
"Я хочу быть объективным. Я знаю, что спасение человечества, нашей планеты в объективности." (Виктор Конецкий, "Солёный лёд")

Обычно я продумываю свои статьи годами. Сегодня я собираюсь поделиться идеями, крайне далёкими от завершённости. Многие из них требуют доработки напильником размером с самолёт, а некоторые не взлетят вообще. Но я полагаю, что если не поделиться ими сейчас, то другой возможности может не наступить никогда.
Я верю в "частичные идеи". Бывает, человек крутит в голове половину чего-то важного. А у кого-то есть вторая половина. Чтобы мысли встретились и "клацнули", кто-то должен свою половину опубликовать. Сегодня это делаю я. Считайте это скорее приглашением к обсуждению, нежели готовым рецептом.
Либретто
Однажды мне захотелось написать небольшой Machine Learning (далее ML)-скрипт, объединяющий предсказания моих друзей по политико-экономическим вопросам в единую картинку. Просто чтобы лучше оценивать будущее, нежели мышлением в одиночку или усреднением мнений.
Задача нетривиальная, но в некоторых постановках вполне разрешимая. В процессе работы я осознал, что система, предсказывающая факты будущие может, в принципе, "предсказывать" и факты уже свершившиеся. То есть, при определённых допущениях, отличать в новостях правду от лжи.
Я бы ещё долго эту мысль вылизывал, но тут грянуло вот это вот всё, и я понял, что лучше не затягивать. Мало ли как оно будет завтра. Так что делюсь тем, что есть.
Почему это важно?
За прошедшие лет сто[10] технологии создания идеологических иллюзий развились лавинообразно. Реклама, маркетинг, пропаганда опираются на колоссальную мощь СМИ, талантливых креативщиков, хорошо изученные законы психологии, современные средства связи, а с недавних пор -- ещё и на "ягодки" ИИ вроде дипфейков или теории соцсетей. Создать иллюзию чего угодно, убедительную для 90% населения, может практически кто угодно за не слишком большие деньги.
Технологии же проверки иллюзий на истинность отстали. Собственно, кроме рывка в статистике, ничего особо нового за 20-21-й век не произошло. Основные инструменты человека, желающего разобраться в картинке мира -- это по-прежнему "тщательная проверка экспертом" и "тщательная сверка фактов". Как правило, штучные и производимые почти вручную.
Итог очевиден. "Письменность с самого своего зарождения имела, казалось бы, единственного врага - ограничение свободы выражения мысли. И вот оказывается, что для мысли едва ли не опаснее свобода слова. Запрещенные мысли могут обращаться втайне, но что прикажете делать, если значимый факт тонет в половодье фальсификатов, а голос истины - в оглушительном гаме и, хотя звучит он свободно, услышать его нельзя? Развитие информационной техники привело лишь к тому, что лучше всех слышен самый трескучий голос, пусть даже и самый лживый." (Станислав Лем, "Глас Господа"). Для улучшения продаж иногда проще вложить деньги в рекламу, нежели в улучшение товара. Для... ладно, не буду про политику. И проблема эта вездесуща и характерна для любой страны мира.
Я полагаю, что сложившаяся ситуация угрожает выживанию человечества. Если каждая страна, каждая группа, каждый бизнес будут гнуть свою линию изнутри пузыря собственных иллюзий, серьёзные столкновения в мире физическом неизбежны.
Нам необходим "цифровой вытрезвитель". Причём основанный не на ручном "фактчекинге" (слово-то какое убогое!), а тоже опирающийся на современные технологии обработки информации и, в частности, машинного обучения. Именно поэтому я пишу сюда. Здесь собрались умные, энергичные, разбирающиеся в вопросе люди, готовые ставить эксперименты хотя бы и просто любопытства ради. На них вся надежда.
Что есть истина? (Общие соображения)
Я привык опираться на следующую иерархию "судов истинности" утверждений:
Личная уверенность. Хорошо работает в бытовых, повседневных вопросах. Оскальзывается коровой на льду нетривиальных ситуаций.
Мнение большинства. Уже лучше. Но, очевидно, это не последняя инстанция. Большинство тоже иногда ошибается. Большинством можно манипулировать. И даже если Вы убедили всех, что реактор безопасен, у реактора на эту тему всё равно может остаться собственное "мнение".
Математическое доказательство. Это то же "мнение большинства", но построенное и проверенное по правилам, радикально снижающим вероятность ошибки. К сожалению, математика тоже не всесильна. Дьявол в том, что одно и то же явление можно описать разными математическими формулировками, получив на выходе разную "истинность". Для галочки отметим, что и сами правила и аксиоматики не все одинаково признаются всеми математиками, хотя для нас это эффект пренебрежимый.
Физическая реальность и физический эксперимент. Трудно объявить химию выдумкой, если разработанные на её основе растворители растворяют, что предсказано. Квантовая механика по крайне мере в полупроводниках истинна, ибо телефоны в руках работают. Парацетамол снимает боль при определённом применении, даже когда вы не верите в медицину.
Гибель, в том числе массовая, при пренебрежении "указами" предыдущей инстанции. Очень хочется этого избежать, по какой причине я и пишу этот текст.
[Верующие люди размещают здесь ещё один уровень -- "божественной истины". Я не берусь о нём судить.]
Сегодняшние системы проверки истинности информации опираются, как правило, на инстанции #1 ("мнение эксперта") или #2.
При этом потенциал даже второго уровня использован лишь частично. Вопрос нередко решается голосованием, т.е. усреднением мнений. Между тем как методы машинного обучения способны[20] объединять в осмысленное целое весьма сложные, нередко на поверхности противоречивые оценки куда более эффективными способами. Так, представьте, что один человек оценивает расстояние до города в километрах, второй в милях, а третий -- в количестве возможных поездок туда-сюда за день. Если их усреднить, получится чушь. Но нейронная сеть или Random Forest может свести их высказывания в осмысленный и весьма точный результат. Хабр, возможно, стал успешной соцсетью для умников отчасти потому, что выдал разные "веса" голосам своих участников, а ведь это ещё очень простой вариант.
