
Представьте, что вы, совершенно один, отдыхаете в своём маленьком бревенчатом домике в лесу. Когда вы, декабрьским вечером, начинаете читать уже вторую книгу из списка «Книги недели», вы слышите поблизости чьи-то тяжёлые шаги. Вы бросаетесь к окну, чтобы посмотреть — кто это там прошёл. Через окно вы видите крупный силуэт кого-то, кто, кажется, покрыт мехом. Существо исчезает в тёмном лесу сразу за вашим крыльцом. Информация, которую вы получили из окружающей среды, прямо-таки кричит вам: «Я встретил снежного человека!». Но ваш здравый рассудок говорит, что это был, с гораздо большей вероятностью, просто слишком увлечённый путешествием турист, который прошёл мимо вашего дома.

Вы только что успешно совершили «правильную ошибку», предположив, что у вас за окном, вероятно, путешественник, несмотря на то, что имеющаяся у вас информация свидетельствует о другом. Ваш мозг нашёл «рациональное объяснение» исходной информации благодаря имеющимся у вас годам опыта жизни в лесу.
В этом эксперименте проводилось сканирование мозга испытуемых в то время, когда они смотрели на картинки, на которых был только «шум». Исследователи выяснили, что фронтальная и затылочная области мозга испытуемых проявляют активность в тот момент, когда испытуемые думают, что они видят в «шуме» лица. Эти области мозга считаются имеющими отношение к высокоуровневому мышлению, например — к планированию и к памяти. Подобный всплеск активности может отражать воздействие на восприятие ожиданий и опыта.
В соответствии с тем, что изложено в работе It’s Bayes All The Way Up, была построена модель восприятия, включающая в себя «рукопожатие» между «нисходящим» и «восходящим» аспектами человеческого восприятия. В упрощённом виде эту модель можно описать так:
«Нисходящий аспект»: Обрабатывает данные и выводит заключения на основании исходной информации, получаемой от органов чувств. Пугающий силуэт + вой = снежный человек.
«Восходящий аспект»: Добавляет поверх исходной информации «слой мышления», который принимает и использует «прежние знания» (то есть — опыт, полученный в прошлом) для того чтобы осмысливать данные. Пугающий силуэт + вой = слишком увлечённый путешествием (или пьяный) турист.

Дети гораздо более склонны «поддаваться» непосредственным выводам, которые делаются на основе «восходящего» восприятия. Это из-за того, что у их «нисходящего» восприятия недостаточно «опыта/обучающих данных», которые позволили бы этому восприятию самообучиться и улучшить свои качества. В некотором смысле это позволяет говорить о том, что их «модель мира» не так совершенна, как у взрослых.
Интересным последствием сильного «нисходящего» восприятия является способность людей видеть всякое, вроде животных и лиц, в облаках (парейдолия). Эта странная особенность мозга может показаться нам чем-то вроде «бага», но для наших предков, которые были охотниками или собирателями, это было скорее не «багом», а жизненно важной «фичей». Для них безопаснее было предполагать, что они видят где-то лицо, даже тогда, когда на самом деле никакого лица там не было. Это было средством защиты от хищников в дикой природе.
Что собой представляют мультимодальные языковые модели?
Большие языковые модели, вроде GPT-3/Luminous/PaLM, это, упрощённо говоря, системы для предсказания следующего токена. Их можно рассматривать как (большие) нейронные сети, которые обучены классификации следующего слова/знака препинания в предложении, что, выполненное достаточное количество раз, как представляется, позволяет генерировать текст, который согласован с контекстом.
Мультимодальные языковые модели — это попытка приблизить то, как подобные языковые модели воспринимают мир, к восприятию мира человеком. Большинство современных популярных моделей глубокого обучения (вроде ResNets, GPT-Neo и т.п.) отличаются узкой специализацией либо на задачах машинного зрения, либо на языковых задачах. Модель RestNet хороша в извлечении информации из изображений, а языковые модели, вроде GPT-Neo, хорошо генерируют тексты. Мультимодальные языковые модели — это попытка сделать так, чтобы нейронные сети воспринимали бы информацию и в виде изображений, и в виде текста. Достигается это благодаря комбинации моделей компьютерного зрения и языковых моделей.
Как работают мультимодальные языковые модели?
Мультимодальные языковые модели способны использовать знания о мире, закодированные в их языковой модели, в других областях, наподобие обработки изображений. Люди не просто читают и пишут. Мы видим, читаем и пишем. Мультимодальные языковые модели пытаются имитировать эти процессы, адаптируя свои части, ответственные за обработку изображений, таким образом, чтобы они оказались бы совместимыми с «пространством эмбеддингов» их языковых моделей.
Одним из примеров подобных моделей является MAGMA. Это — GPT-подобная модель, которая может «видеть». Она способна принять на вход произвольную последовательность данных, включающую в себя текст и изображения, и выдать подходящий текст.
Эту модель можно использовать для генерирования ответов на вопросы относительно изображений, для идентификации и описания объектов, присутствующих на входных изображениях. А иногда она ещё удивительно хороша в деле оптического распознавания символов. Она, кроме того, известна хорошим чувством юмора.

