
Здравствуйте! Меня зовут Дмитрий Моряков, и я ведущий системный аналитик в компании МаксимаТелеком. Теме миграции с монолита на микросервисную архитектуру (здесь и далее — МСА) за последние годы на страницах Хабра было посвящено немало материалов, поэтому я хотел бы сосредоточиться на узких аспектах этого процесса: выделении критической части при реализации пилотного проекта миграции на МСА и реализацию изоляции полученных микросервисов по данным.
Вместо введения:
У микросервисной архитектуры много плюсов, а самый большой её минус — высокая сложность разработки. Каждый микросервис в отдельности прост и для разработки, и для рефакторинга, но возникают очень жёсткие требования с точки зрения механизма взаимодействия микросервисов между собой. И здесь одной из ключевых проблем становится обеспечение: с одной стороны — изоляции микросервисов по данным, с другой — консиcтентности этих данных в условиях такой изоляции.
Основной драйвер развития МСА — высоконагруженные приложения. Рано или поздно развивающиеся бизнесы, имеющие приложение на монолите, упираются в предел производительности и нуждаются в горизонтальном масштабировании автоматизированных систем, на которых эти бизнесы строятся.
Первыми отраслями, которые столкнулись с проблемой предела производительности систем (это произошло ещё в конце нулевых), стали ритейл и логистика. Для этих отраслей характерен нелинейный рост объёма и производительности баз данных. Требованиям этих бизнесов сначала перестало удовлетворять гражданское оборудование, а потом и оборудование двойного назначения, которое используется в том числе и для военных целей.
До прихода в Максиму я работал в крупной логистической компании, корпоративная система которой имела в основе БД на Oracle объёмом несколько десятков терабайт. Эта корпоративная система отвечала за все основные бизнес-процессы: приём заказа, маршрутизация, работа с курьерами, биллинг — я перечислил только малую часть. Постепенно компания столкнулась с тем, что в дни нелинейных пиковых нагрузок (например, «Чёрная пятница» или предновогодний сезон) эта СУБД становилась «бутылочным горлышком» и производительность корпоративной системы ограничивалась производительностью самой СУБД. Компания начала проигрывать борьбу за объёмы по мелким и дешёвым посылкам конкуренту, который перешёл на микросервисную архитектуру раньше, что обеспечило ему горизонтальное масштабирование системы.
Другой пример высоконагруженного приложения, которое в монолите не реализуется в принципе — системы городского видеонаблюдения. Необходимо взять видеопоток с каждой камеры, входящей в систему, разбить этот видеопоток на кадры, попытаться на этих кадрах детектировать лицо человека, построить биометрический индекс, осуществить поиск схожих изображений. Всё это происходит ежесекундно и на огромном количестве камер (в Москве, например, их больше ста тысяч). Можно представить себе масштаб объёма хранения и обработки информации. Приложение без возможности горизонтального масштабирования в этих условиях нереализуемо — оборудования для его развёртывания на данный момент в принципе не существует.
⠀
Что выбрать для пилотного проекта по переходу на МСА?
Предположим, необходимость перехода корпоративной системы на микросервисную архитектуру компания осознала. Но бросаться в омут с головой никто не хочет — существует слишком много примеров, когда неудачные изменения в корпоративных системах приводили к потере бизнеса.
Какими могут быть стратегии перехода?
Во-первых, можно взять какую-то новую функциональность — относительно независимую от уже имеющейся в монолите, и реализовать ее в МСА. Это простой и недорогой способ «потрогать руками» МСА и выявить подводные камни новой технологии. Но с точки зрения понимания того, как переводить на МСА имеющийся монолит, информации будет получено немного. Да, мы запустили микросервисы, и да, теперь они работают и никому не мешают. Но что делать с устаревшей, но составляющей основу бизнеса системой и его базой данных? Ответы на эти вопросы при таком подходе мы вряд ли получим.
Второй вариант — начать строить рядом совершенно новую систему. Но чаще всего это де-факто равно понятию «создать новый бизнес». Как правило, эту новую систему нужно будет запускать параллельно уже имеющейся, а физическая составляющая в редких случаях может работать под управлением двух систем одновременно. А это, в свою очередь, означает следующее: нужно приобрести и развернуть новые склады, новые линии, новую сортировочную технику. Да, это решает проблему, но это колоссальные инвестиции, которые с точки зрения бизнеса не всегда возможны и, как правило, не являются оправданными: функциональность новой системы далеко не всегда отличается от старой.
