

Привет! Меня зовут Николай Тихонов, я работаю в команде Tinkoff eCommerce. Я начинал как фронтендер, а потом стал писать бэкенд и занялся CI/CD. А дальше — FullStack Ops и руководство процессами и собственной командой. Сегодня расскажу про FrontOps, blue-green и релизы без даунтайма. Эта статья — текстовая адаптация моего доклада для FrontendConf 2022.
С минимальными знаниями Ops-технологий фронтендер может показывать каждому пользователю, что он сделал, и в одиночку реализовывать крутые продукты. А релизы с даунтаймом все еще существуют и не дают клиентам пользоваться продуктом ночью, поэтому в этой статье поговорим про практику blue-green.
Зачем нужен blue-green?
Например, чтобы:
повысить доступность;
предоставить окружение — второй прод, на котором можно без побочных прогонять автотесты и нагрузочное тестирование;
расширить кругозор, а как известно, больше кругозор — больше денег.
В Ops-мире миллиарды технологий — для одного только деплоя их сотни. То, чем обычно пользуются в Tinkoff eCommerce, может сильно отличаться от того, чем пользуетесь вы. Поэтому в статье будет максимально абстрактная теория без особенностей реализации. Возможно, эта информация поможет настоящим продакшенам, которые по какой-то причине не переехали в Kubernetes.

Эти два кота помогут в нашем рассказе. Маленький только пришел в индустрию и готов впитывать всю информацию от старших коллег, а большой полон знаний и технической мудрости.
В один чудесный день большой кот решил, что пришло время научить кота-джуна нажимать кнопку деплоя. Да, он еще не понимает, что происходит, но ведь нажать кнопку — это просто.
На радостях маленький кот убедился, что все тесты на тестовом окружении прошли и все работает. Тестировщик сказал, что все супер, значит, можно деплоить. И вот кот нажал кнопку и собрался уходить на обед, но вдруг что-то произошло.

Наверное, многим знакома эта ситуация: котик сломал прод и не понимает, что случилось, ведь все тесты работали. Откатывать сам он боится, поэтому ждет, когда придет большой кот и все откатит.
В итоге прод продолжил жить своей жизнью. Но жизнь маленького котика уже не станет прежней. Ему хочется понять, что пошло не так. А случиться могло многое:
Код недостаточно покрыли тестами или автотестами. Или покрытие тестами в норме, но мы не все протестировали.
Тест и прод сильно различаются. Например, тест гоняется локально на машине разработчика с выходом во внутреннюю сеть, а прод — в Kubernetes. В этом случае 100% что-то пойдет не так.
Нестабильная инфраструктура. К сожалению, рядовой разработчик мало что может с этим сделать. Перепады напряжения, проблемы с сетью, и деплой падает — со всеми бывает.
Простая человеческая ошибка. Мы могли выкатить в прод что-то, что вообще не должно было туда попасть. Например, интеграцию, которую в тестовом режиме уже настроили, а на проде — еще нет. Или не загрузили секреты в продовые конфигурации, и прод лег.
Котик подумал, подошел к большому коту и сказал:

Большой кот призадумался и вспомнил, что, вообще-то, такая штука есть — это blue-green деплоймент. И стал про него рассказывать.
Blue-green to the rescue!
Есть обычный продакшен, присоединенный к обычному интернету, в который приходят обычные люди, — каждый может в него зайти. Чтобы настроить blue-green, поднимают еще один абсолютно идентичный по конфигурации сервер. Если это виртуалка — то еще одну виртуалку. Если сервис в Kubernetes — то еще один такой же.
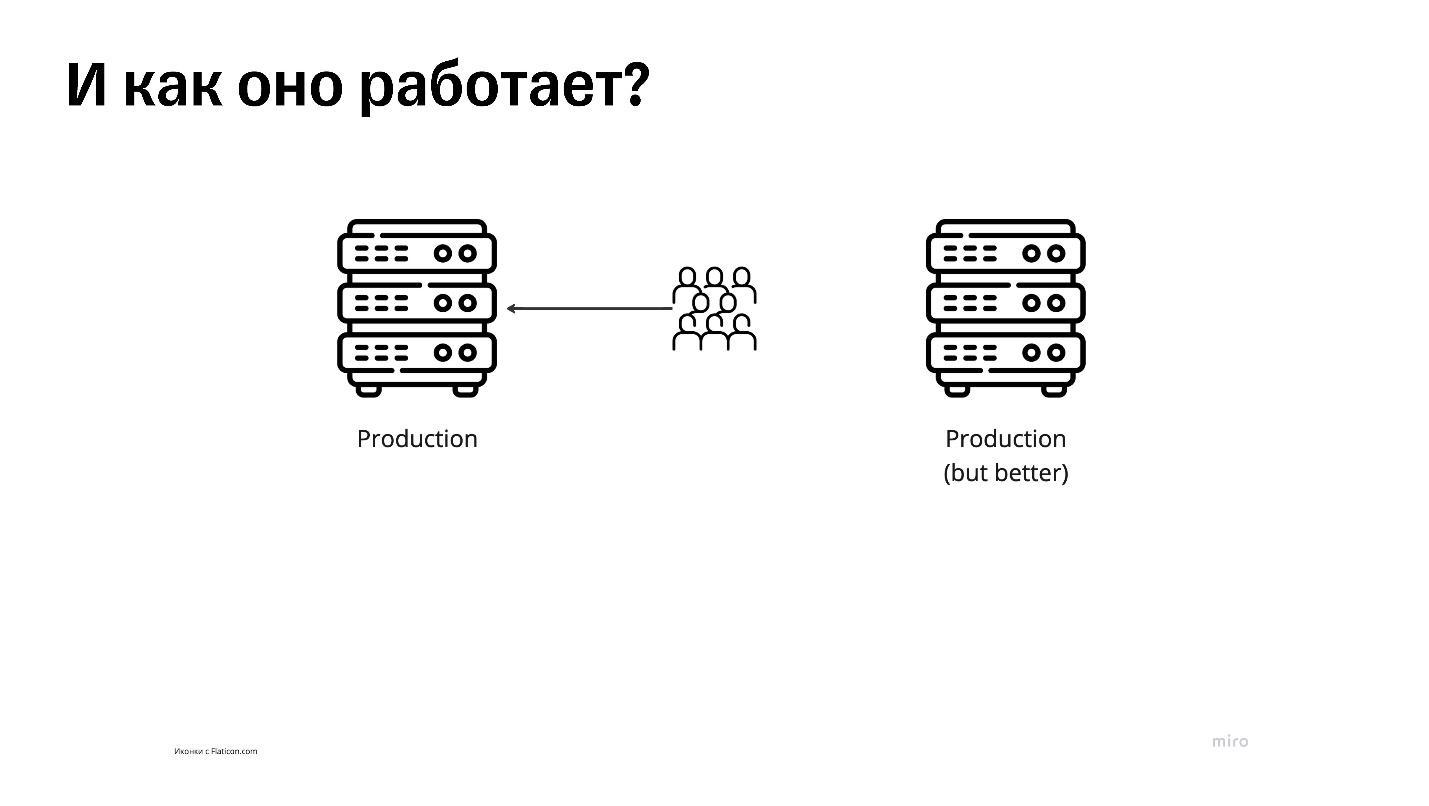
Сервисы абсолютно одинаковы по конфигурации, но версии приложения на них могут лежать разные, поэтому второй прод и подписан на иллюстрации как лучший. Один из продов назовем зеленым, а второй — синим, чтобы различать, потому что не знаем, на каком из них лежит продакшен.

