
Хороший код читается легко, как проза. Многие книги учат нас тому, как важно делить код на небольшие, повторно используемые, легко потребляемые блоки.
Но почему-то, в случае с регэкспами у программистов как будто появляется слепое пятно на чувстве стиля. Вот такая регулярка – совершенно обычное дело:
/^(0[1-9]|1[012])[- /.](0[1-9]|[12][0-9]|3[01])[- /.]((19|20)\d\d)$/Долго вглядываясь в нее, мы, наверное, поймем рано или поздно, что она содержит четыре логических блока - три чиселка, по-разному ограниченных, и некоторый разделитель [- /.]
Не лучше ли ее записать вот так?
"/^" + month + delimiter + day + delimiter + year + "$/"Матерь божья, да это же дата! Сколько наносекунд вам потребовалось для того, чтобы это понять?
Почему же за однострочник вроде тех, что пишет легендарный Stefan Pochmann c leetcode, тебе сразу оторвут руки, а на художества с регулярками смотрят сквозь пальцы? Мне не слишком понятно почему.
// отвратительный однострочник Стефана Почманна
TreeNode* mergeTrees(TreeNode* root1, TreeNode* root2) {
return root1&&root2 ? new TreeNode(root1->val+root2->val,mergeTrees(root1->left,root2->left),mergeTrees(root1->right,root2->right)):root1?root1:root2;
}Наверное, это феномен того же порядка, как и то, что творится в большинстве файлов с юнит-тестами. Дублирование кода, отключенные линтеры, длинные слабочитаемые выражения и халатность при код-ревью.
Итак: не склеивайте регулярки в одну большую регулярку, как будто вы – первокурсник, понтующийся своим однострочником. Регулярки – это код должно быть легко читать, отлаживать и модифицировать. Чтобы он стал таковым, надо большое и непонятное содержимое разбить на группы маленького и понятного. В педагогике это называется chucking, у нас – decomposition.
Действовать будем исходя из следующих положений:
В большинстве языков регулярное выражение может создаваться на основе строки.
В большинстве сложных регулярок можно выделить составные части.
Строки можно конкатенировать.
Подход нехитрый: выделяем смысловые кусочки в переменные и функции, потом все склеиваем. Для примера возьмем регулярочку из другой хабростатьи:
// 1. Строка начинается только с заглавной латинской буквы или цифры
// 2. За ним может быть разрешенный спецсимвол или единичный пробел
// 3. Нельзя использовать кириллицу и другие спецсимволы
const someEngPattern = /^[A-Z0-9]+([a-zA-Z0-9\\!\\#\\%]|\\s(?!\\s))*$/;Это не очень хороший код, на его чтение у меня ушло много времени.
Кроме того, этот код предваряется длинным комментарием, описывающий, что происходит в регулярке. Каким бы ни был болтуном и сектантом автор книги Clean Code Дядюшка Боб (Robert Martin), с его мнением о комментариях в коде я согласен. Комментарии врут. Если они не врут прямо сейчас, то они будут врать в будущем, когда кто-то внесет изменения в код и забудет обновить комментарий. Альтернатива комментариям - это промежуточные переменные и функции с говорящими именами.
Я буду декомпозировать нашу регулярочку "снаружи вовнутрь", шаг за шагом, а потом посмотрим, что получилось. Примеры будут на JS/TS, но для других языков все будет так же.
Шаг 1: начало и конец ввода
Например, давайте сразу избавимся от пары /^ и $/
function wholeInput(regex) {
return "/^" + regex + "$/";
}
const someEngPattern = wholeInput("[A-Z0-9]+([a-zA-Z0-9!#%]|\\s(?!\\s))*")Шаг 2: выделим крупные логические блоки
Два блока, которые вижу я - это первая группа буковок (начинается с большой буквы или с цифры) и все остальное. По лингвистической традиции обзовем их префиксом и суффиксом:
const prefix = "[A-Z0-9]+"
const suffix = "([a-zA-Z0-9\\!\\#\\%]|\\s(?!\\s))*"
const someEngPattern=wholeInput(prefix + suffix)На мой взгляд, префикс уже достаточно прост для того, чтобы дальше его не декомпозировать. А вот в суффиксе происходит довольно много всего.
