

Чтобы понимать, как работают системы машинного обучения, нужно знать, из каких компонентов они состоят и как они связаны друг с другом. Команда VK Cloud Solutions перевела статью об архитектуре систем машинного обучения, которые сейчас используют на практике.
Схема архитектуры
Архитектура современных систем машинного обучения в общих чертах выглядит так:
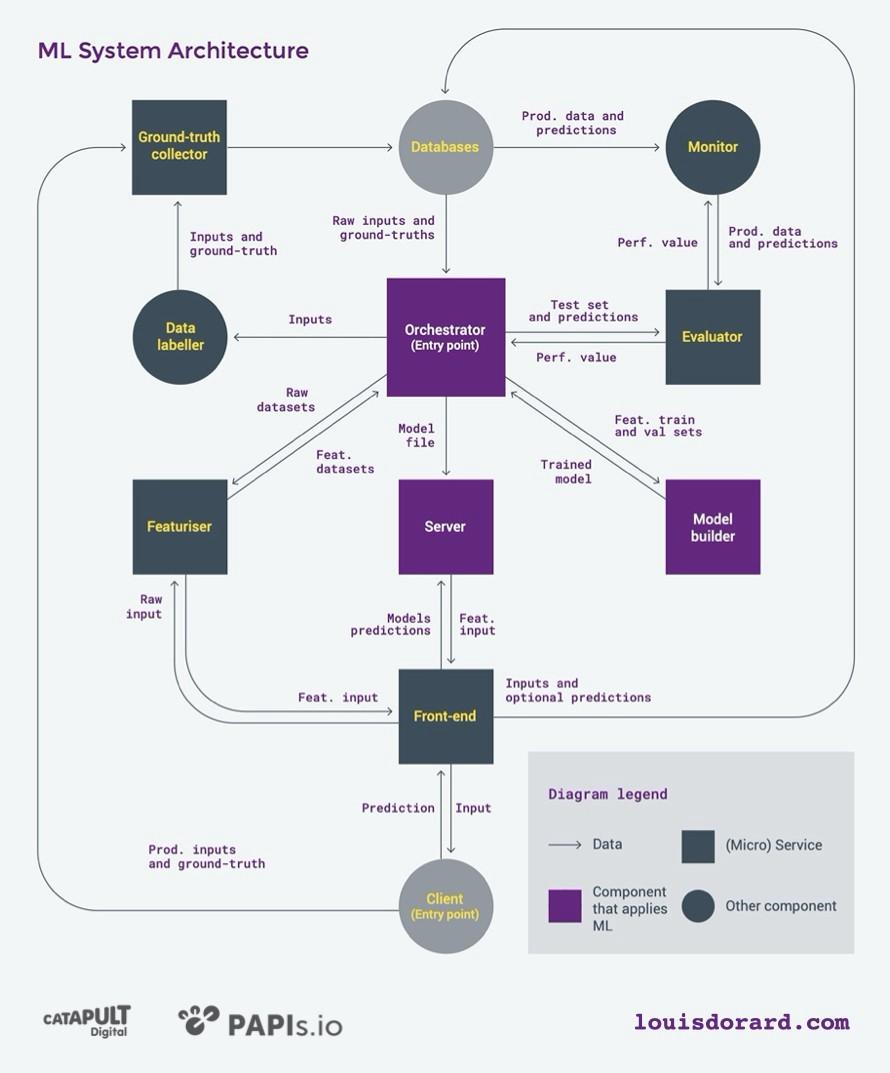
Это клиент-серверная архитектура «обучения с учителем», например, классификации и регрессии. Здесь запрос на прогнозирование отправляет клиент, а выполняет сервер.
Примечание: для некоторых систем логичнее выполнять прогнозирование на стороне клиента. Другие могут даже мотивировать обучение модели на стороне клиента, но инструменты, с помощью которых такие задачи можно было бы эффективно решать в промышленных ML-приложениях, еще не созданы.
Обзор компонентов системы машинного обучения
Чтобы читать статью было удобнее, советую открыть схему в отдельном окне и постоянно с ней сверяться.
