

Истерический, негативно-позитивный пост добра и ненависти, обо всем и ни о чем, из которого вы узнаете: как папа Крузо встретил маму Робинзона, почему трава зеленая а смурфики голубые, как нам реорганизовать Рабкрин и много других, важных штук.
Увертюра
Заголовок поста не просто так, я пишу по мотивам реального проекта, которым сейчас занимаюсь. Это ядро коммерческого продукта, который работает уже почти 20 лет и все это время активно развивается, а учитывая, что это «Кровавый Энтерпрайз» и к тому же еще, плюс минус тиражируемый, в нем накопилось всякого разного. Не сказать, что до этого совсем ничего не предпринималось в плане улучшения внутренней структуры проекта, но такой масштабной переработки не было. И у меня, несмотря на 30+ лет опыта работы, не было опыта именно переработки проекта, такого масштаба. Не знаю, у кого как, а для меня это действительно вызов. Самое смешное, что я создал его для себя сам, не то, чтобы проект совсем пиратский, но я занимаюсь этим в рамках проекта по выкорчевыванию библиотек с не пермиссивными лицензиями. Воспользовался, понимаешь, поводом. К сожалению, я начал записывать свои мысли, которые возникали в процессе работы уже ближе к ее окончанию, жаль, наверное, я что-то упущу, но постараюсь восстановить как можно большее.
Многие проблемы, о которых я пишу дальше, очевидным образом проходили через призму моего восприятия, и мои подходы. Я не настолько самонадеян, чтобы считать это истинной в последней инстанции (но достаточно, чтобы этим поделится). И не считаю, что программирование это вот прям наука, поэтому личность человека важна и накладывает отпечаток на результат. Я знаю, что многим не нравится такой взгляд и считают, что может быть только один единственно верный, математически выверенный подход. Я в это не верю, и «верю» тут ключевое слово. Это конечно не значит, что надо писать код абы как и не следовать никаким правилам, best practices (какой гадкий термин) и т.д. Правила необходимо соблюдать, но правило которое я всегда ставлю на первое место: Правил нет, есть здравый смысл. Если здравый смысл говорит вам – Делай так! – делайте так, даже если нарушаете какой-нибудь DRY, SOLID и т.д., принципы должны помогать, а не мешать.

Например, больная тема: паттерны, паттерны блин, почему-то вспомнились именно они. Знать о них надо, даже надо с ними ознакомится, по крайней мере с самыми известными, их даже надо использовать, но бесит, когда код пишут паттернами, бездумно, просто потому что они есть, потому что так «правильно», и вместо одной строчки кода у вас тоже строчка + новый файл с классом из десяти строк, и это еще ничего, бывает хуже. Человек пишет калькулятор, калькулятора еще нет, зато уже есть адаптер к провайдеру, и скоро появится фабрика математических операторов.
Я недавно тоже писал калькулятор, ну такой, встроенный в программу, Drop down в полях ввода, нужно было избавиться от существующего там LGPL под капотом и ненужных зависимостей. У меня не случилось ни одной фабрики классов, и вообще их (классов) всего два: собственно калькулятор (вычислитель), и контрол для него (отображатель). Уже много, вычислитель за пределами отображателя нигде не используется и не будет, но мне так больше нравится – легче код читать, да да: MVC, я знаю. Зато я взял в руки реальный, железный (пластиковый) бухгалтерский калькулятор, потыкал в него. Опросил наших бухгалтеров – А вам правда нужны M+, M-? Еще как нужны, оказывается. Зато история вычислений с промежуточными результатами – не нужны. Т.е. вообще-то нужны, и еще как, но пользоваться не будут – не привыкли. Знайте, если с вашим ПО работают бухгалтеры, то, наверное, они сидят за десктопами, а не за ноутбуками с их ублюдочными клавиатурами и Num Lock у них всегда включен, правая рука, как коршун висит над цифровым блоком. Это знание может пригодится, например при расстановке ShortCut’ов и прочей клавиатурной навигации. Num Lock важен, Singleton нет! А еще они прошаренные пользователи (я не шучу) и клавиатуру используют в хвост и гриву, т.ч. Tab Order важнее Pixel Perfect (наезд на дизайнеров). Люблю интерфейсы, и у меня есть что сказать и про Material Design’ы всякие, и про бухгалтерские интерфейсы в стиле MS Access, но совсем не тема поста – а жаль.
P.S. Историю вычислений я все равно сделал, и память с произвольным доступом и даже возможность определения собственных констант (ну зачем бухгалтеру π, когда есть ставка чего-то там, про что я никогда не слышал).
Проект, по мотивам которого я пишу этот пост, написан на Паскале (Delphi), поэтому примеры, в основном будут на нем, но большинство тем достаточно общие, много кода не будет и надеюсь он будет понятен, что-то специфичное для Паскаля я постараюсь отмечать и объяснять.
Рефакторинга нет
Или есть, или нет… Когда меняешь дурацкое название переменной — это рефакторинг? Ну да, маленький, но рефакторинг. А когда переписываешь бездонное море кода в ядре системы? Кажется, что уже что-то другое, но формально – функциональность системы то не меняется, меняется только легкость поддержки и развития. А если меняются другие потребительские качества, например быстродействие? Где грань? Оставлю эту тему теоретикам.
