверов уже лет 10, но пока это узкоспециализированные решения

Layan
28.01.2022 12:41Почему узкоспециализированные то? Тот же AWS с Graviton очень даже неплох. Мы довольно быстро на него перешли — дешевле и производительнее получилось. Софт, в основном, уже собран под ARM. Да и собрать тоже не проблема.
Neo28
28.01.2022 13:03+2Амазон переработал заметную часть стека софтового под арм, они себе это могут позволить при их объемах.
Layan
28.01.2022 13:53Но ведь тот софт, что они переработали вполне можно использовать и на других ARM. Так, даже наш софт собирается под ARM и используется и на серверах, и на ноутбуках разработчиков с Apple M1.
Neo28
28.01.2022 21:58Скорее всего амазоновский софт можно пользовать на других армах, только не уверен что амазон все в опен сорс выложил)). И между "можно собрать и пользовать" и "работает хорошо и эффективно" есть большая разница) Не зря же целая индустрия существует, когда опенсорс допиливают и саппортят. Красная шапка вполне приличную кучку денег на этом зарабатывает)
Am0ralist
28.01.2022 13:16+4Смотреть лучше в сторону ARM, Apple не даст соврать.
АРМ зависит от лицензий. Например, лицензии самого арма запрещать могут их использовать в силовых ведомствах и т.п.
И смысл? Мы не китайцы, чтоб выкрутить руки арму и создать независимую от него дочку по сбору лицензионных бабок.
И смысл смотреть на них? Либо «опенсорс», либо велосипед…nixtonixto
28.01.2022 13:41-2Я на 99% уверен, что в российских реалиях «опенсорс» или велосипед окажутся такими же провальными затеями, как Йотафон, Марусся, лунная база… И в лучшем случае его будут так же, как в этой статье, сравнивать с 10...15-летними не-флагманскими моделями Интел. ИМХО более-менее конкурентоспособный процессор в России можно собрать, если брать Актуальные ядра ARM и обвешивать их своими IP, PHY и логикой. Процессор нужен не только оборонке, поэтому для гражданки вполне реально лицензировать ядра и собрать камень в разумные сроки.

anka007
28.01.2022 14:23+1На армах сложно состыковать требования вояк с требованиями лицензии арма. Сейчас вояки больше специализированные отечественные мипсы потребляют, но крупномощного на них ничего нет, насколько я знаю.
amartology
29.01.2022 18:30Вояки всю дорогу прекрасно потребляли не только отечественные ARM, но и скажем, процессоры Intel.
отечественные мипсы потребляют, но крупномощного на них ничего нет, насколько я знаю.
Неправильно знаете)

Paskin
30.01.2022 08:44Думаю, что если "числодробление" скомпилировать Интеловским компилятором - результаты i7 будут гораздо выше. А есть еще оптимизированные математические библиотеки, интринсики и т.п.


Extravert34
27.01.2022 20:08+6Выложите пожалуйста тесты на openbenchmarking.org. Там регулярно выкладываются бенчмарки разных экзотических (и не очень) процессоров, будет интересно сравнить.
EntityFX Автор
27.01.2022 20:09+2Кому интересно как посчитать теоретические FLOPS:
How calculate FLOPS (v1 .. v3):
Single Precision: 4 FP ALUs * 4 Single operation * Cores * Frequency
Double Precision: 4 FP ALUs * 2 Double operation * Cores * FrequencyHow calculate FLOPS (v4):
Single Precision: 6 FP ALUs * 4 Single operation * Cores * Frequency
Double Precision: 6 FP ALUs * 2 Double operation * Cores * FrequencyHow calculate FLOPS (v5+ [128 bit SIMD]):
Single Precision: 6 FP ALUs * 4 Single operation * 2 SIMD * Cores * Frequency
Double Precision: 6 FP ALUs * 2 Double operation * 2 SIMD * Cores * FrequencyExample for Elbrus-16C: 6 ALUs * 2 DP * 2 * 16 Cores * 2e9 = 7.68e11 --> 768 GFlops FP64

V1tol
27.01.2022 20:13+4Интернет говорит, что в 16С аж целых 8 каналов памяти. Думаю, что 2 планки очень сильно ограничивают некоторые результаты.

Armmaster
27.01.2022 20:48+1Java
1 поток:
...
Эльбрус 16С в 1,7 раз медленнее на 1 поток чем Core i7 2600
А можно уточнить, как цифра 1.7 получилась? Просто я смотрю в результаты замеров на Джаве и вижу там другие результаты. Да и чисто из понимания теории, такой результат на Э16С выглядит крайне сомнительным.

wigneddoom
27.01.2022 21:10+2Астрологи объявили неделю эльбрусов...
Baikal-S конечно интереснее выглядит.

perfect_genius
28.01.2022 15:15+2Чем он интереснее других ARM-процессоров?
amartology
28.01.2022 16:59+3Чем он интереснее других ARM-процессоров?
И много вы знаете других 48-ядерных ARM-процессоров?
Не говоря уже о том, что Байкал-S не должен быть интереснее других ARM-процессоров, он должен быть интереснее конкретно вот этого Эльбруса.wigneddoom
29.01.2022 20:01В точку. Что у Байкал, что у Эльбрус только одно "конкурентное" преимущество - проходят под лозунгом "Сделано в РФ". Только у первого готовая экосистема софта и выше производительность.
Что касается других 48-х ARM. У нас на тестах был сервер Хуавей с их KunPeng 920 (48C, 2.6 GHz), вполне приличная машинка. Поэтому если Байкаловцы не врут, и Байкал S сможет работать на 2,5 GHz и производительность будет на уровне 0,7 KunPeng 920 или примерно Intel Xeon Gold 6148, то с этим уже можно работать.
Тут главное как у них пойдёт с поставками и что их партнёры смогут предложить в виде готового продукта.


evil_kabab
27.01.2022 22:16+11Заходил на сайт мцст пару дней назад. У них нет SSL сертификата. Не то чтобы он просрочен или ещё чего, его там просто нет! Печатаешь https: и вываливается ошибка сервера...
Не думаю что это влияет на производительность их цпу, просто наблюдение...

KGeist
27.01.2022 22:58+75Зашел на сайт разработчика сайта - у самих нет сертификата. Прошелся по кейсам клиентов - у половины тоже нет, при том что где-то есть вход/регистрация. Заинтересовало, откуда такая странная студия появилась. Выяснил, что их руководитель - юрист, который делал детский сайт о президенте на на kremlin.ru, сайт о патриархе Кирилле, в основном православные проекты. Сама студия названа в честь арабского правителя 6 века Арефы Эфиопского, которого в одной из войн сжёг омиритский царь-иудей Дунаан. В какой-то момент, читая википедию о христианских великомучениках, я задумался, "а при чем тут, собственно, процессоры Эльбрус", и прекратил исследование :)





forthuser
27.01.2022 23:41+2Жду ваши предложения, какие ещё бенчмарки можно прогнать на этих компьютерах
А, проверьте, если не сложно такой «тест»
vectorforth (SIMD vectorized Forth compiler with CPU based shader application)EntityFX Автор
28.01.2022 09:42Словил ошибки компиляции
line 7861: error #350: more than one operator "*" matches these operands: function template "jtk::Expr<jtk::BinExprOp<jtk::Constant<T>, jtk::matrix<T, Container>::const_iterator, jtk::OpMul <jtk::gettype<T, T2>::ty>>> jtk::operator*(T2, const jtk::matrix<T, Container> &)" function template "jtk::matrix<double, Container> jtk::symmetric_sparse_matrix_wrapper<T>::operator*(const jtk::mat rix<double, Container> &) const [with T=double]" operand types are: const jtk::symmetric_sparse_matrix_wrapper<double> * jtk::matrix<double, std::vector<double, std::allocator<double>>> matrix<T, Container> r = b - A * out; ^ detected during: instantiation of "void jtk::preconditioned_conjugate_gradient(jtk::matrix<T, Container> &, T &, uint32_t &, const jtk::symmetric_sparse_matrix_wrapper<T> &, const TPreconditioner &, const jtk::matrix<T, Container> &, const jtk::matri x<T, Container> &, T) [with T=double, Container=std::vector<double, std::allocator<double>>, TPreconditioner=jtk::diago nal_preconditioner<double>]" at line 7917 instantiation of "void jtk::conjugate_gradient(jtk::matrix<T, Container> &, T &, uint32_t &, const jtk::symmetric_ sparse_matrix_wrapper<T> &, const jtk::matrix<T, Container> &, const jtk::matrix<T, Container> &, T) [with T=double, Co ntainer=std::vector<double, std::allocator<double>>]" at line 4739 of "/root/vectorforth/jtk/jtk.tests/mat_tests.cpp" lcc: "/root/vectorforth/jtk/jtk.tests/../jtk/mat.h", line 7861: error #350: more than one operator "*" matches these operands: function template "jtk::Expr<jtk::BinExprOp<jtk::Constant<T>, jtk::matrix<T, Container>::const_iterator, jtk::OpMul <jtk::gettype<T, T2>::ty>>> jtk::operator*(T2, const jtk::matrix<T, Container> &)" function template "jtk::matrix<float, Container> jtk::symmetric_sparse_matrix_wrapper<T>::operator*(const jtk::matr ix<float, Container> &) const [with T=float]" operand types are: const jtk::symmetric_sparse_matrix_wrapper<float> * jtk::matrix<float, std::vector<float, std::allocator<float>>> matrix<T, Container> r = b - A * out; ^ detected during instantiation of "void jtk::preconditioned_conjugate_gradient(jtk::matrix<T, Container> &, T &, uint32_t &, const jt k::symmetric_sparse_matrix_wrapper<T> &, const TPreconditioner &, const jtk::matrix<T, Container> &, const jtk::matrix< T, Container> &, T) [with T=float, Container=std::vector<float, std::allocator<float>>, TPreconditioner=jtk::diagonal_p reconditioner<float>]" at line 4773 of "/root/vectorforth/jtk/jtk.tests/mat_tests.cpp" lcc: "/opt/mcst/lcc-home/1.25.17/e2k-v5-linux/include/smmintrin.h", line 155: warning #1444: function "__builtin_ia32_dpps" (declared at line 3929 of "/opt/mcst/lcc-home/1.25.17/e2k-v5-linux/include/e2kbuiltin.h") was declared deprecated ("The function may be slow due to inefficient implementation, please try to avoid it") [-Wdeprecated-declarations] ((__m128) __builtin_ia32_dpps ((__v4sf)(__m128)(X), \ ^ in expansion of macro "_mm_dp_ps" at line 5318 of "/root/vectorforth/jtk/jtk.tests/../jtk/mat.h" __m128 d = _mm_dp_ps(v1, v2, 0xf1); ^ detected during instantiation of "void jtk::preconditioned_conjugate_gradient(jtk::matrix<T, Container> &, T &, uint32_t &, const jt k::symmetric_sparse_matrix_wrapper<T> &, const TPreconditioner &, const jtk::matrix<T, Container> &, const jtk::matrix< T, Container> &, T) [with T=float, Container=std::vector<float, std::allocator<float>>, TPreconditioner=jtk::diagonal_p reconditioner<float>]" at line 4773 of "/root/vectorforth/jtk/jtk.tests/mat_tests.cpp" 2 errors detected in the compilation of "/root/vectorforth/jtk/jtk.tests/mat_tests.cpp". make[2]: *** [jtk/jtk.tests/CMakeFiles/jtk.tests.dir/build.make:132: jtk/jtk.tests/CMakeFiles/jtk.tests.dir/mat_tests.c

aborouhin
28.01.2022 00:55+11Вот интересно, почему для сравнения выбран Core i7-2600 10-летней давности, у которого ядер меньше в 4 раза, потоков - в 2, память работает на в 2 с лишним раза меньшей частоте... Если уж мы оцениваем процессор 2021 года, давайте и возьмём в качестве конкурента какой-нибудь 11700K, хотя бы. А лучше, если потом ещё результаты тестов соотнести со стоимостью процессора - сколько производительности мы получаем на доллар/рубль.