Предварительно обученная языковая модель, находящаяся в сердце архитектуры MAGMA, содержит знания о мире, которые используются для того, чтобы «осмысливать входные данные». Это во многих отношениях эквивалентно «нисходящему» элементу человеческого восприятия, что, как будет показано ниже, иногда помогает модели делать «правильные ошибки». Взяв пару цитат из работы It’s Bayes All The Way Up, мы можем обрисовать архитектуру MAGMA следующим образом:
«Восходящая обработка» — это когда восприятие встраивают в модель мира. В данном случае это — работа системы декодирования изображений.
«Нисходящая обработка» — это когда позволяют своей модели мира воздействовать на своё же восприятие. Именно этим и занимается языковая модель.
Что мы имеем в виду под «правильными ошибками»?

Если только вы не видели этого изображения раньше, то высоки шансы того, что вы прочтёте текст с него как «I love Paris in the springtime», а не как «I love Paris in the the springtime» (обратите внимание на второй артикль «the» в последнем варианте текста). Это так из-за того, что ваше «нисходящее восприятие» читает первую часть предложения и с уверенностью предполагает, что оставшаяся часть грамматически правильна.
Даже несмотря на то, что необработанные данные с изображения говорят вам о том, что тут имеется второй артикль «the», вы, благодаря своему «нисходящему восприятию», его пропускаете, что связано со сбором предложений из слов без их полного прочтения.
А теперь вопрос: происходит ли нечто подобное при подготовке выходных данных MAGMA? Ответ на этот вопрос — да.
MAGMA — это, определённо, не наилучшая из существующих модель для оптического распознавания текста. Но она, похоже, имеет некий интуитивный фильтр, накладываемый на результаты решения простой задачи чтения того, что написано на изображении. Когда мы убираем с изображения одно из двух «the», результат остаётся тем же самым.

А изучив ещё одно изображение, мы видим, что MAGMA пытается «заполнить» частично стёртые слова и выдаёт осмысленный результат. Даже хотя модель и потеряла одно из слов, обрабатывая модифицированное изображение, результат её работы всё ещё достаточно близок к оригиналу.

Чем эти мультимодальные языковые модели лучше свёрточных нейронных сетей?
Для решения задач машинного зрения чаще всего используются свёрточные нейронные сети. Это — особая архитектура нейронных сетей. Такие сети обучают на специализированных наборах данных для решения весьма специфических задач наподобие классификации изображений.
На другом краю спектра архитектур нейронных сетей находятся большие языковые модели. Здесь было сказано, что они, в своей основе, представляют собой всего лишь по-настоящему большие нейронные сети с «простой единообразной архитектурой, обученные наитупейшим из возможных способов» (их учат предсказанию следующего слова).
Когда мы передаём свёрточной нейронной сети (например — ResNet50) изображение человека в костюме плюшевого медведя, она кодирует информацию и выдаёт прогноз, в соответствии с которым это — «teddy» (плюшевый медведь). Модель полностью игнорирует тот факт, что это может быть просто человек в костюме медведя. Нам не стоит винить подобные модели за эту их ограниченность, так как их обучали лишь тому, к каким категориям относятся изображения, предоставляя им ограниченный набор категорий (например, в данном случае — набор данных ImageNet).

