

YDB решает задачи в одной из самых критичных областей — позволяет создавать интерактивные приложения, которые можно быстро масштабировать по нагрузке и по объёму данных. Мы разрабатывали её, исходя из ключевых требований к сервисам Яндекса. Во-первых, это катастрофоустойчивость, то есть возможность продолжить работу без деградации при отключении одного из дата-центров. Во-вторых, это масштабируемость на десятки тысяч серверов на чтение и на запись. В-третьих, это строгая консистентность данных.
В посте я расскажу об истории развития технологий баз данных, о том, зачем использовать YDB, как её применяют текущие пользователи и какие плюсы для всех несёт выход в опенсорс. А во второй половине поста поговорим о разных вариантах развёртывания.
В нашей компании YDB используется уже больше пяти лет. На мультитенантных кластерах развёрнуты базы с очень разными нагрузками и паттернами доступа к данным. На практике мы встречаемся с многократным ростом баз данных, ростом объёмов данных с единиц гигабайт до сотен терабайт и ростом нагрузок с тысяч до миллионов RPS. При этом решение задач масштабируемости и отказоустойчивости автоматически осуществляет база, снимая их с разработчиков прикладного кода. Но YDB распространена не только в проектах с высокой нагрузкой. Команды разработки Яндекса сами определяют свой стек в зависимости от задач, аудитории и другой специфики, и многие выбирают YDB за отказоустойчивость, даже если текущие нагрузки невелики. Одна из причин в том, что в случае внезапного роста нагрузок разработчикам будет достаточно добавить ресурсы, не внося изменения в код приложения и не прикладывая усилия к ручному перешардированию базы. Проекты в YDB размещают команды Алисы, Такси, Метрики и других сервисов — сейчас в системе почти 500 проектов.
Широкое распространение YDB внутри Яндекса, популярность в качестве сервиса Яндекс Облака и запросы пользователей cтали для нас хорошим стимулом раскрыть исходный код и сделать базу доступной для свободного использования.
Немного истории
За два последних десятилетия непрерывно растёт использование интернета, в последние годы он начал прочно входить в бытовую сферу. Часы, очки, лампочки, пылесосы — практически все устройства подключены к интернету или подключатся в скором времени. Всё это ведёт к непрерывному росту объёмов хранимых данных и нагрузок, которые БД обрабатывают.
С начала 2000-х вместе с бурным ростом интернета выросла популярность опенсорсных СУБД для OLTP-нагрузок — например, MySQL и PostgreSQL.
Без них или их аналогов сложно представить себе нынешние темпы развития интернета. Даже небольшие стартапы получили возможность работать с возрастающими нагрузками на бесплатных БД. Конечно, существовали тяжёлые коммерческие решения, которые позволяли масштабироваться вертикально, но они были доступны только большим компаниям с соответствующими бюджетами.
К середине 2000-х стали популярны разные виды логического шардирования БД — когда базу шардируют на несколько узлов, исходя из бизнес-логики приложения и его сущностей. Промежуточный слой между приложением и базой или само приложение принимает решение, на каком из узлов БД находятся данные. Но этот распространённый подход приводит к усложнению логики пользовательского приложения и значительно усложняет поддержку множества кластеров. Дополнительные сложности возникают при необходимости выполнить запрос, результат которого выдаёт консистентный результат объединения данных из разных шардов. Эту проблему можно решить за счёт отгрузки данных в отдельную систему или дополнительного усложнения логики приложения, но каждый такой дополнительный шаг только усложняет обслуживаемость системы и делает её менее технологичной. В то же время остаются открытыми такие вопросы, как перешардирование данных при росте нагрузки на конкретный шард. Сложно развить изначально выбранный подход к шардированию при изменившихся бизнес-требованиях к приложению. Нагрузки продолжают расти, а критичность отказов возрастает.
В конце 2000-х набирают популярность NoSQL-решения. Во главе угла становятся проблемы масштабируемости и отказоустойчивовости, в жертву приносится диалект SQL и функциональность join. Приемлемой считается eventual consistency, то есть консистентность в конечном итоге: рано или поздно все реплики во всех зонах доступности или регионах получат консистентный набор данных. Растёт популярность key-value-хранилищ (Redis, AWS DynamoDB), column-family (Cassandra, Hbase) и документных БД (MongoDB, Couchbase).
Мы шли тем же путем, и история развития OLTP СУБД в Яндексе повторяет историю развития операционных БД. Предшественником YDB была СУБД NoSQL (KV), которую мы разрабатывали с 2008 года.
Отсутствие поддержки ACID-транзакций приводит к необходимости самостоятельно их эмулировать. Возрастает сложность прикладного кода, и каждый разработчик фактически вынужден дорабатывать на стороне этого кода функциональность базы — что, во-первых очень сложно, а во-вторых, на большом количестве проектов требует множества костылей и велосипедов в каждом проекте.
Проблема оставалась актуальной. В начале 2010-х появляется новый термин — NewSQL. Про него рассказывают Майкл Стоунбрейкер и Энди Павло, описывая новые требования к OLTP СУБД (точнее, ожидания от такой базы).
NewSQL-базы должны обладать масштабируемостью и отказоустойчивовостью, свойственной NoSQL-системам, но при этом предоставлять ACID-гарантии транзакций и SQL-диалект. Чуть позже термин NewSQL трансформировался — масштабируемые, отказоустойчивые БД с поддержкой SQL и строгой консистентностью стали называть Distributed SQL Databases. Вдохновившись идеей NewSQL, в 2012 году мы сделали первый коммит в YDB.
Зачем использовать YDB
Рынок СУБД развивается давно, на нём представлено много известных и зрелых продуктов. Давайте разберём, какие преимущества может дать YDB в сравнении с другими базами.
Традиционные (нераспределённые) реляционные СУБД
Один из вариантов масштабирования в реляционных базах — ручное шардирование. То есть при разворачивании нужно настроить несколько экземпляров базы и решить, к какому экземпляру обращаться в вашем приложении. Если вам нужен одновременный доступ к данным из нескольких экземпляров БД, вам придется самостоятельно заниматься организацией распределённых транзакций. YDB масштабируется на чтение и запись «из коробки», для этого достаточно добавить больше оборудования в кластер. На практике мы работаем с базами размером в сотни терабайт под нагрузкой в миллионы RPS.
NoSQL-базы
NoSQL-базы очень хорошо масштабируются, но их функциональность ограничена по сравнению с реляционными БД. Например, транзакционное обновление нескольких таблиц с высокой скоростью при помощи SQL-запросов — реальная проблема для NoSQL.
Опенсорсные базы Distributed SQL
Некоторые из таких систем имеют очень похожие возможности по сравнению с YDB. У YDB, на наш взгляд, следующие плюсы:
- Яндекс как пользователь даёт YDB возможность на практике доказывать все свои свойства — поверх СУБД работает множество сервисов с высокими нагрузками и большими объёмами данных.
- Поверх YDB как платформы мы реализовали системы хранения и обработки данных: хранилище временных рядов, на базе которого построены мониторинги в Яндексе; персистентные очереди, на которых построена шина передачи данных Logbroker; Network Block Store — виртуальные диски для Yandex Cloud.
- YDB может стать экосистемой управления данными, поскольку она даёт возможность использовать механизм федеративных запросов и механизм потоковых запросов на базе YQL.
Проприетарные базы Distributed SQL
Код большинства систем ведущих мировых облачных провайдеров закрыт. Некоторые из этих систем также завязаны на специализированное оборудование. Это лишает клиентов возможности локального развертывания системы и разворачивания в различных облаках. YDB, в свою очередь, работает на стандартном железе, её можно развернуть везде с помощью оператора Kubernetes или вручную.
Опыт наших пользователей
Yandex Cloud
