

В настоящее время тема Process Mining продолжает набирать популярность, и все больше применяется при поиске новых путей повышения эффективности бизнес-процессов, в оперативном анализе пилотных проектов и конечно же в задачах аудита. При выборе инструмента для разработки в рамках данной задачи важнейшими критериями становятся доступность, производительность, наличие сообщества.
В этой статье мы рассмотрим bupaR – open-source пакет для анализа бизнес-процессов на языке R. В качестве IDE использовалась RStudio.
Допустим, у нас уже есть файл (csv) журнала (лога) событий активностей пользователей в интернет-магазине. Воспользуемся пакетом readr для загрузки лога событий из данного файла и методом activities_to_eventlog из bupaR для преобразования:
library(readr)
library(bupaR)
df <- readr::read_csv('./gift4iaia_log_file.csv',locale=locale(encoding = 'cp1251'))
events <- bupaR::activities_to_eventlog(
df,
case_id = 'UserID',
activity_id = 'Activity',
resource_id = 'User_name',
timestamps = c('StartTime', 'CompleteTime')
)Теперь выведем сопоставление между идентификаторами событий и полями данных лога.
mapping(events)
Case identifier: UserID
Activity identifier: Activity
Resource identifier: User_name
Activity instance identifier: activity_instance_id
Timestamp: timestamp
Lifecycle transition: lifecycle_id Выведем количество действий из лога событий.
n_activities(events)
[1] 4Посмотрим сводные данные (метод summary):
events %>%
summary
Number of events: 26
Number of cases: 4
Number of traces: 3
Number of distinct activities: 4
Average trace length: 6.5
Start eventlog: 2021-12-01 19:52:01
End eventlog: 2021-12-03 20:48:51
UserID Activity User_name
Length:26 Авторизация :8 Виннипух:8
Class :character Оплата товара :4 Кролик :4
Mode :character Оформление заказа :6 Пятачок :6
Поиск товаров в каталоге:8 Сова :8
activity_instance_id lifecycle_id timestamp .order
Length:26 CompleteTime:13 Min. :2021-12-01 19:52:01 Min. : 1.00
Class :character StartTime :13 1st Qu.:2021-12-01 20:34:53 1st Qu.: 7.25
Mode :character Median :2021-12-01 21:16:51 Median :13.50
Mean :2021-12-02 09:53:00 Mean :13.50
3rd Qu.:2021-12-02 21:51:53 3rd Qu.:19.75
Max. :2021-12-03 20:48:51 Max. :26.00 Построим диаграмму частот действий на основе лога событий. Для этого воспользуемся функцией activity_frequency с параметром "activity", которая формирует свод по каждой активности (количество/частота) и на основе данного свода генерируем саму диаграмму (метод plot()).
library(ggplot2)
events %>%
activity_frequency(level = "activity") %>%
plot() 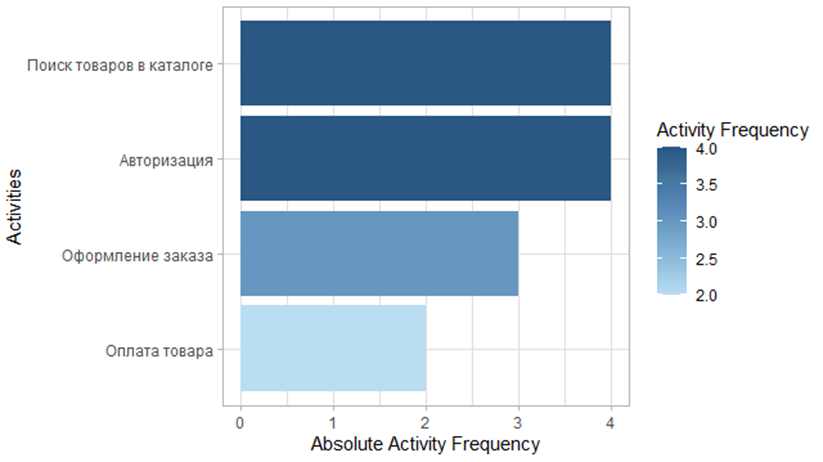
Теперь построим карту процесса. Для этого нам понадобится метод process_map. В данном примере в качестве значения type используется функция frequency с параметром "relative_case" для отображения частоты в процентах (по умолчанию без задания параметров для process_map будут отображаться абсолютные величины)
events %>%
process_map(type = frequency("relative_case")) 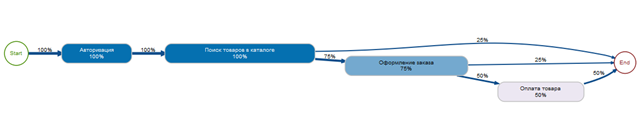
По полученному графу видим, что 75% поиска товаров в каталоге завершилось оформлением заказа и 50% - оплатой товара.
Построим карту процесса в плане производительности. Здесь используем в process_map функцию performance, определяемую двумя аргументами — это статистическая функция, применимая ко времени обработки (среднее — mean, медиана — median и т.д.), а так же единица времени (дни - "days", часы -"hours" , минуты -"mins" и т.д.).
events %>%
process_map(performance(mean, "mins"))
В данном случае мы можем оценить этапы процесса по длительности. Например, этап поиска товаров занимает в среднем 22.82 минуты, а оформление 18.48 минут.
Теперь воспользуемся функцией фильтра filter_trim, которая обрезает для анализа лог событий, таким образом, что последовательность действий начинается с активности (активностей) start_activities и заканчивается активностью (активностями) end_activities. Построим карту процесса для последовательностей действий начинающихся с поиска товаров в каталоге и завершающихся оплатой товара.
events %>%
filter_trim(start_activities = "Поиск товаров в каталоге", end_activities="Оплата товара")%>%
process_map(performance(mean, "mins"))

Из полученного графа видим, что для покупателей, завершивших этап оплаты товара среднее время поиска товаров в каталоге существенно выше, чем для всех пользователей.
Так же в построении карты процесса существует возможность комбинировать вышеперечисленные подходы. Для этого в функции process_map необходимо задать параметры типов узлов и ребер графа процесса (type_nodes, type_edges).
events %>%
process_map(type_nodes=performance(mean, "mins"), type_edges = frequency("relative_case"))
BupaR даёт возможность рассмотреть бизнес-процесс под самыми разными углами. В сочетании с простотой освоения, кастомизацией (в частности, в построении карты процесса), широким набором полезных функций, и, конечно, огромными возможностями языка R, ориентированного на анализ данных и работу со статистикой, использование данного пакета видится отличным решением в проекте по анализу бизнес-процессов.