«Переписывание с нуля гарантирует лишь одно — ноль!»
© Мартин Фаулер (Martin Fowler)
Третьим, — самым высокорисковым, но при этом самым эффективным — является выделение критической части системы и перевод её на микросервисную архитектуру. Здесь мы имеем быстрый эффект и сразу же начинаем повышать производительность той части системы, которая является её «бутылочным горлышком». Сложность и высокие риски при использовании этого метода определяются тем, что именно в этой части системы сосредоточены и сложная бизнес-логика, и сложная техническая реализация. Разберём подход с выделением критической части в микросервис подробнее.
Переход на МСА с точки зрения аналитика
Рассматривать переход на МСА я буду с точки зрения аналитика, а не архитектора. Эта точка зрения имеет свою особенность — аналитик в меньшей степени погружен в детали реализации. Как правило, он не участвует в формировании технологического стека, но в большей степени отвечает за целостность бизнес-процессов, а это значит — и за все процессы, связанные с данными.
Какую ситуацию мы видим в самом начале типового перехода с монолитной архитектуры на микросервисную?
Как правило, бизнес-процессы не описаны, либо их описание не является актуальным. Как правило, высока зависимость организации бизнес-процессов от имеющейся системы: все знают, как устроен тот или иной процесс, но уже никто не помнит (или, по крайней мере, неспособен объективно оценить), насколько структура того или иного процесса была или не была обусловлена бизнес-логикой. Ведь очень часто тот или иной процесс был построен в силу ограничений при реализации предыдущей системы, или как «костыль» от неучтённого требования. Соответственно, к процессам AsIs аналитику следует подходить очень критично.
Сама система на этой стадии, как правило, представляет собой тонны кода, а до половины её разработчиков зачастую уже уволились. В коде есть много мест, в которые никому не хочется лезть; документации недостаточно; наконец, мало кто имеет представление, как связан работающий код с бизнес-процессами.
База данных при этом, как правило, очень большая, но, — и это приятное для аналитика наследие эпохи больших монолитов, — спроектирована и задокументирована качественно. Практически всегда такие базы имеют информативные наименования полей, а в 90% случаев существует ещё и внешняя логическая модель в виде ER-диаграммы.
В этой ситуации перед аналитиком в первую очередь встаёт задача, связанная с реверс-инжинирингом: это сбор требований. Или, точнее будет сказать: восстановление требований, ведь в компаниях, которые пришли к решению декомпозировать монолит, система чаще всего функционирует уже давно, но значительная часть требований оказывается не задокументированной — они предполагаются чем-то, что разумеется само собой.
Вторая задача — проанализировать физическую структуру базы данных. Это нужно для того, чтобы впоследствии предоставить информацию для доменной модели. Также на аналитика ложатся все процессы, связанные с моделированием предметной области и проектированием — как бизнес-процессов, так и самих этих микросервисов на базе тех решений, которые принимаются архитектором.
Ещё одна задача аналитика на этом этапе — своевременно предоставлять информацию о возникающих зависимостях архитектору и разработчикам.
⠀
Как переход на МСА влияет на данные и бизнес-процессы?
При переходе на МСА необходимо выстроить структуру микросервисов таким образом, чтобы чтобы не возникало deadlock’ов и тем самым обеспечивалось масштабирование. Это происходит в том случае, если обеспечивается изоляция микросервсов по данным.
Также необходимо получить ограниченную функциональность каждого микросервиса, (в идеале — чтобы каждый микросервис отвечал только за одну бизнес-функцию) и тем самым обеспечивалась изоляция не только по данным, но и в целом всего контекста.
