
Мы уже как-то рассказывали о базе данных KeyDB — форке Redis, разработка которого началась в 2019 году. Проект распространяется под свободной лицензией BSD, и у него уже почти 6k звезд на GitHub. Авторы в свое время столкнулись с проблемами производительности оригинала и пошли хардкорным путём: взяли всё в свои руки и привнесли много нового как в части многопоточности, так и в других областях.
В статье делимся еще одним положительным опытом замены Redis на KeyDB.

В одном из клиентских проектов у нас довольно нагруженный Redis. Поначалу мы использовали spotahome/redis-operator для реализации Redis Failover в режиме master/slave. Но с ростом проекта стали банально упираться в гигабитную сеть на узле с master-Redis'ом: независимо от количества реплик, вся нагрузка всегда приходилась на мастер-узел, а реплики были «на подхвате».
Тогда мы решили переехать на Redis-кластер: ключи шардируются между несколькими master'ами, у каждого master'а есть реплики. Это избавило от проблемы с сетевой загрузкой, так как данные расползлись по нескольким шардам, и нагрузка, соответственно, тоже распределилась.
Казалось бы, вопрос с ресурсами был закрыт надолго (на такой схеме мы проработали около года). Но беда пришла, откуда не ждали.
Проблема с однопоточностью Redis
После переезда сервиса из одного дата-центра в другой, приложение на PHP вдруг стало работать медленно. Одно из подозрений упало на время ответа Redis, хотя, на первый взгляд, с ним все было неплохо.