red_andr
28.01.2022 01:25+8Ну так будет совсем не честно! Кстати, техпроцесс тоже в два раза отличается. И да, разница более чем в десять лет. Core i7-2600 был запущен в продажу в январе 2011, а Эльбрус 16С, как видим, до сих пор доступен только в инженерных образцах. В серию хорошо если пойдёт к началу 2023 года, то есть будет уже 12 лет.

gshep
28.01.2022 07:51+4наверное просто потому, что у автора тестирования под рукой есть только Core i7-2600. Я предполагаю, что если вы - или кто-либо другой - погоняют эти же самые тесты на упомянутом 11700K или Райзене, то автор добавит эти результаты в статью.

PsihXMak
28.01.2022 08:57Вот мне тоже интересно. Уже столько статей вышло и ни в одной нет сравнения с акутальными моделями.
EntityFX Автор
28.01.2022 09:08+2У меня есть только Core i7 2600 из самых мощных компов, работаю с ним уже 10 лет и все до сих пор летает (веб, разработка, игры не играю).

yamabusi
28.01.2022 14:31+1Очевидно конкретно в тесте Blender важнее многопоточность если E5-2620 v2 сделал Core i7 2600,нежели ГГц,с другой стороны у Elbrus 16C 16 ядер.

BkmzSpb
29.01.2022 13:13Недавно отправил на пенсию 2700K и заменил на 11700KF. Сразу предупреждаю, запускал на Windows как есть (чистое окружение не готовил). Имею проблемы с охлаждение, по моим прикидкам теряю примерно 1% частоты (0.05 ГГц) при продолжительной пиковой нагрузке.
Дотнетовский бенчмарк у меня один раз выпал с ArgumentOutOfRangeException при досутпе к какой-то коллекции. В остальные два раза 24 тест у меня просто не отрабатывал -- 0 загрузки CPU и 0 прогресса. Что-то странное с бенчмарком на сравнение строк параллельно -- потребляет не более 20% CPU cycles, возможно там какой-то data race происходит (либо может это IO-bound/GC-heavy, но я не заметил ни давления на память ни доступа к диску). На джаве параллельные строки работали действительно праллельно с загрузкой в 100%.
Т.к. в джаве не шарю, запустил бинарник "как есть".
Возможно я что-то еще делаю не так, но тест блендера занял у меня 22 секунды.
& 'C:\Program Files\Blender Foundation\Blender 3.0\blender.exe' -b RyzenGraphic_27.blend -f 1 -- --cycles-device CPU.logБенчмарк Blender
Blender 3.0.1 (hash dc2d18018171 built 2022-01-26 01:46:57) Read blend: C:\Users\[redacted]\Downloads\RyzenGraphic_27.blend Fra:1 Mem:63.36M (Peak 65.44M) | Time:00:00.04 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Synchronizing object | Plane.006 Fra:1 Mem:63.37M (Peak 65.44M) | Time:00:00.04 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Synchronizing object | Plane.005 Fra:1 Mem:63.37M (Peak 65.44M) | Time:00:00.04 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Synchronizing object | Plane.003 Fra:1 Mem:63.37M (Peak 65.44M) | Time:00:00.04 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Synchronizing object | Plane.001 Fra:1 Mem:63.37M (Peak 65.44M) | Time:00:00.04 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Synchronizing object | Curve.002 Fra:1 Mem:63.38M (Peak 65.44M) | Time:00:00.04 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Synchronizing object | chip_master pin_001 pin_grp372.001 Fra:1 Mem:63.40M (Peak 65.44M) | Time:00:00.04 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Synchronizing object | chip_master gold_plane.001 Fra:1 Mem:63.40M (Peak 65.44M) | Time:00:00.04 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Synchronizing object | chip_master numbers.001 Fra:1 Mem:65.56M (Peak 65.95M) | Time:00:00.05 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Synchronizing object | chip_master D_letter.001 Fra:1 Mem:64.84M (Peak 65.95M) | Time:00:00.05 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Synchronizing object | chip_master middle_layer.001 Fra:1 Mem:65.05M (Peak 65.95M) | Time:00:00.05 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Synchronizing object | black_glue chip_master.001 Fra:1 Mem:65.47M (Peak 65.95M) | Time:00:00.05 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Synchronizing object | chip_master top_layer.001 Fra:1 Mem:65.78M (Peak 65.95M) | Time:00:00.05 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Synchronizing object | chip_master gold_plane_back.001 Fra:1 Mem:65.79M (Peak 65.95M) | Time:00:00.05 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Synchronizing object | chip_master heat_spreader.001 Fra:1 Mem:66.48M (Peak 66.48M) | Time:00:00.05 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Synchronizing object | chip_master bottom_layer.001 Fra:1 Mem:66.09M (Peak 67.06M) | Time:00:00.05 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Synchronizing object | Plane.004 Fra:1 Mem:64.23M (Peak 67.06M) | Time:00:00.05 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Initializing Fra:1 Mem:58.38M (Peak 67.06M) | Time:00:00.05 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Updating Images | Loading Enso.png Fra:1 Mem:58.38M (Peak 67.06M) | Time:00:00.05 | Mem:0.00M, Peak:0.00M | Scene, RenderLayer | Updating Images | Loading summitRidge_color.jpg Fra:1 Mem:295.96M (Peak 826.42M) | Time:00:00.47 | Mem:256.00M, Peak:256.00M | Scene, RenderLayer | Waiting for render to start Fra:1 Mem:295.96M (Peak 826.42M) | Time:00:00.47 | Mem:256.00M, Peak:256.00M | Scene, RenderLayer | Loading render kernels (may take a few minutes the first time) Fra:1 Mem:295.96M (Peak 826.42M) | Time:00:00.47 | Mem:256.00M, Peak:256.00M | Scene, RenderLayer | Updating Scene Fra:1 Mem:295.96M (Peak 826.42M) | Time:00:00.47 | Mem:256.00M, Peak:256.00M | Scene, RenderLayer | Updating Shaders Fra:1 Mem:296.47M (Peak 826.42M) | Time:00:00.48 | Mem:256.01M, Peak:256.01M | Scene, RenderLayer | Updating Procedurals Fra:1 Mem:296.47M (Peak 826.42M) | Time:00:00.48 | Mem:256.01M, Peak:256.01M | Scene, RenderLayer | Updating Background Fra:1 Mem:296.47M (Peak 826.42M) | Time:00:00.48 | Mem:256.01M, Peak:256.01M | Scene, RenderLayer | Updating Camera Fra:1 Mem:296.47M (Peak 826.42M) | Time:00:00.48 | Mem:256.01M, Peak:256.01M | Scene, RenderLayer | Updating Meshes Flags Fra:1 Mem:296.47M (Peak 826.42M) | Time:00:00.48 | Mem:256.01M, Peak:256.01M | Scene, RenderLayer | Updating Objects Fra:1 Mem:296.47M (Peak 826.42M) | Time:00:00.48 | Mem:256.01M, Peak:256.01M | Scene, RenderLayer | Updating Objects | Copying Transformations to device Fra:1 Mem:296.75M (Peak 826.42M) | Time:00:00.48 | Mem:256.27M, Peak:256.27M | Scene, RenderLayer | Updating Objects | Applying Static Transformations Fra:1 Mem:296.75M (Peak 826.42M) | Time:00:00.48 | Mem:256.27M, Peak:256.27M | Scene, RenderLayer | Updating Particle Systems Fra:1 Mem:296.75M (Peak 826.42M) | Time:00:00.48 | Mem:256.27M, Peak:256.27M | Scene, RenderLayer | Updating Particle Systems | Copying Particles to device Fra:1 Mem:296.75M (Peak 826.42M) | Time:00:00.48 | Mem:256.27M, Peak:256.27M | Scene, RenderLayer | Updating Meshes Fra:1 Mem:297.11M (Peak 826.42M) | Time:00:00.48 | Mem:256.27M, Peak:256.27M | Scene, RenderLayer | Updating Mesh | Computing attributes Fra:1 Mem:297.24M (Peak 826.42M) | Time:00:00.48 | Mem:256.27M, Peak:256.27M | Scene, RenderLayer | Updating Mesh | Copying Attributes to device Fra:1 Mem:297.16M (Peak 826.42M) | Time:00:00.48 | Mem:256.33M, Peak:256.33M | Scene, RenderLayer | Updating Geometry BVH chip_master pin_001 pin_grp1848.001 1/1 | Building BVH Fra:1 Mem:297.16M (Peak 826.42M) | Time:00:00.48 | Mem:256.35M, Peak:256.35M | Scene, RenderLayer | Updating Geometry BVH chip_master pin_001 pin_grp1848.001 1/1 | Building BVH 0% Fra:1 Mem:297.16M (Peak 826.42M) | Time:00:00.48 | Mem:256.34M, Peak:256.36M | Scene, RenderLayer | Updating Scene BVH | Building Fra:1 Mem:297.17M (Peak 826.42M) | Time:00:00.48 | Mem:256.34M, Peak:256.36M | Scene, RenderLayer | Updating Scene BVH | Building BVH Fra:1 Mem:297.17M (Peak 