Потенциал же уровней #3 и #4 вообще лишь чуть тронут. Да, Википедия обычно даёт ссылочку на обосновывающий её статью эксперимент. Но статья, находящаяся за 3-4 ссылки от этой, уже вполне может содержать не слишком бросающееся в глаза противоречие результатам эксперимента. Ибо ни у кого не хватит времени и сил вручную отследить семантическую связность на пространстве столь высокой размерности. И это ещё предполагая, что Википедия не подвергается скоординированному давлению большой группы людей, чётко уверенных в своей правоте, и способных указанную ссылку просто выкинуть.
Прослеживание непротиворечивости между элементами массива данных -- едва ли не основной способ выявления подделок. Ведь можно создать любое видео, написать любой текст, приписать их любым авторам. Цифровая подпись лишь докажет, что "А не подписывал этого известной нам подписью" или что "сообщение не было изменено после возникновения", и только. И она ничего не скажет об его истинности. А вот перекрёстные сверки могут установить, увязывается ли информация с корпусом проверенных знаний, или ему противоречит.
В некоторых формах хранения знаний присутствует внутренняя структура, препятствующая ошибкам и даже намеренным модификациям. Так, в физике невозможно внезапно поменять массу электрона, не вызвав миллион противоречий просто везде. Аналогично, невозможно объявить, что гуру Х бегает, не питаясь, месяц, не войдя в противоречие со всеми учебниками физики. Минимум что можно -- это выпилить целую теорию (например, СТО), заменив её другой. Но это требует чудовищнейшей работы, колоссального ума и десятков лет, чтобы "увязать" все концы, которыми ранее была привязана СТО. Это, кстати, то, чего не понимают всякие сторонники лунного заговора или опровергатели эволюции. Они думают, что если нашли два-три сомнительных места, то всё, можно выкидывать теорию на свалку. Они просто не представляют, что мест стыковки на самом деле тысячи, и что проверять их надо все.
К сожалению, в современных новостях нет подобной самосогласованности. Журналист, да и вообще кто угодно, может написать вещь, противоречащую не только науке, но даже написанному месяц назад, и это в лучшем случае детектируется единицами читателей. Более того, в подаче новостей нет системы, которая удерживала бы смысл от переворота с ног на голову посредством мелкого манипулирования. Берём речь лица Х, опускаем пару фраз, выпячиваем какую-нибудь оговорку -- и всё. Потому что нет корпуса знания, с которым бы это вошло в противоречие. Как вошла бы в противоречие с физикой глава из Ландау после аналогичной хирургии.
Большой корпус данных также необходим для борьбы с, пожалуй, главным современным способом введения в заблуждение, именуемым "ложь умолчанием". Это когда некоторые пикселы на экране креативно закрываются, пока оставшиеся не сложатся в необходимое слово. Каждый из пикселов честно говорит свою правду, но это ли слово на самом деле написано на экране?
Теперь пара слов о предсказании. Если мы собираемся использовать supervised ML, его придётся на чём-то тренировать. Расстановка меток истинности и ложности в тренировочных данных -- дело авторское, а потому, в общем случае, произвольное. "Задавайте любые вопросы, получайте любые ответы." Поэтому, по идее, брать эти вектора надо из как можно более высоких и "твёрдых" "инстанций" истинности, где вероятность ошибки мала. Даже если придётся потом каждый раз "бегать" от них длиннющими путями к проверяемым утверждениям.
Но и самый тщательный отбор тренировочных векторов не гарантирует правильности меток. Бывают неверные интерпретации, бывают ошибки, в том числе и в физике. Бывают баги, наконец.
Для их выявления система должна время от времени обращаться к фактам, неизвестным никому. То есть, пытаться предсказывать будущее, а потом сверять его с результатом работы. Хотя бы в мелочах. Да, предсказание будущего -- очень вкусная функциональность. Но в первую очередь она должна присутствовать, как ежедневный unit-test системы. Как способ регулярно искать и исправлять в себе ошибки. А иначе можно быстро потерять связь с реальностью.
Чем это не является?
Попробуем взглянуть на системы, в чём-то отвечающие моей задумке, но ею не являющиеся. Это поможет очертить требования к ней.
Во-первых, и в самых главных, это не централизованная система. Её работа потенциально может подорвать миллиардные прибыли производителей иллюзий, а теоретическая возможность предсказывать будущее навеет запах аналогичных же прибылей. Если у вещи с такими свойствами обнаружится центр или хозяин, его однозначно подавят или перекупят. Поэтому у системы не должно быть ни хозяина, ни места, ни выключателя. Это должна быть почти самостоятельная форма жизни, как биткойн. И я не хочу произносить слово "блокчейн" но, подозреваю, что решение должно как минимум заимствовать из этой технологии. Отсутствие центра и контроля означает, кстати, невозможность "традиционной" монетизации оплатой или рекламой. Как ни крути, криптовалюта опять получается...
Это не Википедия. Вики задумана как коллекция объективных фактов, и во многом работает. Но ей многого и не хватает:
Она опирается на мнение большинства. Которое может ошибаться. Я же хочу, чтобы истина триангулировалась ("error backpropagate") от "твёрдых" фактов вроде работоспособности телефона, основ геометрии, или результатов раскопок в точке X.
В ней нет автоматической проверки сохранения согласия с источником при удалении от него по ссылкам (уже обсуждалось выше)
Из-за стилистических ограничений далеко не все готовы туда писать. Я, например, за всю жизнь сделал лишь пару мелких правок.
Она ориентирована преимущественно на текстовую информацию.
Она в значительной степени централизована. Её возможно отменить, заблокировать, перекупить.
