
Туториалы делятся на две больших категории: либо "как нарисовать сову", либо подробно расписанные тысячи шагов в формате "напиши туториал для дурака - и только дурак захочет его читать".
К какой из двух категорий относится эта статья — решать вам.
В этой статье вы увидите пошаговое создание cloud-native микросервиса на Amazon AWS, пригодное для "чтения с листа". Чтобы понять, что здесь происходит, не нужно разворачивать проект - достаточно обладать живым воображением и прочитать текст по диагонали. Если же вы всё-таки захотите повторить шаги, вам будут жизненно нужны знания вида, как создавать классы в IDE и что такое Spring.
Вначале мы напишем пару простых микросервисов на Spring Boot, докеризуем их, зальём в AWS, настроим красивые доменные имена и HTTPS, прикрутим логирование и мониторинг, Prometheus и Grafana. Это небольшое путешествие по всем кругам ада, из которого вы не вернетесь прежним.
Текст написан на основе текстов и демо-проекта microservice-customer за авторством @kamaruzzaman. Если вы потеряли нить повествования, всегда можно зайти на GitHub и найти весь код в пригодном для запуска виде. Если захочется закопаться в тему, то бро Дима Чуйко (@Teapot) написал вам ещё две части статьи "Микросервисы: от CRUD до Native Image" (раз, два).
Последняя важная оговорка. В этом гайде будут использоваться технологии Amazon и обычные дистрибутивы OpenJDK. Автор осознает, что мы живём в России, и возможно, вместо Amazon куда лучше подойдет что-то вроде SberCloud или MTS Cloud, а вместо обычного OpenJDK - Axiom JDK с сертификацией по ФСТЭК. Особенности российских технологий - тема для отдельной статьи. Если вы захотите таковую после чтения этого гайда - отметьтесь в комментариях.
Часть 1. Пишем код микросервисов
Выбираем технологии
Какую выбрать Java? Многие всё ещё используют Oracle JDK и не осознали, что он имеет определенные лицензионные проблемы. К счастью, у нас есть множество альтернативных дистрибутивов OpenJDK, которые мы и будем использовать. Все они на 100% совместимы со стандартом, и всё такое прочее, т.е. годятся для серьезного продакшена. Версию Java не имеет смысла брать ниже 11 — новые версии куда лучше годятся для облачного использования.
Какие выбрать фреймворки? Сейчас есть куча отличных технологий, которые не стыдно использовать на проде - Spring (Pivotal), MicroProfile (Eclipse), Quarkus (RedHat), Micronaut (Object Computing), и другие.
Имхо, рынок сейчас устроен так, что Spring задоминировал совершенно всех. Если Quarkus и Micronaut воспринимаются как смелые эксперименты, то Spring давно зарекомендовал себя как "дефолтная" Java-технология, с тех самых пор как JavaEE начала трещать по швам. Можно считать это Spring-шовинизмом, но писать туториал сразу по всему зоопарку технологий - задача непосильная.
Наверное, немного грустно собирать проект из исключительно дефолтных технологий, но хей - именно это обычно и нужно в реальной жизни. Что-то, что действительно будет работать и не сломается на полпути.
Генерация проекта
Очевидно, что разработать свою копию Амазона или Нетфликса было бы эпической задачей, совершенно не подходящей под формат Хабра. Вместо этого мы соберем какой-то небольшой магазинчик на микросервисной архитектуре. Бэкенд будет без фронтенда, как это модно сейчас говорить - headless. Это отличное слово для оправдания своей лени, запомните и никогда не забывайте. В отсутствие интерфейса, тестировать будем через HTTP API, то есть, через curl или Postman.
Мы напишем микросервисы Customer и Order, и каждый из них будет делать одну свою маленькую задачу, как и положено в соответствии с канонами микросервисной архитектуры, да и хорошей архитектуры вообще (single responsibility principle).
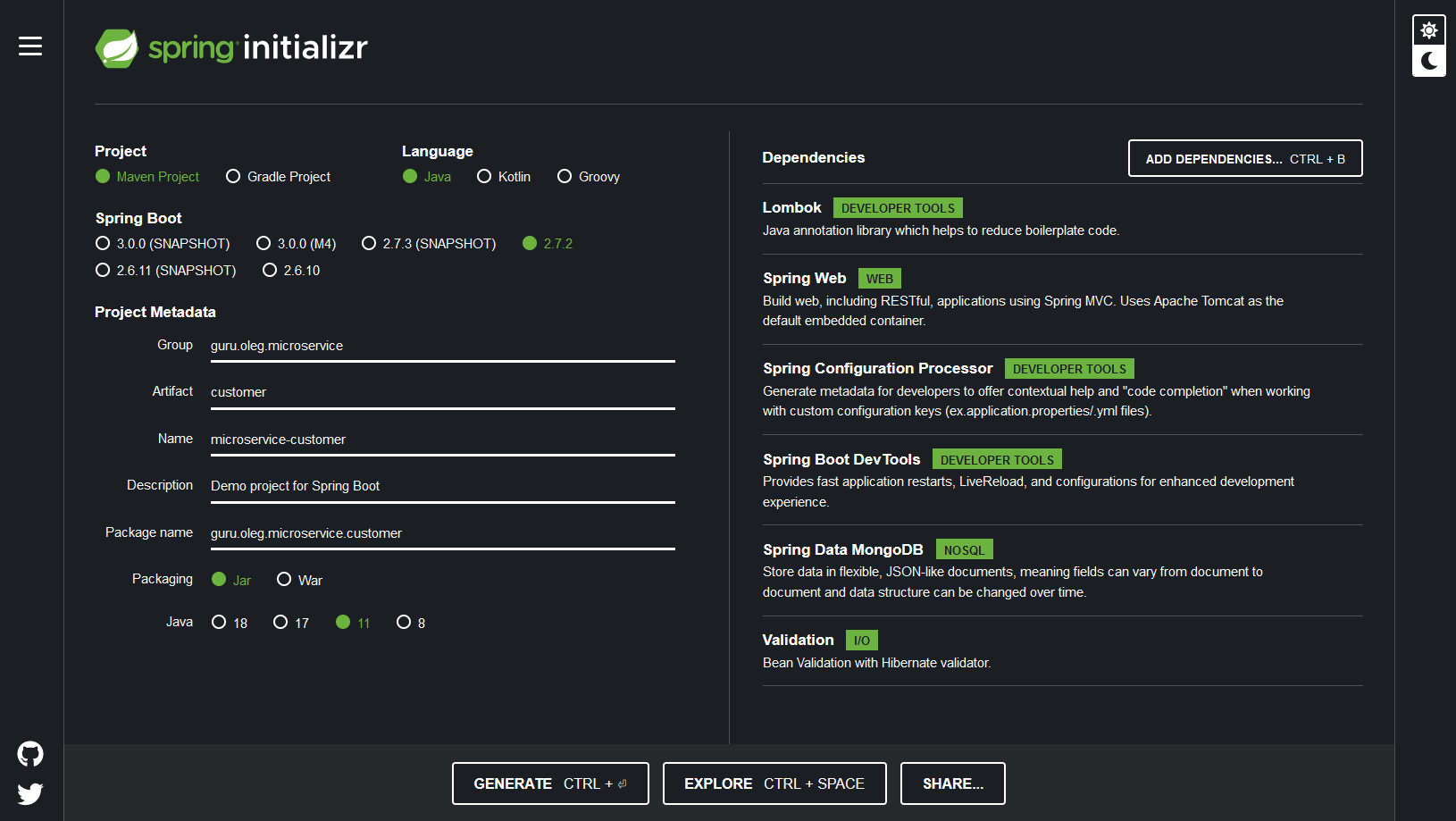
Во-первых, давайте создадим проект Spring Boot с нужными зависимостями. Для этого есть совершенно стандартная для Spring веб-утилита Spring Initializr.
Что нам важно:
Project: Gradle или Maven (лучше Gradle)
Language: Java
Spring Boot: 2.4.2 (ну или какая там будет доступна, они меняются)
Project Metadata: любые какие понравятся
Packaging: JAR
Java: 11
-
Dependencies:
Lombok
Spring Web
Spring Configuration Processor
Spring Boot DevTools
Spring Data MongoDB
Validation
Микросервис Order
Сущность Order
Проект разделен на несколько пакетов, как и положено в соответствии с Domain-Driven Design. Классы домена - это POJO (простые Java-объекты), которые вместе составляют API модели данных. Эти POJO могут пригодиться для хранения данных в MongoDB: их преимущество в том, что не нужно лепить несколько слоёв DTO (data transfer objects) для того, чтобы замапить сущности REST на базу данных.
Вот как выглядит POJO для микросервиса Order:
@Document(collection = "order")
@Getter
@Setter
@ToString
@NoArgsConstructor
public class Order implements Serializable {
private static final long serialVersionUID = 1L;
@Id
private String id;
@NotBlank
@Field("customer_id")
private String customerId;
@Field("created_at")
@CreatedDate
private Instant createdAt;
@Field("updated_at")
@LastModifiedDate
private Instant updatedAt;
@Version
public Integer version;
@Field("status")
private OrderStatus status = OrderStatus.CREATED;
@Field("payment_status")
private Boolean paymentStatus = Boolean.FALSE;
@NotNull
@Field("payment_method")
private PaymentType paymentMethod;
@NotNull
@Field("payment_details")
private String paymentDetails;
@Field("shipping_address")
private Address shippingAddress;
@Field("products")
@NotEmpty
private Set<@Valid Product> products;
Я предлагаю сразу использовать Lombok , чтобы не писать обычный шаблонный код, за который так хейтят Java. Геттеры, сеттеры, toString, hashCode, equals. Мы же хотим, чтобы микросервисы у нас получились модные и молодежные? В любом случае, я решил использовать Lombok, туториал — не место для демократии :-)
Автоматический аудит заказов будет производиться с помощью аннотаций @CreatedDate, @LastModifiedDate и @Version.
Микросервис Order у нас состоит всего из одной коллекции, и все ее сущности (продукты, адреса, итп) стоит встроить прямо в эту коллекцию, а не хранить отдельно.
Репозиторий
В качестве базы данных я выбрал MongoDB. Существует поверие, что Mongo - ужасная база данных, которая ни на что не годна. Ирония в том, что она идеально подходит для коротких туториалов. Deal with it.
В MongoDB есть два способа работать с базой. Первый - использовать Java Driver, который поддерживает нативный, низкоуровневый API базы. Второй и более простой вариант - использовать Spring Data MongoDB. Spring Data - это проект и инициатива сообщества Spring, целью которой является унификация доступа к различным хранилищам (SQL, NoSQL, и т.п.). И она тоже поддерживает идею Domain-Driven Design. В этой демке, мы будем использовать Spring Data MongoDB чтобы упростить разработку и понимание текста.
Чтобы работать с сохранением заказов в базу, нужно создать всего один интерфейс:
@Repository
public interface OrderRepository extends MongoRepository<Order, String> {
}
Контроллеры
Наша микросервисная архитектура выставляет наружу API, которое клиент или какой-то другой микросервис может использовать чтобы общаться с помощью REST. Spring MVC поддерживает паттерн написания контроллеров, которые выставляют наружу REST API, и делается это буквально в несколько строчек.
Для большинства приложений, хорошая практика - заводить эндпоинт /health , с помощью которого можно проверить, что приложение действительно запустилось и работает. Кроме того, его можно использовать в Kubernetes, чтобы посылать heartbeat-запросы.
Для начала, создадим класс Health:
@Data
@NoArgsConstructor
@EqualsAndHashCode
@ToString
public class Health {
private HealthStatus status;
}
И дополняющий его класс HealthStatus:
@RestController
@RequestMapping("/api/v1")
public class HealthStatus {
private final Logger log = LoggerFactory.getLogger(HealthResource.class);
@GetMapping(
value = "/health",
produces = "application/json")
public ResponseEntity<Health> getHealth() {
log.debug("REST request to get the Health Status");
final var health = new Health();
health.setStatus(HealthStatus.UP);
return ResponseEntity.ok().body(health);
}
}
Для микросервиса Order, эндпоинты сервиса определяются в классе OrderResource , который предоставляет REST API для всех CRUD операций, относящихся к заказам. Для простоты, сейчас сделаем только один метод, createOrder (POST request).
@RestController
@RequestMapping("/api/v1")
public class OrderResource {
private final Logger log = LoggerFactory.getLogger(OrderResource.class);
private static final String ENTITY_NAME = "order";
@Value("${spring.application.name}")
private String applicationName;
private final OrderRepository orderRepository;
private final OrderService orderService;
public OrderResource(OrderRepository orderRepository, OrderService orderService) {
this.orderRepository = orderRepository;
this.orderService = orderService;
}
@PostMapping("/orders")
@Transactional
public ResponseEntity<Order> createOrder(@Valid @RequestBody Order order) throws URISyntaxException {
log.debug("REST request to save Order : {}", order);
if (order.getId() != null) {
throw new ResponseStatusException(HttpStatus.CONFLICT, "A new order cannot already have an ID");
}
final var result = orderRepository.save(order);
orderService.createOrder(result);
HttpHeaders headers = new HttpHeaders();
String message = String.format("A new %s is created with identifier %s", ENTITY_NAME, result.getId().toString());
headers.add("X-" + applicationName + "-alert", message);
headers.add("X-" + applicationName + "-params", result.getId().toString());
return ResponseEntity.created(new URI("/api/orders/" + result.getId())).headers(headers).body(result);
}
}
Последний штрих — добавить файлы конфигурации (application.yml, index.html) и один класс ApplicationConfiguration.
@Configuration
public class ApplicationConfiguration {
@Bean
public RestTemplate restTemplate(RestTemplateBuilder builder) {
return builder.build();
}
}
index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Order Microservice</title>
</head>
<body>
<h1>Welcome to the Order Microservice</h1>
<p> Current Time:
<script> document.write(new Date().toLocaleTimeString()); </script>
</p>
<p>The order endpoints are <a href="/order/api/v1/orders">here</a></p>
</body>
</html>
application.yml в директории src/main/resources:
spring:
application:
name: microservice-order
microservice-customer:
url: https://customer.microservicesdemo.net/customer/api/v1/
data:
mongodb:
uri: mongodb+srv://mkmongouser:Secret_Password@cluster0.yu4x6.mongodb.net
database: order
server:
port: 8080
servlet:
context-path: /order
application.yml в директории src/main/local:
spring:
application:
name: microservice-order
microservice-customer:
url: http://localhost:8080/customer/api/v1/
devtools:
restart:
enabled: true
data:
mongodb:
uri: mongodb://localhost:27017
database: order
server:
port: 8080
servlet:
context-path: /order
Микросервис Customer
Во-первых, классы ApplicationConfiguration, Health, HealthStatus и HealthResource совершенно идентичны предыдущему микросервису Order, поэтому их можно и нужно просто скопипастить.
А вот список сущностей мы будем использовать другой:
@Document(collection = "customer")
@Data
@NoArgsConstructor
public class Customer implements Serializable {
private static final long serialVersionUID = 1L;
@Id
private String id;
@Field("orders")
private Set<Order> orders = new HashSet<>();
public Customer addOrder(Order order) {
this.orders.add(order);
return this;
}
}
@Getter
@Setter
@ToString
@NoArgsConstructor
public class Order implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@NotBlank
private String id;
@NotBlank
private String customerId;
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
Order order = (Order) o;
return id.equals(order.id);
}
@Override
public int hashCode() {
return Objects.hash(id);
}
}
Дальше нужно сделать CustomerRepository по аналогии с OrderRepository:
@Repository
public interface CustomerRepository extends MongoRepository<Customer, String> {
}
Эндпоинты сервиса определяются в классе CustomerResource, и предоставляют REST API для всех CRUD операций, связанных с клиентами.
@RestController
@RequestMapping("/api/v1")
public class CustomerResource {
private final Logger log = LoggerFactory.getLogger(CustomerResource.class);
private static final String ENTITY_NAME = "customer";
@Value("${spring.application.name}")
private String applicationName;
private final CustomerRepository customerRepository;
public CustomerResource(CustomerRepository customerRepository) {
this.customerRepository = customerRepository;
}
@PostMapping("/customers")
public ResponseEntity<Customer> createCustomer(@Valid @RequestBody Customer customer) throws URISyntaxException {
log.debug("REST request to save Customer : {}", customer);
if (customer.getId() != null) {
throw new ResponseStatusException(HttpStatus.CONFLICT, "A new customer cannot already have an ID");
}
final var result = customerRepository.save(customer);
HttpHeaders headers = new HttpHeaders();
String message = String.format("A new %s is created with identifier %s", ENTITY_NAME, customer.getId());
headers.add("X-" + applicationName + "-alert", message);
headers.add("X-" + applicationName + "-params", customer.getId());
return ResponseEntity.created(new URI("/api/customers/" + result.getId())).headers(headers).body(result);
}
}
Кроме того, нужно создать CustomerOrderResource, который предоставит REST API для связи между Customer и Order.
@RestController
@RequestMapping("/api/v1")
public class CustomerOrderResource {
private final Logger log = LoggerFactory.getLogger(CustomerOrderResource.class);
private static final String ENTITY_NAME = "order";
@Value("${spring.application.name}")
private String applicationName;
private final CustomerRepository customerRepository;
public CustomerOrderResource(CustomerRepository customerRepository) {
this.customerRepository = customerRepository;
}
@PostMapping("/customerOrders/{customerId}")
public ResponseEntity<Order> createOrder(@PathVariable String customerId, @Valid @RequestBody Order order) {
log.debug("REST request to save Order : {} for Customer ID: {}", order, customerId);
if (customerId.isBlank()) {
throw new ResponseStatusException(
HttpStatus.NOT_FOUND, "No Customer: " + ENTITY_NAME);
}
final Optional<Customer> customerOptional = customerRepository.findById(customerId);
if (customerOptional.isPresent()) {
final var customer = customerOptional.get();
customer.addOrder(order);
customerRepository.save(customer);
return ResponseEntity.ok()
.body(order);
} else {
throw new ResponseStatusException(HttpStatus.BAD_REQUEST, "Invalid Customer: " + ENTITY_NAME);
}
}
}
Ну и традиционно, файлы конфигурации:
index.html:
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Customer Microservice</title>
</head>
<body>
<h1>Welcome to the Customer Microservice</h1>
<p> Current Time:
<script> document.write(new Date().toLocaleTimeString()); </script>
</p>
<p>The customer endpoints are <a href="/customer/api/v1/customers">here</a></p>
<p>The customer-order endpoints are <a href="/customer/api/v1/customerOrders">here</a></p>
</body>
</html>
application.yml в src/main/local:
spring:
application:
name: microservice-customer
devtools:
restart:
enabled: true
data:
mongodb:
uri: mongodb://localhost:27017
database: customer
server:
port: 8080
servlet:
context-path: /customer
application.yml в src/main/resources:
spring:
application:
name: microservice-customer
data:
mongodb:
uri: mongodb+srv://mkmongouser:Secret_Password@cluster0.yu4x6.mongodb.net
database: customer
server:
port: 8080
servlet:
context-path: /customer
Сервисы
В Spring принято хранить бизнес-логику внутри сервисного слоя. Логику синхронизации Customer и Order придется положить в микросервис Order в таком виде:
@Service
@Slf4j
public class OrderService {
private final Logger log = LoggerFactory.getLogger(OrderService.class);
@Autowired
RestTemplate restTemplate;
@Autowired
ObjectMapper objectMapper;
@Value("${spring.application.microservice-customer.url}")
private String customerBaseUrl;
private static final String CUSTOMER_ORDER_URL = "customerOrders/";
public void createOrder(Order order) {
final var url = customerBaseUrl + CUSTOMER_ORDER_URL + order.getCustomerId();
final var headers = new HttpHeaders();
headers.setContentType(MediaType.APPLICATION_JSON);
log.info("Order Request URL: {}", url);
try {
final var request = new HttpEntity<>(order, headers);
final var responseEntity = restTemplate.postForEntity(url, request, Order.class);
if (responseEntity.getStatusCode().isError()) {
log.error("For Order ID: {}, error response: {} is received to create Order in Customer Microservice",
order.getId(),
responseEntity.getStatusCode().getReasonPhrase());
throw new ResponseStatusException(HttpStatus.INTERNAL_SERVER_ERROR, String.format("For Order UUID: %s, Customer Microservice Message: %s", order.getId(), responseEntity.getStatusCodeValue()));
}
if (responseEntity.hasBody()) {