YDB — ключевой компонент Yandex Cloud. Напомню, что вся облачная платформа построена на гиперконвергентной архитектуре. Это означает, что на одном и том же оборудовании работает слой storage и слой compute, они отделены и независимы друг от друга. На том же оборудовании работает и control plane. YDB обеспечивает уровень хранения данных в Yandex Cloud. Это и слой хранения данных для сетевых дисков, и слой хранения данных и метаданных инфраструктурных и платформенных сервисов. Также есть сервисы, которые сами предоставляют средства для работы с данными и реализованы поверх YDB: Monitoring — сервис для сбора и визуализации метрик приложений; Message Queue — очереди для обмена сообщениями между приложениями; Data Streams — масштабируемый сервис для управления потоками данных в реалтайме; Cloud Logging — предназначен для агрегации и чтения логов.
Алиса
Команда Алисы решила переехать на YDB, когда готовилась к существенному росту нагрузки и объёмов данных. До переезда использовали другую базу и замечали нежелательные эффекты при переключении мастера между дата-центрами. После длительных регламентных работ отставшие на много часов реплики приходилось бережно возвращать в строй, тратить на них ресурсы девопс-команды. Переехав, команда смогла отказаться от ручного шардирования, получить из коробки строгую консистентность в кластере на три дата-центра и снизить девопс-нагрузку. Сейчас Алиса использует YDB в разных сценариях. Например, хранит в базе контекст для поддержания естественного диалога с пользователем, необходимую информацию для привязки активационных фраз устройств умного дома к их идентификаторам и расположению в доме. Оперативные логи инфраструктурной платформы разработчиков тоже хранятся в YDB.
Авто.ру
У Авто.ру микросервисная архитектура. Коллеги пришли в YDB, когда столкнулись с тем, что существующие бэкенды базы для трейсов Jaeger стали очень дорогостоящими с точки зрения обработки количества трейсов на ядро сервера. Для команды YDB это был вызов, и мы реализовали специальный API (BulkUpsert) для записи логов и трейсов и оптимизировали базу для трейсов. Производительность YDB позволила в три раза сэкономить вычислительные ресурсы и писать все трейсы без сэмплинга (нагрузка трейсами на YDB сейчас составляет 500 000 спанов в секунду). Когда YDB зарекомендовала себя как экономичная, эффективная, отказоустойчивая база для хранения трейсов в Авто.ру и Яндекс Недвижимости, её также начали использовать как реляционную базу.
Метрика
В Метрике анализируются визиты пользователей на сайты. Для этого необходимо хранить историю всех событий и «склеивать» их на лету. Раньше использовалась конвейерная распределённая система — со своим самописным локальным хранилищем и своей логикой репликации и шардирования. По мере роста нагрузки команда Метрики споткнулась о производительность шардов самописного хранилища, а продолжать наращивать количество шардов без принципиального изменения архитектуры было крайне болезненно.
Новым хранилищем визитов (после экспериментов и нагрузочного тестирования) стала YDB: база обеспечивает прозрачную масштабируемость по месту и по нагрузке. Это позволило продолжить наращивать трафик — сейчас база визитов содержит больше 100 терабайт данных и при этом держит нагрузку больше миллиона RPS. Подробнее про этот проект можно будет узнать из доклада Александра Прудаева на ближайшем HighLoad++.
Почему мы пошли в опенсорс
Мы уверены, что бурное развитие технологий, которое мы наблюдаем в последние десятилетия, было бы невозможно без культуры опенсорс. Например, сейчас уже нельзя представить себе интернет без таких БД, как MySQL, PostgreSQL и ClickHouse, веб-серверов Apache и nginx — примеров можно привести множество.
Открытие проекта создаёт интереснейшую для всех win-win-ситуацию. У сообщества, с одной стороны, появляется возможность пользоваться уникальными наработками, в которые Яндекс инвестировал сотни человеко-лет, познакомиться с кодом, свободно запускать и разрабатывать у себя решения на базе YDB. Технологии, позволяющие Яндексу развиваться быстрее, оперативно реагировать на рост нагрузок и масштабироваться, теперь доступны каждому. С другой стороны, сильно увеличится вариативность пользователей, мы сможем получить обратную связь от мирового сообщества и сделать базу ещё лучше. Важно сломать барьер для пользователей, которые заинтересованы в технологии, но останавливаются, опасаясь закрытости и/или невозможности использовать её на своем оборудовании или в своих облаках.
Как попробовать YDB
Давайте попробуем самый простой вариант, который можно использовать для локального тестирования или отладки — Docker-контейнер.
Работа с Docker-образом YDB
По умолчанию в Docker-образе запускается база данных с именем
/local и используются следующие порты:- Для взаимодействия с YDB API по gRPC без TLS — 2136.
- Для взаимодействия с YDB API по gRPC с поддержкой TLS — 2135. Сертификаты генерируются автоматически. Для использования сертификатов необходимо смонтировать на хост-системе директорию /ydb_cert Docker-контейнера.
- Встроенные средства мониторинга и интроспекции — 8765.
Загрузите актуальную версию Docker-образа:
docker pull cr.yandex/yc/yandex-docker-local-ydb:latestDocker-контейнер YDB хранит данные в файловой системе контейнера, разделы которой отражаются на директории в хост-системе. Приведенная ниже команда запуска контейнера создаст файлы в текущей директории, поэтому перед запуском создайте рабочую директорию, и выполняйте запуск из неё.
Запустите YDB Docker-контейнер со следующими параметрами:
docker run -d \
--rm \
--name ydb-local \
-h localhost \
-p 2135:2135 \
-p 8765:8765 \
-p 2136:2136 \
-v $(pwd)/ydb_certs:/ydb_certs -v $(pwd)/ydb_data:/ydb_data \
-e YDB_DEFAULT_LOG_LEVEL=NOTICE \
-e GRPC_TLS_PORT=2135 \
-e GRPC_PORT=2136 \
-e MON_PORT=8765 \
cr.yandex/yc/yandex-docker-local-ydb:latestПараметры запуска:
- -d — запустить Docker-контейнер в фоновом режиме.
- --rm — удалить контейнер после завершения его работы.
- --name — имя контейнера.
- -h — имя хоста контейнера.
- -p — опубликовать порты контейнера на хост-системе.
- -v — монтировать директории хост-системы в контейнер.
- -e — задать переменные окружения.
С описанием дополнительных параметров запуска Docker-образа YDB можно ознакомиться в документации.
Консольный клиент YDB CLI
Для выполнения запросов и запуска тестовой нагрузки мы будем использовать консольный клиент YDB.
Установите YDB CLI по инструкции. Для проверки успешности соединения с базой данных выполните запрос к базе в Docker-контейнере:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local table query execute -q 'select 1;'Параметры запуска:
- -e — эндпоинт базы данных.
- --ca-file — путь к TLS-сертификату.
- -d — имя базы данных и параметры запроса.
В результате вы должны увидеть сообщение:
┌─────────┐
| column0 |
├─────────┤
| 1 |
└─────────┘Это значит, что соединение с базой прошло и запрос выполнен успешно.
Использование языка запросов YQL
Ниже — краткая инструкция по использованию синтаксиса YQL. Подробнее с синтаксисом и примерами использования можно познакомиться в документации к YQL.
Создайте таблицу с помощью инструкции CREATE TABLE:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'CREATE TABLE series (series_id Uint64, title Utf8, PRIMARY KEY (series_id));'Убедитесь что таблица создалась, с помощью команды получения списка объектов базы
scheme ls:ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scheme ls
Чтобы посмотреть свойства созданной таблицы, воспользуйтесь командой
describe:ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scheme describe series
Добавьте данные в таблицу с помощью инструкции INSERT INTO:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'INSERT INTO series (series_id, title) VALUES (1, "IT Crowd"), (2, "Silicon Valley"), (3, "Fake Series");'Прочитайте данные из таблицы с помощью инструкции SELECT:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'SELECT * FROM series;'
Обновите данные в таблице с помощью инструкции UPDATE:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'UPDATE series SET title="Fake Series Updated" WHERE series_id = 3;'Удалите данные в таблице с помощью инструкции DELETE:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'DELETE FROM series WHERE series_id = 3;'Удалите таблицу с помощью инструкции DROP TABLE:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local scripting yql -s 'DROP TABLE series;'YDB UI — ограничимся скриншотом
Встроенный YDB UI доступен на порту 8765. Перейдите по ссылке http://localhost:8765, чтобы познакомиться с его возможностями.