Базы данных существуют еще до создания ML-системы. Темно-серые и фиолетовые компоненты — новые, их предстоит создать. Также фиолетовым цветом выделены компоненты, которые применяют ML-модели для прогнозирования. Прямоугольные компоненты предоставляют микросервисы, как правило, доступные через REST API. Они работают на бессерверных платформах.
Есть две «точки входа» в нашу ML-систему:
- клиент, обращающийся с запросом о прогнозировании;
- оркестратор, который создает и обновляет модели.
Клиент — это приложение, с помощью которого конечный пользователь получает реальную пользу от применения ML-системы. Например, мобильное приложение, через которое вы заказали еду, обращается с запросом об ожидаемом времени доставки.

Обычно оркестратор — это программа, которую вызывает планировщик для регулярного обновления модели. Либо ее вызывают через API для непрерывного выполнения интеграции или пайплайна развертывания. Задача планировщика — оценивать модели с помощью их сборщика на основе тестовых данных, которые держатся в секрете. Для этого планировщик отправляет тестовые прогнозы в модуль оценки.
Если модель достаточно хороша, ее передают на сервер моделей, где она становится доступной через API. Этот API может напрямую взаимодействовать с клиентской программой, но может потребоваться логика, которая зависит от области применения модели, поэтому она реализуется на стороне.
Допустим, одна или несколько базовых моделей доступны через API, но еще не интегрированы в окончательное приложение. Чтобы решить, какую модель интегрировать и насколько это безопасно, нужно отследить ее производительность на продакшн-данных и визуализировать с помощью модуля мониторинга. В нашем примере с доставкой еды можно сравнить ETD-модели с фактическим временем доставки заказов.
Когда появляется новая версия модели, запросы клиента на прогнозирование будут направляться на ее API через frontend. Это «перенаправление» затрагивает все больше конечных пользователей. При этом мы мониторим производительность и проверяем, не «ломает» ли ничего новая модель. Владелец ML-системы и владелец клиентского приложения все время проверяют дашборд мониторинга.
Давайте подробно рассмотрим 9 главных компонентов схемы:
- Модуль сбора контрольных данных (Ground-truth Collector).
- Модуль разметки данных (Data Labeller).
- Модуль оценки (Evaluator).
- Модуль мониторинга производительности (Performance Monitor).
- Обработчик входных данных (Featurizer).
- Оркестратор (Orchestrator).
- Билдер моделей (Model Builder).
- Сервер моделей (Model Server).
- Frontend
1. Модуль сбора контрольных данных (Ground-truth Collector)
В реальной жизни нужно постоянно собирать новые данные для машинного обучения. Особенно важен один тип: контрольные данные. Это то, что должны предсказывать ваши ML-модели: цену на объект недвижимости; событие со стороны заказчика; метку для входных объектов, например, маркировку сообщения как спам.
Иногда при наблюдении за входным объектом необходимо подождать какое-то время, чтобы с ним произошло то, что вы собирались прогнозировать. Например, приходится ждать, пока недвижимость купят, клиент продлит или отменит подписку, а пользователь откроет новые письма у себя во «Входящих». Возможно, вам нужно получить от пользователя весточку, когда
ML-система ошиблась в своих прогнозах:

Почтовые клиенты часто позволяют пометить сообщение как «Спам» или «Не важное» и учатся на такой обратной связи
Чтобы получать от пользователей обратную связь, понадобится специальный микросервис.
2. Модуль разметки данных (Data Labeller)
Иногда у вас есть доступ к огромному количеству входных данных, но нужно вручную собрать соответствующие контрольные данные. Например, когда вы создаете детектор спама или объекта на изображениях. Уже есть готовые Open Source web-приложения, упрощающие разметку данных (например, Label Studio), и выделенные серверы для аутсорсинга выполняемых вручную задач по разметке данных (например, Figure Eight и Google’s Data Labeling Service).

