
Не прошло и пяти лет, как в Java 18 докатилось небольшое, но очень ожидаемое и обсуждаемое изменение: теперь во всех стандартных API используется UTF-8 кодировка по умолчанию. Это изменение, которое сделает выражение «Write once, run anywhere» действительно правдой, так как теперь поведение приложения будет еще меньше зависеть от системы, где оно запущено.
На конференции Joker я рассказал, как развивались события в работе над JEP-400 и как сделать так, чтобы ничего не поломалось после перехода на новые версии JDK. А теперь делюсь с Хабром и видеозаписью доклада, и текстовой версией. Как говорится, помимо двух самых сложных задач в программировании – нейминга и инвалидация кэша, есть ещё две: таймзоны и кодировки. Вот о кодировках и поговорим. Как читается название — разберёмся в конце.
Мир переходит на Unicode
Стандарты давно фиксируют использование юникода: HTML5 и XML, в JSON-е сразу несколько. Языки программирования меняют кодировку, используемую по умолчанию: Python 3 с появления декларирует Unicode, .NET с выходом Core 2.0. Появляются языки вроде Go и Rust, которые с самого зарождения используют юникод. В PHP 6 тоже хотели завезти нативную поддержку Unicode, но не смогли, но это уже совсем другая история. И вот, настал тот день в 2022-м, когда Java тоже по умолчанию используется UTF-8.

В чём проблема?

Возьмём Windows с Java ниже 18 версии. Запишем «Привет, мир!» в файл методом, который без указания кодировки по умолчанию берёт значение из Charset.defaultCharset(). Перекинем этот файл на Mac или Linux, считаем и получим крякозябры.
Проблемы бывают даже на одном и том же компьютере. Скажем, мы в Windows записали файл с помощью Files.write(path, str.getBytes()), а потом считали с Files.readString(path) и снова закрякозябрились.
Но Java же очень надёжный язык, он не может просто так поломаться? Разработчики языка тоже так подумали и решили, что надо с этим что-то сделать. И пришли к герою сегодняшнего дня: JEP-400.

Жизнь до JEP-400
Сначала посмотрим, как было раньше.
Разработчики не всегда указывают конкретную кодировку при вызове методов. Либо ленятся, либо указание ломает красивые конструкции
(::)в стримах.Property-файлы, начиная с JDK 9, лежат в UTF-8.
Методы класса
java.nio.file.Filesпо умолчанию считываются в UTF-8, в них это прямо захардкожено.Некоторые классы (
URLEncoder/Decoder) задепрекейтили методы без указания кодировки.Остальные получают кодировку из метода
Charset.defaultCharset(), который смотрит на ключик-Dfile.enconding, который, в свою очередь, смотрит на системную локаль.В Windows используются кодировки а-ля Windows-1251, зависящие от региона, а на Linux и Mac используется Unicode.
Из-за этого и возникают проблемы.
Более того, многие используют ключ -Dfile.encodıng, чтобы сказать JVM: «Используй Юникод и не смотри на систему». Хотя на самом деле, этого делать было нельзя, потому что по словам создателей, это внутренняя деталь языка и не следует никак ни читать, ни изменять это значение. И единственный способ поменять кодировку в приложении по словам авторов — это поменять её в системе до старта приложения. Поэтому, например, если поменять на лету значение параметра -Dfile.encodıng с помощью метода setProperty, то ничего не выйдет, так как он кешируется на старте. Это справедливо для большинства JVM, но каждый производитель виртуальной машины вправе сделать это иначе, так как спецификация никак не описывает поведение этого ключа.

