
Я стал большим сторонником DynamoDB за последние несколько лет. Эта база данных имеет много сильных сторон, которых нет у конкурентов, таких как гибкая ценовая модель, соединение без состояния (stateless), которое прекрасно работает для беcсерверных (serverless) вычислений, и постоянное время ответа, даже когда ваша база данных масштабируется до огромных размеров.
Однако разработка структуры данных с помощью DynamoDB вызывает трудности у тех, кто привык к реляционным базам данных, которые доминировали в течение последних нескольких десятилетий. Существует несколько особенностей в создании структуры данных с помощью DynamoDB, но самая значимая - это рекомендация от AWS использовать одну таблицу для всех ваших записей.
В этой статье мы погрузимся в концепции, лежащие в основе одно-табличного дизайна (Single-Table Design).
Вы узнаете:
Что такое одно-табличный дизайн;
Зачем он нужен;
Его недостатки;
Два случая, когда недостатки одно-табличного дизайна превышают преимущества;
Недавно я провел дебаты на эту тему на Twitch с Риком Хулиханом (Rick Houlihan) и Эдином Зуличем (Edin Zulich). Вы можете посмотреть запись здесь. Рик является более убежденным сторонником модели Single-Table Design, поэтому обязательно посмотрите на аргументы, что он приводит.
Давайте начнем!
Что такое одно-табличный дизайн
Прежде чем мы начнем, давайте определим, что такое одно-табличный дизайн. Для этого мы совершим быстрое путешествие по истории баз данных. Мы рассмотрим создание структуры данных в реляционных базах, а затем увидим, почему в DynamoDB нужно действовать иначе. Таким образом, мы поймем главную причину использования одно-табличного дизайна.
В конце этого раздела мы также быстро рассмотрим некоторые другие, менее значимые преимущества одно-табличного дизайна.
SQL и объединение таблиц (JOIN'ы)
Давайте начнем с нашего старого друга - реляционной базы данных.
В реляционных базах данных, обычно вы нормализуете свои данные, создавая таблицу для каждого типа сущности в вашем приложении. Например, если вы создаете приложение электронной коммерции, у вас будет одна таблица для клиентов и одна таблица для заказов.
 и заказов (orders)")
Каждый заказ принадлежит определенному клиенту, и вы используете внешние ключи (FK, foreign keys). Эти внешние ключи действуют как указатели - если мне нужна дополнительная информация о клиенте, который сделал определенный заказ, я могу следовать ссылке внешнего ключа, чтобы получить информацию о клиенте.

Для того, чтобы использовать эти указатели, язык SQL может объединять таблицы с помощью join. Join позволяют объединить записи из двух или более таблиц в момент чтения данных.
Проблема отсутствия join в DynamoDB.
Хотя join в SQL удобны, они дорого стоят. Они требуют сканирования больших частей нескольких таблиц в вашей реляционной базе данных, сравнения разных значений и возврата результата.
DynamoDB была создана для огромных нагрузок, таких как корзина покупок amazon.com. В этих случаях недопустимы несогласованность и снижение производительности при работе с большими объемами данных.
DynamoDB избегает любых операций, которые не могут масштабироваться, и нет универсального способа эффективно масштабировать join в реляционных базах данных. Вместо того, чтобы пытаться ускорить работу join, DynamoDB обходит эту проблему, не давая возможность использовать join вообще.
Однако нам все еще нужно объединение таблиц. И мы хотим иметь возможность получения нескольких разных элементов из нашей базы в одном запросе.
В нашем примере выше мы хотим получить как запись о клиенте, так и все заказы этого клиента. Многие разработчики применяют реляционные паттерны проектирования с DynamoDB, даже если у них нет реляционных инструментов, таких как join. Они размещают свои элементы в разных таблицах в соответствии с их типом. Однако, поскольку в DynamoDB нет join, им придется сделать несколько последовательных запросов, чтобы получить как заказы, так и клиента.

Решение: предварительно объединяйте свои данные в коллекции
Так как же обеспечить высокую и постоянную производительность при работе с DynamoDB без нескольких запросов к вашей базе данных? Предварительно объединяйте свои данные в коллекции.
