
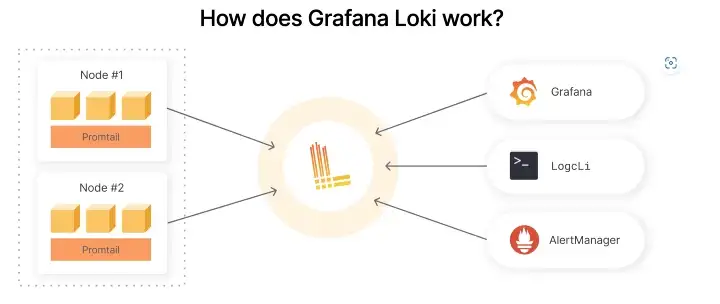
В ходе этой статьи мы развернём следующий стек инструментов Observability (наблюдаемости) Grafana:
- Loki (логи);
- Promtail (агент логов);
- Tempo (трассировка);
- Prometheus (метрики);
- Cortex и Grafana Mimir (долгосрочное хранилище для данных Prometheus);
- Alertmanager (обработка оповещений Prometheus);
- Grafana (визуализация).
Приступим!
Что потребуется
- Кластер Kubernetes (я использую Kind). Я уже писал (англ.) о том, как настраивать Kind с помощью Terraform.
- Kubectl и Helm.
Что такое наблюдаемость?
Наблюдаемость (observability) позволяет нам понять систему снаружи, не вникая в её внутренние механизмы.
Иными словами, она даёт ответ на вопрос: «Как себя ведёт наша система?»
Loki
Loki: подобен Prometheus, только для логов.
Отличие Loki от Prometheus в том, что он ориентирован не на метрики, а на логи, и доставка осуществляется по модели
push, а не pull.Стек логирования на основе Loki состоит из трёх компонентов:
-
promtailвыступает агентом, отвечающим за сбор логов и их отправку Loki. -
lokiявляется основным сервером, отвечающим за хранение логов и обработку запросов. - Grafana отвечает за запросы и отображение логов.
После развёртывания Loki будет выглядеть так:

Для запроса логов нужно быть знакомым с LogQL. Сам формат запроса выглядит так:
{job="mysql"} |= "error" != "timeout"Наглядные примеры использования можно найти в документации.
В нём также есть визуальный инструмент, который можно использовать, если вы не хотите писать запросы сами. Если выбрать Log browser, то он предоставит несколько специализированных лейблов, из которых в моём случае я выбираю namespace.
В результате он показывает мне список пространств имён, существующих в моём кластере Kubernetes.

После выбора своего пространства имён я кликаю по Show logs, выводя все логи этого пространства.
▍ Live tailing
Loki поддерживает функцию Live tailing, отображающую логи системы в режиме реального времени. Включить её можно в верхнем правом углу интерфейса.

▍ Promtail
Promtail – это агент, передающий содержимое локальных логов в закрытый инстанс Grafana Loki или Grafana Cloud. Обычно он развёртывается на каждой машине, где есть приложения, требующие мониторинга.
Его основные задачи:
- обнаружение целей;
- назначение лейблов потокам логов;
- их передача в инстанс Loki.
На данный момент Promtail может собирать логи из двух источников:
- локальных лог-файлов;
- журнала systemd.
▍ Развёртывание Loki
Прежде чем начать, давайте создадим отдельное пространство имён Kubernetes для нашей конфигурации:
kubectl create ns observabilityЛучшей практикой считается организация кластера K8s с помощью пространства имён. Подробнее почитать об этом можно здесь (англ.).
Клонируйте Helm-чарты сообщества Grafana на свою рабочую станцию:
git clone https://github.com/grafana/helm-chartsПерейдите в каталог
loki-stack:cd helm-charts/charts/loki-stackВ файле readme мы видим, что можно развернуть Loki с предустановленной конфигурацией:
helm upgrade --install loki . -n observabilityВывод должен выглядеть так:
NAME: loki
LAST DEPLOYED: Fri Sep 23 17:20:34 2022
NAMESPACE: observability
STATUS: deployed
REVISION: 1
NOTES:
The Loki stack has been deployed to your cluster. Loki can now be added as a datasource in Grafana.Если у вас возникает следующая ошибка:
Error: INSTALLATION FAILED:
An error occurred while checking for chart dependencies.
You may need to run `helm dependency build` to fetch missing dependencies: found in Chart.yaml, but missing in charts/ directory: loki, promtail, fluent-bit, grafana, prometheus, filebeat, logstashВыполните:
helm dependency buildТеперь проверьте, запущены ли поды:
kubectl get pods -n observabilityВывод:
NAME READY STATUS RESTARTS AGE
loki-0 1/1 Running 0 7s
loki-promtail-xvhn5 1/1 Running 0 7sLoki развёрнут :)
Перейдём к Tempo.
Tempo
Grafana Tempo – это открытый и удобный в использовании инструмент трассировки. Он отличается высокой эффективностью, требуя для работы лишь объектное хранилище, и при этом глубоко интегрирован с Grafana, Prometheus и Loki.

