

Рано или поздно большой продукт сталкивается с проблемой количества тестов, а точнее с тем, сколько времени нужно, чтобы их прогнать. При этом не все команды готовы тратить кучу сил на оптимизацию этого процесса. Гораздо проще решить проблему с помощью большого количества эмуляторов или ресурсов на CI.
В этой простыне текста хочу рассказать про то, как мы уменьшили время прогона UI-тестов на мерж-реквесте с 4 часов до 30 минут, какие есть подходы к решению проблемы и как сделать свой Test Impact Analysis.
Проблема большого количества тестов
Представьте, что вы мелкий стартап, который начал разрабатывать свое приложение. Скорее всего, на первых этапах не нужно сильно задумываться о тестах, потому что даже ручной регресс не занимает больше дня.
Со временем приложение подрастет, увеличится количество разработчиков в команде и регресс будет занимать ощутимое время. Чтобы релизный цикл не увеличивался по времени, вы внедряете автоматизированное тестирование. Начинаете покрывать фичи unit- и UI-тестами, чтобы регресс был автоматизирован, насколько это возможно.
Рано или поздно вы оказываетесь в точке, где огромное количество unit- и UI-тестов. C unit-тестами нет особых проблем: они работают быстро, и даже если разработчик не запускал их локально, то их запустит CI на мерж-реквесте (МР). А с UI-тестами непросто: их становится так много, что уже нельзя просто взять и запустить их на каждом МР.
В такой ситуации мы и оказались. На нашем проекте около 5000 UI-и 6500 unit-тестов. Прогон всех UI-тестов давно перевалил за 6 часов. Единственное решение, которое можно внедрить быстро, — запускать тесты не на каждом МР, а на ночных прогонах.

Мы решили проблему со временем прохождения МР, но появилась новая. Обратную связь разработчик может получить только через сутки после того, как смержил изменения. В такой системе тесты часто ломаются, и не всегда команды находят время их починить, ведь у всех горящие фичи, которые нужно быстро выкатить.
Варианты решения проблемы
Параллелизация тестов на уровне CI — одна из первых идей, которые приходят на ум. У нас больше половины тестов располагаются в фиче-модулях, значит, можно объединять некоторые модули в одну Job и запускать только ее.

В теории все хорошо, а на практике появляются две проблемы:
Не всегда Job будут выполняться параллельно. CI даже без тестов загружен и вероятно, что Job будут выстраиваться в очередь. Из-за этого время прогона может затянутся и до 2—3 часов. При часто создаваемых МР можно выйти за все разумные рамки.