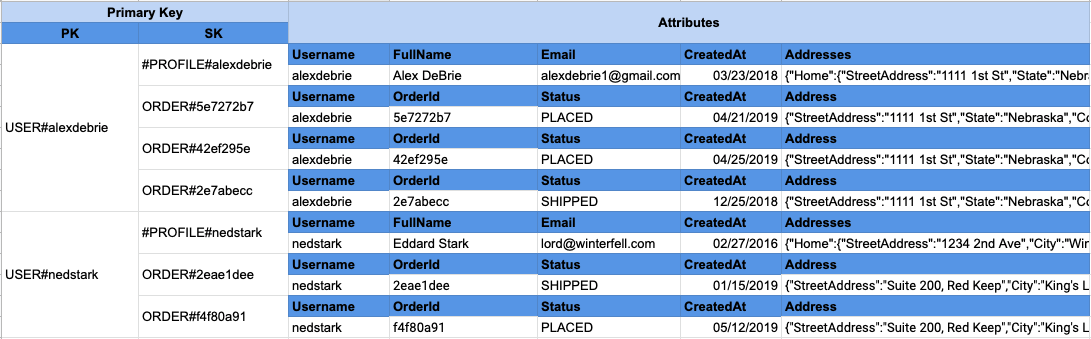
Коллекция элементов в DynamoDB относится ко всем элементам в таблице или индексе, которые имеют общий ключ раздела (partition key). На примере ниже у нас есть таблица DynamoDB, которая содержит актеров и фильмы, в которых они играли. Основной ключ является составным, где ключ раздела - имя актера, а ключ сортировки - название фильма.

Из приведенной выше таблицы можно видеть, что у Тома Хэнкса есть две записи - "Cast Away" и "Toy Story". Поскольку у них одинаковый ключ раздела - имя актера Tom Hanks, они находятся в одной коллекции элементов.
Вы можете сделать запрос в DynamoDB для чтения нескольких элементов с одинаковым ключом раздела. Таким образом, если вам нужно получить несколько различных элементов в одном запросе, вы организуете эти элементы таким образом, чтобы они находились в одной коллекции.
Давайте рассмотрим пример из моего выступления на конференции AWS re:Invent 2019 про разработку структуры данных в DynamoDB. В этом примере мы рассмотрим интернет-магазин, похожий на тот, о котором мы говорили ранее, и который имеет записи о пользователях и заказах. У нас есть запрос, при выполнении которого мы хотим получить запись о пользователе и список его заказов. Чтобы это было возможно сделать в одном запросе, мы убедимся, что все записи о заказах находятся в той же коллекции элементов, что и запись о пользователе, к которому они принадлежат.
Теперь, когда мы хотим получить данные о пользователе и его заказах, мы можем сделать это в одном запросе, не используя дорогостоящий join:

Single-table design - это изменение вашей таблицы так, чтобы необходимые вам данные можно было получить наименьшим количеством запросов, в идеале одним.
И поскольку в виде цитаты это выглядит лучше:
Основная причина использования единой таблицы в DynamoDB заключается в том, чтобы получать различные сущности с помощью одного запроса.
Другие преимущества Single-Table Design
Хотя сокращение количества запросов является главной причиной использования Single-Table Design, есть и другие преимущества. Кратко обсудим их.
Во-первых, есть некоторые операционные расходы для каждой таблицы в DynamoDB. Несмотря на то, что DynamoDB является полностью управляемой (managed service) и достаточно надежной по сравнению с реляционной базой данных, вам все же нужно настраивать оповещения, мониторить метрики и т.д. Если у вас есть одна таблица со всеми элементами в ней вместо восьми отдельных таблиц, то упрощается мониторинг.
Второе преимущество единственной таблицы заключается в экономии денег. Для каждой таблицы вам нужно выделить единицы чтения и записи (RCU и WCU). Обычно вы делаете некоторые расчеты, основанные на ожидаемом трафике, увеличиваете его на какой-то коэффициент и преобразуете в RCU и WCU. Расчет получается с запасом, и если таблица одна, то этот запас является общим для всех сущностей в ней.
Хотя эти два преимущества реальны, они довольно незначительны. Нагрузка на операции в DynamoDB довольно низкая, а ценообразование поможет вам сэкономить немного денег. Кроме того, если вы используете динамическое ценообразование DynamoDB On-Demand, вы не сэкономите никаких денег, переходя к единой таблице.
В целом, рассматривая единую таблицу, следует считать основным преимуществом улучшение производительности за счет одного единственного запроса для получения всех необходимых элементов.
Недостатки одно-табличного дизайна
Хотя схема с одной таблицей является мощной и невероятно масштабируемой, она не бесплатная. В этом разделе мы рассмотрим некоторые из недостатков этого подхода.
На мой взгляд, у концепции единой таблицы есть три недостатка:
Крутая кривая обучения;
Неспособность быстро добавлять новые шаблоны доступа;
Трудность экспорта таблиц для аналитики.