Так выглядел ответ авторов JVM по поводу этого ключика, сейчас уже страничка удалена.
Как решить эти проблемы, если ты разработчик языка?
Представим себя на месте инженеров, создающих Java. С одной стороны, можно оставить всё так, как есть. Может, это и выход, но проблема реальная, и надо её решать.
Можно задепрекейтить методы без конкретного указания кодировки и сказать: «Слушайте, разработчики, теперь вы должны обязательно указывать кодировку». Помимо очевидного удлинения кода (а Java не всегда радует своей лаконичностью), все производители библиотек пойдут хардкодить своё значение кодировки.
Можно забить на развитие Java и выпустить новый язык :) Конечно, это шутка, но у Kotlin и других новых языков всё уже в порядке. Для нас это не выход: очень много систем, которые работают на Java, и сам язык живее всех живых.
Можем просто захардкодить UTF-8 или любое другое значение везде, но тогда мы поломаем обратную совместимость. А Java очень славится стремлением к сохранению контрактов.
И вот мы пришли к пути JEP-400 — это trade-off, выбор между разными вариантами.
Что поделать |
Последствия |
Ничего не делать |
Не решит проблему |
Задепрекейтить методы без указания кодировки |
Удлинит код, риск получить непараметризуемый зоопарк |
Выпустить новый язык :) |
Не выход |
Захардкодить UTF-8 везде |
Ломаем обратную совместимость |
Путь JEP-400 |
Так и победим |
В далёком 2017-ом…
Откроем багтрекер OpenJDK и посмотрим, какие решения тогда были приняты. Там прямо написано «что мы хотим сделать»:
Cделать поведение программ более предсказуемым и портируемым в методах, где используется кодировка по умолчанию.
Определить, где Java API использует кодировку по умолчанию.
Стандартизировать UTF-8 во всех Java API, кроме консоли.
Но почему UTF-8? Почему не любая другая кодировка?

Во-первых, соседние языки, особенно более свежие, уже давно решили избрать ее стандартом.
Во-вторых, популярные способы обмена JSON и XML давно уже используют UTF-8. Это прописано в спецификации.
В-третьих, это уже де-факто стандарт для веба. По статистике подавляющее количество страниц используют UTF-8 кодировку.
Ещё есть методы класса java.nio.file.Files, захардкодившие эту кодировку. И, согласно JEP-226, property тоже в UTF-8.
Но прежде чем мы пойдем дальше, небольшой экскурс UTF-8 и кодировки вообще.
Короткий экскурс в кодировки
Итак, что такое кодировка. Если упрощать — это маппинг между тем, что вы видите на экране и тем, что компьютер на самом деле хранит у себя. Если еще грубее сказать — это некоторый ключ, с помощью которого расшифровывается последовательность нулей и единиц, превращаясь в читаемые символы.
Исторически так сложилось, что компьютеры в разных странах развивались своим темпом, и сейчас существует большое количество кодировок — Java поддерживает 173.
В России были популярны Windows-1251, CP866 и KOI8-R. В Китае вообще интересно — на выбор кодировки влияет в том числе политическая обстановка. Некоторым локациям повезло ещё меньше — вот ситуация в Японии:


В конце концов, нашлись такие ребята, которые в свое время сказали: «Хватит это терпеть!», и сделали как в меме “Что делать, когда у нас и так много конкурирующих стандартов?” — еще один. Назвали Unicode, определили миссию: «Соберем в себе все возможные начертания и символы, которые вообще человечество когда-либо создавало». С переменным успехом это получается.
Но мало собрать все символы — нужно их хранить и передавать. И для этого придумали несколько Unicode Transformation Format — UTF.
UTF-8 использует переменное количество байт на один символ — от 1 до 4. UTF-16 кодирует количеством байтов кратным 2. UTF-32 фиксированной длины — всегда 4 байта.
Простой символ латинского алфавита J живёт в однобайтовом диапазоне. Буква Д уже в двухбайтовом промежутке. А эмодзи ленивца ????, который на самом деле тоже символ юникода, находится в четырехбайтовом диапазоне. Вот так они записываются в разных UTF-форматах:

Как вы думаете — какова длина гусеницы? Что выведет код?
System.out.println(“????”.length()) 1, 2 или 4? Или код вообще не соберется?
Посмотреть ответ
Этот код может не собраться. Зависит от настроек энкодинг-параметра в компиляторе — ключика в javac. Но, как правило, IDE сама прописывает Unicode, приложение соберется, будет работать замечательно, и длина гусеницы будет равна 2.
Как Java хранит строки
Почему так происходит? Для того, чтобы ответить на этот вопрос, давайте посмотрим, как в Java хранятся строки. Создадим строку из шести кириллических символов, пробела и 5 латинских букв и переведём в байты.
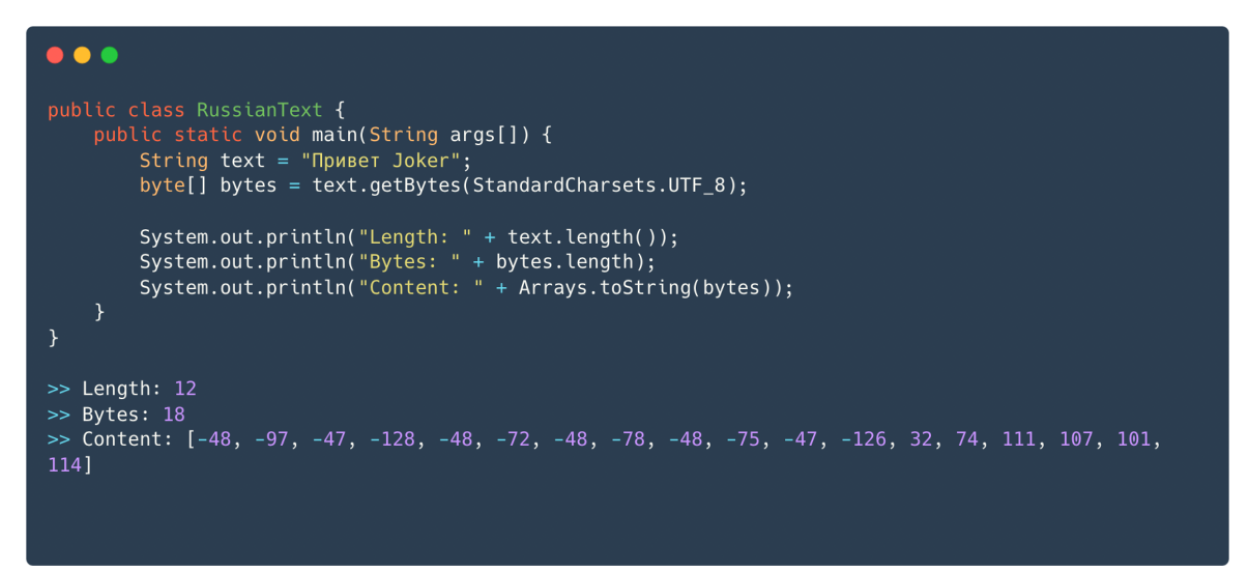
Длина строки 12, что логично. Байтов 18, потому что когда символ помещается в однобайтовый промежуток, он весит 1 байт, плюс по два на символы в «Привет».
Если говорить о гусенице, которая, как эмодзи, входит в четырехбайтовый промежуток, ее длина — два, потому что строки в Java используют UTF-16, и для записи нужно два места.

Кстати, если внутри Java — UTF-16, почему мы идем в UTF-8? Дело в том, что UTF-16 оптимальнее только в больших иероглифических текстах, и в остальных случаях сильно проигрывает по хранению.
Еще есть UTF-32 с фиксированным количеством байтов на символ. Это очень хорошо для индексации, поиска и замены, но очень неоптимально по памяти — крайние байты почти не используются и будут просто заполнены нулями. Поэтому ответ очевиден — надо брать UTF-8.

JDK-17: Подготовка и появление -Dnative.encoding
Вернёмся к нашему детективу. В начале появился параметр -Dnative.encoding, принимающий значение кодировки операционной системы. Учтём предыдущий опыт, когда все повально пошли менять -Dfile.encoding на свои значения, сделаем его исключительно read-only и прямо об этом напишем.

JDK-18: Новое поведение
Едем дальше. Методы класса java.nio.file.Files оставим по умолчанию захардкоженными на UTF-8, как это и было раньше. Остальные методы стандартного API смотрят на Charset.defaultEncoding() и, соответственно, -Dfile.encoding. И вот здесь появляется развилка — новшество, которое пришло в новой Java. Зафиксируем этот параметр по умолчанию в UTF-8, попутно легитимизируя спецификацией его использование и перезаписывание. При этом, помня об обратной совместимости, сделаем compatibility-режим, эмулирующий старое поведение. Если выставить -Dfile.encoding=COMPAT, параметр будет смотреть на свежесозданный -Dnative.encoding, принимающий значение системной кодировки. Таким образом сэмулируем старое поведение.