В инфраструктуре есть ограничение по количеству эмуляторов. При малом количестве эмуляторов мы будем выполнять тесты невообразимо долго, а если захватим большое количество эмуляторов, то возникнут задержки, связанные еще и с ними
В итоге получаем:
➕ Никаких изменений в коде, достаточно немного подкрутить пайплайны.
➖ Большая нагрузка на CI и пул эмуляторов.
Вывод: параллелизацию на CI можно использовать, но как часть более сложного решения.
Анализ измененных файлов — идея, которая возникает в ответ на вопрос «Нужно ли запускать все тесты на МР?». Ограничения со стороны инфраструктуры не дадут это сделать, следовательно, нужен более точный подход.
Самая простая реализация подобной системы выглядит так: на МР из Git получаем названия измененных файлов, затем из Gradle получаем модули, в которых были измененные файлы. После запускаем тесты только на этих модулях.
tasks.register("computeImpactedTest") {
val gitDiff = cmd("git show --name-only origin/main..HEAD")
val testTasks = gitDiff
.filter { filePath -> isModule(filePath) }
.map { filePath -> moduleNameByPath(filePath) }
.distinct()
.map { module -> getTestTask(module) }
.toTypedArray()
dependsOn(*testTasks)
}Реализация простая, но с дефектом. Допустим, есть модуль A, который использует модуль B. В модуле B мы что-то поменяли и запустили на нем тесты. Изменения могли задеть и модуль A, в котором тоже нужно запустить тесты.
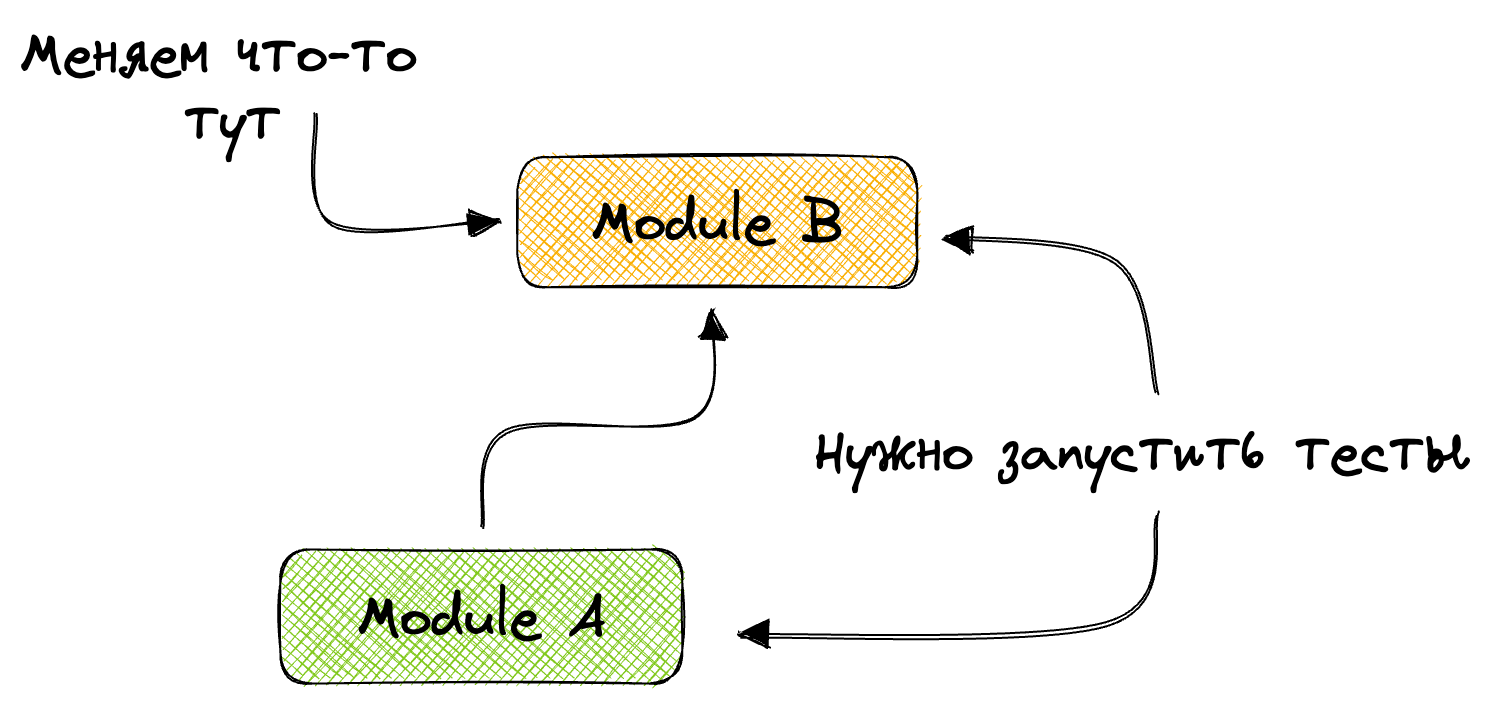
Такая проблема легко решается. Gradle знает весь граф, и после получения модулей, в которых мы что-то поменяли, мы можем получить и зависимые модули. После чего запускаем тесты и в них. Чувствуете подвох? Если зависимый модуль — это главный модуль, в котором огромное количество тестов, да еще и жутко медленных, то мы не сильно-то и решили задачу.
val testTasks = gitDiff
.filter { filePath -> isModule(filePath) }
.map { filePath -> moduleNameByPath(filePath) }
.map { moduleName -> getTestTask(moduleName) + getDependenciesTestTask(moduleName) }
.distinct()
.toTypedArray()Плюсы и минусы подхода:
➕ Простота реализации. Никаких доработок со стороны инфраструктуры, а саму программу можно написать за пару дней неторопливого кодинга.
➖ Запускаем кучу лишних тестов. По имени файла трудно установить, какой именно тест необходимо запустить, поэтому приходится запускать все тесты модуля.
Выводы: такой подход можно использовать, и он реализован у Avito. Если в вашем проекте тесты распределены равномерно по кодовой базе, нет запутанности в графе зависимостей и устраивает запуск лишних тестов, решение вполне вас устроит. Наш проект таким похвастаться не мог, и требовалось более продвинутое решение.
Разметка в коде, которая позволяет соотнести код тестов с кодом проекта, — третье возможное решение. Можно повесить специальную аннотацию на PageObject, которая указывала бы, к какому экрану этот PageObject относится. Ну а дальше при изменении в этих классах запускались бы соответствующие тесты, в которых используется привязанный PageObject.
@UiDsl
@LinkedWith([AccountsFragment::class, AccountsRepository::class])
class AccountsPage {
companion object {
const val TAG = "Экран со списком счетов"
inline operator fun invoke(
block: AccountsPage.() -> Unit
) = AccountsPage().block()
}
//...
}Еще можно сделать файл конфигурации. Как именно это будет реализовано, не так важно — важна суть. Такое решение не самое сложное, но мы должны полностью доверять разработчикам.