Классификация самолетов: Label Studio в действии
3. Модуль оценки (Evaluator)
Если у вас есть исходный датасет для машинного обучения, то перед построением любой ML-модели важно задать критерии оценки предполагаемой системы. В дополнение к измерению точности прогноза рекомендуется оценить краткосрочное и долгосрочное влияние метрик производительности конкретного приложения и системных метрик, таких как lag и throughput.
Оценка нужна, чтобы сравнить модели и решить, какую безопаснее интегрировать в приложение. Оценивать можно на предварительно определенном наборе тестовых сценариев, в отношении которого известен результат прогнозирования на реальных данных. Можно изучить распределение ошибок и собрать их в метриках производительности. Для этого модулю оценки нужен доступ к реальным контрольным данным тестового датасета, чтобы при получении прогнозов на входе он мог рассчитать ошибки и выдать метрики производительности.
Я рекомендую внедрить модуль оценки задолго до построения ML-моделей. Оцените прогнозы, сделанные базовой моделью, чтобы получить эталонные данные для сравнения. Как правило, базовые модели — эвристические, основанные на входных характеристиках (признаках). Это могут быть очень простые правила, заданные вручную:
- При прогнозировании оттока клиентов базовая модель может решить, например, что если за последние 30 дней клиент заходил к вам на сайт меньше трех раз, он, скорее всего, вас покинет.
- При прогнозировании сроков доставки еды базовая модель может вывести среднюю длительность доставки заказов из конкретного ресторана и сроки доставки конкретным курьером за последнюю неделю.
Хотите разрабатывать сложные ML-модели завтра? Посмотрите, какую ценность можно создать с помощью базовой модели сегодня!
4. Модуль мониторинга производительности (Performance Monitor)
На следующем этапе мы решаем, не пора ли интегрировать базовую модель в приложение. Здесь нужно использовать ее входные данные, которые встречаются в продакшн-среде, в условиях, приближенных к реальным, и отслеживать ее производительность в течение какого-то времени.
Чтобы рассчитать и отслеживать метрики производительности, нужно получить и входные продакшн-данные, контрольные данные и прогнозы, а также хранить их в базе данных.
Модуль мониторинга производительности состоит из:
- компонента, который считывает данные из БД и вызывает модуль оценки;
- дашборда, который показывает, как метрики производительности меняются с течением времени.
Наша задача — проверить, хорошо ли модель функционирует с течением времени и оказывает ли она положительное влияние на приложение, в которое интегрирована. Модуль мониторинга можно доработать — добавить к нему виджеты визуализации, которые показывают распределение продакшн-данных. Это поможет увидеть, что модель работает, как мы ожидали, или что в ней появились дрейфы и отклонения.
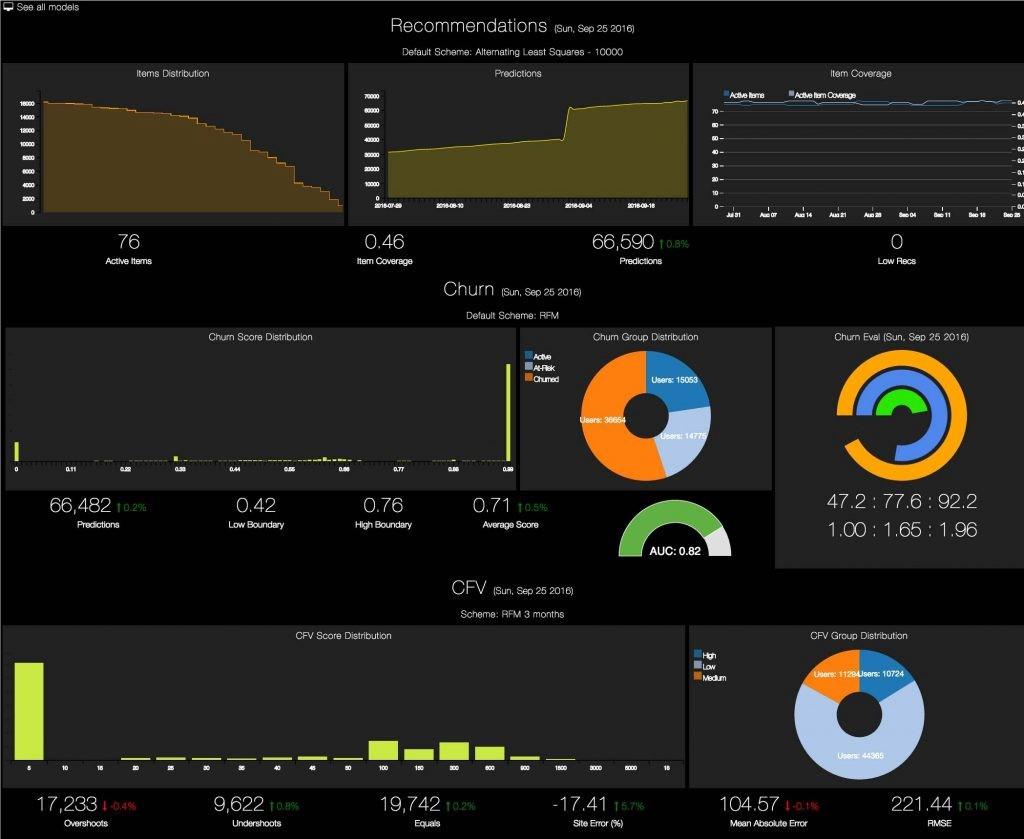
Дашборд мониторинга для модели оттока клиентов (Источник)