Давайте рассмотрим каждый из них по очереди.
Крутая кривая обучения
Первая проблема, на которую чаще всего жалуется сообщество, связана с трудностью изучения одно-табличного дизайна.
Одна перегруженная таблица DynamoDB выглядит действительно странно по сравнению с чистыми, нормализованными таблицами вашей реляционной базы данных. Трудно переучиться всему тому, что вы усвоили за годы моделирования реляционных данных.
Для тех, кто избегает одно-табличного дизайна из-за сложности, мой ответ такой:
Да, это сложно, но надо учиться.
Разработка программного обеспечения - это непрерывный путь обучения, и вы не можете использовать сложность изучения в качестве оправдания неверного использования.
Позже в этом посте я опишу несколько случаев, когда я считаю, что можно не использовать одно-табличный дизайн. Однако вы должны абсолютно точно понимать его принципы, прежде чем принимать это решение. Незнание не является причиной избегать общих рекомендаций.
Сложность добавления новых шаблонов доступа
Вторая проблема заключается в том, что сложно поддерживать новые шаблоны доступа. Эта жалоба вполне обоснована.
При проектировании единой таблицы в DynamoDB необходимо начать с шаблонов доступа. Необходимо тщательно продумать (и записать!) как вы будете получать доступ к своим данным, а затем тщательно спроектировать таблицу, чтобы удовлетворить эти шалоны. При этом вы организуете свои элементы в коллекции таким образом, чтобы каждый шаблон доступа могла быть обработана с помощью наименьшего количества запросов - в идеале одного.
Если вы правильно спроектировали таблицу и реализовали ее, то она будет работать отлично! Ваше приложение сможет масштабироваться бесконечно без снижения производительности.
Однако спроектированное вами решение узко направлено на конкретную цель, для которой оно был разработано. Если ваши шаблоны доступа меняются из-за добавления новых объектов или доступа к нескольким объектам разными способами, вам может потребоваться сканировать каждый элемент в вашей таблице и обновить его с новыми атрибутами. Этот процесс не невозможен, но он добавляет трение к вашему процессу разработки.
Сложность аналитики
DynamoDB разработана для OLTP-сценариев - быстрый доступ к данным, работая с несколькими записями за раз. Однако пользователи также нуждаются в шаблонах доступа OLAP - в больших аналитических запросах по всему набору данных для поиска популярных элементов, количества заказов по дням и т. п.
DynamoDB не подходит для запросов OLAP. Это так и задумано. Она сосредотачивается на обеспечении высокой производительности при запросах OLTP и хочет, чтобы вы использовали другие, специально разработанные базы для OLAP. Для этого вам нужно загрузить свои данные из DynamoDB в другую систему для аналитики.
Если у вас есть единая таблица, то передача ее в правильный формат для аналитической системы может быть затруднительной. Вы денормализовали свои данные и согнули их в загогулину, разработанную для обработки ваших конкретных запросов. Теперь вам нужно "разогнуть" эту таблицу и нормализовать ее таким образом, чтобы она была пригодна для аналитики.
Моя любимая цитата про эту ситуацию приходит от замечательного обзора одно-табличного дизайна от Форреста Бразилла (Forrest Brazeal):
Хорошо оптимизированная таблица а DynamoDB выглядит больше как машинный код, чем простая электронная таблица.
Электронные таблицы легко обрабатываются аналитическими системами, в то время как одно-табличный дизайн требует некоторой работы для преобразования. Вы должны предусмотреть все в процессе разработки заранее, чтобы иметь возможность преобразовать вашу таблицу в формат, пригодный для аналитики.
Когда не следует использовать одно-табличный дизайн.
Итак, мы знаем преимущества и недостатки одно-табличного дизайна в DynamoDB. Теперь пришло время перейти к еще более спорной части - когда не следует использовать его?
В основном случае ответ звучит так: "когда плюсы не перевешивают минусы". Но такой общий ответ нам мало поможет. Более конкретный ответ будет такой: "когда мне нужна гибкость запросов и/или простая аналитика больше, чем высокая производительность." И я думаю, есть две ситуации, когда это наиболее вероятно:
в новых приложениях, где гибкость важнее, чем производительность приложения;
в приложениях, использующих GraphQL.
Мы рассмотрим каждый из них ниже. Однако я хочу подчеркнуть, что это исключения, а не правило. При моделировании в DynamoDB вы должны следовать лучшим практикам, включая денормализацию, дизайн с одной таблицей и другие принципы. И даже если вы выбираете много-табличный дизайн, вы должны понимать дизайн с одной таблицей, чтобы знать, почему он не подходит для вашего конкретного приложения.
