
Всем привет! Меня зовут Денис Ежов, я тимлид команды интернет-магазина Спортмастер (далее ИМСМ) и по совместительству бэкенд-разработчик. Так сложилось (и так говорят), что гексагональная структура и DDD — это дорого и сложно. Но так ли это на самом деле? Мы в ИМСМ внедрили гексагональную архитектуру и DDD именно в том количестве, в котором эти подходы решали наши проблемы. Про то, какие у нас были проблемы и как мы их решали, я расскажу в этом посте. Под катом — про назначение бэкенда ИМСМ, история развития бэкенда ИМСМ и его проблемы. А ещё посмотрим, как мы в новой архитектуре постарались решить проблемы бэкенда, покажем примеры кода, а также то, как код ложится на архитектуру.
Назначение бэкенда в ИМСМ
Бэкенд ИМСМ создавался и существует как BFF – Backend for Frontend. Принято считать, что один BFF ориентирован на один пользовательский интерфейс, и это best practice. BFF позволяет выполнять интеллектуальные пакетные вызовы к другим службам и возвращать все данные сразу или более удобные представления данных путем их преобразования и форматирования. Также в результате применения подхода BFF реализуется фронтенд с минимальной логикой.
Вот небольшой пример взаимодействия.
BFF у нас в центре, он светло-синий, с ним взаимодействует браузер.
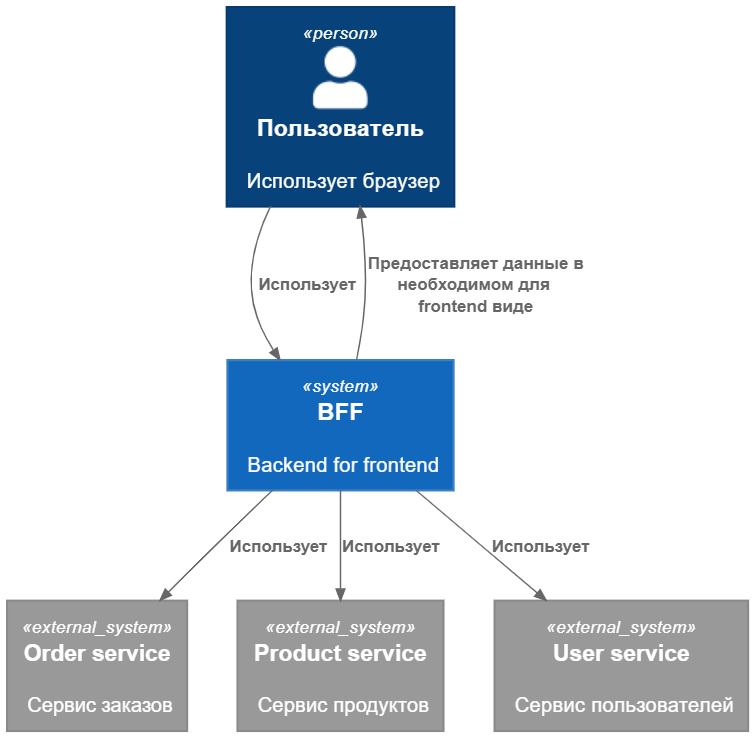
С другой стороны, BFF взаимодействует с внешними сервисами интеграций. Здесь, например, какой-то сервис заказа, сервис продуктов и пользовательский сервис.
Какие есть преимущества у BFF?
Во-первых, разделение обязанностей. Например, требования внешнего интерфейса будут отделены от внутренних задач, что явно проще в обслуживании. Скажем, внутренние сервисы могут предоставлять свое API, интерфейсу требуются какие-то другие данные, соответственно, BFF решает эту проблему, трансформируя данные от внутренних сервисов во внешние.
Во-вторых, проще поддерживать и модифицировать API. Клиентское приложение будет меньше знать о структурах API внутренних сервисов, что делает его более устойчивым к изменениям в этих API.
В-третьих, улучшенная обработка ошибок от внешнего интерфейса. Ошибки сервера в большинстве случаев не имеют смысла для пользовательского интерфейса, например, какие-то ошибки с сервисами интеграции и прочее. Вместо того, чтобы напрямую возвращать отправляемые сервером ошибки, например, ORA-032, BFF может отображать ошибки, которые необходимо показать пользователю. Это, как минимум, улучшает пользовательский опыт.