Интеграция с остальным стеком Grafana очень важна, поскольку позволяет переходить напрямую из Logs (извлекая ID трейса из Loki) в Traces (хранящиеся в Tempo). Помимо этого, вы сможете использовать тот же язык запросов, что упростит получение трейсов.
Если вы уже используете Grafana, Prometheus и Loki, то есть смысл дополнительно подключить к ним Tempo для трассировки данных.
Tempo можно использовать с любым из открытых протоколов трассировки, включая Jaeger, Zipkin и OpenTelemetry.
Это означает, что он может получать пакеты трейсов в любом из упомянутых форматов, буферизовать их и затем записывать в Azure, GCS, S3 либо на локальный диск, делая доступными для запроса через Grafana.
▍ Развёртывание Grafana Tempo
Мы будем использовать тот же репозиторий, что и для развёртывания Loki. Потребуется лишь перейти в каталог
tempo:cd helm-charts/tempoРазвёртывание Tempo с помощью Helm:
helm upgrade --install tempo . -n observabilityВывод должен выглядеть так:
NAME: tempo
LAST DEPLOYED: Fri Sep 23 17:26:22 2022
NAMESPACE: observability
STATUS: deployed
REVISION: 1
TEST SUITE: NoneПроверим, запущены ли поды:
kubectl get pods -n observabilityВывод:
NAME READY STATUS RESTARTS AGE
loki-0 1/1 Running 0 7s
loki-promtail-xvhn5 1/1 Running 0 7s
tempo-0 2/2 Running 0 74sTempo развёрнут :)
Переходим к Prometheus и Grafana.
Prometheus
Prometheus – это продукт Cloud Native Computing Foundation, который представляет собой инструмент для мониторинга систем и сервисов. Он собирает метрики с установленных целей через заданные интервалы времени, оценивает правила, выводит результаты и может активировать оповещения при выполнении указанных условий.

По умолчанию время хранения данных в Prometheus составляет всего 15 дней, что приводит нас к Cortex и Grafana Mimir, которые обеспечивают для него возможность долгосрочного хранения.
Cortex и Grafana Mimir
▍ Cortex
Cortex — это горизонтально масштабируемое, высокодоступное, мультиарендное, долгосрочное хранилище для удалённой записи данных Prometheus.

Для его использования в конфигурацию Prometheus нужно добавить:
remote_write:
- url: http://localhost:9009/api/v1/pushТакже будет нелишним ознакомиться с документацией этого инструмента.
▍ Grafana Mimir
В марте 2022 года разработчики Grafana объявили о выходе Grafana Mimir, построенном на базе Cortex.
Mimir совмещает в себе всё лучшее, что мы создали в Cortex, с возможностями, которые мы разработали для выполнения GEM и Grafana Cloud в широчайших масштабах. Всё это под лицензией AGPLv3.