Это не традиционная наука с её системой указания источников. Вообще-то научное знание, пожалуй, по организации ближе всего к тому, что хотелось бы получить. Но:
Занимается только тем, что считается "наукой". А если применить её вполне рабочие методы к чему-нибудь вовне, получишь или Шнобелевскую премию или удивлённое непонимание. По каковой причине науку (которая, по сути, является не чем иным, как рациональным мышлением "на стероидах") многие люди в жизни не замечают, полагают чем-то эзотерическим, а в дискуссиях с оппонентами используют в той же тональности, что и "магию".
Верификация истинности выводов из ссылок требует колоссального ручного и крайне высококвалифицированного труда. Не масштабируется.
Это не современные коммерческие соцсети вроде ФБ или Твиттера.
Да, они как раз приемлют информацию любого формата и от кого угодно. Но там всё оптимизировано не на поиск истины через обсуждение, а на engagement, и ладно бы, если в виде котиков. "Хорошим" постом обычно считается тот, который больше обсуждают. То есть, чаще некорректно сформулированный, с неаккуратными выводами, наполненный эмоциями. Соцсети не находят истину. Мнения разных людей в них не объединяются в осмысленную картинку, а, наоборот, сталкиваются лбами. А я хочу её находить. В этом смысле "старый ламповый" ЖЖ и то ближе к этой цели. В нём, по крайней мере, ИИ не прячет чужие посты произвольным образом.
Далее, случайно сделанные правильные выводы или пути рассуждений не переиспользуются в других дискуссиях.
Ну и, понятно, они централизованы.
Это не prediction market вроде Metaculus или Авгура:
Заточены на предсказание будущего в ущерб проверке настоящего
Поддерживают лишь очень узкий круг форматов вопросов, обычно с бинарным или цифровым ответом ("изберут ли X президентом до даты Y?")
Методы объединения мнений дедовские. Снаружи, по крайней мере, выглядят как усреднение или какой-нибудь softmax.
Методы, которыми отдельные успешные люди делают правильные предсказания, скрыты, и не могут быть переиспользованы для решения похожих задач.
А у Metaculus-а ещё есть и центр. Кстати, немало вполне успешных prediction markets было закрыто в США в 2003-2015-х годах.
И это, конечно, не Quora, не подобная ей "экспертная" система и не организации для факт-чекинга:
Нет "проверки реальностью"
Опора на мнение единичных "экспертов"
Плюс почти все недостатки вышеперечисленных систем
Это не вычислительная система, работающая только на компьютерах.
Не только какой-нить гигантский распределённый Kubernetes. Причина проста. Важные, даже критически важные новости, факты, события могут поступать в любом формате. От видео до текста на любом языке с тончайшими смысловыми нюансами. Неправильное превращение этих данных в вектора приведёт к провалу. Автоматические методы по "пониманию" этой информации достигли немалых успехов, но далеки ещё от требуемого уровня надёжности[30]. Человек по-прежнему является высшей инстанцией в интерпретации человеком же произведённой информации. А это значит, что люди должны быть включены в систему, массово, как и в роли интерпретаторов ("первого слоя") , так и в роли "мыслителей". И да, люди тоже неидеальны. У софта бывают баги, у людей -- тараканы, и лишь совместная работа обеих форм разума может гарантировать какую-то надёжность.
Общие контуры
...вырисовываются следующие. Нам нужна система:
Способная к предсказанию фактов и их проверке на непротиворечие накопленным "на сегодня" твёрдым знаниям
Распределённая, без центра и выключателя
Массовая, обладающая свойствами соцсети
Принимающая все основные форматы, используемые людьми для общения (текст, звук, графика), без существенных ограничений стиля
Занятая непрерывным "обратным распространением ошибок" (error backpropagation) от как можно более высоких иерархий истинности (в идеале -- "жестких физических фактов") к поступающей информации
Использующая автоматические вычисления для отслеживания "перекрёстных ссылок" и обнаружения противоречий между ними
Использующая ML для объединения возможно противоречивых сигналов в единое целое
Использующая комбинацию ML и человеческого понимания
Стабильная относительно ошибок даже больших групп людей
В идеале умеющая переиспользовать правильные решения на новых задачах
Варианты дизайна
[Ещё раз напоминаю, это черновик, и я в курсе, что идеи эти далеки от совершенства.]
A. Простейший консенсус. Самый простой дизайн, но за счёт этого, видимо, самый реальный.
Определяем узкий круг вопросов, которые мы хотим предсказывать. Лучше с бинарными ответами (да-нет) и одного типа. И лучше такими, чтобы реальность ежедневно поставляла новые наблюдения. Типа "будут ли сегодня на сайте X новости про дороги". Можно и более медленные, но тогда тренироваться придётся на старом историческом материале, который участники наверняка уже видели.
Набираем N >> 1 человек экспертов
Предлагаем им решить k задач по математике, физике, "здравому смыслу". Эти N k-мерных векторов будут частью нашего тренировочного набора данных. Зачем? Этот шаг даёт "привязку" к "твёрдой" реальности. Причём вполне возможно, что по каким-то вопросам точнее окажутся эксперты, которые неправильно решили физические задачи. Их вклад тоже нужно будет учесть через ML.
Дальше добавляем к тренировочным данным m предсказаний каждого эксперта по прошлым вопросам.
Тренируем модель нейронной сетью или (что лучше для небольших и качественно оцифрованных данных) чем-нибудь из семейства Random Forest (сам RF, AdaBoost, Gradient boosting trees -- непринципиально)
Когда реальность предъявляет новый вопрос данного типа, просим экспертов сделать индивидуальные предсказания и объединяем их натренированной моделью для оценки будущего или настоящего факта.
[Внимание! Здесь может возникнуть классическая ошибка с предсказаниями последовательностей. Когда в одном и том же наборе данных для обучения некое поле "вчера" является меткой, а "сегодня" -- фичей, то хороший ML это мгновенно подметит и смухлюет, "предсказав" вчерашнюю метку из "сегодняшнего" будущего. Training AUC получится бешеным, но, понятное дело, про искомую задачу ни шиша такой ML не выучит.]