826.42M) | Time:00:00.49 | Mem:257.67M, Peak:258.67M | Scene, RenderLayer | Updating Scene BVH | Copying BVH to device Fra:1 Mem:297.17M (Peak 826.42M) | Time:00:00.49 | Mem:257.67M, Peak:258.67M | Scene, RenderLayer | Updating Mesh | Computing normals Fra:1 Mem:299.10M (Peak 826.42M) | Time:00:00.49 | Mem:257.67M, Peak:258.67M | Scene, RenderLayer | Updating Mesh | Copying Mesh to device Fra:1 Mem:299.10M (Peak 826.42M) | Time:00:00.49 | Mem:259.59M, Peak:259.59M | Scene, RenderLayer | Updating Objects Flags Fra:1 Mem:299.10M (Peak 826.42M) | Time:00:00.49 | Mem:259.60M, Peak:259.60M | Scene, RenderLayer | Updating Images Fra:1 Mem:299.10M (Peak 826.42M) | Time:00:00.49 | Mem:259.60M, Peak:259.60M | Scene, RenderLayer | Updating Camera Volume Fra:1 Mem:299.10M (Peak 826.42M) | Time:00:00.49 | Mem:259.60M, Peak:259.60M | Scene, RenderLayer | Updating Lookup Tables Fra:1 Mem:299.10M (Peak 826.42M) | Time:00:00.49 | Mem:259.85M, Peak:259.85M | Scene, RenderLayer | Updating Lights Fra:1 Mem:299.10M (Peak 826.42M) | Time:00:00.49 | Mem:259.85M, Peak:259.85M | Scene, RenderLayer | Updating Lights | Computing distribution Fra:1 Mem:299.10M (Peak 826.42M) | Time:00:00.49 | Mem:259.85M, Peak:259.85M | Scene, RenderLayer | Updating Integrator Fra:1 Mem:299.10M (Peak 826.42M) | Time:00:00.49 | Mem:259.86M, Peak:259.86M | Scene, RenderLayer | Updating Film Fra:1 Mem:299.11M (Peak 826.42M) | Time:00:00.49 | Mem:259.61M, Peak:259.86M | Scene, RenderLayer | Updating Lookup Tables Fra:1 Mem:299.11M (Peak 826.42M) | Time:00:00.49 | Mem:259.87M, Peak:259.87M | Scene, RenderLayer | Updating Baking Fra:1 Mem:299.11M (Peak 826.42M) | Time:00:00.49 | Mem:259.87M, Peak:259.87M | Scene, RenderLayer | Updating Device | Writing constant memory Fra:1 Mem:299.13M (Peak 826.42M) | Time:00:00.49 | Mem:259.87M, Peak:259.87M | Scene, RenderLayer | Sample 0/150 Fra:1 Mem:311.38M (Peak 826.42M) | Time:00:00.64 | Remaining:00:22.91 | Mem:272.09M, Peak:272.09M | Scene, RenderLayer | Sample 1/150 Fra:1 Mem:323.59M (Peak 826.42M) | Time:00:21.32 | Mem:272.09M, Peak:272.09M | Scene, RenderLayer | Sample 150/150 Fra:1 Mem:323.59M (Peak 826.42M) | Time:00:21.32 | Mem:272.09M, Peak:272.09M | Scene, RenderLayer | Finished Saved: 'C:\tmp\0001.png' Time: 00:21.93 (Saving: 00:00.57) Blender quitdotnet 6.0
Warmup ........................ Bench [1] ArithemticsBenchmark ArithemticsBenchmark 939.62 ms 9578.35 pts 319279093.35 Iter/s Iterrations: 300000000, Ratio: 0.03 [2] ParallelArithemticsBenchmark ParallelArithemticsBenchmark 2048.15 ms 71348.99 pts 146473632.65 Iter/s Iterrations: 300000000, Ratio: 0.03 [3] MathBenchmark MathBenchmark 8839.98 ms 11312.24 pts 22624489.41 Iter/s Iterrations: 200000000, Ratio: 0.5 [4] ParallelMathBenchmark ParallelMathBenchmark 16034.94 ms 101111.87 pts 12472762.22 Iter/s Iterrations: 200000000, Ratio: 0.5 [5] CallBenchmark CallBenchmark 5052.00 ms 1980.57 pts 198056609.13 Iter/s Iterrations: 2000000000, Ratio: 0.01 [6] ParallelCallBenchmark ParallelCallBenchmark 10741.28 ms 30260.08 pts 186197518.68 Iter/s Iterrations: 2000000000, Ratio: 0.01 [7] IfElseBenchmark IfElseBenchmark 2439.66 ms 8197.86 pts 819786229.26 Iter/s Iterrations: 2000000000, Ratio: 0.01 [8] ParallelIfElseBenchmark ParallelIfElseBenchmark 2700.96 ms 125556.16 pts 740478063.00 Iter/s Iterrations: 2000000000, Ratio: 0.01 [9] StringManipulation StringManipulation 3450.07 ms 14492.44 pts 1449246.34 Iter/s Iterrations: 5000000, Ratio: 10 [10] ParallelStringManipulation ParallelStringManipulation 78165.57 ms 10256.57 pts 63966.79 Iter/s Iterrations: 5000000, Ratio: 10 [11] MemoryBenchmark MemoryBenchmark 1277.64 ms 22872.52 pts 22872.52 MB/s Iterrations: 500000, Ratio: 1 [12] ParallelMemoryBenchmark ParallelMemoryBenchmark 12719.73 ms 181774.73 pts 181774.73 MB/s Iterrations: 500000, Ratio: 1 [13] RandomMemoryBenchmark RandomMemoryBenchmark 2350.07 ms 18237.67 pts 9118.84 MB/s Iterrations: 500000, Ratio: 2 [14] ParallelRandomMemoryBenchmark ParallelRandomMemoryBenchmark 5549.28 ms 251701.26 pts 125850.63 MB/s Iterrations: 500000, Ratio: 2 [15] Scimark2Benchmark Scimark2Benchmark 16709.78 ms 11746.67 pts 1174.67 CompositeScore Iterrations: 0, Ratio: 10 [16] ParallelScimark2Benchmark ParallelScimark2Benchmark 15436.11 ms 119686.33 pts 11968.63 CompositeScore Iterrations: 0, Ratio: 10 [17] DhrystoneBenchmark DhrystoneBenchmark 1348.17 ms 34053.50 pts 8513.38 DMIPS Iterrations: 0, Ratio: 4 [18] ParallelDhrystoneBenchmark ParallelDhrystoneBenchmark 3000.43 ms 245741.61 pts 61435.40 DMIPS Iterrations: 0, Ratio: 4 [19] WhetstoneBenchmark WhetstoneBenchmark 109342.94 ms 7165.07 pts 7165.07 MWIPS Iterrations: 0, Ratio: 1 [20] ParallelWhetstoneBenchmark ParallelWhetstoneBenchmark 110528.07 ms 103971.71 pts 103971.71 MWIPS Iterrations: 0, Ratio: 1 [21] LinpackBenchmark LinpackBenchmark 2483.89 ms 22565.84 pts 2256.58 MFLOPS Iterrations: 0, Ratio: 10 [22] ParallelLinpackBenchmark ParallelLinpackBenchmark 17634.09 ms 5080.34 pts 5080.34 MFLOPS Iterrations: 0, Ratio: 10 [23] HashBenchmark HashBenchmark 2158.10 ms 9267.41 pts 926743.69 Iter/s Iterrations: 2000000, Ratio: 10Java openjdk version "1.8.0_292"
Warmup ........................ Bench [1] ArithemticsBenchmark ArithemticsBenchmark 872 ms 10321.08 pts 344036697.25 Iter/s Iterrations: 300000000, Ratio: 0.030000 [2] ParallelArithemticsBenchmark ParallelArithemticsBenchmark 2447 ms 58876.02 pts 1962538061.39 Iter/s Iterrations: 300000000, Ratio: 0.030000 [3] MathBenchmark MathBenchmark 90900 ms 1100.00 pts 2200220.02 Iter/s Iterrations: 200000000, Ratio: 0.500000 [4] ParallelMathBenchmark ParallelMathBenchmark 135701 ms 11940.00 pts 23888908.06 Iter/s Iterrations: 200000000, Ratio: 0.500000 [5] CallBenchmark Elapsed No Call: 0 Elapsed Call: 4968 CallBenchmark 4968 ms 4024.14 pts 402414486.92 Iter/s Iterrations: 2000000000, Ratio: 0.010000 [6] ParallelCallBenchmark ParallelCallBenchmark 5285 ms 61852.27 pts 6185233887.08 Iter/s Iterrations: 2000000000, Ratio: 0.010000 [7] IfElseBenchmark IfElseBenchmark 1243 ms 16090.10 pts 1609010458.57 Iter/s Iterrations: 2000000000, Ratio: 0.010000 [8] ParallelIfElseBenchmark ParallelIfElseBenchmark 2579 ms 127079.06 pts 12707911543.49 Iter/s Iterrations: 2000000000, Ratio: 0.010000 [9] StringManipulation StringManipulation 6487 ms 7700.00 pts 770772.31 Iter/s Iterrations: 5000000, Ratio: 10.000000 [10] ParallelStringManipulation ParallelStringManipulation 18905 ms 42680.00 pts 4275397.06 Iter/s Iterrations: 5000000, Ratio: 10.000000 [11] MemoryBenchmark int 4k: 24112.65 MB/s int 512k: 21943.82 MB/s int 8M: 20989.25 MB/s int 32M: 16827.59 MB/s long 4k: 47063.25 MB/s long 512k: 34566.37 MB/s long 8M: 23100.59 MB/s long 32M: 21810.06 MB/s Average: 26301.70 MB/s MemoryBenchmark 955 ms 26301.70 pts 26301.70 MB/s Iterrations: 500000, Ratio: 1.000000 [12] ParallelMemoryBenchmark ParallelMemoryBenchmark 5413 ms 147934.36 pts 147934.36 MB/s Iterrations: 500000, Ratio: 1.000000 [13] RandomMemoryBenchmark Random int 4k: 17918.58 MB/s Random int 512k: 17594.59 MB/s Random int 8M: 16973.91 MB/s Random long 4k: 36168.98 MB/s Random long 512k: 34875.00 MB/s Random long 8M: 33367.52 MB/s Average: 26149.76 MB/s RandomMemoryBenchmark 687 ms 52299.53 pts 26149.76 MB/s Iterrations: 500000, Ratio: 2.000000 [14] ParallelRandomMemoryBenchmark ParallelRandomMemoryBenchmark 2411 ms 331520.67 pts 165760.33 MB/s Iterrations: 500000, Ratio: 2.000000 [15] Scimark2Benchmark Scimark2Benchmark 34367 ms 31676.80 pts 3167.68 CompositeScore Iterrations: 0, Ratio: 10.000000 [16] ParallelScimark2Benchmark ParallelScimark2Benchmark 27409 ms 314022.20 pts 31402.22 CompositeScore Iterrations: 0, Ratio: 10.000000 [17] DhrystoneBenchmark DhrystoneBenchmark 295 ms 157004.00 pts 39251.00 DMIPS Iterrations: 