5. Обработчик входных данных (Featurizer)
При проектировании API-прогнозирования надо решить, что API будет воспринимать как входные данные. Например, когда мы делаем прогнозы о заказчиках, что нам использовать в качестве входных данных — полноценное представление заказчика или только его ID?
Часто числовое представление не всегда готово заранее. В отличие от текстов или изображений его сначала нужно рассчитать и передать в модель. В случае с заказчиками, некоторые признаки уже хранятся в базе данных, например, дата рождения, а другие нужно рассчитать. К таким данным относятся поведенческие признаки, которые описывают, как заказчик взаимодействовал с продуктом на протяжении какого-то времени. Чтобы их вычислить, потребуется выполнять запросы и собирать зарегистрированные данные о взаимодействии заказчика с продуктом.
Если признаки меняются не слишком часто, их можно вычислять пакетами. Но в таких сценариях использования ML-модели, вроде ожидаемого времени доставки еды, мы имеем дело с быстро меняющимися признаками, которые надо вычислять в реальном времени — например, среднюю длительность доставки из конкретного ресторана за последние X минут.
Для этого нужно создать по крайней мере один микросервис-конструктор признаков, который извлекал бы признаки для пакета входных данных на основе их ID. Возможно, вам понадобится и микросервис-конструктор признаков в реальном времени, но цена такого удовольствия — усложнение ML-системы.
Конструкторы признаков могут направлять запросы в разные базы данных и по-разному собирать и обрабатывать полученное. У них могут быть параметры, например, количество минут, влияющие на производительность моделей.
6. Оркестратор (Orchestrator)
Рабочий процесс
Оркестратор — это сердцевина ML-системы, взаимодействующая со многими другими компонентами. Вот этапы его пайплайна:
- Извлечь, трансформировать, загрузить и разбить необработанные данные в датасеты для обучения, валидации и тестирования.
- Отправить датасеты для обучения, валидации или тестирования для конструирования признаков, если нужно.
- Подготовить датасеты для обучения, валидации или тестирования с выбранными атрибутами.
- Отправить в билдер моделей URI-адреса подготовленных датасетов для обучения или валидации вместе с метриками для оптимизации.
- Получить оптимальную модель, применить тестовый датасет и отправить прогнозы в модуль оценки.
- Получить значение производительности и решить, нужно ли отправлять модель на сервер, например, для канареечной выкатки на продакшн-данных.
При подготовке датасетов могут быть варианты:
- Дополнить данные для обучения. Например, oversample или undersample; или перевернуть, отразить или обрезать изображения.
- Предварительно обработать датасеты для обучения, валидации или тестирования с очисткой данных. Так их можно беспроблемно использовать для моделирования или прогнозирования. Подготовить данные с учетом решаемой задачи, например, уменьшить насыщенность и изменить размер изображений.