Запуск тестовой нагрузки YDB Workload
Для демонстрации работы и нагрузочного тестирования мы интегрировали в функциональность консольного клиента YDB симулятор склада интернет-магазина — создание заказов из нескольких товаров, получение списка заказов по клиенту.
- getCustomerHistory — чтение заданного количества заказов покупателя с id = 10 000. Создаётся нагрузка на чтение одних и тех же строк из разных потоков.
- getRandomCustomerHistory — чтение заданного количества заказов случайно выбранного покупателя. Создаётся нагрузка на чтение из разных потоков.
- insertRandomOrder — создание случайно сгенерированного заказа. Например, клиент создал заказ из двух товаров, но ещё не оплатил его, поэтому остатки товаров не снижаются. В БД записывается информация о заказе и товарах. Создаётся нагрузка на запись и чтение.
- submitRandomOrder — создание и обработка случайно сгенерированного заказа. Например, покупатель создал и оплатил заказ из двух товаров. В БД записывается информация о заказе, товарах, проверяется их наличие и уменьшаются остатки. Создаётся смешанная нагрузка.
- submitSameOrder — создание заказов с одним и тем же набором товаров. Например, все покупатели покупают один и тот же набор (только что вышедший телефон и зарядное устройство). Создаётся нагрузка в виде конкурентного обновления одних и тех же строк в таблице.
Для начала работы нужно проинициализировать базу данных — создать таблицы и заполнить их данными. Для этого нужно выполнить команду:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local workload stock init -p 100 -q 1000 -o 1000Здесь:
- -p — количество видов товаров,
- -q — количество каждого вида товара на складе,
- -o — первоначальное количество заказов в базе.
Будут созданы таблицы со следующей структурой и настройками:
Остатки:
CREATE TABLE `stock`(
product Utf8,
quantity Int64,
PRIMARY KEY(product)
) WITH (
AUTO_PARTITIONING_BY_LOAD = ENABLED,
AUTO_PARTITIONING_MIN_PARTITIONS_COUNT = <min-partitions>
);Заказы:
CREATE TABLE `orders`(
id Uint64,
customer Utf8,
created Datetime,
processed Datetime,
PRIMARY KEY(id),
INDEX ix_cust GLOBAL ON (customer, created)
) WITH (
READ_REPLICAS_SETTINGS = "per_az:1",
AUTO_PARTITIONING_BY_LOAD = ENABLED,
AUTO_PARTITIONING_MIN_PARTITIONS_COUNT = <min-partitions>,
UNIFORM_PARTITIONS = <min-partitions>,
AUTO_PARTITIONING_MAX_PARTITIONS_COUNT = 1000
);Позиции:
CREATE TABLE `orderLines`(
id_order Uint64,
product Utf8,
quantity Int64,
PRIMARY KEY(id_order, product)
) WITH (
AUTO_PARTITIONING_BY_LOAD = ENABLED,
AUTO_PARTITIONING_MIN_PARTITIONS_COUNT = <min-partitions>,
UNIFORM_PARTITIONS = <min-partitions>,
AUTO_PARTITIONING_MAX_PARTITIONS_COUNT = 1000
);Таблица может быть шардирована по диапазонам значений первичного ключа. Разные шарды таблицы могут обслуживаться разными серверами распределённой БД (в том числе расположенными в разных локациях), а также могут независимо друг от друга перемещаться между серверами для перебалансировки или поддержания работоспособности шарда при отказах серверов или сетевого оборудования.
При росте объёма данных, обслуживаемых шардом (как и при росте нагрузки на шард), YDB автоматически разбивает его на два. Разбиение происходит по медианному значению первичного ключа.
Помимо автоматического разделения вы можете создать пустую таблицу с предопределённым количеством шардов. При этом можно вручную задать точные границы разделения ключей по шардам или указать равномерное разделение на предопределённое количество шардов. Тогда границы создадутся по первой компоненте первичного ключа.
Можно определить следующие параметры партиционирования таблицы:
- AUTO_PARTITIONING_BY_SIZE — режим автоматического партиционирования по размеру партиции. Если размер партиции превысил значение, заданное параметром AUTO_PARTITIONING_PARTITION_SIZE_MB, то она встаёт в очередь на разделение (split). Если суммарный размер двух соседних партиций меньше 50% от значения параметра AUTO_PARTITIONING_PARTITION_SIZE_MB, то они встают в очередь на объединение (merge).
- AUTO_PARTITIONING_PARTITION_SIZE_MB — предпочитаемый размер каждой партиции в мегабайтах.
- AUTO_PARTITIONING_BY_LOAD — режим автоматического партиционирования по нагрузке. Если в течение нескольких десятков секунд шард потребляет более 50% CPU, то он ставится в очередь на разделение (split). Если в течение часа суммарная нагрузка на два соседних шарда утилизировала менее 35% CPU, то они ставятся в очередь на объединение (merge). Выполнение операций разделения или объединения само по себе утилизирует CPU — и занимает время. Поэтому при работе с плавающей нагрузкой рекомендуется вместе с включением этого режима устанавливать отличное от 1 значение параметра минимального количество партиций AUTO_PARTITIONING_MIN_PARTITIONS_COUNT. Тогда спады нагрузки не приведут к снижению количества партиций ниже необходимого, и не будет потребности их заново делить при появлении нагрузки.