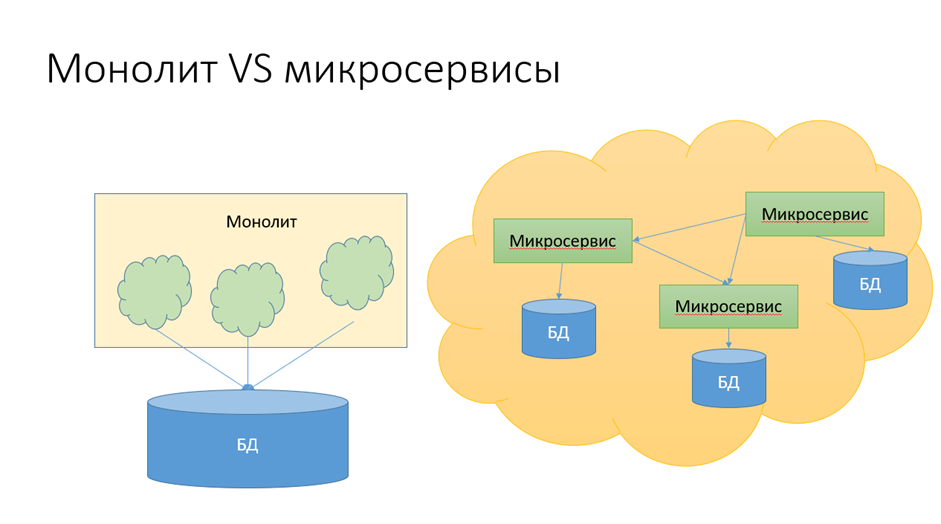
Необходимость организации для каждого микросервиса (а то и для каждого экземпляра микросервиса) своей БД отчасти компенсируется возможностью использования специализированных баз, соответствующих характеру работы микросервиса с данными. Раз уж баз много, то можно выбирать и по типу базы (транзакционные, In-memory и витрины) и конкретные их реализации. При этом у каждого типа базы — свои способы масштабирования:
Транзакционные базы, как правило, масштабируются за счёт шардирования и партиционирования.
Базы данных In-memory могут обеспечивать консистентность данных при одновременно ведущихся процессах записи и чтения за счет своего быстродействия, так что на этом типе БД зачастую хватает вертикального масштабирования. Правда, при этом возникает проблема потери данных при сбоях и потере питания (что требует аккуратного применения баз такого типа или использования энергонезависимой памяти).
Витрины масштабируются за счет того, что все данные в них предназначены только для чтения, благодаря чему не нужно обеспечивать изоляцию транзакций: консистентность данных обеспечена ETL-процедурой при загрузке данных на витрину, и все агрегаты также рассчитаны заранее.
После разделения БД нам необходимо обеспечить связность всех сервисов только через API. И здесь мы сталкиваемся с тем, что транзакции на уровне баз данных у нас больше не работают. О временах, когда мы могли проектировать транзакции произвольной сложности, а СУБД обеспечивала их изоляцию и консистентность данных в любой момент времени, можно смело забыть — теперь мы имеем ситуацию, когда всё находится на ручном управлении. Единственное, что спасает в этом случае — брокеры сообщений, но и они спасают не до конца.
Как правило, переход на микросервисную архитектуру требует изменения самой бизнес-логики, ввода новых понятий и новых бизнес-процессов, которые позволили бы работать в условиях, когда консистентность данных не обеспечивается на системном уровне.
⠀
Как организовать работу аналитика при переходе на MSA?
Порядок наших действий можно описать этой схемой:

Начинать я рекомендую с построения модели предметной области.
При необходимости выполняется reverse-engineering БД монолита (или просто ее анализ, если она хорошо задокументирована) и проводятся интервью с бизнес-пользователями для выделения ключевых понятий ПО и описания их взаимосвязей.
Интервью по построению модели предметной области можно объединить с описанием бизнес-процессов AsIs. В этом случае параллельно происходят два процесса: строятся и доменная модель, и описание бизнес-процессов.
В каком бы порядке ни проходили интервью, важно, чтобы бизнес-процессы, которые мы описываем, велись в тех же понятиях и тех же терминах, в каких мы ведём модель предметной области.
К описанию бизнес-процессов предъявляются дополнительные требования, связанные с технологией их последующего реинжиниринга: необходимо выделять не только исполнителей и дорожки с обозначением отделов компании, а также выделять подсистемы, которые задействованы в каждом процессе, выделять хранилища, выполнять трассировку хранилищ с моделью предметной области.