Шаг 3. опять выделяем логические блоки
Простенькая функция для скобочек и звездочки (а скобочки обозначают группу, то есть группа может повторяться от нуля до бесконечности раз):
function group(regex) {
return "(" + regex + ")";
}
const suffix = group("[a-zA-Z0-9\\!\\#\\%]|\\s(?!\\s)") + "*"Шаг 4. Суффикс и предел декомпозиции
В суффиксе в конце у нас есть что-то хитрое с пробелами:
const onlyOneWhiteSpace="\\s(?!\\s)";Можно ли упростить его еще дальше? Мне сложновато будет найти хорошие имена переменных, поэтому желающему понять, как работает эта конструкция все же придется погрузиться в справочник.
Шаг 5. Экранирование
В кусочке [a-zA-Z0-9\\!\\#\\%] префиксе у нас налицо куча экранированных симовлов. У меня от этих бесконечных палок рябит в глазах, поэтому сделаю-ка я функцию escape:
function escape(rawChar) {
return "\\" + rawChar;
}Для куска a-zA-Z0-9 можно придумать имя:
const letterOrNumber = "a-zA-Z0-9";Шаг 6. Переменные или функции для управляющих конструкций
Одна из сложностей в регекспах - это понять, где у нас управляющие конструкции, а где символы, которые мы match'им. Создадим функцию charClass, которая будет обрамлять свое содержимое квадратными скобочками.
function charClass(regex) {
return "[" + regex + "]";
}А еще я создал переменную or – специально чтобы никто не подумал, что это просто match символа вертикальной палки.
const or = "|"
const suffixLetter = charClass(letterOrNumber+specialChar) + or + onlyOneWhiteSpace;Результат декомпозиции
Было: большая регулярка
// 1. Строка начинается только с заглавной латинской буквы или цифры
// 2. За ним может быть разрешенный спецсимвол или единичный пробел
// 3. Нельзя использовать кириллицу и другие спецсимволы
const someEngPattern = /^[A-Z0-9]+([a-zA-Z0-9\\!\\#\\%]|\\s(?!\\s))*$/;Стало: куча функций и переменных, скомбинированных друг с другом
function escape(rawChar) {
return "\\" + rawChar;
}
function charClass(regex) {
return "[" + regex + "]";
}
function wholeInput(regex) {
return "/^" + regex + "$/";
}
function group(regex) {
return "(" + regex + ")";
}
const prefix = "[A-Z0-9]+";
const letterOrNumber = "a-zA-Z0-9";
const specialChar = escape("!") + escape("#") + escape("%");
const onlyOneWhiteSpace="\\s(?!\\s)";
const or = "|"
const suffixLetter = charClass(letterOrNumber+specialChar) + or + onlyOneWhiteSpace;
const suffix = group(suffixLetter) + "*";
const someEngPattern=wholeInput(prefix + suffix)Возможно, еще стоило бы переименовать переменные префикс и суффикс во что-то удобоваримое, но уж очень громоздкими получаются имена переменных: whitespaceSeparatedLetterNumericalWithSpecChars, брр.
Тут налицо ограничения нашего декомпозиционного подхода. В отличие от семантически ясных day, month и year из предыдущего примера, крупным и сложным сущностям без ясной семантики сложновато подобрать звучные и короткие названия. Как следствие, их природу приходится порой скрывать за безликими лингвистическими жаргонизмами вроде prefix и suffix.
Анализ
Стоит ли овчинка выделки? Этот код я писал дольше, чем записал бы гига-регэксп выше, зато:
его легче читать;
для его понимания почти не надо лезть в справочник;
его куски можно повторно использовать. Функции
group,escapeиwholeInputпонадобятся и потом;его куски можно напрямую отлаживать;
про производительность - не смешите меня, все заинлайнится как миленькое даже в хилом V8, не говоря о дюжем gcc;
если ты - гигант и умеешь читать гига-регэкспы разом, то ты просто можешь добавить
console.log(someEngPattern).
Принципы и лучшие практики
Степень декомпозиции зависит от вас и вашей команды, а остановиться можно в любой момент. Код, который у меня получился, может быть в два раза короче, например вот таким:
function wholeInput(regex) {
return "/^" + regex + "$/";
}
function zeroOrMore(regex) {
return "(" + regex + ")*";
}
const or = "|"
const onlyOneWhiteSpace="\\s(?!\\s)";
const suffix = zeroOrMore ("[a-zA-Z0-9\\!\\#\\%]" + or + onlyOneWhiteSpace)
const someEngPattern = wholeInput( "[A-Z0-9]+" + suffix)Правда ж он менее мерзкий?