- AUTO_PARTITIONING_MIN_PARTITIONS_COUNT — объединение партиций (merge) производится, только если их фактическое количество превышает заданное этим параметром значение.
- AUTO_PARTITIONING_MAX_PARTITIONS_COUNT — разделение партиций (split) производится, только если их количество не превышает заданное этим параметром значение.
- UNIFORM_PARTITIONS — количество партиций для равномерного начального разделения таблицы. Первая колонка первичного ключа должна иметь тип Uint64 или Uint32. Созданная таблица сразу будет разделена на указанное количество партиций.
Применение чтения из фолловеров позволяет:
- Обслуживать клиентов, критичных к минимальным задержкам, недостижимым иными способами в мульти-ДЦ-кластере.
- Обслуживать читающие запросы из фолловеров без влияния на модифицирующие запросы, выполняющиеся на шарде.
- Продолжать обслуживание при переездах лидера партиции (как штатной, при балансировке, так и при сбоях).
- В целом повышать предел производительности чтения шарда, если множество читающих запросов попадают на одни и те же ключи. Можно указать необходимость запуска реплик для чтения для каждого шарда таблицы. Обращения к репликам для чтения (то есть к фолловерам) обычно происходят в пределах сети дата-центра, что позволяет обеспечить время ответа в единицы миллисекунд.
- READ_REPLICAS_SETTINGS — PER_AZ означает использование указанного количества реплик в каждой AZ.
Примеры запуска нагрузки
Запуск нагрузки insertRandomOrder на 10 секунд в 10 потоков с 1000 видов товаров:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local workload stock run insertRandomOrder -s 120 -t 10 -p 1000Запуск нагрузки submitRandomOrder на 10 секунд в 5 потоков с 1000 видов товаров в заказе:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local workload stock run submitRandomOrder -s 10 -t 5 -p 1000Запуск нагрузки getRandomCustomerHistory на 5 секунд в 10 потоков:
ydb -e grpcs://localhost:2135 --ca-file $(pwd)/ydb_certs/ca.pem -d /local workload stock run getRandomCustomerHistory -s 5 -t 10Пример результатов нагрузки:
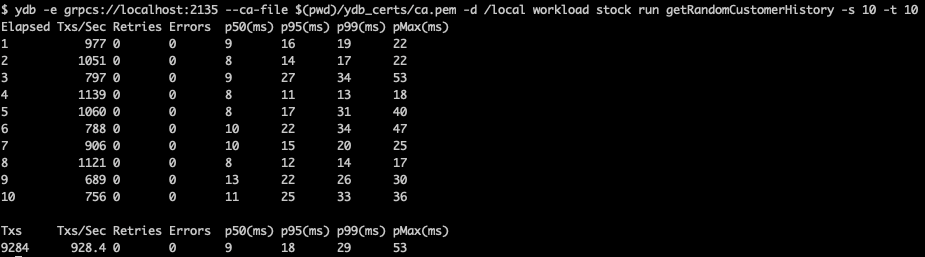
Что означают результаты вывода:
- Elapsed — номер временного окна. По умолчанию временное окно равно 1 секунде.
- Txs/sec — количество успешных транзакций нагрузки во временном окне.
- Retries — количество повторных попыток исполнения транзакции клиентом во временном окне.
- Errors — количество ошибок, случившихся во временном окне.
- p50(ms) — 50-й перцентиль latency запросов в мс.
- p95(ms) — 95-й перцентиль latency запросов в мс.
- p99(ms) — 99-й перцентиль latency запросов в мс.
- pMax(ms) — 100-й перцентиль latency запросов в мс.
- Timestamp — временная метка конца временного окна.
Завершение работы с Docker-контейнером
После завершения работы с YDB остановите Docker-контейнер:
docker kill ydb-localКакие еще есть варианты использования?
Мы постарались предоставить максимальную гибкость при использовании YDB. Для локального тестирования или отладки можно использовать Docker-контейнер или запустить кластер в Kubernetes (например, локально при помощи Minikube). Можно самостоятельно сконфигурировать и запустить кластер YDB с помощью подготовленной нами сборки.
Для промышленной эксплуатации мы рекомендуем развернуть YDB с помощью Kubernetes либо воспользоваться полностью управляемым сервисом в Yandex Cloud. И, конечно, вы всегда можете собрать YDB из исходников.
Что дальше?
Выход в опенсорс — ни в коем случае не финальная остановка. Для нас это скорее начало пути к тому, чтобы стать одной из лучших баз в мире в своём сегменте. Предстоит серьёзная работа: прямо сейчас мы активно трудимся над расширением аналитических способностей YDB.
В разработке возможность «охлаждения» данных в таблицах YDB для удешевления их хранения. Также мы планируем подготовить драйверы для популярных бенчмарков (таких как TPC-C и YCSB), чтобы предоставить возможность тестировать YDB привычным способом и сравнивать базу с аналогами. Планируем продолжать работу над инструментами экспорта и импорта данных. Будем развивать CDC — генерацию потоков событий об изменениях в БД и механизм записи этих событий в поддерживаемые системы передачи (чтобы получить консистентное состояние при их обработке на «приёмнике»). И, конечно, одним из безусловных приоритетов для нас всегда остаётся повышение эффективности системы и улучшение производительности.
Если у вас возникли вопросы — спрашивайте в комментариях и задавайте их на Stack Overflow с тегом YDB. Узнать больше о возможностях и вариантах использования, познакомиться с документацией, а также загрузить необходимые файлы и инструменты можно на странице ydb.tech.
Комментарии (108)