Mimir позволяет отслеживать более миллиарда метрик, обеспечивая простоту развёртывания, высокую доступность, мультиарендность, длительное хранение и высокую скорость обработки запросов, в 40 раз превосходящую скорость Cortex. Mimir размещён на https://github.com/grafana/mimir и выпущен под лицензией AGPLv3.
Как и в случае с Cortex, для его использования потребуется добавить в настройки Prometheus следующее:
remote_write:
- url: http://localhost:9009/api/v1/pushКонфигурация сервера Prometheus, который считывает сам себя и записывает эти метрики в Grafana Mimir, выглядит так:
remote_write:
- url: http://localhost:9009/api/v1/push">http://localhost:9009/api/v1/push
scrape_configs:
- job_name: prometheus
honor_labels: true
static_configs:
- targets: ["localhost:9090"]Подробнее читайте на этой странице.
При желании можете поэкспериментировать с Grafana Mirmir здесь.
Также рекомендую почитать документацию.
Alertmanager
Alertmanager обрабатывает оповещения, отправляемые клиентскими приложениями, такими как сервер Prometheus. При этом он обеспечивает отсутствие повторов, а также группировку и перенаправление сообщений нужному получателю вроде ящика электронной почты, Slack, PagerDuty или OpsGenie. Кроме того, он отвечает за подавление оповещений.

Типичный пример использования Alertmanager – это его подключение к Slack, через который он уведомляет пользователя о возникших в кластере проблемах.
Grafana
Grafana позволяет запрашивать, визуализировать, получать оповещения и трактовать метрики вне зависимости от места их хранения.

- Визуализация: быстрые и гибкие графы на клиентской стороне с множеством опций. Плагины панели предлагают различные способы визуализации метрик и логов.
- Динамические контрольные панели: создавайте динамические и переиспользуемые информационные панели с переменными шаблонов, выводимыми в виде выпадающих окон в верхней части панели.
- Анализ метрик: изучайте данные метрик с помощью специализированных запросов и динамического просмотра. Разделяйте представления для наглядного сравнения различных временных диапазонов, запросов и источников данных.
- Анализ логов: испытайте магию переключения с метрик на логи с сохранёнными фильтрами лейблов, а также выполняйте быстрый поиск по всем логам или выводите их в реальном времени.
- Оповещения: визуально определяйте условия оповещений для наиболее важных метрик. Grafana будет непрерывно оценивать и отправлять уведомления в системы вроде Slack, PagerDuty, VictorOps или OpsGenie.
- Смешанные источники данных: совмещайте разные источники данных в одном графе. При этом источники, в том числе кастомные, можно указывать для отдельных запросов.

Kube-Prometheus
Репозиторий Kube-Prometheus объединяет в себе манифесты Kubernetes, контрольные панели Grafana и правила Prometheus, а также документацию и скрипты, обеспечивая удобство сквозного мониторинга кластеров Kubernetes с помощью Prometheus Operator.
Стек Kube-Prometheus предназначен для мониторинга кластеров.
Достаточно развернуть его в своём кластере K8s, и он автоматически начнёт собирать метрики по всем компонентам. В нём изначально настроен базовый набор правил оповещения и контрольные таблицы Grafana. Превосходное решение!
▍ Развёртывание Kube-Prometheus
Для развёртывания Prometheus и Grafana можно использовать Helm-чарт Kube-Prometheus.
Клонируйте Helm-чарты сообщества Prometheus на свою локальную рабочую станцию:
git clone https://github.com/prometheus-community/helm-charts/Перейдите в каталог
kube-prometheus-stack:cd helm-charts/charts/kube-prometheus-stackПрежде чем развёртывать его с помощью Helm, мы настроим файл
values.yaml.Файл values.yaml содержит предустановленную конфигурацию для конкретного чарта. Если вам потребуется переопределить некоторые из значений, его можно изменить.
В нашем случае нужно добавить два источника данных Grafana, а именно ранее развёрнутые Loki и Tempo.