Плюсы:
Просто. Любой ML-инженер с парой лет опыта это напишет.
Почти наверняка будет работать. Собственно, я знаю, что подобное пробовалось, так что хоть как-то работать оно будет.
Учитывает "физическую реальность"
Может использоваться и для проверки уже свершившихся фактов на истинность.
Минусы:
Работает на очень узком круге вопросов. Если мы хотим вместо "вырастут ли акции X" начать угадывать "вырастут ли акции Y", всю тренировку придётся начинать сначала.
Централизованно и выключаемо.
Истинность тренировочных фактов оценивает кем-то извне. Со всеми сопутствующими рисками.
Можно ли улучшить этот дизайн, заставив его работать на более широком круге задач? Вот тут уже начинаются тонкости.
B. Смешанный разум.
Современный ML прекрасно "вычисляет" на уже оцифрованных данных. Но плохо их цифрует. Плохо, плохо, не надо мне кивать на нейронные сети. То внезапный диван[40] случится, то шизофренический диалог[30]. Достаточно точности, чтобы гнать рекламу по площадям или принимать первый уровень телефонных звонков. Но напрочь мимо, когда надо улавливать тонкие нюансы семантики, иносказаний, иронии и намёков. Из которых треть современной рекламы и пропаганды состоит. Масса вопросов резко меняют смысл от чуть заметной правки, а иногда вообще бывают некорректны. "Достаточно ли на Земле нефти?" ответа не имеет. Потому что предполагает забытое "а для чего?" и "а насколько дешёвой?"
Человек, с другой стороны, все эти вещи понимает "на ура". Но скверно "вычисляет" и очень плохо исполняет "обратное распространение ошибок", даже если насильственно выстроить его в шеренгу нейронную сеть.
Так вот. Нельзя ли "объединить бренды"? Пусть люди "оцифровывают" произвольные сигналы, а ML связывает результаты оцифровки в оценку/предсказание?
В принципе, попытки объединять человеческое и машинное мышление уже делались. Вот "кентавр" -- человеческое сознание сидит на выходе нескольких ML-обработчиков и интерпретирует их выводы. Так работают военные, исследовательские отделы, эксперты. Вот "осьминог" -- выхлоп от большого количества людей объединяется в осмысленное целое ML-обработчиком, сидящим сверху. Сильно подозреваю, что так работает ФБ.
Но нам же нужен "мозг": сеть, элементами которой в почти произвольном порядке могут выступать как люди, так и ML-элементы какой угодно специализации. Причём последним слоем системы должен быть не коммерческий или иной человеческий заказчик (он быстро настроит всю систему под свои сиюминутные нужды), а "твёрдые факты".
Примерно так:
На вход поступает новая единица данных. Текст, статья из Вики, новость, видео, или выхлоп от другой аналогичной системы.
Некоторые люди реагируют на эти данные. Пусть хотя бы лайками, хотя возможны более интересные варианты. Набор этих лайков и будет вектором "оцифровки" поступившего сигнала.
К нему никто не мешает добавить аналогичный вектор оцифровки от ML-элементов (проверка на редактирование; статистические характеристики текста; иные предикторы, тоже пытающиеся что-то предсказать). Например, Latent_Dirichlet_allocation для векторизации текстов. Только не вместо, ибо именно так можно потерять наиболее важные семантические "хвосты".
-
Вектор изменений скармливается "верхнему" слою ML. Далее возможны варианты:
Новой единице уже присвоено известное значение "истина или ложь". ML делает круг обучения на этом примере. Важно, однако, вкармливать тогда в систему как множество "твёрдых" фактов, так и намеренных фейков. Не факт, что людям это понравится.
На выходной (верхний) слой подаётся набор метрик из "физического" мира: начала (или неначала) войн, падения/рост фондового рынка, изменения объёмов эмиграции, признание нового открытия физиками, создание патента или бизнеса на основе новости и т.п. ML пытается предсказывать эти параметры.
После обучения новые новости оцениваются на истину/ложь или на ожидаемое влияние на мир.
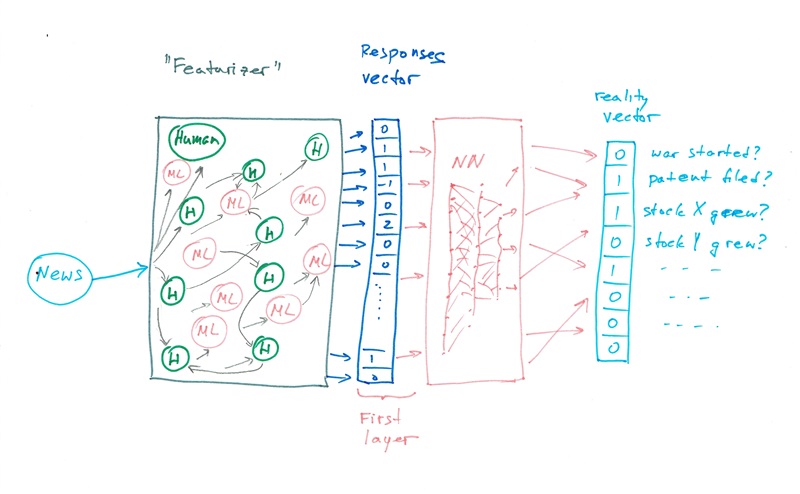
Плюсы:
Легко распределяется. На шагах 2-3 в систему можно подавать выхлоп практически от чего угодно.
Работает с любыми данными.
Минусы:
Работает ли?
Непонятно, решает ли проблему дальних перекрёстных ссылок. Я, например, сомневаюсь, что можно за разумное время пропустить через это всю Википедию.
Задачи "проверки на истинность" и "предсказания будущего" оказываются разведёнными, я не вижу, как свести их здесь в одну.
"Проверка на истинность" по-прежнему может зависеть от определений, данных внешним к системе наблюдателем.
C. Предсказывающая соцсеть
Соцсеть, где кто угодно может писать что угодно. Котики, новости, размышлизмы. Но каждый кусок контента помечается автором комбинацией из следующих четырёх флагов:
а) Это "данные". Фото, наблюдение, воспоминание, результаты эксперимента. Автор, если только не добавил других флагов, не претендует на выводы или предсказания.
б) Это "предсказание". Автор делает верифицируемое предсказание, которое могут проверить на истинность другие участники. "Завтра пойдёт дождь", "процент аварий ракет данного типа превысит 4% за следующие пять лет" и т.п.
в) Это "способ рассуждения". "Если Вам надо решить кубическое уравнение / выбрать хороший фотоаппарат / отличить грипп от простуды, то Вы делаете так". Читаемая вами статья, кстати, принадлежит этой категории.
г) Это "искусство". Автор делает предсказание, что его работа кому-то понравится.
Постить в сеть могут хоть люди, хоть роботы. А дальше действуют такие правила:
а) За сбывшееся предсказание или лайк искусству автор зарабатывает плюшки. Крипту, пойнты, места в рейтинге и т.п. Тут требуется работа, чтобы отсеять тривиальные предсказания с нулевой информацией ("снег завтра или пойдёт, или не пойдёт"), но примем пока, что она проделана.
б) Данные или способы рассуждения, использованные другими авторами для успешных предсказаний, тоже получают плюшки. Аналогично с искусством, использующим другое искусство.