Самое интересное, что я про него выяснил: нет никаких особых правил рефакторинга, все тоже самое, как при разработке нового и доработке существующего - можно заканчивать статью. Зато смещается система приоритетов. Работая с уже написанным кодом, смотришь на него как-бы новым взглядом, даже если это куски твоего собственного старого кода. Когда пишешь что-то новое у тебя в голове есть стройная картинка, ты в потоке, и все самой собой разумеется, а в реальности глаз замылен. Проходит время и все уже не так очевидно: многословно, слишком сложно, нелогично и непонятно... Делайте рефакторинг часто, но не слишком, когда новый взгляд уже есть, но не раньше и лучше не позже. Чем раньше вы облегчите себе и вашим коллегам жизнь, тем лучше. Делайте Code Review, рефакторинг может не понадобится, у нас его нет – пичалька, попробуем замутить.
Что делать
На извечные вопросы русской интеллигенции: Что делать и Кто виноват, есть два ответа: Ничего не делать, никто не виноват; Зимой мерзнуть, летом потеть. Анекдот советских времен
Нельзя просто так взять и сделать рефакторинг, скорее всего вы уже хорошо знаете проект изнутри и представляете себе степень бедствия. Но все равно надо с чего-то начать. Открою страшную тайну: не важно с чего вы начнете, главное ввязаться в битву. Например, проведите ревизию используемых фреймворков, библиотек и прочих зависимостей. Вот вроде бы я главный разработчик и провожу рефакторинг своего проекта, который я не плохо знаю изнутри, а в процессе такой ревизии обнаружил аж пять ZLib’ов. Пять! Карл!
Провели ревизию, теперь наведите уже порядок в своем королевстве, а то у вас свиньи, а не верноподданные! Бродят, где хотят. Поставьте их на место. Скорее всего у вас уже есть модули, библиотеки общего назначения, если нет (серьезно!?) – создайте. Переносите туда все, что у вас есть общего назначения, сплошь и рядом встречаю какие-нибудь там строковые функции в модуле работы с БД. Оформляйте их (библиотеки) как самостоятельный продукт, представьте себе, что вы будете их распространять, и даже продавать, вне зависимости от основного продукта. Выстроите четкую иерархию использования, только в одну сторону, никаких обратных или кросс связей. Должно получиться что-то такое:
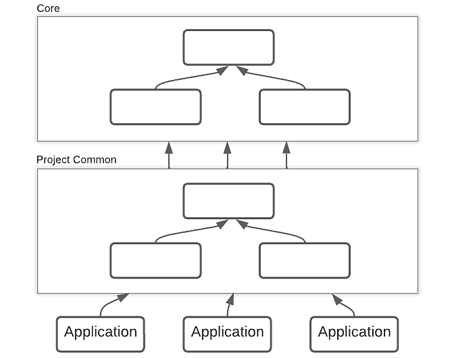
Получите более компактный код на каждом уровне выше, обнаружите кучу функций, дублирующих друг друга (я вам обещаю), станет легче ориентироваться в коде – понятно, где и что лежит, как минимум, где искать. Сплошной профит. Обязательно выносите всё платформенно зависимое в отдельные модули, прикрывайте их платформенно независимыми абстракциями. Я вот выношу, а абстракции оставил «на будущее» - не хватает времени. В самый, самый базовый модуль засуньте компиляторо-зависимые объявления. Например, если вам нужно собираться на старой версии системной библиотеки, и там не хватает типа, которой есть в более свежей версии, IFDEF вам в помощь.
Как метод, вообще создайте новые библиотеки, и переносите туда из старых, по мере востребованности, очень интересно смотреть, какой мусор остается в старых. И он есть, я обнаружил много не используемого. На начальном этапе, изменения были настолько тектонические: создавались и удалялись папки, массово менялись названия файлов, что-то прибывало, что-то убывало, что я это даже в SVN не заливал. Кстати, про репозитории, не вздумайте все это делать на старом репозитории – создайте новый. В старом, только если у вас не такой тотальный разгром, как у меня.
Тестируйте! Обязательно! Я не поклонник TDD, но это не значит, что тесты не нужны. Когда я дошел до тестирования API ядра, ошибок почти не было, а все почему: а потому что у меня раньше велосипеда не было библиотеки протестированы, кода стало меньше, и он стал более воздушный. Тестировать нужно, 100% покрыть все тестами заранее – ну пробуйте, я и пробовать не стал.
Размер имеет значение. Мало плохо, много – тоже плохо. Должно быть «в самый раз». В среде Delphi программистов есть такая тенденция: делать методы на сотни строк и с кучей параметров, юниты на бесконечные тысячи строк. Такое ощущение, что про декомпозицию никто не знает. В среде модных паттерн-программистов обратная тенденция: всякие Import и Uses занимают большую часть текста, и слева (или справа) у вас бесконечная портянка из папочек, в которых папочки, в которых фолдеры, в которых директории. В них файлы. Текста в файлах кот наплакал. Я даже не знаю, что хуже. Воздержание! Воздержание!