Для проверки написали простой тест, эмулирующий работу PHP-приложения с Redis:
<?php
$start=microtime(true);
$redis = new RedisCluster(NULL, Array('redis-cluster:6379'));
$key='test'.rand(0,10000);
$redis->set($key,'test_data',10);
$redis->get($key);
echo (microtime(true)-$start)."\n";Погоняли тест, и результат получился неожиданным — иногда Redis действительно отвечал медленно:
0.003787
0.144506
0.007667
0.005908
0.00354
0.003886
0.006331
0.193661
0.222443
0.00558
0.0029Присмотревшись к проблеме внимательнее, мы обнаружили, что master одного из шардов потребляет почти 100% ресурсов одного ядра. Тут уже вспомнилось, что Redis однопоточный, а значит он просто не может обработать больше запросов.
В новом дата-центре мы переехали на другое железо, в целом более мощное. Но производительность на одно ядро у новых процессоров ниже, чем у предыдущих — ранее были «железные» Intel(R) Xeon(R) CPU @ 3.40GHz, а теперь — vSphere с Intel(R) Xeon(R) Gold 6132 CPU @ 2.60GHz. В результате именно это и вылилось в задержки при обращении к некоторым ключам в Redis'е, а также в целом в работе приложения.
Так это выглядело на машинах в исходном кластере (здесь и далее по оси ординат — используемые процессом ядра CPU):
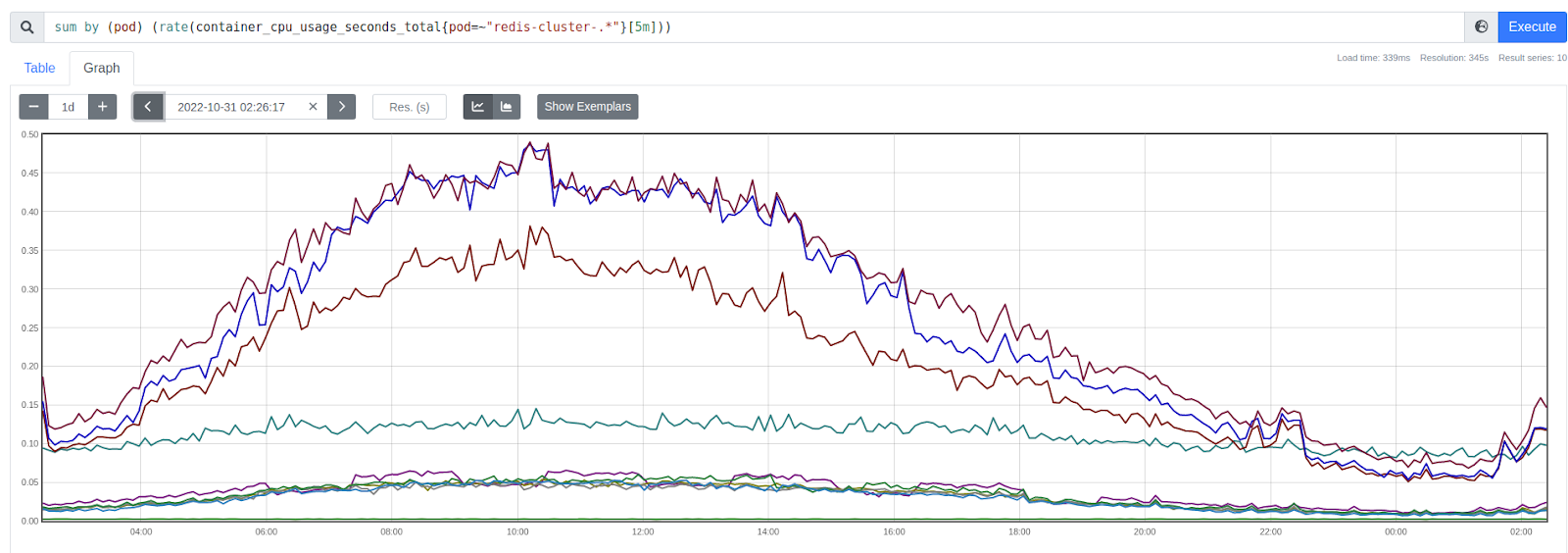
А так — в новом, когда пришла полноценная нагрузка:
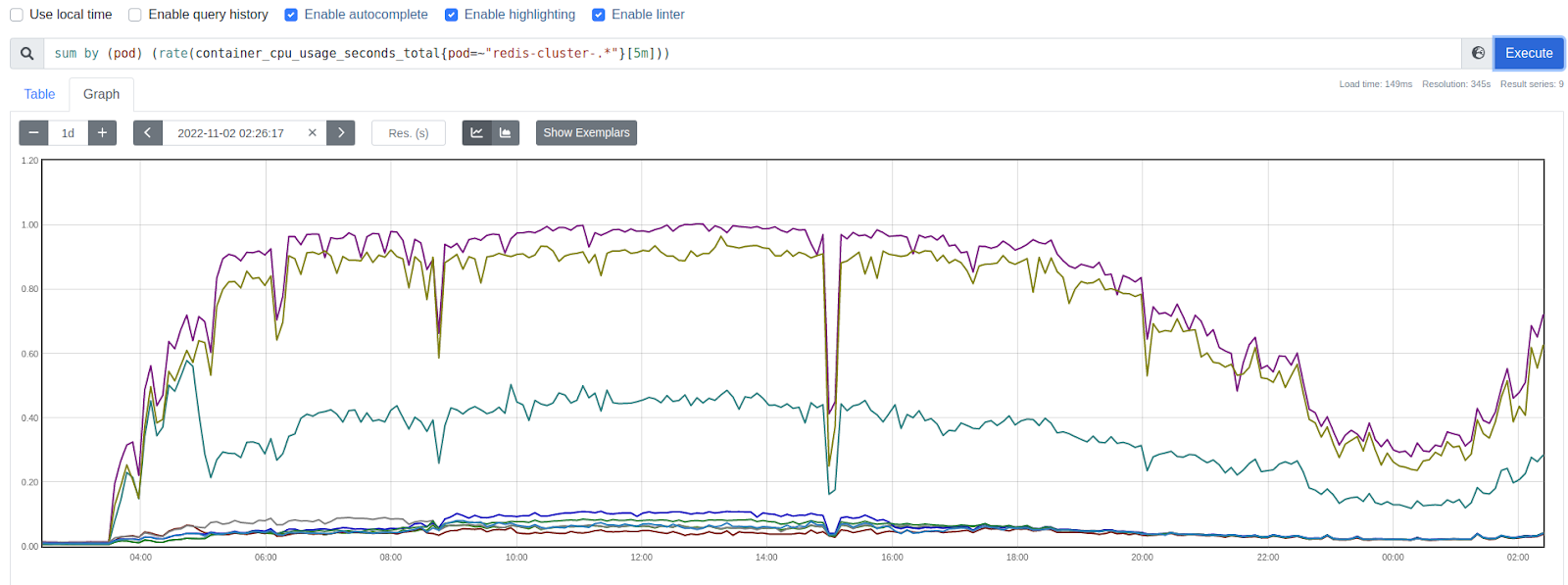
Решение
Что делать?