Подходы к организации рабочего процесса
Весь рабочий процесс можно организовать вручную. Но если нужно часто обновлять модели или совместно настраивать параметры признаков и администратора моделей — рабочий процесс придется автоматизировать. Его можно внедрить как простой скрипт и запускать на одном потоке, однако при параллельном выполнении вычисления будут эффективнее.
В комплексных ML-платформах такая возможность предусмотрена — это единая среда, позволяющая определять и запускать полные ML-пайплайны. Например, Google AI Platform можно использовать с продуктами по работе с данными Google Cloud: Dataprep (инструмент Trifacta для первичной обработки данных), Dataflow (инструмент упрощенной потоковой и пакетной обработки данных), BigQuery (бессерверное облачное хранилище данных). Можно определить приложение для обучения на основе алгоритмов TensorFlow или встроенных алгоритмов (например, XGBoost). Для обработки важных данных часто выбирают Spark. У разработчика Spark, компании Databricks, также есть комплексная платформа.
Есть и альтернативный подход: каждый этап рабочего процесса можно запускать на отдельной платформе или вычислительной среде. Один из вариантов — выполнение этих этапов в разных контейнерах Docker. Kubernetes — одна из наиболее популярных у ML-специалистов open-source систем оркестрации контейнеров.
Kubeflow и Seldon Core — это Open Source-инструменты, которые позволяют пользователям описывать ML-пайплайны и превращать их в кластеризированные приложения Kubernetes. Это можно сделать в локальной среде, запустив приложение на локально установленном кластере Kubernetes или облачной платформе. Другой Open Source-инструмент для управления рабочим процессом — это Apache Airflow, разработанный компанией Airbnb. Airflow — популярный инструмент координации общих ИТ-задач, в том числе машинного обучения. Он поддерживает интеграцию с Kubernetes.
Активное обучение для продвинутых рабочих процессов
Экспертам иногда нужен доступ к модулю разметки данных, где ему покажут входные данные и попросят их разметить. Эти метки хранятся в базе и будут доступны для использования оркестратором с датасетами для обучения, валидации или тестирования. Какие данные представить для разметки: определить вручную или запрограммировать в оркестраторе? Для этого можно посмотреть на входные продакшн-данные, когда модель была правильной, но неуверенной. Или где она была очень уверенной, но сработала неправильно. Это и есть основа «активного обучения».
7. Билдер моделей (Model Builder)
Билдер моделей отвечает за создание оптимальных моделей. Для этого он обучает разные модели на обучающем датасете и оценивает по указанным метрикам на датасете для валидации, чтобы оценить, являются ли модели оптимальными. Обратите внимание: это аналог примера OptiML, который мы рассматривали в предыдущей статье:
$ curl <a href="https://bigml.io/optiml?$BIGML_AUTH">https://bigml.io/optiml?$BIGML_AUTH</a> -d '{"dataset": "<training_dataset_id>", "test_dataset": "<test_dataset_id>", "metric": "area_under_roc_curve", "max_training_time": 3600 }'В BigML модель автоматически становится доступной в API. На других платформах ML-разработки, возможно, придется упаковать ее, сохранить в файл и подождать, пока сервер моделей его загрузит.