в) Главная сложность, разумеется, в том, как определить, что что-то "опиралось на" или "использовало метод Х". Для разрешения этой задачи мыслятся несколько механизмов:
в.1.) Сами авторы могут указывать использованные ресурсы.
в.2.) В процессе написания постов ML может просматривать уже содержащееся в сети и предлагать прошлые посты, если пара "этот, тот пост" генерит высокую вероятность значения "использует", полученную из тренировки на всех предыдущих парах.
в.3.) Более сложные ML-боты могут ходить по уже написанному и выискивать "использующие" пары в прошлых текстах. Правда, тренировать их придётся на мнении большинства. Однако есть надежда, что ошибки оного, даже намеренные, в вопросах использования будут в основном ортогональны ошибкам в вопросах истинности, и поэтому не нарушат сходимость метода.
Важно изначально "засеять" эту соцсеть достоверными "твёрдыми" фактами. Хотя бы научными. Тогда быть может, дальнейшие добавления будут, как минимум, им не противоречить.
Плюсы:
Система предсказывает будущее. Причём может это делать, основываясь даже на ложных фактах.
Минусы:
Соцсеть. Непонятно, удастся ли набрать достаточно желающих ней участвовать? Даже в порядке эксперимента?
Непонятно, будет ли это всё работать, и если да, то к чему сойдётся.
D. EM-подходы.
Тут вообще думать не надо.
Накидали вперемешку фактов всех рангов и мастей, от утверждений квантовой механики до анекдотов и новостей.
Оцифровали их, показав людям и получив оценки истинности 0 или 1 для каждого факта.
Допустили, что каждый факт сгенерился одним из K "генераторов реальности".
Применили кластеринг и разбили наши данные на K "картин мира", более-менее внутренне согласованных.
Плюс тут один: это просто, как топор, пишется одной левой на коленке, и однозначно должно работать.
Главный минус очевиден: подход не разделяет данные на "истинные" и "ложные". Он только делит их на классы. Но всё-таки вместо миллиона видов заблуждений получаем уже лишь 5-10. Можно систематизировать их или налаживать диалог между системами. Кроме того, можно смотреть, какие предсказания делает каждое из "царств" и сверять его с наступившей реальностью. Это быстро позволит отсеять совсем уж неадекватные системы взглядов.
Вторичный минус -- кластеров можно получить столько и таких разных, сколько существует алгоритмов кластеризации и метапараметров. Они ведь лишь более плотно переупаковывают данные, только и всего.
Дизайн можно чуть изменить. Пусть входными данными будут вектора <оцифровка события, оценка истинности>, причём оценки допускаются от кого угодно, от "очевидно" правильных до пусть даже "очевидно ошибочных". Таким образом, одинаковые вектора с противоположными оценками одних и тех же событий тоже могут присутствовать в выборке.
Далее допустим, что при подготовке этих данных действовали K разных механизмов оценки данных на истинность. То есть, наш тренировочный набор -- это смесь из K моделей. Возможно, противоречащих друг другу, но внутренне согласованных. Как разделить эти модели? Следуя парадигме Expectation-Maximization[50], делаем следующее:
Добавляем к данным ещё одну колонку для номера модели, их сгенерившей
Каждому вектору (с оценкой) назначаем случайное значение номера модели, от 0 до K-1
Заводим K бинарных классификаторов
Обучаем каждый из них на всех данных, включая колонку "номер модели". Требуем предсказать оценку истинности в каждом векторе.
Затем для каждого наблюдения: 5.1. Применяем все K классификаторов 5.2. Находим k* -- номер классификатора, чья оценка вероятности истинности для данного наблюдения оказалась наиболее близкой к зафиксированной для него 5.3. Пишем k* в колонку "номер модели" для этого наблюдения
Повторяем 4-5, пока не сойдётся.
А оно сойдётся, это основное свойство Expectation-Maximization. Правда, не факт, что быстро. Результат, в общем, почти тот же, что и выше. Но в качестве "бонуса" у вас ещё K предсказателей, описывающих K основных способов оценки истинности в наблюдаемой "дикой природе".
Что это нам даст?
Предположим, система написана и даже идеально заработала. Перестанут ли люди, политики, реклама, новости вводить в заблуждение? Да никоим образом. Для них выводы системы -- в лучшем случае "ещё одно мнение". Собственно, то, что они делают, и враньём-то назвать нельзя. Это же "толки", простите, прямо по Хайдеггеру: "Беспочвенная сказанность и далее пересказанность есть толк." Разумеется, всё продолжится.
Тогда зачем?
Я вижу три плюса, в зависимости от достигнутой функциональности:
Нахождение кратчайших путей от заданного утверждения к противоречащему ему. "Рациональное мышление не работает" и "компьютер, с которого Вы это пропагандируете, работает" находятся в прямом противоречии. Даже такая рудиментарная способность уже позволит ограничить информационный шум и лучше участвовать в дискуссиях.
Создание "точки сборки" для людей с рациональным мышлением. Для людей, объединяемых эмоциями, такую точку сборки мы (технари!) уже создали. Все эти Фейсбуки, твиттеры, да и Вотсапы, в общем -- это оно. Надеюсь, что к добру, но сами видите, сколько человеческих "приливов" поднимают умело вброшенные туда эмоции. При этом рациональные люди частенько не могут договориться о простейших общих понятиях и поэтому действуют разрозненно. Признаваемая ими всеми база данных "верных" утверждений, этакое credo, может стать центром координации и распознавания "своих".
Массовое прислушивание к голосу системы, если она таки начнёт давать правильные предсказания будущего. Вот тут и потребуется распределённость и невыключаемость. Чтобы ни подавить, ни присвоить нельзя было.
Ссылки
[10] Edward Bernays. Propaganda. Routledge, 1928.
[20] Ensemble learning and Stacking specifically on Wikipedia
[30] Весьма смешные диалоги человека с одним из сильнейших чатботов на планете
[40] Внезапный диван леопардовой расцветки (Хабр)
[50] Expectation-maximization algorithm в Википедии
[60] Скачать pdf статьи, на всякий случай, можно здесь.
Комментарии (42)