log.error("Order From Response: {}", responseEntity.getBody().getId());
}
} catch (Exception e) {
log.error("For Order ID: {}, cannot create Order in Customer Microservice for reason: {}", order.getId(), ExceptionUtils.getRootCauseMessage(e));
throw new ResponseStatusException(HttpStatus.BAD_REQUEST, String.format("For Order UUID: %s, Customer Microservice Response: %d", order.getId(), ExceptionUtils.getRootCauseMessage(e)));
}
}
}
Промежуточные итоги первой части
Что мы сейчас имеем на руках? Мы примерно осознали, чем будем заниматься (делать микросервис на Spring Boot и Mongo), написали базовые сущности (Controller, Service, Repository, Entity). Код должен компилироваться без ошибок.
Часть 2. Контейнеризация микросервисов
Инфраструктура Cloud-Native
Прелесть микросервисной архитектуры в том, что микросервисы можно писать сразу на многих языках программирования и нескольких разношерстных технологиях, даже внутри одного проекта. Строго говоря, обсуждая облачную инфраструктуру, нужно всегда задаваться вопросом: а как мы будем писать в ней на нескольких языках сразу? Тем не менее, многоязычные проекты всё ещё не стали золотым стандартом индустрии (хотя и применяются активно в известных конторах типа Netflix). Поэтому, для простоты будем здесь и дальше считать, что пишем всё на Java.
Чтобы развернуть наше приложение в облаке, нужно построить инфраструктуру, в которой участвуют Docker и Kubernetes. Docker позволяет упаковать приложение и всю его уйму зависимостей в контейнер. Этот контейнер запускать в разных средах, поддерживая безопасную и изолированную среду внутри него.
Другие преимущества контейнеров:
Возможность частичного обновления отдельных участков кода, без необходимости останавливать всё приложение;
Многослойные образы, которые можно переиспользовать для создания новых контейнеров;
Автоматическое развертывание;
Возможность откатываться до предыдущей версии образа.
Минутка рекламы закончена. В этот момент вы должны понять, что Docker — это хорошо, а если не поняли — закрыть статью, отформатировать свой жесткий диск и пойти мести крыши.
Spring Boot предоставляет Cloud-Native Buildpack , который генерирует докерный образ из проекта Spring Boot. Если вы живете в экосистеме Spring, то ваше приложение уже автоматически на полпути в облако.
Один из способов разворачивать приложения Spring Boot или отдельные микросервисы в AWS — создавать докерные контейнеры в формате OCI, использовать Amazon ECR в качестве облачного докерного реестра, Amazon EKS в качестве облачного Kubernetes.
Другой способ — использовать AWS Elastic Beanstalk, который предоставляет Platform as a Service (PaaS) для развертывания веб-приложений в облаке AWS, так что это легко масштабировать и настраивать. В этом гайде мы об этом говорить не станем.
К сожалению, в короткой демке не затронуть всех аспектов жизни в облаках, типа CI/CD, классического JavaEE подхода с помощью MicroProfile, построения распределенных систем, и тому подобного. В голове всё это нужно держать, но сейчас сконцентрируемся на контейнеризации.
Контейнеризация
Вначале нужно установить Docker на компьютер. Процесс этот сильно отличается на разных операционных системах и состоит из множества шагов, поэтому нужно последовать советам из официальной документации.
Микросервисы для упаковки у нас уже есть. Теперь, как построить образы Docker? Теоретически, можно написать свой Dockerfile. Минус в том, что для этого нужно неплохо разбираться в Docker и прочих контейнерных технологиях. Но мы не хотим разбираться, хотим раз-два и в продакшен. Для этого у нас есть Cloud Native Buildpacks , которые умеют превращать исходники в OCI-совместимые Docker-образы без необходимости писать Dockerfile вручную.
(Если вы на самом деле хотите разобраться с вопросом: нормально ли ничего не знать о Docker и генерить всё билдпаками, то обязательно ходите на конференции JUG Ru Group. Например, на JPoint был отличный доклад "Не клади все яйца в один buildpack" Дмитрия Чуйко, запись доступна на YouTube).
Чтобы собрать образ микросервиса Customer, достаточно пройти в его корневую директорию и выполнить команду:
./mvnw spring-boot:build-image
Если вам больше нравится Gradle, то команда будет другая:
./gradlew bootBuildImage
Эта команда собирает образ на основе файла конфигурации Spring. В нашей демке, образ микросервиса Customer будет называться как-то так: docker.io/library/microservice-customer:1.0.0
Точно такй же командой собирается и микросервис Order: docker.io/library/microservice-order:1.0.0
Запустить их можно, использовав это имя:
docker run -d -p 8080:8080 docker.io/library/microservice-customer:1.0.0
Посмотреть, что микросервис запустился, можно на стандартном адресе: http://localhost:8080.
Если контейнер успешно запустился, вы увидите идентификатор этого контейнера в консоли. В вашем случае он будет другой, все идентификаторы уникальны:
c1c3925595047ff5744507dd0abc05b1063f7dc884c3e2a4c9864633a2780d2b
Посмотреть логи контейнера можно с помощью следующей команды:
docker logs c1c3925595047ff5744507dd0abc05b1063f7dc884c3e2a4c9864633a2780d2b
И вы увидите там нечто вроде:
2021-03-03 22:01:21.116 INFO 1 --- [ngodb.net:27017] org.mongodb.driver.cluster : Setting max set version to 2 from replica set primary clustermicroservice-shard-00-01.fzatn.mongodb.net:27017
2021-03-03 22:01:21.116 INFO 1 --- [ngodb.net:27017] org.mongodb.driver.cluster : Discovered replica set primary clustermicroservice-shard-00-01.fzatn.mongodb.net:27017
2021-03-03 22:01:21.184 INFO 1 --- [ main] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService 'applicationTaskExecutor'
2021-03-03 22:01:21.240 INFO 1 --- [ main] o.s.b.a.w.s.WelcomePageHandlerMapping : Adding welcome page: class path resource [static/index.html]
2021-03-03 22:01:21.383 INFO 1 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer
Важно отметить, что именно форвардинг портов (-p 8080) позволяет нам соединяться с нашими сервисами снаружи контейнера, например - с локального компьютера. Можно вписать туда и другую цифру, 8080 просто имеет какое-то ритуальное значение для джавистов.
Теперь становится возможно проверить статус контейнера через GET запрос. Сделать запрос можно разными способами, для простоты пусть это будет curl в консоли:
curl --location --request GET 'http://localhost:8080/customer/api/v1/health'
Вот такой результат мы ожидаем:
< {"status":"UP"}
Чтобы остановить контейнер, нужно выполнить docker stop с указанием идентификатора останавливаемого контейнера:
docker stop c1c3925595047ff5744507dd0abc05b1063f7dc884c3e2a4c9864633a2780d2b
Промежуточные итоги второй части
Мы создали два микросервиса, научились упаковывать их в контейнеры и запускать на своем локальном компьютере. Следующий вопрос - как запустить их в облаке?
Часть 3. Запускаем микросервисы в облаке
Развертывание на Amazon AWS
Для публикации контейнеров мы воспользуемся Amazon ECR. Это Docker Registry, который позволяет хранить, распространять и развертывать контейнеры в облаке AWS.
Вначале, нужно установить и настроить утилиты командной строки AWS CLI на вашем компьютере. Конкретные шаги описаны в официальной инструкции. Я не скопировал их в эту статью исключительно из гуманистических соображений: пара таких инструкций, и Хабр превратится в чертов инсталлятор.
Теперь, для каждого микросервиса нужно создать соответствующий репозиторий в ECR. Важно, чтобы имя репозитория в точности соответствовало названию имени контейнерного образа.
aws ecr create-repository --repository-name microservice-customer
Эта команда создаст репозиторий для микросервиса Order, и должна распечатать вот такой выхлоп:
{
"repository": {
"repositoryArn": "arn:aws:ecr:eu-central-1:877546708265:repository/microservice-customer",
"registryId": "877546708265",
"repositoryName": "microservice-customer",
"repositoryUri": "877546708265.dkr.ecr.eu-central-1.amazonaws.com/microservice-customer",
"createdAt": "2021-03-04T00:18:33+01:00",
"imageTagMutability": "MUTABLE",
"imageScanningConfiguration": {
"scanOnPush": false
},
"encryptionConfiguration": {
"encryptionType": "AES256"
}
}
}
К нашему локально лежащему образу нужно привязать тэг, в котором описан реестр ECR и репозиторий. Вначале нужно взять идентификатор докерного образа для микросервиса Order, и посмотреть о нём полную информацию:
docker image ls microservice-customer:1.0.0
Ожидаемый выхлоп:
REPOSITORY TAG IMAGE ID CREATED SIZE
microservice-customer 1.0.0 652da8e2130b 41 years ago 274MB
Теперь, создаем тэг, указывая ECR и репозиторий:
docker tag 652da8e2130b 877546708265.dkr.ecr.eu-central-1.amazonaws.com/microservice-customer:1.0.0
Для публикации образа в ECR, нужно залогиниться. Этот логин продержится 12 часов, после чего придётся перезайти заново.
aws ecr get-login-password --region eu-central-1 | docker login --username AWS --password-stdin 877546708265.dkr.ecr.eu-central-1.amazonaws.com
Ожидаемый выхлоп:
WARNING! Your password will be stored unencrypted in /home/$USER_NAME/.docker/config.json.
Configure a credential helper to remove this warning. See
https://docs.docker.com/engine/reference/commandline/login/#credentials-store
Login Succeeded
Теперь можно запушить образ в AWS ECR:
docker push 877546708265.dkr.ecr.eu-central-1.amazonaws.com/microservice-order:1.0.0
Скорость загрузки зависит от того, насколько быстрый у вас интернет. Это может занять несколько минут, за которые можно вскипятить чаю и поесть.
После загрузки, неплохо сходить в веб-интерфейс и проверить, что всё получилось:
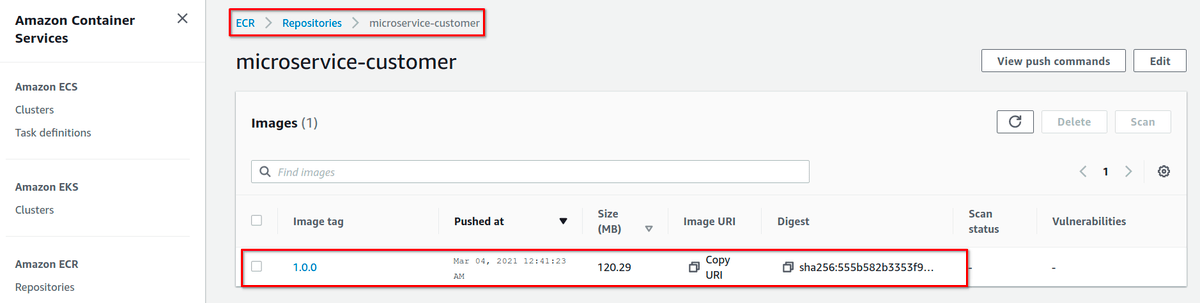
Но самая главная проверка, конечно же, делается не глазами. Давайте попробуем запуллить образ:
docker pull 877546708265.dkr.ecr.eu-central-1.amazonaws.com/microservice-customer:1.0.0
Если вся предыдущие шаги были выполнены правильно, мы увидим долгожданный ответ:
1.0.0: Pulling from microservice-customer
Digest: sha256:555b582b3353f9657ee6f28b35923c8d43b5b5d4ab486db896539da51b4f971a
Status: Image is up to date for 877546708265.dkr.ecr.eu-central-1.amazonaws.com/microservice-customer:1.0.0
877546708265.dkr.ecr.eu-central-1.amazonaws.com/microservice-customer:1.0.0
Развертывание на EKS
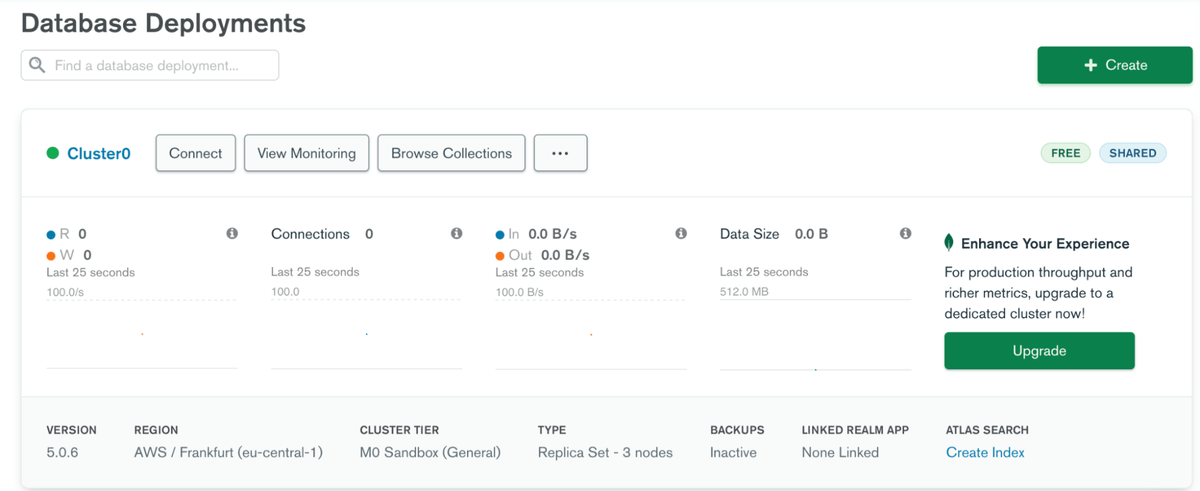
Нашим микросервисам нужна база данных, без них они не заработают. Поэтому, нужно развернуть на Амазоне кластер MongoDB. Зарегистрируйтесь на MongoDB Atlas. После регистрации, создайте бесплатный Shared cluster, выберите cloud provider (AWS) и какой-нибудь регион поближе, и жмите кнопку "Create Cluster". Если не знаете, какой регион выбрать - берите Франкфурт, не ошибётесь. Дальше нужно создать пользователя, указав логин и пароль. Как только кластер создастся, вы увидите такое:
Теперь, нужно сгенерировать строчку для соединения с кластером, которую мы пропишем в микросервисы. Нажмите кнопку "Connect", выберите "Connect your application". Важно: строка для подключения зависит от вашего языка программирования и версии MongoDB. Там будут какие-то инструкции, их все нужно выполнить.
Развертывание Docker-контейнера
Kubernetes (или, для краткости, Куб) — стандарт индустрии для инфраструктурной оркестрации. Он изначально разработан в Google, выложен в опенсорс, и сейчас разрабатывается всем миром. Он помогает в разворачивании, масштабировании и управлении контейнеризованными приложениями.
Если вас это зачем-то интересует, то Kubernetes отлично работает на Docker Desktop, у него в поставке есть сервер и клиент. Не то чтобы это действительно нужно было делать.
К сожалению, Kubernetes требует кучу сисадминской работы. Если хочется только программировать и оставить админскую работу админам, лучше использовать облачные решения, т. е. Managed Kubernetes. Для cloud-native разработки, воспользуемся Amazon Elastic Kubernetes Service (EKS). Он позволяет запускать и масштабировать приложения как в облаке AWS Cloud, так и on-perm на локальном железе.
Установите утилиты для командной строки: eksctl для управления кластером EKS, и kubectl для Kubernetes.
Теперь можно создать кластер EKS, используя команду eksctl:
eksctl create cluster \
--name microservices \
--region eu-central-1 \
--node-type t2.small \
--nodes 2
Эта команда создаёт два воркера типа "t2.small" в регионе "eu-central-1", с именем "microservice".
Где-то там глубоко в кишках, для создания кластера, eksctl использует CloudFormation. Это занимает минут 10-15, поэтому вы снова сможете вскипятить чаю и поесть. Используя облака, вы никогда не умрёте с голоду на рабочем месте. В любом, случае, вот такой в конце концов вас ждет выхлоп:
[✔] saved kubeconfig as "/home/<user>/.kube/config"
[ℹ] no tasks
[✔] all EKS cluster resources for "microservices" have been created
[ℹ] adding identity "arn:aws:iam::877546708265:role/eksctl-microservices-nodegroup-ng-NodeInstanceRole-9PQCLZR7NSYS" to auth ConfigMap
[ℹ] nodegroup "ng-3e8fb16c" has 0 node(s)
[ℹ] waiting for at least 2 node(s) to become ready in "ng-3e8fb16c"
[ℹ] nodegroup "ng-3e8fb16c" has 2 node(s)
[ℹ] node "ip-192-168-77-195.eu-central-1.compute.internal" is ready
[ℹ] node "ip-192-168-9-13.eu-central-1.compute.internal" is ready
[ℹ] kubectl command should work with "/home/<user>/.kube/config", try 'kubectl get nodes'
[✔] EKS cluster "microservices" in "eu-central-1" region is ready
По выхлопу видно, что у нас создалось две ноды и одна группа. Кроме того, конфиг теперь лежит в ./.kube/config. Если у вас уже есть minikube или microk8s, нужно дописывать этот ./.kube/config в качестве параметра --kubeconfig:
После того, как прошла целая вечность и кластер создался, можно проверить его статус командой:
kubectl get nodes --kubeconfig ~/.kube/config
Ожидаемый выхлоп:
NAME STATUS ROLES AGE VERSION
ip-192-168-77-195.eu-central-1.compute.internal Ready <none> 10m v1.18.9-eks-d1db3c
ip-192-168-9-13.eu-central-1.compute.internal Ready <none> 10m v1.18.9-eks-d1db3c
Двигаемся дальше. Создадим конфиг развертывания:
apiVersion: apps/v1
kind: Deployment
metadata:
name: microservice-deployment
labels:
app: microservice-customer
spec:
replicas: 1
selector:
matchLabels:
app: microservice-customer
template:
metadata:
labels:
app: microservice-customer
spec:
containers:
- name: microservice-customer-container
image: 877546708265.dkr.ecr.eu-central-1.amazonaws.com/microservice-customer:1.0.0
ports:
- containerPort: 8080
Теперь, скормим его kubectl, чтобы развернуть приложение в Kubernetes:
kubectl apply -f eks-deployment.yaml --kubeconfig ~/.kube/config
Ожидаемый выхлоп:
deployment.apps/microservice-deployment created
Проверим, что всё запустилось:
kubectl get pods --kubeconfig ~/.kube/config
Ожидаемый выхлоп:
NAME READY STATUS RESTARTS AGE
microservice-deployment-597bd7749b-wcfsz 1/1 Running 0 13m
Для пущей уверенности, можно проверить лог пода:
kubectl logs microservice-deployment-597bd7749b-wcfsz --kubeconfig ~/.kube/config
Ожидаемый выхлоп:
2021-03-04 00:09:50.848 INFO 1 --- [ngodb.net:27017] org.mongodb.driver.cluster : Discovered replica set primary clustermicroservice-shard-00-01.fzatn.mongodb.net:27017
2021-03-04 00:09:52.778 INFO 1 --- [ main] o.s.s.concurrent.ThreadPoolTaskExecutor : Initializing ExecutorService 'applicationTaskExecutor'
2021-03-04 00:09:53.088 INFO 1 --- [ main] o.s.b.a.w.s.WelcomePageHandlerMapping : Adding welcome page: class path resource [static/index.html]
2021-03-04 00:09:53.547 INFO 1 --- [ main] o.s.b.w.embedded.tomcat.TomcatWebServer : Tomcat started on port(s): 8080 (http) with context path '/customer'
2021-03-04 00:09:54.602 INFO 1 --- [ main] o.m.m.customer.CustomerApplication
По логу видно, что микросервис не только запустился на порту 8080, но и подключился к MongoDB Atlas.
Несмотря на то, что микросервис корректно развернулся в EKS, снаружи до него достучаться невозможно. Нужно создать Kubernetes Service Controller, который выставит наружу IP-адрес, по которому к развернутым приложениям можно будет обратиться из внешнего мира. Вот как определить сервис:
apiVersion: v1
kind: Service
metadata:
name: microservice-customer-service
spec:
#Creating a service of type load balancer. Load balancer gets created but takes time to reflect
type: LoadBalancer
selector:
app: microservice-customer
ports:
- protocol: TCP
port: 80
targetPort: 8080
Заметьте, что targetPort должен совпадать со значением containerPort, которое определено в файле развертывания (в нашем случае, ритуальное 8080).
Теперь можно развернуть сервис в AWS:
kubectl apply -f eks-service.yaml --kubeconfig ~/.kube/config
Ожидаемый выхлоп:
service/microservice-customer-service created
Сервис привязан к Elastic Load Balancer (ELB) в AWS. Теперь можно проверить, что лежит на внешнем IP-адресе:
kubectl get svc --kubeconfig ~/.kube/config
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
Kubernetes ClusterIP 10.100.0.1 <none> 443/TCP 39m
microservice-customer-service LoadBalancer 10.100.94.75 aa62f80b9596a4fa6835d80a506227d6-1183908486.eu-central-1.elb.amazonaws.com 80:32248/TCP 21s
Судя по выхлопу, балансировщик находится вот на этом внешнем адресе: aa62f80b9596a4fa6835d80a506227d6-1183908486.eu-central-1.elb.amazonaws.com
Конечно же, можно сходить и в веб-интерфейс:

Заметьте, что DNS имя в ELB — точно такое же, как у внешнего IP-адреса, который мы получили ранее.
Если открыть этот адрес в браузере, то мы увидим веб-страничку нашего микросервиса:

Аналогично, можно развернуть микросервис Order. Просто повторить шаги, перечисленные выше: создать докерный образ, опубликовать его в ECR, развернуть в EKS.
Конечно, вначале, нужно пописать эндпоинт микросервиса Customer в application.yml микросервиса Order:
spring:
application:
name: microservice-order
microservice-customer:
url: http://aa62f80b9596a4fa6835d80a506227d6-1183908486.eu-central-1.elb.amazonaws.com/customer/api/v1/
data:
mongodb:
uri: mongodb+srv://mkmongouser:<Password>@clustermicroservice.fzatn.mongodb.net
database: order
server:
port: 8080
servlet:
context-path: /order
Все остальные шаги совершенно те же самые.
Избавляемся от облачных ресурсов
Использовать Amazon ECS далеко не дешево. Там и сама инфраструктура EKS (мастер-узел), и воркеры, и балансировщики, и группа узлов. В продакшене они крутились бы круглосуточно, но если вы изучаете вопрос по туториалам, стоит вовремя избавляться от ненужного балласта.
К счастью, делается это предельно просто:
eksctl delete cluster --name microservices
Промежуточные итоги третьей части
Миссия практически выполнена: мы развернули контейнеры в Kubernetes и EKS.
Но это ещё не предел мечтаний. У микросервисов уродливые DNS имена, трафик ходит без HTTPS, логирования никакого нет. Это не очень похоже на прод.
Часть 4. Безопасность, мониторинг и красивые имена
Доменные имена
Amazon Route 53 — это высокоустойчивый, масштабируемый облачный DNS. В дополнение к классическим возможностям DNS-роутинга, он позволяет регистрировать домены и проверять живость сервисов.
Конечно же, можно использовать какой-то другой провайдер DNS. В этом гайде мы воспользуемся именно Amazon Route 53, потому что это просто и удобно.
Вначале, откройте вкладку "Route 53" и выберите “Register domain":
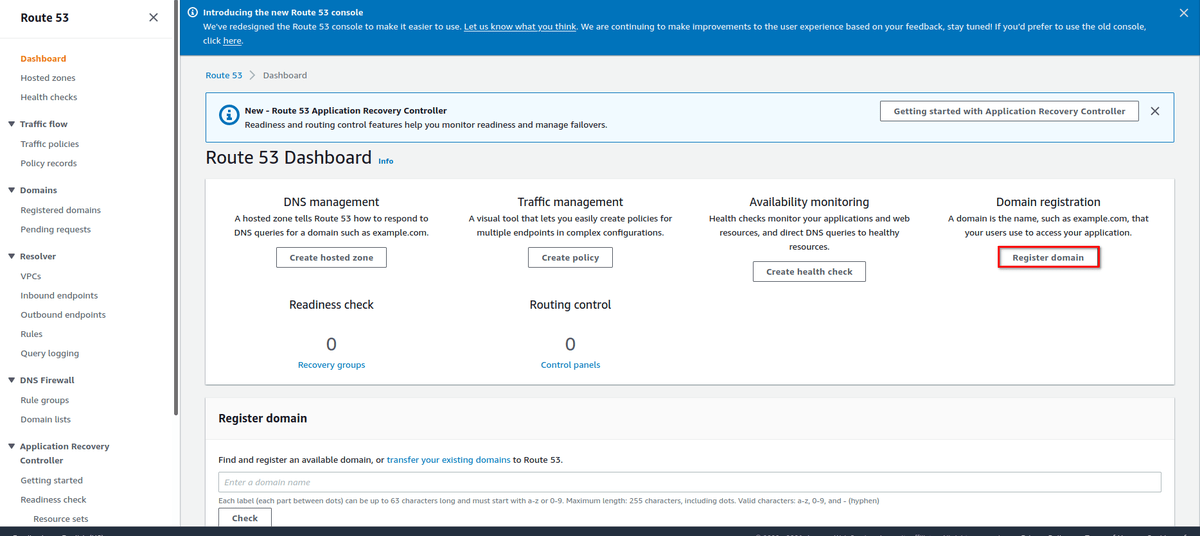
Например, можно выбрать имя “microservicesdemo”. Сразу после этого отображаются другие домены с именем “microservicesdemo”. На момент регистрации, microservicesdemo.net было свободно и стоило около 11 американских USD в год.