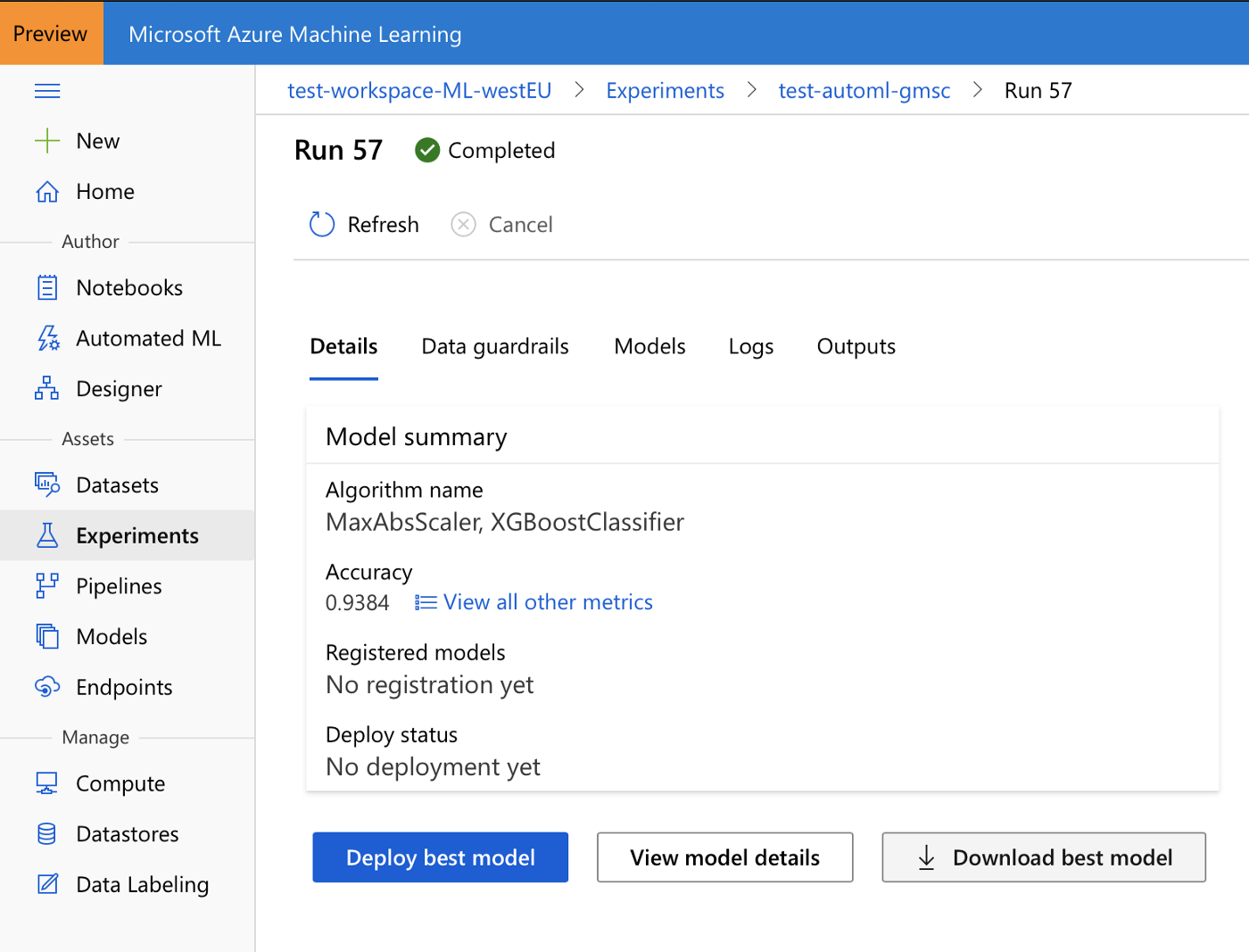
Результат эксперимента «Автоматизированное машинное обучение» на Azure ML. Можно загрузить лучшую из найденных моделей или развернуть ее на Azure
Если вы используете другую платформу ML-разработки или обходитесь вообще без платформы, имеет смысл проектировать систему так, чтобы модели автоматически создавались выделенным сервисом. Он будет принимать датасеты для обучения и валидации и метрики производительности для оптимизации.
8. Сервер моделей (Model Server)
Задача сервера моделей — обрабатывать API-запросы на прогнозирование для конкретной модели. Для этого он:
- Загружает представление модели, сохраненное в файле.
- Применяет его с помощью интерпретатора ко входным данным, обнаруженным в API-запросе.
- Выдает прогнозы в ответе API.
Сервер должен поддерживать параллельную обработку нескольких API-запросов и обновление моделей.