Про жизнь
Лучшая работа – которую не надо делать. И кодирование не исключение.
Попробуйте рефакторинги встроенные в IDE. У меня не взлетело, единственное чем я реально пользуюсь, это переименование. Удобно, если работает. Все остальное – нет. Не так и не то. По крайней мере у меня не зашли всякие там «Extract interface», ни в одной IDE, которой я пользовался. Я не настаиваю, если вам удобно – славно, повезло! Для меня самый удобный рефакторинг – Ctrl+R/Ctrl+H, Replace мощная штука, только регулярки я пишу со скрипом, ну никак они мне не даются. Говорят, у IntelliJ с рефакторингами хорошо, не знаю, не довелось, к сожалению. Но попробуйте обязательно, если еще не пробовали.
Другой способ ничего не делать: взять готовое (ага, выше выкидывали, теперь берем). Писать собственный парсер JSON невероятно интересная задача, и столь же глупая. Возьмите готовую библиотеку. Но и это еще не все, если вы возьмете нашу библиотеку прямо сейчас, то совершенно бесплатно получите в нагрузку лицензию и смену версий, включая отсутствие поддержки устаревших версий. И тут в дело вступает реальность, во всей своей красе. Если вы пишите собственный проект, или просто одноразовый – это одно, можно не заморачиваться и использовать то, что лучше всего подошло. Если внутренний или под заказчика, но долгоживущий – другое, если же, как у нас, долгоживущий, тиражируемый, обросший кучей зависимостей, кастомизаций, интеграций и сертификаций – это капец совсем другое.
С лицензиями все более-менее понятно, есть политика фирмы или продукта, например разрешающая только пермиссивные лицензии, до свидания весь LGPL, MPL и прочая. Так что приходится бить по рукам, в первую очередь себя любимого, когда так и подмывает выкинуть кусок кода и заменить готовым, который написали люди поумнее меня, да и база пользователей у него несравнимая. Но, нет – нельзя. Но проблема решаемая, обычно есть что-то с лицензией Apache, MIT или BSD. Если все совсем плохо, есть коммерческие библиотеки или, иногда, можно купить коммерческую лицензию на Open Source продукт. Если денег дадут, конечно. Обычно дают, если сказать: «Очень надо», но это у нас фирма хорошая, не всем так повезло. Если чувствуете себя в силах – пишите сами, в конце концов, кто-то же написал все эти клевые библиотеки? Чем вы хуже? Создайте еще одну, свою, лучшую, уникальную, двигайте технологии вперед. Были бы идеи.
С версиями все гораздо сложнее, притащив себе что-то в постель проект, нужно отдавать себе отчет, что вам с этим дальше жить. Если на раз, можно и не париться особо, а если надолго? Выбирайте как жену/мужа, избегайте беспорядочных связей со сторонним ПО. Нужно понимать, что вам придется регулярно обновлять весь код, работающий с этой библиотекой, поддерживая работу ее актуальных версий. Если этого не делать, пройдет несколько лет и вы останетесь с тыквой на руках. Надо, просто обязательно, думать об этом заранее, и это не простой выбор: взять и поддерживать актуальность, залить себе в кодовою базу и держать как свое или сразу пилить свое. Оценивайте плюсы и минусы: как это скажется на затратах сейчас и в будущем, как скажется на качестве кода, на возможности развития? Смотрите на историю проекта, как они развиваются, как относятся к обратной совместимости. Сложно, особенно сложно если у вас фронтенд, я безумно рад что у нас его можно сказать что и нет. Ну правда, не представляю себе на чем сейчас писать проект со сроком жизни в годы и даже десятки, ванильный JS и все? Или таки тащить React/Angular/Vue, с их бешенным темпом развития? Или Vaadin? Или переписывать все 5-тыс форм каждые несколько лет? Ужос страшный, и не моя головная боль (хотя я, конечно, знаю, что делать, но не скажу). Как хорошо жить с РСУБД, SQL не меняется десятилетиями – вот что значит грамотный дизайн.
Вот мы и перешли, плавно, к самым страшным словам на свете: Обратная совместимость. Я знаю, руки чешутся, всё зудит… НО! Если вы кого-то на что-то подсадили, всё! Забудьте и не смейте трогать! Добавлять можно, исправлять и улучшать можно – менять, тем более удалять, нельзя! Кое-что конечно сделать можно. Предположим, у вас есть, НЕЧТО, работающее так-то, вас не устраивает как оно работает. Добавляете настройку или параметр или новый header: Старый вариант, Новый вариант, по умолчанию - Старый. Или как-то так: «Версия 1», «Версия 2», «Версия N». Если у вас форматы протоколов, файлов, API – вводите версии форматов, если их еще нет. Без них никак, потом замучаетесь.
Главное, не забудьте, старое должно работать по-старому. Новое – как хотите.