Кроме того, со временем в аннотации или файле накопится огромное количество классов. Это нужно поддерживать: классы будут удалятся, переименовываться, перемещаться в другой пакет и так далее. Такая система подвержена ошибкам и человеческому фактору.
Плюсы и минусы подхода:
➕ Простота реализации.
➖ Человеческий фактор.
Выводы: такой поход можно использовать, если нужно запускать тесты только при изменении UI, во всех остальных случаях метод уступает предыдущим.

Сейчас эпоха развития ML-систем, и почему бы не пофантазировать над тем, чтобы применить нейронную сеть в этой задаче? Так делают гиганты индустрии вроде Google и Facebook. Но этот вариант отпадает по двум причинам: нужны люди для поддержки такой системы и неизвестно, где взять размеченные данные для обучения.
Нужно решение, которое реально реализовать в разумное время. Подход который бы запускал именно те тесты, которые задеты изменениями кода, независимо от того, в каком модуле они находится. Решение, которое работает автоматически и исключает ошибку разработчика. Такое решение существует и называется Test Impact Analysis (TIA).
Описание концепта
Идея TIA не новая, как и многое в индустрии, все было придумано до нас. Про импакт-анализ писал Мартин Фаулер в своей статье.
Суть концепции в том, что в большинстве языков программирования уже реализована такая идея, как Code Сoverage. Запускаем тесты, те, в свою очередь, запускают наш код. После формируется файл, в котором есть информация о том, какие методы и ветки кода были пройдены, а какие нет. Эту информацию может использовать IDE и прямо в редакторе подсвечивать, какой код покрыт тестами, а какой нет.
Возникает довольно простая идея: почему бы не использовать этот Code Coverage в обратную сторону? Создаем Code Coverage, прогоняя все тесты на ночном прогоне, и сохраняем его где-то. Потом берем номера строк из Git и на основе Code Coverage получаем номера или имена тестов, которые вызывают эти строки. Вот и вся концепция, уместилась в один абзац.

Плюсы и минусы подхода:
➕ Запускаем только нужные тесты. Причем запустим их не только в измененном модуле, а во всех зависимых модулях. Становится не важно, как распределены тесты по модулям, — мы не запустим ничего лишнего.
➖ Сложная реализация с изменением инфраструктуры. Дело не обойдется одним скриптом. Это комплексная задача, начиная от специальных раннеров для тестов и заканчивая архитектурой нашего CI. Code Coverage для большого проекта будет весить довольно много, поэтому в компании должны быть инструменты, которые позволяли бы быстро сохранять и скачивать большие файлы.
Рассмотрим одну из реализаций этой идеи, которую мы сделали в своем проекте.
Реализация идеи в проекте
Первая задача, которую нужно решить, — это получение Code Coverage. Для Android-разработки выбора инструментов особо нет и очевидно использовать JaCoCo. Он уже встроен в Gradle, протестирован временем, и у него есть API, которое позволяет нам самим управлять сбором Coverage.
JaCoCo умеет работать в нескольких режимах. Первый режим работы — через Java Agent, или online mode. Второй режим — через модификацию байт-кода при компиляции, или offline mode.