При описании бизнес-процессов выделяются схожие функции для их группировки в микросервисы. Микросервисы группируются, но пока не проектируются детально.


Проектирование процессов ToBe выполняется уже с учетом выделенных на предыдущем шаге микросервисов. После проектирования (либо параллельно с проектированием) процессов ToBe мы уточняем спецификации микросервисов.
Эту спецификацию очень удобно выполнять через через диаграмму последовательности UML: если мы считаем, что сообщение на линию жизни компонента связано с вызовом его метода, то мы можем получить описание API этого компонента.
Специфицируя каждый из вызываемых методов, мы получим спецификацию компонента в целом.
⠀
Выбираем нотации
С точки зрения аналитика очень важно то, каким образом он будет идти по вышеперечисленным этапам с технической точки зрения. Прежде всего стоит вопрос о выборе нотации для моделирования, ведь все нотации относительно независимые: для описания предметной области существуют одни, для проектирования — другие, для бизнес-процессов — третьи. Нам необходимо выбрать конкретные нотации и понять, каким образом их соединять в единый поток моделирования и выполнять трассировку.
Легче всего выбрать нотацию бизнес-процессов — это BPMN. Предыдущая проприетарная нотация описания бизнес-процессов, EPC, практически ушла с рынка.
BPMN, как и EPC, позволяет выделять события, а ещё, как и IDEF0, позволяет работать с декомпозицией процессов. Последнее крайне важно, поскольку нам нужно добиваться уровня детализации бизнес-процессов, соответствующего модели предметной области — как при описании ToDo, так и при описании AsIs.
Так, если бизнес-процессы описаны гораздо крупнее или гораздо мельче, чем описана наша доменная модель, то мы не сможем выполнить трассировку.
При выделении хранилищ необходимо отражать направленность ассоциаций с ними user- и service tasks, чтобы при обработке моделей иметь информацию, какой процесс пишет в хранилище, а какой процесс из него читает. При описании самих бизнес-процессов важно использовать коллаборации, а не оркестровки — потоки сообщений при межпроцессном взаимодействии в бизнес-процессах упростят применение брокеров на стадии проектирования.
В выборе нотации для описания модели предметной области всё очень сильно зависит от команды и от тех инструментариев, которыми она владеет.

Самая простая нотация, которая применяется в agile-командах — система domain-subdomain (слева вверху на рисунке выше). Она проста и удобна, легко читается и понимается всей командой, но у этой простоты есть издержки: как правило, domain-subdomain практически не трассируется с логической моделью базы данных и не отражает ни горизонтальные связи сущностей, ни мощности этих связей.
На другом полюсе находится Class diagram нотации UML (снизу справа на рисунке): с точки зрения точности описания это наиболее правильная модель, здесь отражены и классы, и мощности, но эта диаграмма очень строгая и достаточно сложно понимается участниками команды от бизнеса.
На мой взгляд, разумным компромиссом между простотой и точностью является ER-диаграмма в нотации Питера Чена (по центру).
Почему именно нотация Чена?
На первый взгляд такой выбор может показаться экзотическим — ведь это одна из самых ранних ER-нотаций. Но нотация Чена в контексте решения задачи описания модели предметной области имеет ряд преимуществ перед более популярными IDEF1x или Crowfoot.
Нотации Чена, IDEF1x и Crowfoot отличаются друг от друга, прежде всего, способом описания размерности связи.

IDEF1x или Crowfoot используют графические символы, а нотация Чена отражает связи явно. Это удобнее для доменной модели: в процессе уточнения информации размерности меняются часто. Но наиболее важным свойством нотации Чена для нашей задачи является «открытая» форма описания атрибутов.


Итак, в нотации Чена атрибуты выделены отдельными кружочками, а в IDEF1x они вписаны в сами сущности. Поэтому описания IDEF1x и CrowFoot гораздо более компактные. При описании уже существующих баз данных компактность важна — при «ручном» диаграммировании описать в нотации Чена большую предметную область или логическую структуру большой БД практически невозможно.
Но с появлением систем моделирования, содержащих репозиторий, этот недостаток нотации Чена перестал быть критичным — можно формировать представления любой степени детализации.