Проект под нагрузкой, Redis с данными довольно большой, решардировать его сходу проблематично.
Пришла идея попробовать заменить его на KeyDB. Просто взять и поменять образ redis в контейнере Kubernetes на keydb — должно сработать, ведь разработчики KeyDB заявляют, что структура данных Redis поддерживается без изменений.
Для начала провели опыт в тестовом окружении: в кластер Redis'а записали сотню случайных ключей, заменили образ в контейнере на образ eqalpha/keydb, а команду запуска — с redis-server -c /etc/redis.conf на keydb-server -c /etc/redis.conf --server-threads 4. Затем перезапустили по одному Pod'ы (кластер запущен как набор StatefulSet c updateStrategy OnDelete).
Контейнеры перезапустились по одному, подключились к кластеру и синхронизировались. Все данные на месте: сотня тестовых ключей, которые мы записали в кластер Redis'а, прочиталась из кластера KeyDB.
Все прошло успешно, поэтому мы решились проделать то же самое и с рабочим кластером. Поменяли образ в конфигурации, подождали, пока обновятся Pod'ы и стали наблюдать за временем ответа от всех шардов — теперь оно стало одинаковое для всех.
На графике видно, что новые «Redis'ы» потребляют более одного ядра:
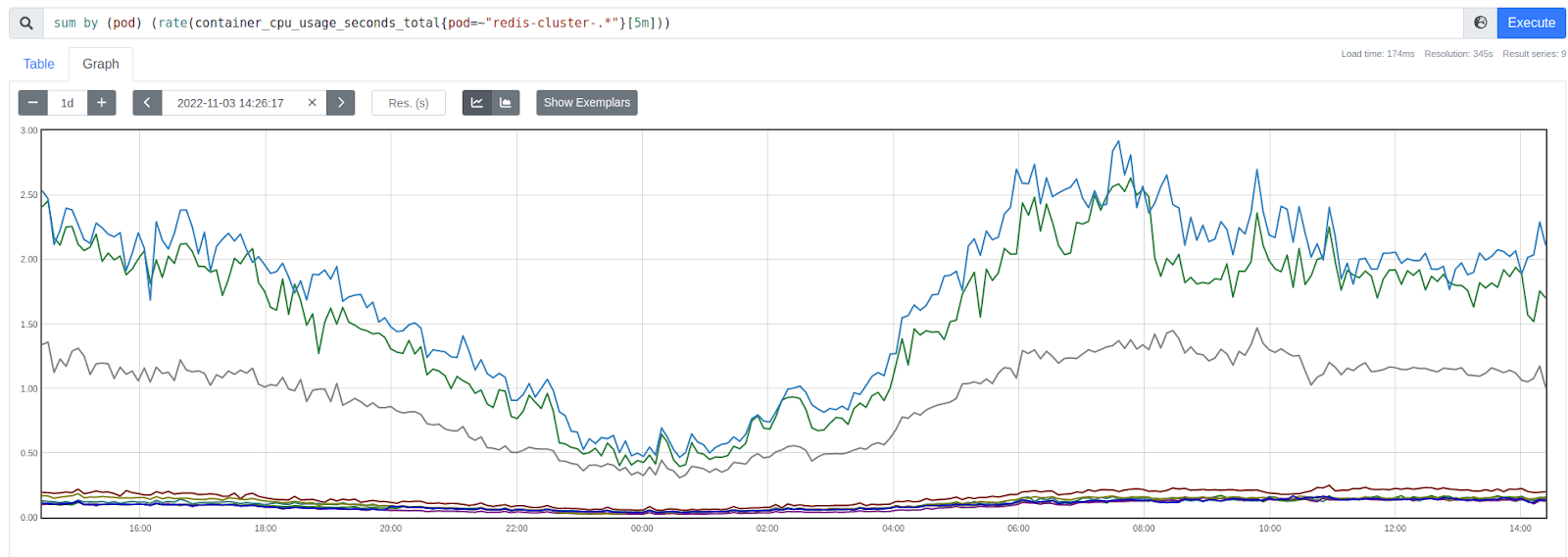
Мониторинг задержек
Чтобы в дальнейшем мониторить скорость ответа Redis-кластера, мы написали небольшое приложение на Go. Раз в секунду оно обращается к кластеру и помещает в него ключ со случайным именем (можно сконфигурировать префикс имени ключа) и TTL 2 сек. Случайное имя использовано для того, чтобы попадать в разные шарды кластера и сделать результат более приближенным к работе реального приложения. Время, затраченное на операцию соединения и записи, сохраняется. Хранятся 60 последних измерений.