vorrutyer
08.03.2022 11:58+5Следующий ход за ту сторону - создание ложных сообщений, способных обходить Ваш семантический фильтр. Сразу вспоминается "растягивание купола" в Криптономиконе Стивенсона.

eugeneb0 Автор
08.03.2022 12:02+1Ну, понятно, борьба щита и меча будет вечной. Однако кажется же, что равновесие в ней сейчас здорово смещено в одну сторону.

olekhy
08.03.2022 12:09Не понимая сути ни одного закона природы, создать великий "Интеграл" хотим.
Светофор как прародитель "глобального предсказателя" и ведь зачастую работает

gans2
08.03.2022 13:34Историки для тех времен пользуются периодизацией, принятой в хрониках монастыря Бан Тоголо в Каракоруме. Уединившиеся там летописцы беспристрастно регистрировали мировые события ЭРМ, пользуясь двухполосной системой сопоставления противоречивых радиосообщений. Удаленность буддийского монастыря — причина, почему там сохранились летописи, — в те времена множество исторических документов в других странах погибло. В Бан Тоголо уцелела самая полная хронология, и мы пользуемся ее календарем.
— Великое сражение Запада и Востока, или битва Мары, было тоже в семнадцатом круге? — спросила Чеди.
— В год красной, или огненной, курицы семнадцатого круга, — подтвердила Фай Родис, — и продолжалось до года красного тигра.


andreyverbin
08.03.2022 15:32-1Не проще ли рейтинг добросовестности давать источникам информации? Те кто врут, врут всегда и по разному. Те кто говорит правду говорят одновременно одно и то же.

Ritan
08.03.2022 18:40+3Те кто говорит правду говорят одновременно одно и то же
Вчера и сегодня говорят правду, завтра заблуждаются, послезавтра - заблуждаются по "убедительной просьбе"
Dukat
08.03.2022 15:59-1Я как раз сейчас размышляю на тему платформы для нового цифрового мира, в основе которой - надёжным способ верификации информации и доверие, исходящее из архитектуры этой системы (прозрачность, СПО, блокчейн...).
Но вот предсказание будущего вызывает у меня сомнения. Хаос же. Прогнозы некоторого рода могут сбываться и создавать впечатление, что "всё работает", но в любой момент может произойти наименее вероятное событие...
А вообще, я бы поддержал идею передачи полномочий по управлению человечеством в руки "ИИ")
PS: напомнило фильм "Особое мнение" и аниме "Neon Genesis Evangelion" с их MAGI.
eugeneb0 Автор
08.03.2022 19:07+1Не думаю, что предсказание будущего вызовет хаос. Синоптики же, вон, предсказывают погоду, и ничего. Мы все, в той или иной степени, занимаемся предсказанием. Ну, повысятся точность и горизонт, вот и всё.
Главное же не предсказывать будущее, а верифицировать этим способом настоящее.
Dukat
09.03.2022 11:41Я имел в виду не вызов хаоса предсказанием, а саму идею предсказывать развите хаоса. Да, есть примеры успешных предсказаний. Но они всё-таки узкоспециализованы, т.е. работают со сравнительно малым количеством "переменных".
Понимаю, что предсказания - не цель проекта, а только инструмент, но с большой вероятностью они затмят первоначальную идею верификации настоящего. Таковы уж люди...
Кстати, думаю, предсказания сами будут влиять на будущее через тех акторов, которые ознакомятся с предсказанием. Хаос от этого не возникнет (он и так уже есть), но это уже совсем другая история)

sumej
08.03.2022 16:45Информация сейчас будет закрыта и однобокая. Факты - искажены. Вот-вот интернет и персональный компьютер будет у немногих россиян, как в 90-х. А может и не будет вовсе - только одна методичка и ящик.
Тех кто думает - расстрел, тюрьма или эмиграция.
Тех кто не думает - им хлеб и зрелищ, ну и что бы не они умирали на чужбине.

victor_1212
08.03.2022 17:21+4Ув. Евгений, мысли интересные, но (imho) слегка сырые, хотелось бы дать позитивный совет (типа куда плыть), советую перечитать/продумать "Трактат... " Витгенштейна, конечно если еще не знакомы, может помочь, переводы доступны


bak
08.03.2022 21:02+3Методы ведения инфо-войн не менялись со времён геббельса.
Правду особо никто не пытается скрыть - это не нужно. "Чем сильнее ложь - тем охотнее в неё верят", "Ложь, повторенная тысячу раз, становится правдой." и прочие. Главное чтоб большинство (которое вообще ничего проверять не будет) кушало и одобряло.
Ну и самые сильные психо-воздействия это "свой-чужой", "внешний враг", "бей или беги" и прочие. Эксплуатация стандартных когнитивных искажений нашего вида.
eugeneb0 Автор
08.03.2022 21:59+1Мне кажется, геббельсовский уровень лжи на неподготовленной почве не прорастёт. Люди просто выпучат глаза и покрутят пальцем у виска. А вот если их подготовить, начав с умеренных искажений.... Которые как раз и можно поймать.
kataus
10.03.2022 08:35Если в лоб заявить, что Мистер Х ест младенцев на ужин - то и правда воспримут как чушь... Но если загодя готовить "факты", вкидывать информацию, понемногу приводить к этой мысли - то вполне поверят и пойдут его свергать/будут ещё больше бояться. Дальнейшее развитие событий по усмотрению заказчика

