
Привет, Хабр! Меня зовут Максим Солопин, в Росбанке я работаю архитектором корпоративного хранилища данных. В этом посте я расскажу о том, как мы переезжали из data lake, куда ежедневно сваливались все сырые данные, в удобную систему на основе Greenplum. А по дороге немного затрону развитие моделей корпоративных хранилищ данных.
К началу проекта в банке было целых 3 КХД, 5 песочниц, 7 BI серверов и 0 golden source, на основе которых несколько лет развивался data lake. Загрузки там дублировались, и чтобы избежать этого, мы решили брать сырые данные из Hadoop.
Но это лишь принесло новые проблемы. Данные грузились медленно, подтягивались не из всех источников в банке (сейчас их более 50). Самописный фреймворк загрузки был сырым, нужен был мониторинг, поддержка и, соответственно, огромное количество ресурсов на это всё и также на разработку.
Затем в начала 2021 года мы решили создать свой первый Golden Source на основе Greenplum. Работала над миграцией наша core-команда, развивающая ритейл-песочницу банка. Greenplum мы выбрали по нескольким причинам: масштабируемость, скорость, умеренная стоимость, совместимость с Hadoop, возможность подключить максимально разнообразные источники в рамках универсальной модели данных.
С моделей данных я и начну подробный рассказ.
Как устроены корпоративные хранилища данных
Классическим подходом к хранению данных в компании считается концепция Data Warehouse (DWH), история которой началась в далеком 1990 году, когда американский ученый Билл Инмон опубликовал книгу «Building the Data Warehouse». Инмон выделял четыре ключевых свойства DWH:
Subject-oriented – все элементы данных в базе, относящиеся к одному и тому же реальному событию или объекту, связаны друг с другом; при этом хранилище данных содержит информацию о конкретном предмете, таком как продукт, клиент, продажи и т.д.
Time-variant – изменения данных в базе отслеживаются и записываются, чтобы можно было создавать отчеты по изменениям с течением времени.
Non-volatile – данные в базе никогда не перезаписываются и не удаляются; после фиксации они становятся статическими, доступными только для чтения и в таком виде сохраняются для будущих отчетов;
Integrated – база содержит данные из большинства или всех операционных приложений организации, и эти данные согласованы.
Несколько иного подхода придерживался оппонент Инмона Ральф Кимбалл и корпорация Microsoft. Они акцентировали внимание на витринах данных, то есть на срезах хранилища данных, представляющих собой массив тематической, узконаправленной информации. Для покупателей такой подход был более привлекательным — продавать витрины с быстрыми и эффектными отчетами легче, чем погружать в сложные процессы создания хранилища.
Создание DWH было более долгим, затратным, и в подходе Инмона витрины появлялись лишь на финальной стадии. Но и подход группы Кимбалла менялся со временем.
DWH работают по методу ETL – Extract, Transform и Load. Это означает, что данные подготавливаются и загружаются в хранилище на регулярной основе, скажем, раз в месяц. Загрузка занимает много времени, и часто на это время хранилище приходится закрывать для использования, что плохо.
Корпоративные хранилища со временем эволюционировали, что привело к появлению концепции Data Lake. Озера данных используют подход ELT – Extract, Load и Transform. Сырые данные сразу же загружаются в хранилище, а затем в фоновом режиме преобразуются и продвигаются от слоя к слою вплоть до последнего слоя витрин данных.
Преимущества Data Lake в том, что здесь нет тяжеловесного этапа подготовки данных и хранилище не нужно закрывать на время обновления. Для финтеха постоянная доступность является критически важной. Кроме того, специалисты по данным и машинному обучению могут использовать данные сразу по мере поступления.
Модель данных в Росбанке
Наша модель данных, основанная на методологии Билла Инмона, была уже обкатана. У нас были выделены основные сущности, такие как клиенты, счета, договора, проводки, балансы и т.д.
Каждая таблица может иметь таблицу-расширение. Например, для таблицы договора расширением может быть таблица-расширение её кредитного договора. В нее уже попадают атрибуты, которые не вписались в таблицу договора. Также у любой таблицы может быть таблица %_property. В нее выносят атрибуты, по которым, например, нужна историчность или не хочется создавать таблицу-расширение, поскольку таких атрибутов мало.
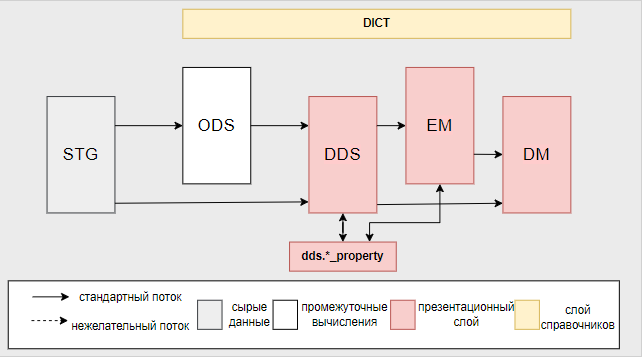
Так организованы потоки данных в нашем хранилище. Поясню некоторые элементы:
STG — слой, содержащий сырые ext-таблицы. Отдельного ELT-потока в GP нет, таблицы только подключаются к Hadoop.