Обратите внимание на
derivedFields.Конфигурация Derived Fields позволяет:
- добавлять поля, спарсенные из лог-сообщения;
- добавлять ссылку, использующую значение поля.
Эту функциональность можно использовать, к примеру, чтобы указывать в логе ссылку на ваш инструмент трассировки или на страницу профиля пользователя, если в строке лога присутствует
userId. Эти ссылки появляются в подробностях логов.Время развернуть kube-prometheus с помощью Helm (заметьте, что мы передаём здесь файл
values.yaml):helm install my-grafana-stack prometheus-community/kube-prometheus-stack -n observability --values values.yamlУстановка
kube-prometheus в ваш кластер Kubernetes займёт некоторое время.NAME: my-grafana-stack
LAST DEPLOYED: Fri Sep 23 19:22:13 2022
NAMESPACE: observability
STATUS: deployed
REVISION: 1
NOTES:
kube-prometheus-stack has been installed. Check its status by running:
kubectl --namespace observability get pods -l "release=my-grafana-stack"Выполните
helm list -A для вывода всех релизов без применения фильтров.NAME NAMESPACE STATUS CHART
loki observability deployed loki-stack-2.8.2
my-grafana-stack observability deployed kube-prometheus-stack-40.1.2
tempo observability deployed tempo-0.16.2Теперь проверьте, запущены ли поды:
kubectl get pods -n observability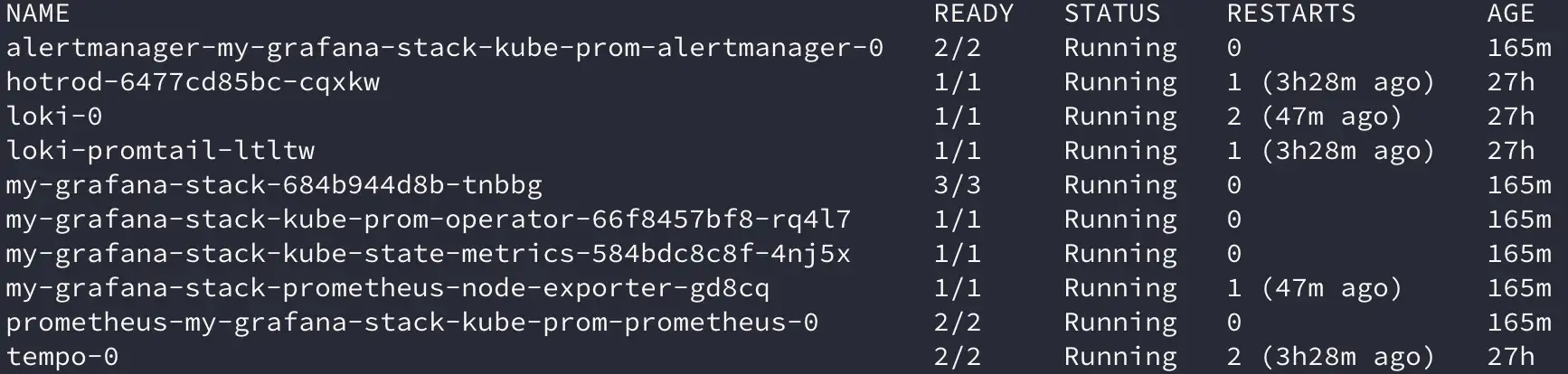
Grafana и Prometheus развёрнуты :)
Авторизация в Prometheus
Для доступа к Prometheus можно использовать проброс портов.
kubectl get svc -n observability
kubectl port-forward svc/my-grafana-stack-kube-prom-prometheus 9090:9090 -n observabilityЧтобы увидеть интерфейс Prometheus, откройте браузер и перейдите на страницу
http://localhost:9090/.
Если вы кликните по кнопке Metrics Explorer, то получите длинный список всех метрик, которые Prometheus собирает по кластеру.