Зато выделение атрибутов в отдельные элементы, характерное для нотации Чена, гораздо удобнее при нормализациях/денормализациях, когда атрибуты преобразовываются в ссылки на сущности, и наоборот:

На примере мы выделили столик как отдельную сущность и не просто указываем номер столика в заказе, а выбираем столик из справочника. Чисто технически в нотации Чена отразить это изменение проще.
В расширенной нотации Чена, которую использует такой продукт как Enterprise Architect, удобно выделять так называемые «существенные связи» или «связи-сущности»: специальные технические сущности для реализации связи типа «многие ко многим» — сюда относятся строки заказов, формуляров и т.д. Такие связи описываются в расширенной нотации Чена как N-арные сущности, в то время как в других нотациях такой возможности нет и сущности разных типов неотличимы.

Это даёт нам возможность отражать связи агрегации и композиции, которая доступна в UML, но недоступна в других нотациях ER.
Итак, ER-диаграмма — не такой строгий и сложный вариант нотации, как диаграмма классов UML, но и не такой примитивный, как обычная модель domain-subdomain.
Для описания проектируемой системы тоже практически нет альтернатив — это UML. Такие нотации, как архитектурная Archimate или инженерная SysML, также можно рассмотреть, но есть два «но». Во-первых, обе эти нотации являются диалектами или расширениями того же UML, во-вторых — для решения задачи описания ПО они часто оказываются менее удобными либо из-за ограниченности, либо из-за избыточности функционала.
⠀
Выбираем инструментарий
При выборе инструмента визуального моделирования/проектирования желательно иметь поддержку всех вышеперечисленных моделей.
Кроме функций построения моделей и репозитория, инструментарий должен иметь средства анализа построенных моделей, а также средства автоматизации построения новых моделей на основании уже имеющихся.
Наиболее распространённым средством UML-моделирования является Sparx Enterprise Architect: помимо UML, он поддерживает также необходимые нам ER и BPMN, а кроме них — ещё около 40 других нотаций.
Есть ещё два продукта: Visual Paradigm — близкий по функционалу, но менее распространённый за счёт своей стоимости, и IServer — достаточно специфичный продукт, который в основном используется в банках.
Поскольку в компании, в которой я работал, в качестве основного инструмента к моменту описываемых событий уже применялся Enterprise Architect, выбор остановили именно на нём. Чуть забегая вперед, скажу, что готовых средств анализа моделей в Enterprise Architect не нашлось, но благодаря наличию в нем встроенного генератора отчетов средства для анализа были разработаны.
Определяем модель трассировки
В нашем потоке моделирования необходимо связать бизнес-процесс, модель предметной области и систему. Мы это делаем с помощью специального вида связей, имеющегося в Enterprise Architect — трассировочных. Их наличие позволяет связывать любые элементы как в рамках одной нотации, так и в рамках разных нотаций.

Выше приведена модель трассировки, которая отражает суть метода обеспечения изоляции микросервисов по данным.
Он сводится к следующему:
При описании бизнес-процесса в BPMN мы отражаем связи между Service task, User task и хранилищами в виде направленной ассоциации. Если такая связь существует, то это означает использование системы: ведь хранилище — это часть нашей системы, хотя и описанное в другой нотации. Нам следует отразить это использование системы как use case на use-case-диаграмме UML и определить соотношение этого use case по отношению к другим элементам функциональной архитектуры,
С другой стороны, каждое хранилище связано с какой-то сущностью или некоторой совокупностью сущностей. То есть, мы можем определить трассировочную связь между хранилищем на BPMN-диаграмме и сущностью — на ER-диаграмме,
Микросервисы мы получили как результат группировки use cases на пакетной диаграмме UML, а потом описали архитектуру нашей системы на компонентной диаграмме UML. Таким образом, у нас есть информация о том, каким конкретным микросервисом реализован тот или иной use case.
Как результат, мы имеем четкие формальные критерии для проверки изоляции. Если каждое хранилище связано только с одним микросервисом (даже если микросервисом будет реализовано несколько вариантов использования и/или в хранилище будет содержаться несколько сущностей), мы можем утверждать, что изоляция обеспечена. Если же возникает ситуация, что с одним хранилищем работает несколько микросервисов — потребуется объединять эти микросервисы между собой либо произвести перекомпоновку use cases.