Про совместимость в коде, бывает страшное, вы сделали что-то нехорошее, хак, и не уверены, что в следующих обновлениях компилятора, базы данных, ОС — это будет работать. Не делайте так! Но иногда очень надо, «ну позязяаа, можно я сделаю каку?» и взгляд кота Шрека. Отмечайте это как-то, лучше всего если на этапе компиляции, вот так:
{$IFDEF CompilerVersion <= 42}
DoShit;
{$ELSE}
У тебя не тестированная версия Delphi! Проверь каку!
{$ENDIF}Компилятор просто свалится на этом куске. Повторюсь, делать так можно только в самом, самом крайнем случае, если остальные варианты еще хуже.
Часто, вопрос совместимости возникает, потому что решили частную проблему, здесь и сейчас. Ну как-же: не заниматься преждевременной оптимизацией, не плодить абстракции раньше времени – херь полная. Хотите создать себе, или другим, страшный геморрой в будущем, не думайте о нем. Затраты на переделку гораздо больше, чем сделать сразу. Иногда, переделать совсем невозможно. Да вы не сможете сразу сделать все правильно, но, чаще всего, это вылезет еще на этапе начальной разработки, когда у вас уже есть зависимости, это делать сложнее. Все знают про снижение зависимостей: интерфейсы там всякие, DI, API абстрактный… И какой DI, какой API, если вы сразу не подумаете о абстракциях? У вас высоконагруженный сервис, а вы фигачите сериализатор на RTTI (Reflection), и протокол к нему в нагрузку соответствующий. Знаете, каково это потом выковыривать? Делайте сразу абстрактную прослойку (Middleware), будут вам и протоколы и сериализаторы на любой вкус. И не забудьте сделать их Zero Copy, ага, если сможете. Ну хоть кольцевой буфер, где-то в конце прослоек, не больше. Думайте о будущем! Make future great again!
Наплодили абстракций, по всему коду приведения типа, плохо наплодили, плохо использовали! Нет, приведение типов нужно, но, если его видите, возьмите лупу, рассмотрите получше. Это как насморк, ничего страшного, но может быть симптомом чего-то нехорошего. Например, Delphi программисты (опять про них, но это потому, что я этот мир лучше знаю. В вашем мире другие примеры, ничем не лучше) часто настолько не любят абстракции, что вообще не используют специализированных типов, особенно для внутреннего использования. Натягивают сову на глобус повсеместно используют TStringList, TList и т.д. куда запихивается все что не попадя, ну что сложно сделать свой тип элементов контейнера, унаследовать от TList свой класс? И это если вы сидите на древней версии, а если на новой? Вам и Generic’ов завезли, и контейнеров на них, на любой вкус, и Record’ы вам с сокрытием видимости, методами и перегрузкой операторов. Не, всё в StringList и потом: TEdit(List.Objects[Index]), тьфу на вас. Хорошо спроектированные типы залог успеха! Они упрощают программу, дают возможности для оптимизаций, сокращают кол-во ошибок.
Ура! Сделали типы! Теперь в них так:
TMyClass = class
Name: string;Не используйте публичные поля, у вас есть property и IDE пишет их за вас.
TMyClass = class
private
FName: string;
procedure SetName(const Value: string);
public
property Name: string read FName write SetName;Обратили внимание на public/private, тоже бывает ленятся. Все публичное в property! Делайте на автомате, думать не надо. А то мне потом breakpoint ставить некуда.
Свойства есть, пора подумать о конструкторах (Внимание!!! это рекомендация для Pascal). Всегда вызывайте унаследованный конструктор в конструкторе, даже если он не виртуальный (разработчики C++ бьются в истерике), даже если в суперклассе его нет. Все равно вызывайте. Вы не знаете, что еще запихнет разработчик суперкласса в свой конструктор. А если он изменит его сигнатуру, вы сразу об этом узнаете. Бывают случаи, когда этого делать не надо, но это редкость и скорее всего ошибка проектирования.
Данные есть, объекты создаются, теперь они должны себя «вести». Пора лепить методы. Раньше я любил делать методы с параметрами по умолчанию, теперь меньше люблю. Предпочитаю перегруженные методы, они более специализированные, соответственно проще, понятнее и часто, быстрее. В любом случае, думайте о сигнатурах методов! Лучше дайте разные названия, чем потом искать почему «происходит что-то странное».
Давайте методам имена в одном стиле, например, типичные для Delphi:
Something – просто метод: собственно поведение;
DoSomething, DoBeforeSomthing, DoAfterSomething – виртуальные методы, с высокой вероятностью вызывающие события (делегаты). Вызываются в Something, интерцепторы;
HandleSomething – то что вешается на события других классов;
GetSomething, SetSomething – понятно.
Сразу понятно, о чем речь. Если у вас большой класс, разбивайте внутри модификаторами доступа, ничего страшного если у вас несколько private и protected секций, зато сеттеры отдельно, делегаты отдельно, реализации интерфейсов отдельно (комментируйте, какой интерфейс реализуете). Внутри сортируйте по алфавиту, все равно не сможете расположить члены класса в некоем «логически верном» порядке. А по алфавиту хоть искать проще.
Используйте правильные модификаторы для параметров. Если с var параметрами, обычно, нет проблем их просто надо ставить «по логике», то с out и const, часто не заморачиваются, а зря. Думаю, понятно почему, и семантика сразу ясна, и защита от ошибок и Warningи не кидаются.