Но когда мы подстроим ту же свёрточную нейронную сеть в расчёте на кодирование изображений, совместимое с «пространством эмбеддингов» языковой модели, мы можем, решая вышеописанную задачу, задействовать знания о мире, которые есть у языковой модели. Эти знания о мире внутри языковой модели примерно аналогичны той форме «нисходящего восприятия», которое обрабатывает исходную визуальную информацию, поступающую от кодировщика изображений.
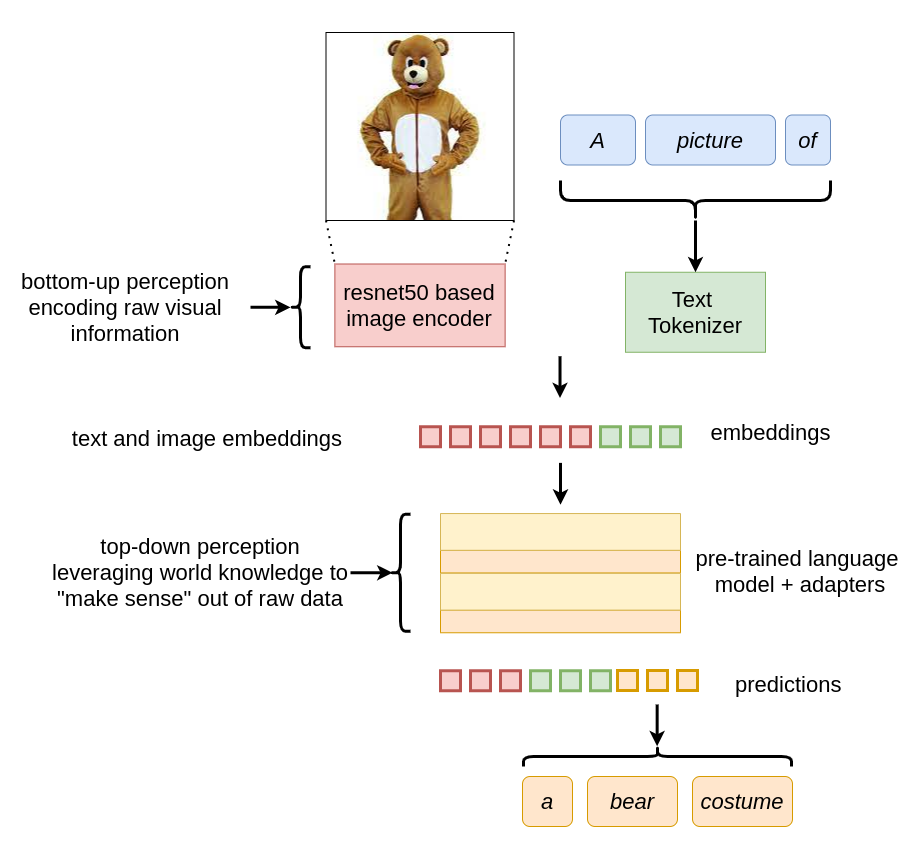
Рис. 6. Не особенно простая схема того, как MAGMA задействует кодировщик изображений для адаптации изображений к пространству своих входов
Чем мультимодальные языковые модели отличаются от простого расширения обучающих данных моделей машинного зрения путём включения в эти данные костюма плюшевого медведя?
В чём заключается проблема попытки простого расширения области выходных данных моделей путём включения в них категорий, наподобие «костюмы плюшевых медведей»? А проблема в том, что это непрактично, так как существует невероятно огромное количество таких категорий. Языковые же модели, с другой стороны, не требуют подобного, так как у них имеются внутренние знания о мире, закодированные в них (возможно — объективные, возможно — нет). В этом случае модель ResNet50 имеет очень ограниченное пространство выходных данных.
По своей сути, появление на выходе ResNet50 чего-то вроде «костюма медведя» ограничено лишь метками классов, на которых была обучена модель. А вот языковые модели могут генерировать выходные данные произвольной длины. Это означает, что они имеют гораздо большее пространство выходных данных, соответствующее масштабам языка, на котором они обучены.
Мультимодальные языковые модели — это попытка расширить входное пространство языковых моделей путём добавления «восходящей» обработки данных к уже существующим в них моделям мира. Мультимодальные языковые модели создают именно так, а не путём расширения выходного пространства моделей машинного зрения.
Итоги
Интересным направлением исследований в этой сфере была бы попытка добавить больше модальностей не только к входам моделей, но и к их выходным пространствам. Это, например, могли бы быть модели, которые способны генерировать и текст, и изображения в виде единого, цельного выходного сигнала.
Интеллект — это не всегда правильность. Иногда это — способность совершать правильные ошибки основываясь на чьём-либо понимании мира. Этот принцип, сам по себе, является важным базовым компонентом работы человеческого мозга.
Я уверен, что многие исследователи искусственного интеллекта были бы несказанно счастливы в тот день, когда ИИ начнёт видеть некие образы в облаках — так же, как видим их мы. Это ещё на шаг приблизит нас к цели в нашем стремлении к созданию машин, размышляющих о разном так же, как люди, и задающих вопросы, которых мы не могли задавать.
О, а приходите к нам работать? ???? ????
Мы в wunderfund.io занимаемся высокочастотной алготорговлей с 2014 года. Высокочастотная торговля — это непрерывное соревнование лучших программистов и математиков всего мира. Присоединившись к нам, вы станете частью этой увлекательной схватки.
Мы предлагаем интересные и сложные задачи по анализу данных и low latency разработке для увлеченных исследователей и программистов. Гибкий график и никакой бюрократии, решения быстро принимаются и воплощаются в жизнь.
Сейчас мы ищем плюсовиков, питонистов, дата-инженеров и мл-рисерчеров.
phenik