Я сейчас собираю принципы для работы с регулярками, вот кое-что:
выносим отдельно надо то, от чего рябит в глазах. Кучи скобочек, обилие слэшей, все, в чем можно запутаться;
выносим то, что представляет собой понятный логический блок. Примеры выше -
день,месяц,год,не более одного пробела;выносим то, для чего требуется редко используемый синтаксис.
a-zA-Zзнают многие, а вот в\\s(?!\\s)сразу и не въедешь;выносим управляющие символы, которые легко перепутать с искомыми символами;
группируем так, чтобы было понятно, к чему относится тот или иной управляющий символ;
если позволяет язык и есть потребность - используем multiline-строки и режим игнорирования whitespace'ов, тогда можно форматировать их с отступами, прям как в нормальном коде, гляньте на пример, предоставленный @shoorick. Для наших примеров использовать обратнокавычечные строки из JS смысла не было, да и переменные внутри них выглядят довольно неуклюже.
Другие подходы
За 15 лет в индустрии я лишь один раз видел, чтобы разработчики декомпозировали свои регулярки. Остальные хреначат в одну строчку и полагаются на авось.
Ну конечно, это плохой способ подводить статистику, и на просторах интернета я нашел несколько других интересных направлений:
Библиотека mol-regex – это когда подход, взятый в нашей статье, доведен до логического завершения. Если у вас действительно много регулярок и api библиотеки вам по душе – надо брать! Коллега @ninjin описывает его в своей статье:
// /4(?:\d){12,}?(?:(?:\d){3,}?){0,1}/gsu
const VISA = from([
'4',
repeat( decimal_only, 12 ),
[ repeat( decimal_only, 3 ) ],
])Вербальные выражения заслуживают отдельной статьи и позволяют получать вот такое:
const tester = VerEx()
.startOfLine()
.then('http')
.maybe('s')
.then('://')
.maybe('www.')
.anythingBut(' ')
.endOfLine();Библиотека SuperExpressive - еще один билдер регулярок, который вспомнил @FanatPHP. Обратите внимание на функцию
end()и табуляцию:
const SuperExpressive = require('super-expressive');
const myRegex = SuperExpressive()
.startOfInput
.optional.string('0x')
.capture
.exactly(4).anyOf
.range('A', 'F')
.range('a', 'f')
.range('0', '9')
.end()
.end()
.endOfInput
.toRegex();
// Produces the following regular expression:
/^(?:0x)?([A-Fa-f0-9]{4})$/Именованные группы - довольно приятная функциональность, встроенная в регулярные выражения, поддерживаемая в большинстве современных языков и улучшающая читабельность. Спасибо @ubx7b8 за то, что вспомнил. Отличный метод работы в случаях, когда у группы есть понятная семантика, например в примере с датой. В микрософтовском руководстве приводится вот такой пример:
(?<duplicateWord>\w+)\s\k<duplicateWord>\W(?<nextWord>\w+)Наконец для сложных штук, типа написания своих раскрашивателей кода или анализаторов DSL, можно уже и грамматиками воспользоваться, а они нам парсеров нагенерируют как делают в PEG.js. Объемная статья про парсинг (в js).
Буду рад, если кто-нибудь принесет примеров из респектабельных open-source проектов, и мы вместе вместе покумекаем над принципами и границами применимости.
Не забывайте о гибридном подходе
И еще один принцип, о котором часто забывают: каждому инструменту – свое применение. Молотки, гвозди, ну вы поняли.
Даже если вы декомпозируете пример с датой из начала статьи, конструкция (0[1-9]|[12][0-9]|3[01]) - это плохой и невкусно пахнущий код.
Почему? Да потому, что он использует текстовые методы для анализа чиселки. Выковыряйте чиселку года вульгарным \d{1,4} , приведите в тип числа и верифицируйте уже численными методами:
function isValidYear(year: number): boolean {
if (isNaN(year)) {
return false;
}
return year > 0 && year < 3000; // ну уж тысячу лет мой код точно проживет
}Другой понятный случай применения гибридного подхода: это когда часть выражения проще/читабельнее верифицировать через старые добрые циклы и строковые операции, чем через регэкспы.
Спасибо хабраюзерам @DirectoriX и @0x131315 за то, что они начали отличную ветку о гибридном подходе в соседнем посте.