Можно спросить: а зачем такие сложности? Зачем настолько формально подходить к проектированию? Ведь agile-подход предполагает использовать как можно более простые модели, отдавая более высокий приоритет коммуникациям в команде. Да и классический DDD (Domen Drive Design — основная технология проектирования микросервисной архитектуры) не предполагает такого тщательного моделирования.
Ответ заключается в том, что целесообразность этого метода проявляется только при определенном сочетании факторов:
Мы занимаемся именно миграцией. Если мы проектируем новое приложение, использовать классический DDD будет эффективней,
Мы ведем пилотный проект. То есть, нам нужна очень тщательная увязка имеющегося монолита и микросервисов пилотного проекта для обеспечения целостности и данных, и бизнес-процессов,
Мы выделили в пилотный проект самую нагруженную и сложную часть системы, соответственно — пошли на высокие риски, связанные с этой нагруженностью и сложностью.
⠀
При чём здесь CAP-теорема?

CAP-теорему (аббревиатура от consistency, availability, partition tolerance) можно упрощённо переформулировать так: «согласованность, доступность, партиционируемость — из этих свойств выберите любые два». Исходя из этого, мы имеем три опции: либо данные доступны и партиционируемы, либо согласованы и партиционируемы, либо доступны и согласованы.
Если мы выбрали микросервисную архитектуру, в качестве результата мы получаем доступность и партиционируемость. А это значит, что нам придется мириться со сложностями в согласовании данных (т.е., получим AP-систему).
У монолита за счет централизованной БД нет проблем с согласованностью, но при этом придется выбирать между партиционированием (иногда проще открыть новую компанию, чем вынести в архив устаревшие данные), либо с доступностью.
Таким образом, при переходе с монолита на микросервисную архитектуру меняется не просто архитектура, а сам тип системы. Поэтому меняется и набор требований к транзакционной системе: ACID (atomicity, consistency, isolation, durability) меняется на BASE (basic avalibility, soft state, eventual conststency).
ACID-подход, при всех его плюсах, обеспечивается только централизованной БД монолита. Соответственно, при возникновении необходимости горизонтального масштабирования и перехода на микросервисы от него приходится отказываться в пользу BASE.
А BASE — это прежде всего «Soft state»: система находится в неустойчивом состоянии, а приводить её в устойчивое состояние должен сам разработчик. При этом обеспечиваются только базовая доступность и согласованность только конечного состояния.
Изменение подхода кардинально влияет на проектирование бизнес-процессов ToBe, и этому стоит посвятить отдельный абзац.
Как проектировать процессы ToBe?
После того, как мы обеспечили изоляцию, остаётся важный вопрос: как нам перепроектировать бизнес-процессы?
В первую очередь, таким образом, чтобы обеспечить и определённую стабильность, и возможность ручного отката каждой транзакции. Здесь уместно вспомнить SAP: оформить транзакцию в нём несложно, но после того, как транзакция уже прошла, аккуратно вернуть её уже не получится: как минимум, потребуется сделать большое количество сторно. При микросервисной архитектуре каждый микросервис работает со своей базой данных, благодаря чему каждая транзакция легко откатывается, но при этом мы имеем дело с тем, что нам самим приходится заботиться о консистентности всех распределённых баз данных.
Соответственно, нам необходимо выработать такую стратегию, которая позволила бы свести к минимуму возможность нарушения консистентности данных: например, минимизировать обновления объектов, заменяя обновление на создание новых версий, а также использовать возможности гарантированной доставки брокеров сообщений для бизнес-транзакций.
Выводы
По результатам проекта, в котором был реализован вышеописанный подход, можно сделать следующие выводы:
1) Можно перевести на микросервисную архитектуру даже самый сложный монолит, если подобрать правильный поток моделирования;
2) Классическое моделирование бизнес-процессов, предметных областей и систем рано списывать со счетов. Да, общий тренд состоит в переходе на упрощенные модели, рекомендованные в AGILE, но ещё существуют задачи, в которых применение классического моделирования предпочтительнее;
3) При моделировании необходимо использовать инструментарий, так как ни один аналитик не в состоянии держать в голове (и даже в виде текста или гипертекста) все связи, которые необходимо учесть для обеспечения изоляции;
4) При моделировании в команде аналитиков обязательно нужно использовать соглашения о моделировании, в которых детализируется и уточняется семантика элементов нотации, рекомендуются или запрещаются те или иные паттерны моделирования. В противном случае добиться единого понимания разрабатываемых моделей невозможно.