Спасибо за перевод. Интересная тематика с учетом дискуссий о достоверности выводов различных больших ЯМ на базе трансформеров. Мультимодальные модели позволят повысить эту достоверность, хотя и рамках чисто языкового подхода не все возможности исчерпаны. Язык в некотором виде содержит модель мира, включая физического, и это позволяет корректировать выводы с помощью Системы 2, см., напр, эту публикацию.
Однако поскольку автор статьи упомянул нейрофизиологические исследования в рамках байесовского подхода к изучению функций мозга несколько критических замечаний. К сожалению методологического характера. По видимому автор переселился в свой внутренний мир — internal models на всех уровнях, и полагается, в основном, на нисходящие top-down влияния)
Чтобы произвести окончательное заключение — Active inference, и тем самым минимизировать свободную энергию дачник должен выйти из дачи и удостоверится, что это не снежный человек, не медведь, и тд, а веселый турист, как он ожидает) И только в том случае, если это не так, а им оказался отставший от корабля возбужденный инопланетянин, скорректировать свои представления — внутреннюю модель, и минимизировать св. энергию таким путем.
Если по простому, то в конце концов, критерием истины является практика, в том числе, наблюдательная.
Это правильно быть на стороже… но причины появления внутренних моделей, пресдказательного режима функционирования и нисходящих контуров управления в том, что это повышает реактивность, минимизирует потребление энергии — дорогого ресурса, и уменьшает вредные последствия связанного с ней метаболизма. Все это начало появляться уже у первых микроорганизмах, до появления многоклеточных и нервных систем, и у человека вылилось в предсказательный разум. По сути это физические ограничения с которыми приходилось считаться не только эволюции, но сейчас разработчикам процессоров, уменьшая ими потребление энергии, решая проблемы теплоотвода и уменьшения вредных последствий ее выделения.
Сравним упомянутые архитектуры ИНС с теми, что в мозге. Сверточные сети являются неплохим приближением структуры вентрального тракта зрительной системы приматов, архитектурой трансформеров являются прямые сети. Не та, не другая архитектура в полной мере не соответствуют структуре биологических сетей, которые являются принципиально рекуррентными. Нисходящие контуры управления в мозге как раз реализуются обратными связями. До биологической правдоподобности эти архитектурам еще далеко. Вероятно это удастся в перспективе достичь только с помощью нейроморфных технологий, над которыми работают многие производители железа. Они энергоэффективны благодаря импульсному режиму работы, асинхронны, непрерывно обучаемы на основе хеббовских принципов, и тд.
Как у человека представления о мире, так и знания о мире в языковых моделях являются ограниченными. В конечном итоге их стабилизирует именно сенсорный ввод, а также образный уровень мышления. Причем в случае ИИ не ввод изображений, видео, и тп, а ввод именно с датчиков, которые непосредственно контактируют с внешней средой. Эта архитектура описывается понятием когнитивной архитектуры (обзор), и до ее приближенной реализации также еще далеко. То что сейчас делается, включая чаты на основе GPT, является технологией интеллектуальных ассистентов, пусть продвинутыми в сравнении существующими — Сири, Алиса, и тд., но пока даже не интеллектуальными агентами.
Как то автор статьи поленился посмотреть по теме. Уже существующие ИНС испытывают иллюзии, которые испытывают люди, см. 1, 2 , 3, 4 .
SADKO
Вот, прямо ку!
А то, такие опусы, что глобус трещит, сова пищит ;-)
И если уж хочется разобраться, то делать это лучше последовательно, честно и с самого начала, иначе таксидермизм получается.