В Android используется подход с модификацией байт-кода во время компиляции. Вероятнее всего, по причине того, что JVM в Android отличается от остальных и там не так просто запустить Java Agent.
Просто взять и использовать JaCoCo, к сожалению, не получится. По умолчанию он собирает один Coverage для всех тестов. Получив один файл, мы не сможем понять, какой именно тест вызывает ту или иную строку. Придется немного подправить это поведение. Для решения сходим и посмотрим, как вообще вызываются методы JaCoCo в UI-тестах.
Тестовый фреймворк предоставляет нам InstrumentationRunListener, позволяющий отслеживать момент старта и окончания какого-либо теста. Помимо этого, у него есть метод, который вызывается, когда выполнение всех тестов закончено. Его и использует JaCoCo.

Так как JaCoCo уже интегрирован в тестовый фреймворк, один из стандартных листенеров — это CoverageListener, который и отвечает за сбор Coverage. Все, что осталось сделать, — это залезть в него и посмотреть, как он это делает. Суть метода приведена тут:
class CoverageListener : InstrumentationRunListener() {
private val EMMA_RUNTIME_CLASS = "com.vladium.emma.rt.RT"
override fun instrumentationRunFinished(
streamResult: PrintStream?,
resultBundle: Bundle?,
junitResults: Result?
) {
val coverageFile = File("coverageFilePath")
try {
val classLoader = instrumentation.targetContext.classLoader
val emmaRTClass = Class.forName(
EMMA_RUNTIME_CLASS,
true,
classLoader
)
val dumpCoverageMethod = emmaRTClass.getMethod(
"dumpCoverageData",
coverageFile.javaClass,
Boolean::class.javaPrimitiveType,
Boolean::class.javaPrimitiveType
)
dumpCoverageMethod.invoke(null, coverageFile, false, false)
} catch (ex: Exception) {
reportEmmaError("Is Emma/JaCoCo jar on classpath?", ex)
}
}
}Для вызовов API JaCoCo используется рефлексия. Причина, по которой она используется, мне до конца не ясна. В сорцах фреймворка есть такой комментарий:
Uses reflection to call emma dump coverage method, to avoid always statically compiling against the JaCoCo jar. The test infrastructure should make sure the JaCoCo library is available when collecting the coverage data.
Скорее всего, если мы как-то завяжемся на jar самого JaCoCo, он преобразует сам себя во время компиляции и не будет работать. В любом случае нам этого более чем достаточно, чтобы сделать свой Listener с блэкджеком и — ну вы поняли.
open class CollectCoverageRunListener : InstrumentationRunListener() {
private val baseDir = File("/sdcard/tia")
override fun testFinished(description: Description) = with(description) {
val allureId = getAnnotation(AllureId::class.java)?.value.orEmpty()
val fileName = "${className}${methodName}#${allureId}.exec"
val resultCoverageFile = baseDir.resolve(fileName)
val emmaRTClass = Class.forName(EMMA_RUNTIME_CLASS, true, classLoader)
val dumpCoverageMethod = emmaRTClass.getMethod(
"dumpCoverageData",
resultCoverageFile.javaClass,
Boolean::class.javaPrimitiveType,
Boolean::class.javaPrimitiveType
)
dumpCoverageMethod.invoke(null, resultCoverageFile, false, false)
super.testFinished(description)
}
}Обратите внимание, что в имя файла мы подсовываем allure id теста. Это нужно, чтобы понимать, к какому тесту относится тот или иной Coverage. Вместо allure id можно использовать название метода или любой другой идентификатор, какой нравится. Останется подсунуть наш Listener в runner. Делается это весьма удобно, как и во всех либах от Гугла:
class TestImpactAnalysisCollectorAllureRunner : AllureAndroidJUnitRunner() {
override fun onCreate(arguments: Bundle) {
val listenerArg = listOfNotNull(
arguments.getCharSequence("listener"),
CollectCoverageRunListener::class.java.name
).joinToString(separator = ",")
arguments.putCharSequence("listener", listenerArg)
super.onCreate(arguments)
}
}Все, что остается, — вытащить нужные файлы при помощи Adb. Получив файлы Coverage в формате exec, мы можем достать информацию о том, какие именно строки кода вызывает тот или иной тест. Вся эта информация хранится в формате JaCoCo, неудобном для обработки. Нам нужно вытащить необходимую информацию и перегнать в тот формат, в котором было бы удобно работать далее.
Чтобы вытащить данные, можно использовать API самого JaCoCo. Тут его уже можно подключать без плясок с рефлексией, ведь Coverage мы собрали.
fun loadCoverage(execFile: File, sourcesDir: File): List<ImpactedFile> {
val loader = ExecFileLoader().also { it.load(execFile) }
val result = mutableListOf<ImpactedFile>()
Analyzer(loader.executionDataStore) { classCoverage ->
val coveredLines = classCoverage.coveredLines
// handleCoveredLines(coveredLines)
}.analyzeAll(sourcesDir)
return result
}Нам нужно отправить в API не только файл exec, но и папку скомпилированных сорцов. Из Gradle мы получаем нужную директорию. Информацию о том, что это за тест, мы получаем из названия файла самого Coverage. Все выглядит довольно просто, но есть проблема.
Допустим, мы делаем этот функционал в виде Gradle-плагина, который подключаем в какой-то модуль. Мы можем получить сорцы этого модуля, а значит, и информацию из exec, которая будет распространятся только на этот модуль. Но нам нужна информация о Coverage и из всех зависимых сорцов. Иначе мы не сможем вычислять, какие тесты нужно запустить, при изменении файлов в зависимых модулях, вроде common, или каких-нибудь domain-модулях с логикой.