В случае, если операция записи не удалась, увеличивается счетчик неудачных попыток. Неудачные попытки не учитываются при расчете среднего времени ответа.
Приложение экспортирует метрики в формате Prometheus: максимальное, минимальное и среднее время операции за последние 60 сек., а также количество ошибок:
# HELP redis_request_fail Counter redis key set fails
# TYPE redis_request_fail counter
redis_request_fail{redis="redis-cluster:6379"} 0
# HELP redis_request_time_avg Gauge redis average request time for last 60 sec
# TYPE redis_request_time_avg gauge
redis_request_time_avg{redis="redis-cluster.:6379"} 0.018229623
# HELP redis_request_time_max Gauge redis max request time for last 60 sec
# TYPE redis_request_time_max gauge
redis_request_time_max{redis="redis-cluster:6379"} 0.039543021
# HELP redis_request_time_min Gauge redis min request time for last 60 sec
# TYPE redis_request_time_min gauge
redis_request_time_min{redis="redis-cluster:6379"} 0.006561593График с результатами:
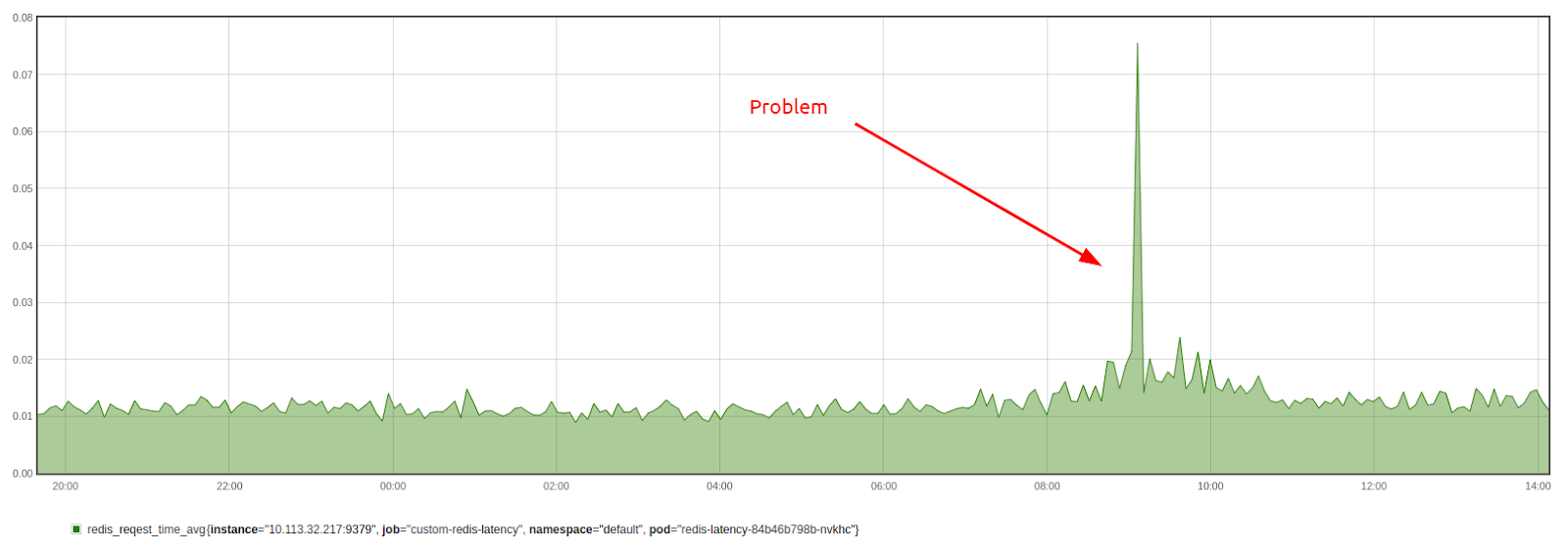
Если запустить тестовое приложение на нескольких или всех узлах кластера, можно увидеть, есть ли зависимость задержек от узла: например, на узле может быть перегружена сеть.
