

Привет, Хабр! Меня зовут Георгий Лебедев, я работаю в команде разработки ядра Tarantool. В 2021 году мы впервые участвовали в Google Summer of Code (GSoC): одним из предложенных студентам проектов была миграция SQL с VDBE на JIT-платформу — с неё и начался мой путь в Tarantool.
Имея за плечами год учебных проектов по разработке различных компонент toolchain’а и вооружившись поддержкой менторов (Никиты Петтика, Тимура Сафина и Игоря Мункина), я взялся за этот проект. Создавая летом, фактически с нуля, платформу для JIT- компиляции SQL- запросов в Tarantool, я наступил на некоторые грабли и приобрёл, на мой взгляд, интересный опыт и знания, которыми хочу поделиться. Статья будет, в первую очередь, интересна тем, кто захочет дальше развивать этот проект, а также тем, кто рассматривает возможность внедрения JIT-компиляции в свой собственный SQL.
С чем нужно было работать
Для поддержки языка SQL в Tarantool используется виртуальная машина (ВМ), унаследованная от SQLite, также известного как Virtual Database Engine (VDBE). Схема этого компонента:

На практике одним из самых популярных способов реализации виртуальных машин является оперирование потоком байтовых инструкций — байткода: на таком же принципе основана VDBE. В этой статье нас будет интересовать байткод в качестве промежуточного представления для виртуальной машины и его интерпретация: далее, говоря о байткоде и реализации ВМ SQL в Tarantool, я буду подразумевать именно VDBE.
Байткод-интерпретация представляет из себя цикл for по массиву opcode’ов (читай, байткод-программе, сгенерированной по SQL-запросу) и switch по типу opcode’а:
for(pOp = &aOp[p->pc]; 1; pOp++) {
switch (pOp->opcode) {
...
}
}Задача
С точки зрения сервера приложений, в Tarantool уже есть виртуальная машина — LuaJIT. Ещё одна рукописная (то есть без использования фреймворков для построения среды исполнения) ВМ для поддержки SQL выглядит не очень изящно с точки зрения архитектуры, не говоря уже о проблемах с производительностью, которые она вносит.
В проекте предлагалось исследовать несколько возможных альтернатив VDBE:
переиспользование инфраструктуры LuaJIT;
использование фреймворка MIR для JIT-компиляции;
использование фреймворка LLVM ORC.
Результаты, которые хотелось получить:
проверка идеи миграции VDBE на выбранную JIT-платформу;
исследование различных сценариев применения JIT-компиляции в контексте SQL;
измерение производительности JIT-компиляции в различных SQL-бенчмарках.
Поскольку решение задачи в заданные сроки (три летних месяца) представлялась неподъёмной, а в Tarantool уже имелся первый подход к снаряду в виде патча трёхлетней давности на базе LLVM ORC, я решил использовать именно этот фреймворк и развивать идею Никиты Петтика. Кроме того, мы оглядывались на успешный опыт Postgres, уже реализовавших такую платформу на основе этого фреймворка.
И сегодня есть ещё СУБД, ClickHouse, в которой также успешно реализована JIT-платформа для SQL на базе LLVM ORC.
JIT-компиляция SQL
JIT-компиляция не является панацеей: у этого подхода есть свои накладные расходы и он не всегда даёт лучшие результаты по сравнению с байткод-интерпретацией — именно поэтому у JIT-компиляции довольно ограниченный набор сценариев применения.
Основные преимущества подхода:
уменьшение количества инструкций перехода и локализация нативного кода — лучшее использование branch predictor’а;
уменьшение количества веток и объёма машинного кода за счёт специализации;
улучшение производительности горячих участков байткода, которые являютсяузкими местами при обработке процессором;
лучшее использование кешей процессора;
генерация инструкций под целевой процессор;
простор для оптимизации сгенерированного IR.
В контексте SQL можно выделить основной сценарий использования JIT-компиляции: тяжелые аналитические data query language (DQL) запросы, содержащие много выражений и логики.
.")
Такие запросы представляют собой последовательность байткода, многократно исполняемую в цикле: последовательность, которую можно сшить в один opcode, являющийся вызовом функции с нативным кодом — идеальный случай для применения JIT-компиляции.
Здесь можно выделить некоторые сценарии вычислений, представляющие наибольший интерес:
декодирование кортежей (строк в терминологии Tarantool);
арифметические и логические выражения разных видов;
агрегатные функции.
Агрегатные функции представляют особый интерес, поскольку для их вычисления используются отдельные циклы — снова очень подходящие условия для JIT-компиляции.
Некоторые трудности и аспекты работы над проектом, на которых я не хотел бы здесь останавливаться, я осветил в своём финальном отчёте для GSoC.
Далее речь пойдёт о наиболее важных, на мой взгляд, выводах, которые я сделал при работе над проектом.
LLVM ORC
Использование стороннего фреймворка для JIT-компиляции, пусть и со своим собственным IR, позволило абстрагироваться от задач генерации, оптимизации и хранения нативного кода, сосредоточившись на генерации LLVM IR и встраивании JIT-компилятора в существующую инфраструктуру SQL.
To inline, or not to inline, that is the question
При встраивании JIT-компиляции в SQL-инфраструктуру возникает вопрос о том, каким образом генерировать LLVM IR, функционально эквивалентный интерпретации opcode’ов на C. Есть два принципиально разных подхода:
полностью ручная генерация LLVM IR для каждого opcode’а (Postgres);
В Postgres второй подход используется только для встроенных функций и операторов.
На мой взгляд, первый подход сопоставим с написанием вручную ассемблерного кода: довольно трудозатратен и чреват ошибками. Кроме того, было бы попросту скучно вместо инновационного летнего проекта заниматься механической работой.Я выбрал такую стратегию: обёртывать существующие блоки кода для SQL opcode’ов в callback’и, вызываемые в JIT-компилируемом коде — это также позволяет избавиться от довольно нетривиального дублирования кода при использовании первого подхода.
Здесь возникает резонный вопрос: а как же специализация кода и другие преимущества JIT-компиляции, которых мы, казалось бы, лишаемся, используя такую стратегию? Тут мне на помощь должны были прийти возможности inlining’а, которые предоставляет LLVM: как выяснилось, для используемого мной C API, который является небольшим подмножеством C++ API LLVM, такие возможности вообще отсутствовали и появились лишь в 13 версии LLVM.