Комментарии (44)

steelratty
17.10.2022 10:00+3Выражу другое мнение. Размазанная регулярка это как собираемый из кусков sql запрос. Кажется, лучше даже разделять пробелами и комменты сверху над блоками
Для того, чтобы рег выражение потом проверить где-то на стороне - его надо собрать из исходного кода, что капец гемор будет в вашем случае.

ShashkovS
17.10.2022 10:05+11function wholeInput(regex) { return "/^" + regex + "$/"; } function zeroOrMore(regex) { return "(" + regex + ")*"; } const or = "|" const onlyOneWhiteSpace="\\s(?!\\s)"; const suffix = zeroOrMore ("[a-zA-Z0-9\\!\\#\\%]" + or + onlyOneWhiteSpace) const someEngPattern = wholeInput( "[A-Z0-9]+" + suffix)
Я вот не могу согласиться с тем, что этот код менее мерзкий.
Я знаю синтаксис регулярок, мне не нужно объяснять, что(regex)*— это сколько угодно повторов, я это сразу вижу. Если уж что-то и нужно объяснять, то мотивацию того, почему или зачем вы делаете именно так.
Зато регулярку текстом я могу скопировать и вставить в условный regex101, чтобы её потестировать (или поправить). А такой код мне нужно частично исполнить, чтобы получить регулярку, которую можно тестировать. И после того, как я её потестирую, мне придётся исправления назад мучительно накатывать в код (с возможными ошибками в процессе).
Вот пример того, как длинная и сложная регулярка оформена в модуле fractions.py:_RATIONAL_FORMAT = re.compile(r""" \A\s* # optional whitespace at the start, (?P<sign>[-+]?) # an optional sign, then (?=\d|\.\d) # lookahead for digit or .digit (?P<num>\d*|\d+(_\d+)*) # numerator (possibly empty) (?: # followed by (?:\s*/\s*(?P<denom>\d+(_\d+)*))? # an optional denominator | # or (?:\.(?P<decimal>d*|\d+(_\d+)*))? # an optional fractional part (?:E(?P<exp>[-+]?\d+(_\d+)*))? # and optional exponent ) \s*\Z # and optional whitespace to finish """, re.VERBOSE | re.IGNORECASE)
Эту регулярку можно как есть вставить в regex101 (нужно не забывать ставить флаг extended).
Вот так это выглядит: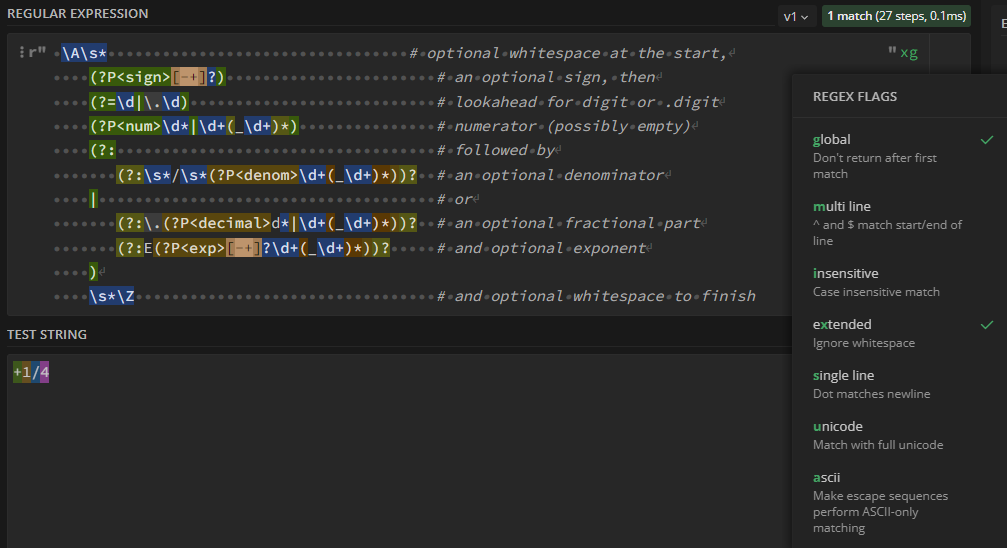
Там, если нужно, можно отладить все аспекты работы регулярки (группы и т.п.), а потом как есть скопировать назад в код.
ganqqwerty Автор
17.10.2022 10:12Собрать конкретно эту регулярку часто можно даже на этапе препроцессинга, не исключено, что даже плагин к vscode есть, который ее подсветит: все куски-то статичные. Ну а если не подсветит, всегда можно console.log впихнуть и посмотреть.