crispart
19.04.2022 12:34+45Хороший шаг. Спасибо, что делитесь с сообществом наработками. Достаточно давно используем в проде ClickHouse. Довольны. Теперь попробуем и YDB.




zueve
19.04.2022 13:55+11Круто, да и конкурентов в opensource немного (cockroachDB ?). Но хотелось бы что бы перечслили и недостатки. Из статьи не совершенно не понятно:
- поддержиывется ли ACID?
- а интерактивные транзакции?
- на скольео YQL соответствует ANSI SQL, в чем причина для нового языка?
iiopy4uk_mck
19.04.2022 14:21+5Там не просто acid, а с уровнем по умолчанию serializable. По описаниям из доки, она под oltp, если с таким уровнем производительна, то считаю это очень приятным.
Сейчас вот сижу читаю доку в разделе концепции, сайт у них очень приятный кстати.

olalala Автор
19.04.2022 15:39+7поддержиывется ли ACID?
да
а интерактивные транзакции?
тоже да
на скольео YQL соответствует ANSI SQL, в чем причина для нового языка?
Про причины появления достаточно подробно написал мой коллега в статье про YQL. Мы в целом стремимся к максимальному сближению с ANSI SQL.


oWeRQ
19.04.2022 14:06+7Исходный код, документация, SDK и все инструменты для работы с базой опубликованы на GitHub под лицензией Apache 2.0.
Не планирует ли Яндекс выпустить свой гитхаб, с рекламой и Алисой? Нынче становится актуально.

eigrad
19.04.2022 15:43+1У них в облаке есть Gitlab - https://cloud.yandex.com/en/services/managed-gitlab
oWeRQ
19.04.2022 18:06+6В облаке, на vds'ке и на железке можно поднять Gitlab или Gitee, только все это будет для личных нужд, если мы говорим про оперсорс - хорошо бы публичный сервис.


Xabroid
19.04.2022 14:18+6@olalala
У вас в документации сказано, что "YQL (YDB Query Language) is a universal declarative query language for YDB, a dialect of SQL. YQL has been natively designed for large distributed databases, and therefore has a number of differences from the SQL standard".Если YQL это диалект, то с каким именно стандартом SQL вы себя здесь сравниваете и в чем конкретно эти отличия состоят? Где найти список того, что из SQL не поддерживается и того, что вами было в него привнесено?