Что не так с консолью?
Казалось бы — всё позади, везде используем Unicode, все счастливы. Но теперь мы возьмём прошлый пример, выведем строку в консоль и сразу же закрякозябримся:

Консоль находится ближе всего к системе, и она определяет системную кодировку другим путём:
Стандартные средства вывода
System.outиспользуют новый методConsole.charset(). Он смотрит на свои параметры и зависит от локали терминала, в котором запущено приложение. Если приложение запущено вне терминала — этот метод будет смотреть на дефолтную кодировку черезCharset.defaultCharset()с его новым поведением.Стандартный логгер в спринге — Logback — как правило параметризует кодировку в настройках аппендера. Если этого не сделать, он пойдёт в
Charset.defaultCharset()и будет теперь UTF-8 по умолчанию. Вот тут риск получить крякозябры в логах при обновлении JDK.Log4j2 также смотрит на настройки аппендера, и хорошо, если мы указали кодировку там. Но если не указали — он уже захардкожен UTF-8. Тут ничего не должно поломаться, так как поведение останется прежним.

С выводом разобрались, а что с вводом?
Здесь — ещё хуже. Кто-то смотрит на Charset.defaultCharset(), кто-то на Console.charset(), кто-то сразу возвращает строку в UTF-16 без возможности считывания символов побайтово, а какую кодировку ожидает на вход скрыто за реализацией JVM.
Что осталось прежним?
Пути файловой системы. Значение кодировки, с которой передаётся строка типа
C:\Program Files\Новая Папка (3)зависит от ключа-Dsun.jnu.encoding.Никак не поменялось внутреннее представление строки.
Проперти файлы. Они, начиная с Java 9 в UTF-8.
Отдельная история — это кодировка исходного кода. Это прямо целый новый мир, любопытные могут начать изучение отсюда.
Какие риски обновления на новые JDK?
Несмотря на стремление авторов Java сохранить обратную совместимость, риски чего-нибудь поломать при обновлении существуют. Например, записанные ранее файлы могут перестать считываться. Причём это заметно не сразу, при записи не будет никаких проблем или исключений, и самое интересное начнётся позже при попытке чтения. Ещё можем закрякозябрить UI. Особенно, если работаем с кириллицей. Плюс, нюансы с выводом в консоль. И в случае, когда мы строим логику в зависимости от значения строк, можем столкнуться с некорректным поведением.

Как минимизировать эти риски?
Самое очевидное — всегда указывать кодировку при вызове методов. Если есть возможность — работать с UTF-8 и просить внешние системы отдавать UTF-8. Если нужно работать с системной кодировкой, читать -Dnative.encoding. Поставить всевозможные линтеры, включить проверку в Quality Gate.
Если система древняя без возможности доработать — пока что есть возможность работать по-старому. Указывайте -Dfile.encoding=COMPAT, и всё будет как прежде.
Меня закракозябрило. Что делать?
Короткий ответ — ничего. Это путь в одну сторону. Но можно попытаться что-то исправить. Например, визуально определить по чеклисту, что это за символы. Либо использовать какие-то бытовые декодеры или библиотеки, которые как-то пытаются угадать, какая это кодировка.
Итак, давайте перейдем к итогам.
Что хорошего получили
В Java, начиная с 18-й версии, везде в стандартных API используется UTF-8 по умолчанию. Ключ -Dfile.encoding, которые многие до этого использовали кустарно — теперь стандартизован, поведение описано, и мы изучили его работу. Появился новый параметр -Dnative.encoding, доступный только для чтения, который показывает системную кодировку.