Комментарии (12)

murkin-kot
20.12.2022 16:02+1В тексте приведены некорректные примеры задач, требующих перехода на микросервисы.
Всплеск продаж
Видеонаблюдение
Первый пункт никак не побеждается разбиением системы на запчасти, взаимодействующие через HTTP или даже что-то доморощенное. Всегда останется задача проверки остатков по позициям, что предполагает одну БД и одну таблицу в ней.
Второй пункт - вообще никак не связан с микросервисами, поскольку это всего лишь распараллеливание обработки на абсолютно одинаковых обработчиках.
То есть с самого начала текста ставится ложная задача - перейдём на микросервисы лишь потому, что автору кажется, что микросервисы чем-то помогут, хотя на самом деле в приведённых задачах они не помогут ничем.

DmitryMoryakov Автор
20.12.2022 16:34>Всегда останется задача проверки остатков по позициям, что предполагает одну БД и одну таблицу в ней.
На мой взгляд, очень спорное утверждение: обработка информации об остатках совершенно не требует одной базы и одной таблицы. Необходимость централизованной обработки информации об остатках не исключает возможность применения МСА - например можно выделить микросервис "Запас", при этом шардировать таблицу с остатками например по подразделениям (местам хранения) , а то и по типам товара или товарным группам. Таким образом мы сможем масшабировать этот микросервис и разделить нагрузку между экземплярами микросервиса и соответствующими ему шардами.Если идти дальше, то можно разделить функции чтения и записи информации об остатках : изменять остатки в OLTP , затем через ETL выкладывать срезы остатков на витрины.
Но на самом деле эффект от МСА будет уже тогда, когда мы сможем собрать все бизнес-функции по работе с товарным запасом в одном микросервисе, отделив их от других функций, связанных с продуктами : управлением ассортиментом, управлением ценами и т.д., что в ERP реализуется на связанных таблицах БД монолита
В любом случае целесообразность таких шагов определяется в конкретном проекте
>Второй пункт - вообще никак не связан с микросервисами, поскольку это всего лишь распараллеливание обработки на абсолютно одинаковых обработчиках.
Ну все таки как-то связан :) Запуск многих экземпляров обработчиков, выделенных в отдельный микросервис, управляемых общим оркестровщиком - довольно распространеное решение для паралельной обработки. Хотя согласен, что есть и другие способы ее реализации.
>То есть с самого начала текста ставится ложная задача - перейдём на микросервисыНе ставилась такая задача. Ну и вообще тема статьи - это не микросервисы vs монолит. Выработка критериев перехода и принятие решения по миграции на МСА - это вообще прерогатива архитекторов. Аналитик работает с уже принятым решением и обеспечивает этог переход
murkin-kot
20.12.2022 18:35+1обработка информации об остатках совершенно не требует одной базы и одной таблицы
А потом сами пишете:
шардировать таблицу с остатками например по подразделениям
То есть вы не ушли от одной БД и одной таблицы.
на самом деле эффект от МСА будет уже тогда, когда мы сможем собрать все
бизнес-функции по работе с товарным запасом в одном микросервисе,
отделив их от других функций, связанных с продуктамиЭто называется "разделить по компонентам". Компонент может быть связан с другими через HTTP, и может общаться напрямую внутри приложения. Наличие компонента никак не зависит от микросервисов - и с ними и без них он будет. А вот вносимая микросервисами задержка при коммуникации будет лишь в случае принятия концепции микросервисов. Добавьте к этому сложность оркестровки зоопарка сервисов.
Я в целом не против разделения ПО на компоненты, но считаю, что такое деление должно быть обосновано, особенно, если за ним следует уменьшение эффективности за счёт появления прямых и косвенных дополнительных задач, как мы видим в случае с микросервисами.
Возможно, вам было бы проще, если бы вы не приводили примеры микросервисов. Просто принято решение - перейти. А обоснование остаётся за скобками. Это паллиатив, конечно, но так вы избежите многих споров.