Нужно достать сорцы не только того модуля, в который мы подключаем наш плагин, но и всех зависимых модулей. И все это отправлять в API для получения данных из exec-файла.
fun computeImpactedFiles(
execFile: File,
sourcesDir: File,
dependenciesSourcesDirs:List<File>
): List<ImpactedFile> {
return (dependenciesSourcesDirs + sourcesDir)
.flatMap { sourcesDir -> loadCoverage(execFile, sourcesDir) }
}Когда вытащим нужные данные, можно преобразовать их в любой удобный формат, например Json. С ним проще всего работать и легко отладить. Этот Json отправляем в файл. В итоге получим по файлу на каждый модуль проекта, в котором есть тесты. Информация о зависимых модулях тоже будет в этом файле.
Далее мы мержим все файлы в один большой Json, убирая дубликаты. Мержим для того, чтобы не париться с построением графа зависимостей и расчетом, какой именно Json-файл нам нужен.
Дальше нужно решить проблему, где хранить полученную информацию о Coverage. Мы используем для этого свой s3. Но тут выбор исходит из ограничений, которые есть в компании.
Переходим к самому интересному. У нас на сервере лежит свежий Coverage, и нужно применить его на МР.
Вычисление изменений и запуск тестов
Итак, у нас есть Json-файл, в котором по классу и строке можно найти тест или список тестов, которые выполняют эту строчку кода. Значит, первое, что нам нужно, — получить измененные строки.
Сделать это проще всего через интеграцию с Git. Возможны два варианта: использовать библиотеку JGit или реализовать самому через вызов CLI. JGit считается официальным решением, но документация оставляет желать лучшего, а в обычном CLI придется возится с Regex, тут каждый выбирает сам.
Независимо от того, используете вы JGit или кастомную реализацию, может возникнуть проблема. Когда пытаемся получить diff, Git по умолчанию показывает много контекста для каждой измененной строки. Вот пример:
--- a/android/samples/android-lib/src/main/java/ru/tinkoff/moba/sample/library/FeatureInteractor.kt
+++ b/android/samples/android-lib/src/main/java/ru/tinkoff/moba/sample/library/FeatureInteractor.kt
@@ -5,7 +5,7 @@ import ru.tinkoff.moba.sample.kotlin.KotlinInteractor
class FeatureInteractor {
fun compute(): Int {
- return 4
+ return 2 + 2
}
fun libCompute(): Int {Внесли изменение в одну строку, а diff выдал кучу других. В этом кейсе сложно вычислить номер измененной строки. В примере выше изменили строку 8, и не совсем очевидно, как из приведенных цифр получить 8. Можно просто правильно выстроить математику на основе цифр в заголовке, а можно упростить задачу.
У Git есть настройка --unified={number}, которая указывает, какое количество строчек, помимо измененных, нужно показывать. Тем самым мы показываем в diff только те строки, которые были изменены, т. е. без какого-либо контекста. Вот тот же пример, но с --unified=0:
--- a/android/samples/android-lib/src/main/java/ru/tinkoff/moba/sample/library/FeatureInteractor.kt
+++ b/android/samples/android-lib/src/main/java/ru/tinkoff/moba/sample/library/FeatureInteractor.kt
@@ -8 +8 @@ class FeatureInteractor {
- return 4
+ return 2 + 2Такой diff анализировать гораздо проще, и мы сразу получаем номер измененной строки.
Когда получили номера изменений строк и классов, скачиваем Coverage. Ищем в нем совпадения сначала по классу(имени файла), затем по строкам. Если находим совпадения, вытаскиваем указанные тесты и складываем их в какой-нибудь отдельный файл. Все, что остается после, — это запустить указанные в этом файле тесты. Если же файл пустой, значит, внесенные изменения никак не задевают тесты, соответственно, запускать их нет смысла.
Заключение
Вот так мы решили боль и сократили прогоны UI-тестов с 6 часов до 30 минут в среднем. Медианное значение количества запускаемых тестов — около 100. Это в 50 раз меньше, чем полный запуск.
У такой системы огромное количество потенциальных улучшений. Можно оптимизировать систему с получением данных о Coverage с помощью бинарного формата вместо Json. А можно добавить exclude по классам, чтобы не учитывать какую-нибудь аналитику в Сoverage, можно конфигурировать глубину анализа по зависимостям и еще куча всего.
Проблем у такого решения две:
1️⃣ Если провести изменения в базовом компоненте, запустятся все тесты. С одной стороны, это хорошо, ведь изменения в core-модулях и должны приводить к регрессу, с другой — мы возвращаемся в начало этой статьи. Решение данной проблемы тянет на отдельную статью, поэтому у этой, возможно, появится вторая часть.