Код приложения доступен в репозиториии. Также можно воспользоваться подготовленным Docker-образом.
Стоит обратить внимание, что в Redis есть метрики по спайкам, которые можно включить командой:
CONFIG SET latency-monitor-threshold 100Но это видение метрики со стороны Redis, а мы хотим наблюдать время ответа и со стороны приложения.
Многопоточность в Redis
В Redis 6 уже реализована многопоточность, впрочем, судя по описанию, не так эффективно, как в KeyDB или Thredis. Для активации этого режима нужно добавить параметр io-threads 4. Прием запросов, парсинг, обработка и отправка будут происходить в разных потоках. Это может быть полезно, когда размер ключей очень большой: в однопоточном режиме Redis не будет принимать и обрабатывать новые запросы, пока не будет отправлен ответ на предыдущий запрос.
Детальное сравнение производительности Redis и KeyDB в многопоточном режиме представлено в официальной документации KeyDB. Согласно результатам, KeyDB демонстрирует значительный прирост производительности по сравнению с Redis по мере того, как становится доступно больше ядер. Даже с многопоточным вводом-выводом Redis 6 по-прежнему отстает от KeyDB из-за более низкой способности к вертикальному масштабированию.
Итог
Мы еще раз проверили и убедились, что в сложной ситуации Redis можно масштабировать вертикально, просто заменив его на KeyDB. У такого способа нет сложных подводных камней, поскольку KeyDB — это форк Redis’а, и он должен без проблем подхватывать данные от оригинального проекта.
Также благодаря разбору ситуации мы написали полезный экспортер и алерты на основании метрик от него. Это поможет более точно диагностировать проблемы и заранее их предотвращать.
P.S.
Читайте также в нашем блоге:
Комментарии (17)

datacompboy
25.11.2022 12:18Ммм... А что за линии на графиках? Одна линия на один под редиски?
Распределение нагрузки выглядит как-то оч не оч. Шардинг по хешу ключа или по подстроке ключа в лоб?

trublast Автор
25.11.2022 23:03+1Шардинг по хэшу ключа.
Из документации: The base algorithm used to map keys to hash slots is the following (read the next paragraph for the hash tag exception to this rule) HASH_SLOT = CRC16(key) mod 16384
На графиках видно 3 нагруженных мастера (один из них действительно чуть менее нагружен, чем два других) и 6 почти бездействующих реплик.
Шардинг по хэшу ключа позволяет как-то более или менее равномерно распределить ключи между шардами - количественно, но не частоту обращений к ним.
Вероятно есть какие-то ключи, которые заметно более популярны, чем какие-то другие. Или значения ключей заметно большего размера.
Можно пораспределять слоты между шардами (мастерами), как-то их подвигать, чтобы выровнять нагрузку на мастеры. Но я большого смысла не вижу, будут другие ключи - и картинка поменяется.
datacompboy
26.11.2022 02:58Хэг не оч, но да, вероятно недостаточно нагрузки чтоб размазать небалансные ключи. Наверное, локальный кеш бы помог на стороне апплы, но нафиг при этой нагрузке

n_bogdanov
25.11.2022 13:11+2Коллеги, а в каких сетапах тестировали KeyDB? Мы пробовали внедрить Active-Active, но кластер разваливался даже на Stage под E2E тестами. Такое чувство, что multi-master, который заявлен как одна из фич keyDB, просто не работает.