Не забываем про компилятор, в Pascal, например, передача всякой динамики (строки, динамические массивы, Variant) и интерфейсов в const параметры существенно оптимизируется, аргументы не копируются в записи активации, не ведется подсчет ссылок. Не поддаются счету такты процессора и ячейки памяти, которые я сэкономил, просто проставив const, где его не было. Ставьте const не думая, если что, компилятор вам напомнит. Если ваш такого не умеет - плохо. Но тогда и модификаторов нет, скорее всего.
Вот и вернулись к «преждевременным» оптимизациям. Оптимизации оптимизациям рознь. Есть эффективные и дешевые, как const параметры, есть дорогие и сложные. И, как правило, сложные не дают кратного роста эффективности, это последний рубеж, когда эффективность дороже затрат. Часто простые оптимизации, отталкивающиеся от знания предметной области, гораздо эффективнее чем от математики или знания нюансов работы процессора. Вот пример:
function TQuery.FindField(const FieldName: string): TField;
var
I: Integer;
begin
for I := FLastFieldIndex to Fields.Count - 1 do
if Fields[I].FieldName = FieldName then
begin
Result := Fields[I];
FLastFieldIndex := I;
Exit;
end;
for I := 0 to FLastFieldIndex - 1 do
if Fields[I].FieldName = FieldName then
begin
Result := Fields[I];
FLastFieldIndex := I;
Exit;
end;
Result := inherited FindField(FieldName);
end;В чем фишка? Это переопределение системного метода FindField, который в цикле перебирает все поля, пока не найдет нужное, причем регистр не учитывается, т.е. там циклический вызов Юникодного сравнения строк без учета регистра – медленно. Из каких предположений написан этот код:
Я знаю, что в нашей системе, все или почти все вызовы, делаются в правильном написании, т.е. мы можем использовать просто равенство, бинарное сравнение гораздо быстрее.
Получение значения одного поля в цикле, LastFieldIndex его покрывает.
Перебор множества полей в цикле, довольно часто порядок перебора и порядок в запросе одинаковы, LastFieldIndex нам в помощь.
Все это не нужно, если не лениться биндить поля на переменные перед циклом – супероптимизация! Лень не всегда двигатель прогресса.
Другой пример. Есть такой код, в системной библиотеке, который мы раньше использовали, пишет Variant’ы в поток (часть сериализатора), и там метод для записи вариантных массивов. Обобщенный, не в смысле Generics, а в смысле что может писать многомерные массивы (код приводить не буду – его слишком много). Код там довольно сложный, и это понятно. Но давайте посмотрим правде в глаза, вы когда последний раз использовали многомерные Variant array? Вообще многомерные массивы? В 100 случаях из 100, это одномерный массив. Ну и пишем простой код, для одномерного массива: длина, элемент. Быстро, просто, эффективно. Старый запихиваем в else, если все-таки встретится многомерный. Идем дальше, очень часто, в таких массивах передаются просто двоичные данные, т.е. это массив чисел. Вспоминаем, что есть волшебная функция VarArrayLock (SafeArrayLock в WinAPI). Возвращает нам ссылку на память, занятую этим массивом, этот блок упакован, ну и пишем его целиком. Никакого копирования памяти при этом не происходит, т.е. представьте себе, мегабайтный массив, в первом случае это миллион раз получить элемент массива, с проверкой индекса, промежуточным копированием значения, во втором никаких проверок, никаких копирований сразу пишется куда надо, и все. Практически бесплатно. Сложная оптимизация? Дорогая?
Make Up
Вы можете выглядеть, как угодно, и даже доедать завтрак из бороды во время презентации, мне плевать кто и что думает о моей внешности, но ваш код обязан быть элегантным, и не только своими решениям, но и внешне. Вы слышите меня бандерлоги пытающиеся запихнуть в одну строчку кода как можно большее? Краткость сестра таланта, но не во вред читабельности. Правила просты и не новы, и все равно, сплошь и рядом жуткая жуть.
Придерживайтесь единого стиля написания кода, даже если он вам не нравится. Если, как в моем случае, все написано в разнобой, приводите к одному стилю, и да, в этом случае, у вас есть возможность выбора. Но не очень большая, по моему мнению надо писать в некотором «общепринятом» стиле, я за основу взял стиль в оформлении и именовании принятый в системной библиотеке (скажем: наиболее распространенный в системной библиотеке).
Даже если язык не чувствителен к регистру, пишите так как будто чувствителен. Повышается читаемость, улучшается поиск. Если чувствителен, не злоупотребляйте этим, мне, лично, не нравится распространённая практика использовать одинаковые идентификаторы для свойств, в CamelCase, и соответствующих им полей класса, в lowercase. Но я их использую, если такова практика, например в C# часто такое. Но предпочитаю так: _lowerCamelCase.
Именование идентификаторов. Во всем надо знать меру, я не люблю короткие имена, но злоупотреблять излишне длинными, тоже ни к чему: FWDDEOF - ужасно, как и FindWordByDifferentDelimitersFormEndOfFile (нужна ли вообще такая функция – отдельный вопрос). Я для себя придумал следующее правило: В цепочке вызовов не должно быть масла масляного, и должно быть понятно, о чем речь:
· Entity.EntityTable.TableName – плохо;
· Entity.Table.Name – хорошо.