2️⃣ Coverage обновляется раз в сутки. Это значит, что если разработчик успеет написать новый функционал, покрыть его тестами, а после поменять, то импакт-анализ не запустит новые тесты, ведь нового кода вообще нет в Coverage. Разумеется, разработчики редко так быстро пишут тесты, но проблему можно решить путем хитрого обновления Coverage, например при мерже в мастер.

Концепт позволяет улучшать его в ту сторону, которая нужна конкретному проекту. В итоге получаем систему, где разработчики точно не забудут запустить нужные тесты и будут вынуждены их сразу починить.
Функционал работает точнее, чем разработчики, которые уверены, какие тесты нужно запустить после изменений.
Если вам понравилась статья и иллюстрации к ней, подписывайтесь на мой телеграм-канал. Я пишу про Android-разработку и Computer Science, на канале есть больше интересных постов про разработку под Android. А еще залетайте на наш ютуб с подборкой про Android - собираем самое интересное с митапов и конференций.
Комментарии (2)

ivanemelin
00.00.0000 00:00Сколько запустится тестов, если разработчик изменил код в xml, которая используется потом в нескольких модулях? Не получится ли в этом случае ноль тестов из-за того, что jacoco смотрит на java код?
gigimon
Каждый раз, открывая статью подобного вида, надеюсь увидеть что-то новое, но нет, все они заканчиваются двумя вариантами: мы стали запускать тесты параллельно; мы стали запускать тесты выборочно