0, Ratio: 4.000000 [18] ParallelDhrystoneBenchmark ParallelDhrystoneBenchmark 1127 ms 741844.00 pts 185461.00 DMIPS Iterrations: 0, Ratio: 4.000000 [19] WhetstoneBenchmark WhetstoneBenchmark 31267 ms 1591.34 pts 1591.34 MWIPS Iterrations: 0, Ratio: 1.000000 [20] ParallelWhetstoneBenchmark ParallelWhetstoneBenchmark 32012 ms 22219.28 pts 22219.28 MWIPS Iterrations: 0, Ratio: 1.000000 [21] LinpackBenchmark LinpackBenchmark 1345 ms 42190.63 pts 4219.06 MFLOPS Iterrations: 0, Ratio: 10.000000 [22] ParallelLinpackBenchmark ParallelLinpackBenchmark 16789 ms 51935.02 pts 5193.50 MFLOPS Iterrations: 0, Ratio: 10.000000 [23] HashBenchmark HashBenchmark 1290 ms 15500.00 pts 1550387.60 Iter/s Iterrations: 2000000, Ratio: 10.000000 [24] ParallelHashBenchmark ParallelHashBenchmark 13803 ms 23830.00 pts 2392870.31 Iter/s Iterrations: 2000000, Ratio: 10.000000 Total: 438557 ms 2301532.18 pts Single-thread results Operating System,Runtime,Threads Count,Memory Used,ArithemticsBenchmark,MathBenchmark,CallBenchmark,IfElseBenchmark,StringManipulation,MemoryBenchmark,RandomMemoryBenchmark,ParallelRandomMemoryBenchmark,Scimark2Benchmark,DhrystoneBenchmark,WhetstoneBenchmark,LinpackBenchmark,HashBenchmark,Total Points,Total Time (ms) Windows 10 10.0 amd64,Java Version 1.8.0_292,16,151860336,10321.08,1100.00,4024.14,16090.10,7700.00,26301.70,52299.53,331520.67,31676.80,157004.00,1591.34,42190.63,15500.00,2301532.18,438557 All results Operating System,Runtime,Threads Count,Memory Used,ArithemticsBenchmark,ParallelArithemticsBenchmark,MathBenchmark,ParallelMathBenchmark,CallBenchmark,ParallelCallBenchmark,IfElseBenchmark,ParallelIfElseBenchmark,StringManipulation,ParallelStringManipulation,MemoryBenchmark,ParallelMemoryBenchmark,RandomMemoryBenchmark,ParallelRandomMemoryBenchmark,Scimark2Benchmark,ParallelScimark2Benchmark,DhrystoneBenchmark,ParallelDhrystoneBenchmark,WhetstoneBenchmark,ParallelWhetstoneBenchmark,LinpackBenchmark,ParallelLinpackBenchmark,HashBenchmark,ParallelHashBenchmark,Total Points,Total Time (ms) Windows 10 10.0 amd64,Java Version 1.8.0_292,16,151860336;10321.08;58876.02;1100.00;11940.00;4024.14;61852.27;16090.10;127079.06;7700.00;42680.00;26301.70;147934.36;52299.53;331520.67;31676.80;314022.20;157004.00;741844.00;1591.34;22219.28;42190.63;51935.02;15500.00;23830.00;2301532.18;438557 Single-thread Units results Operating System,Runtime,Threads Count,Memory Used,ArithemticsBenchmark (Iter/s),MathBenchmark (Iter/s),CallBenchmark (Iter/s),IfElseBenchmark (Iter/s),StringManipulation (Iter/s),MemoryBenchmark (MB/s),RandomMemoryBenchmark (MB/s),ParallelRandomMemoryBenchmark (MB/s),Scimark2Benchmark (CompositeScore),DhrystoneBenchmark (DMIPS),WhetstoneBenchmark (MWIPS),LinpackBenchmark (MFLOPS),HashBenchmark (Iter/s),Total Points,Total Time (ms) Windows 10 10.0 amd64,Java Version 1.8.0_292,16,151860336,344036697.25,2200220.02,402414486.92,1609010458.57,770772.31,26301.70,26149.76,165760.33,3167.68,39251.00,1591.34,4219.06,1550387.60;2301532.18;438557 All Units results Operating System,Runtime,Threads Count,Memory Used,ArithemticsBenchmark (Iter/s),ParallelArithemticsBenchmark (Iter/s),MathBenchmark (Iter/s),ParallelMathBenchmark (Iter/s),CallBenchmark (Iter/s),ParallelCallBenchmark (Iter/s),IfElseBenchmark (Iter/s),ParallelIfElseBenchmark (Iter/s),StringManipulation (Iter/s),ParallelStringManipulation (Iter/s),MemoryBenchmark (MB/s),ParallelMemoryBenchmark (MB/s),RandomMemoryBenchmark (MB/s),ParallelRandomMemoryBenchmark (MB/s),Scimark2Benchmark (CompositeScore),ParallelScimark2Benchmark (CompositeScore),DhrystoneBenchmark (DMIPS),ParallelDhrystoneBenchmark (DMIPS),WhetstoneBenchmark (MWIPS),ParallelWhetstoneBenchmark (MWIPS),LinpackBenchmark (MFLOPS),ParallelLinpackBenchmark (MFLOPS),HashBenchmark (Iter/s),ParallelHashBenchmark (Iter/s),Total Points,Total Time (ms) Windows 10 10.0 amd64,Java Version 1.8.0_292,16,151860336,344036697.25,1962538061.39,2200220.02,23888908.06,402414486.92,6185233887.08,1609010458.57,12707911543.49,770772.31,4275397.06,26301.70,147934.36,26149.76,165760.33,3167.68,31402.22,39251.00,185461.00,1591.34,22219.28,4219.06,5193.50,1550387.60,2392870.31,2301532.18,438557CPU-Z
Processors Information ------------------------------------------------------------------------- Socket 1 ID = 0 Number of cores 8 (max 8) Number of threads 16 (max 16) Manufacturer GenuineIntel Name Intel Core i7 11700KF Codename Rocket Lake Specification 11th Gen Intel(R) Core(TM) i7-11700KF @ 3.60GHz Package (platform ID) Socket 1200 LGA (0x1) CPUID 6.7.1 Extended CPUID 6.A7 Core Stepping B0 Technology 14 nm TDP Limit 125.0 Watts Tjmax 100.0 �C Core Speed 4889.2 MHz Multiplier x Bus Speed 49.0 x 99.8 MHz Base frequency (cores) 99.8 MHz Base frequency (ext.) 99.8 MHz Stock frequency 3600 MHz Max frequency 0 MHz Instructions sets MMX, SSE, SSE2, SSE3, SSSE3, SSE4.1, SSE4.2, EM64T, AES, AVX, AVX2, AVX512F, FMA3, SHA Microcode Revision 0x3C L1 Data cache 8 x 48 KB (12-way, 64-byte line) L1 Instruction cache 8 x 32 KB (8-way, 64-byte line) L2 cache 8 x 512 KB (8-way, 64-byte line) L3 cache 16 MB (16-way, 64-byte line) Preferred cores 2 (#2, #3) Max CPUID level 0000001Bh Max CPUID ext. level 80000008h FID/VID Control yes Turbo Mode supported, enabled Max non-turbo ratio 36x Max turbo ratio 50x Max efficiency ratio 8x Min operating ratio 8x Speedshift Autonomous FLL_OC_MODE 0 FLL_OC_MODE_REG 0x00000000 O/C bins unlimited Ratio 1 core 50x Ratio 2 cores 50x Ratio 3 cores 49x Ratio 4 cores 49x Ratio 5 cores 49x Ratio 6 cores 49x Ratio 7 cores 49x Ratio 8 cores 49x IA Voltage Mode PCU adaptive IA Voltage Offset 0 mV GT Voltage Mode PCU adaptive GT Voltage Offset 0 mV LLC/Ring Voltage Mode PCU adaptive LLC/Ring Voltage Offset 0 mV Agent Voltage Mode Override Agent Voltage Target 1075 mV Agent Voltage Offset 0 mV TDP Level 125.0 W @ 36x TDP Level 95.0 W @ 31x Temperature 0 50 degC (122 degF) (Package) Temperature 1 42 degC (107 degF) (Core #0) Temperature 2 39 degC (102 degF) (Core #1) Temperature 3 39 degC (102 degF) (Core #2) Temperature 4 36 degC (96 degF) (Core #3) Temperature 5 37 degC (98 degF) (Core #4) Temperature 6 43 degC (109 degF) (Core #5) Temperature 7 39 degC (102 degF) (Core #6) Temperature 8 37 degC (98 degF) (Core #7) Voltage 0 1.46 Volts (VID) Voltage 1 +0.00 Volts (IA Offset) Voltage 2 +0.00 Volts (GT Offset) Voltage 3 +0.00 Volts (LLC/Ring Offset) Voltage 4 1.08 Volts (System Agent) Power 00 38.60 W (Package) Power 01 27.07 W (IA Cores) Power 02 n.a. (GT) Power 03 11.53 W (Uncore) Power 04 n.a. (DRAM) Clock Speed 0 4889.22 MHz (Core #0) Clock Speed 1 4889.22 MHz (Core #1) Clock Speed 2 4889.22 MHz (Core #2) Clock Speed 3 4889.22 MHz (Core #3) Clock Speed 4 4889.22 MHz (Core #4) Clock Speed 5 4889.22 MHz (Core #5) Clock Speed 6 4889.22 MHz (Core #6) Clock Speed 7 4889.22 MHz (Core #7) Core 0 max ratio 49.00 (effective 49.00) Core 1 max ratio 49.00 (effective 49.00) Core 2 max ratio 50.00 (effective 50.00) Core 3 max ratio 50.00 (effective 50.00) Core 4 max ratio 49.00 (effective 49.00) Core 5 max ratio 49.00 (effective 49.00) Core 6 max ratio 49.00 (effective 49.00) Core 7 max ratio 49.00 (effective 49.00)BkmzSpb
29.01.2022 13:57C# - имплементация хэширования просто адовая, не учитывает особенности платформы (вангую переписывание бенчей с какой-нибудь Java не задумываясь). Было бы не плохо это починить.
yamabusi
28.01.2022 14:14+1Просто ради интереса отрендерил сцену в Blender на копееченом Зеон с Алика(Intel(R) Xeon(R) CPU E5-2620 v2 @ 2.10GHz),6 ядер/12 потоков.
На 1 секунду медленнее вышло.
https://radikal.ru/lfp/d.radikal.ru/d05/2201/0a/227d8f126617t.jpg/htmЯ понимаю что там далеко не оптимизированно,но в этом плане разница производительность/доллар космическая мягко сказать.)