Дальше вам предлагают вписать разные дополнительные сведения, необходимые для завершения регистрации. Сразу после этого, домен отправляется на регистрацию.

После регистрации имени, Route 53 автоматически настраивает DNS для зарегистрированного домена. Кроме того, создается "Hosted zone", с таким же именем, как и у зарегистрированного домена.
Нам нужно два субдомена для двух микросервисов, трафик с них нужно отправить на балансировщик. Для этого создадим рекорды внутри "Hosted zone":

В поле ”Routing policy” нужно выбрать “Simple routing”.
В разделе “Configure record”, нужно создать “Simple record” для микросервиса Customer, сконфигурить его доменное имя, и отправить трафик на балансировщик:
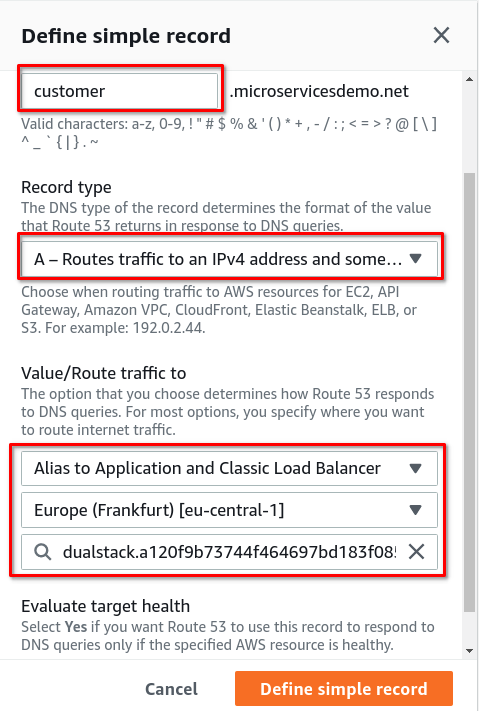
В награду за старания, микросервис Customer теперь доступен по новому имени:

Route 53 DNS Service перенаправляет трафик с субдоменов на балансировщик.
Теперь, нужно повторить все те же самые шаги и сконфигурировать микросервис Order.
Безопасность (HTTPS)
Для любого более-менее энтерпрайзного приложения подразумевается, что трафик ходит через TLS 1.2+. Весь трафик между браузером пользователя и балансировщиком - терминируется TLS (точнее, шифруется и дешифруется по HTTPS). Заметьте, что соединения между балансировщиком и подами шифровать не нужно:

Чтобы управлять сертификатами SSL/TLS у нас есть Amazon Certificate Manager, который мы и заиспользуем на балансировщике.
Откройте Amazon Certificate Manager и найдите раздел с публичными сертификатами:
Дальше нужно запросить сертификат:
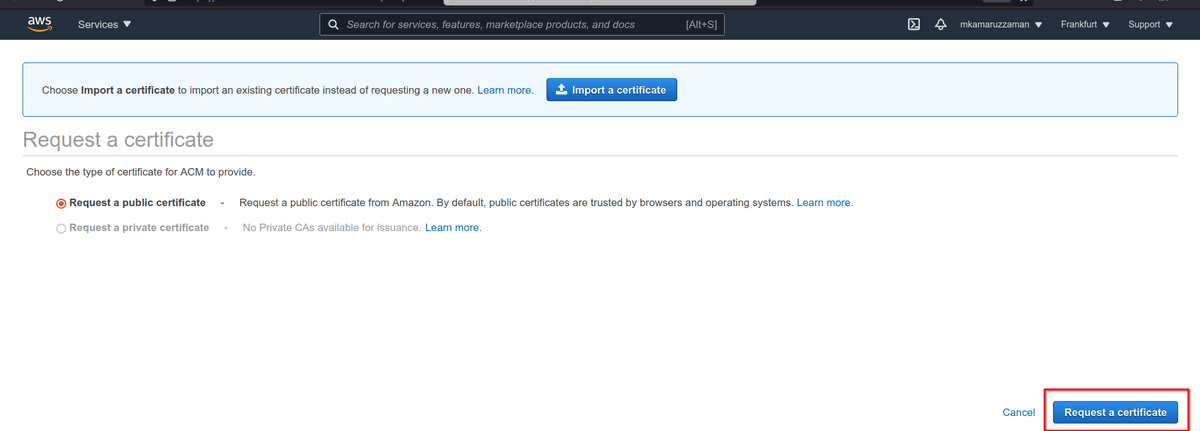
На следующей странице указываем домен:

AWS хочет удостовериться, что домен принадлежит именно нам. Самое простое — выбрать вариант “DNS validation”, раз уж мы всё равно копаемся в админке DNS.

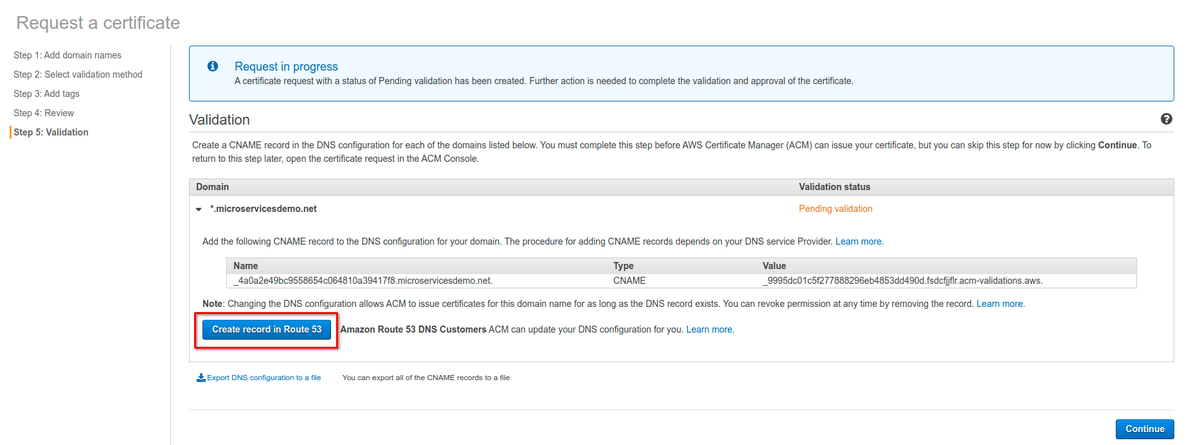
Теперь мы видим DNS-запись CNAME, которую нужно добавить в конфигурацию домена.
Можно сделать это автоматически, прожав кнопку “Create record in Route 53”. (Ценители могут мучиться с конфигом DNS самостоятельно).
Как только сертификат появится, мы увидим вот такой экран:
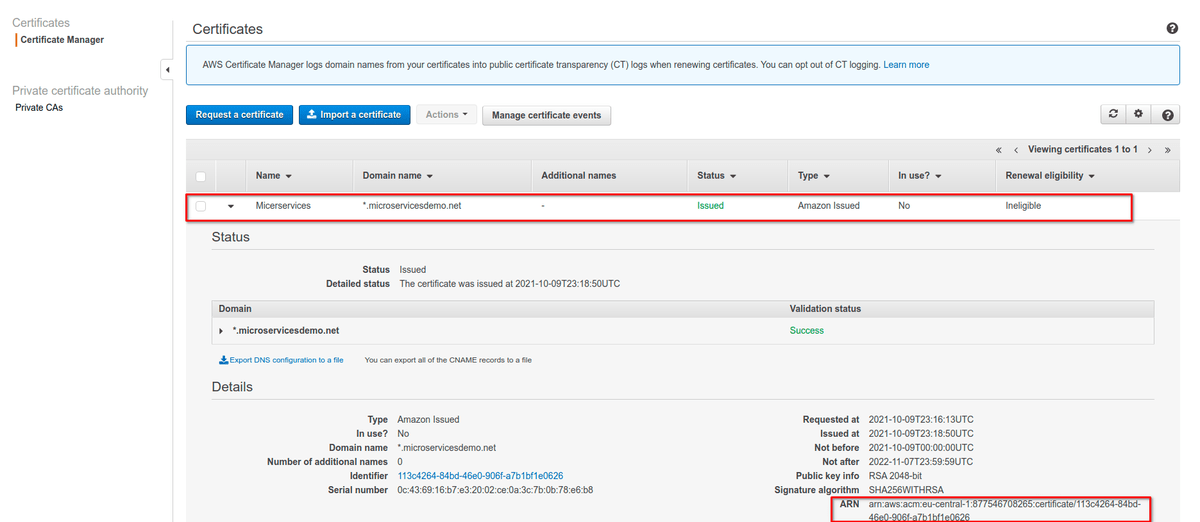
Что мы здесь видим? Статус сертификата — "issued", то есть он корректно выдан AWS. Интерфейс показывает "no" в поле "in use", потому что мы еще не настраивали использование сертификата.
Теперь, нужно терминировать SSL/TLS на балансировщике. Еще раз напомню, что соединение между балансером и подами зашифровано не будет.
Вначале нужно сделать Load Balancer Service “eks-service-tls.yaml” в директории “src/main/k8s”:
apiVersion: v1
kind: Service
metadata:
name: microservice-customer-service
annotations:
service.beta.kubernetes.io/aws-load-balancer-ssl-cert: arn:aws:acm:eu-central-1:877546708265:certificate/113c4264-84bd-46e0-906f-a7b1bf1e0626
service.beta.kubernetes.io/aws-load-balancer-backend-protocol: http
spec:
#Creating a service of type load balancer. Load balancer gets created but takes time to reflect
type: LoadBalancer
selector:
app: microservice-customer
ports:
- protocol: TCP
port: 443
targetPort: 8080
По сравнению с конфигом из предыдущей части, произошли некоторые изменения.
Аннотациями мы сконфигурировали сертификаты, только что выданные в ACM:
annotations:
service.beta.kubernetes.io/aws-load-balancer-ssl-cert: arn:aws:acm:eu-central-1:877546708265:certificate/113c4264-84bd-46e0-906f-a7b1bf1e0626
service.beta.kubernetes.io/aws-load-balancer-backend-protocol: http
Ещё, мы явно определили, что протоколом на бэкенде будет http. Чтобы получить заголовок “X-Forwarded-Proto” мы установили “service.beta.kubernetes.io/aws-load-balancer-backend-protocol” в значение "http".
Ну и порт поменяли на “443”, потому что https.
Теперь можно пройти на страничку микросервиса Customer прямо из браузера: https://customer.microservicesdemo.net/customer