При этом синий остается настоящим продакшеном, куда ходят люди, а зеленый — запасной вариант. Туда пока что нет никакого трафика, и мы можем заходить туда, делать определенные операции: ломать, чинить, тестировать — все что угодно. И уходить.
На самом деле без разницы, какими цветами вы назовете эти конфигурации, просто прижилось blue-green. Можно называть их хоть black-white — как угодно.
Зеленый сервер называем стейджингом, ведь он для нашего личного использования.
Синий остается продакшеном, эта роль с него пока не снималась. Перед ними поставим балансировщик. Это прокси, который будет проксировать все запросы в синий сервер, потому что это продакшен, куда нам нужно отправлять трафик. Но как это сделать?
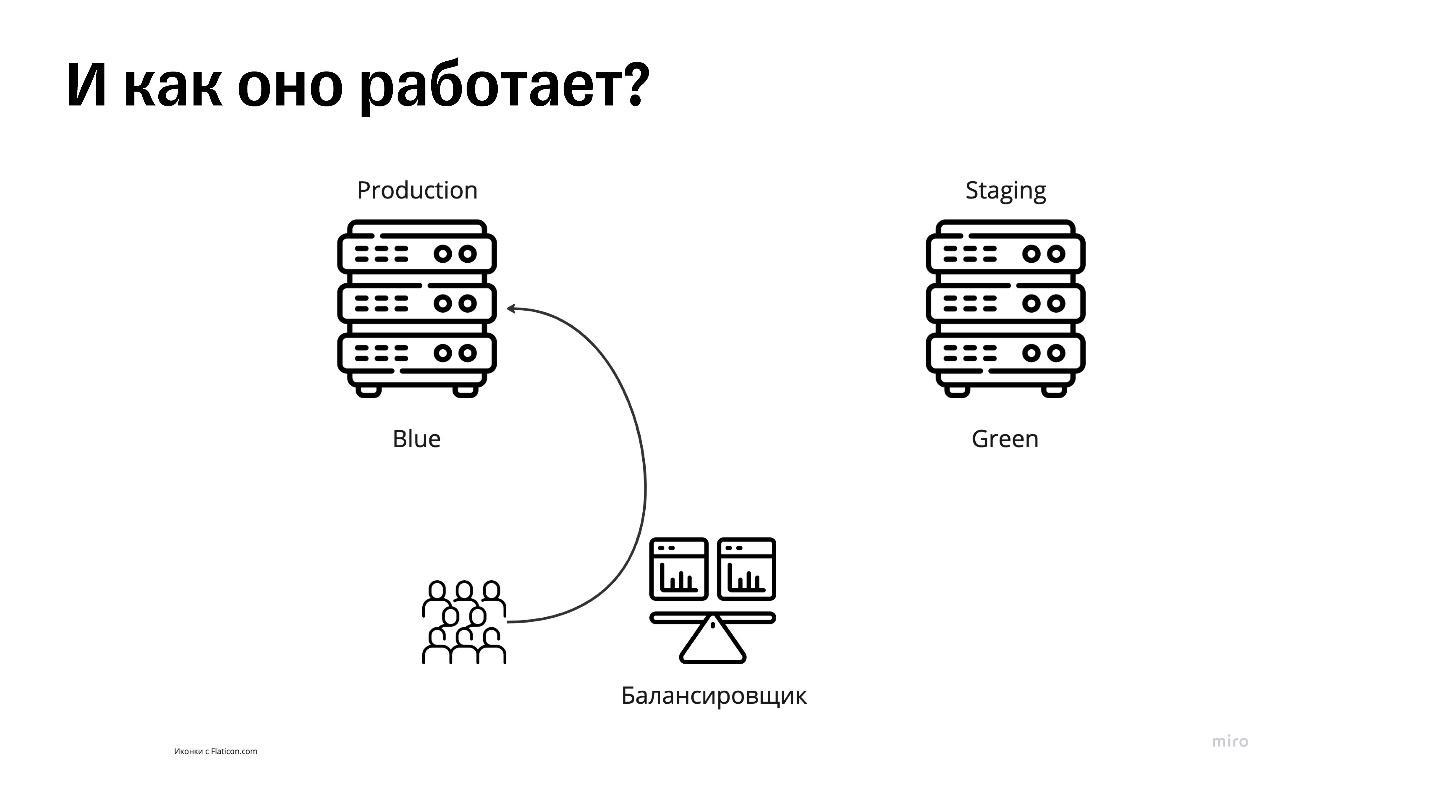
На самом деле продакшен не знает, что он продакшен, потому что и синий, и зеленый сервер идентичны. Оба прода равноправны. За их роли отвечает балансировщик, он знает, что прод — тот, что синий. Именно ему мы сообщаем, какой из продов настоящий.
Так происходит релиз:

Допустим, на синем контуре у нас вторая версия приложения, на зеленом — первая. Когда решаем выкатить релиз, просто раскатываем наше приложение на зеленом контуре, куда никто больше не зайдет. Там мы можем гонять автотесты или нагрузочное тестирование прямо на проде. Его не жалко уронить, потому что там нет трафика.

А потом берем и переключаем весь пользовательский трафик с синего на зеленый.

Для этого нам ничего не нужно трогать на серверах, достаточно сказать балансировщику, что прод теперь зеленый. Делается это за несколько секунд. Если на локальной машине, то хватит всего полсекунды. Эту процедуру обычно называют свитчем.
Откаты мгновенны
Даже если после свитча что-то пошло не так — например, к нам пришел разъяренный котик-продакт и сказал, что мы выкатили лишнего или с опечатками, — можно просто нажать свитч еще раз и за считаные секунды откатиться обратно.

Как попасть на стейджинг
Нам нужно как-то сообщить балансировщику, что мы не рядовые пользователи. Чаще всего это разделение делается на уровне кук или хедеров.
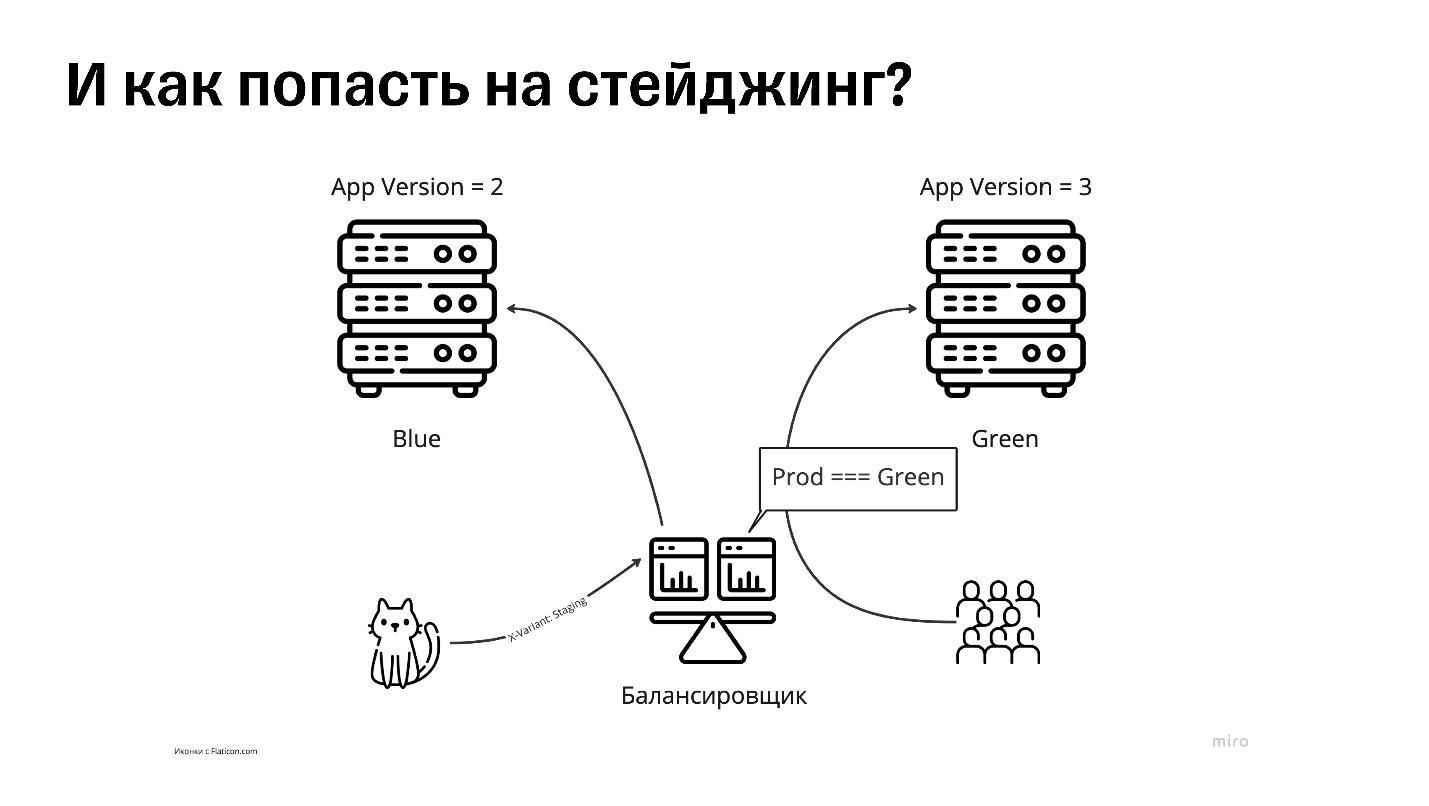
Например, если заходим на балансировщик с проставленным хедером X-Variant: Staging, он понимает, что мы — свои, и пускает нас в стейджинг.
И вот спустя какое-то время в нашей бравой команде из двух котов появляется blue-green. Котик с замиранием сердца снова нажимает на свой первый свитч и видит, что все прошло нормально: на проде и в инкогнито ничего не упало. Но у пользователей почему-то ошибка 404. Большой кот говорит: «Откатывай, что-то пошло не так!» Котик откатывает, заходит на прод — снова все нормально. Только у пользователей ненормально — ошибок 404 стало еще больше. Причина — кэш, или lazyload.
Кэширование, или lazyload
Ребята, которые сидели на прошлом проде, продолжали пользоваться приложением после релиза. Например, пытались перейти в какое-то не прогруженное заранее место. Из-за lazyload они получили ошибку 404, потому что на настоящем проде этого чанка уже нет, он остался на стейдже.
В интернете в этом случае предлагают несколько решений.