Авторизация в Alertmanager
Команда для доступа к Alertmanager:
kubectl port-forward svc/my-grafana-stack-kube-prom-alertmanager 9093:9093 -n observabilityИнтерфейс Alertmanager находится в браузере по адресу
http://localhost:9093/.
Нажав значок
+, вы увидите, что у нас уже есть ряд оповещений.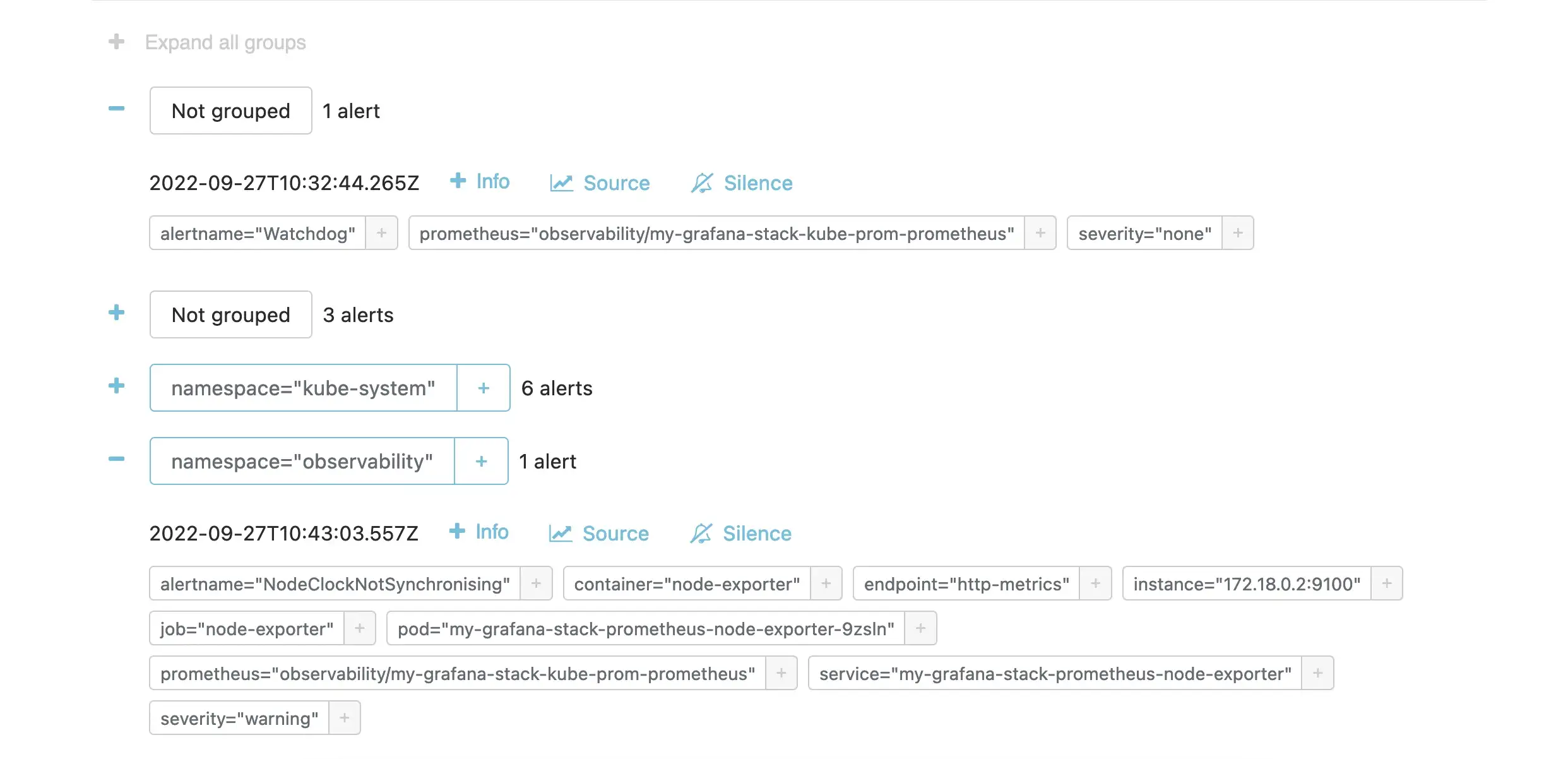
▍ Создание нового оповещения
Давайте создадим новое оповещение, чтобы понять принцип. Для этого потребуется изменить файл
values.yaml.Ранее мы добавили из Grafana два дополнительных источника данных — для Tempo и Loki. Тогда мы внесли их в раздел
grafana.additionalDataSources.Оповещение же добавляется в раздел
additionalPrometheusRulesMap:.Наше оповещение будет проверять, содержит ли пространство имён
observability менее 11 подов. Если вы выполните kubectl get pods -n observability, то увидите, что текущее их число равно 10.
После изменения
values.yaml нужно выполнить helm upgrade для применения изменений.helm upgrade my-grafana-stack prometheus-community/kube-prometheus-stack -n observability --values values.yamlЧтобы убедиться в создании оповещения, откройте ещё раз Prometheus UI и перейдите во вкладку Alerts:
https://127.0.0.1:9090/alertsНайдите в ней созданное нами оповещение ->
observabilityPodsDownСейчас состояние этого оповещения
Pending. Это означает, что продолжительность его активности ещё не превысила установленный порог.
Когда период активности оповещения этот порог превысит, состояние оповещения изменится на
Firing.
Совет: вы можете кликнуть по ссылке выражения, которая перенаправит вас в UI для дополнительной визуализации.

