

Введение в категоризацию классификаций
У вас были когда-нибудь проблемы с поиском товара в продуктовом магазине? Например, вы могли искать замороженный картофель фри в отделе замороженных завтраков, но на самом деле он находился в отделе замороженных овощей. Или вы искали соевый соус в отделе азиатской еды, а он находился в отделе приправ.
Одна из самых больших трудностей для розничных магазинов и торговых площадок — создание каталога путём категоризации миллионов продуктов в сложную систему из тысяч категорий, также называемых классификациями (taxonomies). В реальных магазинах подробная категоризация нужна для логичного упорядочивания стеллажей. В эпоху электронной коммерции и цифровых торговых площадок правильная категоризация обеспечивает множество преимуществ, в том числе улучшенные поисковые рекомендации, более подходящие предложения товаров на замену, а также более строгое соблюдение региональных и федеральных требований.
Категоризация классификаций сложна не только из-за существования в мире бесчисленного количества продуктов, образующих глубоко вложенные иерархические категории, но и из-за постоянно меняющейся природы классификаций. Невозможно найти одного специалиста в предметной области, понимающего весь каталог достаточно хорошо для того, чтобы категоризировать каждый отдельный товар, а процесс обучения команды специалистов недостаточно быстр и масштабируем по современным стандартам. Более того, входные данные никогда не идеальны, и из-за отсутствия информации иногда невозможно понять, относится ли продукт к конкретной классификации.