checkpoint
28.01.2022 03:24+3Что там с тестами кэш памяти ? Это самый важный показатель для СУБД.
EntityFX Автор
28.01.2022 09:15+1Да, есть: www.altlinux.org/Эльбрус/тесты/результаты#Тест_латентности_кеша

https://github.com/EntityFX/test-tlb checkpoint
28.01.2022 11:36+2Хорошая табличка, спасибо.
Видно, что у Э-16С кэш почти в полтора раза медленее чем у Э-8СВ, при том, что частота DDR выше (DDR4-2400 у Э-8СВ и DDR4-3200 у Э-16С если верить спецификации). Не ожиданно.
EntityFX Автор
28.01.2022 12:12+1Инженерник, там частично отключены некоторые кеш-линии, это всё влияет на результаты. Память работает на DDR4-2400, в серийном должна на DDR4-3200.
EntityFX Автор
28.01.2022 20:34STREAM
------------------------------------------------------------- STREAM version $Revision: 5.10 $ ------------------------------------------------------------- This system uses 8 bytes per array element. ------------------------------------------------------------- Array size = 10000000 (elements), Offset = 0 (elements) Memory per array = 76.3 MiB (= 0.1 GiB). Total memory required = 228.9 MiB (= 0.2 GiB). Each kernel will be executed 10 times. The *best* time for each kernel (excluding the first iteration) will be used to compute the reported bandwidth. ------------------------------------------------------------- Your clock granularity/precision appears to be 1 microseconds. Each test below will take on the order of 5202 microseconds. (= 5202 clock ticks) Increase the size of the arrays if this shows that you are not getting at least 20 clock ticks per test. ------------------------------------------------------------- WARNING -- The above is only a rough guideline. For best results, please be sure you know the precision of your system timer. ------------------------------------------------------------- Function Best Rate MB/s Avg time Min time Max time Copy: 20090.1 0.007969 0.007964 0.007975 Scale: 19408.0 0.008253 0.008244 0.008262 Add: 21848.2 0.010992 0.010985 0.011005 Triad: 22284.0 0.010776 0.010770 0.010796 ------------------------------------------------------------- Solution Validates: avg error less than 1.000000e-13 on all three arrays -------------------------------------------------------------checkpoint
28.01.2022 22:26Это тест для Э-16С ? А можно такой же тест для Э-8СВ, ну и для интелла ? Заранее большое спасибо.
InChaos
28.01.2022 09:34Кэш память ЦП важный показатель для СУБД? Извините, не мое дело, но не курите это больше.
checkpoint
28.01.2022 11:25+4Кэш память ЦП важный показатель для СУБД?
Именно так. В СУБД очень мало вычислений, подавляющее большинство операций - это копирование массивов данных из одной области памяти в другую. Чем больше и оперативней кэш, тем быстрее отработает ваш запрос.


amartology
28.01.2022 12:15+13Intel i7-2600
Status: Discontinued
Launch Date: Q1'11
Lithography: 32 nm
Реально? На в два раза меньших проектных нормах получили камень медленнее и жарче, чем уже снятый с производства десятилетний Intel, и после этого кто-то все еще считает, что у Эльбурса как архитектуры есть какие-то перспективы?Fjfvh
28.01.2022 12:43-3Тогда почему этот явно негодный процессор с удовольствием выпускают вполне современные китайские производители? Им на свою репутацию совсем наплевать?
amartology
28.01.2022 13:16+5Какие китайские производители что выпускают? Интел? Вряд ли. Эльбрус? Точно нет.

mithdradates
28.01.2022 14:02+4Тогда почему этот явно негодный процессор с удовольствием выпускают вполне современные китайские производители? Им на свою репутацию совсем наплевать?
Какие китайские производители выпускают Эльбрус? Вы про TSMC что ли? Это фаб, они "выпекают" что закажет клиент.
forthuser
28.01.2022 12:46А, почему нет?
У IA-x86 есть «тяжёлое» наследие, которое Intel должна ускорять с помощью аппаратной магии, у Эльбрус магия ускорения кода в возможностях компилятора.
При этом, полагаю, что железное наполнение у Эльбрус более специфично по его управлению, чем в модели IA-x86 в связи со спецификацией программного кода.
Отсюда следует, предположительно, что инженеры Intel вынуждены использовать определённый базис решений к которым они пришли в результате многих десятилетий, а у Эльбрус архитектуры более свободы в выборе пути реализации проекта программно-аппаратно процессора Эльбрус.
Отсюда и такие, вполне достойные результаты на «коротком» старте этого проекта.
P.S. Мне это так видится в общих рассуждениях. ????
Чем то Эльбрус похож на идеи процессора Transmeta.
Жаль, что они не смогли удержаться на рынке.amartology
28.01.2022 13:18+6Отсюда и такие, вполне достойные результаты на «коротком» старте этого проекта.
Коротком? Архитектура Эльбрус — ровесница ARM.Чем то Эльбрус похож на идеи процессора Transmeta.
Так раз Трансмета и Итаниум не смогли, может в этом есть какая-то закономерность? Например, то, что VLIW как подход к процессорам общего назначения не работает?
Жаль, что они не смогли удержаться на рынке.forthuser
28.01.2022 13:44Так и, к примеру, M68K тоже общего назначения и где то ровесница, и долго была на рынке, но конкурентную борьбу с инженерами Intel не выиграла.
И, вроде, только с Pentium-1 произошёл «отрыв» IA-x86 от конкурентов.
P.S. Даже Apple в своих ПК, 15-ть лет назад перешла на IA-x86 процессоры от Intel закопав свою архитектуру, а сейчас и от Intel процессоров ушла на свои процессоры, но разрабатывала она их в течении где то 10-ти лет.
А, сколько ещё процессоров общего назначения, к примеру, начиная с Z-80 не смогли составить конкуренцию…JerleShannara
28.01.2022 14:29+2Небольшая подсказка: что IBM Power, что M68K, что x86, что ARM вполне себе RISC/CISC/MIPS (х86 только снаружи имеет обёртку CISC, внутри это RISC начиная с Pentium Pro/2). VLIWы это: трансмета (не выстрелила), итаник(почётно утонул), ещё VLIW мелькал в GPU AMD (RDNA 2 уже не VLIW ЕМНИП) и куче сигнальных процессоров(а вот тут он выстрелил, правда нынче, если надо скорости, вместо DSP ставят FPGA).
forthuser
28.01.2022 14:44Небольшая подсказка
Имеет смысл, тогда указать, что в Вашем понимании RISC, и что с того, что где то по слухам внутри x86 есть RISC процессор, а вероятно и не один если к ним нет прямого доступа у программ.
P.S. Вы ещё не указали MISC абревиатуру.JerleShannara
28.01.2022 21:33+1Не по слухам, читайте документацию на интеловские процессоры и особенно про то, что такое микрокод. Если бы современные интеля были бы внутри чистым CISCом, то вместе с процессором вам бы в комплекте шёл фреоновый кондиционер-охладитель для процессора. RISC — короткие инструкции, подразумевающие простые действия вида «записать из памяти в регистр», «прибавить к аккумулятору регистр» и так далее, а не «взять из памяти число по смещению из регистра и прибавив к нему второй регистр положить в аккумулятор».

kedoki
28.01.2022 15:54+1ещё VLIW мелькал в GPU AMD (RDNA 2 уже не VLIW ЕМНИП)
Ну как мелькал, применялся не одно поколение начиная с HD 2000 и заканчивая HD 6000, плюс ранние APU и некоторые видеокарты формально из более поздних линеек (AMD не раз помещала карты с разными архитектурами в одну линейку). За долгие годы AMD не смогли хорошо загружать VLIW, потоковые процессоры хронически недогружались. В HD 6000 VLIW5 порезали до VLIW4, а в следующем поколении перешли на GCN с RISC. RDNA с самого начала RISC, как и GCN.
Итого: слили область GPGPU Хуангу с его RISC, не смогли обеспечить хорошую загрузку VLIW и сменили архитектуру более десяти лет назад. Не сказать, что Itanic в мире видеокарт, но от полного успеха очень далеко.

0xd34df00d
28.01.2022 21:06+7Компилятор физически не способен ускорять то, что становится известно только в рантайме, вроде нетривиальных паттернов переходов для ветвлений.