DmitryMoryakov Автор
20.12.2022 19:00То есть вы не ушли от одной БД и одной таблицы.
Физически шарды логических таблиц - это как правило разные таблицы, даже если шардирование выполняется средствами СУБД. Просто СУБД "проксирует" запросы. При этом возможен вариант шардирования "снаружи", не системными средствами. Например в том случае, если мы строим распределенную структуру и у каждого подразделения или у каждой товарной группы своя БД. В этом случае можно говорить только об одной сущности, а не об одной таблице
Возможно, вам было бы проще, если бы вы не приводили примеры микросервисов. Просто принято решение - перейти.
Без обьяснения мотивов перехода на МСА на мой взгляд нельзя сформулировать требования к потоку моделирования.
А обоснование остаётся за скобками
Именно так
murkin-kot
21.12.2022 13:11Физически шарды логических таблиц - это как правило разные таблицы
Не надо ходить этой скользкой дорожкой. Вы про микросервисы или про внутреннее устройство БД? Если про первое, то БД к ним никакого отношения не имеет, вместе с её внутренностями.
Важно получить обоснование - зачем вам понадобились микросервисы. Вы пока ни одного приемлемого варианта не озвучили, только переводите стрелки на БД и прочие рассуждения.
Ну либо всё же признайте - вам сказано "внедрить", а зачем - не важно. Ну вы и внедряете. Можно даже как-то политкорректно, вроде "у нас решили перейти на микросервисы, потому что очень умные люди очень много рассказывали про важность такого перехода".
DmitryMoryakov Автор
21.12.2022 13:55Вы про микросервисы или про внутреннее устройство БД?
Я про спорность утверждения о единственности таблицы остатков
Ну либо всё же признайте - вам сказано "внедрить", а зачем - не важно.
Признаю : были сформулированы нефункциональные требования и архитектором , как лицом, отвечающим за НФТ, были приняты соответствующие архитектурные решения, которые он согласовал с заинтересованными лицами. Ни ход выполнения проекта, ни результат его выполнения не показал, что принятые архитектурные решения были неверными.
В принципе область эффективности МСА была четко обозначена еще Фаулером, и с того времени , IMHO, по этой теме мало кто чего добавил. Во всяком случае я что-то добавить не готов

nronnie
20.12.2022 18:48Visual Paradigm
Плюсанул за его упоминание. Почему-то мало известный продукт, при том, что "на поиграться" есть полностью бесплатная версия.
DmitryMoryakov Автор
20.12.2022 19:05Согласен. Сейчас еще его плюсом явлется то, что его разработчик базируется в Гонконге. Но на момент этого проекта это было еще неактуально :)
GothicJS
Разъясните пару вопросов для тех, кто не в теме)
А как же сеть? Ведь чем больше микросервисов, тем чаще придется ходить в сеть для общения друг с другом, а поход в сеть это медленная операция. Разве не должно быть так, что от большого количества микросервисов скорость наоборот будет падать?
В случае с монолитом нельзя делать шардирование БД ?
DmitryMoryakov Автор
Рост сетевого трафика конечно тоже надо учитывать. Но если все хорошо спроектировано, то он не должен стать критичным: трафик между сервером приложений и сервером БД тоже идет через сеть. Ну и если все микросервисы в одном ЦОДе , то проблема скорости сети как правило не очень критична. А вот если в процессе миграции на МСА идет переход на распределенную систему, то это в большей степени проблема миграции на распределенную систему, чем на МСА. Но все конечно надо считать.
DmitryMoryakov Автор
Про шардирование:
Шардировать и партиционировать БД безусловно можно и при монолите. Вопрос в том, какая задача в итоге ставиться - горизонтально масштабировать монолит все равно не получиться. Но например чуть повысить производительность за счет уменьшения размера активных таблиц можно. Но при этом делать шардирование и партиционирование механически , не задумываясь о том, как будут проходить транзакции, не будет ли возникать конкуренция за данные, не будет ли падать производительность за счет работы с разными шардами и т.д. не получиться. Все равно нужно будет в какой-то части выполнить работы по изоляции по данным модулей или сервисов , даже, если архитектура останется монолитной