ShashkovS
17.10.2022 11:39+1Ну, это такое. Если склейка регулярки из именованных кусков — это норм, я таки и вправду могу сунуть в console.log, то функции типа
wholeInput— это провал.
Такие функции первые претендуют на то, чтобы выехать в какой-то общий для всех модуль.
И вот после этого, чтобы собрать регулярку в консоли, мне нужно искать по проекту, где живут эти функции, копировать их отдельно в консольку, после этого уже собирать регулярку.
Кроме того, хоть словаwholeInputдовольно понятные, но регулярки очень формальный язык, в которых каждый символ может иметь большое значение. Если я такое увижу в коде, то мне придётся полезть посмотреть, что именно имел в виду автор. А то мало ли, может он исходил из того, что у регулярки ещё какие-то флаги не выставлены?
Если я сделаю так:const reg = new RegExp(wholeInput('\d+'), 'gm'); // wholeInput же умная, наверное? // [...'123\nasdf\n53'.matchAll(reg)] — это два match'а
то могу получить не тот результат, который ожидаю.


ubx7b8
17.10.2022 10:37+9А если воспользоваться встроенными возможностями, чтобы сразу увидеть, какая группа для чего и заодно получить их по имени?
/^(?<day>0[1-9]|1[012])[- /.](?<month>0[1-9]|[12][0-9]|3[01])[- /.](?<year>(19|20)\d\d)$/ganqqwerty Автор
17.10.2022 10:46Вот это, кстати, очень правильно! Именованные группы много где поддерживаются?
ganqqwerty Автор
17.10.2022 10:54+1
Juribiyan
17.10.2022 10:57+1Какой кошмар. Любят же некоторые на пустом месте всё усложнить и понавязывать другим правила.
А чтобы быть конструктивным, предложу альтернативное решение проблемы запутанных регэкспов в коде. Некое расширение для IDE, превращающее регэкспы в интерактивные объекты, по нажатию на которые открывается окошко с парсером и редактором (подобных инструментов создано достаточно). Почти уверен, что в каком-нибудь VS Code это точно уже реализовано.

datacompboy
17.10.2022 11:15+2Зачастую regexp это write-only code. Его не надо читать, в него надо верить.
Если есть недоверие -- переписать. Благо, однострочник.
Да, я знаю про https://emailregex.com/ вариации. Это использование неподходящего инструмента для неподходящей цели. Но ведь можно же!
ganqqwerty Автор
17.10.2022 11:45+1Это уж совсем капитуляция перед задачей. По-моему, не должно быть write-only кода, ни в тестах, ни в регулярках, ни в css или xpath-селекторах, ни даже в bash и perl-скриптах, если их читают и запускают несколько раз несколько людей.
datacompboy
17.10.2022 11:57+4Это избегание постановки ненужных задач. Задача вообще решить бизнес-проблему.
Регулярка это хороший способ быстро (по времени разработчика) решить часть из них.
Обертка если и нужна, то нужна не над регуляркой, а над доменной областью. Тут как с ORM -- мы упрощаем доступ к стандартно-структурированным данным, получая одновременно гомогенность и гарантии минимального качества. Когда ORM начинают использовать чтобы конструировать произвольной сложности SQL запросы вместо использования SQL запросов -- это серьёзная протечка абстракции, а не "мы сделали SQL читаемым".
Так и здесь, регулярка -- это упрощение одного из шагов разбора выражения. Когда регулярка перерастает однострочник надо её выкидывать и декомпозировать в грамматику а не в монстроидное дерево вызовов функций.

OldNileCrocodile
19.10.2022 10:46А клиенту и не надо знать код приложения. Написание регулярок - задача программиста. А разбираться, как она работает будут тестировщики. Если там написана фигня- претензии к программисту. Я понимаю, что есть уж совсем маленькие компании, где нет отдельного штата тестировщиков, и отдел разработки занимается несколькими задачами одновременно. Тут программист может подложить свинью коллегам.