CDN. Нам не нужно думать о старой статике, если она всегда доступна. Если вытащить статику в CDN, в индексе не будет прямых путей к приложению, когда мы зайдем в чанки. Пропатченный индекс делает так, чтобы все ссылки на чанки вели в CDN. Нам не нужно думать о статике, когда она лежит в левом месте.
Хранилище статики. Не нашли файл на проде? Балансировщик попробует поискать там. Если у нас нет CDN, а есть другое хранилище, например внутренний S3, можно сделать фолбек на уровне балансера. Когда балансер хочет выдать ошибку 404, он подумает еще раз и сходит либо в это хранилище, либо в стейджинг. Если он найдет этот чанк, то отдаст его, и только если не найдет — выдаст 404.
Жесткая перезагрузка. Версия, чтобы пользователи точно оставались на текущем проде, но делать так не очень хорошо. Можно попробовать сделать fallback на фронте — жесткую перезагрузку. Можем написать обертку над выполнением запросов, которая будет выполнять location.reload в момент возникновения ошибки 404. Этот вариант подходит только в крайнем случае.
Окраска запросов. Некоторые облака, например Amazon Web Services, позволяют «клеить» сессию к серверу, к которому от клиента пришел первый запрос. Если мы зашли на зеленый прод, то всегда остаемся на нем, так как сессия приклеится к нему. Но тогда приложение будет знать, как мы его деплоим, а это плохо. Ведь если вдруг мы продадим свое приложение в другое облако, где нет такой возможности, придется переписывать большую часть приложения, а это расходы.
Backend-for-Frontend без запар с контрактами
Бэкенд для фронтенда — это когда у нас один огромный бэкенд и куча сервисов, которые пытаются к нему прикрепиться. Например, веб-фронт, фронт с мобилки, нативные мобильные приложения и интеграции. Если мы хотим описывать все одним контрактом, это, как правило, не очень хорошо заканчивается. На фронтенде неудобно пользоваться бэкендом, который старается быть удобным для всех.
Фронтендеры в какой-то момент устали от этого и решили написать свой бэкенд, который будет для них удобен и сможет по контрактам кэшировать ответы.
Если вы все-таки используете бэкенд для фронтенда, то вот несколько лайфхаков.