northzen
28.01.2022 13:54А какие перспективы у неЭльбруса? У его отсутствия?
Радоваться надо, что осиляют технологии хотя бы десятилетней давности.JerleShannara
28.01.2022 14:30+2Перспективы посидеть на ARMах, пока не будут готовы RISC-V.
Am0ralist
28.01.2022 14:44+4Да нет на них перспектив. Его даже в качестве компов ментам всяким не сунешь, как вроде из обсуждения прошлого на хабре вышло. То есть половину госзакупок можно сразу херить.
Наоборот, на эльбрусах можно было бы перекантоваться в плане «защищенных» с сертификатами машинках до появления рисков5, а там бы и закопать глядишь можно было бы, или наоборот, прижились бы где.JerleShannara
28.01.2022 15:18Силовикам на спарках перекантоваться проще, пока риск5 не появится, а вот куда совать e2k я вообще не знаю, ну не пригоден этот процессор на роль GP CPU. В радар его засунуть — может что и выйдет. Не силовкам — на АРМах с перспективой слезть на риск5, если всё станет только хуже.
Am0ralist
28.01.2022 16:15И где вы видели те же гозакупки, работающие на спарках?
Не, серьезно, у вас странные представления о том, чем занимается куча народа (которым компьютер нужен для работы) в наших силовых ведомствах.а вот куда совать e2k я вообще не знаю, ну не пригоден этот процессор на роль GP CPU
чего это не пригоден, когда даже процы а-ля пеньки и силероны офисные считаются пригодными? Ну те, которые 2600k скорей всего так же проиграют в этих же тестах из статьи)))
Уж на кучу рабочих мест подобные вполне сойдут. И уж точно лучше, чем спарки или некоторые мипсы…
А с учётом, что при этом по сути будет а) переход на линь, б) разрабы много чего перенесут на линь, то уж потом что именно под капотом станет вообще глубоко фиолетово.JerleShannara
28.01.2022 16:31Госзакупки, на которые прилетает птица, которая может кушать падаль и не дохнуть, вряд ли видят все. Ну а работать в условном офисе старого разлива под линуксом можно и на Rках от МЦСТ ещё какое-то время.
Am0ralist
28.01.2022 17:12+1А смысл? Эльбрусы вроде как всё равно будут производительнее всего прочего, рки 15-го года на 90 нм делаются. О чем вы?
По мне проще заказать две партии эльбрусов, что уменьшит стоимость, и воткнуть их в рабочие станции, софт даже без натива вроде как будет не хуже, а может лучше работать. А от старых байкалов даже полиция отбрыкивалась, которые мипсы, там же вообще пень4 по сути.
Ещё на 3-4 года этого бы хватило точно. А дальше — вон, ядро пообещало всех порвать, потом правда осётра подурезало по частотам. Но если получится, то эльбрусы могут уйти в какие-то специфические железки, если будут где нужны.JerleShannara
28.01.2022 21:03Ну вот опять вы Тшку приплетаете. Запишите себе: Тшка хороший микроконтроллер для управляемого L2 коммутатора, Тшка с приделанной видеокартой — условно частично терпимый тонкий клиент, если разрешение не выше 720p и нет 3D. По мне проще наконец закопать стюардессу, переждать время на спарках и стартовать на risc-v, у которого хотя бы есть более-менее нормальное комьюнити.
Am0ralist
29.01.2022 11:20Ну вот опять вы Тшку приплетаете.
Я приплетаю?
Ну вот исходя из этого и давайте поговорим, что более приспособлено быть на роль GP CPU из реально существующего?По мне проще наконец закопать стюардессу, переждать время на спарках
какие спарки, если их так же не делают массово и на них производительность тоже ни о чём? там что, 4 ядра на уровне арма 2007 года?
Ну, на них проще закопать всю инфраструктуру вообще. Вон в том окне, где открывали, туда и закрывать бегите, ибо только там бумажка ваша хранитсяJerleShannara
29.01.2022 13:34С таволгой была поличитески-маскишоу ситуация, которую ниже уже описали.
Из имеющегося на рынке с флагом «РФ» — Baikal-M1000, всё прочее либо не GPСPU, либо устаревшее порядком. Для Siloviks я предлагаю переждать на MCST R-Series (гугл кстати про это таки что-то знает). e2k — это не GPCPU как бы его не пытались за него выдать, все попытки вытащить на рынок VLIW процессоры в роли GPCPU завершились гранд-обломами, а уж ресурсов там было потрачено гораздо больше. Если уж тащить эту архитектуру — то делать из неё ускорители (матрицы 10000х10000 там перемножить, всякие фильтры наложить и т.д.) которые будут разгружать GPCPU на рабочих задачах.
JerleShannara
29.01.2022 13:56+1На 1 FPM? Думаю что вполне, если под QEMU на aarch64 запустить через wine и в PCIe вставить хорошую видеокарту.
Am0ralist
29.01.2022 14:04Ну то есть посылаете в гугл и не можете подтвердить, что Rseries r1000 на 90 нм, который примерно равен на ядро арму 2007 года, позволит юзать его как центральный процессор, а процессор, на котором даже в игрушки игрались хоть как-то — всё, фигня, он, видите ли, в 2-3 раза слабее старого i7?
все попытки вытащить на рынок VLIW процессоры в роли GPCPU завершились гранд-обломами,
Итаник завершился обломом, потому что интелу две линии тянуть не хотелось. Причём в конце итаники были просто слабее, но не критично, но смысла не было, не получилось закапать x86.
x86 у нас — нет.
Тогда и арм надо закапывать, если интел от него отказался десяток лет назад, да?
Всё, кроме вашей предвзятости у вас аргументов нет. Если вы считаете, что R1000 лучше вот 16С — ну это прям сильно.
Аргументище!
JerleShannara
29.01.2022 14:15+1Дам ещё одну подсказку — поищите древность по имени «Эльбрус 90 микро», чтобы понять для кого МЦСТ клепает SPARC. Вот они совершенно спокойно на них и пересидят, пока не появится что-то более вкусное на безпроблеммной с точки зрения лицензирования корке. Итаник завершился обломом потому, что там была та же самая канитель «будет совместимо, компилятор разрулит» и интел держал их сугубо для тех, кто поверил в то, что VLIW это круто(ибо контракты и прочее). Трансмета тоже удачно утонула со своим робинзоном на VLIW. И только МЦСТ продолжает тянуть лямку, что VLIW это GPCPU. А так — назовите на момент отказа фирмой Intel от ARM тех, кто ещё делал тогда процессоры на ARM ядрах. И назовите тех, кто на момент отказа фирмы Intel от Итаника делал тогда процессоры на VLIW.
Am0ralist
29.01.2022 14:45Ещё раз, я вам показывают закупку Т, как показатель того, куда и зачем вообще могут быть нужны подобные решения в принципе уже сейчас. Показываю их, вы мне показываете другое, что не имеет отношения к вопросу.
И там 16С — уже будет вполне хватать для всего.
Итаник ушёл, ибо был x86. У нас — НЕТ x86. До этого он как центральный процессор — работал. Понимаете, работал.
Да, на нём не получится сделать топ-топ. И?
Вы отрицаете все процессоры, кроме топов? У вас дома стоит минимум два эпика?
Нет? Тогда в чём вопрос, что даже 16с закроет кучу мест спокойно. Что всех заставят, бедняжек, перейти на линукс, а не винду? Из-за этого преживаете?
JerleShannara
29.01.2022 14:57То есть госзакупки всегда будем делать по принципу «я дебил», хорошо, записал.
Я ругаюсь с того, что стоящий у меня камень, которому уже 11 лет, по прежнему рвёт все эти эльбрусы, при учёте того, что в момент выхода он стоил менее 500уе., а бюджетные деньги тратятся на то, что ему сливает, стоит гораздо дороже и не имеет перспектив на рынке GPCPU. Вам кстати самому не смешно, что «GPCPU», представляемый как серверный, мягко говоря пригоден в основном только как десктопный? Плюс ещё один толстый и большой гвоздь в крышку VLIWа: у нас сейчас основная масса кода — это говнокод. Фреймворки на фреймворках поверх либы абстракции. При этом каждую тему с e2k преследует «ну вот компилятор допилим и всё будет телемаркет» и «ну код надо оптимизировать». Вы себе как представляете тонну говнокодеров, которые будут под e2k оптимизацию делать?
П.С. Серьёзные задачи я на домашней машине не кручу, для этого есть такие удобные штуки как мощные сервера, которые увы на e2k не удастся построить.
П.П.С. Винда у меня уже давно скончалась, живу как-то под линуксом спокойно.
Am0ralist
29.01.2022 15:13Я ругаюсь с того, что стоящий у меня камень, которому уже 11 лет, по прежнему рвёт все эти эльбрусы, при учёте того, что в момент выхода он стоил менее 500уе.
А конфидераты из-за этого войну с севером устроили. Проиграли, прикиньте? Оказалось, что иметь свою промышленность — таки надо!а бюджетные деньги тратятся на то, что ему сливает, стоит гораздо дороже и не имеет перспектив на рынке GPCPU.
Это вы про то, что примерно такой же камень в системнике, как ваш 11 летний, только с сертификатами определёнными, бюджет покупает за 180к, например?Вам кстати самому не смешно, что «GPCPU», представляемый как серверный, мягко говоря пригоден в основном только как десктопный?
Вам не смешно, что в сервере может стоять celeron ххххT?
У вас в декстопе может быть 4 ТБ оперативки?П.С. Серьёзные задачи я на домашней машине не кручу, для этого есть такие удобные штуки как мощные сервера, которые увы на e2k не удастся построить.
Ну и что? Как это отменяет тот факт, что 16С в куче мест будет выше крыши?П.П.С. Винда у меня уже давно скончалась, живу как-то под линуксом спокойно.
А вот тот весь говнософт сейчас в реале под винду написан, если что. И когда выйдут риски5, если выйдут, проблема переписать всё будет также стоять. Ибо что? Пока не пнёшь, не полетит.
Если к моменту выхода оных весь говнософт перейдёт на линукс, то уже б прекрасно всё было, но, однако, по факту, вы предлагаете ещё лет 5 сидеть ровно на заднице, потом ещё лет 5 всё переписывать, вот тогда, возможно, но не точно… Ведь и винда к тому моменту может уже на рисках начать работать.
Ну ок, замечательный план, надёжный, как швейцарские часы, ага.
JerleShannara
29.01.2022 15:18Я предлагаю говнософт пока переписать под ARM/SPARC, параллельно смотря, как это будет теоретически выглядеть на RISC-V, благо его сейчас на «посмотреть» можно даже на cyclone iv собрать. В сервер, где стоит сельдерон можно спокойно запихнуть ARM, или заменить его на несколько серверов на SPARC. В сервер, где стоит парочка Xeon, ну да, ну да, пошёл я на ближайшие пару-тройку лет.
Am0ralist
29.01.2022 16:38Я предлагаю говнософт пока переписать под ARM/SPARC,
армы уже нельзя, спарки имеют производительность хуже эльбрусов вообще.
И?
Вместо переписать под линукс.В сервер, где стоит сельдерон можно спокойно запихнуть ARM, или заменить его на несколько серверов на SPARC
с 4 тб. ну да, ну да. вы гуляйте, гуляйте
JerleShannara
29.01.2022 17:02Эмм, если вы в сервера с сельдеронами пихаете 4Тб оперативки, то надо проверить психическое здоровье.
amartology
29.01.2022 12:05+1А от старых байкалов даже полиция отбрыкивалась
Таки полиция отбрыкивалась, или просто появился удобный повод посадить владельца компании, отобрать у него бизнес и передать кому надо? А владельца потом отпустить в связи с тем, что за предельный срок ограничения свободы никакое внятное обвинение так и не вышло предъявить?Am0ralist
29.01.2022 14:06Если вы не знаете, как работают госзакупки, то, кстати, не советую вам там участвовать, а по срокам они там конкретно накосячили, кстати.
А отбрыкивались, как понимаю, в том числе потому, что, как сказал выше человек:Тшка хороший микроконтроллер для управляемого L2 коммутатора, Тшка с приделанной видеокартой — условно частично терпимый тонкий клиент, если разрешение не выше 720p и нет 3D.
А не то чтобы нормальное рабочее место, под которые ещё б пришлось кучу всего переделывать, а желания у ментов явно было мало…
Отжим компаний не обязательно через суды делать, ага.
northzen
28.01.2022 18:43Это вариант "еще немножко потерпеть". Но когда терпится, опыт разработки не накапливается, а лишь теряется.
JerleShannara
28.01.2022 21:04Ну так никто не говорит, что надо оставаться на АРМах, можно уже начинать пилить софт по risc.