Кроме того, даже для применения C++ API необходимо построить целую инфраструктуру, чтобы:
хранить, индексировать и загружать bitcode, сгенерированный clang;
искать в bitcode-модулях (единица трансляции в терминологии LLVM) нужные callback’и и переносить их IR между модулями;
явно inline’ить callback’и.
Хорошим примером того, как можно реализовать такую инфраструктуру на практике, является Postgres.
Патчинг сгенерированного LLVM IR
В JIT-компиляции SQL в Tarantool есть важный нюанс: некоторые opcode’ы VBDE патчатся при генерации байткода. Например, это используется для оптимизации: чтения напрямую из таблицы можно заменить чтением из индекса:


Видно, что у всех opcode’ов Column изменился первый аргумент, соответствующий номеру курсора.
Ещё одно обстоятельство, при котором нужно патчить байткод-инструкции — это корутины, используемые для подзапросов. Байткод, загружающий колонки из таблицы корутины, должен меняться на байткод, копирующий колонки из регистров возвращаемых значений корутины:


Эти же обстоятельства нужно отражать и в генерируемом LLVM IR; с точки зрения IR решение этой проблемы напрашивается само собой: использовать для каждого opcode’а свой базовый блок — это сильно упрощает анализ, поиск и патчинг нужных инструкций. Или даже позволяет выкидывать целые блоки и заменять их на другие. И всё это нелинейно!


LLVM IR выше для запроса select A from DEMO соответствует загрузке колонки в регистр: видно, как поменялось значение аргумента инструкции store в базовом блоке OP_Column_begin:
store i32 1, i32* %tab, align 4
Представленный ниже LLVM IR генерируется для запроса select * from (select A from DEMO), использующего корутину:


SQL-бенчмарки
Заключительной частью проекта было измерение производительности в стандартных SQL-бенчмарках: я взял TPC-H, как наиболее показательный — в нём отражены типичные аналитические SQL-запросы.
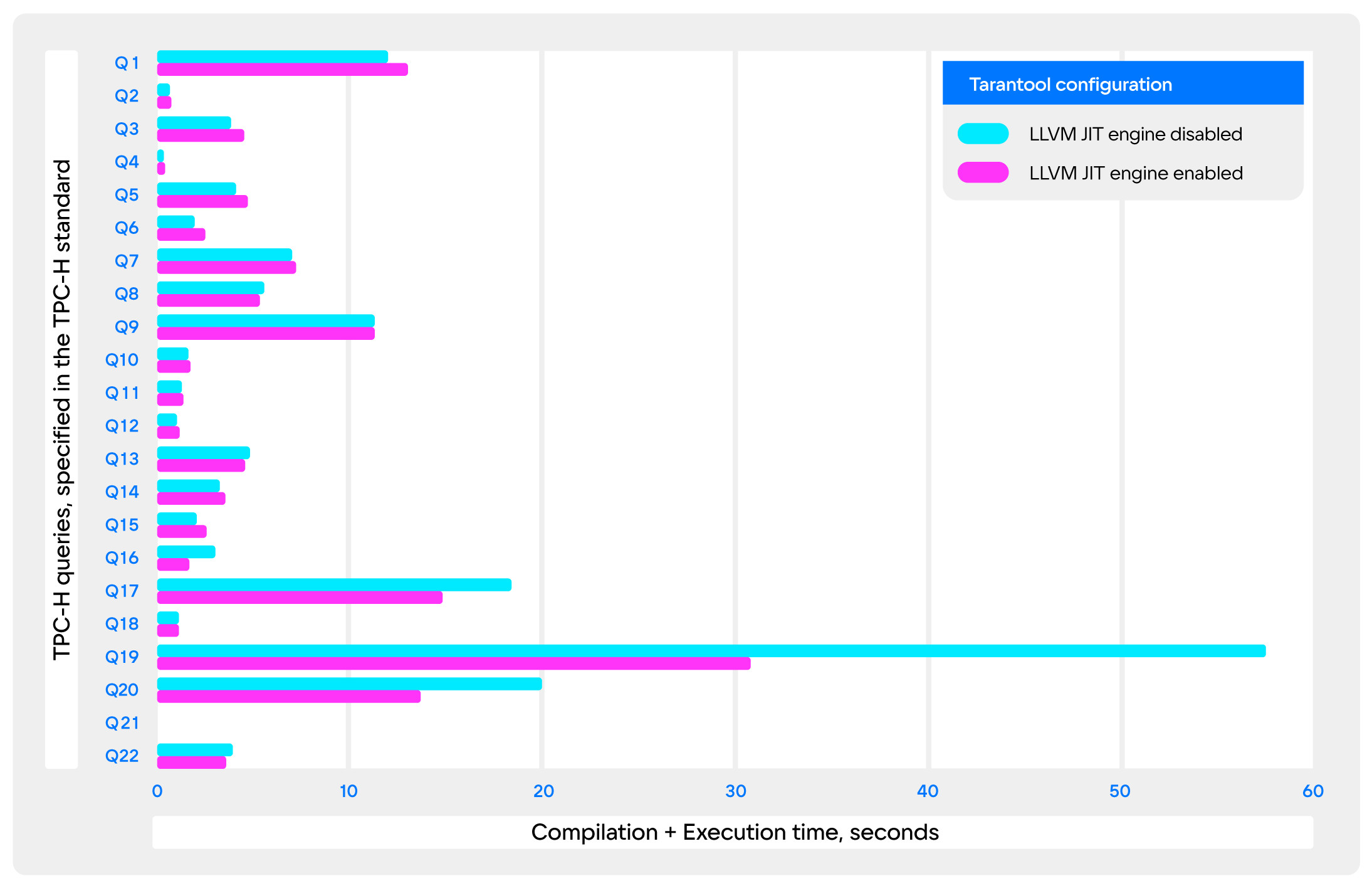
При измерениях учитывалось также время анализа и компиляции запросов, тогда как на практике предполагается применять JIT-компиляцию только для prepared-запросов. Если пренебречь этими накладными расходами, то можно считать, что потери производительности при использовании JIT-компиляции отсутствуют.
К сожалению, из-за того, что я не успел сделать JIT-компиляцию арифметических выражений, а большинство запросов в TPC-H содержат их в большом количестве, мало где удалось увидеть её в деле. Выстрелили только Q17, Q19, Q20. Наиболее примечателен Q19: он содержит огромное количество колоночных ссылок и литералов — прирост производительности оказался практически двухкратным!
Результаты
Патч-сет с платформой для JIT-компиляции SQL на основе 12 версии LLVM ORC.
JIT-компиляция различных
SELECT-выражений: литералов, колоночных ссылок и агрегатных колонок.JIT-компиляция агрегатных функций (например,
SUM,COUNT,AVG) с некоторыми ограничениями на сложность запроса.Бенчмарк TPC-H показал существенный прирост производительности на некоторых типах запросов и не показал заметной деградации производительности на остальных.
Вместо заключения
В 2022 году можно продолжить работу над JIT-компиляцией SQL в Tarantool. Мы запустили собственную программу для студентов, о чём недавно рассказали на Хабре. Также мы участвуем в Summer OSPP и приглашаем всех, кто заинтересовался проектом, попробовать свои силы. Айда JIT-компилировать!
Оставайтесь на связи в нашем Telegram-чате по студенческой программе и Summer OSPP.
Hixon10
Привет,
не особо понятно, что это означает. Можно, пожалуйста, демонстрирующий идею пример?
xhinhellhx
Скорее всего, имеется ввиду повторное использование интерпретатора байт-кода, если можно так выразиться. Представь что у тебя в интерпретаторе байт-кода есть какая-нибудь функция
handleSelect(). При генерации машинного кода грубо говоря встраивается вызов функции с аналогичной реализацией (с точностью до оптимизаций), который впоследствии должен inline-иться. И при таком подходе основной прирост производительности должен быть за счет этих самых inline-ов: захотел ты обработать R строк в таблице, на каждую строку при интерпретации у тебя было бы N вызовов, несущих в себе еще и PUSH/MOV-инструкции, а так у тебя в конечном счете выполняется наO(RN)инструкций меньше.CuriousGeorgiy Автор
Привет!
@xhinhellhxвсё правильно написал. Проиллюстрирую на примере OP_Column: оборачиваем этот switch-case в функцию, добавляем её в бутстрап-модуль LLVM, загружаем её сигнатуру оттуда, и, наконец, генерируем вызовы к ней, когда JIT-компилируем OP_Column'ы.
Добавлю от себя ещё, что помимо сшития (избавления от интрукций перехода) машинного кода, который дает inlining, есть возможность использовать оптимизационные проходы LLVM — за счет динамической информации об аргументах callbaсk'ов (сейчас понял, что тут этот термин действительно немного не к месту здесь), помимо прочего, можно убирать целые ветки кода (читай: constexpr if statement). Причем при таком подходе результат получается автоматически.