В-четвертых, несколько типов устройств могут вызывать серверную часть параллельно: пока браузер делает запрос к BFF, мобильные устройства могут делать то же самое. Это поможет быстрее получать ответы от сервисов. Тут речь про то, что у BFF только один клиент, соответственно, для мобильного устройства тоже должен быть свой BFF. Соответственно, нагрузка становится меньше.
В-пятых, улучшенная безопасность: некая конфиденциальная информация может быть скрыта, а ненужные данные для внешнего интерфейса могут быть опущены при отправке ответа на внешний интерфейс. То есть BFF при необходимости скрывает какие-то секретные данные, также нивелирует раскрытие технологий, на который что-то сделано, что, как я сказал, усложняет атаку.
Давайте зафиксируем эти пять пунктов и посмотрим, как они накладываются на то, что у нас было, и на то, что мы делаем сейчас.

Как и ожидаемо, для нового проекта мы всегда все начинаем с нуля в полной надежде на то, что в этот раз мы точно не накосячим, у нас будет поддерживаемый, масштабируемый, легко развиваемый проект. ИМСМ в данном случае не стал исключением, он развивался с нуля, и, как полагается новому проекту, мы считали точно так же. Поэтому небольшая история.
Как создавался ИМСМ

ИМСМ задумывался поначалу как MVP — тестовая версия продукта, услуги или сервиса с минимальным набором функций, иногда даже одной, которая несет ценность для конечного потребителя. MVP создают для тестирования гипотез, проверки жизнеспособности задуманного продукта, насколько он будет ценным и востребованным на рынке. Результаты тестирования минимально жизнеспособного продукта и обратная связь с его аудиторией помогают понять, стоит ли развивать проект дальше, какие изменения следует внести в стратегию, а что оставить в первоначальном виде.
Тут важно подчеркнуть, что у ИМСМ перехода от MVP к production-ready решения не было. В целом, из моего опыта, у меня еще ни разу не было продукта, чтобы MVP было выброшено, весь опыт был аккумулирован, и разрабатывалось приложение заново с полным пониманием того, что нужно. Поэтому здесь произошла та же самая ситуация: изначально все разрабатывалось как MVP в надежде на то, что мы что-то проверим, что-то протестируем, поймем, как лучше и как правильнее, код выкинем и, возможно, что-то улучшим.
Что же мы в реализовали на этапе MVP? Давайте посмотрим на архитектуру MVP по пакетам.

С высоты все выглядит достаточно логично и понятно: у нас есть какой-то пакет сервисов, у которого есть какие-то подпакеты, и есть какой-то пакет репозиториев, у которых есть интерфейсы. Стоит обратить внимание на то, что структура пакетов сервисов была направлена на повторение взаимодействия со сторонними системами интеграции, то есть, когда мы открываем проект бэкенда, мы сразу видим, что у нас есть какие-то сервисы, которые работают с юзером, с продуктом, с персонализацией, с order’ом. Но, тем не менее, уже на том этапе прослеживалась острая необходимость понимания реализуемых сценариев. Среди, казалось бы, стандартных пакетов в сервисах мы обнаруживаем, что наше приложение может делать checkout. С пакетом репозиториев дела обстояли не лучше, каждый интерфейс отвечал за интеграцию с конкретной системой. Так у нас был TerritoryRepository, PersonalizationRepository, CardRepository и прочие. Однако желание и необходимость выделить сценарии или важные понятия уже проявлялось, как, например, TerritoryRepository, ShopRepository и ProfileRepository. Уже на данном этапе в этих интерфейсах можно было встретить до семи методов, что настораживало.