AlexanderplUs
08.03.2022 21:06+1Как минимум две явных проблемы вижу в описанном подходе:
GIGO (garbage in, garbage out). Сейчас при распространении информации делается упор на массовость и количество повторений, отсюда создается много шума и производных данных, вплоть до полного искажения. Плюс большое количество фейков, не основанных вообще ни на чем. Отсеять мусор от фактов - крайне сложная отдельная задача.
Наличие человека в качестве интерпретатора при попадании данных в систему - сразу слабое место. Достоверность суждений человека по определенным фактам в прошлом совершенно не гарантирует достоверность его суждений в будущем.
eugeneb0 Автор
08.03.2022 21:29Я думаю, не всё так плохо. Нам же не надо, чтобы информация или суждения человека были истинными. Нам достаточно, чтобы они в среднем не являлись случайным шумом, вот и всё. Явная ложь войдёт в решение, грубо говоря, со знаком минус. Явные искажения в человеческом суждении можно, условно, "поделить на три и сдвинуть".
[Я как-то попросил своих друзей не-химиков оценить температуры кипения пары десятков веществ, про многие из которых они и не слышали раньше. Индивидуальные оценки были жутко искажены. Собранные в кучу с помощью ML, оказались не так уж и плохи]
Единственное, когда это не будет работать -- это если входящая информация является случайным шумом (тот самый garbage). Но если работает целенаправленная пропаганда с определённой целью, она не может себе позволить совершенно случайно шуметь. Она вынуждена в какой-то степени быть преобразованной формой истины.
AlexanderplUs
08.03.2022 23:49«явная ложь», «явные искажения» - увы, это внешние и вполне субъективные оценки.
В примере с химиками, они были нейтральны относительно вашего вопроса. Если бы значительная часть ставила своей целью вашу дезинформацию - результат был бы совсем иным.
Пропаганда может искажать истину сколь угодно сильно и даже вовсе её не содержать. В «1984» это очень хорошо проиллюстрировано.
eugeneb0 Автор
09.03.2022 07:26«явная ложь», «явные искажения» - увы, это внешние и вполне субъективные оценки.
Нет. Не знаю, насколько Вы знакомы с тем, как работает Machine Learning, но для него они вполне объективны, и выражаются в несогласии предсказанной метки с заданным значением. В каковом случае ML будет продолжать искать увязывающую закономерность. Не найдёт он её либо если не хватит памяти (маловероятно -- людская меньше), или если зависимость полностью случайна (маловероятно -- люди очень плохие генераторы случайных чисел).
А 1984 я как бы знаком. Не забываем, что это фантастика. И фантастика слабая, полная сама себе противоречий. В мире, где не могут сделать лезвия, камеры тоже будут работать через раз.

janatem
08.03.2022 23:25+1Я верю в "частичные идеи". Бывает, человек крутит в голове половину
чего-то важного. А у кого-то есть вторая половина. Чтобы мысли
встретились и "клацнули", кто-то должен свою половину опубликовать.Не могу сказать, что у меня есть вторая недостающая половина, но тем не менее какой-то вроде бы подходящий кусочек пазла могу предложить. На самом деле это тема отдельной статьи или даже серии статей, но я попробую вкраце изложить ту часть, которая особенно резонирует с вашей идеей.
Иногда полезно обобщить и, казалось бы, усложнить задачу (пример: изучать электромагнетизм гораздо продуктивней, чем электричество и магнетизм по отдельности). В этой статье ставится задача поиска истинности утверждений. Я сейчас сформулирую свою задачу, а потом посмотрим, как связаны эти задачи между собой, не является ли одна обобщением другой, и имеет ли смысл решать их совместно. Я хочу построить бесцензурную сеть, в которой, грубо говоря, писатель пишет, что хочет, а читатель читает, что хочет. Задача состоит в том, чтобы показать читателю в огромном море информации именно то, что он хочет, и не показывать то, чего он не хочет. В каком-то смысле поисковики и социальные сети с модерацией отчасти решают эту задачу, но я хочу отдать всю власть по фильтрации бездны в руки читателя. Как это сделать? Мой ответ состоит в создании экосистемы фильтров (очевидно, децентрализованной по построению), где будут представлены разнообразные способы построения фильтров, в том числе те, которыей сейчас и нельзя помыслить. Есть несколько очевидных способов создания фильтров: примитивые (по ключевым словам, например), хитрые (с каким-то машинным обучением), основанные на сети доверия, и т.д., но главное — их можно соединять путем композиции. Это очень богатая тема, но я сейчас не буду останавливаться на том, как именно фильтры создаются. Важно, что читатель сам выбирает фильтры, которые будет применять — «вся власть читателю!» Забегая вперед, скажу, что должно получиться что-то близкое к тому, что описано в этой статье в разделе «C. Предсказывающая соцсеть».
Теперь возвращаемся к тому, как связаны эти две задачи: определение истинности (чтобы это ни значило) и индивидуальная фильтрация. Среди всего зоопарка фильтров могут и должны существовать такие, которые стараются отделить истинные высказывания от всех остальных. То есть в каком-то смысле фильтрация — более общая задача. Пока у меня есть только несколько сырых идей, на каких принципах строить полезные фильтры, но даже их описание не поместится на полях этой рукописи…
eugeneb0 Автор
09.03.2022 05:51Это, безусловно, близко связанные задачи. Но я не уверен, что задача о фильтрах проще задачи проверки на истинность. Хотя с точки зрения "продажи" её пользователю вполне может быть и проще.
Тут надо ещё думать.
janatem
09.03.2022 15:16В самом общем виде, задача о фильтрах, конечно, сложнее. Но если хотя бы научиться отфильтровывать шум, спам, сообщения, не являющиеся утверждениями, то с оставшимся материалом будет проще работать. Один из моих тезисов состоит в том, что мы пока не знаем, какие фильтры будут полезны и эффективны, поэтому нужно создать биом, где они будут эволюционно конкурентно развиваться.
Еще с помощью фильтров можно искать не только «истинное», но и «красивое».

olegkrutov
09.03.2022 09:04Тогда получится усилитель имеющейся у читателя уже в голове картинки мира, а не средство приведения этой картинки к объективному состоянию. Читатель просто отфильтрует то, что не вписывается в его точки зрения, и все.
janatem
09.03.2022 15:07Такой риск есть, но всё в руках читателя. Сейчас, напомню, этим занимаются модераторы (люди и роботы) соцсетей, и они по факту формируют отдельные информационные пузыри. Поиск объективной истины — это задача, которую читатель может взять на себя добровольно, и нужно, я считаю, «всего лишь» помочь ему, дав подходящие инструменты.