На самом деле, когда есть специальные бэкенды для фронтенда, следить за контрактами бывает лень. Одно поле переименовали в контрактах — уже боль. Многие решают это хорошими инженерными практиками — например, плавными переходами, версионированием и составлением старых эндпойнтов на несколько релизов вперед. Но если у нашего бэкенда только один потребитель — и это мы сами, — то ничего не мешает соединить два приложения в одно и релизить бэкенд вместе с фронтендом. Многие так и делают.
Но обычно релизы все равно не происходят синхронно, потому что фронтенд, как правило, выкатывается быстрее бэкенда и инициализировать в нем нечего. Между этими релизами все равно есть микролаг. Например, фронтенд обгоняет бэкенд на 10 секунд, час или четыре часа.
Релиз всего сразу
Blue-green позволяет спрятать за одним местом балансировки неограниченное количество размеченных сервисов, а не только фронтенд.

Их стоит покрасить в один и тот же цвет — тогда можно и фронтенд, и бэкенд задеплоить с разницей хоть в несколько часов. Они все равно останутся на стейджинге. Попасть туда можно только самостоятельно, пользователей туда не пускают, а потом просто делают свитч.

Все — пользователи ушли на новый фронт и бэк одновременно. Но теперь будет сложнее работать с кэшированием, ведь если у нас подкэшировалось хоть что-то на фронтенде, мы, скорее всего, будем ходить в старый бэкенд.
Когда проблема решена, бэкенды для фронтендов сделаны и приложение продолжает жить своей жизнью. Мы спокойно его релизим, но подходит подросший маленький котик, который уже стал крутым мидлом, и говорит, что слышал про canary-релизы. Он предлагает внедрить их. Большой кот спрашивает: «А что это такое?»