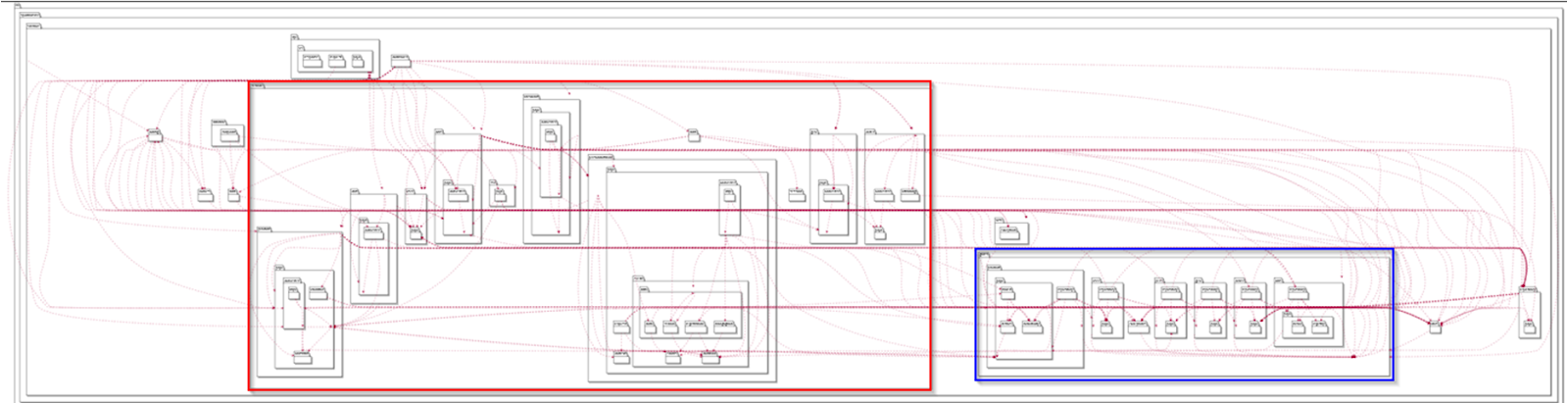
На схеме красным я выделил наш пакет сервисов и синим - реализацию нашего пакета репозиториев. Давайте немного приблизимся к этим пакетам.
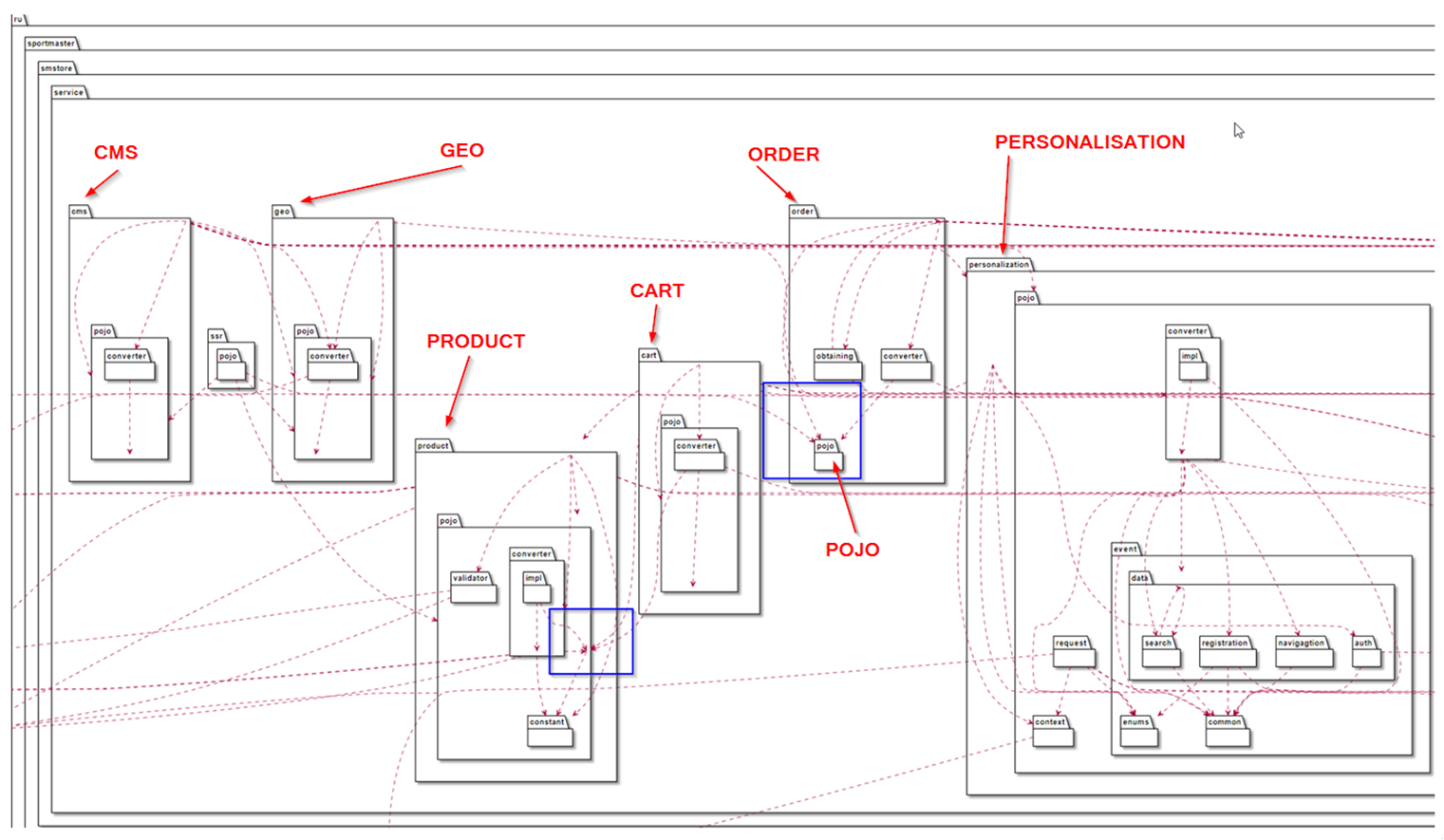
На что стоит обратить внимание в первую очередь? Самое главное - одни пакеты используют сущности других пакетов, это выделено синим, например, пакет Order имеет какую-то Pojo DTO-сущность, которую использует Cart. Если посмотреть, есть еще другие пакеты, которые используются другими пакетами, извиняюсь за тавтологию. Здесь налицо нарушение всем известных SOLID-принципов, о которых мы говорим на собеседованиях и между собой. Давайте вспомним их.