Авторизация в Grafana
Для доступа к Grafana можно использовать проброс портов:
Команда kubectl port-forward пригождается для тестирования/отладки, так что вы можете обращаться к своему сервису, не раскрывая его.
kubectl port-forward svc/my-grafana-stack 3000:80 -n observabilityИнтерфейс Alertmanager доступен через браузер по адресу
http://localhost:3000/.Логин по умолчанию:
admin : prom-operator
Если вы кликните по Dashboard, то увидите, что чарт Helm установил уже настроенные контрольные панели.


Теперь, когда мы поняли, как обращаться к Grafana, Prometheus и Alertmanager, посмотрим, как использовать Loki и Tempo.
Источники данных
Grafana поддерживает множество разных хранилищ для ваших данных временных рядов. Список поддерживаемых источников данных находится здесь.
Если вы сейчас перейдёте в Data Sources, то найдёте источники данных для Loki и Tempo, которые мы добавили в файл
values.yaml.
Источник данных Prometheus был добавлен при развёртывании Kube-Prometheus.

Отправка трейсов
Для просмотра трейсов в Grafana у нас должно быть приложение. Обычно для тестирования используют специально созданное демо HotRod (Rides on Demand).
HotROD (Rides on Demand)
HotRod разработала команда Jaeger, и он вполне годится для тестирования трейсов. Разработчик Jaeger, Юрий Шкуро, написал об этом прекрасную статью Take Jaeger for a HotROD ride.
Если коротко, то это демо-приложение для бронирования поездок, которое состоит из нескольких микросервисов (и сопутствующего хранилища вроде MySQL и Redis). При запуске оно генерирует веб-страницу с кнопками, представляющими клиентов.
Мы писали о HotRod в предыдущей статье -> A beginner’s guide to Jaeger, где вы найдёте все необходимые инструкции о том, как связать его с Jaeger:)
Теперь, когда мы поняли, что из себя представляет HotRod, давайте создадим два файла Kubernetes (
deployment и service).▍ HotROD Deployment
vim hotrod-deployment.yaml
Прежде чем применить файл развёртывания, обратите внимание на переменные среды. Демо HotROD направлено через них на сборщик трейсов.
-
JAEGER_AGENT_HOST: имя хоста для связи с агентом. -