Paskin
19.04.2022 16:40Походу - привнесены всякие ключевые слова и параметры, связанные с масштабированием.
Xabroid
19.04.2022 18:00Увидел выше ответ "Мы в целом стремимся к максимальному сближению с ANSI SQL". Т.е. здесь имеется в виду самый первый стандарт SQL, принятый в 1986 году.
olalala Автор
19.04.2022 18:48Пока не готовы точно сказать про версию стандарта, но безусловно будем учитывать и уже поддержанную в YDB функцинальность, такую как поддержка JSON (поддержка синтаксиса появилась в ANSI SQL 2016) и планы по будущей функциональности.
Xabroid
20.04.2022 00:35Я бы советовал не упоминать ANSI SQL в качестве целевого стандарта и даже не потому что ANSI – это Американский национальный институт стандартов, который представляет интересы США.
Просто в отношении стандарта SQL есть очень распространенное
заблуждение – думать, что ANSI создает стандарт SQL. На самом деле сейчас в
США просто берут очередную ревизию международного стандарта ISO/IEC 9075 и утверждают его в качестве национального. Например, говоря "ANSI SQL 2016" вы, скорее всего, имели в виду "ISO/IEC 9075:2016". Но у этого заблуждения есть корни – первый стандарт SQL (ANSI X3.135-1986) действительно был создан структурами, аккредитованными ANSI.

onyxmaster
19.04.2022 14:31+12Будете тесты Jepsen заказывать? А то бенчмарки производительности хорошо, но надёжность для данных важнее :)
olalala Автор
19.04.2022 18:49+2Думаем про это, учитываем при формировании планов на будущее. Пока используем свою систему тестирования.
DiligentMetal
19.04.2022 14:46+2А будет ли тяжело освоится в YDB мне как новичку, который только научился разрабатывать отчеты с использованием ETL-процессов? Я учился на Oracle PL/SQL , если что.

as3k
19.04.2022 15:04-51GitHub банит Россию, а главная ИТ-компания выкладывает туда свой проект. При чем тут политика?

fireSparrow
19.04.2022 16:26+11Не могли бы вы более развёрнуто описать свою мысль?
Вы считаете, что не надо ничего выкладывать на гитхаб, поскольку он повёл себя недружественно? Или вы считаете, что не надо выкладывать на гитхаб поскольку высок риск, что репозиторий заблочат? Или надо демонстративно не выкладывать на гитхаб, чтобы обозначить перед всеми позицию в данном конфликте?as3k
19.04.2022 16:45-10Естественно! Яндексу нужно было показательно выложить репозиторий на ftp.yandex.ru, а коммиты по E-mail принимать будет лично Платон Щукин.
Можно к ftp прикрутить соцсеть с рекламой и будет Яндекс.Интернет!:)
А технически статья хорошая, мне понравилась.

zhengxi
20.04.2022 11:23высок риск, что репозиторий заблочат. причём вместе с форками, т.е. работой сторонних контрибюторов.
сам git-репозиторий не сложно восстановить из локального, но тикеты и пуллреквесты пропадут навсегда

rat1
21.04.2022 04:08-2Уже писал)) Когда Яндекс стал иметь отношение к России? Да, он ведет бизнес в России, но главное юридическое лицо зарегистрировано не здесь. Он также еще много где ведет бизнес) Основатель из России? Сергей Брин тоже из России) Но мы же не называем гугл российским )


Xabroid
19.04.2022 15:16+3@olalala
У вас в документации сказано, что "На затронутые в ходе транзакции сущности ставятся оптимистичные блокировки, при завершении транзакции проверяется, что блокировки не были инвалидированы".Под "сущностями" здесь что подразумевается – таблицы, строки, поля, что-то другое?

interrupt
19.04.2022 17:07Строки. Оптимистические блокировки работают на уровне строк.
Xabroid
20.04.2022 02:35Ниже Олег olalala ответил, что "Шард (таблетка) однопоточен, изменения будут выполнены последовательно". Поэтому координатор транзакций, вероятно, при планировании транзакций оперирует не строками, а шардами. И поэтому квантом данных для блокировки здесь, вероятно, является не строка, а шард.

ubx7b8
19.04.2022 15:21+4сейчас база визитов содержит больше 100 терабайт данных
А с точки зрения позиционирования вашего продукта есть какая-то хотя бы размытая грань, где уже стоит выбрать YDB или по-прежнему использовать старые добрые MySQL/PostgreSQL итд? Спасибо.

BugM
19.04.2022 16:24+3Да как обычно. Пока обычные БД тянут нагрузку без особых костылей - используем их. Как перестали начинаем смотреть А что ещё есть?
О нагрузке стоит думать до написания кода. Чтобы потом срочно не переделывать все.
olalala Автор
19.04.2022 22:29Например, когда планируется рост нагрузки или объема данных. Даже если на текущий момент проект небольшой — дешевле спроектировать решение с учетом планируемых нагрузок. На практике у нас есть много проектов, которые росли с единиц RPS до сотен тысяч RPS и с мегабайт до десятков терабайт без рефакторинга кода.

tbl
19.04.2022 15:21+1По возможностям выглядит как амазоновская DynamoDB с натянутым поверх парсером SQL
olalala Автор
19.04.2022 22:34+3Это только узкое подмножество задач, которое можно решить с помощью YDB. Именно поэтому мы реализовали поддержку совместимости с DynamoDB API в бессерверном режиме в Yandex Cloud.
tbl
19.04.2022 23:52О, круто.
Хотелось бы посмотреть на comparison-chart фич с существующими KV-хранилищами: поддержка локальных/глобальных вторичных ключей, кастомных типов данных, репликация и т.п.
olalala Автор
20.04.2022 00:03+5У нас в родмапе есть сравнительный анализ с различными конкурентами. Постепенно будем готовить статьи.


yokotoka
19.04.2022 15:29+13А как вы победили CAP-теорему? Что, в итоге, стало слабым звеном?