Приоритет гибкости в новых приложениях
За последние несколько лет многие стартапы и крупные компании выбирают для создания своих приложений бессерверные вычисления, такие как AWS Lambda. У них есть несколько преимуществ, от простоты развертывания и беспроблемного масштабирования до удобной модели оплаты.
Многие из этих приложений используют DynamoDB в качестве базы данных из-за того, что хорошо она вписывается в бессерверную архитектуру. DynamoDB идеально подходит для создания бессерверных приложений, в то время как традиционные реляционные базы данных могут вызывать проблемы.
Однако важно помнить, что хотя DynamoDB отлично работает с беcсерверной архитектурой, она не была создана именно для нее.
DynamoDB была создана для масштабируемых приложений с высокой производительностью, которым было бы недостаточно возможностей реляционных баз данных. А реляционные базы данных могут масштабироваться довольно далеко! Даже если вы создаете новое приложение в стартапе, то вам, скорее всего, не требуются возможности масштабирования DynamoDB сразу. Но, возможно, они потребуются по мере его эволюции.
В такой ситуации вы можете решить, что производительность решения с одной таблицей не стоит потери гибкости и более сложной аналитики. Вы можете выбрать подход Faux-SQL, при котором вы используете DynamoDB в реляционной манере, нормализуя свои данные по нескольким таблицам.
Это означает, что вам может потребоваться выполнять несколько последовательных вызовов к DynamoDB, чтобы чтобы получить требуемые данные. Ваше приложение может выглядеть следующим образом:
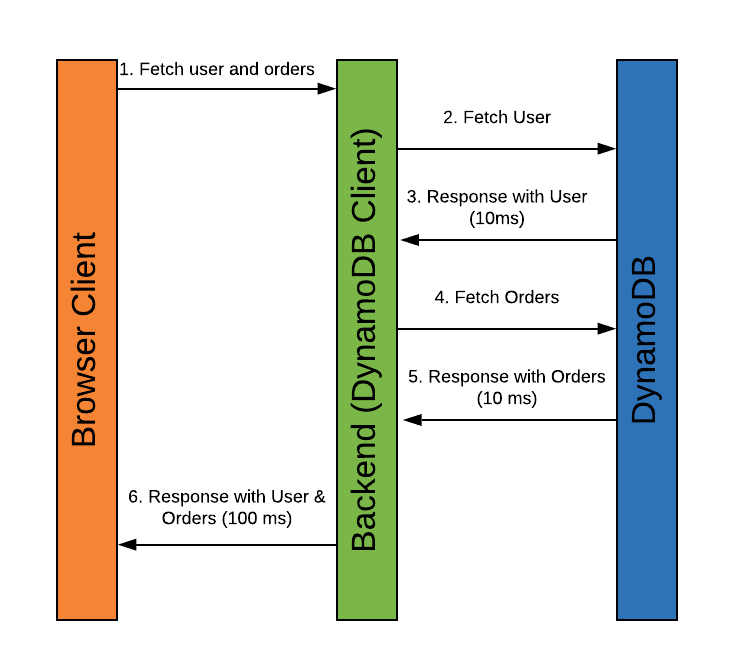
Обратите внимание, что здесь два отдельных запроса к DynamoDB. Сначала выполняется запрос для получения клиента, затем следует запрос для получения заказов для данного клиента. Поскольку необходимо выполнить несколько запросов, и эти запросы должны выполняться последовательно, время ответа для клиентов вашего приложения на стороне сервера будет больше.
В некоторых случаях это может быть приемлемо. Не все приложения должны иметь время ответа менее 30 мс. Если ваше приложение устраивает время ответа в 100 мс, то производительность будет хорошей ценой за большую гибкость и простую аналитику.
GraphQL и одно-табличный дизайн
Второе место, где вам может захотеться избежать проектирования с одной таблицей в DynamoDB - это GraphQL-приложения.
Прежде, чем меня будут донимать "а на самом деле...", я хочу уточнить, что да, я знаю, что GraphQL - это исполнительный механизм, а не язык запросов для конкретной базы данных. И да, я знаю, что GraphQL не привязан к конкретной базе.
Мой посыл не в том, что нельзя использовать единую таблицу с GraphQL. Я говорю, что из-за того, как работает GraphQL, вы теряете большую часть преимуществ одно-табличного дизайна, сохраняя при этом все недостатки.
Чтобы понять, почему, давайте посмотрим, как работает GraphQL и одну из основных проблем, которую он стремится решить.