Именование счетчиков, не надо их называть ItemIndex, достаточно I, J, K… Хотя если дошли до K, остановитесь, наверное, что-то пошло не так.
Пример из жизни, как плохо жить с непонятным кодом. Имеем следующее:
procedure TProvider.ProcessLF(ads,dds:TDataset;sads:TQueryDataset);
Что имеем (кроме эмоций):
1. Экономию пробелов, в дефиците были;
2. LF в названии метода. Вы знаете, что такое LF? Я тоже не знаю. Line Feed?
3. ads, dds, sads – ну теперь то стало понятнее! Что, не стало? Мне тоже нет.
Лезем в код, ага, LF это Linked Fields. Про DS’ы ясно только одно – это TDataset. Что делает метод, тоже не особо понятно, из кода не очевидно, верьте мне. Ищем вызовы метода, ага «ads» – SourceDS, «dds» – DeltaDS, становится яснее. Я знаю, что это такое, более того именно так они называются в системной библиотеке. Остался «sads», и это… барабанная дробь! Тоже самое, что и SourceDS, но приведенное к конкретному типу. Тупо переименовываем, и получаем:
TProvider.ProcessLinkedFields(SourceDS: TQueryDataSet; DeltaDS: TDataSet);
Уже гораздо лучше. Еще немного рефакторингов, и конечный результат:
TLinkedFieldList.Build(const SourceDS: TQueryDataSet; const DeltaDS: TCustomClientDataSet);
Вызов:
Provider.LinkedFields.Build
Кроме всего прочего, код в Build, сократился вдвое, за счет устранения ненужных преобразований, приведений типов и проверок.
Комментарии. Кажется уже всем плешь проели: Пишите их только если что-то нельзя понять из кода, описывать код не надо. Надо писать так, чтобы и без них все было понятно. И все равно… Правильные комментарии:
//Workaround VCL bug, QC #12345678
//TODO: Вынести в настройки
Отстой:
Counter: Integer; //Счетчик записей
Document.Delete; //Удаляем документ
OM = $08; // FPU Overflow interrupt mask
Лучше так:
FPUOverflowMask = $08; // Комментарий уже не нужен
{ Вариант для эстетов: }
{$SCOPEDENUMS ON}
TFPUControlMask = (
…
Overflow = $08
);«Магические» константы. Ну даже писать ничего не буду, но они все равно есть. Вот почему Copy(S, I, 99999) вместо Copy(S, I, MaxInt)!? И это еще не самое худшее.
Все знают, если есть повторяющийся кусок кода, наверное его надо вынести в отдельный метод. Но я часто выделяю код в отдельный метод, или чаще локальную функцию, просто для повышения читабельности, даже если в этом нет другого смысла. Например, у вас есть длинный метод, с циклом, скажем. Внутри цикла сложная проверка, и если она выполняется, делаем одно, если нет – другое. Если кода много (в экран не влазит), я разбиваю, проверка в отдельной функции, действия при True в другой, при False в третьей. Читабельность резко повышается.
Доктор едет-едет
Верьте себе! Не верьте себе!
Иногда бывает, что вы смотрите на код и он вам не нравится, непонятно чем, но с ним «что-то не так». Подумайте, почему у вас такая реакция на этот код, что именно «не так»? С высокой вероятностью обнаружится какая-либо проблема и/или пути улучшения кода. Очень часто наши интуитивные реакции оказываются верными. Верьте себе!
Из наблюдений за собой, основной источник плохого кода: доведение кода до рабочего состояния: вот здесь подправлю, тут добавлю, а еще это не так работает… Тяп ляп, во – работает. Закончил кусок, посмотри на него снова, оцени.
Основной источник дублирования кода – память (ваша, а не комьютера), невозможно удержать все фреймворки и библиотеки, со всеми их возможностями в памяти, вот и появляется дублирование. Не пишите функции там, где не надо, просто потому что они вам понадобились именно здесь. Найдите им «правильное» место, возможно там ее и найдете. А вообще не знаю, как решать проблему системно.
Системное мышление порождает несистемные проблемы. Если я вижу, что какие-то классы содержат похожий набор методов, реализующих сходное поведение, я сразу-же «на автомате» начинаю выделять общий базовый класс, интерфейс, агрегат. Потом оказывается, что этот интерфейс нигде и не используется, так зачем плодить сущности? Выделить интерфейс, если он нужен, всегда успеется. Тем не менее, однозначно есть повод призадуматься. И тогда могут открыться интересные вещи, а могут и не открыться.
Иногда, я захожу в тупик, проще говоря начинаю пороть уйню, или просто тупить. Не верьте себе! Следите за собой, если почувствовали, что всё, приехали - остановитесь, переключите задачу. Вообще переключите область деятельности, займитесь спортом, напейтесь, сварите борщ. Мозг рано или поздно вернется, но не надо его насиловать, это неприятно и вредно для него и для работы. Я, вот, пишу этот пост.