Luchnik22
19.04.2022 18:40+3При обсуждении YDB и теоремы CAP, мне сегодня намекнули, что лучше ей не пользоваться, так как не всё так однозначно (перевод на хабре)
P.S. Моё мнение было, что это CP система, в жертву A


Xabroid
19.04.2022 17:20+1@olalala
У вас в документации сказано, что "Каждый индекс обслуживается своим набором шардов, и решения о разделении или объединении его партиций принимаются независимо на основании настроек по умолчанию. В будущем эти настройки могут быть сделаны доступными пользователям, аналогично настройкам основной таблицы".Означает ли это, что сейчас отсутствует возможность управлять шардированием индекса для конкретной таблицы?
olalala Автор
19.04.2022 22:44Сейчас настройки пользователем параметров партицирования доступны только для таблицы. Для партицирования вторичного индекса применяются специальные эвристики и автоматическое партицирование по нагрузке. В будущем мы планируем дать пользователям возможность изменять эти настройки аналогично настройкам основной таблицы.
Xabroid
19.04.2022 17:36+1@olalala
У вас в документации про шардирование сказано, что "Характерное время операции разделения или объединения — порядка 500 мс. На это время вовлеченные в операцию данные становятся кратковременно недоступны для чтения и записи… Стоит отметить, что если система по каким-то причинам перегружена (например, из-за общей нехватки CPU или пропускной способности выделенных базе дисковых ресурсов) то операции разделения и объединения могут длиться дольше ".А вот это "характерное время" в 500 мс. откуда взялось? Судя по тексту, оно не зависит от размера самих шардов, а зависит только от загрузки ресурсов CPU/IO – это так надо понимать?
olalala Автор
20.04.2022 12:26Это действительно "характерное" время в несколько сотен мс. Связано с набором операций, которые нужно выполнить — заблокировать шард на запись, дождаться разбора и выполнения всех операций в очереди шарда, выполнить компакшн, ... (это не весь пайплайн, целиком пайплайн достаточно большой). Системная таблетка SchemeShard, которая отвечает за всю работу со схемой данных, ждёт оповещения о завершении всех этих работ, завершает схемную операцию, публикует изменения.

yegreS
19.04.2022 17:45+3А где можно почитать про общую архитектуру? из статьи и из оф. документации так до конца и не понял как она устроена.
В кластере один мастер и несколько slave? При этом все запросы идут через мастер и проксируются на рабочие ноды(Tablet), потом результат собирается на мастере и отдается клиенту?
и я так понял под капотам там key->value хранилище?olalala Автор
19.04.2022 18:28Можно посмотреть доклад про Distributed Storage и про распределенные транзакции. Больше выступлений и публичных материалов можно посмотреть по ссылке https://cloud.yandex.ru/docs/ydb/public_talks
olalala Автор
19.04.2022 22:49В кластере один мастер и несколько slave? При этом все запросы идут через мастер и проксируются на рабочие ноды(Tablet), потом результат собирается на мастере и отдается клиенту?
У вас смешаны термины. Мастер есть у каждой таблетки. Мастер у таблетки один. Возможно наличие у таблетки мастера — фолловеров, то есть реплик на чтение. Таблетка очень легковесная сущность — отвечает за хранение не более чем 1-2 GB. Таблеток в кластере может быть очень много. Что вы имеете в виду под нодой? Обычно мы употребляем этот термин в значении сервер.
tbl
20.04.2022 00:00Насколько легковесна "таблетка"? Может ли она одновременно выполнять более одной читающей операции, или надо множить таблетки для поддержания высокого throughoutput?
olalala Автор
20.04.2022 00:15Таблетка однопоточна. Для масштабируемости throughput мы партицируем таблицу на таблетки. Есть возможность настроить автоматический сплит по размеру или по нагрузке.
yegreS
20.04.2022 11:53Спасибо за ссылки.
Видимо я пока плохо разобрался, попробую перефразировать вопрос.Точкой подключения для клиента (приложения) что является? какой-то конкретный мастер сервер? Или у вас умный клиент и он сам определяет куда подключится?
olalala Автор
20.04.2022 14:29У нас клиентская балансировка, первый запрос который выполняет SDK — это ListEndpoints. То есть сначала выполняется Discovery, далее клиент устанавливает соединения с доступными для базы ендпойнтами.

voidSoul
21.04.2022 17:21Уточню: в инсталляциях YDB у нас есть нечто похожее на "конкретный мастер", точнее это либо L3-балансер, либо DNS-балансер. Это (начальный endpoint) надо задавать явно. Поэтому первый запрос Discovery/ListEndpoints действительно "выясняет" конфигурацию кластера и дальше работает клиентская балансировка в SDK уже с конкретными нодами YDB.
Или у вас умный клиент и он сам определяет куда подключится?
Как будто бы умный клиент получается

Xabroid
19.04.2022 18:17@olalala
У вас в документации сказано, что "При выполнении запросов в YDB фактическое выполнение запроса к каждому шарду осуществляется в единой точке, обслуживающей протокол распределенных транзакций. ... данные уже хранятся реплицированно и возможно обслуживание более одного читателя (но писатель при этом все еще в каждый момент строго один)".Поясните фразу "писатель при этом все еще в каждый момент строго один". Означает ли это, что два непересекающихся множества строк в одном шарде не могут параллельно изменяться двумя разными приложениями при том, что каждое приложение изменяет только "свое" множество строк?
olalala Автор
20.04.2022 00:18Шард (таблетка) однопоточен, изменения будут выполнены последовательно

SIMPLicity
19.04.2022 18:25Платежи через использование YDB идут?, или (пока?) мимо,- через другие механизмы?
PS Вопрос скорее о доверии разработанному механизму ACID ...
olalala Автор
20.04.2022 11:48Есть биллинговые системы, которые используют YDB для аккаунтинга данных.