В течение последних нескольких лет многие приложения выбирают REST-ориентированный API на сервере и одностраничное приложение (single page application, SPA) на клиентской стороне. Это может выглядеть следующим образом:

В REST-ориентированном API вы имеете различные ресурсы, которые обычно отображаются на сущность вашего приложения, такие как клиенты или заказы. Вы можете выполнять операции, похожие на CRUD, на этих ресурсах, используя различные HTTP-глаголы для указания операции, которую вы хотите выполнить.
Одна из распространенных причин разочарования фронтенд-разработчиков при использовании REST API заключается в том, что им может потребоваться делать несколько запросов к различным эндпоинтам, чтобы получить все данные для страницы:

В приведенном выше примере браузеру необходимо сделать два запроса: один, чтобы получить клиента, и один, чтобы получить последние заказы этого клиента.
С помощью GraphQL вы можете получить все данные, которые вам нужны для страницы, в одном запросе. Например, у вас может быть запрос GraphQL, который выглядит следующим образом:
query {
User(id: 112233) {
firstName
lastName
addresses
orders {
orderDate
amount
status
}
}
}В блоке выше мы делаем запрос для получения клиента с идентификатором 112233, затем мы получаем определенные атрибуты о нем (включая firstName, lastName и addresses), а также все заказы, которые принадлежат этому клиенту.
Теперь получение данных выглядит так:

Веб-браузер делает только один запрос к нашему серверу. Содержимое этого запроса будет таким, как будет показано ниже. Реализация GraphQL разберет запрос и обработает его.
На первый взгляд, это выглядит выгодно: наш фронтенд делает только один запрос к бекенду! Ура!
В некотором смысле, это отражает наше обсуждение ранее о том, почему вы хотите использовать одно-табличный дизайн в DynamoDB. Мы хотим делать только один запрос к DynamoDB для получения различных данных, подобно тому, как фронтенд хочет сделать только один запрос к бекенд для получения различных ресурсов. Это звучит как идеальное совпадение!
Проблема заключается в том, как GraphQL обрабатывает ресурсы на стороне сервера. Каждое поле каждого типа в вашей схеме GraphQL обрабатывается специальным резолвером. Этот резолвер понимает, как заполнить данные для полей.
Для разных типов в вашем запросе, таких как User и Order в нашем примере, обычно у вас есть резолвер, который делает запрос к базе данных, чтобы получить данные. Резолверу будут переданы некоторые аргументы, чтобы указать, какие записи этого типа нужны, а затем резолвер получит и вернет их.
Проблема заключается в том, что резолверы являются практически независимыми друг от друга. В приведенном выше примере корневой резолвер выполнится первым, чтобы найти пользователя с идентификатором 112233. Для этого нужен запрос к базе данных. Затем, когда эти данные будут получены, они будут переданы резолверу Order, чтобы получить соответствующие заказы. Это приведет к последующим запросам к базе для их получения.
Теперь наш процесс выглядит так:

В этом сценарии наш бекенд выполняет несколько последовательных запросов к DynamoDB. Это именно то, что мы пытаемся избежать с помощью единой таблицы!
Это не означает, что вы не можете использовать DynamoDB с GraphQL - конечно, можете. Я просто думаю, что использование единой таблицы при использовании GraphQL с DynamoDB является неоправданным тратой времени. Поскольку сущности GraphQL запрашиваются отдельно, я думаю, что оправдано размещать каждую сущность в отдельной таблице. Это обеспечит большую гибкость и упростит аналитику в будущем.
Заключение
В этой статье мы рассмотрели концепцию одно-табличного дизайна в DynamoDB. Сначала мы рассмотрели историю развития NoSQL и DynamoDB и почему проектирование с единственной таблицей является необходимым.
Во-вторых, мы рассмотрели некоторые недостатки одно-табличного дизайна. Конкретно мы увидели, как проектирование с единственной таблицей может затруднить доступ к вашим данным и усложнить работу с аналитикой.
Наконец, мы рассмотрели две ситуации, когда преимущества одно-табличного дизайна в DynamoDB могут не оправдать затрат. Первая ситуация - это новые, быстро развивающиеся приложения с использованием бессерверных вычислений, где ключевым является гибкость. Вторая ситуация - это использование GraphQL из-за способа его выполнения.
Я по-прежнему являюсь сторонником проектирования с единственной таблицей в большинстве случаев. И даже если вы сомневаетесь, что это подходит для вашей ситуации, я все же считаю, что вы должны изучить и понять этот подход, прежде чем отказаться от него. Основные принципы проектирования NoSQL помогут вам даже если вы не следуете лучшим практикам.