yurixi
09.03.2022 01:43+2То что делается кем-либо продуцируется всегда исходя из цели. Если вы хотите сделать «мощное понимание», то самое странное, что может быть — это высказываться в стиле «цели и так понятны, пора заняться технической стороной». Потому что этим допускается незнание своих целей. В других вопросах это не критично, но здесь — получится мы очень хотим, но неизвестно чего. Тогда неизвестно что и получится. Цель главенствует над техникой, идеология над страной, вера над человеком.
victor_1212
09.03.2022 02:02> хотите сделать «мощное понимание» ....
для этого вероятно потребуется формальная проверка истинности, т.е. формализм, язык для философского анализа, см. "Витгенштейн, философия познания в аналитической традиции", см. например
yurixi
09.03.2022 02:25+2Проблемы «проверки истинности» являются смешением проблем выяснения принадлежности к области, которая определяется как истинная, и проблем цели, потому что и сама это область определяется исходя из целей. То есть, при разных целях сама понимаемая истинность различается.
А вера в какую-то «общую истину» имеет все негативные последствия религии.fabius
09.03.2022 06:27+1Поддерживаю. Само по себе составление прогнозов, без цели использования этой информации - бессмысленно. Цель всегда вначале любого осмысленного процесса. Человек, например, не всегда осознаёт свою цель, тогда неявными целями выступают задачи, определяемые эволюцией. Но перед машиной ставить цель необходимо, только критерий успешности выполнения задачи позволяет эффективно обучить нейронную сеть.
victor_1212
09.03.2022 17:04-1> принадлежности к области, которая определяется как истинная, и проблем цели
нет, речь не об «общей истине» или абсолюте, скорее об истинности в смысле логики, или мат. логики, конечно к религии никакого отношения,
Ваш ответ предполагает существование областей, выяснения принадлежности к ним и пр., что характерно например для распознавания образов, аналитический метод Витгенштейна исходит из другой модели, не берусь здесь излагать по понятным причинам, если интересно посмотрите источники,
сильно огрубляя, Ваш подход напоминает типа определение корректности программы путем проверки принадлежности данного кода области истинных синтаксически корректных программ, а аналитический метод несколько напоминает работу компилятора, аналогия конечно грубая просто показать, что подход связанный с областями и пр. в данном случае не слишком полезный, кроме общих слов двигаться особенно не получается, в теории распознавания образов обычно ситуация другая, пространство признаков и пр устроено проще
ps
сам метод Витгенштейна пришел с другого конца, а именно как отличить утверждения для которых возможно в принципе установление истинности (неважно как, например с использованием нейронных сетей), от тех где нет, снова огрубляя конечно

eimrine
09.03.2022 06:55Вы уверенны что хотите именно цифровой вытрезвитель, а не что-то похожее?
Создайте такую платформу, но только для кода, это решит проблему хранения данных в блокчейне (одно минутное видео может занимать больше байт чем совокупный труд всех программистов за день). Из идеи prediction market возьмите запрет на бесплатную запись в БД, чтобы не потонуть во флуде. Правда, тех кто оказался не флудером, придётся как-нибудь наградить, иначе они не будут записывать в вашу БД. Догадайтесь, какой ЯП решит проблему того чтобы написать один раз а использовать на любых устройствах. даже через 100 лет. Ну и последнее но не наименьшее по важности — если делать платформу для кода, а не для злободневных новостей, — то нужно принять решение для чего этот код нужен.
PS Мне очень интересная тема рынков предсказаний, если у вас есть ссылка наКстати, немало вполне успешных prediction markets было закрыто в США в 2003-2015-х годах.
то это поможет для моей частичной идеи, которая весьма похожа на вашу. У меня, в моей частичной идее, код который я предлагаю вам вместо мультимедиа-контента, нужен для системы которая пишет саму себяad nauseamдо достижения стадии сильного ИИ.

bipiem
10.03.2022 12:04Цифровой спор
Замахнулись на сложное, но видимо можно начать с более простых вещей.
Назовём это «Цифровой спор». Есть событие, например, та же «Z операция». Далее есть возможность не «длинного» обсуждения, а категоризации и построения гипотез возникновения события (целей и т.п.), другие ветки обсуждения. Категоризация, гипотезы и т.п. – имеют название, а их суть - ограничена абзацем (т.е. короткие смысловые пояснения).
Обычно мнения делятся на два больших и противодействующих лагеря. Пользователь может проголосовать или добавить свою гипотезу\ категорию. В итоге получаем два конкурирующих стакана мнений (голоса поднимают гипотезу вверх стакана). Для каждой гипотезы ведется свой стакан ссылок, подтверждающих гипотезу. Вообще, это более сложный набор «стаканов», т.к. есть еще возможность вести стакан опровержений по конкурирующей гипотезе. Суть, что это лишь кратко «изложенное» в комплекте с ссылками и ранжированием мнений.
Имеется расширенный фильтр, включая уникальность IP (или авторизованный вход голосователя через соцсеть), локацию и т.п. Это - если кратко.
В целом – это опросник с развитием в направлении Wiki \ Zettelkasten. Может что-то подобное уже есть?
Существуют и другие - более простые направления (без всякого ML), которые можно отнести к «технологиям поиска правды». Например, я не встречал нормального бесплатного сервиса или ПО (простого в установке) для группового (публичного) аннотирования статей (pdf, html). Которые видел (бесплатные) - имеют слишком слабый функционал. Например, лучший бесплатный сервис, который встретил (у многих других - ограничение на объем файла):
olekhy
Крик души. Давайте усложним сложное и создадим электро-техно-"Дух".
Думаю что всю свою жизнь учусь думать что-бы выживать, а выживаю только за счёт интуиции.
1A1A1
Интуиция это неформализованный опыт. Люди разным образом воспринимают и хранят информацию.
olekhy
Я сказал тоже самое в меру моего понимания или интуиции.
Я надеюсь я правильно понял смысл статьи: как создать технолоическую интуицию для всех? Как оценить стоимость "создания" в смысле кто и сколько заплатит.