Катарсис
Может сложится впечатление, что я переделывал какой-то ад кромешный — это не так, понятно, что я приводил самые вопиющие примеры, не все так плохо. Но все равно эта работа вымотала меня окончательно.
Жалею ли я, что ввязался в это? – ни на грамм. Я давно не испытывал такого кайфа. Улучшать, создавать для продукта перспективы на будущее развитие – огромный кайф!
Кода
Я, на разных этапах, давал почитать этот пост разным людям, и собрал много критики: словоблудие сплошное, слишком длинно, непонятно на кого рассчитано, плохо структурировано, вот это так делать нельзя… Каюсь, все правда, со всем согласен! И всё равно, я не стал ничего править и публикую в том виде, в каком есть. Дело в том, что это не мой пост, он сам себя написал, мне не было сложно его писать, он такой родился. Сам собою. И я не хочу его предавать, пытаясь улучшить и переделать, тем более не публиковать.
За сим откланиваюсь, желаю всем в новом году сделать что-нибудь хорошее, доброе, вечное, так как год ожидает быть… Пошел стругать Буратину оливье. Пока!
Комментарии (21)

PastorGL
27.12.2022 19:36-2Начал читать. Протёр глаза. Проверил календарь. Декабрь 2022 года, точно. Но ощущение, что читаю пост с sql.ru откуда-то из 2002, никак не проходит. Такой древностью повеяло, что аж страшно.
Автор, батенька, вы напрочь сварились в собственном соку. За то время, пока вы (судя по тону, в основном в одно лицо) разрабатывали ваш продукт, индустрия ушла уже очень далеко.
Я и сам не то что бы молод, и если бы я продолжал разрабатывать свой первый относительно успешный продукт с 2001 года по сей день, вероятно, написал бы что-то в таком же духе. Но я с тех пор трижды поменял технологический стек, а предметную область и того больше раз. Было тяжко каждый раз, но зато не застрял в прошлом. (А относительно успешным продуктом пускай лучше занимается молодёжь, уже без моего участия.)
Да просто чтение чужого кода, написанного с новым синтаксическим сахарком в очередном модном молодёжном стиле, здорово поднимает уровень осознанности того, что ты делаешь. Особенно хорошо, если этот чужой код на каком-то новом для тебя языке с другими акцентами.
Не тащите на себе это вечное легаси, в нём не будет счастья.

ap1973 Автор
27.12.2022 19:54+2Вам со стороны виднее, спорить не буду. По фактической стороне:
Нет, я пишу не один, совсем даже не один. Вот этот рефакторинг (только рефакторинг) делает аж цельных три человека. Просто на мне большая нагрузка, это да. А в целом, над продуктом работает несколько десятков человек, и это только разработчиков, не считая тестирования и прочего...
Поверьте, я менял технологический стек, и у меня в багаже много всего разного, и очень древнего, и не слишком, в том числе и модного, молодежного. Тут вы ошиблись.

oldd
28.12.2022 09:41+3Не так всё однозначно.. Вы можете привести пример языка, который строит нативный exe в считанные секунды? Пишу в основном под десктоп, и это прям боль, ждать когда сборщик соизволит закончить работу. Что ява, что котлин, что qt, что электрон, все тормознутые донельзя. Плюс размер бинарников какой-то умопомрачительный.
А родная старая делфа - нажмёшь F9, пара секунд и форма на экране. Как же мне этого не хватает.

splinters
27.12.2022 20:27Во многом соглашусь. Пойду-ка я дальше перелопачивать 12 репозиториев по ~300kloc индусского жавакода.

Maccimo
28.12.2022 01:11+2новый файл с классом из десяти строк
Это лучше, чем unit-братская могила на 10 000 строк, в которую напихано всё подряд.
Но при чём тут «паттерны»?
Если употребление паттерна улучшает качество кода, то его использование оправдано. А сколько там строк совершенно не важно.По крайней мере у меня не зашли всякие там «Extract interface», ни в одной IDE, которой я пользовался.
Можно подумать, будто для Delphi много IDE.
Начните с «Extract Method», а там втянетесь.Для меня самый удобный рефакторинг – Ctrl+R/Ctrl+H, Replace мощная штука, только регулярки я пишу со скрипом, ну никак они мне не даются.
Тупиковый путь, чреватый ошибками.
Говорят, у IntelliJ с рефакторингами хорошо
В IDEA он божественен.
У тебя не тестированная версия Delphi! Проверь каку!
Директиву $MESSAGE FATAL завезли ещё в каком-то дремучем году.
Нет никаких причин косплеить Turbo Pascal for DOS.Result := Fields[I]; Exit;Можно просто
Exit(Fields[I]);ap1973 Автор
28.12.2022 01:42+1Про паттерны, я же не написал что не надо их использовать. Весь пост про умеренность.
Рефактоинги - я писал: пользуйтесь. У меня, лично, не зашло. Про Replace спорить не буду, сомнительный путь, но работает иногда.
Про MESSAGE FATAL не знал, спасибо!