TimoshkinVlad
19.04.2022 20:36+2Большое спасибо. А есть ли минимальные требования? Т.е. если сравнить ydb использование с postgee будет ли выигрыш по деньгам, скажем на представленном тестовом магазине? Т.е. есть ли смысл её использовать в небольших проектах в надежде обойтись 'стандартным' хостингом? Я понимаю, как это звучит, но всё же?
olalala Автор
20.04.2022 00:00+1Вместо стандартного хостинга вам вероятно лучше подойдёт YDB как managed service.
voidSoul
20.04.2022 01:22Я бы даже рекомендовал посмотреть в сторону serverless YDB в Yandex.Cloud. Пока ваш магазин маленький - плата ничтожная. Если начнет лавинообразно расти нагрузка (например в случае успеха продвижения товаров/бренда/магазина) - произойдет автомасштабирование, соответственно пропорционально вырастут расходы на сервис. О железе/хостинге думать вообще не надо
tbl
20.04.2022 01:25+3Лавинообразный рост нагрузки совсем не означает лавинообразный рост доходов магазина. Так можно и погореть.


gmelikov
19.04.2022 22:37+5If you know what i mean https://github.com/ydb-platform/ydb/search?q=kikimr
ZakharY
19.04.2022 23:58В документации не вижу как сделать авторизацию, к примеру через Access Token. Сейчас в self-hosted это не поддерживается?

archibaldtelepov
21.04.2022 08:27В YDB можно настроить авторизацию по логину/паролю.
Мы готовим документацию.


cadovvl
20.04.2022 10:33Правильно ли я понял правила работы Serverless YDB: если я использую меньше гигабайта данных, и до миллиона RU в месяц (и до 100 RPS), то сервис будет для меня бесплатным.
Мой телеграм бот делает примерно 200-300 запросов в сутки, и я его могу подключить просто нахаляву, а когда он наберет гигабайт данных - начнут списывать по 20 рублей в месяц. Все верно? Или есть тарификация чего-то еще, чего я не заметил?olalala Автор
20.04.2022 12:50+3На бессерверный режим YDB действуют специальные тарифы, в рамках которых определенный объем услуг не тарифицируется.
Каждый месяц не тарифицируются первые:
1 000 000 операций (в единицах Request Unit);
1 ГБ/месяц хранения данных.
Хранение данных, свыше 1 ГБ в месяц стоит 21,3800 ₽ за 1 ГБ в месяц.
То есть до определенного уровня потребления действительно можно пользоваться "нахаляву". Без скрытых списаний.


unih
20.04.2022 12:51+1Спасибо огромное. На майских буду тестить и если понравится - насаждать добро среди наших датаинженеров.

ElectricPigeon
20.04.2022 13:26А как YDB позиционирует себя относительно ClickHouse? Это "более современная" замена ему? Или у них принципиально разные сферы применимости?
cadovvl
20.04.2022 13:54+2Полагаю, разные хранилища и для разных целей.
ClickHouse нацелен на огромные объемы операций записи (натурально каждый клик), и редкие запросы на чтение, которые по этим данным собирают агрегированную статистику.
Классические базы данных (и YDB) подразумевают большие объемы чтения и малые записи: мы показываем магазин чаще, чем покупаем в нем, или меняем цены.
Ну и, исходя из задач, появляются разные особенности использования, функционал, синтаксис, гарантии и т.п.
Поправьте, если я не прав.olalala Автор
20.04.2022 22:35+1Это не так. Вы приводите только один из множества примеров типов нагрузки, они могут быть совершенно различными. Соотношения чтение/запись также могут быть очень разными.
Например базовый набор нагрузок для теста KV СУБД YCSB содержит несколько типов соотношений чтение/запись: 50/50, 95/5, 100/0.
BugM
20.04.2022 14:37+2Они разные.
Кликхаус это аналитическая БД. Посчитать агрегат по сотням миллионов строк.
YDB это ближе к kv. Читать и писать по ключу небольшие объемы за раз, но с огромным rps.
olalala Автор
20.04.2022 22:31+2Необязательно по ключу. KV это только один из возможных паттернов доступа.
olalala Автор
20.04.2022 22:31ClickHouse это аналитическая СУБД. YDB - база данных для операционной (OLTP) нагрузки. То есть обеспечивает большой и легко масштабируемый поток транзакций, каждая из которых читает/пишет/изменяет небольшой объём данных, при этом каждая из транзакций выполняется за относительно небольшое время, так как запросы часто интерактивны.

stranger_shaman
20.04.2022 13:32При попытке создать симулятор скалад интернет-магазина выдает:
ydb -e grpc://localhost:2136 -d /local workload stock init -p 100 -q 1000 -o 1000 Query execution failed: <main>: Error: Execution, code: 1060 <main>:1:150: Error: Operation aborted due to constraint violation: insert_pk, code: 2012 Query: --!syntax_v1 DECLARE $stocks AS List<Struct<product:Utf8,quantity:Int64>>; INSERT INTO `stock`(product, quantity) SELECT product, quantity from AS_TABLE( $stocks );в чем может быть проблема?
archibaldtelepov
22.04.2022 10:03Предположу, что вы повторно запускаете stock init. И он про попытке вставить строки натыкается на уже существующие
Konwin
20.04.2022 22:32Планируется ли выпуск JDBC драйвера?
olalala Автор
20.04.2022 22:59Да, экспериментальная версия уже доступна https://github.com/yandex-cloud/ydb-java-sdk/tree/master/jdbc
Backend-Sanya
а userver тоже в этом году выйдет в опенсорс?
olalala Автор
Это вопрос скорей к авторам userver @antoshkka
PereslavlFoto
А будут ли выложены в опенсорс звукозаписи, изображения и тексты, которые создаёт Музей Яндекса?
antoshkka
Да, если не случится непредвиденного. Выложим в opensource вместе с:
Шаблоном для создания своих сервисов. CI, сборка, тестовое окружение уже настроены из коробки
Сервисом динамических конфигов. Можно менять параметры вашего работающего сервиса без его рестарта
Документацией, примерами и чатами поддержки (куда же без этого!)
svad1947
Воу, как же это здорово! будем ждать, верить, надеяться :))
vvzvlad
Вы что, наркоман?
aegoroff
По ходу да