JAEGER_AGENT_PORT: порт для сообщения с агентом. -
JAEGER_SAMPLE_TYPEиJAEGER_SAMPLE_PARAM: используются для ручной активации сэмплинга. Подробности здесь.
Применяется он командой
kubectl apply -f hotrod-deployment.yaml▍ HotROD Service
vim hotrod-service.yaml
kubectl apply -f hotrod-service.yamlПосле развёртывания демо-приложения получить к нему доступ можно через проброс портов:
kubectl port-forward service/hotrod -n observability 3001:8080Откройте в браузере
http://127.0.0.1:3001/
Сгенерируйте несколько запросов/трейсов, кликнув по имени клиента. Эти запросы появятся в Grafana, что мы вскоре увидим.
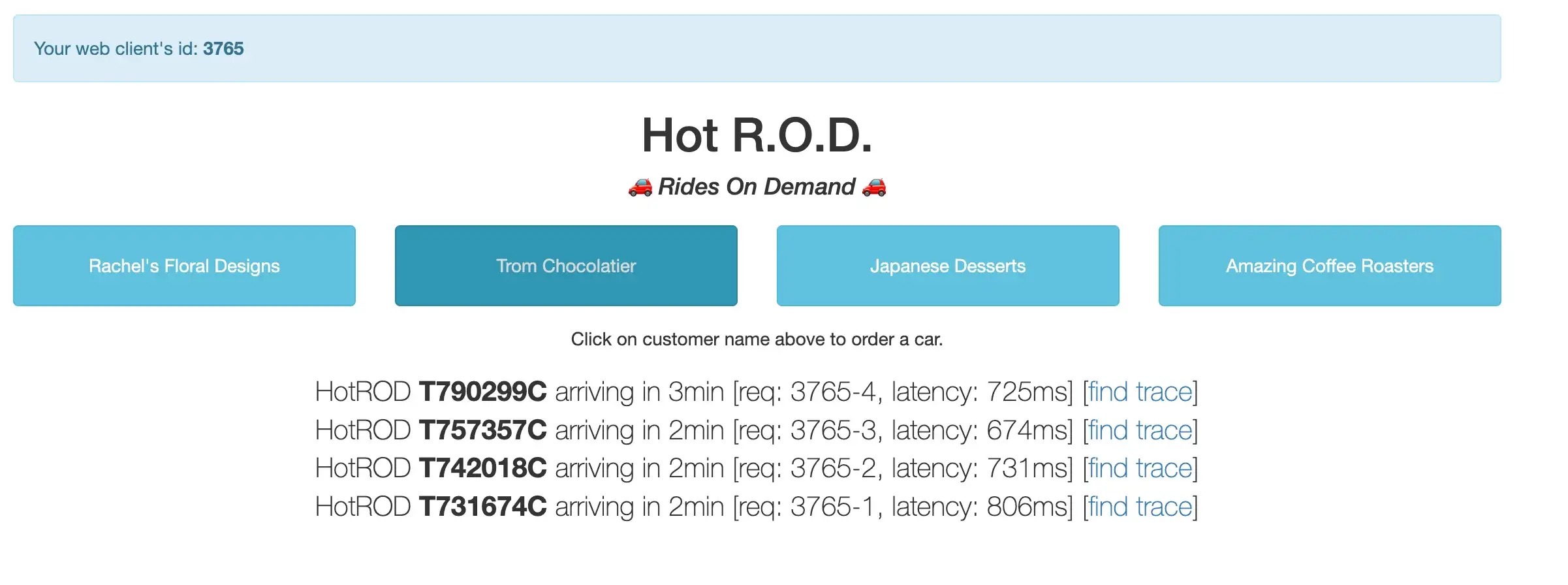
Просмотр трейсов в Tempo
Время запросить логи приложения HotROD.
- Вернитесь в Grafana и кликните по кнопке Explore.
- Из выпадающего списка выберите в качестве источника данных Loki.
- В разделе Labels выберите app, а затем hotrod.

- Кликните по кнопке Run Query в верхнем правом углу.
Теперь в нижней части экрана вы увидите все логи (loki).

- Кликните по одной из записей логов, чтобы её открыть. Обратите внимание на поле
TraceID, которое представляет извлечённый из логовtrace_id.

Теперь рядом с
TraceID должна быть видна синяя кнопка Tempo. Кликнув по ней, вы откроете Tempo UI, где можно просмотреть информацию о трейсах.
Отсюда можно использовать весь трейс, на который ведёт ссылка из логов Loki. Это очень круто, поскольку вы можете переходить напрямую из логов (Loki) в трейсы (Tempo).
Заключение
Поздравляю, вы только что развернули стек наблюдаемости Grafana, включающий Grafana, Prometheus, Loki и Tempo.
Telegram-канал с полезностями и уютный чат

Комментарии (3)

shifttstas
27.11.2022 13:58+1Мне кажеться вместо "наблюдаемости" все же Observability лучше использовать т.к первое очень ухо режет и непонятно о чем речь.

Bright_Translate Автор
27.11.2022 23:07+1Вот и я тоже испытывал сомнения по этому поводу, но все же наблюдаемость широко используется. Давайте в названии заменим и во вступлении поясним скобками.
chemtech
Спасибо за пост. Добавлю что у VictoriaMetrics есть бенчмарк с Grafana Mimir - https://victoriametrics.com/blog/mimir-benchmark/