S - принцип единой ответственности - объединяйте вещи, изменяющиеся по одним причинам, разделяйте вещи, изменяющиеся по разным причинам. На нашей схеме мы видим, что, если мы захотим поменять какую-то Pojo или DTO в одном пакете, например, Order, это сразу зааффектит другие пакеты, которым, казалось бы, это изменение не нужно.
O - Принцип открытости и закрытости: модуль должен быть открытым для расширения, но закрытым для изменения. Сталкиваемся с точно такой же ситуацией: если нам нужно что-то откорректировать, это зааффектит и другие пакеты.
L - Принципа Барбары Лисков касаться не будем, на такой высоте не видно нарушения такого принципа, но рассмотрим его уже при работе с исключениями.
I - Принцип разделения интерфейса — некоторые репозитории и сервисы уже содержали до семи методов, соответственно, если бы мы захотели реализовать какое-то другое поведение, для чего и предназначен интерфейс, у нас были или заглушки, или исключение Java UnsupportedOperationException.
D - Принцип инверсии зависимостей — достаточно сложно в этой схеме понять, какой пакет должен или не должен зависеть от другого пакета и насколько нужны эти зависимости. Выглядит так, что, если у тебя есть возможность создать класс, неважно, в каком пакете, мы его можем смело создать. Принцип инверсии зависимостей говорит о том, что необходимо направлять зависимости согласно абстракциям, высокоуровневые модули не должны зависеть от низкоуровневых модулей. Здесь непонятно, какой из пакетов высокоуровневый, какой низкоуровневый, все находится на одной линии и могут создавать и использовать эти классы кто угодно.
А такие проблемы у нас были с архитектурой на конкретных примерах.
Проблемы
№1
Использование одного и того же понятия в разных сценариях, отсюда как проблема — невозможно определить обязательности поля и его валидации для разных сценариев использования. Валидации для разных сценариев использования мы коснемся немного позже, когда будем говорить о работе с исключениями и валидации в целом. Обратите внимание, что у нас есть конвертер, который из каких-то разных объектов формирует, казалось бы, одинаковый заказ, но, к сожалению, у нас заполняется profileid и contactUser как null в одном конвертере, но и заполняется profileid и contactUser уже из нашего интеграционного сервиса непосредственно.

Понять, в каком сценарии, в каком API нужно одно поведение и другое, достаточно сложно без детального анализа и погружения во всю цепочку вызовов. Любое изменение этого заказа также может вызывать дополнительный анализ: что упадет, если вдруг мы это поле сделаем не null или наоборот.
№2

Сильное связывание. Контракт другого сервиса проникает на уровень логики, что делает зависимым логику от него. В данном случае это как раз OrdersRepositoryConverter, мы берем контракт сервиса и пытаемся его преобразовать в какой-то заказ, непонятно для чего этот заказ, для какого сценария. Непонятны сценарии использования, неясный контракт и разделяемые понятия.
Часть интерфейсов хранилищ возвращала оригинальные DTO сторонних сервисов, что способствовало сильной связности и зависимости от сервисов интеграции. Здесь стоит сказать пару слов о том, что такое оригинальные DTO сервисов и сильная связанность с сервисами интеграции.