Mox
28.01.2022 16:17+316 нанометровый процессор с 16 ядрами тягается, и временами проигрывает, 4-х ядерному, 8 поточному 32 нанометровому, да еще и на более медленной памяти.
Что-то печально это все (((
Надежда на то что компилятор все таки может раскрыть потенциал, но без серьезных вливаний надежды особо нет, да и политика закрытости тоже не позволяет надеяться что сообщество что-то там подпатчит.amartology
28.01.2022 17:02+3Надежда на то что компилятор все таки может
Решительно ничем не обоснованная, зато опровергаемая опытом других сходных архитектур.Mox
28.01.2022 17:44Я так понимаю что lcc еще толком не умеет profile-guided optimization, а без этого для vliw компилятора слишком мало данных. На это надежда )
amartology
28.01.2022 20:59+3Видите ли, идея VLIW была в том, чтобы можно было сделать более простое железо и дальше разогнать машину за счет компилятора. Прямо сейчас мы уже видим, что железо намного более сложное и дорогое (не конкретно сейчас более дорогое, а в большой серии 16 нм сильно дороже, чем 32 нм), чем сильно превосходящие его х86. Так зачем оно тогда?
Mox
28.01.2022 23:12Я кстати не знаю насколько оно сложное, думаю что все таки попроще чем конкуренты.
Я так понимаю что идея уперлась в то, что вещи типа Tensorflow, где процессор бы раскрылся - никто на него не портирует. А для обычных задач статических данных недостаточно, нужен компилятор с поддержкой оптимизации по собранной статистике выполнения. gcc кстати такое умел еще хз когда.Зачем - я не знаю. Идея как идея. Пока считаю чтоб без встряски, крупных инвестиций и смены политики в отношении открытости к сообществу проект загнется. Чуваки слишком надеются на государство, не пытаются денег заработать
amartology
29.01.2022 12:08кстати не знаю насколько оно сложное, думаю что все таки попроще чем конкуренты.
Настолько проще, что нужен гораздо более продвинутый техпроцесс, чтобы достичь существенно худших параметров?вещи типа Tensorflow, где процессор бы раскрылся
Не вижу причин, по которым Эльбрус был бы хорош как аппаратная часть для нейросеток. Точнее, если бы он был хорош в этом, он бы уже там использовался вовсю.
JerleShannara
29.01.2022 04:35+2Выкидываем из e2k всю ненужную периферию. Оставляем в нём только PCIe Device и кучу каналов памяти, сажаем всё это дело на full sized PCIe карту. Получаем ускоритель, который поможет разгрузить CPU на всяких хитрых задачах.
saboteur_kiev
28.01.2022 20:42+1Я вам так скажу, что мы тут в Украине завидуем что у вас есть свои разработки процессоров, которые в принципе можно сравнивать по производительности в десятки раз, а то и в разы (а не в тысячи и десятки тысяч).
Это означает что отрасль в принципе вообще есть. Да маленькая. Да, не конкурент на мировом рынке, но уже существует в виде, когда ее можно использовать даже в продакшене, и на внутреннем рынке у нее уже могут/должны быть заказчики, а это значит продолжение разработки, наработка экспертизы. И кто его знает что будет лет через 10-20.amartology
28.01.2022 21:00+1Я вам так скажу, что мы тут в Украине завидуем
У вас в Украине тоже есть толковые микроэлектронщики. Они только, как и ваши айтишники, работают на мировой рынок, а не на внутренний. И это, кстати, в плане квалификации большой плюс.saboteur_kiev
28.01.2022 23:05В том-то и дело, что работая на "мировой рынок" ты патенты не себе нарабатываешь. А в разработку основных узлов и не пустят.
amartology
29.01.2022 12:12+1А в разработку основных узлов и не пустят.
Насколько мне известно, пускают ещё как. Патенты себе — это и риски себе, видимо, желающих создавать свои собственные компании особенно нет. Но специалисты есть, и отрасль в каком-то виде есть.
В России все крутится вокруг госзаказа, а у Украины собственных денег на микроэлектронный госзаказ нет. Но у Украины есть, например, перспективы войти в ЕС и устроиться в европейскую систему микроэлектронного госзаказа. — тогда, глядишь, и собственные компании станут выгоднее работы на дядю.
vakhramov
28.01.2022 19:52DSP ядра выпилили из него?
Ребята разработали эмулятор популярного в узких музыкальных кругах ДСП от моторолы, и x86_64 этот эмулятор тянет со скрипом...

{kind=link}
theoretician
29.01.2022 07:34+2По-моему, главная проблема МЦСТ в том, что она не понимает, как правильно презентовать свои процессоры рынку. Почему-то всё время сравнивает с Intel и AMD, говоря при этом, что у монструозных западных компаний намного больше денег на разработку, производство и т.д. В этом главная ошибка, мне кажется, не надо пытаться бросать вызов существующим решениям сразу во всём, особенно в том, в чём они заведомо выиграют - в общих задачах со сложной логикой и тем более в попытках запустить программы с трансляцией в x86, показать выполнение Windows и прочее - не нужно этого делать. Автор данного повествования тоже зря ограничился "для бенчмарков это запрещено делать" - ничего не запрещено, такая честность никого не интересует, и вообще честность - это бред, в рынке надо полностью раскручивать все преимущества, даже полностью спекулятивные и фиктивные. Наоборот, надо брать особенности данной архитектуры и читить так, как недоступно для других архитектур, перекомпилировать с флагами и оптимизировать, по ситуации представляя данные процессоры не как общего серверного назначения, а специалированного. Даже статья получилась бы намного интереснее, если бы удалось полностью раскрыть именно особенности этой архитектуры, и если бы при этом эльбрусы ушли в отрыв.
Сейчас МЦСТ ещё не вклинилась в рынок, живёт за счёт господдержки, но, лично я бы не стал рассчитывать в российских реалиях на это в долгосрочной перспективе. Пусть сейчас есть господдержка, но её надо использовать, чтобы постепенно найти себя в рынке.