Exit(Result) - это если у вас, семерки нет в списке совместимостей ;)

DenisPantushev
28.12.2022 12:35Зачем нужно публичные поля загонять в приватные и делать проперти-геттеры-сеттеры? Что это дает? Ну, кроме мусора, конечно? Какие тайные знания появляются, какой функционал у системы появляется? Проперти нужны, если при при присваивании имеются действия, которые необходимо выполнять при присваивании. Много у вас таких филдов в приложении? Прям все? В шарпе взяли моду, все абсолютно поля делать приватными и геттеросеттеры плодить. В джаве - хоть и можно делать публичные поля, но джава-общество принципиально не согласно не заниматься ахинеей. При этом эти бессмысленные и бесполезные геттеросеттеры настолько всех задолбали, что даже придумали ломбок, который сам делает геттеросеттеры. И к чему все вылилось? Фактически, все публичные поля, которые должны быть по-хорошему объявлены публик (и не париться), и являются публик, но через жопу - через ломбок.
Сплошное применение геттеросеттеров вредит структуре проекта. Нарушает явное разделение полей на закрытые от внешнего мира и открытые. Они все - приватные, но НЕКОТОРЫЕ - с геттерами и/или сеттерами. Вместо того, чтобы просто увидеть "публик", надо анализировать взглядом, есть у него геттеросеттеры или нет. Ладно, если ломбок есть, там по собаке можно определить. А если через обычные методы? Шариться по коду?
Чем мне нравился Дельфи - так это тем, что там можно было делать публичные поля, и там где надо - приватные. И вы тоже тащите в Дельфи всю эту гомосятину с гетеросеттерами. "Рефакторите" хороший прямой код. Фу.
ap1973 Автор
28.12.2022 12:44Вот уж не думал, что тема свойств будет так обсуждаться. Проходная совершенно. Забавно.
qw1
ap1973 Автор
А затем, что бы другому разработчику не надо было лазить в ваш код.Написали название с типом и Ctrl+Shift+C, все готово. Вам, что жалко?
Про паттерны, я все таки про что-то более крупное, мне не приходило в голову, что пропертю можно обозвать паттерном, хотя наверное можно.
qw1
Так лишние строки из ниоткуда появляются, и какая от них польза, непонятно.
Чем «свойство» спасёт стороннего разработчика от необходимости залазить в ваш код? Разве что у вас VCL-компонент, а свойство published, и тогда его можно настроить из IDE, но в примере это не так.
ap1973 Автор
Я подумал, почему же все таки свойства, и понял вот что:
В отладке это действительно важно, и это частая ситуация, когда вам нужно посмотреть, где происходит присвоение. Под "залазит в код" я имел ввиду его изменение. Сторонний, очень условно, это ваш коллега, который использует, но не пишет, эту библиотеку.
Вот о чем я не написал, не здесь, ни в посте, так это о единообразии. Может быть, это вкусовщина, или даже мания, но меня бесит когда его нет. Когда в одном месте свойства, в другом поля. Или хуже того в одном классе и то и другое. Может быть это мое личное, но не порядочек.
Есть все таки семантическая разница, между полем и свойством. Чисто с технической точки зрения ее нет (если
property Name: string read FName write FName), но она как суслик - есть.qw1
Я понимаю манию на свойства в java/.net, там это объясняется тем, что библиотеки ORM или сериализации создают служебные прокси-классы — наследники ваших классов, и могут перекрыть геттеры/сеттеры, чтобы добавить нужное поведение (в java все методы по умолчанию виртальные). Но в Delphi-то зачем?
DenisPantushev
В дельфи разве нет брекпоинта на изменение переменной или поля? Точно?
и 3. Вы здесь противоречите самому себе. Если есть разница между полем и свойством - то и надо писать поля (закрытые или открытые) и только в НЕКОТОРЫХ случаях - свойства. Только когда нужно. А не писать единообразно и поля и свойства в виде пропертей. Нельзя "единообразно" писать, потому что да, между полем и свойством (и даже между приватным полем и публичным полей) - есть разница.
Maccimo
Вам за экономию строк платят? Нет? Тогда не стоит заниматься ерундой.
qw1
Мне нравится лаконичность. Чем меньше строк, тем проще читать и понимать код.
Maccimo
Нет ни одной причины держать поле публичным кроме «прадед моего прадеда писал так». Нужно будет отлавливать запись — добавите в декларацию свойства сеттер вместо имени поля.
qw1
Тут вы расходитесь с автором статьи, который всегда хочет сеттер в явном виде, чтобы ставить туда брейкпоинты (кстати почему запись хочет ловить, а чтение не хочет, показывая в примере
не вижу никакой причины, кроме «прадед моего прадеда писал так»read FName write SetName?).писать же
doctorw
При отладке какого-нибудь бага нередко возникает ситуация, когда в свойстве оказывается какое-то неожиданное значение, и в попытке узнать откуда оно там берётся — ставится точка останова на сеттере свойства.
DenisPantushev
Прадеды так не писали, мне кажется. Тотальное закрытие полей и гетеросеттеризация - относительно новый тренд.
qw1
Да уже выросло поколение, у которых деды практиковали эти паттерны.