FanatPHP
17.10.2022 11:17Бывает нечто, о чем говорят: "смотри, вот это новое"; но это было уже в веках, бывших прежде нас. Эккл. 1:10
Сказать по правде, уже известное решение, с его действительно читабельным
const myRegex = SuperExpressive() .startOfInput .optional.string('0x') .capture .exactly(4).anyOf .range('A', 'F') .range('a', 'f') .range('0', '9') .end() .end() .endOfInput .toRegex();выглядит куда более стройным и последовательным, чем все эти метания между константами и функциями. Но даже и оно как-то не особо популярно. РНР форк вообще не взлетел. О причинах можно гадать, но факт налицо — попытки улучшить регулярные выражения не находят отклика у программистов.
ganqqwerty Автор
17.10.2022 11:26Неплохое, сейчас добавим! Тут, наверное, та же ситуация, что и с другими библиотеками – не хочется тащить ее в код, если в проекте регулярок меньше пары десятков, но вполне можно – если их много, а сменяющие друг друга программисты уже стонут.

ionicman
17.10.2022 11:30+1а сменяющие друг друга программисты уже стонут
А привнесение еще одного синтаксиса еще одного не стандартного фреймворка вместо стандарта, стоны, конечно-же, прекратит )

musk
17.10.2022 11:35+3Даже если вы декомпозируете пример с датой из начала статьи, конструкция
(0[1-9]|[12][0-9]|3[01])- это плохой и невкусно пахнущий код. Выковыряйте чиселку года вульгарным\d{1,4}Это как раз-таки вполне здравый подход в данном случае в рамках применения регулярок, а ваши дополнительные проверки в коде как раз и есть плохой и невкусно пахнущий код.
Регулярки на то и регулярки, чтобы ими оставаться. А вы превратили относительно просто читаемое выражение в вырвиглазный псевдоскрипт, который малопереносим, да и сложен в проверке в каком-нибудь regex101. Вы с тем же успехом поучите математиков формулы писать. Вполне достаточно давать понятные имена самое переменной, использовать именованные группы или разбивку по строкам.ganqqwerty Автор
17.10.2022 11:40Мне не понятна ваша логика. Моя логика такая: проверка того, что выковырянное значение года больше нуля и меньше
3000- это численная проверка. Натягивать на нее текстовый метод, пользуясь тем, что наш способ записи чисел таков – это применять инструмент не по назначению.Вот если бы надо было проверить, что 988 год будет записан как
0988или что 8 марта записывается не как8.3, а как08.03- тогда да, это явно текстуальная вещь, регэкспы очень в тему.datacompboy
17.10.2022 11:47+4это не численная проверка а минимизация срабатываний.
ganqqwerty Автор
17.10.2022 11:51Ммм, о чем речь? Не слишком понял.
datacompboy
17.10.2022 12:00+1в тексте можно встретить много цифр самых разнообразных. задание 0[1-9]|[12][0-9]3[0-1] лучше чем \d\d просто потому, что минимизирует выкусывания не-дат. да, это не гарантия, это просто микрооптимизация, чтобы не кусать лишнего.
musk
17.10.2022 14:25+1Это потому что вы смешали теплое с мягким. Тема была о декомпозиции регулярных выражений, и в рамках их применения, да, регулярка тут лучше, чем какой-то странный код, который по факту занимается валидацией, а не сопоставлением, прикидываясь, что этим и занимается. Валидация же может быть любой сложности и далеко выходить за рамки поиска.

nivorbud
17.10.2022 11:39Опять эти войны остроконечников с тупоконечниками... Ни к чему это. Оба подхода имеют право на жизнь. Да, приведенные в статье примеры (статичных по сути) регулярок нет смысла декомпозировать в переменные/функции. Но в некоторых сложных случаях без такой декомпозиции не обойтись, особенно когда некоторые данные для регулярок подтягиваются извне и/или когда построение регулярки зависит от разных условий, т.е. когда регулярку надо формировать динамически. Пример: yargy-парсер, основанный на правилах.
ganqqwerty Автор
17.10.2022 11:49-1У меня именно в том пойнт, что в обычном коде, без матлингвистики или построения компиляторов все строчки читаются за 0.5 секунд, а регулярка внезапно читается пять минут. Если это так, с ней не все в порядке, и надо искать способы, чтобы она тоже читалась быстрее.