Canary
На самом деле Canary похожа на blue-green.
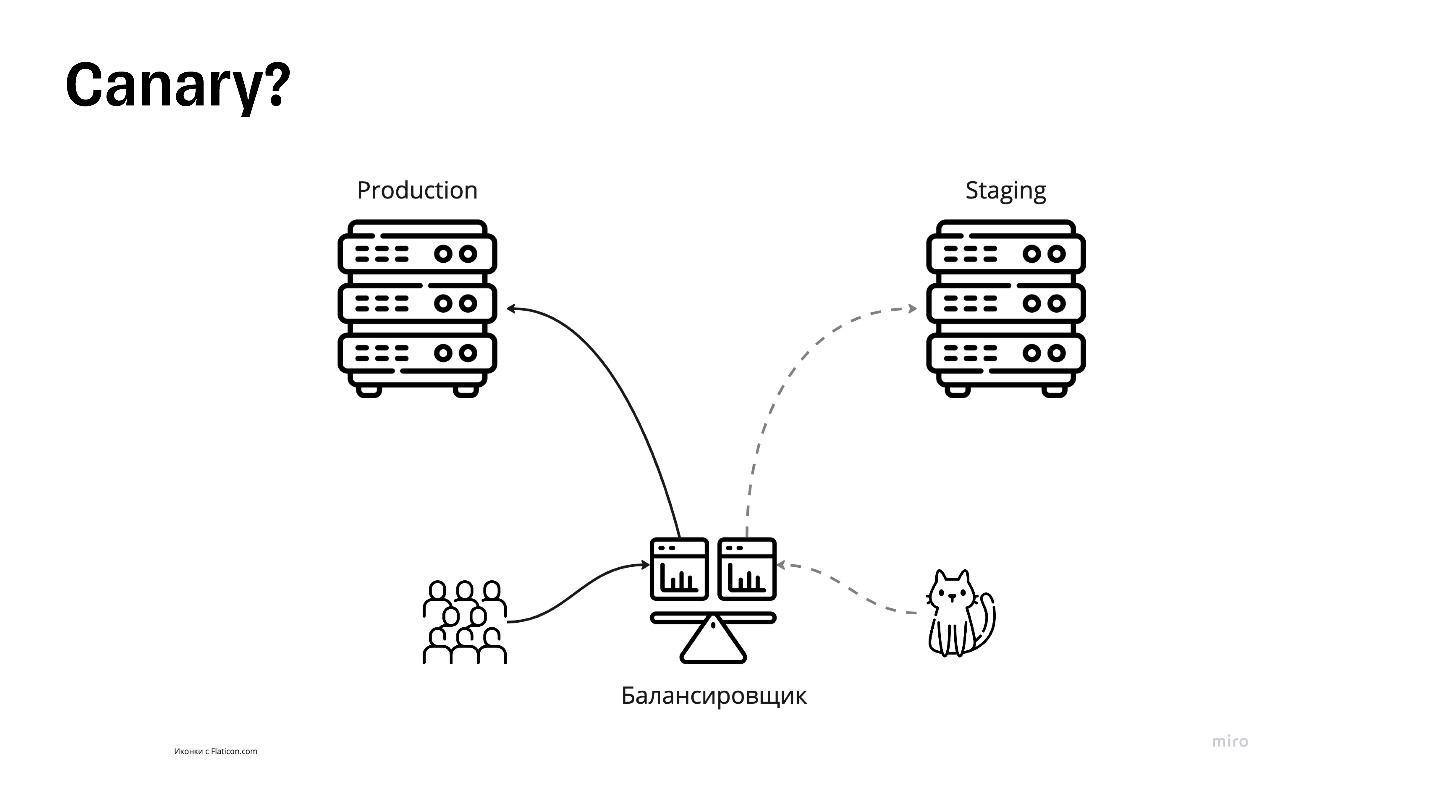
Тут опубликована схема из blue-green, потому что, если он хорошо спроектирован, его можно легко переделать под Canary.
Здесь не нужны цвета, потому что продакшены будут хоть и одинаковые по конфигурации, но немного разные по размерам. Например, если приложение довольно большое, по три сервера под прод и под стейджинг — на каждый цвет по три сервера.
Один из этих серверов можно оставить под стейджинг, а остальные пять перегнать в прод. Тогда прод будет более устойчивым и выдержит больше нагрузки.

Один оставшийся сервер оставляют под так называемую канареечную версию.