Какие зоны развития
Несмотря на усилия, JEP-400 поломал обратную совместимость. В классе java.nio.file.Files методы по умолчанию захардкоженно смотрят на UTF-8. Возможно, в будущем это поменяется — в JDK ещё много мест для стандартизации подходов при работе с кодировками.
Вместо послесловия
Наблюдать за развитием языков бывает увлекательно, особенно когда это касается спорных моментов, где нужно выбирать между несколькими вариантами, каждый из которых имеет последствия. Изучая багтрекеры, можно лучше понять причины конкретной реализации, попутно вдохновляясь элегантными (и не только) ходами, которые можно переиспользовать в бытовой разработке.
На этом всё. А назывался доклад «JEP-400 или UTF-8 кодировка по умолчанию».
Рассказывайте в комментариях, с какими проблемами с кодировками вы сталкивались в своей жизни?
Минутка рекламы от организаторов конференции. Если вас заинтересовал этот доклад, наверняка найдёте интересное и на следующей Java-конференции JPoint, которая пройдёт в апреле. Можно будет хоть поучаствовать в онлайне, хоть лично прийти на конференционную площадку в Москве. Все подробности и билеты — на сайте.
Комментарии (20)


Busla
12.01.2023 15:19+5.NET с выходом Core 2.0
разве в .NET Framework под капотом не с самого начала был UTF-16?

enabokov
13.01.2023 00:23String как был UTF-16 с первой версии, таким и остался.
Источник: String Class (System) | Microsoft Learn

sugrobov Автор
13.01.2023 10:18+1Под капотом действительно UTF-16. Что мне понравилось, ровно как и в Java, методы класса
System.IO.Fileпо умолчанию вне зависимости от системы выдадут UTF-8. А вотEncoding.Default, которым пользуются остальные для определения кодировки по умолчанию, в .NET Framework смотрит на систему, и на винде выдаст что-то ANSI-подобное – в отличие от .NET Core.Вот, например, официальная документация к Framework говорит об этой разнице. Или хорошо это подмечено тут


periskop
12.01.2023 15:35+4лучше использовать рабочую
https://web.archive.org/web/20201027153639/https://bugs.java.com/bugdatabase/view_bug.do?bug_id=4163515sugrobov Автор
13.01.2023 18:25+1Спасибо, на момент написания не находилась в веб архиве ссылка, сейчас заменил.

event1
12.01.2023 18:44-2Вообще проблема выглядит несколько надуманной, чтобы ради неё писать целый jep и целую статью. Если на машине не настроена правильная кодировка, то винавата не джава, а пользователь. В питоне, например, надо указывать кодировку при перекодировании str в bytes и никто не кашляет.

3735928559
13.01.2023 10:18Да, при этом в тексте упоминается как проблема вызов Files.write(path, str.getBytes()) и Files.readString(path). Конечно же в String.getBytes() и Files.readString() можно передать Charset.
event1
13.01.2023 12:59Я имел ввиду, что можно заставлять всегда указывать кодировку явно (как в питоне для str->bytes) и вообще не будет проблемы.

Rsa97
12.01.2023 19:07+6UTF-8 использует переменное количество байт на один символ — от 1 до 6.
Только до четырёх.
В ноябре 2003 года стандарт RFC 3629 запретил использование пятого и шестого байтов, а диапазон кодируемых символов был ограничен символом U+10FFFF. Это было сделано для обеспечения совместимости с UTF-16.

enabokov
13.01.2023 00:31Автор смешивает таблицу символов Unicode и стандарты её кодирования UTF-8, UTF-16 и т. д.
.NET Framework поддерживает Unicode с первой версии, кодируя текст в своих классах в UTF-16 (как и весь текстовый API Windows). Encoding.UTF8 поддерживается как минимум с версии 1.1 (источник Encoding.UTF8 Property (System.Text) | Microsoft Learn)

ToSHiC
13.01.2023 02:14+3По заголовку статьи сразу видно, что закодировали русские буквы как UTF8, а прочитали как cp1251.

usernameak
13.01.2023 18:57Кто в здравом смысле не юзает StandardCharsets.UTF_8, а полагается на дефолт?

valery1707
13.01.2023 19:14В основном те для кого дефолт и есть
UTF-8так как для них разницы нет.
Страдают те для кого это не так.

Mingun
В данном случае не поэтому, а потому, что попросили байты в кодировке UTF-8. Так будет на любой джаве.
sugrobov Автор
И правда, поменял в статье, спасибо!