На скриншоте можно увидеть значок "замка" рядом с URL, который означает, что мы используем защищенное соединение. Если щелкнуть по "замку", то мы увидим подробную информацию о только что выданном сертификате SSL/TLS (в том числе то, что он выдан Amazon, дата выдачи - сейчас, и тому подобное).
Все те же самые шаги нужно сделать для микросервиса Order.
Логирование через Fluent Bit
Логирование — неотъемлемая часть разработки и эксплуатации. Для продакшена же оно совершенно необходимо. В ходе логирования мы собираем как можно больше полезных данных о том, как работает приложение, и о всех важных событиях. Примеры, зачем это нужно:
Если приложение сломалось, мы можем проанализировать логи и найти корень проблемы;
Если в приложении закрался баг, по логам мы можем воспроизвести проблему;
Если необходимо понять, как работает приложение.
В нашем демо-проекте мы тоже пишем логи. Но как их собрать и проанализировать?
Есть много способов экспортировать логи наружу. Их можено писать в файлы, собирать с помощью специальных API, выливать в STDOUT на консоль, использовать какие-то коллекторы...
Согласно идеям twelve factor apps, которые являются золотым стандартом современной разработки, приложение не должно само писать в файлы или коллекторы. Вместо этого, приложение складывает логи в небуферизованный STDOUT, как в поток ивентов. В случае разработки на локальной машине, программисты имеют возможность видеть этот поток ивентов прямо в своей консоли.
На стейджинге или проде, логи собираются средой исполнения. Роутеры и коллекторы логов собирают и отправляют их в какое-то определенное место конечного хранения (например, базу данных или файл), где их можно складировать и анализировать.
В нашем демо-проекте из двух микросервисов, мы последуем путями “12 factor apps logging”: сгенерируем лог как поток событий, который поймают поды Kubernetes, отправим его в коллектор и анализатор, а в качестве места последнего упокоения заиспользуем Amazon Cloud Watch.
На рынке существует куча разных коллекторов логов. Чаще всего используют вендор-нейтральный Fluentd. Он заслужил определенную славу в последние годы, из-за своих лёгких, но довольно функцинальных фичей. Более того, Fluent Bit, в первую очередь, предназначен именно для работы с контейнерами.
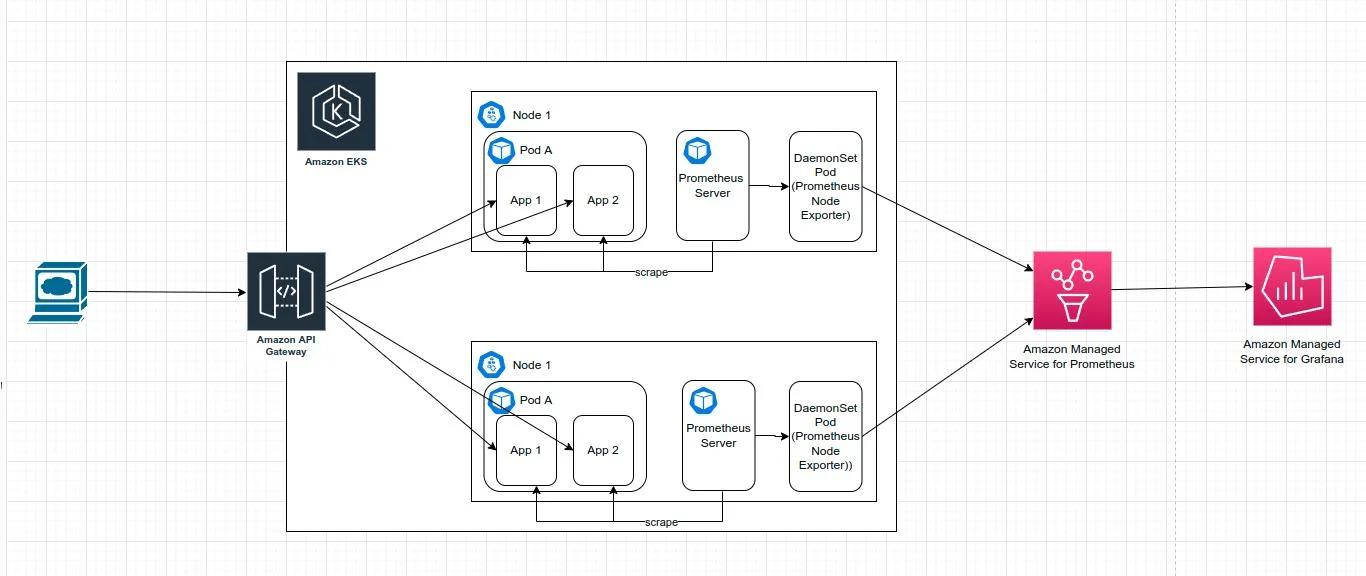
Для нашего демо-проекта, мы заиспользуем Fluent Bit, чтобы собрать данные из подов. Для дальнейшего анализа пригодится Amazon CloudWatch Container Insights. Вот примерная схема используемых компонентов:
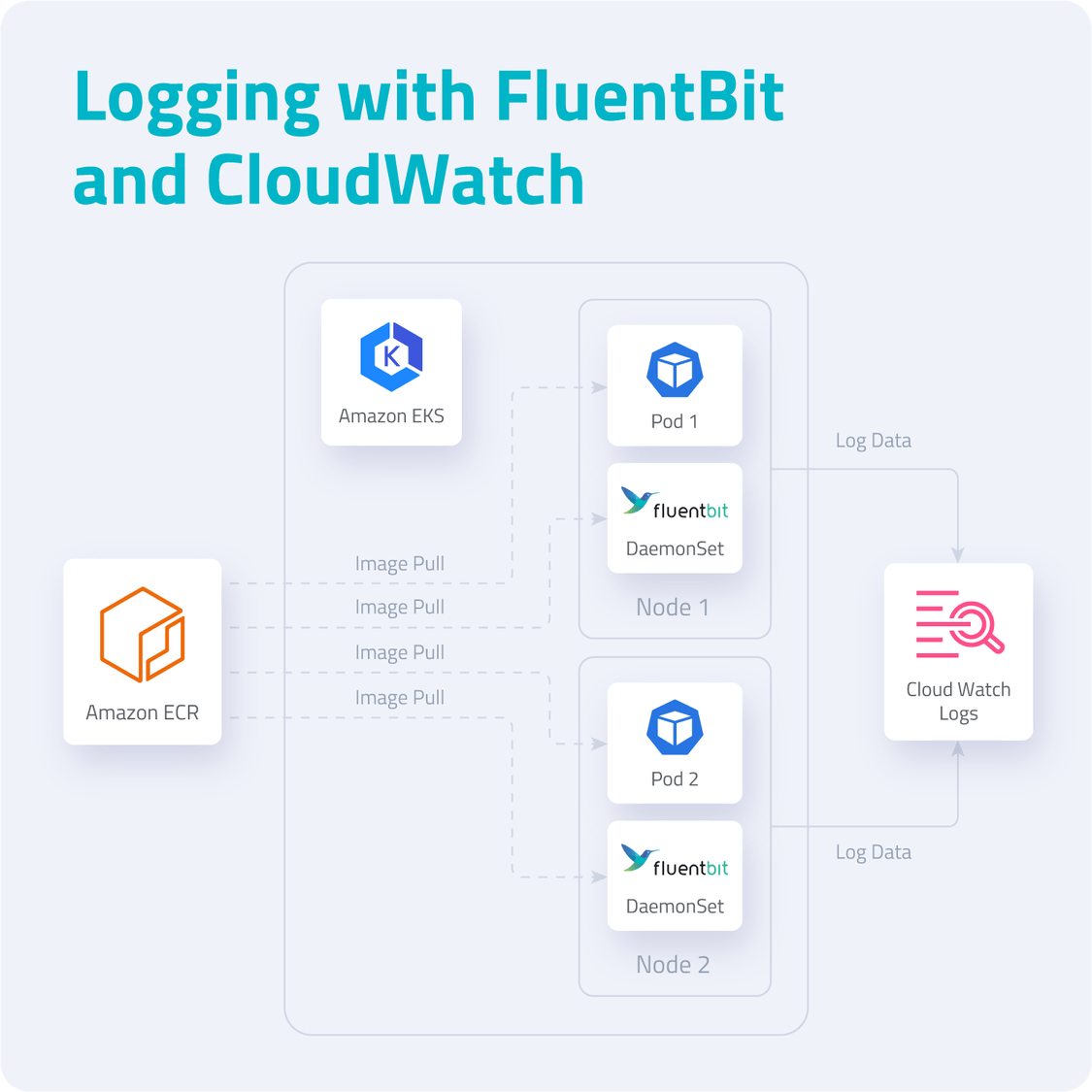
Fluent Bit — это опенсорсный процессор и форвардер логов, который позволяет собирать всевозможные данные (например, метрики и логи) из различных источников, фильтровать и отправлять их по нескольким направлениям, включая CloudWatch. Это очевидное решение для контейнерных технологий, в том числе, для Kubernetes. Архитектура Fluent Bit создана с расчетом на высокую производительность. Для этого она написана на Си и позволяет работать с высокой пропускной способностью, не тратя на это излишние ресурсы процессора и памяти.
В нашем кластере EKS есть следующие типы логов:
Application logs — создаются приложением и лежат в /var/log/containers/*.log
Host logs — системные логи, которые создаются хостовыми нодами EKS и хранятся в файлах
/var/log/messages,/var/log/dmesg,/var/log/secureData Plane logs — создаются компонентами EKS Data Plane
В Kubernetes существует концепция DaemonSet: все ноды держат по копии пода. Это полезно для кластерных операций, таких как сбор логов и мониторинга узлов, при которых поды автоматически добавляются к новым узлам.
Кстати говоря, DaemonSet — отличный пример, когда стоит вспомнить о размере контейнерных образов. Постоянная загрузка образов жрёт трафик как не в себя. Но к счастью, образы, генерируемые в Spring Boot, собираются на основе Alpine Linux и специальных дистрибутивов OpenJDK, что позволяет им быть очень маленькими. Базовый образ весит на диске меньше 100 мегабайт.
Нам нужно настроить Fluent Bit как DaemonSet, чтобы посылать логи в AWS CloudWatch.
Вначале нужно предоставить IAM разрешения для Kubernetes-воркеров, чтобы метрики и логи улетали в CloudWatch. Это делается добавлением политики в IAM hоли воркеров. Заметьте, что это задача администрирования кластера, и делается ровно один раз при его создании. Заниматься этим каждый день, к счастью, не придется. Вначале, нужно выделить IAM роли воркеров (инстансов EC2):