ValeriyFilatov
17.10.2022 18:09+2Если рассматривать регулярку как "функцию", коей она и является под капотом, то вполне нормально, что на осмысление может потребоваться более "0.5 секунд"

ReinRaus
17.10.2022 17:16+1Сугубо личное мнение (обрабатываю много текста регулярными выражениями и вообще их фанат):
Декомпозиция описанная в статье излишня. Она порождает нагромождение высокоуровневого кода над регулярным выражением.
В большинстве случаев даже для сложных регулярных выражений достаточно использовать именованные группы и форматирование отступами для того, чтобы минимизировать проблемы восприятия регулярных выражений.
Есть исключение: иногда нужно переиспользовать отдельные части регулярных выражений и иметь возможность менять шаблон в одной точке кода. Тогда лучше выделить часть шаблона в отдельную переменную и после этого включать эту часть в другое регулярное выражение через replace, чтобы не смешивать высокоуровневый синтаксис с регулярным выражением:userID = "user\d+"; regex = "^USERID$"; regex = regex.replace( "USERID", userID );

mentin
17.10.2022 19:33+1Для питона есть похожая библиотека
https://github.com/manoss96/pregex
Узнал о ней из вот этой статьи, хорошее описание как она улучшает читабельность
https://towardsdatascience.com/pregex-write-human-readable-regular-expressions-in-python-9c87d1b1335
ionicman
Знаете, все, конечно, ИМХО. Но я занимаюсь регулярками практически с самого их появления, и то, что Вы описали в статье — скорее вред, чем польза.
Обьясню почему — вы привнесли в регулярки еще один язык высокого уровня, который во-первых замедляет их выполнение, во-вторых лишает кроссмплатформенности и быстроты проверки. Да, я понимаю, что можно в конце концов вытащить итоговое выражение и оно будет работать везде — но его еще собрать надо.
Кроме того, большинство программистов привыкли именно к такому виду, который Вы показали в начале статьи + есть огромное количество инструментов для визуализации и работы с регулярками.
Если хочется более-менее порядка и стройности в данных выражениях, то для этого есть флаг PCRE-EXTENDED и после этого у вас появляется возможность использовать пробелы, табуляцию и перевод строки для разделения кусков регулярного выражения, возможность писать комментарии, а если совместить это с именованием групп — то вообще все будет с читаемостью отлично. И при этом никаких лишних сущностей не требуется.
Ну и в результате те, кто применяют регулярки редко точно не будут заниматься тем, что описано в статье, а те, которые с ними работают часто — точно также не будут этого оделать, так как есть стандарт + инструменты + опыт взаимодействия со всем этим — и то, что описано у вас, будет восприниматься как пятая нога.
ganqqwerty Автор
Насчет того, что привыкли – а насколько это ценно? В плюсах раньше триграфами писали - а глядишь, переучились. Можно простую метрику ввести. Берем сто человек, даем им почитать длинную регулярку и декомпозированную. Засекаем время, которое им потребуется для того, чтобы решить типичные задачи программиста: понять/рассказать, что в коде происходит, устранить ошибку, переместить код куда-то, модифицировать поведение и прочее. У меня определенный оптимизм есть насчет результатов.
ionicman
То, к чему привыкли — очень ценно. Привычки, знаете-ли тяжело менять — что в интерфейсах, что в программировании. И если и менять — то должен быть очень веский повод для этого.
В приведенном вами варианте регулярка становится размазанной по коду, начинает зависеть от еще одного языка иперестает быть воспринимаемой как регулярка и читаемости прибавляется только на последнем шаге при сборке — оно того ИМХО не стоит никаким образом, тем более — не стоит того чтобы менять устоявшиеся практики, ибо минусов куда больше, чем плюсов.
aelaa
В современном мире новых программистов приходит больше чем есть привыкнувших. А порог входа таки высокий.
ionicman
В современном мире программисты стараются из кубиков складывать, а в нутро не лезть) Тем более — новые программисты. Есть такие вещи, которые не в тренде — регулярки именно оттуда.
На одной из конференций в 2021 делали опрос про регулярки — примерно 60% их знало, около 35% могли писать что-то, и только около 8% понимали как оно работает. А теперь внезапно возраст — первая группа 18-45, вторая — 20-45, третья 29-45. Так что увы и ах.
Это, естественно, не означает какую-то оценку ума — это лишь означает важность опыта. Я встречал и 18-летнего дева, который в регулярках был, как в своем родном болоте — просто потому, что ему было интересно, и он на системника учился — но это скорее исключение, чем правило.