У нас на бэкенде ИМСМ все DTO и вся интеграция с сервисами генерируется по спецификации этих сервисов. Соответственно, самый низкий уровень, через который мы взаимодействуем с гейтами, это те самые DTO, которые получаются из сервисов. Происходило так, что, например, для какого-то сценария нам требовалось три поля, вместо этого вся DTO, которая содержала 15 полей, еще три вложенный списка и прочее, долетала до самой бизнес-логики. На этой схеме уже видно, что наш сервис, казалось бы, с бизнес-логикой, принимает в себя интерфейс репозитория и обязательно интерфейс конвертера.
Это значит, что этот сервис уже знает о DTO, уже передает их, получает из репозитория, чтобы сконвертировать, и прочее. Раскрывается вся инкапсуляция, от которой мы хотели избавиться, потому что, если ты передаешь в какой-то метод объект, который содержит восемь полей, ты ожидаешь, что эти восемь полей нужны. Если вдруг придет бизнес-задача убрать какие-то два поля или добавить два поля, тебе придется провести анализ того, как эти поля используются. Хорошо, если они не используются. Если они используются просто потому, что они передаются, это еще более усложняет процесс соответственно, время на разработку, на рефакторинг, на реализацию нового функционала также будет увеличиваться.
№3

Интерфейсы репозиториев вынесены в отдельный пакет без уровней вложенности, этот как раз то, что мы видели несколько слайдов назад, и оперируют доменными объектами и исключениями, которые находятся в другом пакете. Вот яркий пример: у нас есть два сервиса, обратите внимание, в каких пакетах они находятся. Один находится в пакете user, другой — в пакете auth. Оба сервиса, в которых зачастую располагается бизнес-логика, оперируют хранилищем ProfileRepository, которое на тот момент уже имело 14 методов. Более того, оба этих сервиса используют единственный метод, который возвращает ProfileByLogin.
Отсюда возникает вопрос: что будет, если, например, для UserGateService ProfileByLogin какое-то поле будет допускать null, для сервиса AuthServiceImpl это поле не будет допускать null? Здесь может появиться конкуренция, так как это разные поля для разных сценариев. Соответственно, это возможный технический долг, который нужно будет устранять.
№4
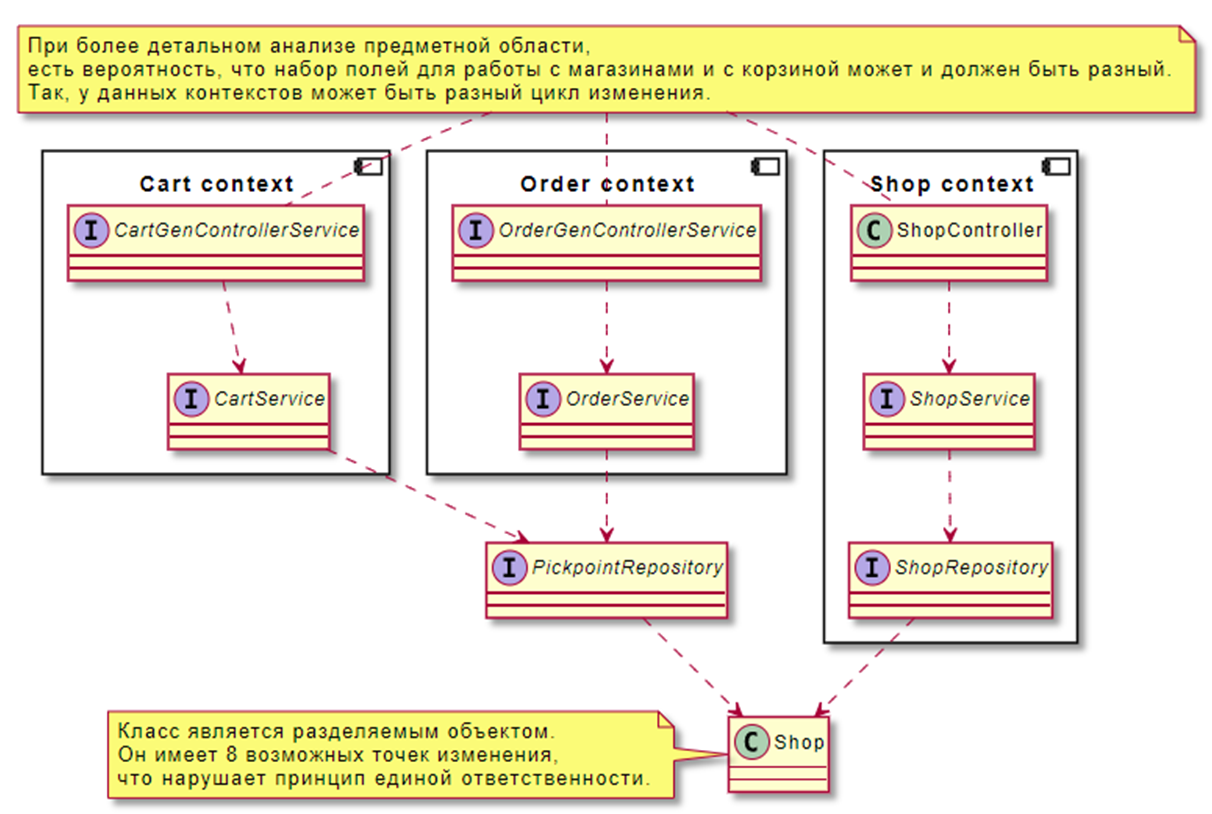
Но и это ещё на всё. Общий доменный объект. Проблема похожа на предыдущую, но здесь ситуация хуже. При более детальном анализе предметной области есть вероятность, что набор полей для работы с магазинами и с корзиной может и должен быть разным, так как у данных контекстов может быть разный цикл изменения. В данном случае класс Shop является разделяемым объектом, он имеет восемь возможный точек изменения, что нарушает, как минимум, принцип единой ответственности, то есть любой бизнес-сценарий пришедший к нам из любого контекста, будь то корзина, заказ, магазин, может повлиять на Shop, причем на какое-то поле, которое используется в другом контексте. Здесь мы попадаем в гонку с тем, какое поле от чего зависит, какое поле должно быть, что, опять же, добавляет технического долга в перспективе и сложности в развитии данного функционала.