Далее, приаттачить политику “CloudWatchAgentServerPolicy” в IAM роли:
Далее, создать неймспейс “amazon-cloudwatch”:
kubectl apply -f https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/cloudwatch-namespace.yaml --kubeconfig ~/.kube/config
Далее, создать ConfigMap с именем “fluent-bit-cluster-info”:
ClusterName=microservices
RegionName=eu-central-1
FluentBitHttpPort='2020'
FluentBitReadFromHead='Off'
[[ ${FluentBitReadFromHead} = 'On' ]] && FluentBitReadFromTail='Off'|| FluentBitReadFromTail='On'
[[ -z ${FluentBitHttpPort} ]] && FluentBitHttpServer='Off' || FluentBitHttpServer='On'
kubectl create configmap fluent-bit-cluster-info \
--from-literal=cluster.name=${ClusterName} \
--from-literal=http.server=${FluentBitHttpServer} \
--from-literal=http.port=${FluentBitHttpPort} \
--from-literal=read.head=${FluentBitReadFromHead} \
--from-literal=read.tail=${FluentBitReadFromTail} \
--from-literal=logs.region=${RegionName} -n amazon-cloudwatch \
--kubeconfig ~/.kube/config
Здесь приведены дефолтные настройки FluentBitHttpServer. В дополнение, Fluent Bit читает логи из tail, и поэтому после развертывания захватывает только свежие логи.
Дальше, нужно скачать и развернуть Fluent Bit DaemonSet:
kubectl apply -f https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/fluent-bit/fluent-bit.yaml --kubeconfig ~/.kube/config
После этих шагов, в вашем кластере появятся следующие ресурсы:
Сервис-аккаунт с именем Fluent-Bit в неймспейсе amazon-cloudwatch. Он используется для запуска Fluent Bit daemonSet;
Кластерная роль с именем Fluent-Bit-role в неймспейсе amazon-cloudwatch. Она позволяет учетке Fluent-Bit смотреть и загружать логи подов;
ConfigMap с именем Fluent-Bit-config в неймспейсе amazon-cloudwatch. В нем хранится конфигурация Fluent Bit.
Дальше, нужно на практике проверить, что у нас запустилось:
kubectl get pods -n amazon-cloudwatch --kubeconfig ~/.kube/config
В списке должны быть поды с именем, начинающимся на “fluent-bit-”, по штуке на узел. Ожидаемый выхлоп выглядит так:
NAME READY STATUS RESTARTS AGE
fluent-bit-8xdlg 1/1 Running 0 11m
fluent-bit-rmbw6 1/1 Running 0 11m
Если зайти в веб-консоль AWS, наш DaemonSet выглядит как-то так:

Если пройти в консоль CloudWatch, то можно посмотреть, правильно ли мы настроили Fluent Bit. Важно проверить, что регион CloudWatch Console совпадает с регионом вашего кластера EKS (в этом гайде, чуть выше по тексту мы выбирали eu-central-1). В логе должны появиться три группы:

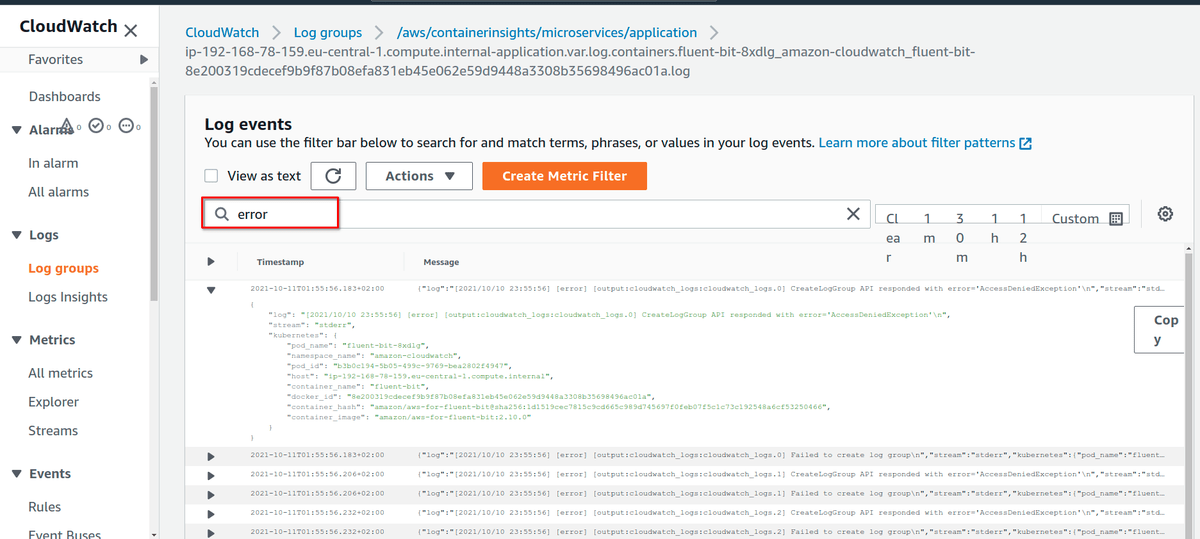
Можно проверить группу /aws/containerinsights/microservices/application, в которой сложены все события от микросервисов.
Лог можно фильтровать и смотреть в аггрегированном виде. В нашем демо-проекте, создание заказа с несуществующим customer ID возвращает “500 Internal Server Error”. Все такие события легко ловятся в логах:
Мониторинг через CloudWatch Container Insights
Мониторинг микросервисов на проде не менее важен, чем логирование. Для мониторинга Kubernetes создали кучу всевозможных инструментов. Amazon CloudWatch — это "родной" способ мониторить кластеры EC2. Amazon CloudWatch предоставляет сервис Container Insights, который позволяет мониторить, траблошутить и следить за AWS Elastic Kubernetes Service (EKS) и AWS Elastic Container Service (ECS).
Дашборда Container Insights показывает:
Утилизацию процессора и памяти
Количество задач и сервисов
R/W хранилища
Rx/Tx сети
Количество контейнеров
Чтобы включить CloudWatch Container Insights, необходимо развернуть в кластере EKS агент CloudWatch для FluentBit:
ClusterName=microservices
RegionName=eu-central-1
FluentBitHttpPort='2020'
FluentBitReadFromHead='Off'
[[ ${FluentBitReadFromHead} = 'On' ]] && FluentBitReadFromTail='Off'|| FluentBitReadFromTail='On'
[[ -z ${FluentBitHttpPort} ]] && FluentBitHttpServer='Off' || FluentBitHttpServer='On'
curl https://raw.githubusercontent.com/aws-samples/amazon-cloudwatch-container-insights/latest/k8s-deployment-manifest-templates/deployment-mode/daemonset/container-insights-monitoring/quickstart/cwagent-fluent-bit-quickstart.yaml | sed 's//'${ClusterName}'/;s//'${RegionName}'/;s//"'${FluentBitHttpServer}'"/;s//"'${FluentBitHttpPort}'"/;s//"'${FluentBitReadFromHead}'"/;s//"'${FluentBitReadFromTail}'"/' | kubectl apply -f - --kubeconfig ~/.kube/config
Теперь можно зайти в дашборду CloudWatch Container Insights и понаблюдать за нагрузкой на наш кластер EKS:

Промежуточные итоги четвертой части
Что мы имеем на руках? Мы написали пару микросервисов, опакетили в контейнер, запустили на AWS, прикрутили красивые доменные имена и логи. Тем не менее, CloudWatch Container Insights — это не предел мечтаний, и наш рассказ был бы неполон без ещё одной, последней части.
Часть 5. Мониторинг в Prometheus
Когда вы запускаете Java-приложение (или даже, любое JVM-приложение) в контейнере, то на самом деле оно выполняется на JVM. (Капитан Очевидность отдает честь). Поэтому, если мы мониторим только контейнер, то всей картины получить никак не получится. Для лучшего обзервабилити, нужно мониторить и саму JVM. Одно из ограничений Amazon CloudWatch Container Insights заключается в том, что он может собрать метрики и процессить алерты только на уровне контейнера, а на уровне JVM он так не умеет.
Есть несколько инструментов, которые можно использовать для мониторинга JVM микросервисов в Kubernetes. Один из лучших инструментов - Prometheus.
Prometheus — популярная и широко используемая база данных для time series (временных рядов). Она входит в Cloud Native Computing Foundation (CNCF). На GitHub у нее больше 40 тысяч звезд, и по сути, это самое популярное опенсорсное решение для мониторинга.
Prometheus предоставляет очень эффективное хранилище на time series базе данных, кучу интеграций, крутой язык запросов PromQL, отличные визуализации и алерты.
В отличие от CloudWatch, Prometheus работает на основе мониторинга, который пуллит и собирает те данные из приложения, которые выставлены наружу через Metrics API. При разработке cloud-native микросервисов, pull может быть лучше, чем push, потому что это генерирует меньше трафика, создает меньше нагрузки на сеть.
Есть два способа, которым Prometheus вытягивает метрики. Первый заключается в том, что приложения выставляют Metrics API с помощью клиентских библиотек. Библиотека позволяет разработчикам выставить наружу важные им бизнесовые метрики, которые потом пойдут в дашборду Prometheus. Этот способ используется для тех приложений, которые вы сами разрабатываете. Второй способ — запускать рядом с приложением Exporter, который сам выставляет метрики через API. Этот метод больше подходит для сторонних приложений, например, для баз данных. Мы будем использовать клиентскую библиотеку.
Чтобы включить мониторинг Prometheus на AWS, придется немного доделать наши приложения, написанные на Spring Boot.
Включаем Prometheus в Spring Boot
В Java-приложениях есть несколько способов выставить наружу эндпоинты для мониторинга. Эти эндпоинты используются для сбора метрик приложения. Можно использовать данные Prometheus вместе с JMX бинами. В Spring, есть Spring Boot Actuator, который используется для создания хороших, готовых для продакшена эндпоинтов, совместимых с любым приложением на Spring MVC. Почитать про Spring Boot Actuator, можно в официальной документации.
В нашем микросервисе Customer, нужно добавить следующую зависимость: io.micrometer:micrometer-registry-prometheus. Для Gradle это делается в build.gradle, для Maven - pom.xml соответственно.
Кроме того, в конфигурацию нужно доложить еще несколько свойств для корректной работы Prometheus Metrics API:
management:
endpoints:
web:
exposure:
include: health, prometheus, info, metrics
health:
show-details: always
metrics:
tags:
application: MonitoringCustomerMicroservice
На следующем шаге, нужно заставить работать авто-дискавери, чтобы Prometheus смог сам нас найти и стянуть все данные. Для этого в “eks-deployment.yaml” нужно добавить еще парочку аннотаций:
template:
metadata:
labels:
app: microservice-customer
annotations:
prometheus.io/scrape: "true"
prometheus.io/port: "8080"
prometheus.io/path: "/customer/actuator/prometheus"
Теперь, возвращаемся в EKS, и создаем неймспейс Prometheus в нашем кластере:
kubectl create namespace eks-prometheus-namespace --kubeconfig ~/.kube/config
Теперь нужно создать докерный образ и развернуть его на неймспейсе “eks-prometheus-namespace”. Этот процесс мы уже описывали ранее в этом гайде. (Жестокая реальность в том, что я не буду копипастить сюда третью часть этого гайда, вам придется осознать это самостоятельно).
Как только приложение задеплоилось, нужно пройти в Actuator и проверить эндпоинт Prometheus:

Этот эндпоинт (https://customer.microservicesdemo.net/customer/actuator/prometheus) отдаёт следующие метрики:

Как всегда, нужно повторить все эти процедуры для второго нашего микросервиса, Order.
Amazon Managed Service for Prometheus (AMP)
AMP Workspace — место для того, чтобы получать, хранить и анализировать метрики Prometheus. AMP Workspace помогает изолировать мониторинг различных проектов/приложений.
Создать AMP Workspace можно через AWS CLI или через AWS Console. Идём в Amazon Prometheus и создаем его примерно так:

Теперь в консоли AWS можно посмотреть подробности о созданном Prometheus Workspace :
Настройка Prometheus Metrics Collector
AMP не стягивает оперативные метрики автоматически. Для этого нужно сконфигурировать Prometheus Metrics Collector. Он стягивает их с контейнеризованных Java-микросервисов, запущенных в кластере, и посылает в AMP Workspace.
Есть несколько способов развернуть Prometheus Metrics Collector в AWS: либо сервер Prometheus, либо агент OpenTelemetry. В этом примере, мы будем использовать AWS-овский дистрибутив OpenTelemetry Collector/Prometheus server.
Установка сервера Prometheus
Устанавливать новый сервер Prometheus имеет смысл с помощью Helm. Helm — это популярный пакетный менеджер для Kubernetes. С помощью него легко и приятно искать, распространять и использовать софт, сделанный специально для Kubernetes.
Вначале, нужно установить Helm на наш локальный компьютер, как рассказано в официальной документацией.
Дальше, нужно добавить репозиторий чартов, где лежит Prometheus:
helm repo add prometheus-community https://prometheus-community.github.io/helm-charts
helm repo add kube-state-metrics https://kubernetes.github.io/kube-state-metrics
helm repo update
Настройка ролей IAM
Нужно настроить IAM роли сервис-аккаунтов для приема метрик из кластера EKS. Сервер Prometheus посылает данные с по HTTPS. Данные нужно подписать валидными креденшелами AWS и алгоритмом AWS Signature Version 4 для аутентификации и авторизации каждого клиентского запроса, предназначенного для управляемого сервиса. Запросы отправляются инстансу AWS signing proxy, который перенаправляет эти запросы на управляемый сервер.
AWS signing proxy может быть развернут на кластере EKS и может запускаться от имени сервис-аккаунта Kubernetes. С помощью IAM Roles for Service Account (IRSA), можно связать роль IAM с сервис-аккаунтом Kubernetes, и тем самым предоставить полномочия для каждого пода, который использует этот сервис-аккаунт. Это соответствует принципу минимальных привилегий: IRSA используется для безопасной настройки AWS signing proxy, чтобы переливать метрики Prometheus в AMP.
Подробное объяснение того, как для AMP настроить IAM роли сервис-аккаунтов можно прочитать в официальном гайде.
После создания двух ролей (одной для приема метрик, и второй для запросов), мы можем проверить правильность происходящего, поискав эти роли в консоли:

С помощью Helm можно переопределить конфигурацию Kubernetes. Нужно создать файл с именем “prometheus_eks_values.yaml” и содержимым типа такого:
serviceAccounts:
server:
name: amp-iamproxy-ingest-service-account
annotations:
eks.amazonaws.com/role-arn: ${IAM_PROXY_PROMETHEUS_ROLE_ARN}
server:
remoteWrite:
- url: https://aps-workspaces.${AWS_REGION}.amazonaws.com/workspaces/${WORKSPACE_ID}/api/v1/remote_write
sigv4:
region: ${AWS_REGION}
queue_config:
max_samples_per_send: 1000
max_shards: 200
capacity: 2500
В этом файле, мы просим использовать целевой Amazon Managed Service for Prometheus, а сервер Prometheus, запущенный на EKS Kubernetes, будет посылать данные с мониторинга.
Теперь, создадим сервер Prometheus следующей командой Helm:
helm install prometheus-chart-eks prometheus-community/prometheus -n eks-prometheus-namespace -f prometheus_eks_values.yml
Визуализация метрик в Amazon Managed Grafana
Grafana — это опенсорсная веб-консоль для аналитики и визуализации данных. Он предоставляет дашборд с графиками, таблицами, алертами (будучи подключена к источнику данных, который такое поддерживает). Grafana оказывается полезной для логирования, мониторинга, трейсинга, и так далее. Часто она используется в тандеме с Prometheus: можно показать дашборд с данными Prometheus на AWS.
Amazon предоставляет полностью управляемую облачную Grafana.
Дальше я опишу шаги, которые позволяют настроить амазоновскую Grafana так, чтобы она начала визуализировать данные от Prometheus.
Для аутентификации в управляемой Grafana, мы будем использовать AWS SSO. Если у вас включена “AWS Organization”, то вы можете сделать пользователя AWS SSO как-то так:

Дальше, нужно создать воркспейс для Grafana. Grafana Workspace — это некий виртуальный сервер, который используется как общий дашборд для данных из различных источников.
Из раздела “Amazon Grafana” > Workspaces, новый воркспейс можно создать, выбрав опцию “Create workspace”:
Теперь нужно указать имя воркспейса, в нашем примере это “prometheus-metrics”:
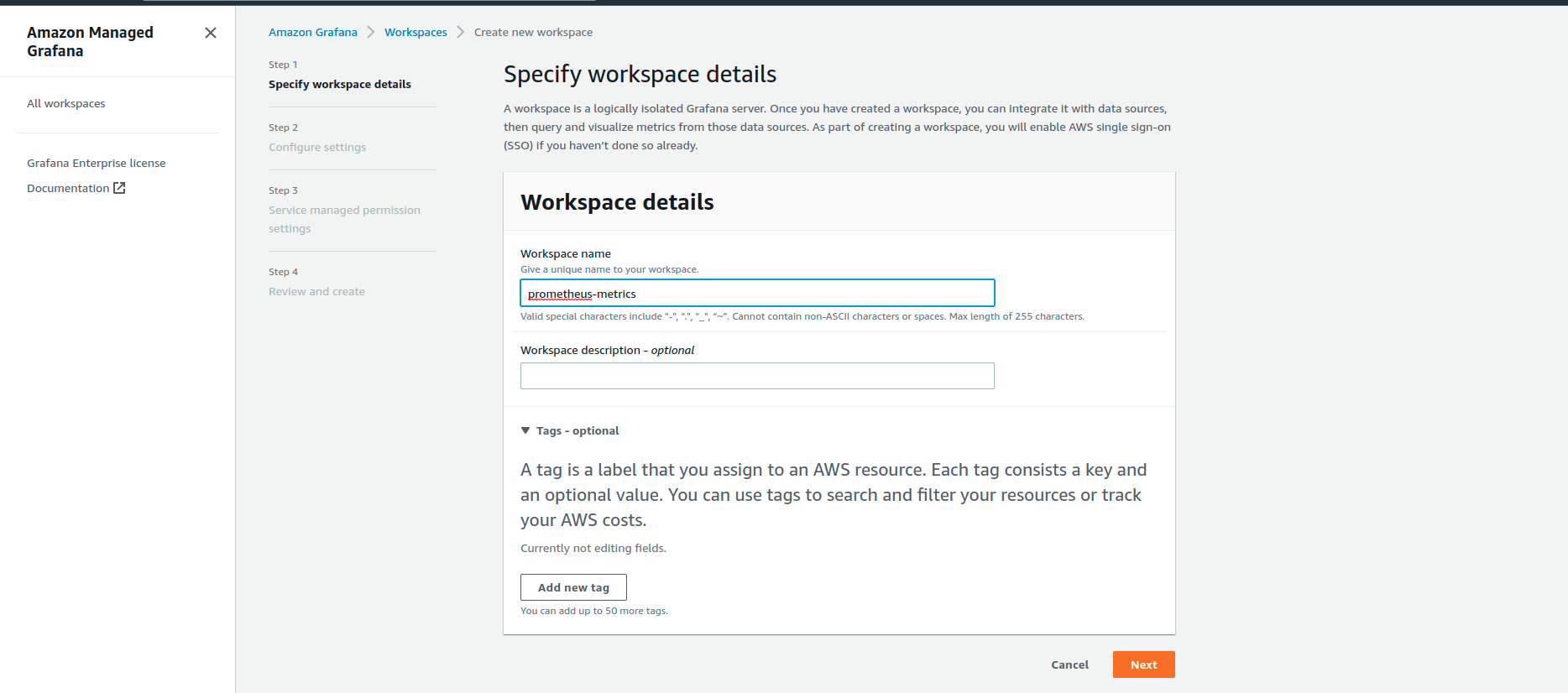
Дальше, этот воркспейс нужно настроить. Мы будем использовать AWS SSO как метод аутентификации, и тогда ранее созданный аккаунт WEB SSO можно будет использовать чтобы залогиниться в Grafana. “Permission Type” установим в значение “Service managed”, тогда AWS автоматически будет предоставлять нужные разрешения.

На последней странице мастера, нужно установить “IAM permission access settings” в значение “Current Account”. В разделе “Data Sources” можно выбрать разные источники данных, и таким образом, у нас будет один дашборд Grafana, который можно использовать для разных целей и разных инструментов (Prometheus Monitoring, AWS CloudWatch Monitoring, AWS X-Ray Tracing, итп). Сейчас в качестве источника данных выберем “Amazon Managed Service for Prometheus”. Для нотификаций пусть будет “Amazon SNS”.
Как только воркспейс создан, становится возможным привязать нашего ранее созданного пользователя AWS SSO к этому воркспейсу:
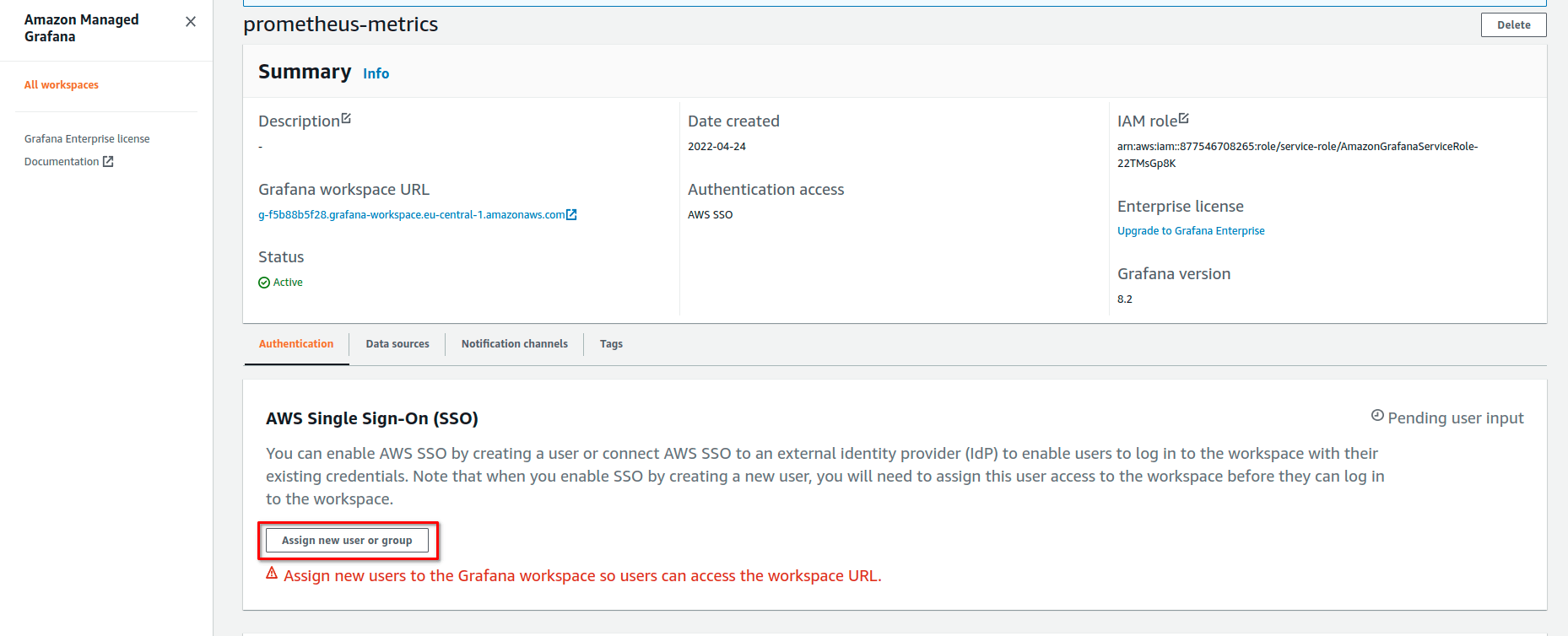

Далее, логинимся в воркспейс Grafana, пройдя на URL воркспейса, через AWS SSO. Сразу после логина, мы можем добавить воркспейс Prometheus в качестве “Data Source”:

В этом датасорсе, нужно использовать эндпоинт Prometheus Query URL, но без суффикса “/api/v1/query”. Ещё, нужно включить “SigV4 auth” в разделе “Auth”. В разделе “SigV4 Auth Details”, нужно выбрать правильный регион (в этом демо-проекте - “eu-central-1”) и “AWS SDK Default” как провайдер аутентификации:

Дальше, нужно добавить дашборд для мониторинга наших приложений Spring Boot, запущенных на кластере EKS Kubernetes. На сайте grafana.com уже есть дашборд для мониторинга Spring Boot APM. Можно импортировать его по id = "12900".
После успешного импорта, можно увидеть дашборд с данными мониторинга Kubernetes, включая JVM-специфичную информацию типа использования CPU или использования джавной кучи:

И конечно, какой же джавист не хочет посмотреть на подробности работы сборщика мусора?
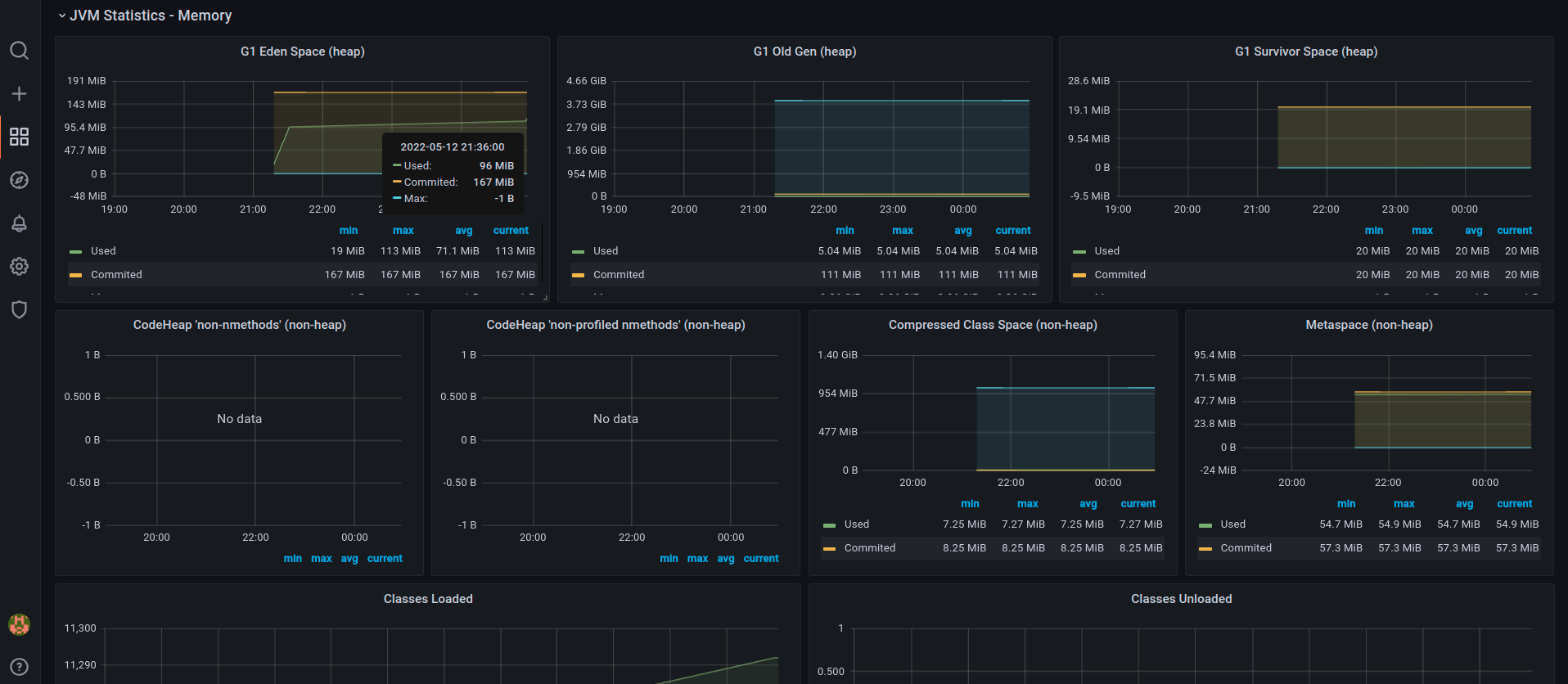
В дополнение к мониторингу JVM, мы можем делать продвинутый мониторинг Kubernetes, используя Prometheus и Grafana. Добавив Grafana dashboard for Kubernetes , можно видеть метрики кластера Kubernetes (количество узлов, подов, свойства кластера). Еще, можно искать метрики за какой-то конкретный период времени. Вот снапшот с несколькими репликами, запущенными на кластере в неймспейсе “eks-prometheus-namespace”:
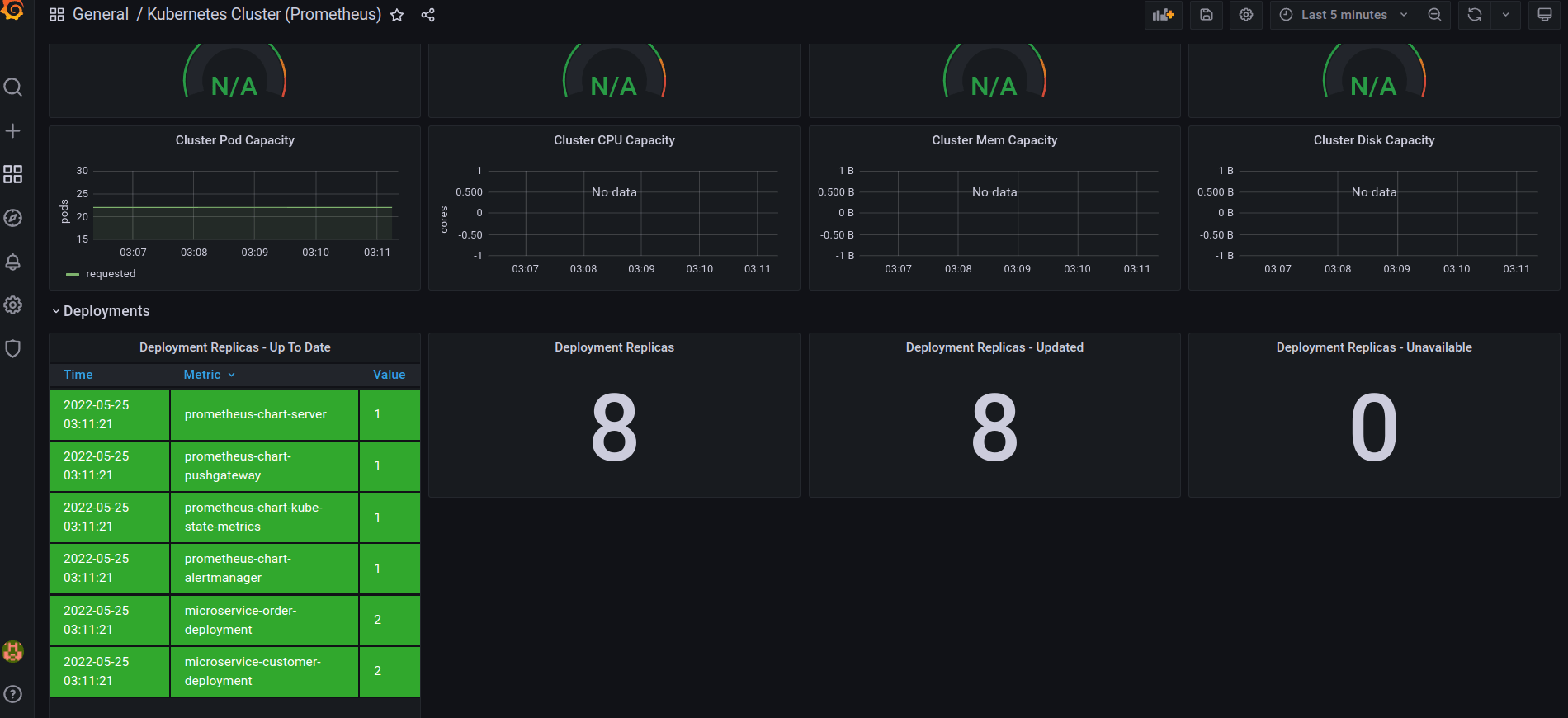
Ещё, мы можем смотреть историю реплики с нужными критериями поиска:

Диаграмма выше показывает, что все наши реплики (4 для микросервисов и 4 для кластера Prometheus), отлично себе работают и не падают.
На проде очень важно установить правильный набор алертов, чтобы вовремя заметить некорректную работу приложения. Алерты позволяют техподдержке быстро отреагировать на ошибку на проде. Алерты просто необходимы, если вам нужно выполнять какие-то понятные SLA/SLO на приложение.
Вот пара примеров того, что можно использовать в алертах:
CPU используется более чем на 80%
RAM используется более чем на 80%
Поды перезагружаются каждые 10 минут
База данных заполнена на 90%
Когда у вас сработал какой-то алерт, активируется триггер, сообщающий об этом команде техподдержки или безопасникам. В зависимости от того, какой алерт сработал, можно использовать разные каналы оповещения: электронную почту, SMS, чаты.
Итоги
В этом гайде мы совершили небольшое путешествие по разработке микросервисов. Оно началось с написания кода в IDE и закончилось наблюдением графиков в Grafana.
Надеюсь, этот гайд окажется хорошей отправной точкой для людей, в первый раз погружающихся в страшный волшебный мир микросервисов на Java и всего того DevOps ада, который ждёт вас при встрече с облачными провайдерами.
Все сообщения об опечатках, отвратительных англицизмах, битых ссылках и прочих вопросах по форме, а не по сути — прошу пройти с ними в личку, чтобы не мусорить в комментариях.
Если хотите пообщаться со мной по существу, лучше использовать не личку Хабра (там миллионы каких-то сообщений, шансов разгрести которые нет), а писать на рабочую почту (по рабочим вопросам), либо в личный Facebook и личную почту (по приватным вопросам).
Отдельная просьба к сотрудникам облачных провайдеров. Если вы готовы предоставить помощь в написании подобной статьи не для Amazon, а для ваших облаков (SberCloud, MTS Cloud, Selectel, Yandex.Cloud, VK cloud solutions, итп), свяжитесь со мной любым способом. Помощь может выражаться, например, в экспертизе по использованию ваших аналогов зарубежных сервисов, помощи в вычитке статьи, либо предоставлении демо-доступа до ваших облаков.
Приятного Сезона Java на Хабре!
Комментарии (21)

amarkevich
16.08.2022 12:43+4Для большинства приложений, хорошая практика - заводить эндпоинт
/healthв части 5 описан Actuator - он прекрасно справляется с поставленной задачей


smarthomeblog
17.08.2022 17:40+1Спасибо за познавательную статью. Много полезного для себя нашел хоть Java не относится к моему стеку. Хотелось бы отметить, что дополнительно можно использовать Terraform для описания всей инфры.

olegchir Автор
18.08.2022 13:56Можно! Возможно, стоит написать про терраформ, особенно применительно к российским облакам

tsypanov
18.08.2022 11:05+1@Repository public interface OrderRepository extends MongoRepository<Order, String> { }@Repositoryздесь лишний: ЕМНИП, Спринг подхватывает любой интерфейс унаследованный отCrudRepository,JpaRepositoryи т.п.olegchir Автор
18.08.2022 13:55+1Ты прав. Либо экстендить стандартные репозитории (Crud, Jpa..), либо помечать через @Repository@RepositoryDefinitionn.
tsypanov
18.08.2022 11:08+1@RestController @RequestMapping("/api/v1") public class HealthStatus { private final Logger log = LoggerFactory.getLogger(HealthResource.class); //... }Скажите, а чем вызвано явное приписывание логгеров в коде, у нас же Ломбок прикручен и мы можем использовать
@Slf4j?olegchir Автор
18.08.2022 13:48Тем, что вначале лобка там не было, а потом случились исторические причины :) Спасибо, что заметил!

sandersru
>> Если Quarkus и Micronaut воспринимаются как смелые эксперименты
На всякий случай замечу, что и микропрофайл и хибернейт(а так же многое другое как например vert.x или resteasy и smallrye) поддерживаются именно RedHat. Более того, поддерживаются одними и теми же людьми. При чем даже на экспериментальные фичи, иногда выдавали мне фиксы за день и со мной эти же люди дебажили код из jdk вплоть до натива по обычной апаче лицензии, чтобы понять где проблемы... Ну да, очень смелые эксперименты.
Ну а с учётом, что эти эксперименты уже давно и глубоко используются в Энтерпрайз, да и тот же редхат уже на quarkus переписал keycloak и infinispan - то я бы не называл их экспериментами уж точно.
olegchir Автор
Может быть, разные люди и компании живут в разных реальностях, своих информационных бабблах... Ты знаешь какие-нибудь соцсети, банки, государственные структуры, крупный ритейл (аля X5) и другой российский энтерпрайз, который сидит на Кваркусе? Если знаешь - поделись, пожалуйста. Я знаю много кто экспериментировал, но у них (этих неназванных из-за NDA компаний) это всё так и живёт на фазе эксперимента, а в проде там крутится JavaEE такой версии, что на ней писали ещё прадедушки
sandersru
Российские банки и государственные структуры - это немножко меньше мирового IT. И окологосударственнось(как и везде) накладывает какие то ограничения. На "сертифицированный Линукс", "сертифицированный JDK", фрэймворк и так далее. При чем чем глубже сидят эти компании, тем больше ограничения.
Про j2ee в проде - это отдельная история. Как про ту же сертификацию, так и про то, что апгрэйд чего то на что то надо тестировать, а это деньги. И не айтишные дяденьки, с большими калькуляторами прекрасно умеют считать, что "модно и молодежно" и "зачем платить много денег когда jdk в LTS" прекрасно делают выбор.
Кстати, на сколько я помню, Твиттер переехал на Грааль и натив ещё во времена 19й версии.требования по железу упали на 10-15%. На их объемах, это солидная экономия. Соответственно кваркуса тогда не было, а Спринг в нативе до сих пор толком то и нет
olegchir Автор
Эмм, я же не утверждаю, что Спринг Нейтив или Кваркус или не работают. Хочу только отметить, что большая часть мира не в курсе, что они вообще существуют, и более того - им всё равно.
Хочется еще раз пропиарить схему из книги Crossing the Chasm.
Иногда инноваторы забывают, что там на схеме есть ещё и весь остальной мир :)
Превращение продукта из "смелого эксперимента" для аудитории инноваторов в "этим легаси мы уже миллион лет пользуемся" для laggards - это целая история!
sandersru
Зевает. Ну не подводите "большую часть мира" под себя.
То есть то что вы не пользовались, это не значит, что это эксперементально или вообще не существует. Скорее поинт в том, что в следующий раз разберитесь глубже, либо используйте более мягкую терминологию.
Большая часть мира вообще считает что айтишники - это какие то странные ребята, бубнят себе что-то под нос и делают всякие непонятные вещи.
А для большей части мира Сишников - все java фрэймворки могут быть так же на одно лицо и иногда даже совсем не существуют.
olegchir Автор
На тренировках по фехтованию нас учили, что самое непродуктивное, что можно сделать - закрывать глаза, когда тебя бьют в голову. Ты можешь нормально что-то сделать только пока полностью адекватен реальности, видишь всё широко раскрытыми глазами и способен моментально реагировать на это.
Нельзя закрывать глаза на факты типа того, что айтишников действительно супер мало (до Событий их было в России не больше 2 миллионов человек), а Спринг Нейтиву и Кваркусу до стандарта индустрии - как пешком до Марса. Не надо врать, в особенности себе. Тогда появляется шанс как-то выбраться из сложившейся ситуации
sandersru
А простите, что есть "стандарты индустрии" и не расскажите, каким образом и в каких местах тому же Кваркусу далеко. Спринг-натив понятно, он там еще из беты по моему не выбрался. Что с Кваркусом не так? Просто вот интересно, то ли вас фихтованию не доучили, то ли я индустрию не так понимаю. Но определенно, кто-то из нас ошибается. Можно по пунктам, у вас же будет аргументация?
Пока для меня это звучит просто как голословные утверждения, хотелось бы фактаж.
jbaruch
Берем какой-нить опрос по-репрезентативней, например, JetBrains: https://www.jetbrains.com/lp/devecosystem-2021/java/, смотрим на 3% Кваркуса, и понимаем, что надо слушать Олега, а не жить в своём баббле.
sandersru
Слушать, простите что? Что Олег что-то придумал и не может аргументировать?
https://newsroom.eclipse.org/news/announcements/amid-growth-cloud-native-enterprise-java-adoption-eclipse-foundation-announces тут 13%
https://www.jrebel.com/blog/2021-java-technology-report тут 6%
Я вот какую мысль пытаюсь понять. Новые технологии - это плохо и надо вечно сидеть на старых? Вроде как нет. Вы тому пример в том числе.
Или что Олегу (да и всем остальным) надо бежать по всем своим клиентам/заказчикам и компаниям и пытаться их заставить отказаться от KeyCloak/Infinispan т.к. они написаны на "смелых экспериментах", а в дальнейшем от всего RedHat, который на java? Попробуйте, потом расскажите, интересная статься может получиться.
Или все же таки попробывать разобраться и говорить о плюсах, минусах, экперементальности и production ready? Пока от Олега было ноль аргументов.
Пока я вижу минус только один. В RUнете на нем никто(практически) писать не умеет. Как когда то на том же Spring-е. Коммерчески (для компаний) это в чем то show-stoper, но как бы и на golang совсем недавно никто не умел.
Да, возможно кваркус где то приживется, где то нет. Может и совсем умрет, но говорить о эксперементальности - это просто не знание контекста.
olegchir Автор
мне интересно помогать людям, а пишут они на новых или старых технологиях - не имеет никакого значения
sandersru
>>мне интересно помогать людям, а пишут они на новых или старых технологиях - не имеет никакого значения
Помогать правильно. Perception создавать по другим технолологиям - не очень. В любом случае, спасибо за статью.
Удачи!