Приведем в качестве примера запрос и ответ для модели анализа тональности высказываний, где в качестве входных данных применяется всего один текстовый признак:
$ curl <a href="https://mydomain.com/sentiment">https://mydomain.com/sentiment</a>
-H 'X-ApiKey: MY_API_KEY'
-d '{"input": "I love this series of articles on ML platforms"}'
{"prediction": 0.90827194878055087}Существуют разные представления модели, например, ONNX и PMML. Другой стандартный подход — сохранять в файле устойчивое состояние моделей, существующих как объекты в вычислительной среде. Для этого нужно сохранить представление вычислительной среды, в частности, ее зависимостей, чтобы объектную модель можно было создать снова. В этом случае «интерпретатор» модели представляет собой всего лишь
model.predict(new_input).9. Frontend
Frontend решает множество задач:
-
Упрощает выходные данные модели. Например, превращает список вероятностей классов в наиболее вероятный класс.
-
Добавляет информацию к выходным данным модели. Например, предоставляет объяснение прогноза с помощью модуля объяснения модели «черный ящик» (как у Indico).
-
Внедряет логику для конкретной области. Например, принятие решения на основе прогнозов или резервное действие при получении аномальных входных данных.
-
Отправляет входные рабочие данные и прогнозы модели на хранение в продакшн-базу данных.
-
Тестирует новые модели, в том числе формулируя запросы к прогнозам из них (в дополнение к live-моделям) и сохраняя их. Так модуль мониторинга сможет построить метрики производительности этих новых пробных моделей за определенный период времени.
Управление жизненным циклом модели
Если на тестовом датасете новая пробная модель демонстрирует производительность лучше, чем текущая, можно протестировать ее фактическое влияние на приложение, получив прогноз этой модели в frontend для малой доли конечных пользователей нашего приложения («канареечная выкатка»).
Для этого нужно, чтобы модуль оценки и модуль мониторинга работали с метриками производительности, характеризующими это приложение. Для теста пользователей можно взять из списка или выбрать по одному из атрибутов или вообще произвольно.
Если в результате мониторинга производительности становится ясно, что новая модель ничего не ломает, разработчики могут постепенно увеличить пропорцию тестовых пользователей и выполнить A/B-тестирование, сравнив новую и старую модель. Если окажется, что новая модель все-таки лучше, frontend просто «заменяет» старую модель, в обязательном порядке возвращая прогнозы новой модели. Если новая модель не работает как надо, через frontend можно ее откатить.
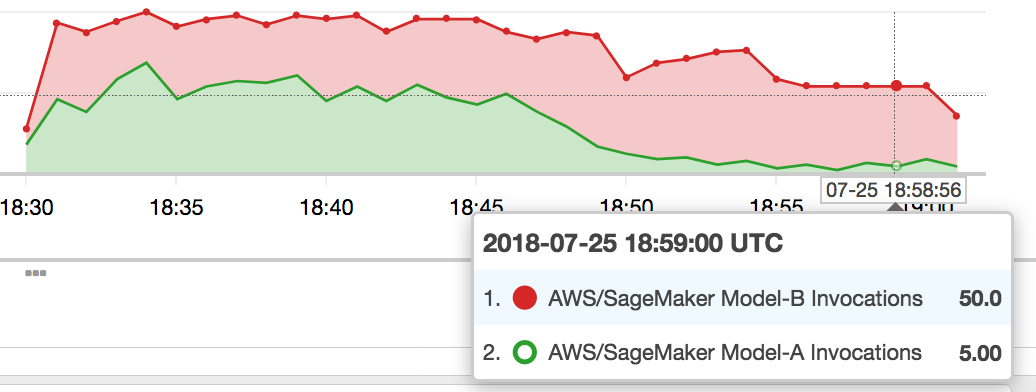
Постепенно направляем трафик на модель B и замещаем модель A (Источник)
Команда VK Cloud Solutions тоже развивает собственные Big Data-решения. Вы можете их протестировать — для этого мы начисляем новым пользователям 3 000 бонусных рублей.
OzymandiasMelancholia
Это не совсем так, например в TensorFlow Lite на данный момент есть возможность тренировать модель прямо на устройстве, см. On-Device Training with TensorFlow Lite в документации.