Канареечные релизы — это когда небольшая часть пользователей самостоятельно заходит на стейджинг и смотрит на новый деплоймент. По факту релизы обходятся без нас. По метрикам или просто сидя в чате с алертами можно проверять, что происходит: не упало ли что-то, молчит ли Sentry. Если все хорошо, выкатываем канареечную версию в продакшен, если нет — откатываем изменения.
Еще нужно понимать, что пользователи на самом деле лояльны и готовы к таким релизам. Чтобы это проверить, можно размечать cookie при авторизации. Например, если пользователь залогинился, проставим cookie «лояльный». Балансировщик видит лояльность пользователя и пускает его на стейджинг или в прод. Это делается примерно так же, как в blue-green.
Но здесь снова могут возникнуть проблемы. Например, канареечный прод может упасть и какое-то время лежать. Даже если лояльный пользователь зашел на прод, а он лежит, это не весело. Если мы пользуемся бэкендами для фронтендов, появляется лаг: когда мы раскатываем на продакшен, бэкенд снова может закатиться позже фронтенда. Приходится включать голову, становиться хорошими инженерами, что-то версионировать и придумывать. А не хочется.
Но мы и не будем говорить про Canary, потому что это уже совсем другая история. Если у вас настоящий прод и вы не уехали в Kubernetes, можете их попробовать.
Заключение
Ни для кого не секрет: чтобы стать большим мудрым котом, надо много практиковаться. Еще недавно говорили, что достаточно 10 тысяч часов, сейчас уже говорят о 30 тысячах часов. Но стать мастером своего дела без отличных инструментов невозможно.
Поэтому, если вы еще в начале пути, берите на вооружение blue-green и все остальное, о чем мы говорили. Не стесняйтесь спрашивать и пробовать. Ищите — и обязательно найдете.
А если вы уже большой кот, не забывайте делиться своей мудростью с маленькими. От этого и им польза, и вам профит!
Комментарии (5)

DmitryKoterov
00.00.0000 00:00+5Ой, да ну ради ж бога.
Давайте возьмем самую простую из проблем - деплой stateless-сервиса - и разбалуним ее из ее реальных 2% до 98%, чтобы на конференциях обыватели хлопали и импакты сыпались. Кубернетисы головного мозга и т.д. Из серии «установил Линукс - отпишись на Хабре».
В реальности же 98% сложности и интересности в stateful мире. В базах данных и стороджах например. Вот ИХ как деплоить (или схемой управлять консистентно) - это реально тема.

luckywastaken Автор
00.00.0000 00:00+1Не сомневаюсь, сам в стейтфуле тонул. Однако это выступление было на конфе про фронтенд, для того чтобы познакомить с темой и как раз сказать что есть и простые вещи, которых не нужно бояться и для которых не нужно джва года ждать девопсов в команду

alexkuzko
00.00.0000 00:00+1Недавно заметил что AWS активно стал напоминать что для их SQL баз данных (RDS Aurora) доступен blue-green вариант выкладки с настраиваемой глубиной отката (!).
Там переключение тоже не моментальное, секунд 15, но сам подход интересный, плюс эта возможность вернуть не просто на шаг назад иногда может быть интересной (да, вероятность сделать серию деплоев в прод невысока, но зато летальность такой процедуры при "заболевании" как у бешенства...). Да, там через реплицирование работает под капотом.
Так что про проблему stateful знают и решают, где как.
С хранилищами это через версии и объектные хранилища работает. При условии поддержки на стороне приложения, правда. Пока не встречал прямо изумительной реализации (так то можно и снапшоты притянуть за уши...), так что если кто что слышал/использовал, поделитесь.
Max_Pershin
Вы знаете я пролистал вашу статью - я далек от энтерпрайз, может быть это вообще не в тему сказано. Но вот придумывают парадигму слабого связывания - у вас наверное микросервисы. Но зачем вся эта инфраструктура - эти варианты версий, их синхронизация - если есть система из маленьких отлаженных куском с простым api? Какой смысл в микросервисах и модульности реакт, если в итоге все равно дикие проблемы чтобы все это соединить?
luckywastaken Автор
Статья немного не про это — тут про доступность одного конкретного сервиса, а не про связку микросервисов. Вставка про bff больше про решение уже существующей проблемы, а не хорошие инженерные решения на начале проекта