ODS — слой для накопления истории из слоя STG по нужным атрибутам. Используется редко, так как историю сырых данных мы не копим.
DDS — содержит детальные данные по основным сущностям.
EM — содержит витрины с агрегированными показателями базовых сущностей: клиентский портфель, портфель HR, кредитные и депозитные портфели и т.д.
DM — витрины с рассчитанными агрегатами, сложными расчетами атрибутов. Этот слой содержит общие витрины для всех департаментов. Только на его основе далее формируются отчеты. Также есть отдельные DM-слои под конкретные бизнес направления.
DICT – слой справочников.
Справочники могут загружаться вручную, могут наполняться из файлов, могут затягиваться из систем-источников: с MDS, через API и т. д.
Расскажу немного о параллельной работе над двумя хранилищами. Для работы над новым хранилищем мы задействовали команду старого, и ребятам приходилось одновременно поддерживать оба. Бизнес всегда на первом месте, поэтому приоритеты часто менялись, и на новое хранилище временами не хватало рук. Разработку на старом хранилище мы не заморозили, и в итоге у нас несколько расходилась логика с новым; пришлось потратить много ресурсов, чтобы его доделать.
Помогло нам то, что мы позволили активно развивать хранилище любым другим командам разработчиков. Для этого все они должны придерживаться нашей установленной модели данных и стандартов проектирования. И в команде должен быть хотя бы один лидер, который будет эти стандарты валидировать, обучать людей, отвечать на вопросы по архитектуре модели. Несколько раз в неделю эти лидеры собираются на архитектурные митапы, где обсуждают возникающие проблемы и вопросы, задаются новые правила, стандарты и т. д.
Таким образом мы исключили проблемы с большим бэклогом на одной команде.
Оркестрация загрузок
Оркестрация потоков идет в airflow, и для нас это был новый инструмент. Все загрузки Hadoop, которые шли раньше в cron, мы перевели в airflow. Для этого был сделан генератор дагов, который автоматически формирует задачи по загрузке таблиц из источников.
Затем мы сделали такой же генератор для запуска sql-функций на GP. Там зависимости не такие линейные, и выглядит в airflow это уже не так красиво:
Сейчас идет пилот по переходу на Gitlab + Gitlab CI, и в ближайшее время мы перейдем на автоматизацию процесса поставок кода. Пока же весь код в БД попадает только через Bitbucket, в ручном режиме после апрува пулл-реквеста.
Загрузчик реплик в БД
В начале статьи я упоминал наш фреймворк для загрузки данных. Расскажу о нем отдельно. Универсальный загрузчик создает реплики таблиц из БД систем-источников (DB2, Oracle, MSSQL, PostgeSQL, Pervasive), а также актуализирует реплики на указанную дату. Загрузчик обеспечивает накопление истории изменений таблиц в Hadoop в структуре Slow Changing Dimension type 2 (маркировка версий записей полями DT_FROM, DT_TO), причем на неограниченную глубину.
Список входной информации загрузчика выглядит так:
batch-версия — read-only таблицы в системах-источниках, подключение через JDBC);
CDC-версия — файлы данных в виде changelog, полученных в результате работы CDC (в формате JSON, Parquet или ORC);
файлы конфигурации и метаданные (описание таблицы).
А это выходная информация:
таблица-реплика в Hive с возможностью хранения истории изменений;
журналы работы в YARN и в базе метаданных.
Загрузчик поддерживает автоматическую репликацию DDL — изменение структуры таблицы в Hive после изменения DDL на источнике. Для batch-загрузки доступна проверка на дубликаты по ключу с отбрасыванием дублей в reject-таблицу. Для CDC-загрузки возможно игнорирование полных дубликатов во входных данных (если был выполнен CDC-refresh без удаления старых файлов), а также операций Update/Delete по несуществующим ключам.
Загрузчик пока что имеет некоторые ограничения, связанные с загрузкой колонок таблиц, совместимостью и функциональностью для репликации DDL.
Итоги
Миграция первой песочницы прошла успешно. Сейчас на основе новых данных у нас ежедневно рассылается мотивация сотрудникам. К середине года будет завершена полная миграция и параллельно другие команды начинают миграцию остальных хранилищ банка.
Главный урок, который мы получили во время проекта: мы сами должны понимать, что хотим, сами выстраивать нужную архитектуру и модель, а не полагаться на вендоров. И у нас должны быть ресурсы, которые всё это поддерживают.
Sunchezzz
Какую в итоге сборку гринплама используете?
MaximSolopin Автор
Мы выбрали дистрибутив от arenadata, сейчас используем достаточно свежую версию 6.20.3