В статье вижу, что просто заменили Redis на KeyDB в готовом Redis Cluster. Соответственно, как я понимаю, модель записи и работы с Shard у вас не поменялась.
trublast Автор
25.11.2022 22:34+2В описанном в статье кейсе в итоге остался Redis Custer ( шарды + реплики), keydb задействовали чтобы выйти за лимит в 1 ядро без перешардирования.
Из документации я так и не понял, как для Keydb Cluster включить active-active (хотя очень хотелось, что-то подобное). Казалось бы, что каждый шард - это мастер с набором реплик, почему бы нет. Но нигде не описано, что такая конфигурация возможна, разе что взять и попробовать.
Вообще, так как из редиса идет в основном чтение, можно на клиенте включать READONLY для запросов чтения. Тогда можно будет читать в том числе из реплик, и таким образом снизить нагрузку на мастеры. Но это нужно дорабатывать приложения, работающие с redis. А режим active-active решил бы эту проблему прозрачно для приложения. Но увы...

Eremite_b
26.11.2022 21:19Так, в итоге, я так понял, не стоит Redis не стоит менять на Keydb пока.
trublast Автор
27.11.2022 09:00Зависит от ситуации наверное.
Если вы упираетесь в одно ядро на существующем редисе и при этом не хотите особо заморачиваться с шардированием редиса в несколько инстансов по разным ядрам - можно просто запустить бинарь keydb-server вместо redis-server на той же конфигурации, и доутилизировать другие ядра (если они есть конечно)
Остальное конечно требует исследований, однозначных ответов "кто лучше" конечно не существует.

Artarik
25.11.2022 18:46+1какую версию keydb использовали? Для 6.3.1 уже больше месяца висит issue, о проблемах с производительностью
trublast Автор
25.11.2022 22:38+1Использовали 6.3.1 , и она показала лучшую производительность, чем редис 6.0.2 Может не на ядро, но в совокупности на том же железе сервис стал работать лучше.
Про issue хороший поинт, может имеет смысл откатиться на 6.2.2, но на данный момент проблем с производительностью не испытываем.

andreyverbin
26.11.2022 00:37Почему нельзя запустить столько redis, сколько ядер на сервере? Ключи растекаться на каждый из них, нагрузка выровняется и все будет хорошо, в теории. Интересно мнение практиков.

LaserPro
26.11.2022 07:14можно, более того, именно это и советуют на официальном сайте Redis, в ответ на критику со стороны разработчиков многопоточных форков. И в ответ приводят бенчмарки, в которых видно что правильно приготовленный Redis даже быстрее конкурентов
См. тут https://redis.com/blog/redis-architecture-13-years-later/

Ninako
28.11.2022 09:51"В одном из клиентских проектов" - этот проект случайно не состоит из двух слов на "Л" и "О"?
HapH
А не пробовали Dragonfly https://github.com/dragonflydb/dragonfly ? По их тестам он еще быстрее, чем KeyDB, при этом тоже совместимое API
150Rus
У меня на домашнем компьютере dragonfly в 2 раза медленнее чем redis и в 1.8 раза медленнее чем keyDB. Тестил на set, get, rpush, lrange без pipe. Запускал через докер.
upd. на всякий случай сбилдил, всё равно медленно.
LaserPro
Про совместимость API:
> Из возможностей, доступных в первом выпуске DragonFly отмечается поддержка протокола RESP2 и 130 команд Redis, что примерно соответствует функциональности выпуска Redis 2.8
Это было полгода назад. Разработчики постепенно добавляют поддержку команд из более новых версий Redis, но о полной совместимости говорить рано.
Про быстродействие:
По бенчмаркам команды Redis (ниже приводил ссылку на офсайт), они быстрее чем DragonFly. При этом они конечно запускали не один инстанс Redis на многопоточном процессоре, а несколько.
А вот еще одно небольшое сравнение redis vs keyDB, и тут тоже не вышло превосходства keyDB в 5-25х маркетинговых раз.