Давайте посмотрим, как та архитектура, которую я вам сейчас показал, соответствует целям BFF.

Красным здесь отмечены пункты, которые не удовлетворяют условиям, пункты 4 и 5 удовлетворяют. Разделения обязанностей по сути не было, у нас отсутствует выраженный сценарий использования, создается большое количество связей и возникают God объекты, на примере того же Shop ProfileRepository и прочих классов. Пусть вас не удивляет то, что я описал так мало примеров, но это яркие примеры большого количества кейсов, то есть не было смысла дублировать кейсы с похожими проблемами.
Что интересно, на момент создания наше приложение уже соответствовало четвертому и пятому пунктам, которые не зависят от архитектуры самого приложения, а зависят от того, что оно создается как BFF.
Архитектура
Какие виды архитектуры мы рассматривали? На самом деле, как такового выбора архитектуры с выписыванием плюсов, минусов, сравнением не было. Самым важным для нас была поддержка архитектурой всех пяти требований BFF. Было решено использовать несколько практик, а именно гексагональную архитектуру, кричащую архитектуру и DDD. Почему? У меня в практике уже применялась гексагональная архитектура и DDD, я уже создавал приложения и мог объяснить, где и как лучше использовать и какие проблемы это решает.
Что такое гексагональная архитектура?

Это та самая картинка, которая путешествует по интернету. Какие у нее есть плюсы? Направления зависимостей, поддержка сценариев, легкое расширение функционала и единый аргументированный подход, что не менее важно, чем предыдущие три пункта. Термин «гексагональная архитектура» был введен Алистером Коберном, и основное назначение этой архитектуры в том, что она позволяет взаимодействовать с приложением как пользователю, так и программам, автоматическим тестам, скриптам пакетной обработки, также позволяет разрабатывать и тестировать приложения без каких-либо дополнительных устройств или баз данных.
Чего мы хотели добиться, внедрив гексагональную архитектуру? Самое главное — чтобы изменение в одной части приложения как можно меньше затрагивало (или вообще не затрагивало) другие части приложения, только если они действительно сцеплены между собой. Добавление нового функционала не должно требовать каких-то масштабных изменений в коде, организация нового интерфейса для взаимодействия с приложениями, должна приводить к минимально возможным изменениям приложения. Отладка должна включать как можно меньше временных решений и хаков. Тестирование должно происходить относительно легко, стараемся сделать наше приложение более простым в поддержке.
В следующей части поста мы подробнее поговорим про гексагональную архитектуру, её фундаментальные блоки и многое другое.