А вот попытки перетащить то, что надо просто понимать в то, в чем ты уже понимаешь — это как раз черта новых программистов — не в обиду вам будет сказано. Это как вечные попытки натянуть классическое ООП на JS с прототипами, хотя последнее при понимании отнюдь не хуже. Ну и из-за количества этих программистов в конце-концов в JS таки втянули это дело, до регулярок пока не добрались т-т-т )
ganqqwerty Автор
Думаю, что знало там тоже на уровне: знало, что звездочка - это повтор.
aelaa
Программисты уже 70 лет строят высокоуровневые языки поверх низкоуровневых. Олдфагов с хекскодами я не видел уже лет 20 (с ассемблером не сильно меньше), но ворчание их хорошо помню. Но все равно люди будут это делать, потому что удобно всем.
ionicman
Если высокоуровневый язык дает хорошие преимущества — почему бы и нет? Олдфаги здесь не причем, это простая рациональность.
А вот если преимущество сводится лишь к тому «хочу, чтобы было так, как я знаю сейчас и как мне удобно, а как там было до меня — все равно» — это, ИМХО, тупик.
SiteCenter
Поддерживаю, ибо данный жирный плюс полностью нивелирует заявленную в статье "нечитабельность". Жертвовать скоростью выполнения кода и допускать проблемы совместимости ради надуманного удобства написания кода считаю дурным тоном. Пожалуй, единственный случай, когда советы из данной статьи могут быть полезными - это случай, когда регулярки пишутся в простом блокноте
domix32
извините, не удержался
А вот это сильно не правда. В компилируемых языках можно такие конструкции сделать статически вычисляемыми и оно ничем не будет отличаться от того же месива, что и сплошной строке. В каком-нибудь JS почти наверняка в какой-то момент сработает оптимизация hotpath, однако я слабо представляю ситуацию, когда вы с каждым циклом пересобираете регулярку заново. То есть единоразовый вызов сборки регулярки не сказать чтобы сильно замедлит ваш код. Если конечно вы не запускаете эти регулярки на чем-то особенном.
ionicman
Грубо — все это очень сильно зависит от среды и языка — фишка в том, что вполне можно обойтись без этого и вообще не напрягаться по этому поводу.
domix32
В статье примеры на JS, но суть статьи про декомпозицию регулярок, а не про JS.
ionicman
Это было про оптимизацию, которую Вы затронули.
Ну и суть моего комментария тоже не про JS, а про то, что придумывать себе ветряные мельницы, а потом героически с ними бороться — плохо, ибо можно было всего этого избежать и вообще не заморачиваться со всем этим.
Декомпозиция регулярок возможна как стандартными, встроенными методами (о которых я писал в первом комментарии), так и спец. инструментарием, а не дополнительными сущностями на абсолютно другом языке.
domix32
Тогда можно сразу к старой доброй фразе вернуться - если у вас есть проблема и вы решаете её регулярками - у вас две проблемы.
Кстати, про кроссплатформенность пошутил, но забыл спросить, а какие собственно с этим могут быть проблемы? perl/js/c++/вставить свой вариант вроде везде относительно единообразно работают.
ionicman
Регулярки — это хороший инструмент для решения определенного круга задач — если это держать в голове — проблем не будет. В реальной жизни также — попытка отверткой забивать гвозди обычно оканчивается печально.
С кроссплатформенностью тоже есть нюансы — как и любой инструмент — регулярки развивались, мало того, что там существуют как минимум два стандарта, так еще и они внутри могут отличаться — например не поддерживать именованные группы — о чем тут уже было. Не поддерживать просмотр вперед/назад (или даже отмену или включение жадности). Есть очень интересная и крутая фича современных регулярок — рекурсивные регулярки (правда она еще сложнее для понимания, чем обычные варианты) — вот она поддерживается далеко не всеми. Короче, нюансов тоже предостаточно.
domix32
А, ну то есть кроссдвижковость, а не кроссплатформенность.
ionicman
Ну можно и так сказать. Просто платформа для меня — это еще и система, а не только железо. Например второй стандарт до сих пор живет активно именно под *nix-системами, под win его и не встретить щас. Ну а железо может накладывать ограничение на глубину просмотра, а также на кол-во захватываемых групп и тд.
Но вообще, если брать PCRE — то таки да, с небольшими допущениями он практически везде работает одинаково.