Наша компания работает с ведущими компаниями в сфере электронной коммерции и торговых площадок над разметкой и категоризацией миллионов продуктов в сложные иерархии классификаций. В этом посте мы опишем некоторые техники и уроки, полученные при работе над масштабированием наших конвейеров.
Динамический консенсус
Для субъективных, сложных задач мы используем технику под названием динамический консенсус. Нескольким сотрудникам предлагается независимо друг от друга выбрать ответ на одну и ту же задачу. Если мнения сотрудников совпадают, вероятность правильности ответа увеличивается. К тому же одновременно мы назначаем больший вес ответам тех сотрудников, которые ранее имели высокие показатели точности по сравнению с теми, точность которых ранее была ниже. Использование предыдущих оценок точности при вычислении консенсуса повышает точность в будущем.
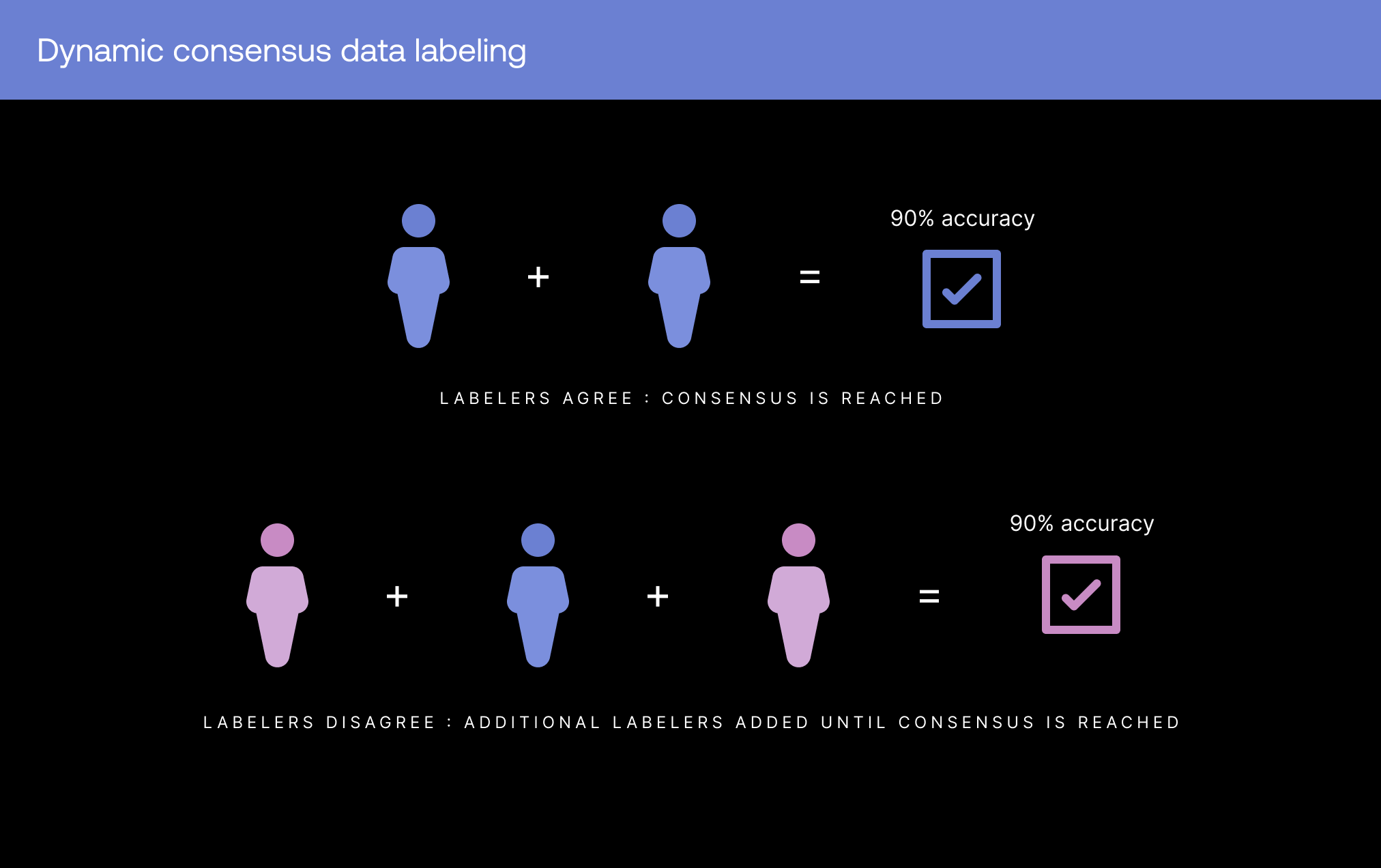
И здесь в дело вступает «динамичность» динамического консенсуса. Мы алгоритмически изменяем количество запросов ответов, пока не будет достигнут определённый уровень уверенности. Например, если на одну задачу три сотрудника дали разные ответы, мы попросим выполнить эту задачу четвёртого или даже пятого сотрудника, пока не получим высокую степень уверенности в ответе. Это позволяет нам быстро масштабировать разметку, сохраняя при этом тот же уровень качества, что и при работе с небольшой командой хорошо обученных специалистов в предметной области.
Однако с ростом количества категоризируемых продуктов также увеличивается количество нюансов задач, в которых сотрудники не достигают консенсуса. Нам необходим способ уменьшения количества задач с отсутствием консенсуса, чтобы контролёры (сотрудники, повышенные благодаря точности их работы) тратили своё время эффективнее, проверяя только действительно самые сложные задачи.
ML и консенсус между людьми
Какое-то время наша команда машинного обучения (ML) для обеспечения высококачественной разметки использовала в наших конвейерах аннотирования компьютерного зрения предразметку и автоматизацию на основе ML. (Подробнее о том, как мы масштабировали ML для нашего конвейера компьютерного зрения см. в этом посте). Предразметка (pre-labeling) — популярная техника для гибридных процессов разметки машинами + людьми, при которой модель прогнозирует ответ, а люди выполняют аудит или исправляют прогнозы модели, чтобы повысить качество. Однако при выполнении таких дискретных задач, как категоризация классификаций, подтверждение или изменение живыми сотрудниками прогнозов модели не сильно повышает её эффективность. Проверка задач категоризации занимала столько же времени, как и выполнение их с нуля. Поэтому вместо этого мы начали экспериментировать с использованием входных данных модели как отдельного мнения в нашем рабочем процессе с динамическим консенсусом.
Мы начали с обучения модели классификатора прогнозированию категории продукта из списка 4000 категорий при помощи золотого массива данных. Золотой массив данных — это подмножество данных, которое уже было размечено и подверглось многоуровневому контролю для обеспечения чрезвычайно высокого (98%+) качества. Модель, обученная на золотом массиве данных, достигла точности 75% без тонкой настройки гиперпараметров и изменения архитектуры модели. Далее мы подготовили серию экспериментов с различными комбинациями логики агрегирования ML + консенсуса между людьми, например:
- Только 1 решение ML (с наибольшей уверенностью).
- 1 решение человека + 1 решение ML (выбранное на основе различных пороговых значений уверенности).
Затем наши самые надёжные контролёры оценили точность каждой комбинации. В наших экспериментах выяснилось, что наивысший уровень точности обеспечивает один ответ человека плюс один ответ ML при уверенности 0,8. Благодаря сочетанию с другими проприетарными инструментами обеспечения качества мы смогли создать полные пакеты данных с точностью 97%+ на самом глубоком уровне категорий. Добиться такой точности чрезвычайно трудно, особенно при сложной классификации с более 4 тысячами узлов и четырьмя-шестью уровнями вложенных меток. Тем не менее, благодаря встраиванию в конвейер модели в большинстве случаев нам удалось достигать этого показателя точности при помощи одного решения человека.
В комбинации этого гибридного подхода с динамическим консенсусом все задачи получали решение хотя бы одного человека независимо от прогноза модели. Если прогноз модели и ответ человека достигают консенсуса с учётом дополнительных проверок, задача финализируется. Благодаря этому подходу мы смогли достичь консенсуса в большинстве задач и увеличили точность по сравнению с рабочим процессом, в котором участвовали только живые сотрудники, потому что ошибки моделей ML не коррелировали с ошибками людей. Это значит, что модель и человек редко ошибаются одинаково, поэтому согласие между ними обеспечивает высокую надёжность.

В более нюансированных или сложных задачах, где прогнозы моделей и ответы людей имеют низкую степень совпадений, добавляется больше мнений, пока не будет достигнут достаточный уровень согласованности, чтобы вычисленный показатель уверенности по задаче превышал пороговое значение для проекта (97%).
Вывод
Этот новый подход, комбинирующий ML + консенсус человека, значительно снижает долю задач с низкой степенью согласованности. Ещё такой подход позволяет нашим самым надёжным специалистам выверять только самые сложные проблемы во всём массиве данных.
При обучении модели классификатора мы заметили, что качество модели зависит от качества используемого в обучении массива данных. Это подкрепляет мысль о том, что в ML критически важно ставить на первое место данные.
fotobred
"Категоризация классификаций сложна ...!"
Например: - где искать растворитель Ксилол в строительном супермаркете? Возможно там же где растворители, краски, лаки? Нет - там где цемент, грунт и шпаклевка.
На первой моей работе мне поручили разработку конструкторско-технологического классификатора - не смог !
Ось, вал, шток - одно и тоже или совсем разное? Смысл / контекст разный
Вы считаете что можно "обучить" ИИ различать это?
Хорошо бы!