edo1h
29.01.2022 23:59почему всего в двумя модулями памяти? память уж точно дефицитом не является.
каналов памяти у процессора явно больше
AKonia
Простейший вопрос: тесты оптимизировали ? Просто под интел они ясен пень оптимизированы и в цифрах соменения нет, но с Эльбрусом же важна связь с компилятором, т.е. это примитивные тесты или пиковые с учётом оптимизации ? В противном случае было бы не правильно, если данное сравнение окажется из той же оперы, что и "сравниваю пузырьковую сортировку с быстрой, без оглядки на теорию сложности"
EntityFX Автор
Да, само собой. Сам код не менял, игрался флагами сборки, профилирование компилятором LCC. Но вообще компилятор МЦСТ порой странно ведёт себя, да.
Ul3ainee
Может это в начале статьи где-то указать? А то меня ровно тот же вопрос сопровождал в течение всей статьи: «чем и как компилировали тесты?». Уж очень сильно это меняет дело в случае VLIW.
EntityFX Автор
Да, добавил, а то СМИ там уже ахинею начали писать.
Banzay48
Да дружище, маху ты дал, первоначально не указав, что тесты не были оптимизированы под Эльбрус-16...
А то там в новостях, твои тесты выдирают из контекста, и пишут чуть ли не
"Энтузиаст вогнал гвоздь в крышку гроба МЦСТ и Эльбруса"...
На том же ДНС-ШОП в новостях усираются, что именно ты доказал, что Эльбрус-16 чуть ли не в 250 раз слабее Intel Core7, а в комментах там такой срач развели что дай дороги. Чуть ли не "энтузиаст-оппозиционер протестировал Эльбрус-16С, и всему миру доказал что это полный кал, крайне не рекомендованный к приобретению".
Смотри как бы теперь у тебя проблем не возникло. Те же ДНС полностью переиначили твою статью, и выставили тебя чуть ли не "борцом с системой и изобличителем лжи о импортозамещении".
Я бы на твоем месте подал на ДНС в суд, или потребовал опровержения
EntityFX Автор
Я со СМИ не сотрудничаю, мне интересны бенчмарки Эльбрусов, да и сами Эльбрусы (энтузиаст: работа с ними, программирование. Честно, мне Эльбрусы очень нравятся, хотел бы себе такой). Что там они пишут - я не отвечаю, я отвечаю за цифры и косяки тестов, постараюсь исправлять, если найдут ошибки в тестах/методике.
Факторы:
Инженерник (отключены часть кеш-линий)
2 планки ОЗУ на не полной частоте (2400 вместо 3200), надо 8 планок
Компилятор не последней версии
khis
"А вы тесты оптимизировали?" - от создателей "А вы систему оптимизировали? " И "А вы ПО оптимизировали? ".
Не слишком ли много накладных расходов ради того, чтобы заставить эту поделку работать хотябы на уровне 10-ти летнего? Я бы ещё может согласился с тем, что да, надо своё развивать, но ядра то, насколько я понимаю, это не отечественная разработка, то есть всё отечественное процессоростроение это не о классных спецах в проектировании ядер и архитектур, а о спецах, объединяющих IP ядра в соответствии с госзаказом?
trunya
Вы эльбрус с байкалом путаете
bbvoronin
Ядра, свои, родные, посконные, вероятно вы путаете Эльбрус с Байкалом (там АРМ)
Neo28
Там mips, но не суть)
amartology
В Байкал-Т — MIPS. В Байкал-M и Байкал-S — ARM.
Am0ralist
Господи, сколько дзеном затянуло сюда людей, которые к IT отношение не имеют чуть более, чем полностью…
AllexIn
ТАк VLIW это как раз о "оптимизировано компилятором".
Если мы забиваем на качество компиляции - бенч можно даже не запускать.
EntityFX Автор
Верно, это сразу бросается в глаза. Ещё нужно лезть в код и оптимизировать участки.
Neo28
Под платформу тест на уровне кода оптимизирует компилятор. У интел вместе с железом доступен свой компилятор. Основные вендоры железа контрибьютят в gcc и прочие тулы опенсорсные, что бы код работал бодро на их железе. Это огромная работа, сопоставимая с разработкой железа
oYASo
Что значит "тесты оптимизированы"? Для разработчика должно быть все по дефолту: взял код, собрал, проверил, отправил в прод. То, что там есть какая-то связь с компилятором - прекрасно, но я же не буду оптимизировать десятки миллионов строк плюсового кода, чтобы они как-то по-особенному стали работать на Эльбрусе. Разработчики процессора это подразумевают, но не уверен, что с ними согласны разработчики софта.
anka007
Вообще-то вычислительная система состоит не только из процессора. И разработчики компиляторов точно так же оттачивают свое детище на условных коремарках. Игнорирование ключей компиляции удел скриптописателей, для них эти ключи вообще что-то страшное. А вот разработчики на тех же плюсах еще и собственный скрипт сборки напишут (aka makefile), как именно и с какими ключами собирать разные части программы, чтобы получилось хорошо.
oYASo
Ключи оптимизации являются инструментом компилятора, они, естественно, должны быть выбраны максимально эффективно для целевой платформы, но я говорю не про них.
В моем понимании "оптимизация" - это затачивание тестов под конкретную платформу. e2k архитектура подразумевает, что вы знаете о широкой команде, и стараетесь писать код так, чтобы эту широкую команду максимально заполнить для параллельной обработки. Если вы делаете так, вы действительно получаете сильный буст, но проблема в том, что 99.999% кода написано без оглядки на такие архитектуры, а, следовательно, никаких преимуществ вы тут не получите.
Поэтому интересны такие тестовые кейсы:
1) Мы берем любой стандартный бенчмарк и компилим код as is под x86 и e2k и смотрим, какая разница в попугаях. В подавляюшем большинстве это то, на что нужно смотреть, потому что вряд ли люди будут переписывать openssl или какой-нибудь jsoncpp.
2) Пишем максимально эффективный код для x86 и e2k и смотрим, насколько архитектура реально эффективно тащит задачу. Этот кейс ок, когда вы самые ресурсоемкие части своего продукта сразу пишите с оглядкой на платформу e2k. Не представляю, кому это, кроме МО РФ и некоторой госухе, надо.
И я на всякий случай напомню, что VLIW в Intel умер. Да и не только в Intel, были разные идеи сделать что-то похожее, потому как сама идея выглядит вполне себе ок, но на практике оказалось, что писать эффективный компилятор под этой дело крайне сложно, а заставить всех разработчиков быть умными и сразу писать эффектиный код под архитектуру не получилось.
Crazy_Pit
это свойство vliw.. вот если в эльбрусе бы не было транслятора для Х86 . то без компилятора бы тест не запустили и вопросов бы таких не возникало..то есть на нем можно запустить тест в двух режимах.
oYASo
Не очень понял, о чем Вы. Да, Эльбрус имеет бинарный транслятор, но это все-таки дополнительный бонус для историй, когда код под платформы по каким-то причинам пересобрать нельзя. Наверное, разработчиков в первую очередь интересует история, когда код собрать можно.
Или о чем был комментарий?
Crazy_Pit
тесты собраны под х86. и сравнивать именно этот процессор в режиме трансляции не корректно. то что хотели сделать плюсом процессора обернулось минусом. тк в режиме трансляции он устурает кстати разработчики это и не скрывают. я не собирал под данный процессор ничего. и поэтому не могу ничего сказать о сложности сборки под эльбрус.
oYASo
У автора статьи тесты собраны как нативно под платформу, так и с бинарной трансляцией. Тут можно поискать со словом RTC: https://github.com/EntityFX/anybench/tree/master/results
Конечно, делать выводы по нативному исполнению и эмуляции некорреткно, это понятно. Но эмуляция x86 для Эльбруса стратегически правильное решение, потому что есть куча софта, которые портировать не получится, а запускать надо.
Но основное сравнение: это все-таки нативный код для e2k и нативный код для x86.
saboteur_kiev
> Для разработчика должно быть все по дефолту: взял код, собрал, проверил, отправил в прод
Да ладно. Возьмем какой-нить софт для расчетов, например magma
http://magma.maths.usyd.edu.au/magma/download/x86_64-linux/
Почему там есть отдельные дистрибутивы под amd и под intel?
Просто Эльбрус недоступен широким массам и не популярен, поэтому под него нужно специально компилировать, и это еще компилятор должен знать особенности эльбруса.
А так, если вас не интересует производительность, то совместимость позволяет работать и так. Но как разработчика, это вас не красит.
Am0ralist
oYASo
Потому что можно использовать свежие SSE и прочие AVX-512, которые дают сильный буст на математике.
А использование всего оптимизационного добра на e2k хоть и дают сильный буст, но только в рамках их архитектуры - остальным они все равно сильно проигрывают. Поэтому ребята из magma и всех других расчетных софтов вряд ли будут пилить какую-то серьезную поддержку нашей архитектуры, потому что зачем? И отдел стратегического планирования МЦСТ должен это понимать: никакой массовости не будет, никто специально поддержку пилить не будет, значит, большинство кода на платформе будет использоваться as is.
Karbofos42
не будешь оптимизировать - значит твой софт будет проигрывать конкурентам и его не будут покупать. Как-будто под интелы не оптимизируют и всё само работает. Нужно найти что-то в упорядоченной коллекции из миллиона элементов - все конечно же тупо перебором ищут, а там уже умный процессор встроенный оптимизатор включает и внезапно какой-нибудь бинарный поиск появляется. Или это не так работает?
sgjurano
Бинарный поиск вместо линейного процессоры делать всё же не должны :)
Они больше про локальное переупорядочивание инструкций и прочий пайплайнинг на уровне машинного кода, семантики у него особо нет, насколько мне известно.
Neo28
Хороший компилятор код довольно сильно переколбашивает, в том числе на уровне симантики языка и кусков кода, иногда заметного объема, в сотни с/c++ функций. У подобного поделия фронт энд который парсит язык это процентов 10% кода от силы, еще 10% это кодогенерация, а оставшиеся 80 это почти все оптимизация. Только по оптимизации циклов книжка с теорией страниц 500, с математикой) и еще 500-600 страниц по общим оптимизациям построением всяких SSA форм)) и еще наверно 400 про векторизацию, и наверно 300 про кодогенерацию...ну это если "класику брать")) они больше на учебник по матану похоже, чем на книжку по программированию))
arantar
Можете пожалуйста названия этих книжек скинуть?
Neo28
https://www.amazon.com/Software-Vectorization-Handbook-Multimedia-Performance/dp/0974364924#aw-udpv3-customer-reviews_feature_div
https://www.amazon.com/Compilers-Principles-Techniques-Alfred-Aho/dp/0201100886/ref=mp_s_a_1_2?crid=2AG0N3HEAF5YZ&keywords=compilers+principles%2C+techniques%2C+and+tools&qid=1643426879&sprefix=compilers%2Caps%2C252&sr=8-2
https://www.amazon.com/Optimizing-Compilers-Modern-Architectures-Dependence-based/dp/1558602860
https://www.amazon.com/Advanced-Compiler-Design-Implementation-Muchnick/dp/1558603204/ref=pd_aw_sbs_2/147-7943669-8618115?pd_rd_w=Dy5zN&pf_rd_p=bc45384a-cf15-479c-b874-e31c5245d34e&pf_rd_r=C0M20AERN9B8JMHTT1Z9&pd_rd_r=6569f36c-24e0-4e75-a233-bf6385b525dc&pd_rd_wg=uihha&pd_rd_i=1558603204&psc=1
https://www.amazon.com/Engineering-Compiler-Keith-Cooper/dp/012088478X/ref=pd_aw_vtp_1/147-7943669-8618115?pd_rd_w=Kg6m4&pf_rd_p=5de75ffb-8b60-480a-8e6e-73ac6e3b849a&pf_rd_r=C0M20AERN9B8JMHTT1Z9&pd_rd_r=6569f36c-24e0-4e75-a233-bf6385b525dc&pd_rd_wg=uihha&pd_rd_i=012088478X&psc=1
oYASo
Свидетели Отечественных Процессоров на Хабр ботов завезли, что ли?
Какой софт каким конкурентам будет проигрывать? Речь у нас про то, что софт под Эльбрус проигрывает по скорости конкурентам Intel, AMD и далее по списку. Рынок не у Эльбруса, чтобы он задавал тренды, если что :)
Под привычную нам архитектуру x86 большинство оптимизации делает компилятор, не разработчик. Эльбрусовский же компилятор за вас не делает ту работу, которая нужна дла VLIW процов. Есть даже инструкция, как с этим жить.
А то, что вы тут пишите про какие-то коллекции и поиски элементов за линию, говорит лишь о том, что вы вообще не понимаете, о чем тут речь и к чему все претензии. Алгоритмы и структуры данных работают одинаково на всех существующих платформах, потому что это математика.
DungeonLords
Для общего развития вам может быть полезна
https://habr.com/ru/post/442682/
DistortNeo
Собственно, да. После вот этой статьи:
https://habr.com/ru/post/647165/
где оптимизацией кода можно достичь ускорения в 44 раза на Эльбрусе, становится очевидным, что тестировать надо тоже правильно.
EntityFX Автор
Полностью согласен!
Neo28
Кейс классический вообщем-то. Есть софт, есть железка. Софт собирается компилятором, получается скорость х. Затем если необходимо идёт тонкая настройка руками. Стоимость доведения софта до максимальной скорости работы руками обычно дорогая и применяется в крайних случаях. Если всё вылизать то в данном случае и конкуренты мягко говоря сильно прибавят). Если надо ещё быстрее то берём и считаем на gpu, как вообщем то и делают для подобных разностных схем обычно)
Я что пытаюсь сказать. Сравнивать надо яблоки с яблоками. Те как работает тест или задача из коробки. И сколько можно выжать и за какое время руками(ну и не забываем, что людей кто может подобное делать хорошо не так много) . Ну и выбираем железо правильно под задачу)
Am0ralist
И поэтому интел кучу лет угробил на компилятор свой, который сам колбасит по исходному коду нехило так, при этом зачастую ещё и условия вставляя «если амд, не используй ветку с новыми наборами команд», чтоб сравнивались яблоки с яблоками, ага.
Если всё вылизать или если всё прибить гвоздями к конкретной реализации некросплатформенно?Более того, в том кейсе автор проводил по большей части классические манипуляции, которые улучшали скорость везде, ровно по той причине, что компиляторы сами не всегда правильно преобразуют код и иногда код нужно написать более понятно для них (не для железа).
Neo28
Ни один компилятор пока не умеет делать идеальный код. В любом компиляторе всегда ищется баланс.
Компилятор у интел специально не замедляет код для АМД, он не пользует просто фичи, где АМД лучше интел) . Да, смысл то же для юзера, но юридический смысл другой, интел из за этого ходил неоднократно в суд). И делает он так очевидно почему. Интел же не компилятор продаёт, а процессор. АМД так же делал, когда у них был свой компилятор лет 20 назад или около того. Просто бизнес)
А и да, код вылизывают, прибивают не просто гвоздями к вендору, А бывает и к конкретной железке иногда) вылизывают не всё, а только боттл неки, которые основное время жрут. Поэтому если такие кастомеры садятся на платформу, подвинуть их на конкурента очень сложно. Я ещё до времён gpu использования для расчётов с плавающей арифметики, для пиксара делал оптимизацию рендера, для рендеринга мультиков. Они сидели на интел и к красным уходить не хотели совсем) потаму что интел помогал код вылизывать, а они каждые 3-4 года обновляли процы для 20к серверов)
Am0ralist
А если найду, вы перестанете писать подобное? А если вспомнить, что бывают ещё библиотеки интела?
Так ведь в статье никто не прибил код к Эльбрусу, вообще-то. Поэтому ваши
Некорректны
X3_Shim
>> А если вспомнить, что бывают ещё библиотеки интела?
Кстати, совсем давно я ускорял матлаб, путем подсовывания в него MKL, вместо использующейся ACML, получил огромное ускорение и параллельность. Всего то небольшую интерфейсную либу приделал к MKL.
А MKL_DEBUG_CPU_TYPE вообще была изначально задумана для тестирования разных веток кода на топовых процах. Расползлось однако, хотя прикрыто имя переменной в коде было просто XORом :)
DistortNeo
Если посмотрите статью, на которую я сослался, то окажется, что прибавка у конкурентов уже не такая существенная.